Compare commits
1250 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
| 53835adf23 | |||
| 279f5e115d | |||
| 90fa1104a7 | |||
| b5421c72f1 | |||
| 3b1bdcbae2 | |||
| d171024456 | |||
| 08ebbde322 | |||
| 17bcaf9cb7 | |||
| 943e649fab | |||
| eb5e14461a | |||
| 3e892a1d49 | |||
| f3d012f7a3 | |||
| b326bafbd5 | |||
| 10b54fac72 | |||
| 32eb8ce894 | |||
| 5c57e068c1 | |||
| 8350c811a8 | |||
| bd97a84f62 | |||
| 1d4fe226c5 | |||
| e4dfe39bfc | |||
| 07c864e507 | |||
| 94b6ae05c8 | |||
| 1757237dbd | |||
| 13743a6120 | |||
| e4d17b9621 | |||
| 27000de78a | |||
| 1ddd7fbcb8 | |||
| bc885eaa31 | |||
| ef1dc1e424 | |||
| 739675d1fe | |||
| 2d07034e35 | |||
| b602572b97 | |||
| d9de932595 | |||
| 2dce679f63 | |||
| bb93e24e0f | |||
| 787b2d55f4 | |||
| 19b878a71c | |||
| c740f5756c | |||
| d74b9c7862 | |||
| 53362832e9 | |||
| 7e39c02114 | |||
| 3a79db0090 | |||
| ae55844e06 | |||
| 816d074fc2 | |||
| 925cbe6da8 | |||
| 02bd2f80a8 | |||
| 76526659ec | |||
| 8914727cf8 | |||
| cbfa1e7f81 | |||
| 42edf41ba7 | |||
| 2b35714ca5 | |||
| a9c5c490d5 | |||
| b5820c81aa | |||
| c7f25dc562 | |||
| 142e1fcab6 | |||
| 76f0a3b982 | |||
| 6c2cbb4a1a | |||
| 39d3900d8e | |||
| fffb200296 | |||
| f5c2599987 | |||
| 8aae483cb0 | |||
| 90955d22fa | |||
| 3ff27b9d4f | |||
| 294ed8773d | |||
| 4b8e4eb523 | |||
| 7f2f0068e6 | |||
| e1ff132805 | |||
| 9cdcd89500 | |||
| 4532078a2a | |||
| ab23830418 | |||
| d9cb251a8d | |||
| 48dc48319b | |||
| 1f0d59fc55 | |||
| 4efbb8457b | |||
| 63ef14265f | |||
| baa044d823 | |||
| bdd5275dd4 | |||
| afaff37d85 | |||
| 41fd93f699 | |||
| d9bf1a6376 | |||
| 74bf4c977e | |||
| 4623c3daf1 | |||
| d0c3ab425e | |||
| f4335433fc | |||
| 0a4f59282c | |||
| 7c014cad7e | |||
| 1261d737c0 | |||
| 0825ff7427 | |||
| 7a13791635 | |||
| fccb1b25cc | |||
| d915e95b14 | |||
| 56bb93de8e | |||
| b4564c66f7 | |||
| ae46140751 | |||
| f77059b0f7 | |||
| 43bd9a77e9 | |||
| 5c40e8ed3f | |||
| 4f59ff543e | |||
| 80184cc531 | |||
| 243f0b5153 | |||
| 6ccb83f8e4 | |||
| a484bf9924 | |||
| 7512f77c75 | |||
| e69e112900 | |||
| e9776f7b36 | |||
| a3194eb1a3 | |||
| fd3665b2c4 | |||
| d9e6ac93fd | |||
| adacd64d78 | |||
| ab9d780bf9 | |||
| bbe9de7b17 | |||
| be5e0e6054 | |||
| b55ffff338 | |||
| b5cc9ec4ad | |||
| 4c8a78a1de | |||
| 63d49d1124 | |||
| 0c78264b7d | |||
| 188d932ff1 | |||
| 22d66335d2 | |||
| 3965d00e3c | |||
| 165b87af98 | |||
| 18b40f1ab2 | |||
| a57d8dcb66 | |||
| 549a1dc2e4 | |||
| def0f4940a | |||
| ff1a5042d3 | |||
| f1b53ead45 | |||
| 63ad79bf3d | |||
| a7ef37cbaa | |||
| bd183df368 | |||
| 36fe1697c9 | |||
| 89c187f71d | |||
| 8227d5f636 | |||
| 3f6a9571b0 | |||
| 73853bcd94 | |||
| 49a2977015 | |||
| 772f05ee7a | |||
| 57ad2478fa | |||
| 64811451bc | |||
| 255acf78d4 | |||
| f92bfb3f32 | |||
| 8b091a3c88 | |||
| 17e00c65b7 | |||
| c09c2a662f | |||
| 98ac904dd3 | |||
| 8f30169831 | |||
| a64189a649 | |||
| ee35bdff3d | |||
| 2826bc556c | |||
| c81b82040e | |||
| bcbc8e3f7b | |||
| 0a01d0e869 | |||
| 10911fd692 | |||
| b347000307 | |||
| 78a461f200 | |||
| 1235394467 | |||
| 5289aed9c1 | |||
| 364500d3a6 | |||
| e583f1114b | |||
| 0e383c5122 | |||
| 5f7353564f | |||
| 33253f7f62 | |||
| 274f17104a | |||
| fcbbf34d97 | |||
| 940bf96fcd | |||
| 6471378f6b | |||
| 7585447505 | |||
| 53f990bab3 | |||
| d051688820 | |||
| cff696754e | |||
| 1ffa1f956f | |||
| 2d35b5ccf8 | |||
| 3aef66f309 | |||
| 94ca8b15c8 | |||
| e31cffd42c | |||
| 5146aa1523 | |||
| 0c36a39dce | |||
| d5efd6b914 | |||
| 915eb1539a | |||
| a537a5bb2c | |||
| 83c3ebaccc | |||
| 9b426873a6 | |||
| e73e84bf08 | |||
| 1bcad1ab20 | |||
| 76de9e4c63 | |||
| 8429bdb20b | |||
| ad606e8e83 | |||
| 32c5a8a217 | |||
| 33e253507d | |||
| ebda7b4a06 | |||
| ec69830de1 | |||
| 186a7b8cea | |||
| 070b5c1acb | |||
| eb90c24637 | |||
| c3445e1106 | |||
| c9dea26fd2 | |||
| a099634802 | |||
| cdcc660b16 | |||
| c065ab523d | |||
| a1b4a3d2f8 | |||
| 77aba37f85 | |||
| 020dc8ca83 | |||
| 3402ee4778 | |||
| 928f746115 | |||
| 041ddf8d46 | |||
| e61779ace3 | |||
| 81adbdb680 | |||
| b41de7711f | |||
| 34a1d59a76 | |||
| 72587bd4b9 | |||
| d05c8bd98f | |||
| 02570aad98 | |||
| 037e769074 | |||
| 9449251026 | |||
| 726d618b0e | |||
| dcfb4299cb | |||
| d1c7d283e0 | |||
| 562f1bdd1d | |||
| d0d57dd812 | |||
| e0be38a050 | |||
| b847fdb168 | |||
| 6784848681 | |||
| e0db83de31 | |||
| b81defcc3e | |||
| aa5d4e104d | |||
| 216bd5b5fa | |||
| b59d4a73f2 | |||
| 691d62f3ae | |||
| 351210cfc7 | |||
| 03d11d15a6 | |||
| d5ef37b404 | |||
| 887f29c063 | |||
| a6b5be3ce8 | |||
| a38eb5ac3b | |||
| cfe5c5cd50 | |||
| 5d7bad168c | |||
| 7a393118ca | |||
| 56658725e5 | |||
| d52a81eff3 | |||
| 3197604d29 | |||
| ac5e03a25b | |||
| 450a36cf2e | |||
| e73574c32e | |||
| 364539af82 | |||
| 7abb6db770 | |||
| e07aa0dafe | |||
| f88ff4a520 | |||
| f80c8da943 | |||
| 98cecab906 | |||
| ad7fa40e1b | |||
| e9527b1e72 | |||
| 20cc4f586f | |||
| 9f018ce8c7 | |||
| bd92534fdd | |||
| c42ea60e85 | |||
| 5b740f9861 | |||
| 1872c601a3 | |||
| 5d0d817c4e | |||
| 9175a02fc6 | |||
| e64bf32b17 | |||
| 7d08f5ecab | |||
| b342417dc9 | |||
| ce97d6ed40 | |||
| 88c40e5bdf | |||
|
|
025575a7e1 | ||
| c7eff2c182 | |||
| db54afeca4 | |||
| be893d679d | |||
| 8fc4ae6c34 | |||
| a211a2fbd6 | |||
| a4b1094183 | |||
| bab5f7c7e8 | |||
| 48d4f5bc23 | |||
| cfe450fac7 | |||
| b2da24c4b5 | |||
| 016a6fcc95 | |||
| 3d6a98adcb | |||
| 4957f11bb0 | |||
| 5aefd2ff65 | |||
| 23dfbb60aa | |||
| 2e0e8aad52 | |||
| 0311fad127 | |||
| 702ee93a49 | |||
| 06d2651d3a | |||
| 6fbde6e66b | |||
| c96a5e4e45 | |||
| 88581af7d3 | |||
| 3bf3e2830c | |||
| d13d6c82dc | |||
| c3f6bf12c1 | |||
| 6b8922b260 | |||
| 2d9776ebbc | |||
| c56d8e29d9 | |||
| 71edd2cd87 | |||
| 71483a8619 | |||
| 559a31c048 | |||
| e7907bd33b | |||
| e24dea6e1a | |||
| 77076f47b7 | |||
| 32eea210f2 | |||
| 7686a445f2 | |||
| bb95440931 | |||
| 2197c54133 | |||
| a1d179a6b5 | |||
| 2504c685f5 | |||
| 1a6d215f89 | |||
| 1162e335f9 | |||
| b4ca83880f | |||
| bea2c670ec | |||
| 063dcd1efa | |||
| 01da2a3768 | |||
| bd98a9d3be | |||
| fe04ed6240 | |||
| 75d0bbab7f | |||
| 22d60d3064 | |||
| 78727972cd | |||
| 8df6fc4bf3 | |||
| 1a99390f9a | |||
| de9d9cb328 | |||
| 3dcc75fd8d | |||
| 482a93a49c | |||
| 3f2ead9a14 | |||
| 26746d59d0 | |||
| 036e2a20b9 | |||
| f80ed17fb2 | |||
| b992a33868 | |||
| 010fce293b | |||
| 2d80bd1c4f | |||
| d0bdc33f55 | |||
| 0240ac24dc | |||
| c806da095f | |||
| 5e14de5883 | |||
| 1011723580 | |||
| d4ca8a5e23 | |||
| af6cfc04d6 | |||
| 3f482a44b5 | |||
| 8cea14cc4d | |||
| 0de7b7ac6f | |||
| a9174024d1 | |||
| 93e36fd356 | |||
| 98c2db90c6 | |||
| 4fbea422ab | |||
| 5da7a914bb | |||
| fee475c4ae | |||
| 4755875388 | |||
| f8c46c9bcb | |||
| 217bf92648 | |||
| 64cc53b462 | |||
| 98ef74e3cb | |||
| 1774a194e0 | |||
| 454c8fd895 | |||
| c9ecb1e117 | |||
| cb4e82b1ca | |||
| 520b06748e | |||
| aa9c494e16 | |||
| 2797fe2039 | |||
| 1abf61d1fc | |||
| 7ccad7cee6 | |||
| 9204dc8dbf | |||
| 99221a5463 | |||
| 2372d906c0 | |||
| e7ddfee584 | |||
| b5f3345e9a | |||
| d09d383fab | |||
| 4d9a1b91bd | |||
| d4d4623c76 | |||
| 10a112e180 | |||
| 951cc830a1 | |||
| b1cf76c004 | |||
| 3e926981ea | |||
| 1dbfb5636b | |||
| 84109611cf | |||
| f55147fab4 | |||
| c30c3b2be8 | |||
| 9a62bcd94d | |||
| 31cc4de512 | |||
| 48fa5847fc | |||
| 922906146b | |||
| e08a6d253b | |||
| 576dc43627 | |||
| fe78cd0f9b | |||
| 50f4205743 | |||
| 670c89d4cb | |||
| dbbac1f125 | |||
| d7f39c528f | |||
| d64df15f33 | |||
| 708b3b8ae2 | |||
| b5d1cc40df | |||
| 78ba13aa59 | |||
| 38c65bb735 | |||
| ca13fbd359 | |||
| fc24d25d03 | |||
| e12e139143 | |||
| 13d98987c4 | |||
| c47eaec6ac | |||
| 4936ab1e93 | |||
| d22679dab6 | |||
| 97e4f327c8 | |||
| 58659f217c | |||
| fae1be974e | |||
| 10c5517013 | |||
| 0534b21a1a | |||
| 52255aec0f | |||
| c62fe1f3ed | |||
| 4aa4ff8d46 | |||
| 498aaaccf4 | |||
| a3e9d0c9df | |||
| fc30546f7f | |||
| dce18ad848 | |||
| 9ce49ff66f | |||
| 5509f9c143 | |||
| bd987ff9f2 | |||
| 5208ea17f0 | |||
| 2f2f770fb9 | |||
| 1229f4bda7 | |||
| 22eec496fd | |||
| 0c5094133f | |||
| 15c82dbf31 | |||
| a2c9baa731 | |||
| 906510a66f | |||
| 6cbce1139b | |||
| 2e95faf73a | |||
| cacf1872e1 | |||
| 3cdf28843b | |||
| b9bf125809 | |||
| 3d172dbe10 | |||
| 878733dec1 | |||
| b15765bb22 | |||
| b27f66b38b | |||
| a29ca8833a | |||
| ab6865ecaa | |||
| 87ba0e3dd3 | |||
| e39200ee7f | |||
| 48f8d348b5 | |||
| 9e4799fc1d | |||
| 4297a48520 | |||
| 369acec5f0 | |||
| 61785a9438 | |||
| a717c8333d | |||
| 138250b5c0 | |||
|
|
140e15191a | ||
| b76d500026 | |||
| 6b72a975e8 | |||
|
|
42e71e2dd9 | ||
|
|
946bc7f9f1 | ||
| b06eb9c21c | |||
| d57316ea1c | |||
| 156fc07b79 | |||
| d58d4dfb69 | |||
| 9e65785250 | |||
| 1d93bc6b88 | |||
| de59c44ae8 | |||
| 2036b817d3 | |||
|
|
b9d48f1295 | ||
| 82a789f03d | |||
| f27d3035e7 | |||
| eb6f1414d0 | |||
| 91044d842e | |||
| 93464ea6f4 | |||
| 4a773587c5 | |||
| ff74724afa | |||
| 2d57819456 | |||
| 8ad2446551 | |||
| 14219bb803 | |||
| fab240a113 | |||
| a7434babd6 | |||
| 9c4d430f50 | |||
| 97c6100dd8 | |||
| ed0603679a | |||
| 57ac07b858 | |||
| f1b4128614 | |||
| c3e2b89bdb | |||
| cd3159da34 | |||
| 99c3630651 | |||
| 7bd199056e | |||
| abbced8914 | |||
| 5244c3ba37 | |||
| 68a2950c80 | |||
| 99b2567b83 | |||
|
|
8fcff43616 | ||
|
|
5d6075672c | ||
| d9ded4c56a | |||
| 6e55139ffc | |||
| ec7e0f9702 | |||
| 9a3d26f474 | |||
| 5d9122dad8 | |||
| ea3cf0455b | |||
| 5a3033991b | |||
| 56535a22d3 | |||
| 32230d93e4 | |||
| bd728b347f | |||
| 6a251795b3 | |||
|
|
0854127b94 | ||
|
|
517b2acdce | ||
| 582ec7de93 | |||
| af65f29a56 | |||
| 237a787b19 | |||
| fdf720fd08 | |||
| f08f95e1c7 | |||
| 17012a6998 | |||
| 9b37357264 | |||
| 9736cc5b8f | |||
| 9dacd8eab3 | |||
| 849eb5188d | |||
| 55ad30bdaf | |||
| 624de1cc22 | |||
| a16ce8de2b | |||
| 4939bf781d | |||
| 4fa9922d7d | |||
| b0c087653c | |||
| 069db4e233 | |||
| b1226fadf9 | |||
| 7c539430bb | |||
| 11361bddf9 | |||
| 0ad9a351df | |||
| 79f30ce433 | |||
| 23a6f1fe1a | |||
| 41da6bd005 | |||
| b13b158f6c | |||
| 0d8fd39491 | |||
| 14d9da2af3 | |||
| 42b4395329 | |||
| 18c270c9ff | |||
| d0fdb99f43 | |||
| 26f7a860eb | |||
| 4f4a66e067 | |||
| a5a6855bcb | |||
| 4f43917680 | |||
| 15f9bc7e23 | |||
| 9764b95549 | |||
| a3d49dc7a9 | |||
| 39b3d6f5ef | |||
| e579083c4c | |||
| 89ad49be09 | |||
| d54e37787e | |||
| e975c1305d | |||
| 32546e03d2 | |||
| 9522887db7 | |||
| 9a6c81083e | |||
| 369543e606 | |||
| 38007e9b2f | |||
| 5a6c0f038e | |||
| 67f20bb84a | |||
| df53b4af35 | |||
| 26f5198070 | |||
| 80b87c13b3 | |||
| d8b36e8e16 | |||
| 94422ee832 | |||
| ccded68704 | |||
| 0e1bf24a01 | |||
| 635abb25e1 | |||
| e244502cdd | |||
| 6d426239bb | |||
| 0968b18d78 | |||
| de2e164040 | |||
| b77288fa85 | |||
| 7208d12af2 | |||
| e9a09c427f | |||
| 9065b1effd | |||
| 93990295ec | |||
| ed45d9fceb | |||
| 80cef12276 | |||
| bcab212f34 | |||
| eadf0b71fe | |||
| 7293cd877a | |||
| cc5307000f | |||
| 2f8c425f9d | |||
| da19f64d07 | |||
| b7ea1ea43d | |||
| 1887ffd153 | |||
| 0c81fc8076 | |||
| 4db2a23226 | |||
| bf46c12e69 | |||
| 11393f2bad | |||
| acb779d298 | |||
| e10c0c8896 | |||
| 2f21819f22 | |||
| eb4f8def32 | |||
| b79f78cc8e | |||
| ece560f2ff | |||
| 7f09df3968 | |||
| 5af69cfa2c | |||
| 97364a71e0 | |||
| 4db145504d | |||
| d51b32b692 | |||
| 09f086625e | |||
| f5e0e2cacd | |||
| 0abf1e0243 | |||
| 38f8b31b58 | |||
| 289aa70b91 | |||
| c4047e488c | |||
| 08b435b191 | |||
| 21606fff97 | |||
| 4da4e9bc8a | |||
| 687e7c8183 | |||
| af79987f2e | |||
| c552ebe754 | |||
| 49023656d3 | |||
| 7f4281c0c7 | |||
| 79b0289f72 | |||
| f111a07b7c | |||
| b7d09419db | |||
| cac1df1b02 | |||
| 2278572956 | |||
| f516a886e9 | |||
| 84f7990e3b | |||
| 4bf9d7eb82 | |||
| 08aff172ed | |||
| 2ad90801df | |||
| b49168fc83 | |||
| 236018a74f | |||
| b81177028a | |||
| 70d6ac1a44 | |||
| 71ca8d8e55 | |||
| e429df9a83 | |||
| 37384f4bf2 | |||
| d7f3920bc4 | |||
| 74b9c90856 | |||
| cf3ca04242 | |||
| 8b06a8eb76 | |||
| a95e93cdfd | |||
| 8e59a3c08a | |||
| 1a9b421b5e | |||
| 0759352656 | |||
| 641ce0d453 | |||
| 55e2b15928 | |||
| 8e7a30d6eb | |||
| 8d1d728241 | |||
| dfbf9f0d34 | |||
| 670cf1a222 | |||
| ae45f0467a | |||
| cbab37d7a6 | |||
| 70510dc906 | |||
| 7d005f7894 | |||
| b620d8454e | |||
| 54c801c0bc | |||
| d5888fd98f | |||
| 19b77d22cf | |||
| 8c23357eb4 | |||
| 738c5220aa | |||
| 6c5ab7e7db | |||
| 13660e80f1 | |||
| 98359fe3c5 | |||
| db7890b061 | |||
| c7cd410f7d | |||
| 270b5f7944 | |||
| e14dc631c5 | |||
| 8c458cf6e7 | |||
| 290abefa3c | |||
| 0793a45b32 | |||
| 6eaef23ffd | |||
| 05a1a0830d | |||
| f202afe564 | |||
| 94f6a18dbd | |||
| 8b04e06d0e | |||
| 7bc29bc310 | |||
| 8d03d79a43 | |||
| 888f08f7ea | |||
| 7889c710d0 | |||
| 051ef6fbf3 | |||
| 1244e03ca8 | |||
| 1321ff8ef3 | |||
| eb510a665b | |||
| ce0aa244b3 | |||
| 462bb97028 | |||
| f02b578ad4 | |||
| a8389a1748 | |||
| bd02969944 | |||
| 18ad2b3e2e | |||
| ca24fe5a58 | |||
| b841543d06 | |||
| e1722ce583 | |||
| b8f3c29d58 | |||
| 1906920e0f | |||
| 9feade3a56 | |||
| 431ecad829 | |||
| fe1160531f | |||
| 97bf0c71e2 | |||
| 2658cd723d | |||
| 3843b1868e | |||
| 3ebba9181a | |||
| 7906f71afe | |||
| 976f57094c | |||
| b4c3aeb7b0 | |||
| a51e3c0330 | |||
| 5a6dd420ad | |||
| 465c5fca2f | |||
| 03b0a0fc4f | |||
| 6a88da919e | |||
| 3b6cb298dd | |||
| 1acf509cd5 | |||
| b013eae5ff | |||
| 297a2d0fd0 | |||
| 5805ccc88d | |||
| 065104678a | |||
| 64cd72834f | |||
| 3b69e68c68 | |||
| 96714cf86f | |||
| ac85d71c09 | |||
| a183810ec0 | |||
| 6e769db305 | |||
| 5f48040f68 | |||
| 67cd24be8c | |||
| 7ce7770fd9 | |||
| 95f1777282 | |||
| 19eb0489b1 | |||
| 7be98d80fe | |||
| 2ab2ebdac3 | |||
| ea8b11bf66 | |||
| 37ea275bb3 | |||
| 30f25a1ba6 | |||
| 4e73c3673f | |||
| 4eaf719563 | |||
| 75d6563d88 | |||
| e2f5af01ca | |||
| f17685b6af | |||
| b1bb64c130 | |||
| 4d81829a7d | |||
| 425a07c453 | |||
| 967567a82d | |||
| dd10986c2a | |||
| 1b79126c95 | |||
| 23565f6494 | |||
| b6de5e9024 | |||
| cdb4302794 | |||
| 3466cae684 | |||
| 650c359280 | |||
| 9914034a16 | |||
| 75f985b727 | |||
| bf16cd8874 | |||
| 43790f1ef1 | |||
| 0503d1500a | |||
| d624e1b9e2 | |||
| 4f8404b180 | |||
| 7a75e080c9 | |||
| 46836c436f | |||
| fb75959d0a | |||
| 24eec48dfb | |||
| 69275ddf3c | |||
| 914c8b0d3c | |||
| f5745a4b43 | |||
| 6e7db225aa | |||
| 42846fc2c6 | |||
| df308ff8fa | |||
| 48e6cba92d | |||
| 607b500a20 | |||
| 7f7ed6b851 | |||
| d519291a6f | |||
| e50cc2d517 | |||
| e93104dc31 | |||
| 7c0493590d | |||
| 65e4b3dfc3 | |||
| 56d9b16765 | |||
| 94a0b9bbd8 | |||
| 326fcb088e | |||
| a70ecb4bac | |||
| 990335d73b | |||
| 22dce13975 | |||
| 6d5579ab93 | |||
| 8262accfa8 | |||
| 018e294592 | |||
| 1b3bcf5dd9 | |||
| a0ea885b44 | |||
| 5d4f2d724a | |||
| 9f827d4138 | |||
| a2d5579560 | |||
| bcd2fe3b24 | |||
| 8b254bc6f1 | |||
| 713ef1b3f3 | |||
| 8a1b7c01a5 | |||
| a9ed0f3a04 | |||
| 5df7c705f6 | |||
| 7bc2147c32 | |||
| fdbb633b7c | |||
| 025a444027 | |||
| 8f34de0f5e | |||
| a94df966d6 | |||
| ad38cf5973 | |||
| a163da80cd | |||
| cc8452ef41 | |||
| 47f56e9eab | |||
| 14779680b6 | |||
| 3c12261123 | |||
| ad6fb599c6 | |||
| c046bc0dfd | |||
| 7ce7063e70 | |||
| bf94f4b7fa | |||
| 6a3d7ff793 | |||
| 376a8db290 | |||
| c28de252be | |||
| 37ad32d82c | |||
| d425a1b64b | |||
| 36851f4d8c | |||
| 5fd78c2e28 | |||
| 2ad4bd283c | |||
| 857734f725 | |||
| d640ff2c17 | |||
| 89504d718a | |||
| 2a398b18be | |||
| b4aad5d442 | |||
| bf509acc4b | |||
| 81b9a37659 | |||
| 07563ae39d | |||
| 023b5a759c | |||
| 870a494434 | |||
| 5210ba5989 | |||
| 01bbdbd871 | |||
| 4e988eb1d5 | |||
| 1dd44d87f3 | |||
| e2a5a6e07f | |||
| 1cc689607f | |||
| b97ccf69a1 | |||
| 79ec7d1a71 | |||
| 62c30e5405 | |||
| 05eeddad6a | |||
| 7e1fccbc1f | |||
| 1b59e3931b | |||
| 8225a94b2a | |||
| 5df5b672c8 | |||
| cd7cdf0d7f | |||
| ae824caeb5 | |||
| de34985d85 | |||
| d6ccd33659 | |||
| 09c19da0b4 | |||
| 758fa7b609 | |||
| 6a3a90cfc8 | |||
| 20b3a8c24f | |||
| 8b31786a99 | |||
| 1677cfc7bd | |||
| 31b2756ea4 | |||
| caffd2ffd0 | |||
| d26ba7a260 | |||
| 3d042fedb5 | |||
| cf1f45d1f1 | |||
| 3b73f2ec66 | |||
| a067accf1f | |||
| d71e1dd711 | |||
| f42be61cb7 | |||
| a0eebc2829 | |||
| 634b32e6f6 | |||
| a3b6cbdc35 | |||
| f343ab27fc | |||
| 43ddc7a199 | |||
| 8b0de16542 | |||
| 9fe8dd9221 | |||
| d58a0976f9 | |||
| d1c1cf9a88 | |||
| 41b08e6dae | |||
| 3bfbe0d902 | |||
| a4b526f10b | |||
| 791de5d962 | |||
| 56aab9cd60 | |||
| 5e391d8034 | |||
| b0ab648a84 | |||
| e5049bf745 | |||
| 634ca5ed66 | |||
| f0b0a292de | |||
| 3360fc9987 | |||
| 945f0ec273 | |||
| 0c615320af | |||
| 9e8641e5c9 | |||
| fbd511101e | |||
| c5b35646f7 | |||
| d76800b16d | |||
| a423ce391a | |||
| 6c20b11439 | |||
| fc184ce27a | |||
| a67f15374b | |||
| bc91f11049 | |||
| 20fe1b96a2 | |||
| 23cf241a87 | |||
| f9e7d0eaf1 | |||
| 67b8fffafb | |||
| a8694b8de7 | |||
| aeb9c4174e | |||
| 7fa2c5ba7f | |||
| 8d132a7fe0 | |||
| 5deb5e0177 | |||
| fcfbf6e317 | |||
| 830425a99f | |||
| 243a461dc6 | |||
| 8c88c44684 | |||
| 8ceb2ef2aa | |||
| 8e1f7c3989 | |||
| bc67b44c67 | |||
| 0618cd7610 | |||
| e80a20c38c | |||
| b9ca3c5679 | |||
| 2244c154f9 | |||
| 5ed58223c3 | |||
| a6848cace3 | |||
| 665d43c6da | |||
| f5af4be555 | |||
| 63ad60f2ca | |||
| 16690600ba | |||
| e71f213555 | |||
| ca58249d62 | |||
| 0e662ff2c8 | |||
| 6dc09aa381 | |||
| 62480ac786 | |||
| eaad73df7c | |||
| 1cfb5f0d4a | |||
| 87d89eb2b0 | |||
| 06fec23f6b | |||
| fbe064ecb4 | |||
| d981396f28 | |||
| 8b7ac79ba0 | |||
| 297c746fa2 | |||
| 68fb45f2e7 | |||
| 54446db373 | |||
| c026422601 | |||
| 552d2e265b | |||
| da55365f81 | |||
| 561423c04d | |||
| db92d0b8ad | |||
| e6b63c5f4c | |||
| 68f84e57dc | |||
| 6fcf640ecb | |||
| 18ddd8ec33 | |||
| f381e49918 | |||
| 8457edcd52 | |||
| b40c253814 | |||
| a18bc7cf65 | |||
| 4103ad2cea | |||
| 66f41d824f | |||
| 8bcae47773 | |||
| 66fa011570 | |||
| 5ea1c96a20 | |||
| 1396272f18 | |||
| f647915eab | |||
| 1b3c522227 | |||
| ce2d8034e0 | |||
| fb71aa80af | |||
| e6d905f298 | |||
| e9b906c401 | |||
| f06b3f7005 | |||
| 008f8514d1 | |||
| e97723fe7c | |||
| 3e85a63006 | |||
| 517d7b1fc3 | |||
| 7faec6987f | |||
| fc13c9a2f3 | |||
| 8d3ce15207 | |||
| b1cf1e6857 | |||
| ffb046b1e8 | |||
| 5142ac9e82 | |||
| c6d5c4a29f | |||
| 8f2777c7bf | |||
| 74a42e9112 | |||
| 55f9e170a4 | |||
| 6484768109 | |||
| 881afd4d93 | |||
| e7a7897e78 | |||
| 04b5ac602b | |||
| d0d73d000e | |||
| 60f109d22e | |||
| 1a3e7b0d63 | |||
| e59e89f787 | |||
| 915bd89914 | |||
| 5c875ee08b | |||
| 8b58311a45 | |||
| 2792a31f7e | |||
| 2613c53226 | |||
| a209c4562e | |||
| 5ba87c6544 | |||
| 8f01867706 | |||
| 0e1761cd53 | |||
| 6c2aec3fa9 | |||
| 4910123b3d | |||
| d7a9c85954 | |||
| c05d698c66 | |||
| 0a69b329b8 | |||
| 502c91e3c4 | |||
| e95865c48e | |||
| a71d71e63f | |||
| 7b43f1391c | |||
| 6430bc9fe3 | |||
| c9ae443d5f | |||
| aa3f803c37 | |||
| 6977c4ccd9 | |||
| d66c3665ee | |||
| 4a532daff3 | |||
| e4cae78b84 | |||
| af7117af28 | |||
| 7aaa583268 | |||
| ad8348166a | |||
| abfe66c888 | |||
| 3c7c795756 | |||
| 4213f05c92 | |||
| fc91208134 | |||
| ed12581bd2 | |||
| 67571f22f6 | |||
| e1b18c8dc1 | |||
| a5cb65f583 | |||
| 3a6210c3a7 | |||
| a9900f5747 | |||
| e1637bffb3 | |||
| 5229e6b576 | |||
| 0f405f933b | |||
| 90565214c3 | |||
| 0f23f2e051 | |||
| 9aaa261651 | |||
| 6cb61bc3a4 | |||
| 66982fc3c8 | |||
| 52b098de60 | |||
| 1cfaaaf75e | |||
| bbcba016fe | |||
| 64d5d4fd77 | |||
| a5ef24c3e6 | |||
| 7c94a35874 | |||
| 59bab4ed5f | |||
| 2912a19ffb | |||
| 02dd2ec720 | |||
| ef2b53f291 | |||
| 82b58ebebc | |||
| 31ca371a97 | |||
| 6bd64554c2 | |||
| 9e0d01cff0 | |||
| ece7403da7 | |||
| 4d30a875ef | |||
| 8e7c1ccd6f | |||
| 18d8519f8e | |||
| c65c18ea69 | |||
| 364dd2a47b | |||
| f7f11abbf3 | |||
| dcfc3203dd | |||
| e437f80330 | |||
| 9024af9c7b | |||
| 4ddb1c615d | |||
| e0f2b6dbe0 | |||
| d81d8e4e2a | |||
| 0f32b08cb8 | |||
| 6fec24e50d | |||
| 1b4b97ced0 | |||
| ce315e90a5 | |||
| b7701994a4 | |||
| 410cce25eb | |||
| e38fd6da6f | |||
| 0a21fc26bf | |||
| 8900908632 | |||
| 1732b20210 | |||
| 7fdb10d2fc | |||
| 0853fde213 | |||
| 3a4efa2e88 | |||
| 048e8bacce | |||
| 96ec1fee8c | |||
| e4dcdcc3b3 | |||
| 0ab43b0950 | |||
| dd3e672668 | |||
| 6ea2cda987 | |||
| 21b9c8ddc8 | |||
| 9d961f88ef | |||
| 38a7c9458b | |||
| 7a72226cb2 | |||
| 2dec3b7fd7 | |||
| ee19dddded | |||
| 2aa1ed8ba8 | |||
| d382204501 | |||
| 1f2f0017ac | |||
| 26b53449aa | |||
| 7cf5363108 | |||
| b9ead554d0 | |||
| d3ac0e1b0d | |||
| 497e92219c | |||
| 425141198c | |||
| b4056d6580 | |||
| 84b82b6923 | |||
| 3cba26c9ae | |||
| 4823550169 | |||
| f9d5552f8a | |||
| ba571b1ef1 | |||
| 102abf2648 | |||
| 8833ded20f | |||
| 18d8e2cdff | |||
| 314f3b6679 | |||
| 3df446fe8e | |||
| bdfb6c3aec | |||
| 4a2a3e6023 | |||
| 1d3354282f | |||
| b8fdf1077a | |||
| 7cbb518aae | |||
| c3b3c58a28 | |||
| 1769d5094e | |||
| b8721a1a8c | |||
| a241ca48f0 | |||
| ee90ebd09f | |||
| 2adff72160 | |||
| 72eeb87937 | |||
| 7df587e6ad | |||
| 903cc387a6 | |||
| 4ab8719c50 | |||
| 2a3901cc38 | |||
| c2390cfe2f | |||
| 0720bbb09e | |||
| fe33b511de | |||
| 570fdf6494 | |||
| 3f75d311e8 | |||
| 68293b2f36 | |||
| 9f6c746d7e | |||
| 2e9e34d69e | |||
| 88e2456c00 | |||
| 1e96a3ab80 | |||
| 19468c3577 | |||
| 901b531c8a | |||
| 0e03c1ee44 | |||
| 00f6179838 | |||
| 7820b3b70e | |||
| 6aa580cea0 | |||
| 9f62c35d5b | |||
| b46698b166 | |||
| 77296a745c | |||
| c64f78be4a | |||
| 07414d4e8a | |||
| e8c3a2eec5 | |||
| 9fcd64dcce | |||
| b65f895234 | |||
| e4851a5bc8 | |||
| 512f3adff4 | |||
| 8c54fbe98e | |||
| 2f325e4557 | |||
| ddd4b8f0ad | |||
| efc3b54774 | |||
| 4e11da80ac | |||
| d4bc0e46bc | |||
| acdefd6a86 | |||
| fc54dc1595 | |||
| c6a5a52003 | |||
| ace77db192 | |||
| dc394917dd | |||
| 7745acb46e | |||
| 569efca5f1 | |||
| 1d6350abad | |||
| d023d4d16a | |||
| 89bdfcbea7 | |||
| c71112f500 | |||
| ecad4bf462 | |||
| 37ddc70929 | |||
| 5cca092842 | |||
| 074d1b438b | |||
| 19b3be94d4 | |||
| 0d4bb047c6 | |||
| 8c85bda12a | |||
| 81d53ed746 | |||
| 562bca06cb | |||
| 419e2efd39 | |||
| 8512254b6c | |||
| dd8fee1544 | |||
| 9527967eb7 | |||
| cc8ff64199 | |||
| d689a11f07 | |||
| a94fdcd91c | |||
| 6fe40f1fd5 | |||
| c6a8d257a7 | |||
| 2d58891978 | |||
| 6cd8597aea | |||
| 7b3cea4c1b | |||
| a34220248b | |||
| c37e1187b7 | |||
| 98b34a632c | |||
| 13faa91944 | |||
| 218e472e17 | |||
| d71c92f784 | |||
| db4ec908e8 | |||
| a21ea5f5de | |||
| bb490cc1d9 | |||
| 6fa381d950 | |||
| 4eba69fa2f | |||
| a2f8b2b110 | |||
| 87828f160b | |||
| aa0b318d7f | |||
| 978c0380a9 | |||
| 4be86aea47 | |||
| 09032933e9 | |||
| e79bbd3b03 | |||
| 6d0186d562 | |||
| ea8087dcc4 | |||
| eb7cbaeab8 | |||
| f17be7c6fb | |||
| 339320f090 | |||
| 4531ed2e3f | |||
| a7e50d42cb | |||
| ff3cfd0f12 | |||
| 3f841b7037 | |||
| 6fe606ebf3 | |||
| f02e25f7ba | |||
| cae31d838f | |||
| 83a473375a | |||
| b4801adcbf | |||
| fdfa9ffa2a | |||
| 1ef18587e3 | |||
| 3e3603a0cf | |||
| 9c51cfc8f6 | |||
| 5c2545f1d5 | |||
| 6a84fe0b2f | |||
| 5a3ac61cfe | |||
| 73715eab13 | |||
| f827083935 | |||
| ef3c214738 | |||
| 4d301b2df0 | |||
| d0403bfa94 | |||
| e4e8b8f532 | |||
| 893013d81e | |||
| 6295d04d22 | |||
| 90ef560f9e | |||
| 0527e13e6c | |||
| 096e6ed4be | |||
| 58de5eec00 | |||
| 73a5a03295 | |||
| c4c4e4dd2c | |||
| 0886550ac7 | |||
| d68a35bae7 | |||
| 2292aacf83 | |||
| c153863808 | |||
| 59b4477e77 | |||
| e8ff9c3e7d | |||
| 9e26d2ee6d | |||
| 2b2d1d5db1 | |||
| 7e9510b55a | |||
| 3944e119d5 | |||
| b2bd5d5e20 | |||
| c93753a9c6 | |||
| 6e7c76f127 | |||
| c0408388fb | |||
| 0f9c622417 | |||
| a05f1391e9 | |||
| 968f19556c | |||
| 22f60d730e | |||
| 3c437c979d | |||
| ca8df714c6 | |||
| 975f47e02e | |||
| 9f98902a90 | |||
| 83869a9ee1 | |||
| 6a2c45d33a | |||
| 26a9c16005 | |||
| 2849260b88 | |||
| 7375808a61 | |||
| c71b1a5a68 | |||
| 33502f0480 | |||
| 68e2b24cc1 | |||
| 123e03aec2 | |||
| cf68aaab06 | |||
| b666d78720 | |||
| 37f485c922 | |||
| 2f771889fb | |||
| 59afbf4e42 | |||
| 9872a8d9ef | |||
| 8c993bd4b9 | |||
| f5a0403207 | |||
| c0df74aede | |||
| fbe7d535f4 |
@ -18,3 +18,4 @@ redirects: null
|
||||
routes: null
|
||||
blog:
|
||||
route: /blog
|
||||
zzztest: TEST
|
||||
|
||||
13
pages/04.categories/dp2023/category.md
Normal file
@ -0,0 +1,13 @@
|
||||
---
|
||||
title: Diplomové práce 2022/2023
|
||||
category: dp2023
|
||||
---
|
||||
# Diplomové práce 2022/2023
|
||||
|
||||
## Témy
|
||||
|
||||
1. Strojový preklad pomocou neurónových sietí (Jancura)
|
||||
2. Generatívne jazykové modely (Megela)
|
||||
3. Detekcia emócií z textu:
|
||||
- https://github.com/savan77/EmotionDetectionBERT
|
||||
|
||||
31
pages/04.categories/vp2022/category.md
Normal file
@ -0,0 +1,31 @@
|
||||
---
|
||||
title: Vedecký projekt 2021/2022
|
||||
category: vp2022
|
||||
---
|
||||
## Vedecký projekt 2022
|
||||
|
||||
Príprava na bakalársky projekt pre študentov 2. ročníka programu Počítačové siete. Letný semester.
|
||||
|
||||
Vedúci: Ing. Daniel Hládek PhD.
|
||||
|
||||
Požiadavky:
|
||||
|
||||
- Chuť naučiť sa niečo nové.
|
||||
|
||||
Obsah:
|
||||
|
||||
- Naštudujete si zadanú problematiku.
|
||||
- Naučte sa základy jazyka Python.
|
||||
- Podrobne si prejdite minimálne dva tutoriály.
|
||||
- Napíšte krátky report na 2 strany kde napíšete čo ste urobili a čo ste sa dozvedeli.
|
||||
|
||||
### Extrakcia informácií z webových stránok
|
||||
|
||||
- Naštudujete si knižnicu BeautifulSoup a navrhnete skripty pre parsovanie niekoľkých webových stránok
|
||||
|
||||
### Dotrénovanie jazykových modelov
|
||||
|
||||
- Naučte sa pracovať s knižnicou HuggingFace transformers.
|
||||
- Naučíte sa základy neurónových jazykových modelov.
|
||||
- Dorénujete neurónovú sieť na vybraný problém.
|
||||
|
||||
5
pages/authors/maros-harahus/author.md
Normal file
@ -0,0 +1,5 @@
|
||||
---
|
||||
title: Maroš Harahus
|
||||
author: Maroš Harahus
|
||||
---
|
||||
|
||||
@ -10,37 +10,71 @@ taxonomy:
|
||||
|
||||
# Záverečné práce na KEMT
|
||||
|
||||
Wiki stánka pre spoluprácu na záverečných prácach.
|
||||
Wiki stránka pre spoluprácu na záverečných prácach.
|
||||
|
||||
- [Často kladené otázky](/topics/faq)
|
||||
- [Ako napíšem záverečnú prácu](/topics/akopisat)
|
||||
|
||||
## Vedúci
|
||||
|
||||
- [Daniel Hládek](/authors/daniel-hladek)
|
||||
- [Prostredie Anaconda a jazyk Python pre strojové učenie](/topics/python)
|
||||
|
||||
## Predmety
|
||||
|
||||
- [Tímový projekt 2021 / Diplomové práce 2022](/categories/tp2021)
|
||||
- [Diplomové práce 2026](https://zp.kemt.fei.tuke.sk/taxonomy?name=category&val=dp2026)
|
||||
- [Bakalárske práce 2026](https://zp.kemt.fei.tuke.sk/taxonomy?name=category&val=bp2026)
|
||||
|
||||
## Vedecké projekty
|
||||
|
||||
## Bežiace projekty
|
||||
|
||||
- [Spracovanie súdnych dát](/topics/legal)
|
||||
|
||||
## Ukončené projekty
|
||||
|
||||
- [Dialógový systém](/topics/chatbot)
|
||||
- Rozpoznávanie nenávistnej reči (Hate Speech Detection)
|
||||
- [Hate Speech Project Page](/topics/hatespeech)
|
||||
- Rozpoznávanie pomenovaných entít
|
||||
- [Projektová stránka](/topics/named-entity)
|
||||
- [Anotujte korpus](/topics/named-entity/navod)
|
||||
- [Ostatné projekty](/categories/projects)
|
||||
- [Podpora slovenčiny v knižnici Spacy](/topics/spacy)
|
||||
- [Slovenský BERT model](/topics/bert)
|
||||
- [AI4Steel](/topics/steel)
|
||||
- Korpus otázok a odpovedí
|
||||
- [Projektová stránka](/topics/question)
|
||||
- [Vytvorte otázky a odpovede](/topics/question/navod)
|
||||
- [Validujte otázky a odpovede](/topics/question/validacie)
|
||||
- [Vytvorte nezodpovedateľné otázky a odpovede](/topics/question/nezodpovedatelne)
|
||||
- Rozpoznávanie pomenovaných entít
|
||||
- [Projektová stránka](/topics/named-entity)
|
||||
- [Anotujte korpus](/topics/named-entity/navod)
|
||||
- [Podpora slovenčiny v knižnici Spacy](/topics/spacy)
|
||||
- [Ostatné projekty](/categories/projects)
|
||||
|
||||
|
||||
## Uzavreté predmety
|
||||
|
||||
- [Výsledky Tímového projektu 2020](/categories/tp2020)
|
||||
- [Bakalárske práce 2020](/categories/bp2020)
|
||||
## 2025
|
||||
|
||||
- [Diplomové práce 2025](https://zp.kemt.fei.tuke.sk/taxonomy?name=category&val=dp2025)
|
||||
- [Bakalárske práce 2025](https://zp.kemt.fei.tuke.sk/taxonomy?name=category&val=bp2025)
|
||||
|
||||
## 2024
|
||||
|
||||
- [Diplomové práce 2024](https://zp.kemt.fei.tuke.sk/taxonomy?name=category&val=dp2024)
|
||||
- [Bakalárske práce 2024](https://zp.kemt.fei.tuke.sk/taxonomy?name=category&val=bp2024)
|
||||
|
||||
|
||||
## 2023
|
||||
|
||||
- [Diplomové práce 2023](/categories/dp2023)
|
||||
- [Bakalárske práce 2023](/categories/bp2023)
|
||||
|
||||
## 2022
|
||||
|
||||
- [Diplomové práce 2022](/categories/dp2022)
|
||||
- [Bakalárske práce 2022](/categories/bp2022)
|
||||
|
||||
## 2021
|
||||
|
||||
- [Bakalárske práce 2021](/categories/bp2021)
|
||||
- [Vedecký projekt 2021](/categories/vp2021)
|
||||
- [Bakalárske práce 2021](/categories/bp2021)
|
||||
- [Diplomové práce 2021](/categories/dp2021)
|
||||
|
||||
## 2020
|
||||
|
||||
- [Výsledky Tímového projektu 2020](/categories/tp2020)
|
||||
- [Bakalárske práce 2020](/categories/bp2020)
|
||||
|
||||
45
pages/interns/bogdan_paul_chis/README.md
Normal file
@ -0,0 +1,45 @@
|
||||
---
|
||||
title: Bogdan Paul Chiș
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [erasmus]
|
||||
tag: [nlp, ie, rag, medical]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
ERASMUS Intern Spring 2026, 20 March - 21 May (62 days)
|
||||
|
||||
Topic:
|
||||
|
||||
(multilingual) Triplet extraction from medical data
|
||||
|
||||
Goal:
|
||||
|
||||
- Construct a knowledge graph from medical package inserts in multiple languages
|
||||
- Utilize the graph in an intelligent agent that recommends medication.
|
||||
|
||||
Tasks:
|
||||
|
||||
- Learn intelligent agents and generative models - OpenAI API, Agent frameworks, RAG systems.
|
||||
- Learn about knowledge graphs and GraphRAG. Read several research papers.
|
||||
- Find several existing drug knowledge databases. Identify possible entities and relations.
|
||||
- Prepare a Python based workflow, use git code repository
|
||||
- Try Light RAG - Simple RAG.
|
||||
- Scrape package inserts and parse the data.
|
||||
- Index the data and write a script that extracts a knowledge graph from data.
|
||||
- Visualize the graph
|
||||
- Prepare an agent that utilizes the unstructured data and graph-data.
|
||||
- Evaluate the agent using DeepEval or RAGAS.
|
||||
- Write a report
|
||||
- Put all code to GIT
|
||||
|
||||
Meeting 18.5.2026
|
||||
|
||||
State:
|
||||
|
||||
All tasks finished.
|
||||
|
||||
Repository with outputs:
|
||||
|
||||
https://github.com/chis-facultate/erasmus-kosice
|
||||
|
||||
@ -1,5 +1,16 @@
|
||||
---
|
||||
title: Cesar Abascal Gutierrez
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [iaeste]
|
||||
tag: [ner,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
## Named entity annotations
|
||||
|
||||
Intern, probably summer 2019
|
||||
|
||||
Cesar Abascal Gutierrez <cesarbielva1994@gmail.com>
|
||||
|
||||
## Goals
|
||||
|
||||
66
pages/interns/oliver_pejic/README.md
Normal file
@ -0,0 +1,66 @@
|
||||
---
|
||||
title: Oliver Pejic
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [iaeste]
|
||||
tag: [hatespeech,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
Oliver Pejic
|
||||
|
||||
IAESTE Intern Summer 2024, 12 weeks in August, September and October.
|
||||
|
||||
Goal:
|
||||
|
||||
- Help with the [Hate Speech Project](/topics/hatespeech)
|
||||
- Help with evaluation of sentence transformer models using toolkit [MTEB](https://github.com/embeddings-benchmark/mteb)
|
||||
|
||||
Final Tasks:
|
||||
|
||||
- Prepare an MTEB evaluation task for [Slovak HATE speech](https://huggingface.co/datasets/TUKE-KEMT/hate_speech_slovak).
|
||||
- Prepare an MTEB evaluation task for [Slovak question answering](https://huggingface.co/datasets/TUKE-KEMT/retrieval-skquad).
|
||||
- [Machine translate](https://huggingface.co/google/madlad400-3b-mt) an SBERT evaluation set for multiple slavic languages.
|
||||
- Write a short scientific paper with results.
|
||||
|
||||
Meeting 3.10.:
|
||||
|
||||
State:
|
||||
|
||||
- Prepared a pull request for Retrieval SK Quad.
|
||||
- Prepared a pull request for Hate Speech Slovak.
|
||||
|
||||
Tasks:
|
||||
|
||||
- Make the pull request compatible with the MTEB Contribution guidelines. Discuss it when it is done.
|
||||
- Submit pull requests to MTEB project.
|
||||
- Machine Translate a database (HotpotQA, DB Pedia, FEVER) . Pick a database that is short, because translation might be slow.
|
||||
|
||||
Non priority tasks:
|
||||
|
||||
- Prepare databse and subnit it to HuggingFace Hub.
|
||||
- Prepare a MTEB PR for the databse.
|
||||
|
||||
Meeting 3.9:
|
||||
|
||||
State: Studied MTEB framework and transformers.
|
||||
|
||||
Tasks:
|
||||
|
||||
- Prepare and try MTEB evaluation tasks for the database. For evaluation you can try me5-base model.
|
||||
- Make a fork of MTEB and do necessary modification, including the documentation references for the task.
|
||||
- Prepare 2 GITHUB pull requests for the databases, preliminary BEIR script given.
|
||||
|
||||
Future tasks:
|
||||
|
||||
- Prepare a machine translation system to create another slovak/multilingual evaluation task from English task.
|
||||
|
||||
Preparation (7.8.2024):
|
||||
|
||||
- Get familiar with [SentenceTransformer](https://sbert.net/) framework, study fundamental papers and write down notes.
|
||||
- Get familiar with [MTEB](https://github.com/embeddings-benchmark/mteb) evaluation framework.
|
||||
- Prepare a working environment on Google Colab or on school server or Anaconda.
|
||||
- Get familiar with [existing finetuning scripts](https://git.kemt.fei.tuke.sk/dano/slovakretrieval).
|
||||
|
||||
|
||||
|
||||
104
pages/interns/sevval_bulburu/README.md
Normal file
@ -0,0 +1,104 @@
|
||||
---
|
||||
title: Sevval Bulburu
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [iaeste]
|
||||
tag: [hatespeech,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
Sevval Bulburu
|
||||
|
||||
|
||||
IAESTE Intern Summer 2023, two months
|
||||
|
||||
Goal: Help with the [Hate Speech Project](/topics/hatespeech)
|
||||
|
||||
Meeting 12.10.2023
|
||||
|
||||
[Github Repo with results](https://github.com/sevvalbulburu/Hate_Speech_Detection_Slovak)
|
||||
|
||||
State:
|
||||
|
||||
- Proposed and tried extra layers above BERT model to make a classifier in seriees of experiments. There is a single sigmoid neuron on the output.
|
||||
- Manually adjusted the slovak HS dataset. Slovak dataset is not balanced. Tried some methods for "balancing" the dataset. By google translate - augmentation. Other samples are "generated" by translation into random langauge and translating back. This creates "paraphrases" of the original samples. It helps.
|
||||
- Tried SMOTE upsampling, it did not work.
|
||||
- Is date and user name an important feature?
|
||||
- tried some grid search for hyperparameter of the neural network - learning rate, dropout, epoch size, batch size. Batch size 64 no good.
|
||||
- Tried multilingal models for Slovak dataset (cnerg), result are not good.
|
||||
|
||||
Tasks:
|
||||
|
||||
- Please send me your work report. Please upload your scripts and notebooks on git and send me a link. git is git.kemt.fei.tuke.sk or github. Prepare some short comment about scripts.You can also upload the slovak datasetthere is some work done on it.
|
||||
|
||||
Ideas for a paper:
|
||||
|
||||
Possible names:
|
||||
|
||||
- "Data set balancing for Multilingual Hate Speech Detection"
|
||||
- "BERT embeddings for HS Detection in Low Resource Languages" (Turkish and Slovak).
|
||||
|
||||
(Possible) Tasks for paper:
|
||||
|
||||
- Create a shared draft document, e.g. on Overleaf or Google Doc
|
||||
- Write a good introduction and literature overview (Zuzka).
|
||||
- Try 2 or 3 class Softmax Layer for neural network.
|
||||
- Change the dataset for 3 class classification.
|
||||
- Prepare classifier for Slovak, English, Turkish and for multiple BERT models. Try to use multilingual BERT model for baseline embeddings.
|
||||
- Measure the effect of balancing the dataset by generation of additional examples.
|
||||
- Summarize experiments in tables.
|
||||
|
||||
|
||||
|
||||
|
||||
Meeting 5.9.2023
|
||||
|
||||
State:
|
||||
|
||||
- Proposed own Flask application
|
||||
- Created Django application with data model https://github.com/hladek/hate-annot
|
||||
|
||||
Tasks:
|
||||
|
||||
Meeting 22.8.2023
|
||||
|
||||
State:
|
||||
|
||||
- Familiar with Python, Anaconda, Tensorflow, AI projects
|
||||
- created account at idoc.fei.tuke.sk and installed anaconda.
|
||||
- Continue with previous open tasks.
|
||||
- Read a website and pick a dataset from https://hatespeechdata.com/
|
||||
- Evaluate (calculate p r f1) existing multilingual model. E.G. https://huggingface.co/Andrazp/multilingual-hate-speech-robacofi with any data
|
||||
- Get familiar with Django.
|
||||
|
||||
|
||||
Notes:
|
||||
|
||||
- ssh bulbur@idoc.fei.tuke.sk
|
||||
- nvidia-smi command to check status of GPU.
|
||||
- Use WinSCP to Copy Files. Use anaconda virtual env to create and activate a new python virtual environment. Use Visual Studio Code Remote to delvelop on your computer and run on remote computer (idoc.fei.tuke.sk). Use the same credentials for idoc server.
|
||||
- Use WSL2 to have local linux just to play.
|
||||
|
||||
Tasks:
|
||||
|
||||
- [ ] Get familiar with the task of Hate speech detection. Find out how can we use Transformer neural networks to detect and categorize hate speech in internet comments created by random people.
|
||||
- [ ] Get familiar with the basic tools: Huggingface Transformers, Learn how to use https://huggingface.co/Andrazp/multilingual-hate-speech-robacofi in Python script. Learn something about Transformer neural networks.
|
||||
|
||||
- [x] get familiar with Prodi.gy annotation tool.
|
||||
- [-] Set up web-based annotation environment for students (open, cooperation with [Vladimir Ferko](/students/2021/vladimir_ferko) ).
|
||||
|
||||
Ideas for annotation tools:
|
||||
|
||||
- https://github.com/UniversalDataTool/universal-data-tool
|
||||
- https://www.johnsnowlabs.com/top-6-text-annotation-tools/
|
||||
- https://app.labelbox.com/
|
||||
- https://github.com/recogito/recogito-js
|
||||
- https://github.com/topics/text-annotation?l=javascript
|
||||
|
||||
Future tasks (to be decided):
|
||||
|
||||
- Translate existing English dataset into Slovak. Use OPUS English Slovak Marian NMT model. Train Slovak munolingual model.
|
||||
- Prepare existing Slovak Twitter dataaset, train evaluate a model.
|
||||
|
||||
|
||||
|
||||
157
pages/interns/yussef_ressaissi/README.md
Normal file
@ -0,0 +1,157 @@
|
||||
---
|
||||
title: Youssef Ressaissi
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [iaeste]
|
||||
tag: [summarization,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
|
||||
IAESTE Intern Summer 2025, 1.7. - 31.8.2025
|
||||
|
||||
Goal: Evaluate and improve language models for summarization in Slovak medical or legal domain.
|
||||
|
||||
Results:
|
||||
|
||||
- [Report](https://git.kemt.fei.tuke.sk/yr804he/summarization25/src/branch/main/)Evaluating%20and%20Improving%20Language%20Models%20for%20Summarization%20in%20the%20Slovak%20Medical%20Domain.pdf
|
||||
- [Repo, Počítanie objektívnych metrík](https://git.kemt.fei.tuke.sk/yr804he/summarization25)
|
||||
- Dotrénovanie Gemma, Slovak Mistral 7b na sumarizáciu: https://git.kemt.fei.tuke.sk/yr804he/summarization25/src/branch/google/gemma-3-4b-it-finetuned
|
||||
- https://git.kemt.fei.tuke.sk/yr804he/summarization25/src/branch/llama3-8b-lora
|
||||
- https://git.kemt.fei.tuke.sk/yr804he/summarization25/src/branch/mixtral-finetuning
|
||||
|
||||
|
||||
|
||||
Tasks:
|
||||
|
||||
1. Get familiar with basic tools
|
||||
- and prepare working environment: HF transformers, datasets, lm-evaluation-harness, HF trl
|
||||
- Read several recent papers about summarization using LLM and write a report.
|
||||
- Get familiar how to perform and evaluate document summarization using language models in Slovak.
|
||||
2. Make a comparison experiment
|
||||
- Pick summarization datasets and models. Evaluate several models for evaluation using ROUGE and BLEU metrics.
|
||||
- https://github.com/slovak-nlp/resources
|
||||
- Describe the experiments. Summarize results in a table. Describe the results.
|
||||
3. Improve performance of a languge model.
|
||||
- Use more data. Prepare a domain-oriented dataset and finetune a model. Maybe generate artificial data to imporve summarization.
|
||||
- Run new expriments and write down the results.
|
||||
4. Report and disseminate
|
||||
- Prepare a final report with analysis, experiments and conclusions.
|
||||
- Publish the fine-tuned models in HF HUB. Publish the paper from the project.
|
||||
|
||||
Meeting 25.8.2025
|
||||
|
||||
State:
|
||||
|
||||
- Fine tuned several models - Slovak Mistral,
|
||||
- HPLT and Gemma 3 looks the best
|
||||
|
||||
Tasks:
|
||||
|
||||
- Finish Report
|
||||
- Define the task that we solved.
|
||||
- List models, Describe the datasets, experimental setup - type of finetuning, type of evaluation.
|
||||
- put results in a table for each model / zero shot performance / manual evaluation / finetuning performance.
|
||||
- describe the created scripts.
|
||||
- write down a conclustion. What did we learn? What new did we discover?
|
||||
- put script and report to the git repository
|
||||
|
||||
Meeting 19.8.
|
||||
|
||||
State:
|
||||
|
||||
- Fine tuned Slovak Mistral 7B
|
||||
- Tried Llama3 7B - results look ok, but MIstral is Better.
|
||||
- Tried gpt-oss, but it does not work because of dependencies.
|
||||
- Work on preliminary final report.
|
||||
- ROUGE score is not good for abstractive summarization.
|
||||
- The best way to evaluate so far is to see it in person.
|
||||
|
||||
Tasks:
|
||||
|
||||
- Try to fine tune other models. 'google/gemma-3-4b-it, HPLT/hplt2c_slk_checkpoints Qwen/Qwen3-4B'. Results wil be in different branches of the repository.
|
||||
- Try to automatically evaluate the results using a large LLM. Read some papers about it. Prepare a script using ollama and gpt-oss-20B.
|
||||
- Work on the final report.
|
||||
|
||||
|
||||
|
||||
Meeting 4.8.
|
||||
|
||||
State:
|
||||
|
||||
- Tested LMs with ROUGE metrics, most models got 4-5 ROGUE, facebook/mbart-large-50 got 17 (trained for translation).
|
||||
- In my opinion, large-50 is not good for finetuning, because it is already fine tuned for translation.
|
||||
- no finetuning done yet.
|
||||
|
||||
Tasks:
|
||||
|
||||
- Try evaluate google/flan-t5-large, kiviki/mbart-slovaksum-large-sum and similar models. These should be already working.
|
||||
- continue working on finetuning t5 or Mbart models, but ask when you are stuck. Use hf examples script on summarization
|
||||
|
||||
Future tasks:
|
||||
|
||||
- use LLMS (open or closed) and evaluate (ROUGE) summarization without fine-tuning on slovak legal data set
|
||||
- install lm-eval-harness, learn it, prepare and run task for slovak summarization
|
||||
|
||||
|
||||
Meeting 13.8.2025
|
||||
|
||||
State:
|
||||
|
||||
- Managed to fine-tune Slovak Mistral-7B on Legal documents. One epoch is enough.
|
||||
- Ditched T5 pipeline
|
||||
|
||||
Tasks:
|
||||
|
||||
- try to fine tune some different llm and compare the results.
|
||||
- try to fine tune with the news dataset.
|
||||
- prepare a table - tables with results
|
||||
- compare with zero- shot scenario (with various models)
|
||||
- dont forget to put scripts on GIT.
|
||||
|
||||
Future task:
|
||||
|
||||
- Find the optimal hyperparameters.
|
||||
- Write the technical report, where you summarize methods, experiments and results.
|
||||
|
||||
|
||||
Meeting 24.7.
|
||||
|
||||
State:
|
||||
|
||||
- Working custom environment with JupyterNotebook
|
||||
- Fine-tuning mbart, results are not great
|
||||
|
||||
Tasks:
|
||||
|
||||
- Try T5 based models: slovak t5-base, umt5, mt5, flan-t5,
|
||||
- Zero shot-evaluate LLMs on news and legal data.
|
||||
- Find a way to fine-tune LLM for summarization.
|
||||
- Fine-tune LLM for summarization.
|
||||
|
||||
Meeting 17.7.2025:
|
||||
|
||||
State:
|
||||
|
||||
- Studying of the task, metrics (ROUGE,BLEU)
|
||||
- Loaded a model. preprocessed a dataset, evaluated a model
|
||||
- loaded more models, used SlovakSum, generated summarization with four model and compare them with ROUGE and BLEU (TUKE-KEMT/slovak-t5-base, google/mt5-small, google/mt5-base, facebook/mbart-large-50)
|
||||
- the comparison is without fine tuning (zero shot), for far, the best is MBART-large
|
||||
- working on legal dataset "dennlinger/eur-lex-sum",
|
||||
- notebooks are on the kemt git
|
||||
|
||||
Tasks:
|
||||
|
||||
- Prepare "mango.kemt.fei.tuke.sk" workflow
|
||||
- Finetune an existing models and evaluate it. Use News and Legal datasets
|
||||
- Try mbart-large, flan-t5-large, slovak-t5-base, google/t5-v1_1-large
|
||||
- Describe the experimental setup, prepare tables with results.
|
||||
|
||||
|
||||
Future tasks:
|
||||
|
||||
- Try prompting LLM and evaluation of the results. We need to pick LLM with SLovak Support
|
||||
- Finetune an LLM to summarize
|
||||
- Use medical data (after they are ready).
|
||||
- Prepare a detailed report (to be converted into a paper).
|
||||
|
||||
@ -12,17 +12,61 @@ taxonomy:
|
||||
|
||||
## Diplomová práca 2022
|
||||
|
||||
*Názov diplomovej práce*: Prepis postupností pomocou neurónových sietí pre strojový preklad
|
||||
[GIT repozitár](https://git.kemt.fei.tuke.sk/dn161mb/dp2022)
|
||||
|
||||
*Názov diplomovej práce*: Neurónový strojový preklad pomocou knižnice Fairseq
|
||||
|
||||
*Meno vedúceho*: Ing. Daniel Hládek, PhD.
|
||||
|
||||
*Zadanie diplomovej práce*:
|
||||
|
||||
1. Vypracujte teoretický prehľad metód "sequence to sequence".
|
||||
2. Pripravte si dátovú množinu na trénovanie modelu sequence to sequence pre úlohu strojového prekladu.
|
||||
3. Vyberte minimálne dva rôzne modely a porovnajte ich presnosť na vhodnej dátovej množine.
|
||||
1. Vypracujte teoretický prehľad metód neurónového strojového prekladu.
|
||||
2. Podrobne opíšte vybranú metódu neurónového strojového prekladu.
|
||||
3. Natrénujte viacero modelov pre strojový preklad pomocou nástroja Fairseq a vyhodnoťte ich.
|
||||
4. Na základe výsledkov experimentov navrhnite zlepšenia.
|
||||
|
||||
|
||||
Stretnutie 11.1.2022
|
||||
|
||||
- Urobené všetky úlohy z minulého stretnutia, okrem textu a gitu.
|
||||
- Natrénované modely fairseq pre obojsmerný preklad angličtina slovenčina.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- dajte všetky skripty do repozitára dp2022
|
||||
- Napíšte si osnovu diplomovej práce.
|
||||
- Vypracujte draft (hrubý text) diplomovej práce.
|
||||
- V texte DP sumarizujte vykonané experimenty.
|
||||
- Pripravte si prezentáciu na obhajoby.
|
||||
- Skontrolovať či sa robí tokenizácia správne pri vyhodnotení.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Pripravte článok (pre vedúceho).
|
||||
- Urobte experiment s architektúrou MBART. Porovnajte Vaše výsledky s výsledkami v článku MBART (Liu et al. : Multilingual Denoising Pre-training for Neural Machine Translation).
|
||||
|
||||
|
||||
Stretnutie 17.12.2021
|
||||
|
||||
Stav:
|
||||
|
||||
- rozbehané trénovanie na slovensko-anglickom (LinDat) paralelnom korpuse.
|
||||
- model z angličtiny do slovenčiny.
|
||||
- tokenizácia subword NMT.
|
||||
- rozbehané trénovanie na GPU, bez anaconda.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Cieľ je aby Vaše experimenty boli zopakovateľné. Pridajte všetky trénovacie skripty do git repozitára. Nepridávajte dáta. Pridajte skripty alebo návody na to ako pripraviť dáta.
|
||||
- [x] Zostavte tabuľku kde zapíšete parametre trénovania a dosiahnuté výsledky.
|
||||
- Napíšte prehľad aktuálnych metód strojového prekladu pomocou neurónových sietí kde prečítate viacero vedeckých článkov a ku každému uvediete názov a čo ste sa z neho dozvedeli. Vyhľadávajte kľúčové slovíčka: "Survey of neural machine translation". Chceme sa dozvedieť aj o transformeroch a neurónových jazykových modeloch.
|
||||
- [x] vyskúšajte trénovanie aj s inými architektúrami. Ku každému trénovaniu si poznačte skript, výsledky a dajte to na git.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- [x] Výskúšajte preklad v opačnom smere.
|
||||
- [x] Vyskúšanie inej metódy tokenizácie (BPE, sentencepiece, wordpiece - huggingface tokenizers).
|
||||
|
||||
Stretnutie 6.7.2021
|
||||
|
||||
Stav:
|
||||
@ -31,7 +75,7 @@ Stav:
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v trénovaní na servri IDOC, použite sakrupt na príápravu prostredia ktorý som Vám dal.
|
||||
- Pokračujte v trénovaní na servri IDOC, použite skript na príápravu prostredia ktorý som Vám dal.
|
||||
- Pripravte veľký slovensko-anglický paralelný korpus a natrénujte z neho model.
|
||||
- Model vyhodnotťe pomocou metriky BLEU. Naštudujte si metriku BLEU.
|
||||
|
||||
|
||||
@ -14,7 +14,7 @@ taxonomy:
|
||||
|
||||
Anotácia a rozpoznávanie pomenovaných entít v slovenskom jazyku.
|
||||
|
||||
|
||||
[CRZP](https://opac.crzp.sk/?fn=detailBiblioForm&sid=ECC3D3F0B3159C4F3217EC027BE4)
|
||||
|
||||
1. Vypracujte teoretický úvod, kde vysvetlíte čo je to rozpoznávanie pomenovaných entít a akými najnovšími metódami sa robí. Vysvetlite, ako pracuje klasifikátor pre rozpoznávanie pomenovaných entít v knižnici Spacy.
|
||||
2. Pripravte postup na anotáciu textového korpusu pre systém Prodigy pre trénovanie modelu vo vybranej úlohe spracovania prirodzeného jazyka.
|
||||
|
||||
133
pages/students/2016/mark_feher/README.md
Normal file
@ -0,0 +1,133 @@
|
||||
---
|
||||
title: Márk Fehér
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [dp2022]
|
||||
tag: [scikit,nlp,klasifikácia]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
# Diplomová práca 2022
|
||||
|
||||
Názov diplomovej práce: Klasifikácia textu metódami strojového učenia
|
||||
|
||||
- [GIT repozitár](https://git.kemt.fei.tuke.sk/mf425hk/dp2022)
|
||||
|
||||
## Návrh na zadanie DP
|
||||
|
||||
1. Vypracujte prehľad metód klasifikácie textu metódami strojového učenia.
|
||||
2. Pripravte slovenské trénovacie dáta vo vhodnom formáte a natrénujte viacero modelov pre klasifikáciu textu do viacerých kategórií
|
||||
3. Navrhnite, vykonajte a vyhodnoťte experimenty pre porovnanie presnosti klasifikácie textu.
|
||||
4. Navrhnite zlepšenia presnosti klasifikácie textu.
|
||||
|
||||
18.3.
|
||||
|
||||
- Práca na texte pokračuje
|
||||
- Podarilo sa spustiť finetning huggingface glue s scnc datasetom.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračovať v texte.
|
||||
- LSTM trénovanie urobené, výsledky sú v práci.
|
||||
- Pokúsiť sa urobiť dataset interface na vlastné dáta.
|
||||
|
||||
4.3.2022
|
||||
|
||||
- Stretnutie bolo aj minulý týždeň.
|
||||
- LSTM trénovanie beží (skoro ukončené).
|
||||
- SlovakBert na colab prvé výsledky cca 65 percent na scnc (asi tam je chyba).
|
||||
- Práca na texte pokračuje.
|
||||
- Vedúcim dodaný skript na scnc datasets rozhranie
|
||||
- Vedúcim dodaný skript na trénovanie run_glue.py
|
||||
- Dodaný skript na inštaláciu pytorch a cuda 11.3
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Práca na texte - sumarizácia experimentov do tabuľky
|
||||
- Vyskúšať dotrénovanie na idoc pomocou dodaných skriptov.
|
||||
- Na trénovanie na pozadí použiť `tmux a -t 0`.
|
||||
|
||||
## Diplomový projekt 2021
|
||||
|
||||
Stretnutie 3.12.
|
||||
|
||||
- Dopracované vyhodnotenie pomocou SCNC. Výsledkom je konfúzna matica a grafy presnosti so štatistickými modelmi.
|
||||
- Rozpracovaná klasifikácia LSTM (Keras).
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pridať klasifikáciu pomocou Huggingface Transformers, model SlovakBert, multilingualBert, alebo aj iné multilinguálne modely.
|
||||
- dokončiť LSTM.
|
||||
- Pokračovať na textovej časti.
|
||||
- Zobrazte aj F1
|
||||
|
||||
|
||||
Stretnutie 5.11.2021
|
||||
|
||||
- Práca na texte, štúdium literatúry
|
||||
- pridané kódy na GIT
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zopakujte experimenty na korpuse scnc. Slovak Categorized News Corpus.
|
||||
- Pokračujte v otvorených úlohách
|
||||
- Upravte skripty do opakovateľnej podoby, pripravte dokumentáciu k skriptom.
|
||||
|
||||
|
||||
Stretnutie 15.10.
|
||||
|
||||
- trénovanie pomocou LSTM, zatiaľ nie je na gite
|
||||
- písanie do šabóny práce (cca 35 strán).
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Doplniť na GIT.
|
||||
- Zabrániť overfittingu LSTM. Early stopping alebo dropout.
|
||||
|
||||
Stretnutie 1.10.
|
||||
|
||||
Stav:
|
||||
|
||||
- modifikácia trénovacích skriptov na vypisovanie pomocných štatistík.
|
||||
- Vytvorený GIT repozitár
|
||||
- Práca na text (cca 22 strán)
|
||||
- Pridaná referenčná literatúra.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Stiahnite si šablónu práce a vložte text čo máte pripravené, vrátane bibliografie.
|
||||
- [x] Doplňte zdrojové kódy na GITe, tak aby boli opakovateľné.
|
||||
- [x] Zoznam knižníc zapíšte do súboru requirements.txt.
|
||||
- Alebo zapíšte zoznam conda balíčkov.
|
||||
- Vyberte jednu úlohu zo zásobníka a vypracujte ju.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vyskúšajte klasifikáciu pomocou neurónových sietí.
|
||||
- Vytvorte web demo pomocou Docker
|
||||
- [x] Skúste klasifikáciu pomocou neurónovej siete.
|
||||
|
||||
|
||||
|
||||
|
||||
Stretnutie 23.9.
|
||||
|
||||
Stav:
|
||||
|
||||
- vypracovaný draft diplomovej práce
|
||||
- pripravené dáta z BeautifulSoup - z rôznych webov (sme.sk)
|
||||
- vypracované experimenty pomocou scikit-learn na klasifikátoroch:
|
||||
- multinomial Bayes
|
||||
- random forest
|
||||
- support vector machine
|
||||
- Stochastic Gradient Descent Classifier
|
||||
- k-neighbours
|
||||
- decision tree
|
||||
- vypracované vyhodnotenie pomocou konfúznej matice,
|
||||
|
||||
|
||||
Ciele na ďalšie stretnutie:
|
||||
|
||||
- Vytvoríte si repozitár dp2022 na školskom gite, kde dáte dáta, zdrojové kódy aj texty.
|
||||
- Vybrať jeden odborný článok alebo knihu o klasifikácii textu a vypracujte poznámky.
|
||||
|
||||
@ -3,16 +3,389 @@ title: Maroš Harahus
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [dp2021,bp2019]
|
||||
tag: [spacy,nlp]
|
||||
tag: [spelling,spacy,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
# Maroš Harahus
|
||||
|
||||
- [Git repozitár ai4steel](https://git.kemt.fei.tuke.sk/ai4steel/ai4steel) (pre členov skupiny)
|
||||
- [GIT repozitár s poznámkami](https://git.kemt.fei.tuke.sk/mh496vd/Doktorandske) (súkromný)
|
||||
|
||||
|
||||
## Dizertačná práca
|
||||
|
||||
v roku 2023/24
|
||||
|
||||
Automatické opravy textu a spracovanie prirodzeného jazyka
|
||||
|
||||
Ciele:
|
||||
|
||||
- Zverejniť a obhájiť minimovku
|
||||
- Napísať dizertačnú prácu
|
||||
- Publikovať 2 články triedy Q2-Q3
|
||||
|
||||
Súvisiaca BP [Vladyslav Krupko](/students/2020/vladyslav_krupko)
|
||||
|
||||
|
||||
## Druhý rok doktorandského štúdia
|
||||
|
||||
Ciele:
|
||||
|
||||
- *Publikovanie článku Q2/Q3* - podmienka pre pokračovanie v štúdiu.
|
||||
- *Obhájiť minimovku*. Minimovka by mala obsahovať definíciu riešenej úlohy, prehľad problematiky, tézy dizertačnej práce - vedecké prínosy.
|
||||
- Poskytnite najnovší prehľad.
|
||||
- Popísať vedecký prínos dizertačnej práce
|
||||
- Zverejniť min. 1 príspevok na školskej konferencii.
|
||||
- Publikovať min. 1 riadny konferenčný príspevok.
|
||||
- Pripraviť demo.
|
||||
- Pomáhať s výukou, projektami a výskumom.
|
||||
|
||||
### Návrh na tézy dizertačnej práce
|
||||
|
||||
Automatické opravy textu pri spracovaní prirodzeného jazyka
|
||||
|
||||
Hlavným cieľom dizertačnej práce je návrh, implementácia a overenie modelu pre automatickú opravu textov.
|
||||
|
||||
Na splnenie tohto cieľa je potrebné vykonať tieto úlohy:
|
||||
|
||||
1. Analyzovať súčasný stav modelov pre opravu gramatických chýb a preklepov.
|
||||
2. Vybrať vhodné metódy a navrhnúť vlastný model pre automatickú opravu textov v slovenskom jazyku.
|
||||
3. Navrhnúť a pripraviť metódu augumentácie dát generovaním chýb v texte.
|
||||
4. Zozbierať dáta a pripraviť ich do podoby vhodnej na overenie modelu pre automatickú opravu slovenského textu.
|
||||
5. Navrhnúť a vykonať viacero experimentov pre overenie a porovnanie navrhnutého modelu.
|
||||
|
||||
|
||||
|
||||
Plán činosti na semester:
|
||||
|
||||
1. Prediskutovať a vybrať definitívnu tému. Obidve témy sú komplikované.
|
||||
- Trénovanie jazykových modelov. Cieľom by bolo zlepšenie jazykového modelovania.
|
||||
- [x] Dá sa nadviazať na existujúce trénovacie skripty.
|
||||
- [x] Dá sa využiť webový korpus.
|
||||
- [x] Dá sa využiť naša GPU infraštruktúra. (Na trénovanie menších modelov)
|
||||
- [x] Veľký praktický prínos.
|
||||
- [ ] Teoretický prínos je otázny.
|
||||
- [ ] Naša infraštruktúra je asi slabá na väčšie modely.
|
||||
- Oprava gramatických chýb.
|
||||
- [x] Dá sa nadviazať na "spelling correction" výskum a skripty.
|
||||
- [x] Teoretický prínos je väčší.
|
||||
- [x] Trénovanie by bolo jednoduchšie na našom HW.
|
||||
- Posledné review je z [2020](https://scholar.google.sk/scholar?hl=en&as_sdt=0%2C5&q=grammatical+error+correction+survey&btnG=)
|
||||
|
||||
|
||||
2. Napísať prehľadový článok.
|
||||
- Prečítať existujúce prehľady na danú tému. Zistitť ako boli napísané, kde boli uverejnené, čo je ich prínos. Je dobré použiť metodiku https://www.prisma-statement.org//
|
||||
- Identifikovať v čom by bol náš prehľad originálny a kde by bolo možné uverejniť.
|
||||
- Prečítať a zotriediť aspoň 200 článkov na danú tému.
|
||||
- Zistiť, aké metódy, datasety a spôsoby vyhodnotenia sa používajú.
|
||||
- Rozšíriť prehľadový článok do formy minimovky.
|
||||
|
||||
3. Priebežne pracovať na experimentoch.
|
||||
- Vybrať vhodnú dátovú množinu a metriku vyhodotenia.
|
||||
- Vybrať základnú metódu a vyhodnotiť.
|
||||
- Vyskúšať modifikáciu základnej metódy a vyhodotiť.
|
||||
|
||||
4. Napísať 2 konferenčné články.
|
||||
- Písať si poznámky pri experimentoch.
|
||||
- Predbežné experimenty zverejniť v krátkom článku.
|
||||
- Prediskutovať spôsob financovania.
|
||||
|
||||
Stretnutie 27.10.
|
||||
|
||||
Stav:
|
||||
|
||||
- Prečítaných a spoznámkovaných cca 4O článkov na tému "Grammar Error Correction".
|
||||
- Experimenty strojový preklad s Fairseq. Z toho vznikol článok SAMI.
|
||||
- Poznámky o Transfer Leaarning. Preštudované GPT3.
|
||||
- Sú rozpracované ďalšie modely pre strojový preklad. Česko-slovenský.
|
||||
- https://github.com/KaushalBajaj11/GEC--Grammatical-Error-Correction
|
||||
- https://github.com/LukasStankevicius/Towards-Lithuanian-Grammatical-Error-Correction
|
||||
- https://github.com/yuantiku/fairseq-gec
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Rozbehať fairseq GEC a porozmýšľať ako by a to dalo zlepšiť.
|
||||
- Pozrieť si prehľad https://scholar.google.sk/scholar?hl=en&as_sdt=0%2C5&q=question+generation&btnG=&oq=question+ge a napísať niekoľko poznámok. Vedeli by sme nájsť prínos?
|
||||
|
||||
Nápady:
|
||||
|
||||
- Smerovať to na inú generatívnu úlohu podobnú strojovému prekladu. Napríklad "Question generation".
|
||||
- question generation by sa dalo použiť na zlepšenie QA-IR systémov.
|
||||
- Možno "multilingual question generation"?
|
||||
|
||||
Stretnutie 9.9.2022
|
||||
|
||||
Stav:
|
||||
|
||||
Počas prázdnin sa pracovalo na experimentoch s fairseq - strojový preklad a Spacy trénovanie, štúdium literatúry.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Prečítať niekoľko prehľadov na tému Grammar Correction, zistiť ako sú napísané a čo je v nich napísané.
|
||||
- [x] Prečítať niekoľko prehľadov (survey) na tému Neural Language Modelling - BERT Type models. Zistiť, kde je priestor na vedecký prínos.
|
||||
- [x] Zistiť čo je to Transfer Learning. https://ieeexplore.ieee.org/abstract/document/9134370
|
||||
- Na obe témy vyhľadať a prečítať niekoľko článkov. Uložiť záznam do databázy, napísať poznánky ku článku.
|
||||
- [ ] Porozmýšľať nad témou práce.
|
||||
- [x] Pokračovať v experimenotch fairseq so strojovým prekladom. Vieme pripraviť experiment na tému "spelling", "grammar" alebo training "roberta small", "bart small" na web korpuse? Toto by sa mohlo publikovať na konferenčnom článku do konca roka. treba vybrať dátovú množinu, metodiku vyhodnoteia, metódu trénovania.
|
||||
- [-] Čítať knihy - Bishop-Patter Recognition. Yang: Transfer Learning.
|
||||
|
||||
|
||||
|
||||
## Prvý ročník PhD štúdia
|
||||
|
||||
29.6.
|
||||
|
||||
- Vyskúšané https://github.com/NicGian/text_VAE, podľa článku https://arxiv.org/pdf/1511.06349.pdf
|
||||
Tento prístup je pôvodne na Question Generation. Využíva GLOVE embeding a VAE. Možno by sa to dalo využiť ako chybový model.
|
||||
- So skriptami fairseq sú zatiaľ problémy.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračovať v otvorených úlohách.
|
||||
- Vyskúšať tutoriál https://fairseq.readthedocs.io/en/latest/getting_started.html#training-a-new-model.
|
||||
- Prečítať knihu "Bishop: Pattern Recognition".
|
||||
|
||||
|
||||
17.6.
|
||||
|
||||
- Končí financovanie USsteel , je potrebné zmeniť tému.
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Do konca ďalšieho školského roka submitovať karent článok. To je podmienka pre ďalšie pokračovanie. Článok by mal nadviazať na predošlý výskum v oblasti "spelling correction".
|
||||
- Preštudovať články:
|
||||
* Survey of automatic spelling correction
|
||||
* Learning string distance with smoothing for OCR spelling correction
|
||||
* Sequence to Sequence Convolutional Neural Network for Automatic Spelling Correction
|
||||
* Iné súvisiace články. Kľúčové slová: "automatic spelling correction."
|
||||
- Naučiť sa pracovať s fairseq. Naučiť sa ako funguje strojový preklad.
|
||||
- Zopakovať experiment OCR Trec-5 Confusion Track. Pridaný prístup do repozitára https://git.kemt.fei.tuke.sk/dano/correct
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vymyslieť systém pre opravu gramatických chýb. Aka Grammarly.
|
||||
- Využiť GAN-VAE sieť na generovanie chybového textu. To by mohlo pomôcť pri učení NS.
|
||||
|
||||
|
||||
|
||||
3.6.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pripraviť experiment pri ktorom sa vyhodnotia rôzne spôsoby zhlukovania pre rôzne veľkosti priestoru (PCA, k-means, DBSCAN, KernelPCA - to mi padalo). Základ je v súbore embed.py
|
||||
- Do tabuľky spísať najdôležitejšie a najmenej dôležité parametre pre rôzne konvertory a pre všetky konvertory naraz (furnace-linear.py).
|
||||
- Vypočítanie presnosti pre každý konvertor zo spojeného modelu, pokračovať.
|
||||
|
||||
27.5.
|
||||
|
||||
- Našli sme medzné hodnoty pre dáta zo skriptov USS.
|
||||
- Urobený skript, polynómová transformácia príznakov nepomáha.
|
||||
- rozrobený skript na generovanie dát GAN.
|
||||
|
||||
Otvorené úlohy:
|
||||
|
||||
- Pokračovať v otvorených úlohách.
|
||||
- (3) Urobiť zhlukovanie a pridať informáciu do dátovej množiny. Zistiť, či informácia o zhlukoch zlepšuje presnosť. Informácia o grade umožňuje predikciu.
|
||||
|
||||
Stretnutie 20.5.
|
||||
|
||||
Otvorené úlohy:
|
||||
|
||||
- [ ] (1) Vypočítanie presnosti pre každý konvertor zo spojeného modelu a porovnanie s osobitnými modelmi. Chceme potvrdiť či je spojený model lepší vo všetkých prípadoch.
|
||||
- [ ] (2) Doplniť fyzické limity pre jednotlivé kolónky do anotácie. Ktoré kolónky nemôžu byť negatívne? Tieto fyzické limity by mali byť zapracované do testu robustnosti.
|
||||
- [ ] (4) Overenie robustnosti modelu. Vymyslieť testy invariantnosti, ktoré overia ako sa model správa v extrémnej situácii. Urobiť funkciu, kotrá otestuje parametre lineárnej regresie a povie či je model validný. Urobiť funkciu, ktorá navrhne nejaké vstupy a otestuje, či je výstup validný.
|
||||
|
||||
Neprioritné úlohy:
|
||||
|
||||
- [o] Preskúmať možnosti zníženia rozmeru vstupného priestoru. PCA? alebo zhlukovanie? Zistiť, či vôbec má zmysel používať autoenóder (aj VAE). (Asi to nemá zmysel)
|
||||
- [x] Vyradenie niektorých kolóniek, podľa koeficientu lineárnej regresie (daniel, funguje ale nezlepšuje presnosť).
|
||||
- Generovať umelé "extrémne" dáta. Sledovať, ako sa model správa. Extrémne dáta by mali byť fyzicky možné.
|
||||
|
||||
|
||||
Urobené úlohy:
|
||||
|
||||
- Hľadanie hyperparametrov pre neurónku a náhodný les.
|
||||
|
||||
Report 29.4.2022
|
||||
|
||||
- Práca na VE.
|
||||
- Čítanie článkov.
|
||||
|
||||
Report 8.4.2022
|
||||
|
||||
- Študovanie teórie
|
||||
- Práca na VAE kóde rozpracovaný
|
||||
|
||||
Report 1.4.2022
|
||||
|
||||
- práca na DH neurónovej sieťi
|
||||

|
||||
- študovanie o Deep Belief Network
|
||||
|
||||
Stretnutie 28.3.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Dokončiť podrobnú anotáciu dát. Aké sú kazuálne súvisosti medzi atribútmi?
|
||||
- Zopakovať a vylepšiť DH neurónovú sieť na predikciu síry
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Zvážiť použitie Deep Belief Network.
|
||||
|
||||
Report 25.3.2022
|
||||
|
||||
- Porovnávanie dát január, február (subor je na gite)
|
||||
- Hodnotenie ešte nemám spisujem čo tým chcem dosiahnuť ci to ma vôbec zmysel na tom pracovať
|
||||
|
||||
Report 18.3.2022
|
||||
|
||||
- práca na dátach (príprava na TS, zisťovanie súvislosti, hľadanie hraničných hodnôt)
|
||||
- študovanie timesesries (https://heartbeat.comet.ml/building-deep-learning-model-to-predict-stock-prices-part-1-2-58e62ad754dd,)
|
||||
- študovanie o reinforcement learning (https://github.com/dennybritz/reinforcement-learning
|
||||
https://github.com/ShangtongZhang/reinforcement-learning-an-introduction)
|
||||
- študovanie o transfer learning
|
||||
- študovanie feature selection (https://machinelearningmastery.com/feature-selection-machine-learning-python/
|
||||
https://www.kdnuggets.com/2021/12/alternative-feature-selection-methods-machine-learning.html)
|
||||
|
||||
Report 11.3.2022
|
||||
|
||||
- Data Preprocessing (inspirácia- https://www.kaggle.com/tajuddinkh/drugs-prediction-data-preprocessing-json-to-csv)
|
||||
- Analyzovanie dát (inspirácia- https://www.kaggle.com/rounakbanik/ted-data-analysis, https://www.kaggle.com/lostinworlds/analysing-pokemon-dataset
|
||||
https://www.kaggle.com/kanncaa1/data-sciencetutorial-for-beginners)
|
||||
- Pracovanie na scripte jsnol --> csv
|
||||
|
||||
- Študovanie time series (https://www.machinelearningplus.com/time-series/time-series-analysis-python/
|
||||
Python Live - 1| Time Series Analysis in Python | Data Science with Python Training | Edureka
|
||||
Complete Python Pandas Data Science Tutorial! (Reading CSV/Excel files, Sorting, Filtering, Groupby)
|
||||
https://www.kaggle.com/kashnitsky/topic-9-part-1-time-series-analysis-in-python)
|
||||
- Time series články (https://ieeexplore.ieee.org/abstract/document/8853246
|
||||
https://ieeexplore.ieee.org/abstract/document/8931714
|
||||
https://ieeexplore.ieee.org/abstract/document/8942842
|
||||
https://arxiv.org/abs/2103.01904)
|
||||
|
||||
Working on:
|
||||
- Neurónovej siete pre GAN time series (stále mam nejaké errory)
|
||||
- klasickej neuronke
|
||||
|
||||
Stretnutie 1.3.2022
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zapracovať wandB pre reporting experimentov
|
||||
- Textovo opísať dáta
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vyskúšať predtrénovanie pomocou "historických dát".
|
||||
|
||||
Report 25.02.2022
|
||||
|
||||
- Prehlaď o jazykových modeloch (BERT, RoBERTa, BART, XLNet, GPT-3) (spracovane poznámky na gite)
|
||||
- Prehlaď o time-series GAN
|
||||
- Úprava skriptu z peci jsnol -- > csv
|
||||
- Skúšanie programu GAN na generovanie obrázkov (na pochopenie ako to funguje)
|
||||
- Hľadanie vhodnej implementácie na generovanie dát
|
||||
- Rozpracovaná (veľmi malo) analýza datasetu peci
|
||||
|
||||
Stretnutie 2.2.2022
|
||||
|
||||
In progress:
|
||||
|
||||
- Práca na prehľade článkov VAE-GAN
|
||||
- na (súkromný) git pridaný náhľad dát a tavný list
|
||||
- práca na Pandas skripte
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Dokončiť spacy článok
|
||||
- Dokončiť prehľad článkov
|
||||
- Pripraviť prezentáciu na spoločné stretnutie. Do prezentácie uveď čo si sa dozvedel o metódach VAE a GAN. Vysvetli, ako funguje "autoenkóder".
|
||||
- Napísať krátky blog vrátane odkazov nal literatúru o tom ako funguje neurónový jazykový model (BERT, Roberta, BART, GPT-3, XLNet). Ako funguje? Na čo všetko sa používa?
|
||||
|
||||
|
||||
Stretnutie 18.1.2022
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [ ] Do git repozitára pridať súbor s podrobným popisom jednotlivých kolóniek v dátovej množine.
|
||||
- [-] Do git repozitára pridať skript na načítanie dát do Pandas formátu.
|
||||
- [ ] Vypracovať písomný prehľad metód modelovania procesov v oceliarni (kyslíkového konvertora BOS-basic oxygen steelmaking).
|
||||
- [x] Nájsť oznam najnovších článkov k vyhľadávaciuemu heslu "gan time series", "vae time series", "sequence modeling,prediction" napísať ku nim komentár (abstrakt z abstraktu) a dať na git.
|
||||
- [x] Preformulovať zadanie BP Stromp.
|
||||
- [-] Dokončiť draft článok spacy.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- [-] Získať prehľad o najnovších metódach NLP - transformers,GAN, VAE a nájsť súvis s modelovaním BOS.
|
||||
- [ ] nájsť vhodnú implementáciu gan-vae v pythone pre analýzu časových radov alebo postupnosti.
|
||||
|
||||
Stretnutie 17.1.2022
|
||||
|
||||
- Mame dáta z vysokej pece (500GB)
|
||||
- Zlepšený konvolučný autoenkóder - dosahuje state-of-the-art.
|
||||
- Prečítané niečo o transformers a word2vec.
|
||||
|
||||
Stretnutie 9.12.2021
|
||||
|
||||
- Natrénovaný autoenkóder (feed-forward) pre predikciu celkovej váhy Fe a obsahu S.
|
||||
- dát je celkom dosť.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vyskúšať iné neurónové siete (keras?).
|
||||
- Pohľadať dátové množiny, ktoré sú podobné riešenej úlohe. Napr. Open Data.
|
||||
|
||||
Stretnutie 26.11.2021
|
||||
|
||||
Dáta z US Steel:
|
||||
|
||||
- Najprv sa do vysokej pece nasypú suroviny.
|
||||
- Z tavby sa postupne odoberajú vzorky a meria sa množstvo jednotlivých vzoriek.
|
||||
- Na konci tavby sa robí finálna analýza taveniny.
|
||||
- Priebeh procesu závisí od vlastností konkrétnej pece. Sú vlastnosti pece stacionárne? Je možné , že vlastnosti pece sa v čase menia.
|
||||
- Cieľom je predpovedať výsledky anaýzy finálnej tavby na základe predošlých vzoriek?
|
||||
- Cieľom je predpovedať výsledky nasledujúceho odberu na základe predchádzajúcich?
|
||||
- Čo znamená "dobrá tavba"?
|
||||
- Čo znamená "dobrá predpoveď výsledkov"?
|
||||
- Je dôležitý čas odbery vzorky?
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Formulovať problém ako "predikcia časových radov" - sequence prediction.
|
||||
- Nápad: The analysis of time series : an introduction / Chris Chatfield. 5th ed. Boca Raton : Chapman and Hall, 1996. xii, 283 s. (Chapman & Hall texts in statistical science series). - ISBN 0-412-71640-2 (brož.).
|
||||
- Prezrieť literatúru a zistiť najnovšie metódy na predikciu.
|
||||
- Navrhnúť metódu konverzie dát na vektor príznakov. Sú potrebné binárne vektory?
|
||||
- Navrhnúť metódu výpočtu chybovej funkcie - asi euklidovská vzdialenosť medzi výsledkov a očakávaním.
|
||||
- Vyskúšať navrhnúť rekurentnú neurónovú sieť - RNN, GRU, LSTM.
|
||||
- Nápad: Transformer network, Generative Adversarial Network.
|
||||
- Nápad: Vyskúšať klasické štatistické modely (scikit-learn) - napr. aproximácia polynómom, alebo SVM.
|
||||
|
||||
Stretnutie 1.10.
|
||||
|
||||
Stav:
|
||||
|
||||
- Štúdium základov neurónových sietí
|
||||
- Úvodné stretnutie s US Steel
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vypracovať prehľad aktuálnych metód grafových neurónových sietí
|
||||
- Nájsť a vyskúšať toolkit na GNN.
|
||||
- Vytvoriť pracovný repozitár na GITe.
|
||||
- Naštudovať dáta z US Steel.
|
||||
- Publikovať diplomovú prácu.
|
||||
|
||||
|
||||
## Diplomová práca 2021
|
||||
|
||||
- [CRZP](https://opac.crzp.sk/?fn=detailBiblioForm&sid=ECC3D3F0B3159C4F3216E2027BE4)
|
||||
- [Zdrojové kódy](https://git.kemt.fei.tuke.sk/mh496vd/diplomovka/)
|
||||
|
||||
Názov diplomovej práce: Neurónová morfologická anotácia slovenského jazyka
|
||||
|
||||
|
||||
## Návrh na zadanie DP
|
||||
|
||||
1. Vysvetlite, ako funguje neurónová morfologická anotácia v knižnici Spacy. Vysvetlite, ako funguje predtrénovanie v knižnici Spacy.
|
||||
2. Pripravte slovenské trénovacie dáta vo vhodnom formáte a natrénujte základný model morfologickej anotácie pomocou knižnice Spacy.
|
||||
3. Pripravte model pre morfologickú anotáciu s pomocou predtrénovania.
|
||||
@ -209,8 +582,6 @@ Stretnutie: 20.2.2020:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## Tímový projekt 2019
|
||||
|
||||
Projektové stránky:
|
||||
|
||||
BIN
pages/students/2016/maros_harahus/uss.PNG
Normal file
{kind=link}
|
After Width: | Height: | Size: 35 KiB |
@ -8,14 +8,17 @@ taxonomy:
|
||||
---
|
||||
# Patrik Pavlišin
|
||||
|
||||
Predbežný názov diplomovej práce:
|
||||
# Diplomová práca 2022
|
||||
|
||||
Neurónový strojový preklad
|
||||
|
||||
Predbežný názov: Neurónový strojový preklad
|
||||
|
||||
Návrh na nástroje pre strojový preklad:
|
||||
|
||||
- OpenNMT-py
|
||||
- Fairseq
|
||||
- Hugging Face Transformers
|
||||
|
||||
|
||||
## Návrh na zadanie diplomovej práce
|
||||
|
||||
@ -24,6 +27,120 @@ Návrh na nástroje pre strojový preklad:
|
||||
3. Pripraviť vybraný paralelný korpus do vhodnej podoby a pomocou vybranej metódy natrénovať model pre strojový preklad.
|
||||
4. Vyhodnotiť experimenty a navrhnúť možnosti na zlepšenie.
|
||||
|
||||
## Diplomový projekt 2
|
||||
|
||||
Ciele na semester:
|
||||
|
||||
1. Natrénovať "kvalitný model" na preklad z angličtiny do slovenčiny.
|
||||
2. Napísať draft diplomovej práce.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- natrénovať aj iné preklady (z a do češtiny).
|
||||
|
||||
18.2.2022
|
||||
|
||||
- Beží trénovanie na idoc
|
||||
|
||||
Úlohy:
|
||||
|
||||
Zmeňte štruktúru práce podľa tohoto myšienkového postupu.
|
||||
Pridajte nové časti a vyradte nerelevantné časti.
|
||||
|
||||
1. Vysvetlite čo je to neurónový strojovyý preklad.
|
||||
2. Vysvetlite, čo je to neurónová sieť.
|
||||
3. Povedze aké typy neurónových sietí sa používajú na strojový preklad.
|
||||
4. Vyberte konkrétnu neurónovú sieť (tú ktorá sa používa v OPennmt) a podrobne opíšte ako funguje.
|
||||
5. Predstavte Open NMT.
|
||||
6. Povedzte o dátach ktoré ste použili (dorobiť).
|
||||
7. Vysvetlite, ako ste pripravili experimenty, ako ste ich spustili a aké výlsekdy ste dosiahli (dorobiť).
|
||||
8. Sumarizujte experimenty a určite miesto na zlepšenie (dorobiť).
|
||||
|
||||
27.1.2022
|
||||
|
||||
- Hotovy model na CZ-EN
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Aktualizujte trénovacie skripty na gite.
|
||||
- Rozbehajte GPU trénovnaie na idoc. Vyriešte technické problémy.
|
||||
- Natrénujte viacero modelov s viacerými nastaveniami a výsledkyž dajte do tabuľky. Ku každému modelu si poznačte výsledné BLEU. Výsledky skontrolujte aj osobne.
|
||||
- Pokračujte na texte práce. Odstrániť nezmyselné časti. Pri ďalšom stretnutí prezentujte stav textovej časti.
|
||||
|
||||
|
||||
17.12.2021
|
||||
|
||||
- Vylepšený draft práce.
|
||||
- Nové vyhodnotenie a výsledky modelu.
|
||||
- Trénovanie na česko-anglickom korpuse.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- natrénujte na tomto EN-SK korpuse: https://lindat.mff.cuni.cz/repository/xmlui/handle/11858/00-097C-0000-0006-AAE0-A
|
||||
- Pokračujte v otvorených úlohách z minulého stretnutia.
|
||||
- Výsledky experiemntov zhrňte do tabuľky. Poznačte architektúru neurónovej siete, parametre trénovania.
|
||||
- Skúste rozbehať trénovanie na GPU.
|
||||
|
||||
1. Vytvorte nové conda prostredie. Spustite:
|
||||
|
||||
conda install pytorch=1.8.1cudatoolkit=10.1 -c pytorch
|
||||
|
||||
2. Nainštalujte OpenNMT.
|
||||
|
||||
|
||||
26.11.2021
|
||||
|
||||
Natrénovaný prvý model OpenNMT na korpuse europarlament.
|
||||
Výslekdy vyzerajú OK, ale sú chaotické. Pravdepodobne bolo trénovanie prerušené predčasne. Zatiaľ nefunguje trénovanie na GPU.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v trénovaní Europarl. Modelu, skúste vylepšiť výsledky.
|
||||
- Trénovanie robte opakovateľným spôsobom - dajte na git nastavenia a trénovacie skripty, ale nie textové dáta. Len poznačte odkiaľ ste ich stiahli.
|
||||
- Pokračujte v práci na texte - myšlienky by mali logicky nasledovať za sebou.
|
||||
|
||||
|
||||
12.11.2021
|
||||
|
||||
Práca na texte
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zlepšiť štruktúru práce
|
||||
- Dotrénovať a vyhodnotiť model slovenčina-angličtina.
|
||||
|
||||
28.10.
|
||||
|
||||
Stav:
|
||||
|
||||
- Vypracovaný draft článoku o transformeroch, treba vylepšiť. Článok je na ZP Wiki
|
||||
- Problém pri príprave trénovacích dát.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Naučte sa pripravovať textové dáta. Prejdite si knihu https://diveintopython3.net aspoň do 4 kapitoly. Vypracujte všetky príklady z nej.
|
||||
- Pokračujte v práci na článku. Treba doplniť odkazy do textu. Treba zlepšiť štruktúru a logickú náväznosť viet. Vysvetlite neznáme pojmy.
|
||||
- Zmente článok na draft diplomovej práce. Vypracujte osnovu diplomovej práce - napíšte názvy kapitol a ich obsah. Zaraďte tam text o transformeroch ktorý ste vypracovali.
|
||||
- Pripravte textové dáta do vhodnej podoby a spustite trénovanie.
|
||||
|
||||
|
||||
Stretnutie 30.9.
|
||||
|
||||
Stav:
|
||||
|
||||
- Len začaté štúdium článkov, ostatné úlohy zostávajú otvorené.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračovať v úlohách zo 17.6.
|
||||
- Na trénovanie použite OpenNMT.
|
||||
- Vytvorte si repozitár dp2022 a do neho dajte skripty na natrénovanie modelov. Nedávajte tam veľké dáta, ale dajte tam skript na ich stiahnutie, napr. pomocou wget.
|
||||
- prepare-env.sh : ako ste vyttvorili Vaše prostredie - nainštalovali programy.
|
||||
- download-data.sh: ako ste získali dáta
|
||||
- prepare-data.sh: ako ste pripravili dáta
|
||||
- train1.sh: ako ste natrénovali model
|
||||
- evaluate1.sh: ako ste vyhodnotili model.
|
||||
|
||||
## Diplomový projekt 1
|
||||
|
||||
Stretnutie 17.6.
|
||||
@ -36,7 +153,7 @@ Stretnutie 17.6.
|
||||
- Skúste zlepšiť presnosť strojového prekladu. Modifikujte setup tak, aby sa výsledky zlepšili.
|
||||
- Preštudujte si architektúru neurónovej siete typu Transformer. Prečítajte si blogy a urobte poznámky,
|
||||
Prečítajte si článok s názvom "Attention is all you need.". Urobte si poznámky čo ste sa dozvedeli.
|
||||
- Preštudujte si architektúru typu enkóder-dekóider. Urobte si poznámky čo ste sa dozvedeli a z akých zdrojov.
|
||||
- Preštudujte si architektúru typu enkóder-dekóder. Urobte si poznámky čo ste sa dozvedeli a z akých zdrojov.
|
||||
Využívajte vyhľadávač Scholar.
|
||||
|
||||
Stretnutie 9.4.
|
||||
|
||||
@ -0,0 +1 @@
|
||||
data downloaded from " https://lindat.mff.cuni.cz/repository/xmlui/discover "
|
||||
1
pages/students/2016/patrik_pavlisin/dp2022/evaluate1.sh
Normal file
@ -0,0 +1 @@
|
||||
nohup perl tools/multi-bleu.perl dp2022/sk-en/europarl-v7.clean.sk-en.sk < dp2022/sk-en/pred_10000.txt2 > prekladsk&
|
||||
11
pages/students/2016/patrik_pavlisin/dp2022/prepare-data.sh
Normal file
@ -0,0 +1,11 @@
|
||||
import sys
|
||||
|
||||
for l in sys.stdin:
|
||||
line = l.rstrip()
|
||||
tokens = line.split()
|
||||
result = []
|
||||
for token in tokens:
|
||||
items = token.split("|")
|
||||
print(items)
|
||||
result.append(items[0])
|
||||
print(" ".join(result))
|
||||
@ -0,0 +1,6 @@
|
||||
onmt_build_vocab -config dp2022/sk-en/trainsk.yaml -n_sample 10000
|
||||
|
||||
onmt_train -config dp2022/sk-en/trainsk.yaml
|
||||
|
||||
onmt_translate -model dp2022/sk-en/run/model_step_1000.pt -src dp2022/sk-en/src-test.txt -output dp2022/sk-en/pred_1000.txt -verbose
|
||||
|
||||
33
pages/students/2016/patrik_pavlisin/dp2022/train1.yaml
Normal file
@ -0,0 +1,33 @@
|
||||
# train.yaml
|
||||
|
||||
## Where the samples will be written
|
||||
save_data: dp2022/run2/example
|
||||
## Where the vocab(s) will be written
|
||||
src_vocab: dp2022/run2/example.vocab.src
|
||||
tgt_vocab: dp2022/run2/example.vocab.tgt
|
||||
# Prevent overwriting existing files in the folder
|
||||
overwrite: False
|
||||
|
||||
|
||||
# Corpus opts
|
||||
data:
|
||||
corpus_1:
|
||||
path_src: dp2022/europarl-v7.sk-en.en
|
||||
path_tgt: dp2022/europarl-v7.sk-en.sk
|
||||
valid:
|
||||
path_src: dp2022/europarl-v7.clean.sk-en.en
|
||||
path_tgt: dp2022/europarl-v7.clean.sk-en.sk
|
||||
|
||||
# Vocabulary files that were just created
|
||||
src_vocab: dp2022/run2/example.vocab.src
|
||||
tgt_vocab: dp2022/run2/example.vocab.tgt
|
||||
|
||||
# Train on a single GPU
|
||||
world_size: 1
|
||||
gpu_ranks: [0]
|
||||
|
||||
# Where to save the checkpoints
|
||||
save_model: dp2022/run2/model
|
||||
save_checkpoint_steps: 1000
|
||||
train_steps: 20000
|
||||
valid_steps: 10000
|
||||
BIN
pages/students/2016/patrik_pavlisin/dp21/.README.md.swp
Normal file
@ -171,4 +171,3 @@ Výsledkom je model, ktorý môžeme použiť na predpovedanie nových údajov.
|
||||
|
||||
[3]. ŠÍMA J., NERUDA R.: Teoretické otázky neurónových sítí [online]. [1996].
|
||||
|
||||
[4]. ZHANG A., LIPTON C. Z., LI M., SMOLA J. A.: Dive into Deep Learning. [online]. [citované 06-11-2020].
|
||||
{kind=link}
|
After Width: | Height: | Size: 98 KiB |
{kind=link}
|
After Width: | Height: | Size: 32 KiB |
BIN
pages/students/2016/patrik_pavlisin/dp22/R-Transformer.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 42 KiB |
127
pages/students/2016/patrik_pavlisin/dp22/README.md
Normal file
@ -0,0 +1,127 @@
|
||||
## Attention, The Transformer
|
||||
|
||||
**Úvod**
|
||||
|
||||
Transformer je modelová architektúra, ktorá sa vyhýba opakovaniu a namiesto toho sa úplne spolieha na mechanizmus pozornosti na kreslenie globálnych závislostí medzi vstupom a výstupom. Je to prvý transdukčný model, ktorý sa spolieha úplne na vlastnú pozornosť pri výpočte reprezentácii vstupu a výstupu bez použitia RNN (Recurrent Neural Network) alebo CNN (Convolution Neural Network). Používa sa predovšetkým v oblasti NLP (Natural Language Processing) a CV (Computer Vision). Mechanizmy pozornosti sa stali súčasťou presvedčivého modelovania sekvencií a prenosových modelov v rôznych úlohách, ktoré umožňujú modelovanie závislostí bez ohľadu na ich vzdialenosť vo vstupných alebo výstupných sekvenciách. Takmer vo všetkých prípadoch sa však takéto mechanizmy pozornosti používajú v spojení s rekurentnou sieťou. Systémy počítačového videnia (CV) založené na CNN môžu tiež ťažiť z mechanizmov pozornosti. Hlavnou vlastnosťou tzv. “mechanizmus pozornosti” je že vie na základe vstupnej postupnosti v každom kroku rozhodnúť, ktoré časti postupnosti sú dôležité. Je to technika, ktorá napodobňuje kognitívnu pozornosť.
|
||||
|
||||
Najmä Multi-head attention mechanizmus v Transformeri umožňuje, aby bola každá pozícia priamo spojená s akýmikoľvek inými pozíciami v sekvencii. Informácie tak môžu prúdiť cez pozície bez akejkoľvek medzistraty. Napriek tomu existujú dva problémy, ktoré môžu poškodiť účinnosť Multi-head attention pri sekvenčnom učení. Prvý pochádza zo straty sekvenčných informácií o pozíciách, pretože s každou pozíciou zaobchádza rovnako. Na zmiernenie tohto problému Transformer zavádza vkladanie pozícií, ktorých účinky sa však ukázali ako obmedzené. [4]
|
||||
|
||||
Na vyriešenie vyššie uvedených obmedzení štandardného Transformera bol navrhnutý nový model sekvenčného učenia R-Transformer. Ide o viacvrstvovú architektúru postavenú na RNN a štandardnom Transformeri, pričom využíva výhody oboch svetov, ale zároveň sa vyhýba ich príslušným nevýhodám. Konkrétnejšie, pred výpočtom globálnych závislostí pozícii pomocou Multi-head attention najskôr spresníme znázornenie každej polohy tak, aby sa sekvenčné a lokálne informácie v jej susedstve mohli v reprezentácii skomprimovať. Aby sa to dosiahlo bola zavedená lokálna rekurentná neurónová sieť, označená ako LocalRNN, na spracovanie signálov v rámci lokálneho okna končiaceho na danej pozícii. LocalRNN navyše pracuje na miestnych oknách všetkých pozícií identicky a nezávisle a pre každú z nich vytvára skrytú reprezentáciu. Okrem toho, keďže sa lokálne okno posúva pozdĺž sekvencie jednu pozíciu za druhou, sú zahrnuté aj globálne sekvenčné informácie. Dôležité najme je, že nakoľko LocalRNN sa používa iba na lokálne okná, vyššie uvedené nevýhody RNN je možné zmierniť. [1][6]
|
||||
|
||||
Rekurentné neurónové siete, najmä long short-term pamäť (LSMT, špeciálny druh RNN, vytvorený na riešenie problémov s miznúcim gradientom) a uzavreté rekurentné neurónové siete, boli pevne zavedené ako najmodernejšie prístupy k problémom sekvenčného modelovania a prenosov, ako je jazykové modelovanie a strojový preklad. LSTM je architektúra umelej rekurentnej neurónovej siete (RNN), ktorá sa používa v oblasti deep-learning učenia. Na rozdiel od štandardných dopredných neurónových sietí (ang. Feedforward neural network) má LSTM spätnú väzbu. Dokáže spracovať nielen jednotlivé dátové body (napríklad obrázky), ale aj celé sekvencie dát (napríklad reč alebo video). Početné snahy odvtedy pokračujú v posúvaní hraníc rekurentných jazykových modelov a architektúr encoder-decoder. Sieťové pamäte typu end-to-end sú založené na RNN (Recurrent Neural Network) mechanizme namiesto opakovania zarovnaného podľa sekvencie a ukázalo sa, že fungujú dobre pri úlohách zodpovedajúcich otázky v jednoduchom jazyku a pri modelovaní jazykov. End-to-end učenie je typ Deep Learningu, v ktorom sú všetky parametre trénované spoločne, a nie krok za krokom. [7] [8]
|
||||
|
||||
RNN boli dlhodobo dominantnou voľbou pre sekvenčné modelovanie, závažne však trpia najme dvoma problémami. Po prvé, ľahko trpí problémami s miznutím a explodovaním gradientu, čo do značnej miery obmedzuje schopnosť naučiť sa veľmi dlhodobé závislosti. Po druhé, sekvenčná povaha prechodov dopredu aj dozadu veľmi sťažuje, ak nie priam znemožňuje, paralelizáciu výpočtu, čo dramaticky zvyšuje časovú zložitosť v tréningovom aj testovacom postupe. Preto mnohé nedávno vyvinuté modely sekvenčného učenia úplne vypustili rekurentnú štruktúru a spoliehajú sa iba na konvolučnú (Convolution Neural Network) alebo mechanizmus pozornosti, ktoré sa dajú ľahko paralelizovať a umožňujú tok informácií v ľubovoľnej dĺžke. Dva reprezentatívne modely, ktoré pritiahli veľkú pozornosť, sú Temporal Convolution Networks (TCN) a Transformer. V rôznych úlohách sekvenčného učenia preukázali porovnateľný alebo dokonca lepší výkon ako výkonnosť RNN. [8]
|
||||
|
||||
**Modelová architektúra**
|
||||
|
||||
Väčšina konkurenčných prenosových modelov neurónovej sekvencie má štruktúru encoder-decoder. V tomto prípade encoder mapuje vstupnú sekvenciu symbolových reprezentácií (x1, ..., xn) na sekvenciu spojitých reprezentácií z = (z1, ..., zn). Vzhľadom na z, decoder potom generuje výstupnú sekvenciu (y1, ..., ym) symbolov jeden po druhom. V každom kroku je model automaticky regresívny a pri generovaní ďalšieho spotrebuje predtým vygenerované symboly ako ďalší vstup. [1]
|
||||
|
||||
|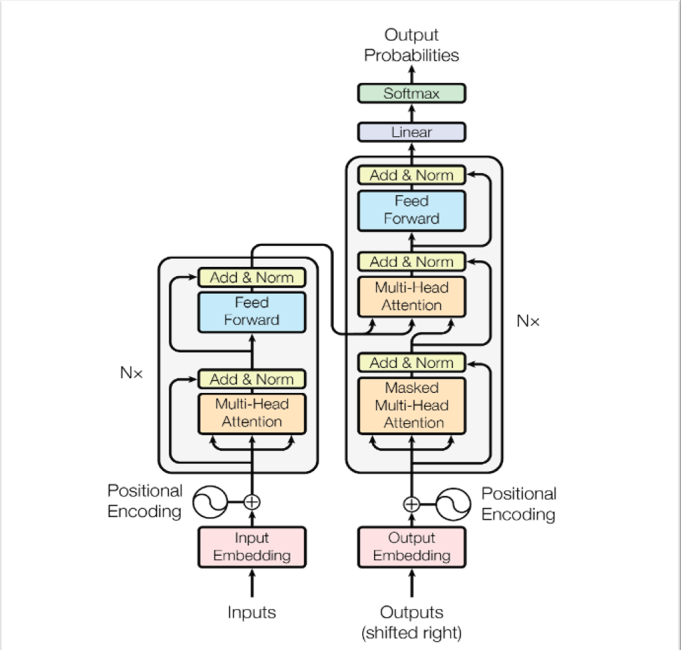|
|
||||
|:--:|
|
||||
|Obr 1. Modelová architektúra Transformer|
|
||||
|
||||
## Encoder-Decoder architektúra
|
||||
|
||||
Rovnako ako predchádzajúce modely, Transformer používa architektúru encoder-decoder. Encoder-Decoder architektúra je spôsob použitia rekurentných neurónových sietí na problémy s predikciou sekvencie k sekvencii. Pôvodne bol vyvinutý pre problémy so strojovým prekladom, aj keď sa osvedčil pri súvisiacich problémoch s predikciou sekvencie k sekvencii, ako je zhrnutie textu a zodpovedanie otázok. Skladá sa z 3 častí (encoder, intermediate vector a decoder).
|
||||
|
||||
Encoder – prijme jeden prvok vstupnej sekvencie v každom časovom kroku, spracuje ho, zhromaždí informácie o danom prvku a šíri ho ďalej.
|
||||
|
||||
Intermediate vector – konečný vnútorný stav vytvorený z časti encoder modelu. Obsahuje informácie o celej vstupnej sekvencii, ktoré pomôžu decoderu robiť presné predpovede.
|
||||
|
||||
Decoder – predpovedá výstup v každom časovom kroku.
|
||||
|
||||
Encoder pozostáva z kódovacích vrstiev, ktoré spracovávajú vstup iteračne jednu vrstvu za druhou, zatiaľ čo decoder pozostáva z dekódovacích vrstiev, ktoré robia to isté s výstupom encodera. Funkciou každej vrstvy encodera je generovať kódovanie, ktoré obsahuje informácie o tom, ktoré časti vstupov sú navzájom relevantné. Odošle svoje kódovanie do ďalšej vrstvy encodera ako vstupy. Každá decoderová vrstva robí opak, pričom použije všetky kódovania a na začlenenie výstupnej sekvencie použije svoje začlenené kontextové informácie. Aby sa to dosiahlo, každá vrstva encodera a decodera využíva mechanizmus pozornosti.
|
||||
|
||||
Pri každom vstupe pozornosť zvažuje relevanciu každého ďalšieho vstupu a čerpá z neho pri vytváraní výstupu. Každá decoderová vrstva má mechanizmus dodatočnej pozornosti, ktorý čerpá informácie z výstupov predchádzajúcich decoderov, než vrstva decodera čerpá informácie z kódovaní.
|
||||
|
||||
Obe vrstvy encodera a decodera majú feed-forward neurónovú sieť (umelá neurónová sieť, v ktorej spojenia medzi uzlami netvoria cyklus) na dodatočné spracovanie výstupov a obsahujú zvyškové spojenia a kroky na normalizácie vrstiev. [3]
|
||||
|
||||
|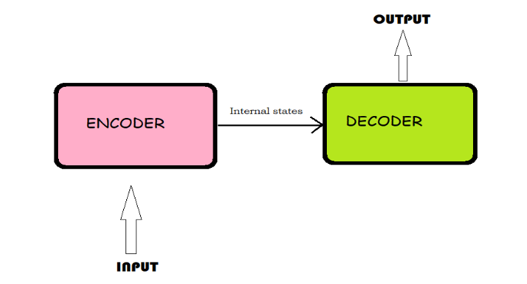|
|
||||
|:--:|
|
||||
|Obr 2. Štruktúra modelu sequence to sequence (encoder-decoder)|
|
||||
|
||||
**Transformer Encoder**
|
||||
|
||||
Encoder sa skladá zo zásobníka _N = 6_ rovnakých vrstiev. Každá vrstva má dve podvrstvy. Prvým je multi-head self-attention mechanizmus a druhým je jednoduchá polohovo plne prepojená sieť spätnej väzby. Multi-head Attention je modul pre mechanizmy pozornosti, ktorý prechádza mechanizmom pozornosti niekoľkokrát paralelne. Self-attention, tiež známy ako Intra-attention, je mechanizmus pozornosti, ktorý spája rôzne polohy jednej sekvencie s cieľom vypočítať reprezentáciu tej istej sekvencie. Okolo každej z dvoch čiastkových vrstiev sa používa zvyškové spojenie, po ktorom nasleduje normalizácia vrstvy. To znamená, že výstupom každej podvrstvy je _LayerNorm (x + Sublayer (x))_, kde _Sublayer (x)_ je funkcia implementovaná samotnou podvrstvou. Aby sa uľahčili tieto zvyškové spojenia, všetky podvrstvy v modeli, ako aj vkladacie vrstvy, produkujú výstupy dimenzie _dmodel_ = 512. [1]
|
||||
|
||||
**Transformer Decoder**
|
||||
|
||||
Decoder je tiež zložený zo zásobníka _N = 6_ rovnakých vrstiev. Okrem dvoch podvrstiev v každej vrstve encodera, decoder vkladá tretiu podvrstvu, ktorá vykonáva multi-head attention nad výstupom encoder zásobníka. Podobne ako encoder, používa zvyškové spojenia okolo každej z podvrstiev, po ktorých nasleduje normalizácia vrstvy. Toto maskovanie v kombinácii so skutočnosťou, že vloženia výstupov sú posunuté o jednu pozíciu, zaisťuje, že predpovede pre polohu _i_ môžu závisieť iba od známych výstupov v polohách menších ako _i_. [1]
|
||||
|
||||
**Scaled Dot-Product Attention**
|
||||
|
||||
Našu osobitnú pozornosť nazývame „Pozornosť zameraná na produkt“ (obrázok 2). Vstup pozostáva z dotazov a kľúčov dimenzie _dk_ a hodnôt dimenzie _dv_. Bodové produkty dotazu vypočítame všetkými klávesmi, každý vydelíme √_dk_ a použijeme funkciu _softmax_, aby sme získali váhy hodnôt.
|
||||
|
||||
|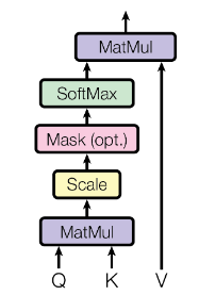|
|
||||
|:--:|
|
||||
|Obr 3. Scaled Dot-Production Attention|
|
||||
|
||||
V praxi počítame funkciu pozornosti pre množinu dotazov súčasne zabalených do matice _Q_. Kľúče a hodnoty sú tiež zabalené spolu do matíc _K_ a _V_. Maticu výstupov vypočítame ako:
|
||||
|
||||
||
|
||||
|:--:|
|
||||
|
||||
Dve najčastejšie používané funkcie pozornosti sú additive attention a dot-product attention. Dot-product attention je identická s naším algoritmom, s výnimkou faktora mierky 1/$\sqrt{dk}$. Additive attention počíta funkciu kompatibility pomocou siete spätnej väzby s jednou skrytou vrstvou. Aj keď sú tieto dva teoreticky náročné, dot-product attention je v praxi oveľa rýchlejšia a priestorovo efektívnejšia, pretože je možné ich implementovať pomocou vysoko optimalizovaného maticového multiplikačného kódu.
|
||||
|
||||
Zatiaľ čo pri malých hodnotách dk tieto dva mechanizmy fungujú podobne, additive attention prevyšuje pozornosť produktu bez toho, aby sa škálovala pri väčších hodnotách _dk_. Je pravdepodobné, že pri veľkých hodnotách _dk_ sa bodové produkty zväčšujú a tlačia funkciu _softmax_ do oblastí, kde má extrémne malé gradienty (v strojovom učení je gradient derivátom funkcie, ktorá má viac ako jednu vstupnú premennú). Aby sa tomuto efektu zabránilo, škálujeme bodové produkty o 1/$\sqrt{dk}$ [1] [4]
|
||||
|
||||
**Multi-Head Attention**
|
||||
|
||||
Namiesto toho, aby sme vykonávali funkciu jedinej pozornosti s _dmodel_-dimenzionálnymi kľúčmi, hodnotami a dotazmi, považuje sa za výhodné lineárne premietať dotazy, kľúče a hodnoty _h_-krát s rôznymi, naučenými lineárnymi projekciami do dimenzií _dk_, _dk_ a _dv_. Na každej z týchto predpokladaných verzií dotazov, kľúčov a hodnôt potom paralelne vykonávame funkciu pozornosti, čím sme získali _dv_-dimenzionálne výstupné hodnoty. Tieto sú zreťazené a znova premietnuté, výsledkom sú konečné hodnoty (obrázok 4).
|
||||
|
||||
|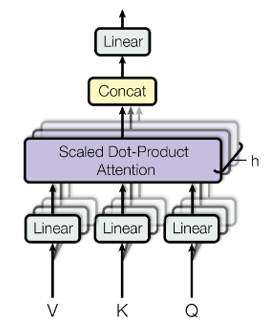|
|
||||
|:--:|
|
||||
|Obr 4. Multi-Head Attention|
|
||||
|
||||
Multi-head attention umožňuje modelu spoločne sa zaoberať informáciami z rôznych reprezentačných podpriestorov na rôznych pozíciách. Pri použití single-head attention to priemerovanie bráni.
|
||||
|
||||
|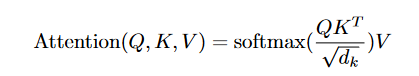|
|
||||
|:--:|
|
||||
|
||||
|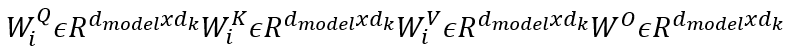|
|
||||
|:--:|
|
||||
|Obr 5. matice parametrov|
|
||||
|
||||
V tomto prípade si za _h_ dosadíme 8 paralelných vrstiev pozornosti, alebo „heads“. Pre každý z nich používame _dk_ = _dv_ = _dmodel/h_ = _64_. Vzhľadom na zmenšený rozmer každej hlavy sú celkové výpočtové náklady podobné nákladom na pozornosť single-head s plnou dimenzionalitou (koľko atribútov má množina údajov).
|
||||
|
||||
The Transformer využíva Multi-head attention tromi rôznymi spôsobmi:
|
||||
|
||||
Vo vrstvách „encoder-decoder attention“ pochádzajú dotazy z predchádzajúcej vrstvy decodera a pamäťové kľúče a hodnoty sú z výstupu encodera. To umožňuje každej pozícii v decoderi zúčastniť sa na všetkých pozíciách vo vstupnej sekvencii.
|
||||
|
||||
Encoder obsahuje vrstvy self-attention. Vo vrstve self-attention pochádzajú všetky kľúče, hodnoty a dotazy z rovnakého miesta, teda predchádzajúcej vrstvy v encoderu. Každá pozícia v encoderi sa môže venovať všetkým polohám v predchádzajúcej vrstve encodera.
|
||||
|
||||
Vrstvy self-attention v decoderi umožňujú každej pozícii v decoderi zúčastniť sa na všetkých polohách v decoderi až do danej polohy. Musí sa zabrániť toku informácii v decoderi, aby sa zachovala autoregresívna vlastnosť (model časových radov, ktorý používa pozorovania z predchádzajúcich časových krokov ako vstup do regresnej rovnice na predpovedanie hodnoty v nasledujúcom časovom kroku). To implementujeme do scaled dot-product attention pomocou maskovania (nastavením na -∞) všetkých hodnôt na vstupe softmax, ktoré zodpovedajú nezákonným spojeniam. [1] [4]
|
||||
|
||||
## R-Transformer
|
||||
|
||||
|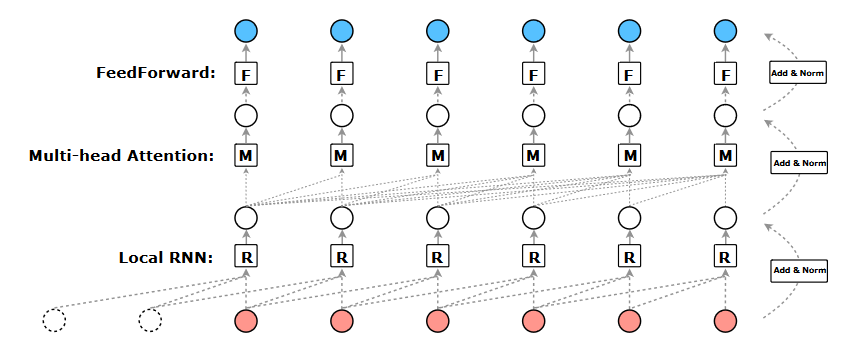|
|
||||
|:--:|
|
||||
|Obr 5. R-Transformer|
|
||||
|
||||
Navrhovaný transformátor R sa skladá zo stohu rovnakých vrstiev. Každá vrstva má 3 komponenty, ktoré sú usporiadané hierarchicky. Ako je znázornené na obrázku, nižšou úrovňou sú lokálne rekurentné neurónové siete, ktoré sú určené na modelovanie lokálnych štruktúr v sekvencii, stredná úroveň je Multi-head attention, ktorá je schopná zachytiť globálne dlhodobé závislosti a horná úroveň je position-wise feedforward sieť, ktorá vykonáva nelineárnu transformáciu prvkov. [2]
|
||||
|
||||
**Porovnanie s TCN**
|
||||
|
||||
R-Transformer je čiastočne motivovaný hierarchickou štruktúrou v TCN, v TCN je lokalita v sekvenciách zachytená konvolučnými filtrami. Sekvenčné informácie v rámci každého receptívneho poľa sú však pri konvolučných operáciách ignorované. Na rozdiel od toho, štruktúra LocalRNN v R-Transformer ju môže plne začleniť vďaka sekvenčnej povahe RNN. Pre modelovanie globálnych dlhodobých závislostí to TCN dosahuje pomocou rozšírených konvolúcií, ktoré fungujú na nenásledných pozíciách. Aj keď táto operácia vedie k väčším receptívnym poliam v nižších vrstvách, chýba značné množstvo informácií z veľkej časti pozícií v každej vrstve. [2]
|
||||
|
||||
**Porovnanie s Transformerom**
|
||||
|
||||
R-Transformer a štandardný Transformer majú podobnú kapacitu dlhodobého zapamätania vďaka Multi-head attention mechanizmu. Dve dôležité vlastnosti však odlišujú R-Transformer od štandardného Transformera. Po prvé, R-Transformer explicitne a efektívne zachytáva lokalitu v sekvenciách s novou štruktúrou LocalRNN, zatiaľ čo štandardný Transformer ju modeluje veľmi nepresne pomocou Multi-head attention, ktorá pôsobí na všetkých pozíciách. Po druhé, R-Transformer sa nespolieha na žiadne vloženie polohy ako Transformer. V skutočnosti sú výhody jednoduchého polohového zabudovania veľmi obmedzené a vyžaduje značné úsilie na navrhnutie efektívnych polohových zabudovaní, ako aj správnych spôsobov ich začlenenia. [2] [4]
|
||||
|
||||
## Zoznam použitej literatúry
|
||||
|
||||
[1]. VASWANI A., SHAZEER N., PARMAR N., USZKOREIT J., JONES L., GOMEZ N.A., KASIER L., POLUSUKHIN.I.: _Attention Is All You Need._ [online]. [citované 2017].
|
||||
|
||||
[2]. WANG Z., MA Y., LIU Z., TANG J.: _R-Transformer: Recurrent Neural Network Enhanced Transformer._ [online]. [citované 12-07-2019].
|
||||
|
||||
[3]. SRIVASTAVA S.: _Machine Translation (Encoder-Decoder Model)!._ [online]. [citované 31-10-2019].
|
||||
|
||||
[4]. ALAMMAR J.: _The Illustrated Transformer._ [online]. [citované 27-06-2018].
|
||||
|
||||
[5]. _Sequence Modeling with Neural Networks (Part 2): Attention Models_ [online]. [citované 18-04-2016].
|
||||
|
||||
[6]. GIACAGLIA G.: _How Transformers Work._ [online]. [citované 11-03-2019].
|
||||
|
||||
[7]. _Understanding LSMT Networks_ [online]. [citované 27-08-2015].
|
||||
|
||||
[8]. _6 Types of Artifical Neural Networks Currently Being Used in Machine Translation_ [online]. [citované 15-01-201].
|
||||
{kind=link}
|
After Width: | Height: | Size: 18 KiB |
BIN
pages/students/2016/patrik_pavlisin/dp22/Screenshot_1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 5.6 KiB |
BIN
pages/students/2016/patrik_pavlisin/dp22/rovnica 1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 12 KiB |
BIN
pages/students/2016/patrik_pavlisin/dp22/rovnica 2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 5.9 KiB |
{kind=link}
|
After Width: | Height: | Size: 16 KiB |
@ -2,13 +2,91 @@
|
||||
title: Tomáš Kuchárik
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [dp2021]
|
||||
tag: [annotation,question-answer,nlp]
|
||||
category: [dp2021,dp2022]
|
||||
tag: [nmt,translation,question-answer,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
# Tomáš Kuchárik
|
||||
(študent KPI)
|
||||
|
||||
Súvisiace práce:
|
||||
|
||||
- [Martin Jancura](/students/2017/martin_jancura)
|
||||
- [Patrik Pavlišin](/students/2016/patrik_pavlisin)
|
||||
- [Projekt SK QUAD](/topics/question)
|
||||
|
||||
|
||||
## Diplomová práca 2022
|
||||
|
||||
[Repozitár s výsledkami](https://git.kemt.fei.tuke.sk/tk634rv/dp2022)
|
||||
|
||||
Názov: Tvorba korpusu otázok a odpovedí v slovenskom jazyku pomocou strojového prekladu
|
||||
|
||||
Zadanie:
|
||||
|
||||
1. Vypracujte prehľad jazykových mutácii overovacej množiny SQUAD a opíšte spôsob ich tvorby.
|
||||
2. Vypracujte prehľad aktuálnych systémov pre generovanie odpovede na otázku v prirodzenom jazyku.
|
||||
3. Navrhnite postup pre vytvorenie korpusu otázok a odpovedí v slovenskom jazyku pomocou strojového prekladu z anglického jazyka,
|
||||
4. Porovnajte strojovo preloženú verziu SQUAD s manuálne vytvorenou verziou.
|
||||
5. Porovnajte presnosť systému generovania odpovedí naučenom na strojovo preloženej verzie SQUAD s s manuálne vytvorenou verziou.
|
||||
|
||||
Stretnutie 21.2.2022
|
||||
|
||||
- Urobený skript na preklad SQUAD pomocou google API.
|
||||
- Text nie je.
|
||||
|
||||
Úlohy
|
||||
|
||||
- Pridali možnosť na preklad pomocou európskeho prekladača etranslation. Transformujte celý squad do textového súboru so špeciálnymi značkami a nazad.
|
||||
- Vypracujte draft práce. Napíšte osnovu, napíšte teóriu, napíšte čo ste robili.
|
||||
|
||||
|
||||
|
||||
|
||||
## Diplomový projekt 2 2021
|
||||
|
||||
Cieľom je vytvoriť strojovo preloženú verziu SQUAD a overiť ju na QA systém.
|
||||
|
||||
Sttetnutie 22.10.2021
|
||||
|
||||
Stav:
|
||||
|
||||
- Začatý prieskum jazykových mutácií strojovo preloženého SQUAD - španielsky, taliansky, francúzsky a švédsky.
|
||||
- Začatý priestup prekladových API - napr. na google sa platí 20 $ za milion znakov.
|
||||
- Zaujala ma metód prekladu pomocou špeciálnych znakov.
|
||||
- Španielsky SQUAD má svoju štatistickú metódu zarovnania.
|
||||
- Možnosti pre preklad:
|
||||
- Google, Microsoft v rámci Free kreditu (asi ho je málo).
|
||||
- Zakúpiť kredit cez projekt.
|
||||
- Využiť "nekomerčný" projekt pre preklad, napr. [etranslation](https://ec.europa.eu/cefdigital/wiki/display/CEFDIGITAL/eTranslation).
|
||||
|
||||
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v písomnom prieskume jazykových mutácií SQUAD.
|
||||
- Začnite pracovať na skripte na strojový preklad SQUAD. Jedna z možností je prepísať SQUAD do čisto textového formátu obohateného o špeciálne značky. Pripravte skript, ktorý prevedie SQUAD do čisto textového formátu obohateného o špeciálne značky. Vyskúšajte formát v dostupných prekladačoch. V prípade, že značky sú zachované, pripravte aj skript na spätnú konverziu preloženého výsledku do formátu SQUAD.
|
||||
|
||||
|
||||
|
||||
|
||||
Stretnutie 15.10.
|
||||
|
||||
Stav:
|
||||
- Pôvodné zadanie neaktuálne
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Upraviť nové zadanie DP.
|
||||
- Urobiť písomný prieskum rôznych jazykových verzií overovacej množiny squad a spôsobov ich vytvorenia. Môžete začať v archíve HuggingFace Datasets.
|
||||
- Vybrať vhodný spôsob ako strojovo preložiť SQUAD. Zistiť aké sú možné problémy.
|
||||
- Zistiť ako funguje strojový preklad cez API.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- [ ] Urobiť vyhodnotenie SQUAD na knižnici Hugging Face Transformers.
|
||||
|
||||
## Diplomová práca 2021
|
||||
|
||||
Názov: Tvorba korpusu otázok a odpovedí v slovenskom jazyku pomocou crowdsourcingu
|
||||
|
||||
@ -1,54 +0,0 @@
|
||||
---
|
||||
title: Vzorný študent 2016
|
||||
taxonomy:
|
||||
type: student
|
||||
start_year: 2016
|
||||
teacher: hladek
|
||||
topics:
|
||||
- nlp
|
||||
- python
|
||||
keywords:
|
||||
- sablona
|
||||
---
|
||||
|
||||
# Vzorový študent
|
||||
|
||||
Toto je šablóna pre osobný profil. Do hlavného nadpisu dajte Vaše meno.´Nahraďte obyčajný text podľa inštrukcií, *zvýraznený text* a nadpisy nechajte ako sú.
|
||||
|
||||
*Rok začiatku štúdia*: uveďte rok začiatku štúdia.
|
||||
|
||||
Môžte pridať odkaz na Vašu osobnú stránku, fotografiu alebo zoznam Vašich osodných alebo odborných záujmov.
|
||||
|
||||
## Diplomová práca 2021
|
||||
|
||||
*Názov diplomovej práce*: Napíšte názov diplomovej práce
|
||||
|
||||
*Meno vedúceho*: meno vedúceho
|
||||
|
||||
*Zadanie diplomovej práce*: Tu napíšte zadanie Vašej diplomovej práce
|
||||
|
||||
## Tímový projekt 2019
|
||||
|
||||
*Písomná práca* : [Názov písomnej práce](./timovy_projekt) Uveďte odkaz na text vytvorený v rámci tímového projektu
|
||||
|
||||
*Ostatné výsledky* - odkaz na zdrojové kódy, ak sú nejaké
|
||||
|
||||
*Úlohy tímového projektu*: Uveďte zoznam úloh riešených v rámci predmetu Tímový projekt
|
||||
|
||||
- Úloha 1
|
||||
- Úloha 2
|
||||
|
||||
Poznámky k vypracovaniu projektu (od vedúceho alebo Vaše) uveďte ako sekcie nižšej úrovne
|
||||
|
||||
## Bakalárska práca 2019
|
||||
|
||||
*Meno vedúceho*: meno vedúceho
|
||||
|
||||
*Názov bakalárskej práce*: Napíšte názov bakalárskej práce
|
||||
|
||||
*Text bakalárskej práce*: uvedte odkaz na text Vašej bakalárskej práce, Odkaz na text vyhľadajte v [Centrálnom registri záverečných prác](https://opac.crzp.sk/?fn=*AdvancedSearch&search=advanced&entity=0&seo=CRZP-H%C4%BEadanie)
|
||||
|
||||
*Zadanie bakalárskej práce*: Tu napíšte zadanie Vašej bakalárskej práce
|
||||
|
||||
|
||||
|
||||
@ -1 +0,0 @@
|
||||
# Moja výborná práca
|
||||
@ -2,14 +2,178 @@
|
||||
title: Martin Jancura
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [bp2021]
|
||||
category: [bp2021,dp2023]
|
||||
tag: [opennmt,translation,demo,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
# Martin Jancura
|
||||
|
||||
*Rok začiatku štúdia*: 2017
|
||||
|
||||
## Diplomový projekt
|
||||
|
||||
- [GIT repozitár](https://git.kemt.fei.tuke.sk/mj130zg/DP2023)
|
||||
- [DP Práca](https://opac.crzp.sk/?fn=detailBiblioForm&sid=E4E659F3575B0C5BCF0C726CCD36)
|
||||
|
||||
Názov diplomovej práce:
|
||||
|
||||
Rozpoznávanie emócií v texte
|
||||
|
||||
Zadanie diplomovej práce:
|
||||
|
||||
1. Vypracujte prehľad metód rozpoznávania sentimentu z textu.
|
||||
2. Vytvorte slovenskú overovaciu množinu pre rozpoznávanie sentimentu.
|
||||
3. Vyberte vhodný model pre rozpoznávanie sentimentu v slovenských textoch.
|
||||
4. Vyhodnoťte vybraný model pomocou vytvorenej množiny a navrhnite jeho zlepšenia.
|
||||
|
||||
|
||||
|
||||
Ciele:
|
||||
|
||||
- Vedieť klasifikovať emocionálny náboj v texte pomocou neurónovej siete.
|
||||
|
||||
Ciele na semester:
|
||||
|
||||
- Získať prehľad v problematike rozpoznávania emócií z textu
|
||||
- Vybrať dátovú množinu, vybrať vhodný klasifikátor, natrénovať model a vyhodnotiť výsledky.
|
||||
|
||||
Informácie:
|
||||
|
||||
- [Hate speech Project](/topics/hatespeech)
|
||||
- https://www.sciencedirect.com/topics/computer-science/emotion-detection
|
||||
|
||||
Stretnutie 10.1.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Scraper je na GITe
|
||||
- Písomná časť je začatá.
|
||||
- Vyskúšaný SlovakBERT so sentiment classification
|
||||
- anotované množina topky, príliš veľa HATE.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vypracovať prehľad datasetov
|
||||
- Treba anotovať inú množinu, kde budú aj pozitívne príspevky.
|
||||
- Vyhodnotiť P R F1
|
||||
- Pripraviť zero shot experiment s Slovak GPT2.. Dostupné na Huggingface Hub.
|
||||
- Výsledky experimentov dať do tabuľky
|
||||
- Pokračovať v písomnej práci.
|
||||
|
||||
|
||||
Stretnutie 20.1.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Vylepšený scraper, tak by zachytával jednotilivé príspevky, autora, text aj rating.
|
||||
- Teoretická časť nebola urobená.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zdrojové kódy scrapera pridajte na GIT.
|
||||
- Vpracujte písomný prehľad datasetov pre slovenčinu a rozpoznávanie emócií https://github.com/slovak-nlp/resources.
|
||||
- Vypracujte prehľad neurónových metód na rozpoznávanie emócií z textu. bert, roberta, gpt.
|
||||
- Zistite, ako sa pomocou modelu GPT robí "zero shot sentiment classification".
|
||||
- Vyskúšajte slovenský model pre klasifikáciu sentimentu https://huggingface.co/kinit/slovakbert-sentiment-twitter.
|
||||
- Ručne anotujte vytvorenú databázu diskusných príspevkov z topky.sk
|
||||
- Urobte klasifikáciu príspevkov pomocou neurónového modelu a vyhodnoťte presnosť (accuracy, precision, recall).
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Do scrapera skúste doplniť zaznamenanie ID nadradeného príspevku. ID môže byť aj nejaký hash.
|
||||
- Urobte zero shot classification pomocou slovenského GPT .
|
||||
|
||||
|
||||
|
||||
Stretnutie 25.11.
|
||||
|
||||
Stav:
|
||||
|
||||
- Vieme parsovať Disqus fóra z topky.sk. Vieme získať nadpis a hlavičku článku, tagy článku. Vieme odlíšiť jednotlivé diskusné príspevky. Scraper je v javascripte, knižnica puppeteer.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zdrojové texty scrapera dajte do git repozitára.
|
||||
- Nainštalujte si balíček Anaconda a HF transformers.
|
||||
- Pozrite si tento model https://huggingface.co/cardiffnlp/twitter-xlm-roberta-base-sentiment. Vyskúšajte ho na anglickom texte aj na slovenskom texte. Prečítajte si vedecký článok a urobte si poznámky.
|
||||
- Prečítajte si článok o modeli XLM a napíšte poznámky. Prečítajte si vedecký článok o datasete, ktorý bol použitý a urobrte si poznámky. Vyhľadajte si dataset na huggingface HUB a pozrite sa ako vyzerá. Na vyhľadávanie použite TUKE sieť a google scholar.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Zo získaných slovenských dát vytvorte overovaciu množinu pre vybranýb model pre klasifikáciu sentimentu.
|
||||
- Pozrieť či existuje databáza.
|
||||
|
||||
Stretnutie 8.6.
|
||||
|
||||
Stav:
|
||||
|
||||
- Vypracovaný tutoriál huggingface
|
||||
- Vytvorený jednoduchý scraper Beautifulsoup na Topky.sk
|
||||
- Rozpracovaný scraper Selenium
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [-] Dať kódy na GIT - scraper (twitter, topky) aj tutorial
|
||||
- [ ] Dopísať písomnú správu o tutoriáli (2 až 3 strany) - čo ste sa dozvedeli o BERT, čo ste urobili. Dajte to do README.md.
|
||||
|
||||
Stretnutie 20.5.2022
|
||||
|
||||
Mierny pokrok nastal len v oblasti Python.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračovať v otvorených úlohách.
|
||||
- Chceme sa sústrediť na "sledovanie medií".
|
||||
- [x] Vytvoriť skript pre sledovanie Twitter kanálov. Skript by mal v pravidelných interovaloch získať nový obsah a uložiť ho do databázy (cassandra?). Zistitie, ktoré informácie o príspevkoch sú dôležité. čo vieme zistiť o príspevkoch?
|
||||
- Aký emočný náboj je v príspevku? Cieľom môže byť detekcia nenávistného obsahu.
|
||||
|
||||
|
||||
11.3.2022
|
||||
|
||||
Návrh na tému:
|
||||
|
||||
- Sledovanie médií alebo sociálnych sietí. - blogy, noviny, diskusie, twitter.
|
||||
- Zistenie metainformácií o príspevkoch.
|
||||
- Spracovanie príspevku - identifikácia sentimentu, detekcia nenávistnej reči, určenie témy príspevku, lepšie vyhľadávanie v databáze príspevkov. Ktorý materiál sa týka určitej témy?
|
||||
|
||||
Návrh na postup:
|
||||
|
||||
1. Oboznámenie sa s problematikou.
|
||||
2. Zostavenie databázy príspevkov. Stiahnutie a predspracovanie.
|
||||
3. Spracovanie databázy - natrénovanie neurónovej siete, klasifikácia a vyhodnotenie.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [ ] Zistite ako funguje neurónový jazykový model typu BERT - ako ho trénujeme a ako ho dotrénujeme. Zistite ako vieme pomocou neurónového jazykového modelu rozpoznávať sentiment v texte. Napíšte o tom krátku správu.
|
||||
- [ ] Nainštalujte si Anaconda, Oboznámte sa s knižnicou *HuggingFace Transformers*. Vyberte si tutoriál, prejdite ho a napíšte krátku správu.
|
||||
- [ ] Vyskúšajte tento [model](https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment) pre klasifikáciu anglických textov.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- [x] Pokračujte v štúdiu Pythonu, Oboznámte sa s Twitter API a zistite ako získať nejaký príspevok na Twitteri.
|
||||
- [ ] Naučte sa pracovať s knižnicou BeautifulSoup a pripravte scraper na vybraný zdroj.
|
||||
|
||||
|
||||
|
||||
|
||||
Stretnutie 4.3.2022
|
||||
|
||||
Nápady na tému diplomovej práce:
|
||||
|
||||
- Strojový preklad pomocou neurónových sietí.
|
||||
- Rozpoznávanie reči pomocou transformerov - Hubert.
|
||||
- Rozpoznávanie nenávistnej reči pomocou transfomers.
|
||||
- Sledovanie medií - vytvorenie databázy a jej analýza.
|
||||
- Rozpoznávanie (klasifikácia) obrázkov pomocou neurónovej siete.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Porozmýšľajte nad každou hore uvedenou témou.
|
||||
- Porozmýšľajte nad témou čo by Vás bavila.
|
||||
- Pokračujte v štúdiu Pythonu.
|
||||
- Oboznámte sa s knižnicou HuggingFace Transformers alebo s knižnocou fairseq.
|
||||
|
||||
## Bakalárska práca 2020
|
||||
|
||||
Názov: Webová aplikácia pre demonštráciu strojového prekladu
|
||||
|
||||
155
pages/students/2018/adrian_remias/README.md
Normal file
@ -0,0 +1,155 @@
|
||||
---
|
||||
title: Adrián Remiáš
|
||||
published: true
|
||||
date: 01-02-2014
|
||||
taxonomy:
|
||||
category: [dp2024]
|
||||
tag: [nlp, transformers, interpuction]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
# Adrián Remiáš
|
||||
|
||||
Rok začiatku štúdia: 2018
|
||||
|
||||
|
||||
# Diplomová práca 2024
|
||||
|
||||
Návrh na zadamie:
|
||||
|
||||
1. Vypracujte prehľad metód obnovy interpunkcie v slovenskom jazyku.
|
||||
2. Vypracujte prehľad metód jazykového modelovania pomocou neurónovej siete typu Transformer.
|
||||
3. Pripravte dátovú množinu pre trénovanie a vyhodnotenie neurónovej siete na úlohu dopĺňania a opravy interpunkcie.
|
||||
4. Vyberte viacero neurónových modelov, natrénujte ich na úlohu dopĺňania a opravy interpunkcie.
|
||||
5. Vyhodnoťte experimenty a vyberte najlepší model.
|
||||
|
||||
|
||||
Ciele:
|
||||
|
||||
- Natrénovanie modelu pre opravu iterpunkcie a jeho vyhodnotenie.
|
||||
- Výsledky by mali byť prezentovateľné vo vedeckom článku.
|
||||
|
||||
Stretnutie 3.1.2024
|
||||
|
||||
Stav:
|
||||
|
||||
. Funguje zero shot metóda založená na dopňĺňaní mask tokenu.
|
||||
|
||||
Úlohy:
|
||||
|
||||
1. Vyskúšajte príklad [token classification](https://github.com/huggingface/transformers/tree/main/examples/pytorch/token-classification) z repozitára HF transformers pre úlohu NER alebo POS. Oboznámte sa s argumentami príkazového riadka.
|
||||
2. Pripravte si trénovacie dáta. Použite formát JSON. Na jeden riadok ide jeden príklad. Príklad je tvorený textom (zoznamom slov) a interpunkciou (zoznam tried). Budete mať súbor train.json a test.json. Na prípravu dátovej množiny si pripravte skript aby to bolo opakovateľné.
|
||||
3. Spustite skript so svojimi dátami a so slovenským BERTOMN. Nastavte parametre príkazového riadku a formát trénovacej množiny tak aby tomu skript rozumel.
|
||||
4. Vyskúšajte viaceré experimenty s viacerými rôznymi BERT modelmi s podporou slovenčiny a výžsledky zapíšte do tabuľky.
|
||||
5. Skúste číselne vyhodnotiť aj Vašu "zero shot" metódu.
|
||||
- Pokračujte v písaní tectu práce.
|
||||
|
||||
Stretnutie 7.12.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Vytvorený program na trénovanie neurónovej siete. Masked language modeling skript run_mlm.py. Roberta for Masked LM DataCollatorForLanguageModelling.
|
||||
- Navrhnutý skript pridáva mask token medzi slová a sleduje, čo doplní model. Časť s trénovaním je v tomto prípade zbytočná.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vyhoddnotte prenosť Vami navrhnutého prístupu. Mali by ste zostaviť kontingenčnú tabuľku. (confusion matrix). Tabuľka má na jednej osi očakávané hodnoty a na druhej osi skutočné hodnoty. https://www.analyticsvidhya.com/blog/2020/09/precision-recall-machine-learning/
|
||||
- O spôsobe vyhodnotenia môžete napísať aj krátku podkapitolu.
|
||||
- Uvedte zdroje odkiaľ ste čerpali pri tvorbe.
|
||||
|
||||
```
|
||||
Pôvodný text: Dnes je pekný deň .
|
||||
Opravený text Dnes , je pekný deň .
|
||||
|
||||
. , ? ! x toto dáva sieť
|
||||
. 2 1 0 0 0
|
||||
,
|
||||
?
|
||||
!
|
||||
x 1 1
|
||||
očakávané hodnoty
|
||||
```
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Dotrénujte neurónovú sieť na úlohu dopňlňania interpunkcie. Úloha je formulovaná ako "klasifikácia postupností" a je podobná úlohám "part of speech tagging" alebo "named entity recognition". Pokračujte v prieskume literatúry na túto tému a robte si poznámky o prístupoch.
|
||||
- Podrobné {vysvetlenie](https://medium.com/@alexmriggio/bert-for-sequence-classification-from-scratch-code-and-theory-fb88053800fa).
|
||||
|
||||
Takto by mala vyzerať trénovacia množina.
|
||||
|
||||
```
|
||||
x x x . , x x .
|
||||
Dnes je pekný den Povedala že ostane doma
|
||||
```
|
||||
|
||||
- Môžete využiť [skripty](https://github.com/huggingface/transformers/tree/main/examples/pytorch/token-classification). Tam je potrebn0 správne pripraviť dátovú množinu tak, aby na ľavej strane bole len slová a na pravej strane bola ku kažnédmu slovu pridelená trieda. Formát by mal byť JSON, na jeden riadok jeden dokument, zrozumiteľný pre [HF datasets](https://huggingface.co/docs/datasets/loading#json).
|
||||
|
||||
Stretnutie 23.11.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Boli nainštalované softvéry na idoc podľa pokynov.
|
||||
- Śtúdium a kódovanie: problémy.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [ ] Podrobne sa oboznámte https://github.com/xashru/punctuation-restoration/tree/master . Prečítajte si
|
||||
článok. Urobte si poznámky čo ste sa dozvedeli. Zistite, aké metódy iné sa používajú na PR a aká metóda je v článku. Zistitie, ako to súvisí s Modelom BERT.
|
||||
- Pohľadajte iný podobný repozitár.
|
||||
- Získajte zdrojové kódy a spustite experimenty v naglickom a bangla jazyku s dátami dodanými v repozitári. Oboznámte sa so zdrojovými kódmi a skúste pochopiť ktorá časť robí čo.
|
||||
- Pokračujte v štúdiu jazyka Python. https://diveintopython3.net/
|
||||
- Pokračujte v písaní práce podľa pokynov vyššie.
|
||||
|
||||
Stretnutie 26.10.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Štúdium a poznámky podľa pokynov. Vyskúšaná Anaconda a transformers.
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [ ] Pokračovať v štúdiu a v poznámkach. To je teoretická časť DP.
|
||||
- [-] Na katedrovom gite si vytvorte repozitár s názvom DP2024, do neho dajte kódy pre tvorbu dát a trénovanie siete. Dáta nedávajte na git.
|
||||
- [x] Inštalujte Pytorch s podporou CUDA 10.1 alebo 10.2 z https://pytorch.org/get-started/previous-versions/
|
||||
- [x] Na idoc nainštalujte transformers, pytorch s CUDA 10.1 pomocou Anaconda.
|
||||
- Vyberte množinu slovenských textov a upravte ju do podoby vhodnej na trénovanie neurónovej siete. Dáta sa nachádzajú na servri idoc.fei.tuke.sk v /mnt/sharedhome/hladek/bert-train/data/corpus3/.
|
||||
Na ľavej strane bude text bez interpunkcie. Na pravej strane bude len interpunkcia.
|
||||
- [ ] Natrénujte neurónovú sieť. Množinu rozdeľte na trénovaciu a testovaciu časť. Začneme s modelom SlovakBERT.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vyskúšajte iný model ako je Slovak BERT.
|
||||
- Pripravte dáta na "čiastočné" dopňlňanie. Skúste identifikovať iba koniec vety. Skúste náhodne "pokaziť" interpunkciu a pomocou neurónovej siete ju opraviť.
|
||||
|
||||
Stretnutie 5.10.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Urobená bakalárska práca na tému "Analýza textu z pohľadu forenznej lingvistiky".
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Nainštalujte si balíček Anaconda. Pomocou neho si nainštalujete knižnicu Pytorch s podporou CUDA.
|
||||
|
||||
|
||||
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
|
||||
pip install transformers
|
||||
|
||||
- [x] Oboznámte sa s frameworkom HuggingFace [Transformers](https://huggingface.co/docs/transformers/index). Vypracujte si viacero úvodných tutoriálov.
|
||||
- [x] Podrobne sa oboznámte s úlohou [token classificaton](https://huggingface.co/docs/transformers/tasks/token_classification).
|
||||
- [x] Prečítajte si [článok](https://ieeexplore.ieee.org/abstract/document/9089903 Comparison of Recurrent Neural Networks for Slovak Punctuation Restoration, urobte si poznámky.
|
||||
- [x] Prečítajte si "Attention is all you need" https://arxiv.org/abs/1706.03762, urobte si poznámky.
|
||||
- [-] Vyhľadajte heslo "punctuation restoration" na google scholar, poznačte si najdôležitejšie články. Prečítajte si ich a napíšte, akú metódu používaju.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vyberte množinu slovenských textov a upravte ju do podoby vhodnej na trénovanie neurónovej siete. Natrénujte neurónovú sieť.
|
||||
- Na katedrovom gite si vytvorte repozitár s názvom DP2024, do neho dajte kódy pre tvorbu dát a trénovanie siete. Dáta nedávajte na git.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
52
pages/students/2018/david_ilas/README.md
Normal file
@ -0,0 +1,52 @@
|
||||
---
|
||||
title: Dávid Iľaš
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [dp2023]
|
||||
tag: [nlp,emotion]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
|
||||
Rok začiatku štúdia: 2018
|
||||
|
||||
Už neštuduje tento študijný program.
|
||||
|
||||
## Diplomová práca 2023
|
||||
|
||||
Téma: Rozpoznávanie emócií z textu.
|
||||
|
||||
TODO: Návrh na zadanie diplomovej práce.
|
||||
|
||||
Ciele:
|
||||
|
||||
- Vedieť klasifikovať emocionálny náboj v texte pomocou neurónovej siete.
|
||||
|
||||
Ciele na semester:
|
||||
|
||||
- Získať prehľad v problematike rozpoznávania emócií z textu
|
||||
- Vybrať dátovú množinu, vybrať vhodný klasifikátor, natrénovať model a vyhodnotiť výsledky.
|
||||
|
||||
Informácie:
|
||||
|
||||
- [Hate speech Project](/topics/hatespeech)
|
||||
- https://www.sciencedirect.com/topics/computer-science/emotion-detection
|
||||
|
||||
|
||||
|
||||
|
||||
Stretnutie 18.2.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vyberte 3 vedecké články, prečítajte si ich a napíšte poznámky čo ste sa dozvedeli. Poznačte si bibliografické informácie o článkoch.
|
||||
- Heslá na vyhľadávanie: eomotion recognition, transfer learning, deep learning, emotion classification, emotion detection
|
||||
- Na vyhľadávanie článkov použite google scholar alebo scopus.com.
|
||||
- Nainštalujte si balíček Anaconda
|
||||
- Prejdite si niekoľko Python tutoriálov, odporúčam online knihu Dive Into Python 3
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Oboznámte sa s knižnicou Huggingface Transformers
|
||||
|
||||
|
||||
228
pages/students/2018/david_omasta/README.md
Normal file
@ -0,0 +1,228 @@
|
||||
---
|
||||
title: Dávid Omasta
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [dp2023,dp2024]
|
||||
tag: [lm]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
Začiatok štúdia: 2018
|
||||
|
||||
Súvisiace stránky:
|
||||
|
||||
- [Question Answering](/topics/question) - interný projekt
|
||||
- Jozef Olekšák
|
||||
- Matej Čarňanský (BERT)
|
||||
- Ondrej Megela
|
||||
|
||||
# Diplomová práca 2024
|
||||
|
||||
Vedúci: Daniel Hládek
|
||||
|
||||
Návrh na názov:
|
||||
|
||||
Generatívne modely pre automatické odpovede na otázky v slovenskom jazyku
|
||||
|
||||
Návrh na zadanie DP:
|
||||
|
||||
- Vypracujte prehľad najnovších generatívnych neurónových jazykových modelov.
|
||||
- Vypracujte prehľad slovenských a multilinguálnych generatívnych jazykových modelov.
|
||||
- Navrhnite experiment, pri ktorom bude model generovať odpovede na zadané otázky v kontexte.
|
||||
- Analyzujte výsledky experimentu vhodným spôsobom a identifikujte možné zlepšenia.
|
||||
|
||||
Ciele:
|
||||
|
||||
- Pripraviť demo.
|
||||
- Pripravť vedecký článok z DP.
|
||||
|
||||
Stretnutie 9.2.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Dotrénovaný mt5-small na poľský jazyk.
|
||||
- Práca na texte
|
||||
- Urobené demo streamlit a Dockerfile.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zdrojáky dajte na GIT
|
||||
- Pridajte výsledky do tabuľky
|
||||
- Pokračujte v práci na texte.
|
||||
- Pridajte experimenty s modelom https://huggingface.co/google/umt5-small na slovenský, anglický aj poľský jazyk.
|
||||
|
||||
|
||||
Stretnutie 8.12.
|
||||
|
||||
Stav:
|
||||
|
||||
- Urobený Dockerfile a compose.
|
||||
- Pridaný experiment s mT5.
|
||||
- Práca na teoretickej časti.
|
||||
- Vyskúšaná LLAMA na idoc aj mt5-base ale nejde kvôli GPU
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v písomnej práci. Výsledky experiemntov opíšte a dajte do tabuliek.
|
||||
- Dokončite DEMOZ
|
||||
- pre porovnanie, vyskúšajte dotrénovať mt5 na dátovej sade pre iný jazyk. Angličtina - squad, Poľský jazyk clarin-pl/poqaud .
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Keď bude k dispozícii, vyskúšajte nový slovenský t5 model.
|
||||
|
||||
|
||||
|
||||
Stretnutie 10.11
|
||||
|
||||
Stav:
|
||||
|
||||
- DP je rozpísaná. Existuje draft.
|
||||
- Vypracovaný experiment s Slovak t5 small
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [-] Opravte DP podľa pokynov
|
||||
- [x] Pridajte experiment s mt5 small .https://huggingface.co/google/mt5-small
|
||||
- [-] Pripravte demo na nasadenie. Zmente Windows kontajner na Linux.
|
||||
- [x] zdrojáky dajte na kemt GIT
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- [-] Skúste generovanie odpovedí s modelom LLAMA alebo podobným.
|
||||
- [x] Skúste generovanie odpovedí s "base" modelmi na školskom servri.
|
||||
|
||||
Stretnutie 6.10
|
||||
|
||||
Stav:
|
||||
|
||||
- Práca na Dockerfile so streamlit
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pozrieť a pracovať na minulých otvorených úlohách.
|
||||
- Pripraviť draft na prečítanie.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vyskúšať aj iné generatívne modely a pripraviť z nich experimenty.
|
||||
- Pripraviť a vyskúšať aj iné dátové množiny.
|
||||
|
||||
|
||||
# Diplomová práca 2023
|
||||
|
||||
Téma: Dotrénovanie slovenského generatívneho jazykového modelu.
|
||||
|
||||
Vedúci: Ján Staš
|
||||
|
||||
Návrh na názov:
|
||||
|
||||
Generatívne modely slovenského jazyka
|
||||
|
||||
Návrh na zadanie DP:
|
||||
|
||||
- Vypracujte prehľad najnovších generatívnych neurónových jazykových modelov.
|
||||
- Vypracujte prehľad slovenských a multilinguálnych generatívnych jazykových modelov.
|
||||
- Navrhnite experiment, pri ktorom bude model generovať odpovede na zadané otázky a kontext.
|
||||
- Analyzujte výsledky experimentu vhodným spôsobom a identifikujte možné zlepšenia.
|
||||
|
||||
Ciele na zimný semester:
|
||||
|
||||
Praktické:
|
||||
|
||||
- Rozbehajte proces dotrénovania jazykových modelov pomocou knižnice Huggingface Transformers
|
||||
- Vyberte alebo vytvorte vhodnú dátovú množinu ktorá bude obsahovať slovenské dialógu.
|
||||
- Vyskúšajte slovenský generatívny model GPT a dotrénujte ho pre použitie v dialógovom systéme.
|
||||
- Vytvorte demonštračnú aplikáciu.
|
||||
|
||||
Teoretické:
|
||||
|
||||
- Vypracujte prehľad najnovších generatívnych neurónových jazykových modelov (cca 20 strán).
|
||||
- Napíšte návod na inštaláciu a návod na použitie skriptov pre dotrénovanie (cca 5 strán).
|
||||
|
||||
Stretnutie 25.4.
|
||||
|
||||
Stav:
|
||||
|
||||
- Napísaný draft práce
|
||||
- Pripravené demo s generovaním otázok pomocou t5, huggingface, streamlit, fastapi.
|
||||
- Git je momentálne na https://git.kpi.fei.tuke.sk/do867bc
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pracovať na textovej časti podľa poznámok - zlepšiť text, štruktúru a úpravu.
|
||||
- Vytvoriť repozitár na git.kemt.fei.tuke.sk a dajte tam zdrojáky
|
||||
- Finalizovať repozitár s demom. Pridajte odkazy na modely, modely nedávajte na GIT. Na git dajte zdrojové kódy v Python a Notebooky. Pridajte README s opisom kódov a návodom na inštaláciu.
|
||||
- Skontrolujte výsledky ROUGE, vyzerajú podozrivo.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vytvorte Dockerfile
|
||||
|
||||
|
||||
Stretnutie 24.2.2023
|
||||
|
||||
Stav:
|
||||
|
||||
|
||||
- Rozbehaný notebook na dotrénovanie slovenského t5 na úlohu generatívneho question answering.
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Dajte notebook na GIT
|
||||
- [x] Vyhodnnotte presnosť generovania odpovede pomocou P-R-F1 pre celú dev množinu.
|
||||
- [-] Pokračujte v písaní textu DP. Opíšte slovenský QA dataset. Slovne opíšte experiment. Aký postup ste použili, aké dáta, aké modely.
|
||||
- [x] Zopakujte experiment pre model mt5-small, mt5-base. Výsledky dajte do tabuľky.
|
||||
|
||||
|
||||
Stretnutie 24.11
|
||||
|
||||
Stav:
|
||||
|
||||
- nainštalované prostredie na idoc, spustený hf skript run_generation.py
|
||||
- prečítané články.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [-] písomne vysvetlite ako funguje neurónová sieť typu Transformer . Uveďte odkazy na odborné články.
|
||||
- [ ] Písomne vysvetlite, čo to je generatívny jazykový model a ako funguje. Uveďte odkazy na najnovšie články o generatívnych jazykových modeloch - T5, GPT, BART.
|
||||
- Vyskúšajte tento skript run_clm.py : https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling. Pozrite si príklad na run_mlm.py v repozitári https://git.kemt.fei.tuke.sk/dano/bert-train v adresári hugging/roberta-train
|
||||
- Pozrite si tento tutoriál https://towardsdatascience.com/fine-tune-a-non-english-gpt-2-model-with-huggingface-9acc2dc7635b
|
||||
- Pozrite si toto demo https://huggingface.co/blog/few-shot-learning-gpt-neo-and-inference-api
|
||||
- Vytvorte si git repozitár do ktoréhu budete ukladať Vaše skripty.
|
||||
- Vyskúšajte slovenský GPT model https://huggingface.co/Milos/slovak-gpt-j-162M (je malý, stredný, veľký)
|
||||
|
||||
|
||||
Stretnutie 14.10.
|
||||
|
||||
Stav:
|
||||
|
||||
- Na vlastnom počítači rozbehané Anaconda, Pytorch a CUDA.
|
||||
- Prečítané články.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračovať.
|
||||
|
||||
Stretnutie 7.10.
|
||||
|
||||
Stav:
|
||||
|
||||
- Obznámený s Google Colab. Vyskúšané tutoriály BERT text classification,
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [-] Prečítajte si ako funguje neurónová sieť typu Transformer a [ ] písomne to vysvetlite. Uveďte odkazy na odborné články.
|
||||
- [ ] Písomne vysvetlite, čo to je generatívny jazykový model a ako funguje. Uveďte odkazy na najnovšie články o generatívnych jazykových modeloch - T5, GPT, BART.
|
||||
- [x] Nainštalujte si prostredie Anaconda, knižnicu PyTorch s podporou CUDA a knižnicu HF transformers. Použite server idoc.
|
||||
- [x] Vyskúšajte tento skript: https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-generation.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Prečítajte si ako funguje neurónová sieť typu GPT a písomne to vysvetlite, Uveďte odkazy na odborné články.
|
||||
- Vyskúšajte tento tutoriál https://towardsdatascience.com/fine-tune-a-non-english-gpt-2-model-with-huggingface-9acc2dc7635b
|
||||
- Pozrite si toto demo https://huggingface.co/blog/few-shot-learning-gpt-neo-and-inference-api
|
||||
- Vytvorte si git repozitár do ktoréhu budete ukladať Vaše skripty.
|
||||
- Vyskúšajte slovenský GPT model https://huggingface.co/Milos/slovak-gpt-j-162M (je malý, stredný, veľký)
|
||||
@ -2,7 +2,7 @@
|
||||
title: Ondrej Megela
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [bp2021]
|
||||
category: [bp2021,dp2023]
|
||||
tag: [nlp,fairseq,lm,bert,question-answer,qa]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
@ -17,6 +17,251 @@ Súvisiace stránky:
|
||||
- [Question Answering](/topics/question) - interný projekt
|
||||
- Matej Čarňanský (BERT)
|
||||
|
||||
|
||||
Pozrieť toto:
|
||||
|
||||
https://paperswithcode.com/task/text-generation?page=3
|
||||
|
||||
# Diplomová práca 2023
|
||||
|
||||
|
||||
https://opac.crzp.sk/?fn=detailBiblioForm&sid=E4E659F3575B0C5BCF0F726CCD36
|
||||
|
||||
Nazov:
|
||||
|
||||
Automatické generovanie otázok v slovenskom jazyku
|
||||
|
||||
1. Vypracujte prehľad generatívnych jazykových modelov.
|
||||
2. Vypracujte prehľad vyhodnocovacích metrík pre generatívne modely.
|
||||
3. Navrhnite a vykonajte viaceré experimenty pre úlohu generovania otázok.
|
||||
4. Vyhodnoťte experimenty vhodnou metrikou a navrhnite zlepšenia modelu generovania otázok.
|
||||
|
||||
Súvisiace práce:
|
||||
|
||||
- Dávid Omasta
|
||||
|
||||
Cieľ: Využiť slovenský generatívny model na tvorbu databázy otázok a odpovedí.
|
||||
|
||||
https://git.kemt.fei.tuke.sk/om385wg/DP
|
||||
|
||||
Stretnutie 24.2.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Vytvorený notebook pre vyhodnotenie generovanie otázok pomocou BLEU. Zatiaľ nefunguje, pretože asi je potrebné spoávne zoradiť vygenerovanú otázku a referenciu, Ku paragrafu môže existovať viacero rôznych otázok, preto je tažké ich porovnať pomocou BLEU ngramov.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Na vyhodnotenie použiť sémantický model. POdľa modelu vytvoriť dvojice - generovaná veta a referencia.
|
||||
- Na vyhodnotneie použiť "Answerability" - QA model s thresholdom.
|
||||
- Pracovať na diplomovej práci - písať prehľad - metódy, metriky vyhodnotenia, datasety.
|
||||
- Do DP pripraviť experiment s vyhodnotením.
|
||||
|
||||
Zásobník úloh:
|
||||
- Priradiť vgenerované vety ku referencii na základe sémantickej podobnosti.
|
||||
- Priamo merať sémantickú pokdobnosť vygenerovaných viet a referenciíá.
|
||||
- Použiť operátor max, mean alebo kl-diveregencia, cross-entropy?
|
||||
|
||||
Stretnutie 23.1.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Modifikovany ssk quad dataset, tak aby aby sa dal vykonat finetuning t5. Vstupom je kontext a viacero otazok.
|
||||
- Dotrenovany t5 model na generovanie otazok. Vyzera ze ide.
|
||||
- Vyskusany few shot learning pomocou prikladov zo sk quad.
|
||||
|
||||
Ulohy:
|
||||
|
||||
- Pokracovat v pisani podla aktualizovaneho zadania
|
||||
- Implementovat vyhodnbotenie generovania otazok. Vyhodnotenie pomocou generovanej odpovede. BLEU-ROUGE-METEOR pre gemnerovanue otazky a gold truth otazky. Ako sa to robi v literature ? Zistit a napisat.
|
||||
|
||||
|
||||
Zasobnik uloh:
|
||||
|
||||
- Navrhnut eperimenty pre DP/clanbok.
|
||||
- porovnat slovensky a anglicky model. Mozno aj iny jazyk.
|
||||
- vyskusat, ako pomahaju generovane toazky pri QA.
|
||||
- rucne vyhodnotit vygenerovane otazky.
|
||||
|
||||
|
||||
Stretnutie 22.12.
|
||||
|
||||
- Slovenský GPT model nefunguje na few shot generovanie otázok.
|
||||
- Existuje slovenský T5 model small. Ten funguje.
|
||||
- Vyskúšaný finetuning na colabe na slovenský T5 model na anglických dátach, zbehol za 1.5. hodiny.
|
||||
- Nájdený QA evaluátor, ktorý ohodnotí vygenerované otázky pomocou BERT. Evaluátor hodnotí, či otázka a odpovedˇ sedia spolu. Trénuje sa na rovnakom datasete ako generátor.
|
||||
- QA evaluátor a generátor https://github.com/AMontgomerie/question_generator
|
||||
- Finetuning slovenského T5 https://colab.research.google.com/drive/1z-Zl2hftMrFXabYfmz8o9YZpgYx6sGeW?usp=sharing
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pracovať na textovej časti DP a.k.a. ATKS
|
||||
- Skontrolovať a na ďalšom stretnutí updatovať zadanie DP.
|
||||
- Dokončiť skripty a generovať otázky pre slovenský jazyk.
|
||||
- Vyhodnotiť kvalitu generovania otázok.
|
||||
- Pripraviť experiment, kde vo viacerých scenároch (finetuning, few shot) generujeme otázky.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Pripraviť článok (do časopisu). Najprv prekladom z DP.
|
||||
- Pripraviť aj out-of-domain test - iná doména (noviny, úäradné dokumenty). Iný jazyk. Porovnanie slovenského a anglického generovanie.
|
||||
- Pripraviť test, kde odmieriame prínos automaticky generovanej databázy na probmém question answering.
|
||||
- Použiť generátor pri manuálnej anotácii. Človek môže hodnotiť kvalitu generovanej otázky alebo ju opraviť.
|
||||
|
||||
|
||||
|
||||
Stretnutie 28.10
|
||||
|
||||
Stav:
|
||||
- Vyskúšaný slovenský GPT model v rôznych veľkostiach. Generovanie funguje. Obbmedzene funguje aj zero shot sentiment classification. Zagtiaľ nefuguje pre generovanie otázok.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračovať v Zero Shot: Vymeniť Sentence za Veta. Pozrieť Separátor v slovníku.
|
||||
- Skúsiť rozbehať run_clm pre slovenský GPT model pre úlohu generovania otázok. Poskytnutý prístup do repozitára bert-train. Ak skript bude fungovať, tak ho pridajte do repozitára bert-train/huggingface/clm
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Možno by sa dalo formulovať úlohu ako klasický machne translation a použiť niekotrý existujúci setup pre preklad bez predtrénovania. Existujú skripty pre fairseq.
|
||||
- Možno bude fungovať nejaký multilinguálny generatívny model.
|
||||
|
||||
Stretnutie 7.10:
|
||||
|
||||
Stav:
|
||||
|
||||
- PatilSuraj zatiaľ nefunguje. Funguje iba na T5 a Bart vlastné anglické, nefunguje na gpt-j ano na mt5. Stále je tam možnosť vyskúšať vlastný slovenský BART.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Vyskúšať slovenský GPT model v úlohe few-shot learning. Inšpirácia https://huggingface.co/blog/few-shot-learning-gpt-neo-and-inference-api. Použite niektorý prístup z patilsuraj.
|
||||
- [ ] Vyoracujte písomný prehľad generatívnych jazykových modelov.
|
||||
- [ ] Vypracujte písomný prehľad metód generovania otázok pomocou jazykového modelu. Nezabudnite na odkazy na odbornú literatúru.
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- [ ] Dotrénovať slovenský GPT model pomocou HF skriptu run_clm.py
|
||||
- [ ] Zistiť aký veľký model nám funguje.
|
||||
- [ ] Vybrať vhodný server na dorénovanie. Koľko GRAM potrebujeme?
|
||||
- [ ] Záložná možnosť - písať pre anglický jazyk.
|
||||
|
||||
## Diplomový projekt 1 2022
|
||||
|
||||
Cieľ:
|
||||
|
||||
- Vytvoriť a vyhodnotiť generatívny model slovenského jazyka.
|
||||
- Navrhnúť a vytvoriť overovaciu množinu pre slovenské generatívne modely.
|
||||
|
||||
Stretnutie 29.6.
|
||||
|
||||
- Vyskúšané dosadenie slovenského GPT modelu do kódu patil-suraj. Nefunguje - nepasuje konfigurácia.
|
||||
- Vyskúšané nasadenie Multilingual T5. Podarilo sa ho nahrať. Chyba "index Out Of Range".
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračovať v otvorených úlohách. Rozbehať skripty "patil-suraj".
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vyskúšať existujúci slovenský BART model (od vedúceho).
|
||||
- Natrénovať a vyskúšať nový slovenský BART model (aj pre vedúceho).
|
||||
|
||||
Stretnutie 8.4.
|
||||
|
||||
Prezreté sú tri repozitáre. kompatibilné s HF Transformers
|
||||
|
||||
https://github.com/p208p2002/Transformer-QG-on-SQuAD#seq2seq-lm
|
||||
- Používa modely GPT-2, BART,T5, upravený „BERT“
|
||||
- vstup ide odsek + zvýraznená odpoveď pomocou tokenu [HL]
|
||||
|
||||
Haystack deepset – QG pipeline
|
||||
- Postup: (https://haystack.deepset.ai/tutorials/question-generation)
|
||||
- kompatibilný s HF Transformers
|
||||
- https://github.com/deepset-ai/haystack#mortar_board-tutorials
|
||||
- https://www.deepset.ai/blog/generate-questions-automatically-for-faster-annotation
|
||||
|
||||
https://github.com/patil-suraj/question_generation
|
||||
- Využíva 2 formáty vstupu:
|
||||
- Oddelenie odpovede pomocou SEP, odpoveď je osobitne
|
||||
- 42 `[SEP]` 42 is the answer to life, the universe and everything. Vyznačenie odpovede pomocou HL priamo v kontexte.
|
||||
- `<hl>` 42 `<hl>` is the answer to life, the universe and everything.
|
||||
|
||||
3 možnosti definície úlohy generovanie otázok :
|
||||
- QG – vstup je kontext a odpoveď, výstup je otázka
|
||||
- Multitask QA- QG: Deje sa vo viacerých krokoch: vyhľadanie odpovede (zaujímavej časti) v texte, generovanie otazky na zaklade odpovede, spätné vyhľadanie odpovede
|
||||
- End-to-End QG – Generovanie otázok len na zaklade kontextu, vstup je kontext, výstup je otázka.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Začneme s prístupom "End-To-End" - generovanie otázok na základe zadaného odseku.
|
||||
- Rozbehnite skript, ktorý naučí generatívny model generovať otázky na základe zadaného odseku. Ako vstup použite sk-quad.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Navrhnite a implementujte spôsob vyhľadanie zaujímavej časti odseku - kandidáta na možnú odpoveď.
|
||||
|
||||
|
||||
|
||||
11.3.
|
||||
|
||||
- Vyskúšaný GPT na cloab, zatiaľ nefunguje kvôli pamäti.
|
||||
|
||||
Možné spôsoby využitia generatívnych modelov:
|
||||
|
||||
- mnli - multi natural language inference - textual entailment and contradiction, zero shot classification
|
||||
- strojový preklad
|
||||
- sumarizácia, conditional generation - asi nepotrebuje finetinung
|
||||
- konverzačné systémy - generovanie odpovede na otázku
|
||||
- generovanie otázok ku zadanému odseku (reverse squad)
|
||||
|
||||
Možné spôsoby vytvorenia overovacej množiny:
|
||||
|
||||
- Využitie slovenského squadu pre úlohu generovania otázok.
|
||||
- Strojový preklad existujúceho jazykového zdroja do slovenčiny.
|
||||
- Pokúsime sa vytvoriť vlastnú dátovú množinu od začiatku. Pre ktorú úlohu?
|
||||
- Na overenie použijeme existujúci paralelný korpus - to si vyžaduje fine-tuning pre strojový preklad.
|
||||
- Strojovo vytvoríme overovaciu databázu pre úlohu sumarizácie. Zoberieme novinové články alebo vedecké články alebo záverečné práce ktoré majú uvedený abstrakt.
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- vyskúšať menší GPT model
|
||||
- Zistit a stručne opísať, ako funguje automatické generovanie otázok vo formáte squad. Ako neurónka berie do úvahy odpoveď? Zisitiť ako vyznačiť zaujímavé časti odseku (NER, parser, sumarizácia..) - ako vygenerovať odpoveď.
|
||||
- Porozmýšľať, ako použiť na túto úlohu Transformers.
|
||||
|
||||
25.2.
|
||||
|
||||
- Vytvorený textový report, kde je urobený prehľad metód vyhodnotenia a niekoľkých testovacích korpusov a benchmarkov. Rouge je používaná metrika.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vypracovať prehľad generatívnych jazykových modelov
|
||||
- Vyskúšať slovenský GPT model.
|
||||
- Navrhnúť ako dotrénovať model na úlohu sumarizácie.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vytvoriť model pre generovanie faktických otázok ku zadanému paragrahu.. Môžeme využiť slovenský squad.
|
||||
- Vytvoriť model pre sumarizáciu novinových článkov.
|
||||
- Vytvoriť databázu pre vyhodnotenie generatívnych vlastností jazykového mo,delu.
|
||||
Napr. úloha sumarizácie alebo iná.
|
||||
|
||||
|
||||
|
||||
Stretnutie 27.1.2022
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Napísať prehľad spôsobov vyhodnotenia generatívnych modelov
|
||||
- Zostaviť prehľad metrík a dátových množin.
|
||||
- Zostaviť prehľad najnovších generatívnych modelov.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Zistiť niečo o algoritmoch GAN (generative adversarial network) a VAE (variational autoendoder).
|
||||
- Napíšte na aké NLP úlohy sa používajú a s akými výsledkami.
|
||||
- Zistite aké (optinálne) Python-Pytorch knižnice sa dajú použiť.
|
||||
|
||||
## Bakalárska práca 2020
|
||||
|
||||
|
||||
|
||||
201
pages/students/2019/alina_vitko/README.md
Normal file
@ -0,0 +1,201 @@
|
||||
---
|
||||
title: Alina Vitko
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [bp2022]
|
||||
tag: [ir,qa,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
rok začiatku štúdia: 2019
|
||||
|
||||
# Bakalárska práca 2022
|
||||
|
||||
Systémy pre generovanie odpovede na otázku v prirodzenom jazyku
|
||||
|
||||
|
||||
1. Vypracujte prehľad aktuálnych metód pre generovanie odpovede na otázku v prirodzenom jazyku.
|
||||
2. Vyberte a podrobne opíšte existujúci systém pre generovanie odpovede na otázku v prirodzenom slovenskom jazyku.
|
||||
3. Vytvorte demonštračnú webovú aplikáciu pre vybraný systém.
|
||||
4. Navrhnite zlepšenia systému pre generovanie odpovede.
|
||||
|
||||
Stretnutie 8.4.
|
||||
|
||||
Progres zatiaľ nenastal.
|
||||
|
||||
Úlohy platia z minulého stretnutia.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Študujte Python a Docker.
|
||||
- Pripravte nasadenie aplikácie pomocou systému Docker. Napíšte Dockerfile.
|
||||
- Napíšte vlastnú aplikáciu Streamlit alebo inej knižnice (pywebio, gradio).
|
||||
- Inšpirujte sa:
|
||||
- https://github.com/gradio-app/hub-bert-squad
|
||||
- https://www.mihaileric.com/posts/state-of-the-art-question-answering-streamlit-huggingface/
|
||||
|
||||
|
||||
|
||||
Stretnutie 17.1.2022
|
||||
|
||||
- Zmenené texty v demo aplikácii
|
||||
- Pridaná časť do textu práce
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Dokončiť demo slovenským modelom podľa minulých úloh.
|
||||
- pokračovať v písaní práce.
|
||||
|
||||
Stretnutie 28.1.
|
||||
|
||||
- Demo aplikácia funguje - vieme ju spustit aj nainstalovat.
|
||||
- Vytvorený repozitár so zdrojovými kódmi demo aplikácie https://git.kemt.fei.tuke.sk/dano/qademo
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Naklonujte si repozitár.
|
||||
- Získajte slovenský model a dajte ho do adresára models. Zistite, akého typu je slovenský model.
|
||||
- Modifikujte demo aplikáciu tak, aby pracovala so slovenským modelom.
|
||||
- Modifikujte demo aplikáciu tak aby bola "naša". Preložte ju, doplnte obrázky.
|
||||
- Oboznámte sa s knižnicou https://streamlit.io/
|
||||
- Do práce pridajte časť, kde podrobne opíšete ako funguje QA s použitím knižnite transformers. Napíšte o modeloch, ktoré budete prezentovať.
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Pripravte aplikáciu do podoby vhodnej na nasadenie. Vytvorte Dockerfile.
|
||||
|
||||
|
||||
|
||||
## Bakalársky projekt 2021
|
||||
|
||||
Vytovrenie prehľadu existujúcich systémov QA.
|
||||
|
||||
Stretnutie 17.12.2021
|
||||
|
||||
- Inštalácia funguje, ale spustenie nefunguje. Možný dôvod je to že to nie je kompatibilné s Windows. Alebo nastala chyba pri inštalácii.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Nainštalujte si WSL2 a Windows Terminal.
|
||||
- do ubuntu na wsl2 nainštalujte Anaconda for Linux.
|
||||
- Vyskúšajte to ešte raz do čistého prostredia anaconda. Staré zmažte.
|
||||
- Prejdite si knihu https://diveintopython3.net/
|
||||
- Pozrite si https://github.com/gerulata/slovakbert a prečítajte si článok na Arxiv. https://arxiv.org/abs/2109.15254 . Vytvorte si nové Anaconda prostredie a prejdite si tutoriál na tej stránke.
|
||||
|
||||
|
||||
|
||||
Stretnutie 10.12.2021
|
||||
|
||||
- Vyskúšané https://github.com/fastforwardlabs/question_answering, zatiaľ nefunguje.
|
||||
- Mierne vylepšené texty.
|
||||
|
||||
Úlohy:
|
||||
|
||||
Vyskúšajte nainštalovať https://github.com/facebookresearch/DrQA do virtuálneho priostredia Anaconda.
|
||||
|
||||
|
||||
Ako nainštalovať https://github.com/fastforwardlabs/question_answering:
|
||||
|
||||
Je potrebné mať nekoľko GB voľného miesta. Ak je Váš počítač pomalý, vytvorím Vám konto na školskom servri.
|
||||
|
||||
1. Aktivujte si prázdne prostredie Anaconda.
|
||||
|
||||
```
|
||||
conda create -m qa
|
||||
conda activate qa
|
||||
```
|
||||
|
||||
2. Nainštalujte Pytorch:
|
||||
|
||||
```
|
||||
conda install pytorch=1.6 torchvision torchaudio cpuonly -c pytorch
|
||||
```
|
||||
|
||||
3. naklonujte repozitár
|
||||
|
||||
```
|
||||
git clone https://github.com/fastforwardlabs/question_answering
|
||||
cd question_answering
|
||||
```
|
||||
|
||||
4. nainštalujte aplikáciu
|
||||
|
||||
```
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
5. Spustite web rozhranie
|
||||
|
||||
```
|
||||
streamlit run ./apps/wikiqa.py
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
Stretnutie 12.11.2021
|
||||
|
||||
- Pokračuje práca na texte
|
||||
- Nainštalovaná Anaconda
|
||||
- Začiatok Python Tutoriálu
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v práci na texte.
|
||||
- Pokračujte v Python Tutoriáli.
|
||||
- Prečítajte si blogy na https://qa.fastforwardlabs.com/ Vyskúšajte si, či Vám to pôjde v Anaconde.
|
||||
- Nainštalujte si HuggingFace transformers: https://huggingface.co/transformers/installation.html do Anacondy
|
||||
- Prejdite si tutoriál https://huggingface.co/transformers/training.html
|
||||
- Ak Vám to pôjde, prejdite si tutoriál https://github.com/huggingface/notebooks/blob/master/examples/question_answering.ipynb
|
||||
- Ak sa zaseknete, skúsime to vyriešiť na konzultácii.
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Nainštalujte a vyskúšajte toto: https://github.com/facebookresearch/DrQA
|
||||
|
||||
|
||||
Stretnutie 5.11.2021
|
||||
|
||||
- Splnené zadané úlohy z minulého týždňa, okrem nainštalovania
|
||||
|
||||
Stretnutie 28.10.2021
|
||||
|
||||
Stav:
|
||||
|
||||
Vypracovaný prehľad viacerých systémov QA a viacerých datasetov na QA.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Navrhnite niekoľko spôsobov prekladu výrazu question answering systems do slovenčiny.
|
||||
- napr. systémy odpovedania na otázku, systémy pre generovanie odpovede na otázku v prirodzenom jazyku.
|
||||
- Vyhľadajte tieto termíny na internete.
|
||||
- Nainštalujte a vyskúšajte vybraný systém
|
||||
- Doplňte odkazy na odborné články do textu práce.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Doplňte odkazy na zdroje, aj do textu.
|
||||
- [x] Doplňte teoretický úvod do QA.
|
||||
- [x] Dopíšte informácie o datasetoch SQUAD -1.0 a 2.0. a [MRQA](https://mrqa.github.io/2019/shared).
|
||||
- [x] Doplňte metodiku vyhodnotenia QA, napr. F1-precision-recall.
|
||||
- [ ] Vyberte jeden systém QA, skúste ho nainštalovať a vyskúšať tak ako je.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Nainštalujte si najprv balíček Anaconda.
|
||||
- Prejdite si knihu https://diveintopython3.net/
|
||||
|
||||
Stretnutie 15.10.2021
|
||||
|
||||
Stav:
|
||||
|
||||
- Začiatok písania prehľadu QA (nie hotový).
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vyberte min. dva odborné články alebo knihy a napíšte čo ste sa z nich dozvedeli o systémoch pre generovanie odpovede na otázku v prirodzenom jazyku, Napíšte bibliografické údaje o zdroji.
|
||||
- Webové stránky a blogy môžete tiež používať.
|
||||
- Nájdite a opíšte čo najviac QA systémov. Začať môžete systémom DRQA.
|
||||
|
||||
44
pages/students/2019/artem_yatsenko/README.md
Normal file
@ -0,0 +1,44 @@
|
||||
---
|
||||
title: Artem Yatsenko
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [bp2022]
|
||||
tag: [ner,spacy,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
Začiatok štúdia 2019
|
||||
|
||||
# Bakalárska práca 2022
|
||||
|
||||
Názov: Rozpoznávanie pomenovaných entít v slovenskom jazyku
|
||||
|
||||
Pomenované entity sú väčšinou vlastné podstatné mená v texte. Ich rozpoznanie nám pomôže určiť o čom text je. To sa často využíva v chatbotoch alebo vo vyhľadávaní v texte.
|
||||
|
||||
Návrh na zadanie:
|
||||
|
||||
1. Vypracujte prehľad metód pre rozpoznávanie pomenovaných entít v texte.
|
||||
2. Vyberte vhodnú metódu a natrénujte model pre rozpoznávanie pomenovaných entít.
|
||||
3. Vykonajte viacero experimentov a zistite s akými parametrami má model najvyššiu presnosť.
|
||||
4. Navrhnite ďalšie zlepšenia modelu pre rozpoznávanie pomenovaných entít.
|
||||
|
||||
Podobné práce:
|
||||
|
||||
- [Jakub Maruniak](/students/2016/jakub_maruniak)
|
||||
- [Martin Wencel](students/2018/martin_wencel)
|
||||
|
||||
# Bakalársky projekt 2021
|
||||
|
||||
- Zlepšite model pre rozpoznávanie pomenovaných entít.
|
||||
- Anotujte korpus, navrhnite lepší klasifikátor.
|
||||
|
||||
Stretnutie 30.9.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Prihláste sa na github.com, získajte prístup k repozitáru https://github.com/hladek/spacy-skmodel. Nainštalujte si prostredie, spustite trénovací skript. Budete potrebovať prostredie Anaconda. Môžete využiť svoj počítač, alebo školský server idoc.fei.tuke.sk (urobím prístup v prípade potreby).
|
||||
- Vyznačte niekoľko (min. 20 článkov) pomenovaných entít cez webové rozhranie https://zp.kemt.fei.tuke.sk/topics/named-entity/navod
|
||||
- Napíšte krátku správu o tom čo je to rozpoznávanie pomenovaných entít a ako sa robí. Napíšte z akých zdrojov ste čerpali.
|
||||
|
||||
|
||||
|
||||
@ -1,15 +1,208 @@
|
||||
# Dávid Stromp
|
||||
|
||||
---
|
||||
title: Dávid Stromp
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [bp2022]
|
||||
tag: [ir,cassandra,nlp,cluster]
|
||||
author: Maroš Harahus
|
||||
---
|
||||
Rok začiatku štúdia: 2019
|
||||
|
||||
## Bakalársky projekt 2021
|
||||
# Bakalárska práca 2022
|
||||
|
||||
Návrh na zadanie:
|
||||
|
||||
1. Vypracujte prehľad distribuovaných databáz alebo súborových systémov vhodných pre uloženie veľkého množstva textu.
|
||||
2. Vyberte vhodný spôsob uloženia veľkého množstva webových stránok.
|
||||
3. Nasaďte vybrané distribuované úložisko na testovací klaster pomocou systému Kubernetes.
|
||||
4. Vykonajte sadu testov pre overenia priepustnosti operácií zápisov a čítania.
|
||||
5. Identifikujte slabé miesta distribuovaného úložiska a navrhnite zlepšenia.
|
||||
|
||||
TO-DO na Diplomovku
|
||||
Cieľ práce:
|
||||
|
||||
- Zlepšiť proces získavania informácií
|
||||
- Implementovať algoritmus paralelného spracovania dokumentov v databáze Cassandra.
|
||||
- Implementovať algoritmus Page Rank alebo algoritmus jazykového modelu dokumentu.
|
||||
|
||||
## Bakalársky projekt 2021
|
||||
|
||||
Ciele:
|
||||
|
||||
- Vytvoriť nasadenie distribuovanej databázy na testovaci K8S klaster.
|
||||
-
|
||||
|
||||
22.8.2022
|
||||
- Praca skontrolovana pripravena na odovzdanie, treba este poriesit zadavaci list
|
||||
|
||||
|
||||
9.8.2022
|
||||
- Doplnene grafy z grafany do prace
|
||||
|
||||
8.8.2022
|
||||
- Skontrolovana praca pridane komentare
|
||||
- Student opravil chyby podla komentarov
|
||||
|
||||
3.8.2022
|
||||
- Poslana praca na kontrolu
|
||||
|
||||
1.8.2022
|
||||
- Prakticka cast hotova
|
||||
- Dohodnutie sa na pisani praktickej casti
|
||||
|
||||
25.7.2022
|
||||
- 1 Giga týka je takmer nemožné kedže je tam teraz 2 milióby entries ( zápis trval vyše 3 hodin a 2 razy mi plne spadlo spojenie ( preto usudzujem že celonočný zápis nebude veľmi účinný )) a má to len 50 Mb, hladal som softwárové riešenia ktoré by generovali veľké množstvo dát pre cassandru, avšak čo som našiel bolo len na normálnu cassandru a nie na k8ssandru bežiacu na kubernete
|
||||
|
||||
25.7.2022
|
||||
- Vytvoreni script na generovanie udajov
|
||||
- Skusanie scriptu
|
||||
- nainstalovana Grafana
|
||||
|
||||
|
||||
22.7.2022
|
||||
- Testovanie clustra prenasanie suborov atd
|
||||
|
||||
8.7.2022
|
||||
- Stretnutie čo dalej
|
||||
|
||||
2.6.2022
|
||||
- Presuvame pracu na September pretoze nestiahame pravit prenasany predmet
|
||||
|
||||
6.5.2022
|
||||
- Teoreticka praca skontrolovane subezne praca na praktickej casti
|
||||
|
||||
8.4.2022
|
||||
- Práca na teoretickej casti prace
|
||||
|
||||
|
||||
1.4.2022
|
||||
- Dohodli sme sa ze vynechame Page rank a budeme sa sustredit iba na distribuovane ulozisko
|
||||
|
||||
14.3.2022
|
||||
- Page rank implemetovany, beži ale nie v takej forme aku si prestavujeme
|
||||
|
||||
1.3.2022
|
||||
- Problem pri implementácii page ranku
|
||||
|
||||
22.2.2022
|
||||
- K8ssandra nainštalovaná na virtuálnych strojoch
|
||||
|
||||
15.2.2022
|
||||
- Kubernetes beží na virtualkach. Potreba nainštalovať ešte k8ssandru, dnes
|
||||
|
||||
14.2.2022
|
||||
- Vytvorené ďalšie 4 virtualky na UVT
|
||||
|
||||
10.2.2022
|
||||
- Vytvorená Virtualka na UVT
|
||||
|
||||
|
||||
Stretnutie 18.10.2021
|
||||
- Nahodený dashboard
|
||||
- Vygenerovaný token
|
||||
- Poslane prihlasovacie údaje
|
||||
|
||||
Stretnutie 22.10.2021
|
||||
- cassandra operátor zatiaľ nie je spojazdnený,
|
||||
- servicy nenabiehajú.
|
||||
- Pracuje sa na odstránení problému
|
||||
|
||||
Stretnutie 27.10.2021
|
||||
- Error standard_init_linux.go:228: exec user process caused: exec format error
|
||||
|
||||
|
||||
|
||||
Stretnutie 29.10.2021
|
||||
- Poslaný návod na k8ssandru
|
||||
- Snaha odstránení problému
|
||||
|
||||
|
||||
Stretnutie 8.11.2021
|
||||
- Na novo inštalácia k8s cluster
|
||||
- Vyskúšanie staršej verzie k8s
|
||||
prvý je ten že ten reaper operator s cass operatorom nesúvisí až tak úplne,
|
||||
a druhý je ten že aj keď staršia verzia k8ssandry opravila cass-operaotr, tak reaper-operator stále je v crashloope, takže to celé nefunguje,
|
||||
|
||||
Stretnutie 12.11.2021
|
||||
Poslaná teória
|
||||
|
||||
Stretnutie 28.11.2021
|
||||
- Prechod na virtulky virtual box
|
||||
|
||||
Stretnutie 3.12.2021
|
||||
- nechce fungovať DNS resolving,
|
||||
- pracuje s ana odstranieni problem
|
||||
|
||||
Stretnutie 4.12.2021
|
||||
- k8ssandra rozbehaná,
|
||||
|
||||
16.12.2021
|
||||
- Zhodnotenie výsledkom
|
||||
- Dohodnutie sa na teórii a odovzdaní
|
||||
|
||||
Stretnutie 19.01.2022
|
||||
- Uvažovanie o možnosti virtualizie na UVT
|
||||
- Ďalšie kroky
|
||||
|
||||
Stretnutie 23.1.2022
|
||||
- Písanie teórie
|
||||
- Poslanie prezentácie na pred obhajoby
|
||||
|
||||
|
||||
Stretnutie 15.10
|
||||
- Rozbehaný dashboard
|
||||
- Vytvorenie účtu
|
||||
- Pridanie ďalších raspberry pi
|
||||
- Predstavenie dashboardu
|
||||
|
||||
|
||||
Úlohy na ďalší týždeň:
|
||||
- Nainštalovanie Casasndry
|
||||
- Prepojenie s databázou
|
||||
|
||||
Stretnutie 08.10
|
||||
|
||||
- Preinštalovanie kubernetes
|
||||
- Nainštalovanie Casasndry
|
||||
- Spravená časť osnovy
|
||||
- Prepojenie s databázou
|
||||
|
||||
Úlohy na ďalší týždeň:
|
||||
|
||||
- Sfunkčnite k8s dashboard
|
||||
- Nainštalovať všetky potrebne veci
|
||||
|
||||
|
||||
Stretnutie 01.10.
|
||||
- Minikube funguje na vlastnom počítací
|
||||
- Pripravené relevantné poznámky k bakalárskej práci
|
||||
- Získaný prístup k RaspberryPi klastru
|
||||
|
||||
Úlohy na ďalší týždeň:
|
||||
- Sfunkčnite Casasndra operator (K8ssandra)
|
||||
- Sfunkčnite k8s dashboard
|
||||
- Naučte sa vkladať dáta do Cassandry a písať dotazy.
|
||||
- pošlite osnovu k bakalárskej práci a relevantný text (stačí aj v poznámkovom bloku)
|
||||
|
||||
|
||||
|
||||
Stretnutie 24.9.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Napíšte osnovu bakalárskej práce a pridajte do nej relevantné text čo máte.
|
||||
- Pripravte Casasndra operator - na začiatok na Vašom počítači. (napr. microk8s, minikube).
|
||||
- Dohodntite sa s Ing. Harahusom a získajte prístup ku RaspberryPi klastru.
|
||||
- Naučte sa vkladať dáta do Cassandry a písať dotazy.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Rozbehať crawler Websucker s Cassandrou.
|
||||
- Implementovať PageRank.
|
||||
- Napísať skript na indexovanie pomocou ElasticSearch.
|
||||
|
||||
|
||||
|
||||
Stretnutie 10.9.
|
||||
|
||||
Úlohy:
|
||||
@ -20,7 +213,3 @@ Stretnutie 10.9.
|
||||
- Naštudujte si článok http://ilpubs.stanford.edu:8090/422/ (Brin and Page). Zistite ako súvisí implementácia algorimtu PageRank s Cassandrou. Napíšte to do záznamu.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
42
pages/students/2019/dmytro_mural/README.md
Normal file
@ -0,0 +1,42 @@
|
||||
---
|
||||
title: Dmytro Mural
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [bp2022]
|
||||
tag: []
|
||||
author: Maroš Harahus
|
||||
---
|
||||
Rok začiatku štúdia: 2019
|
||||
|
||||
# Bakalárska práca 2022
|
||||
|
||||
Grafové neurónové siete pre vyhľadávanie na internete.
|
||||
|
||||
https://arxiv.org/abs/1810.05997
|
||||
|
||||
|
||||
Návrh na zadanie:
|
||||
|
||||
1. Vysvetlite čo je to grafová neurónová sieť
|
||||
2. Vypracujte prehľad najnovších druhov grafových neurónovýsh sietí.
|
||||
3. Vyberte jednu metódu grafových neurónových sietí a navrhnite spôsob experimentálneho ohodnotenia sady prepojených článkov pomocou grafovej neurónovej siete.
|
||||
4. Vyhodnnoťte experimenty a navrhnite zlepšenia Vášho prístupu.
|
||||
|
||||
|
||||
Cieľ práce:
|
||||
|
||||
Zlpešite metódy ohodnotenia prepojených ddkumentov na internete .
|
||||
|
||||
|
||||
|
||||
|
||||
## Bakalársky projekt 2021
|
||||
|
||||
Ciele:
|
||||
|
||||
Stretnutie 15.10
|
||||
|
||||
- Naštudovať si ako fungujú neurónové siete
|
||||
- Naštudovať ako fungujú grafové neurónové siete
|
||||
- Napísať rešerš
|
||||
|
||||
365
pages/students/2019/filip_tomas/README.md
Normal file
@ -0,0 +1,365 @@
|
||||
---
|
||||
title: Filip Tomáš
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [bp2022,dp2024,dp2025]
|
||||
tag: [testovanie,javascript,typescript]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
rok začiatku štúdia: 2019
|
||||
|
||||
|
||||
DP sa prekladá na rok 2025
|
||||
|
||||
# Diplomová práca 2024 - 2025
|
||||
|
||||
|
||||
Vektorové vyhľadávanie dokumentov v prostredí Kubernetes
|
||||
|
||||
Zadanie:
|
||||
|
||||
1. Napíšte prehľad metód vektorovej reprezentácie dokumentov pomocou neurónových sietí.
|
||||
2. Napíšte prehľad vektorových databáz a ich metód vyhľadávania.
|
||||
3. Nasaďte vybranú vektorovú databázu do testovacieho distribuovaného prostredia.
|
||||
4. Vytvorte index väčšieho množstva textových dokumentov vo vybranej vektorovej databáze.
|
||||
5. Vytvorte webové rozhranie na vyhľadávanie a slovne vyhodnoťte výsledky.
|
||||
|
||||
Ciel:
|
||||
|
||||
- Vytvorte distribuovaný vyhľadávací index pre dáta zo slovenského internetu. Cieľom je vytvoriť vyhľadávanie na (skoro) celom slovenskom internete.
|
||||
|
||||
Spolupráca Michal Stromko, Kristián Sopkovič. Huzenko
|
||||
|
||||
Stretnutie:
|
||||
|
||||
Stav:
|
||||
- Text je rozpísaný.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zlepšiť štruktúru práce
|
||||
|
||||
Stretnutie 10.3.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Zaindexovaná slovenská Wikipédia na servri QUADRO. Trvalo to niekoľko hodín na jednej karte - SlovakBERT.
|
||||
- Práca na texte.
|
||||
- RPI už funguje (2x reštart, problém s káblom).
|
||||
|
||||
Stretnutie 21.2.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Optimalizácia procesu indexovania - veľkosť dávky.
|
||||
- Treba reštartovať RPI Klaster.
|
||||
|
||||
|
||||
Stretnutie 17.1.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Pokus o indexovanie na Quadre, ale treba nainštalovať Anaconda pre závislosti.
|
||||
- Prezentácia.
|
||||
|
||||
|
||||
|
||||
Stretnutie 16.12.
|
||||
|
||||
- Vytvorený indexer
|
||||
- Vytvorené rozhranie vyhľadávania
|
||||
- Deployment Milvus.
|
||||
- Zatiaľ je indexovanie pomalé na domácej karte.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Dajte kódy na GIT.
|
||||
- Vyskúšajte indexovanie na servri QUADRO
|
||||
- Pracujte na textovej časti.
|
||||
|
||||
|
||||
Stretnutie 22.11.
|
||||
|
||||
Stav:
|
||||
|
||||
- Použitý HELM chart pre Milvus. Sú potrebné úpravy konfigurácie pre ARM - vymeniť Docker IMAGES.
|
||||
- PV je vyriešené.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Skripty aj konfiguráky dávajte na GIT.
|
||||
- Urobte skripty pre "prípravu" klastra.
|
||||
- Urobte skripty pre nasadenie Milvus na Klaster.
|
||||
- Pokračujte v písaní práce.
|
||||
|
||||
|
||||
Zásobík úloh:
|
||||
|
||||
- Keď to bude hotové, vyskúšajte skripty na DeskPI Super6C Klastri, p. Huzenko.
|
||||
- Urobte benchamark na Milvus deployment.
|
||||
- Naštudujte si Ansible a urobíte Ansible konfiguráciu microk8s.
|
||||
|
||||
|
||||
Stretnutie 7.11.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Riešenie problémov súvisiacich s PersistentVolume
|
||||
- Práca na texte
|
||||
|
||||
|
||||
|
||||
Stretnutie 15.10.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Rozpísaná práca
|
||||
- Príprava na nasadenie Milvus DB na RPI klaster.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Píšte prácu: Definuje úlohu. Napíšte súčasný stav. Predstavte naše riešenie. Vyhodnotte naše riešenie. Postupujte od všeobnecného ku konkrétnemu.
|
||||
- Pokračujte v práci na HW a SW.
|
||||
|
||||
Stretnutie 27.9.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Urobené vyhľadávanie Milvus, odstavce sú v sqlite.
|
||||
- Indexovanie je v osobitnom skripte.
|
||||
- Urobené web rozhranie pomocou Flask.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Na indexovanie používajte server quadro - 4 GPU karty 1080 12GB RAM. Prístup dá vedúci. Skript upravte tak, aby používal všetky 4 karty. Urobte meranie o koľko sa zrýchlylo spracovanie. Prihlásite sa ccez SSH `filip@quadro.kemt.fei.tuke.sk` . Server je dostupn7 iba cez VPN. Vytvoríte si prostredie Anaconda. Dlhý skript pustíte pomocou screen alebo tmux.
|
||||
- Na RPI klaster k8s urobte paralelný deployment Milvus a mongodb aj webové rozhranie.
|
||||
- Pokračujte v štúdiu LangChain.
|
||||
- Pokračujte v písaní - sentence transformers, retrieval augmented generation, distributed database.
|
||||
|
||||
Stretnutie 23.7.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Vytvorený jednoduchý index pomocou Milvus, indexovanie pomocou slovakbert-mnlr.
|
||||
- Zatiaľ slovakbert-mnlr vyzerá lepšie, ale treba to ešte vyskúšať.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte pri vytváraní indexu pomocou Milvus- slovakbert-mnlr. Snažte sa zindexovať celú wikipédiu. Indexujte na úrovni odstavcov. Na uloženie textu môžete použiť súborový systém (urobte si funkciu ktorá namapuje ID na meno súboru). Alebo na uloženie použite databázu. Napríklad minio alebo sqlite.
|
||||
- Skripty dávajte na GIT.
|
||||
- Oboznámte sa s knižnicou LangChain, začnite tu https://python.langchain.com/v0.2/docs/tutorials/retrievers/
|
||||
- robte si písomné poznámky. študujte vedecké články (napr. z Arxiv). Odkaz na článok si poznačte a zapíšte si čo sa v článku píše.
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- vyhľadávací systém môžete urobiť pomocou langchain alebo inej knižnice.
|
||||
- Pripravte deployment navrhnutého systému na k8s klaster.
|
||||
- skúste spustiť vyhľadávací systém na raspberry pi klastri.
|
||||
- zaindexujte slovenský internet.
|
||||
- Pripravte benchmark rýchlosti indexovania.
|
||||
- Pripravte webové rozhranie pre vyhľadávanie.
|
||||
|
||||
|
||||
Stretnutie 3.5.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Rozbehaný Milvus lokálne pomocou Docker.
|
||||
- Implementácia vyhľadávania pomocou Python.
|
||||
- Rozpracovaná príprava na Milvus RPI Klaster.
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Skúste zaindexovať slovenské dáta. Na vektorovú reprezentáciu použite https://huggingface.co/TUKE-DeutscheTelekom/slovakbert-skquad-mnlr
|
||||
- Na začiatok zaindexujte slovenskú wikipédiu. Sparsovaný text bol dodaný.
|
||||
- Napíšte o tom čo je to SentenceTransformer - ako sa trénuje a ako sa používa.
|
||||
- Pozrite si DP M. Stromko a K. Sopkovič.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Benchmarking vyhľadávania. Vyskúšame viacero embeddingov s rôznym rozmerom. Modely typu Matroshka.
|
||||
- Zhlukovanie dokumentov - zostavenie doménového korpusu s dát.
|
||||
- Dolovanie otázok a odpovedí.
|
||||
- Je priestor pre nákupy RPI pre nový RPI klaster.
|
||||
|
||||
Stretnutie 8.12.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Funguje microk8s RPI klaster. Aktivované HA.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vypracujte prehľad vektorových databáz. QDRANT, *MILVUS*, Weaviate, a iné. Opíšte ako funguje ich vyhľadávací index. Ako funguje tvorba a vyhľadávanie v distribuovanom indexe?. Citujte odborné články,
|
||||
- Pokračujte v úlohách: nasadte databázu, zaindexujte dokumenty a vypracujte webové rozhranie.
|
||||
|
||||
Stretnutie 10.11.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Teoretická príprava a tri strany poznámok.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Nasadte databázu Milvus na RPi. Vytvorte skripty na nasadenie pomocou Kubernetes. Zvážte možnosž použitia HELM alebo K8S Operátor.
|
||||
- Preštudujte si ako funguje distribuované nasadenie Milvus.
|
||||
- Zistitie si čo je K8S operator.
|
||||
- Zistite čo to je HELM.
|
||||
- Zisite ako nasadit Milvus pomocu Operator alebo pomocou HELM.
|
||||
- Skúste zaindexovať pár dokumentov.
|
||||
- Pokračujte v písaní práce.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vytvorte HTML rozhranie pre hybridné vyhľadávanie. Môžete využiť pomoc od Stromko-Sopkovič.
|
||||
|
||||
|
||||
Stretnutie 26.10.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Vypracovaný text na tému: Hardware RPI, kontajnerizácia, Čo je ingress. Paralelné spracovanie dát, o Kubernetes.
|
||||
- Na klastri sú nainštalované všetky potrebné nástroje: Multipass, k8s,
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Je potrebný Multipass na beh MicroK8s RPI klastra? Ak áno tak prečo. Ak nie tak to opravte.
|
||||
- [ ] Pozrite si profily Stromko, Sopkovič.
|
||||
- [x] Zistite, ako funguje "vektorové" vyhľadávanie pomocou neurónových sietí. Ako funguje SBERT-SentenceTransformer? Ako funguje vyhľadávanie BM25? Nájdite články a napíšte poznámky na 3 strany.
|
||||
- [x] Prečítajte si https://qdrant.tech/articles/hybrid-search/
|
||||
- [ ] Použite vektorovú databázu s podporou ukladania textu.
|
||||
- [x] Preskúmajte možnosti nasadenia QDRANT, *MILVUS*, Weaviate. Oboznámte sa s týmito databázami. Umožňujú hybridné vyhľadávanie? Vyberte jednu vhodnú na nasadenie v našich podmienkach. Mala by fungovať aj na RPI klastri, mala by podporovať aj hybridné vyhľadávanie.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Zaindexujte slovenský internet.
|
||||
- Pripravte jednoduché webové rozhranie pre vyhľadávanie na slovenskom internete.
|
||||
- Vykonajte záťažové testy pre indexovanie a vyhľadávanie.
|
||||
|
||||
|
||||
|
||||
|
||||
# Diplomový projekt 2023
|
||||
|
||||
Nápady:
|
||||
|
||||
- Zostaviť Raspberry Pi K8S Cluster pre podporu výuky predmetu ZKT. Chceme mať k dispozícii viacero fyzických uzlov, kde je možné spúštať rôzne aplikácie.
|
||||
- Klaster by malo byť jednoduché dať do východiskového stavu.
|
||||
- Klaster by mal mať aj podpornú infraštruktúru: Storage, Ingress, Registry, LoadBalancer.
|
||||
- Možno vytvoriť iný klaster pre skúštanie výukových alebo demonštračných aplikácií. Napr. JupyterLab, NLP demo pre GPU.
|
||||
- Preskúmať možnosti paralelného spracovania dát - Dask, SLURM, Spark,
|
||||
|
||||
|
||||
Stav:
|
||||
|
||||
- Podarilo sa nainštalovať a nasadiť Kubernetes klaster na raspberry PI
|
||||
- Bola vytvorená písomná správa
|
||||
- Skripty sú na https://git.kemt.fei.tuke.sk/ft835qr/dp2024
|
||||
- Výsledky boli odovzdané na poslednú chvíľu.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Oboznámte sa so systémom microk8s. Nainštalujte si ho a vyskúšajte.
|
||||
- Zistite čo je Ingress a ako si ho vytvoríme.
|
||||
- Zistite, aké storage podporuje microk8s a ako ho implementovať.
|
||||
- Navrhnite architektúru k8s klastra. Máme k dispozícii 5 jednotiek RPi4 s SD kartami. 1 jednotku Nvidia Jetson Xavier.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Namontovať klaster do serverovne a prideliť IP.
|
||||
- Rozbehať JupyterLab.
|
||||
|
||||
|
||||
# Bakalárska práca 2022
|
||||
|
||||
|
||||
Názov bakalárskej práce:
|
||||
|
||||
Aplikačné testy v systémoch kontinuálnej integrácie a nasadenia
|
||||
|
||||
Návrh na zadanie:
|
||||
|
||||
1. Vypracujte prehľad metód a nástrojov automatického testovania
|
||||
2. Vypracujte prehľad metód a nástrojov systémov kontinuálnej integrácie a nasadenia
|
||||
3. Vyberte vhodné metódy a pomocou systému Docker Compose nasaďte systém automatického testovania do vybraného systému kontinuálnej itengrácie a nasadenia.
|
||||
4. Vypracujte sadu aplikačných testov na vybranú webovú aplikáciu.
|
||||
5. Navrhnite zlepšenia systému spúšťania automatických testov.
|
||||
|
||||
Stretnutie 15.3.
|
||||
|
||||
- Podarilo sa implementovať GitLab CI CD pipeline s Cypress
|
||||
- Výsledky sú na https://git.kpi.fei.tuke.sk/filip.tomas/bp2022
|
||||
- Treba vedúcemu prideliť práva na čítanie.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pracujte na texte
|
||||
- Pokračujte v práci na otvorenyých úlohách.
|
||||
|
||||
Stretnutie 25.2.
|
||||
|
||||
- Fungujú automatické testy Cypress
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [ ] Vypracovať písomný prehľad CI CD systémov nasaditeľných pomocou Docker Compose.
|
||||
- [ ] Vybrať vhodný systém, optimálne taký, ktorý sa dá integrovať so systémov Gitea. https://gitea.com/gitea/awesome-gitea#user-content-devops
|
||||
- [ ] Pripravte deployment docker compose, kotrý bude obsahovať GITEA aj CI CD podľa výberu. Najčastejšie sa používa asi Jenkins.
|
||||
|
||||
Interakcia medzi Gitea a CI CD sa deje pomocou webhook. Riešenie pomocou GITlab je akceptovateľné, ale nie preferované.
|
||||
|
||||
# Bakalársky projekt 2021
|
||||
|
||||
Ciele:
|
||||
|
||||
1. [ ] Naučiť sa nasadiť a pracovať so systémom CI-CD. Vytvoriť pokusné nasadenie CI CD systému pomocou Docker compose. Môžete použiť [TUKE Cloud](https://cloud.tuke.sk/).
|
||||
2. [x] Vytvoriť automatické aplikačné testy ku aplikácii Traktor.
|
||||
3. [-] Vytvoriť kompletný reťazec CI-CD ku aplikácii Traktor. Automatický build a test, zobrazenie reportu.
|
||||
4. [-] Vypracovanie písomného prehľadu.
|
||||
|
||||
Stretnutie 10.12.2021
|
||||
|
||||
- Pripravený prvý reálny test, skladá sa z viacerých scenárov.
|
||||
- Práca na texte
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračovať s vytváraním testov
|
||||
- Pokračovať v práci na texte.
|
||||
- Rozbehať vlastný CI CD.
|
||||
|
||||
Práca na texte.
|
||||
|
||||
Úlohy: Pokračujte v otvorených úlohách
|
||||
- Napíšte čo je to testovanie a aké spôsoby testovania poznáme (aplikačné, použiteľnosti, jednotkové... ).
|
||||
|
||||
Stretnutie 22.10.
|
||||
|
||||
- Napísaný prvý draf s poznámkami o CI CD
|
||||
- pripravené prvé test-case
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v otvorených úlohách
|
||||
- Vytvorte GIT repozitár s názvom bp2022 a nahrajte do neho testovacie scenáre.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- [ ] Skúste vytvoriť nasadenie vhodného CI CD na tuke cloude.
|
||||
- [ ] Upravte scenáre tak, aby boli ľahko automaticky spustiteľné. vytvorte skript pre inštaláciu potrebných komponentov a pre spustenie testov.
|
||||
|
||||
|
||||
Stretnutie 23.9.
|
||||
|
||||
- Dohodli sme sa na zadaní, cieľoch a názve.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [ ] Urobte písomný prehľad systémov CI-CD. Uveďte zdroje z ktorých ste čerpali.
|
||||
- [ ] Nájdite vhodnú odbornú literatúru, uveďte ju do prehľadu. V školskej knižnici môže byť dobrá kniha.
|
||||
- [x] Navrhnite základné testovacie scenáre pre aplikáciu https://traktor.kemt.fei.tuke.sk.
|
||||
|
||||
|
||||
@ -1,23 +1,462 @@
|
||||
---
|
||||
title: Kristán Sopkovič
|
||||
title: Kristián Sopkovič
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [bp2022]
|
||||
category: [bp2022,dp2024]
|
||||
tag: [spacy,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
rok začiatku štúdia: 2019
|
||||
|
||||
# Dizertačná práca 2028
|
||||
|
||||
Cieľ:
|
||||
|
||||
- Vylepšiť RAG-QA v slovenskom jazyku.
|
||||
|
||||
Stretnutie 6.11.2024
|
||||
|
||||
Kritériá na rok 24-25:
|
||||
|
||||
- Získať min. 40 bodov za publikácie podľa [tabuľky](https://www.fei.tuke.sk/uploads/1d/fa/1dfad875721c7e707dbe9c1f93f327b3/2022_Zasady_PhD_studia_TUKE_uplne_znenie_po_D1_web.pdf) dole.
|
||||
|
||||
Plán na publikácie - povinná jazda:
|
||||
|
||||
- SCYR 8B
|
||||
- [RADIOELEKTRONIKA 2025 15](https://radioelektronika.uniza.sk/home.php?id_conference=28)
|
||||
- RADIOELEKTRONIKA 2025 15 (Eva Kupcová)
|
||||
- V prípade núdze [EEI](https://eei.fei.tuke.sk/deadlines/) alebo [AEI](https://www.aei.tuke.sk/index.html). Tam sa dajú uverejniť aj výsledky záverečných prác.
|
||||
|
||||
Ďalšie "jednoduché" konferencie kde zvykneme chodiť:
|
||||
|
||||
- ELMAR
|
||||
- SAMI
|
||||
- CINTI
|
||||
- ICETA
|
||||
- ITAT
|
||||
|
||||
Treba overiť konkrétny termín "uzávierky" hodnotenia doktoranda.
|
||||
|
||||
Plán na publikácie - Conference our level:
|
||||
|
||||
- Slovko (výstup ide do Jaz. časopisu)
|
||||
- TSD 2025
|
||||
- LREC-COLING 2026 konferencia.
|
||||
|
||||
Plán na publikácie - Journal our level:
|
||||
|
||||
- Jazykovedný časopis, má dobré hodnotenie (Scopus Q2-eq. WOS Q3)
|
||||
- IEEE Access Q2
|
||||
- PeerJ Computer Science Q2
|
||||
- Pattern Recognition Q2
|
||||
- Nature Scienfic Reports Q2
|
||||
- Language Resources and Evaluation Q3
|
||||
- Natural Language Processing (Journal) asi Q3
|
||||
|
||||
|
||||
Plán na publikácie - Cream de la Creme:
|
||||
|
||||
- INTERSPPECH
|
||||
- ENLP alebo iná ACL konferencia
|
||||
|
||||
Stretnutie 21.6.
|
||||
|
||||
Nápady na tému DP:
|
||||
|
||||
- Agentový prístup k získavaniu informácií. Agent vie iniciatívne získať ďalšie potrebné informácie pre splnenie cieľa získavania informácií.
|
||||
- Grafová reprezentácia informácie - vyhľadávanie v štruktúrovaných, prepojených dokumenotch.
|
||||
- Zlepšenie modelov vektorovej reprezentácie.
|
||||
- Tvorba nových "základných" generatívnych modelov.
|
||||
|
||||
# Diplomová práca 2024
|
||||
|
||||
Neurónové vyhľadávanie na základe sémantickej podobnosti vektorov.
|
||||
|
||||
1. Vypracujte prehľad metód neurónovej vektorovej reprezentácie viet alebo odsekov.
|
||||
1. Pripravte trénovaciu množinu a natrénujte model vektorovej reprezentácie dokumentov.
|
||||
1. Vyhodnoťte natrénovaný model vo viacerých experimentoch.
|
||||
1. Identifikujte slabé miesta modelu a navrhnite jeho zlepšenia.
|
||||
|
||||
Zadanie sa ešte môže zmeniť.
|
||||
|
||||
|
||||
Súvisiace práce: Michal Stromko
|
||||
|
||||
Cieľ je zlepšiť slovenské vyhľadávanie pomocou neurónových sietí.
|
||||
|
||||
Námety na tému:
|
||||
|
||||
- Natrénujte alebo dotrénujte Sentence Transformer Model, alebo iný model pre sémantícké vyhľadávanie. Aké sú potrebné databázy? Je možné dotrénovať *multilinguálny model*?
|
||||
- Vytvorte databázu pre trénovanie SBERT. Strojový preklad, existujúcej NLI databázy, Semantic Textual Similarity databázy. Alebo ak získame grant, tak vytvoríme "originálnu" (klon) slovenskú databázu.
|
||||
- Vytvorte kognitívne vyhľadávanie pre mesto Košice
|
||||
|
||||
[Slovak Semantic Textual Similarity Benchmark](https://huggingface.co/datasets/crabz/stsb-sk)
|
||||
na trénovanie Sentence Transformer
|
||||
|
||||
|
||||
## Diplomový projekt 2
|
||||
|
||||
|
||||
Stretnutie 1.3.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Práca na teórii
|
||||
- Preskúmané modifikátory stratovej funkcie - Matrioshka embedding. Metóda zníženia dimenzie embeddingov.
|
||||
- Porovnané slovenská (preložená) SNLI-sk a STSB-sk. e5 small model (374dim) MNLR plus loss modifier a matrioshka LOSS.
|
||||
|
||||
|
||||
|
||||
|
||||
Stretnutie 29.1.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Príprava prezentácie.
|
||||
- Natrénované viacerá MNLR modely a vyhodnotené na SK QUAD, zostavená tabuľka s výsledkami. Najlepšie vychýdza dotrénovaný e5 model, SlovakBERT dotrénovaný je 2. najlepší. Na dotrénovanie boli použíté preložené SNLI dáta.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Stretnutie 15.12.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Lepšie preložená databáza (Azure) SNLI a STSB-SK (pôvodne preložená cez OPUS).
|
||||
- Natrénovaný Bi Encoder (SNLI) aj Cross Encoder (STSB) zo SlovakBERT a E5.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vyhoddnotte natrénované modely a výsledky sumarizujte v dip. práci. Môžete použit slovenský dataset od M Stromka keď bude.
|
||||
- Datasety a modely nahrajte na HF HUB, zatiaľ privátne. TUKE-DeutscheTelekom ORG. Zistite vo firme podmienky zverejnenia.
|
||||
- Po Novom roku dodajte draft DP.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Porozmýšľajte nad článkom.
|
||||
|
||||
|
||||
Stretnutie 3.11.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Sú spracované ďalšie dáta o službách z Magistrátu Košíc.
|
||||
- Dotrénovanie multilinguálnych modelov na NLI databázach. MNLR loss. Model E5 a varianty. Batch size by mala byť najmenej 256. LR na finetuning je E-5. Preto je možné pracovať iba so SMALL model. Max seq. len bol orezaný na 256 z 512 aby to išlo na 1x24 GB Titan.
|
||||
- SIMSCE prístup na trénovanie pomocou MNLR, je SOTA. Koher reranker je tiež SOTA, ale je komerčný.
|
||||
- Pokračujeme v minulých úlohách.
|
||||
- Evaluačná množina SK QUAD bola preložená do nemčiny a angličtiny.
|
||||
- Mistrail LLM model natrénovaný na európskych jazykoch.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Chceme dotrénovať E5 model na anglickom, nemeckom a slovenskom SNLI pre úlohu kros linguálneho IR. Vyhodnocovať budeme na SQUADE anglickom, nemeckom a slovenskom jazyku.
|
||||
- Pokračujte v písaní diplomovej práce. Pripravte si osnovu a ku každej časti napíšte čo by v nej malo byť. Udržiavajte si zoznam použitej literatúry. Poznačte si bib. údaje o článkoch a knihách z ktorých čerpáte, priradte kódy jednotlivým záznamom.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Výsledky budeme demonštrovať na košických dátach.
|
||||
|
||||
|
||||
Stretnutie 13.10.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Spracované dáta z mesta Košice - 110 najčastejších otázok a odpovedí.
|
||||
- Nasadená 13B ChatLLama na Titan, 4 bit kvantizácia.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Chceme vytvoriť model pre cross-lingual information retrieval. Model bude vedieť vytvoriť "vyhľadávací embedding" pre texty a otázky vo viacerých jazykoch.
|
||||
- Na základe dostupných dát natrénujte takýto model. K dispozícii máme preloženú Slovak NLI, Anglickú NLI. Určite existujú aj iné jazyky. Zoberte viacero NLI databáz a dotrénujte z nich multilinguálny model. Aký model je najlepší ako "základ"? Možno multilinguálne SBERT: E5, mpnet, miniLM.
|
||||
- Model vyhodndotte na dostupných databázach.
|
||||
- Prečítajte si viacero nových článkov na tému "mutlilingual alebo crosslingual" "information retrieval" "document embeddings". Urobte si poznámky do DP.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Košické dáta je možné využiť pri vyhdonotení.
|
||||
- Možno dáta na vyhodnotenie slovenského IR vytvorí aj M. Stromko.
|
||||
- Pripraviť API na ChatLLAma.
|
||||
|
||||
Stretnutie 28.9.20023
|
||||
|
||||
Stav:
|
||||
|
||||
- Vieme pracovať - natrénovať SBERT (Sentence Transformer).
|
||||
- Je strojovo preložená SNLI databáza pomocou Marian NMT setup.
|
||||
|
||||
Nápady:
|
||||
|
||||
- Získať dáta-dokumenty z webovej stránky mesta Košice.
|
||||
- Získať informácie z webovej stránky https://www.esluzbykosice.sk/
|
||||
- Spracovať dáta o často kladených otázkach, ktoré sme dostali z mesta Košice.
|
||||
- Spracovať dáta o agende, ktoré sme dostali z mesta Košice.
|
||||
- Vytvoriť ku týmto dátam "asistenta" pre získavanie informácí.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [-] Porozmýšľať ktorú časť problému "pomoci občanom mesta Košice" by sme mohli riešiť.
|
||||
- [-] Spracujte dodané dáta od mesta Košice (vedúci pripraví a pošle).
|
||||
- [ ] Dáta zaindexujte a pripravte jednoduché vyhľadávanie.
|
||||
- [ ] Pokračujte v písomnej teoretickej príprave na tému "Sentence Transformers".
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Pripravte scraper na dáta od mesta Košice.
|
||||
|
||||
|
||||
|
||||
## Diplomový projekt 1
|
||||
|
||||
Stretnutie 2.6.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Natrénovaný IR retriever
|
||||
- Natrénovaný model pre generatívne odpovede na báze Slovak T5 Small.
|
||||
- Práca na texte
|
||||
|
||||
Stretnutie 25.5.
|
||||
|
||||
Stav:
|
||||
|
||||
- Trénovanie MNLR nebolo v poriadku, lebo boli použité iba kladné príklady.
|
||||
|
||||
Úloha:
|
||||
|
||||
- Natrénovať model SNLI. Natrénovať iný model STSB.
|
||||
- Porovnajte ich ako cross-encoder. Vyhodnoťte recall vyhľadávania na databáze sk-quad.
|
||||
- Porovnajte to so základným modelom mnlr sk quad.
|
||||
- Skúste oba modely dotrénovať na MNLR skquad a vyhodnotiť.
|
||||
- pracujte na písomnej časti.
|
||||
|
||||
|
||||
Stretnutie 5.5.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Natrénovaný model MNLR SlovakBERT na preloženej databáze Standformd SNLI.st.: tot je asi zle
|
||||
- Urobnené predbežné vyhodnotenie - analýza strednej hodnoty kosínusovej podobnosti pre triedy entailment, contradiction, neutral.
|
||||
- Výsledkom MNLR je kosínusové podobnisť.
|
||||
- Urobené aj softmax trénovanie. Výsledkom softmax je trieda pre 2 zadané vety.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Upravte a dajte trénovacie skripty na GIT.
|
||||
- Vyhodnotiť presnosť klasifikácie softmax pomocou konfúznej matice - p,r,f1
|
||||
- Dotrénovať SNLI ST na SK Quad a vyhodnotiť na úlohe sémantického vyhľadávania. - recall. To tj e zlá úloha.
|
||||
- Pracujte na písomnej správe, ktorá poslúži ako základ pre DP a pre článok. Do textu opíšte trénovanie ktoré ste vykonali, postup pri preklade, návrh experimentov a výsledky. Do teoretickej časti píšte o sentence transformeroch.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Cieľom je poblikovať kvalitný článok.
|
||||
- Cieľ 2 je aplikovať model pre úlohu vyhonotenia súladu staevebnej dokumentácie so regulatívou - zákonmi a vyhláškami.
|
||||
- Využijeme databázu STSB-sk (na hf hube) ako ďalší zdroj dát
|
||||
- Pripravte porovnávacie experimenty pre anglické datasety.
|
||||
- Do ďalších experimentov zahrňte multilinguálne modely.
|
||||
|
||||
Stretnutie 24.4.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Preložené SNLI - všetky 3 časti.
|
||||
|
||||
|
||||
Stretnutie 17.3.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Je preložená SNLI databáza, trénovacia časť. Použitý OPUS Helsinki NLP model
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Preložiť aj testovaciu časť.
|
||||
- Natrénovať Sentence Transforner (ST) na databáze SNLI, podľa SlovakBERT.
|
||||
- Dotrénovať SNLI ST na SK Quad a vyhodnotiť na úlohe sémantického vyhľadávania. - recall
|
||||
- Podobným spôsobom vyhodnotiť Slovakbert-stsb.
|
||||
- Napíšte o tom čo je to ST, ako funguje. Pripravte prehľad databáz na trénovanie ST.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Porovnať s slovakbert-crossencoder na tuke-dtss modelmm.
|
||||
|
||||
Stretnutie 17.2.2023
|
||||
|
||||
Úlohy
|
||||
|
||||
- Zoberte existujúci model SlovakBERT-stsb a použite ho na dotrénovanie bi-encódera na databáze SK quad. Porovnajte presnosť vyhľadávania s bi-encóderom natrénovaným iba na SlovakBERT (dodá vedúci). Použite skripty v repozitári slovak-retrieval.
|
||||
- Urobte prehľad databáz potrebných na dotrénovanie Sentence Transformer. Vyberte vhodnú databázu na strojový preklad, napr. nejakú NLI databázu. Použite ju na dotrénovanie bi-encódera.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Zistite ako využiť slovenský generatívny model pre sémantické vyhľadávnaie. Pripravte experiment a vyhodnotte ho.
|
||||
- Vyberte databázu pre sémantické vyhľadávanie alebo question answering na vhodnú na vytvorenie slovenského klonu.
|
||||
|
||||
|
||||
Stretnutie 24.11.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Porozmýľať ďalej o téme, komuikovať o možnom grante na anotáciu.
|
||||
- Vyskúšajte [Sentence Transformers framework](https://github.com/UKPLab/sentence-transformers/tree/master/examples). Pozrite si príklady, ako trénovať.
|
||||
- Prečítajte si článok https://arxiv.org/abs/1908.10084.
|
||||
- Zistite, čo je Natural Language Inference, aké sú dostupné databázy.
|
||||
- Zistite, čo je Semantic Textual Similarity, aké sú dostupné databázy.
|
||||
- Pozrite si https://git.kemt.fei.tuke.sk/dano/slovakretrieval/
|
||||
|
||||
# Bakalárska práca 2022
|
||||
|
||||
Návrh na názov bakalárkej práce:
|
||||
|
||||
Model Spacy pre spracovanie prirodzeného jazyka v slovenčine
|
||||
Model Spacy pre spracovanie prirodzeného jazyka v slovenčine
|
||||
|
||||
Ciele bakalárskej práce:
|
||||
|
||||
- Zlepšiť presnosť modelu Spacy pre slovenčinu
|
||||
|
||||
|
||||
Zadanie:
|
||||
|
||||
1. Zistite ako pracuje knižnica Spacy a opíšte metódy ktoré používa.
|
||||
2. Natrénujte model pre spracovanie slovenského prirodzeného jazyka.
|
||||
3. Vykonajte viacero experimentov a zistite presnosť pri rôznych parametroch.
|
||||
4. Identifikujte slabé miesta a zlepšite presnosť spracovania.
|
||||
|
||||
25.3.2022
|
||||
|
||||
- Zopakované trénovanie POS aj NER
|
||||
- Zisitili sme, že keď sa NER trénuje osobitne bez POS tak dáva lepšie výsledky. Prečo?
|
||||
- konfiguračné súbory sú na githube. malý nepoužíva slovné vektory, stredný používa 200000 ti. slov vektorov.
|
||||
- uncased multilingual bert vychadza lepsie ako cased.
|
||||
- v konfiguácii sú fasattext slovné vektory aj multilingualbert uncased. Používajú sa slovné vektory pri klasifikácii???
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zosumarizovať výsledky experimentov do písomneč časti
|
||||
- Finalizovať BP - na ďalšom stretnutí prejdeme spolu draft.
|
||||
- Pripraviť skripty na natrenovanie modelov na verejnú distribúciu.
|
||||
|
||||
|
||||
4.3. 2022
|
||||
|
||||
- Natrénované NER modely Spacy Transformers, výsledky sú na wandb
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [ ] Pripraviť modely (návody na trénovanie) na verejnú distribúciu.
|
||||
- [x] Natrénovať menšie modely bez slovných vektorov.
|
||||
- [-] Pokračovať v písaní.
|
||||
- [x] Vytvoriť rozhranie pre využitie modelov huggingface ,modelov slovakbert. Využiť spacy-transformers alebo spacy-sentence-transformers.
|
||||
- [x] Na githube vytvorte fork alebo branch repozitára, dajte mi prístup. tam bude pracovná verzia s novými modelmi.
|
||||
|
||||
25.2.2022
|
||||
|
||||
- Vyskúšané experimenty s hyperparametrami s pôvodnou architektúrou POS modelu.
|
||||
- Zmenená architektúra POS na Spacy Transformer (bez BERT predtrénovania, využíva slovné vektory). Dosiahnuté zlepšenie POS z 0.8 na 0,9. Výsledky sú vo forme grafu dostupné na wandb
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zdieľať wandb projekt,
|
||||
- Vyskúšať transformers architektúru na NER model.
|
||||
- Vyskúšať BERT architektúry - MultilingualBERT, SlovakBERT, LABSE, Slovak GPT
|
||||
- Pracujte na texte
|
||||
|
||||
|
||||
## Bakalársky projekt 2021
|
||||
|
||||
|
||||
18.2.2022
|
||||
|
||||
- Na idoc je problém s timeout pri zostaení pip balíčka, ale funguje trénovanie spacy pos
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Zatiaľ sa sústrediť na POS model čo funguje.
|
||||
- [x] Do týždňa opraviť idoc (pre vedúceho).
|
||||
|
||||
|
||||
7.2.2022
|
||||
|
||||
- Rozbehaný trénovací skript na vlastnom počítači
|
||||
- Spustených niekoľko experimentov.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Pokračujte v otvorených úlohách.
|
||||
- [x] Výsledky experimentov dajte do tabuľky do práce.
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- [x] Skúste použiť logovací nástroj https://docs.wandb.ai/guides/integrations/spacy
|
||||
- [x] Skúste rozbehať trénovacie skripty na školskom servri. Problémy vytriešime na konzultácii.
|
||||
|
||||
26.11. 2021
|
||||
|
||||
- Absolvovaný kurz Explosion https://course.spacy.io/en/
|
||||
- Mierne zlepšený text práce.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Vytvorte GIT a vložte do neho svoje trénovacie skritpy. Nedávajte tam veľké textové súbory. Dajte odkazy odkiaľ ste získali dáta. Celý proces by mal byť opakovateľný,
|
||||
- [x] Skúste zlepšiť hyperparametre môjho trénovacieho skriptu spacy3
|
||||
- [ ] Skúste pridať MultilingualBert do trénovania.
|
||||
- [ ] Pokračujte v práci na textovej časti.
|
||||
- [x] Vytvorené modely je potrebné vyhodnotiť. Pozrite ako to je v mojom Spacy repozitári.
|
||||
|
||||
|
||||
Zápis 21.10.
|
||||
|
||||
Vyskúšať toto:
|
||||
|
||||
- [MultilingualBert](https://github.com/google-research/bert/blob/master/multilingual.md). Dá sa adaptovať na Slovak Treebank.
|
||||
- [Spacy Transformers](https://spacy.io/universe/project/spacy-transformers)
|
||||
|
||||
Stretnutie 15.10.
|
||||
|
||||
Stav:
|
||||
|
||||
- Rozpracovaná kapitola o Spacy
|
||||
- Pokusné trénovanie HuggingFace v Pytorch
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračovať v otvorených úlohách.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Aplikovať model BERT do Spacy Pipeline.
|
||||
|
||||
Stretnutie 1.10
|
||||
|
||||
Stav:
|
||||
|
||||
- Vypracovaných asi 8 strán osnovy
|
||||
- Preštudované Transformery a Spacy
|
||||
- Vyskúšané trénovanie Pytorch
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pripravte si prostredie Anaconda a v ňom spustite trénovanie.
|
||||
- Pokračovať v otvorených úlohách.
|
||||
|
||||
Stretnutie 24.9.2021
|
||||
|
||||
Stav:
|
||||
|
||||
- Naštudovaná knižnica Spacy - pozreté tutoriály
|
||||
- Vytvorený prístup na idoc
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Spustite trénovanie podľa skriptov na githube. Môžete použiť server idoc.
|
||||
- Skúste napísať osnovu BP práce.
|
||||
- Nájdite odborný článok na tému "Transformer neural network" a do BP napíšte čo ste sa dozvedeli.
|
||||
- Stručne napíšte čo je to knižnica Spacy a ako pracuje. Citujte aspoň jeden odborný článok.
|
||||
- Zistite ako by sa dal zlepšiť proces trénovania.
|
||||
|
||||
|
||||
Stretnutie 25.6.2021
|
||||
|
||||
- Vytvorený prístup do repozitára spacy-skmodel na GIThube
|
||||
|
||||
@ -2,13 +2,521 @@
|
||||
title: Michal Stromko
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [vp2021]
|
||||
category: [vp2021,bp2022,dp2024]
|
||||
tag: [ir,cloud,demo,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
rok začiatku štúdia: 2019
|
||||
|
||||
# Diplomová práca 2023/24
|
||||
|
||||
Sémantické vyhľadávanie v slovenskom texte
|
||||
|
||||
|
||||
Zadanie práce:
|
||||
|
||||
1. Vypracujte prehľad najnovších metód sémantického vyhľadávania pomocou neurónových sietí.
|
||||
2. Implementujte sémantické vyhľadávanie na slovenskej wikipédii pomocou existujúcich modelov.
|
||||
2. Vyberte dátovú množinu otázok a odpovedí a ručne anotujte výsledky sémantického vyhľadávania.
|
||||
3. Pripravte, vykonajte a opíšte experimenty na vyhodnotenie vyhľadávania pomocou Vami ručne vytvorenej množiny.
|
||||
4. Vyhodnoťte experimenty a identifikujte slabé miesta a navrhnite zlepšenia.
|
||||
|
||||
Ciele DP:
|
||||
|
||||
- Bolo by fajn, keby z DP bol vedecký článok.
|
||||
- Dotrénovať slovenský ST model.
|
||||
- Porovnať viacero metód na vyhľadávanie v slovenskom texte - BM25, TF IDF, WordEmbedding, SentenceTransformers, Alebo iné embeddingy.
|
||||
|
||||
|
||||
Stretnutie 6.3.
|
||||
|
||||
- Hotová anotácia 1134 otázok, ku každej je 20 odpovedí v 5 kategóriách.
|
||||
- Hotové vyhodnotenie modelu Slovakbert-mnlr, metriky recall, MRR, MAP, NDCG. Model je "podpriemerný".
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [ ]Dokončiť text DP, asi bude treba niektoré časti skrátiť.
|
||||
- [ ] Nájsť podobnú databázu. STSB je podobná, ale možno iná je podobnejšia.
|
||||
- [x] Spraviť nový dockerfile pre vyhľadávacie demo.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Pripraviť databázy do kompletnej podoby pre uverejnenie. Na jedno miesto dať všetky potrebné súbory, vrátane sk quad.
|
||||
- Databázu treba dať do podoby, aby bola kompatibilná s inými vyhodnocovacími skriptami.
|
||||
- Pripraviť vlastný vyhodnocovací skript. 1. vstup sú výsledky z vyhľadávania (predicted), druhé sú pravdivé výsledky (gold, actual). Výstupom sú hodnoty metrík v JSON.
|
||||
- * Napísať článok, zverejniť databázu *. Zvážiť spoločný článok s Kristiánom S.
|
||||
|
||||
|
||||
Stretnutie 16.2.
|
||||
|
||||
Stav:
|
||||
|
||||
- Dokončená teoretická časť DP.
|
||||
- Dokončená aplikácia "Vyhľadávanie na slovenskej wikipédii". Treba ešte dorobiť Dockerfile.
|
||||
- Začatá práca na kapitole - Tvorba korpusu pre vyhodnotenie sémantického vyhľadávania.
|
||||
- Treba urobiť ešte vyhodnotenie na modeli Slovakbert-mnlr. Porovnanie s bm25 baseline, aj hybrid.
|
||||
|
||||
|
||||
# Diplomový projekt 2
|
||||
|
||||
Stretnutie 30.11.20
|
||||
|
||||
Stav:
|
||||
|
||||
- Rozrobený text
|
||||
- Anotovaných cca 1000 dokumentov
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Skúsiť experimenty
|
||||
- Pokračovať v anotáciách
|
||||
- Pokračovať v písaní textu.
|
||||
|
||||
|
||||
Stretnutie 9.11. 2023
|
||||
|
||||
Stav - urobené úlohy:
|
||||
- Je anotovaných cca 240 otázok, ku každej cca 20 dokumentov
|
||||
- [x] Pridať kódy na Git
|
||||
- [x] Napísať návod pre anotovanie
|
||||
- [x] Spaviť jednu stránku pre vypísanie počtu už anotovaných otázok z danej sady
|
||||
- [x] Pridať do indexu search, každému kontextu ID
|
||||
- [x] Pri vyhľadávaní sprrávnych odpovedí uložiť uložiť tak, aby bol súbor odpovede, ktorý bude mať parametere id_odpovede a k nemu priradený text odpovede
|
||||
- [x] Rozdelenie anotačného datasetu na sady (anotačné sady je ich 8)
|
||||
- [x] Zamiešanie správnych odpovedí okrem odpovede zo skquad tá je na index = 0 vždy
|
||||
- [x] Prerobiť anotačnú aplikáciu tak, aby mala po anotovaní štruktúru id správnej odpovede a kategóriu.
|
||||
- [x] Pri anotovaní budem ťahať z id odpovede presný text z toho datasetu
|
||||
- [x] Anotovacie kategórie: sú na gite skwiki
|
||||
- [x] Zapísať nové veci a poznámky do Mira
|
||||
- [x] Zmeniť v Mire štruktúru anotačného aj finálneho datasetu
|
||||
- [x] Opovedí môže byť rôzne množstvo nie iba po jednej odpove
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračovať v anotácia prvých a druhých 1000 otázok
|
||||
- Pripraviť experimenty pre vyhodnotenie presnosti s novými dátami
|
||||
- Pokračovať v písaní.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Zvážiť indexovať kratšie kontexty. Nevýhody: vznikne neporiadok. Výhody: Môže sa urýchliť práca anotátorov.
|
||||
- Zvážiť nasadenie, úpravu django appky a anotovať s náhodnými študentami.
|
||||
|
||||
|
||||
Stretnutie 2.11.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Prvá verzia anotačnej aplikácie v Streamlit
|
||||
- Pripravené dáta na anotovanie.
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Prideliť ID pre kontexty a pridať ich do indexu.
|
||||
- Upraviť rozhranie. Defaultná položka je 0 - "nevidel som - ignoroval som". Premenovať ostatné kategórie na "Nevidel som", "Neviem","Relevantné", "Slabo relevantné", "Nerelevantné". Kontext zo SQUAD bude 1, neviditeľný pre antátorov.
|
||||
- Premiešať 20 najlepších odpovedí.
|
||||
- Pracujte na texte DP - robte si poznámky z článkov o metrikách vyhodnotenia.
|
||||
|
||||
|
||||
Stretnutie 26.10.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Urobený preskum dostupných databáz na vyhodnotenie IR.
|
||||
- Prípravený plán na tvorbu databázy. Zoberieme otázky zo SK QUAD a ku nim vyhľadáme 20 najlepších paragrafov z celej wikipédie 2023. Kategória 1 budú kontexty zo SKQUAD. Kategória 2 budú iné správne kontexty. Kategória 3 budú čiastočne správne. Kategória 4 budú nesprávne kontexty. Na vyhľadávanie použijeme aktuálny demo systém.
|
||||
Zatiaľ sa nebude robiť kros validácia.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pripravte anotačné prostredie na báze Streamlit. Otázky berte podľa poradia v poslednej verzii SKQUAD databázy. Anotujte čo najviac otázok. Ku každej otázke bude 20 dokumentov.
|
||||
- Urobte prehľad článkov, ktoré anotujú databázu podobným spôsobom.
|
||||
- Anotovať aj "nezodpovedateľné" otázky. Zodpovedajúci "nesprávny" kontext so SKQUAD bude kategória 5.
|
||||
- Kontexty zo SQUADU by nemali byť v indexe. Doplníme ich neskôr. Bude potrebné ich identifikovať vo nájdených kontextoch, lebo sa môžu mierne líšiť.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Zvážiť strojový preklad vybranej databázy a ich porovnanie.
|
||||
- Čo urobiť s kontextami zo SKQUAD vo Wiki2023 - vyznačiť?
|
||||
|
||||
|
||||
Stretnutie 5.10.2023
|
||||
|
||||
Nápad:
|
||||
|
||||
- Vytvoriť novú databázu pre vyhodnotenie získavania informácií v slovenskom jazyku.
|
||||
- Predošlá práca je https://nlp.kemt.fei.tuke.sk/language/categorizednews
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Definovať úlohu pre ktorú chceme vytvoriť overenie. Ako by mala vyzerať "otázka"? Ako by mala vyzerať "odpoveď"? Čo znamená dobrá odpoveď?
|
||||
- Zostaviť prehľad existujúcich databáz pre vyhodnotenie vyhľadávania. Napíšte si poznámky.
|
||||
- Vyberte vhodnú databázu na "klonovanie".
|
||||
- Zvážiť vytvorenie strojovo preloženej databázy na porovnanie.
|
||||
- Vybrať vhodnú metódu anotácie dát. K tejto metóde implementovať anotačné nástroje. Je možnosť použiť "vyhľadávacie demo na wikipédiu".
|
||||
|
||||
Stretnutie 28.9.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Naindexovaná nová verzia Wikipédie (14.8.2023). Sentence Transformers a BM25.
|
||||
- Otázky sú v angličtine aj v slovenčine.
|
||||
- Zistili sme, že otázky v SK QUAD sú veľmi jednoduché.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Dajte skripty na parsovanie Wiki na GIT.
|
||||
- Vytvorte a vyhoddnoťte kros linguálny QA systém. Otázky v slovenčine by fungovali aj pre anglickú databázu.
|
||||
- Nájdite vedecké články publikované na túto tému. Prečítajte si ich a urobte si poznámky. Aké databázy a aké spôsoby vyhodnotenia sa používajú? Systém sa skladá z dvoch modulov - information retrieval a question answering. Každý sa vyhodnocuje inak. Vyhľadávajte "cross lingual information retrieval", "cross lingual question answering". Môže sa použiť ako esej AKT.
|
||||
- Skúste vytvoriť systém na "kros linguálne" indexovanie na "information retrieval". Je potrebné zistiť, aké modely a metódy sa na to používajú. MPnet alebo LABSE?
|
||||
|
||||
|
||||
Nápad:
|
||||
|
||||
- Vytvoriť alebo vybrať zložitejšie otázky a vyhodnotiť ich.
|
||||
|
||||
|
||||
# Diplomovy projekt 1
|
||||
|
||||
|
||||
Nápady na semester (spolu s K. Sopkovicom)
|
||||
|
||||
- Chceme rozbehat demo vyhľadávanie. Existuje streamlit verzia.
|
||||
- Chceme natrénovať a vyhodbnotiť model pre sémantické vyhľadávanie. Existuje prvá verzia sentence transformera (Cross Encoder, Dual Encoder natrénovaná na SK QUAD. Porovnať s STS SlovakBERT.
|
||||
- Chceme využiť aj QA model - využiť ho v deme.
|
||||
- Chcemem vyhodnotiť výkonnosť celého systému - všetky komponenty naraz. Aké sú možné metriky.
|
||||
- Pripraviť slovenskú databázu STS a NLI.
|
||||
- Vypracovať prehľad metód na vyhodnotenie IR systémov a kompletných systémov QA.
|
||||
- Preskúmať možnosti zlepšenia - Sentence Transformer skripty pre doménovú adaptáciu a multilinguálne modely.
|
||||
- Vypracovať prehľad článkov, ktoré riešia kompletné sémantické vyhľadávanie.
|
||||
- Podrobne opísať proces fungovania a trénovanie sentence transformera. Princíp dual-encoder, cross-encoder.
|
||||
- Pripraviť multi-lingual experiment na vyhľadávanie, napr. Angličtina, Slovenčina, Nemčina.
|
||||
- Vyskúšať vyhľadávanie v inej doméne (noviny, mestské dokumenty).
|
||||
|
||||
|
||||
|
||||
Stretnutie 26.6.
|
||||
|
||||
Stav:
|
||||
|
||||
- Demo funguje, je odladene aj nasadene
|
||||
- Praca naa pisomenj casti pokracuje
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pripraviť vyhľadávanie čislo anglické, čislo slovenské a slovensko anglické multilinguálne.
|
||||
- Vyčísliť p-r-f1 celého vyhľadávania pre tieto tri prípady to tak, že jeden dokument (jedna jednotka) je jeden odsek (paragraf). Teda indexujete po paragrafoch.
|
||||
- Cieľ je aby bola diplomovka publikovateľná.
|
||||
- Pokračovať v písaní. Text by mal byť podkladom na prezentované experimenty.
|
||||
Mal by vysvetľovať základné pojmy. Pozrite si články na tému "information retrieval in wikipedia".
|
||||
|
||||
Stretnutie 27.3.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Jednoduché demo stremalit fuguje - vektorové vyhľadávanie pomocou transformers utils.semantic_search.
|
||||
- Cieľ: ku každému paragrafu vypočítať embedding pomocou mnlr. Poznačiť si dokument id. V prvom kroku ku otázke vyhľadať paragrafy. V druhom kroku ku otázke vyhľadať odpovede v paragrafoch. V treťom kroku zobraziť odpoveď na otázku aj najrelevantnejšie dokumenty.
|
||||
- Pokračovať v písomnej časti.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- util_semanticsearch vymentiť za qdrant alebo faiss alebo iné.
|
||||
- Určiť prah, na základe ktorého sa zistí, že odpoveď nie je v databáze.
|
||||
- Neskôr dorobiť "fallback" na "fuzzy" vyhľadávanie relevatných dokumentov.
|
||||
|
||||
|
||||
Stretnutie 20.2.2023
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [-] Spravte QA demo pomocou streamlit. Najprv vytvorte faiss index, do pamäte nahrajte všetky paragrafy.
|
||||
- [ ] Dotaz transformuje na vektor. Nájdite 5 najlepších odsekov. Vykonajte QA na všety odseky. Zobrazte odseky. Zobrazte najlepšiu odpoveď a názov dokumentu kde sa nachádza.
|
||||
- [ ] Modely sa nachádzajú na HF TUKE-DeutscheTelekom.
|
||||
|
||||
Zásobník:
|
||||
|
||||
- Na uloženie odsekov a vektorov vyberte a použite vhodnú databázu (faiss, sqlite, qdrtant, jina ....).
|
||||
- Implementujte stránkovanie (ak bude potrebné), zlepšite výzor.
|
||||
|
||||
|
||||
|
||||
Stretnutie 17.2.2023
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zoberte existujúci model bi-encoder. Indexujte všetky odseky do vektorovej databázy FAISS.
|
||||
- Upravte streamlit demo na QA systém. Skript sa nachádza v slovak-retrieval/qademo. Skript bude vyhľadávať k najlepších dokumentov vektorovým vyhľadávaním.
|
||||
- Potom v najlepších dokumentoch vykonajte QA vyhľadávanie.
|
||||
- Zobrazte výsledky používateľovi.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Pripravte experimenty, kde prezentujeme komponenty, porovnáme rôzne možnosti do podoby článku.
|
||||
|
||||
|
||||
|
||||
# Vedecky projekt 2022/23
|
||||
|
||||
|
||||
Súvisiace práce:
|
||||
|
||||
- Matej Kobyľan
|
||||
- Suchanič
|
||||
- Kristián Sopkovič
|
||||
|
||||
Ciele na semester:
|
||||
|
||||
- Zistiť ktorá knižnica je dobrá a ktorý model je dobrý na slovenské vyhľadávnaie vo wikipédii pre QA.
|
||||
- Možnosti pre knižnice sú: JinaDocArray, Elasticsearch-Opensearch, Faiss, Haystack
|
||||
- Možnosti pre modely sú: DPR, LABSE, LASER, Iný Sentence Transformer, WordEmbedding.
|
||||
- Vypracovat demonštračné vyhľadávanie v slovenskej wikipédii.
|
||||
- Vypracovat spravu o precitanych clankoch spolu s odkazmi, cca 4 strany
|
||||
- Vyslovit ciele diplomovej prace.
|
||||
|
||||
|
||||
Klucove slova:
|
||||
|
||||
- Jina, Rasa, Vektorova Databaza
|
||||
- Hierarchicke vztahy medzi dokumentami
|
||||
- Faiss, Elasticsearch-Opensearch, Fasttext
|
||||
- https://aclanthology.org/2020.emnlp-main.550/, Dense Passage Retrieval for Open-Domain Question Answering.
|
||||
- Urobit demo vyhladavanie v slovenskej wikipedii.
|
||||
- LABSE, LASER embedding model
|
||||
- multi language IR
|
||||
|
||||
Stretnutie 9.1.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Vyrobená tabuľka s experimentami pre rôzne modely a rôzne veľkosti vrátenej množiny k
|
||||
- Zatiaľ najlepší je model BM25
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pripravte experiment v ktorom najprv vyhľadáte množinu k=(napr. 100, 200 alebo 50) prvkov pomocou bm25, výsledky zoradíte pomocou neurónovej siete a vyberiete m=(napr. 10,20,50) najlepších prvkov. Výsledky vyhodnotíte.
|
||||
- Zoradenie pomocou NN vyzerá takto: zoberiete otázku a paragraf. Vypočítate skóre podobnosti. Prvý spôsob výpočtu je, že vložíte otázku aj paragraf naraz do NN. Výsledok je podobnosť. Na výpočet podobnosti zatiaľ použite model slovakbert-stsb.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vytvoriť vyhľadávanie v dvoch krokoch. Najprv "nahrubo", potom výsledky znova zoradiť.
|
||||
- Druhý spôsob vyhľadávania nahrubo je: vypočítate významový vektor pre paragraf aj pre odsek. Výpočítate kosínusovú podobnosť jedného aj druhého.
|
||||
- Vyhodnotiť modely v adresári crossencoder.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Stretnutie 19.12.2022
|
||||
|
||||
Stav:
|
||||
|
||||
- Spustený skript pre vyhodnotenie
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pripravte testovací scenár. Množina SK QUAD. Vyhľadávame v paragrafoch. Pri vyhľadávaní nás zaujíma k najlepších výsledkov. K=1,5,10,20,30
|
||||
- V testovacom scenári vyskúšqjte viacero modelov. WordEmbedding, LABSE, SlovakBERT, BN25
|
||||
- V texte opíšte použíté modely, dataset aj testovací scenár.
|
||||
- Z výsledky by mohol byť konferenčný článok.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Natrénujte model Kharpukin DPR, podľa Facebook skriptov alebo pomocou Nvidia Deep learning examples.
|
||||
- Vyhodnotte celý proces QA na vrátených výsledkoch.
|
||||
|
||||
Stretnutie 10.11.2022
|
||||
|
||||
Stav:
|
||||
|
||||
- Konvertovaný SCNC do JSON.
|
||||
- Práca s Jina-Elasticsearch pre uloženie embeddingov.
|
||||
- Prečítaný a spoznámkovaný článok "Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation".
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Rozbehať skript SlovakRetrieval ktorý využíva FAISS. V skripte je už aj BM25, ostatné modely aj vyhodnotenie Recall na množine SK QUAD.
|
||||
- Vytvoriť slovenské vyhľadávanie pomocou WordEmbeding. Použiť slovenský Spacy Model.
|
||||
- Prečítať a spoznámkovať ďalšie články z https://github.com/UKPLab/sentence-transformers
|
||||
|
||||
|
||||
Zasobnik uloh:
|
||||
|
||||
- Dotrénovať sentence transformer na slovenský jazyk. Ako?
|
||||
|
||||
Stretnutie 14.10.2022
|
||||
|
||||
Ulohy:
|
||||
|
||||
- Precitat si clanok, napiste poznamky
|
||||
- Navrhnite na co by ste sa chceli sustredit.
|
||||
|
||||
|
||||
Stav:
|
||||
|
||||
- Naštudovaný článok Kharpukin Dense Passage Retrieval
|
||||
- Naštudované Jina-DocArray.
|
||||
- Je k dispozícci ES na školskom servri - aj tak je lepšie pracovať na vlastnej inštancii.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Dodaný skript na indexovanie SCNC do ES. Upravte skript na Jina DocArray
|
||||
- Skúste zaindexovať slovenské dokumenty pomocou JinaDoc Array. Vyberte vhdoný existujúci model, napr. LABSE.
|
||||
- Skúste ich vyhľadávať.
|
||||
- Nájdite si článok o vyhľadávaní pomocou LABSE. Napíšte si z neho poznámky. Ako prebieha vyhľadávanie pomocou LABSE?
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- skúste zaindexovať slovenské dokumenty pomocou Elasticsearch.
|
||||
- Zistite ako funguje vektorové vyhľadávanie v ES.
|
||||
|
||||
|
||||
# Bakalárska práca 2022
|
||||
|
||||
|
||||
- [Repozitár](https://git.kemt.fei.tuke.sk/ms111of/bp2022)
|
||||
|
||||
Názov: Indexovanie slovenského textu pomocou Elasticsearch
|
||||
|
||||
1. Vypracujte prehľad metód pre získavanie informácií.
|
||||
2. Vytvorte vyhľadávací index dokumentov zo slovenského internetu.
|
||||
3. Vytvorte demonštračnú webovú aplikáciu pre vyhľadávanie na slovenskom internete.
|
||||
4. Navrhnite zlepšenia vyhľadávania.
|
||||
|
||||
## Bakalársky projekt 2021
|
||||
|
||||
4.3.2022
|
||||
|
||||
- Prebehlo viacero stretnutí
|
||||
- Spravená Flask aplikácia, funguje, doplnené stránkovanie, zobrazenie otázok samosttne aj s ohodnotením , zobrazenie článku. Vyhľadanie podľa ľubovoľnej otázky.
|
||||
- Urobený compose pre ES a Kibanu
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Dorobiť Dockerfile pre web aplikáciu.
|
||||
- Pracovať na texte práce.
|
||||
|
||||
|
||||
Stretnutie 18.2.2022
|
||||
|
||||
- Boli viaceré stretnutia
|
||||
- Aplikácia funguje
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Doplniť stránkovanie, vyhľadanie vo voľnej otázke, zobrazenie článku.
|
||||
- Pracovač na texte.
|
||||
|
||||
|
||||
Stretnutie 7.1.2022
|
||||
|
||||
- Vytvorená Flask aplikácia a Dockerfile
|
||||
- Urobené jednoduché vyhodnotenie pomocou počtu výsledkov.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Urobte konfiguráciu url Elasticsearch pomocou premennej prostredia alebo argumentu príkazového riadka do Dockerfile.
|
||||
- Môžete dať všetko do docker-compose.
|
||||
- Urobte vyhodnotenie vyhľadávania pomocou Precision-recalll. Pozrite si DP Ján Holp. Zaindexujete testovaciu množinu. V testeovacej množine sú vzorové otázky a vzorové vyýsledky. Zoberiete vzorovú otázu a ku nej vyhľadáte výsledky. Porovnáte Vašu množinu a vzorovú množinu. zistíte veľkosť ich prieniku. Podľa veľkosti vzorovej množiny a výsledkovej množiny vypožítate precision-recall.
|
||||
- Dorobte prezentáciu
|
||||
- Do práce pridajte opis toho ako funguje Flask aplikácia a ako komunikuje s Elasticsearch.
|
||||
|
||||
|
||||
|
||||
Stretnutie 3.12.2021
|
||||
|
||||
- Podarilo sa zaindexovať dokument do ES pomocou Python skriptu
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zaindexujte viac dát
|
||||
- Vytvorte webové rozhranie pre vyhľadávanie. Flaśk aplikácia.
|
||||
|
||||
|
||||
Stretnutie 26.11.2021
|
||||
|
||||
- Vypracované skripty na vkladanie, ale zatiaľ nefungujú.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zoznámte sa s ES API
|
||||
- Prejdite tutoriál http://blog.adnansiddiqi.me/getting-started-with-elasticsearch-in-python/
|
||||
|
||||
|
||||
Stretnutie 12.11.2021
|
||||
|
||||
Pokračujú práce na písomnej časti, na praktickej zatiaľ nie.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zlepšiť štruktúru práce.
|
||||
- Doplniť do textu odkazy na literatúru.
|
||||
|
||||
Ciele na semester:
|
||||
|
||||
- vedieť zaindexovať väčšie množstvo slovenských textov.
|
||||
- vytvoriť funkčné webové demo na vyhľadávanie v týchto textoch.
|
||||
|
||||
|
||||
Stretnutie 22.10.2021:
|
||||
|
||||
- Pokračovanie na otvrených úlohách - problémy s Essential Data Docker setup
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Nainštalovať ES a Kibana, upravte compose na https://alysivji.github.io/elasticsearch-kibana-with-docker-compose.html
|
||||
- Pozrieť si knihu https://nlp.stanford.edu/IR-book/ a urobiť z nej poznámky do teoretickej časti BP. Odvolávajte sa na túto knihu v texte.
|
||||
- Skúste cez Kibanu zaindexovať jeden text a vyhľadať niečo.
|
||||
- Preštudujte si ES Analyzer.
|
||||
|
||||
|
||||
|
||||
Stretnutie 15.10.2021
|
||||
|
||||
Stav:
|
||||
|
||||
- Nainštalovaný ES na UVT virtuálke s dostatkom miesta.
|
||||
- Naštudovaný Docker.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračovať v otvorených úlohách.
|
||||
- Vyberte vhodnú klientskú knižnicu pre prácu s ES.
|
||||
- Pozrite podporu slovenčiny na ES od [Essential Data](https://github.com/essential-data/elasticsearch-sk).
|
||||
|
||||
|
||||
Stretnutie 1.10.2021
|
||||
|
||||
Stav:
|
||||
|
||||
- Urobený GIT, Overleaf aj virtuálny stroj na tuke cloud.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračovať v otvorených úlohách.
|
||||
|
||||
|
||||
Stretnutie 24.9.2021
|
||||
|
||||
Stav:
|
||||
|
||||
- Urobené poznámku ku knihe "Learning to Rank".
|
||||
- Naštudované Cassandra.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Kódy dávajte na GIT do repozitára bp2022
|
||||
- Začnite pracovať na Flask Web aplikácii. Aplikácia by mala vedieť zadať dotaz a zobraziť výsledky vyhľadávania.
|
||||
- Vytvorte skript na indexovanie wikipédie do ES
|
||||
- Napíšte si osnovu bakalárskej práce a dopíšte do nej relevantné texty ktoré máte.
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vytvorte si virtuálny stroj na cloud.tuke.sk
|
||||
- Web aplikácia by mala byť Dockerizovaná - vytvoríme Docker image.
|
||||
- Vytvorte si pracovné prostredie s ElasticSearch a docker-compose: nainštalujete Docker Swarm
|
||||
|
||||
## Vedecký projekt 2021
|
||||
|
||||
Návrh na zadanie bakalárskej práce:
|
||||
@ -55,10 +563,6 @@ Do budúcnosti:
|
||||
- Zaindexovať texty
|
||||
- Vytvoriť webové rozhranie pre vyhľadávací index.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Stretnutie 7.5.
|
||||
|
||||
Stav:
|
||||
|
||||
@ -0,0 +1,39 @@
|
||||
# Evaluation Set for Slovak News Information Retrieval
|
||||
|
||||
Vyhodnocovací datset pre vyhľadávanie informácii
|
||||
|
||||
## Poznámky
|
||||
- článok ukazuje ako vytvoriť vyhodnocovací súbor (databázu) otázok a odpovedí v slovenčine pre rôzne typy úloh v NLP.
|
||||
- databáza je kompatibilná s datasetom Cranfield
|
||||
- táto databáza je zostavená z relevantých dokumentov pre vyhodnotenie vyhľadávania
|
||||
- v databáze sa nachádzajú tieto polia:
|
||||
- názov článku
|
||||
- meno autora
|
||||
- dátum publikovania článku
|
||||
- text článku
|
||||
- kategória článku (napr. politika, ekonomika)
|
||||
- databáza obsahuje 3980 novinových článkov rozdelených do 6tich kategórii: ekonomika a podnikanie, kultúra, šport, domáce správy, svetové správy a zdravotníctvo
|
||||
- v databáze môžeme nájsť aj 80 otázok, ktoré sa týkajú novynových článkov.
|
||||
- každej jednej otázke je priradený atribút, ktorí hovorí relevanciu danej otázky v intervale 1 - 4
|
||||
|
||||
**Vyhodnotenie vyhľadávania informácii**
|
||||
|
||||
- je to proces merania ako dobrý je daný systém, ktorý vyhľadáva informácie v danej databáze na základe preddefinovaných kritérii
|
||||
- pre vyhodnotenie potrebujeme relevantné dokumenty, v ktorých sa nachádza odpoveď na otázku
|
||||
- Vyhodnotenie vieme zapísať pomocou rôznych metrík ako:
|
||||
- Presnosť
|
||||
- Návratnosť
|
||||
- F miera
|
||||
|
||||
## Túto tému dať do DP má veľký význam aspoň podkapitola
|
||||
**Lingvistické problémy Information Retreival v slovečine**
|
||||
|
||||
- aby sme mohli implementovať systém IR pre slovenský jazyk, alebo podobný jazyk ako je slovenčina je potrebné zohľadniť nasledujúce špecifické problémy:
|
||||
- streaming or lemmatization
|
||||
- viacslovnsé výrazy a pomenované entity
|
||||
- synonymá a hononymá
|
||||
|
||||
- jedným hlavným problémom, ktorý je špecifický pre slovenský jazyk je identifikovanie slov v texte
|
||||
- prvý krok je vykonanie morfologickej analýzi na identifikáciu pôvodnej základnej morfologickej formy
|
||||
- pre slovenský jazyk v tomto článku bola navrhnutá morfologická forma s využitím skrytého Markovho modelu.
|
||||
- skoro rovanký prístup môžeme zvoliť aj pre indetifikáciu koreňa slova s použitím systému, ktorí je založený na. pravidlách (Hunspell)
|
||||
22
pages/students/2019/michal_stromko/dp2024/Evaluation_IR.md
Normal file
@ -0,0 +1,22 @@
|
||||
# Prehľad existujúcich databáz pre vyhodnotenie vyhľadávania
|
||||
|
||||
- Začiatok IR sa datuje až do 60. rokov 20-teho storočia -> prvé Granfields experiments
|
||||
- V roku 1968 Gerrard Salton vynašiel model vektorového priestoru, definoval, že IR je oblasť týkajúca sa genrovania, ukladania, klasifikácie, analýzy a vyhľadávania
|
||||
|
||||

|
||||
|
||||
Najrošírenejšie databázy
|
||||
- TREC (Text Retrieval Conference) vzniklo tu viacero datasetov pre sémantické vyhľadávanie
|
||||
- Cranfield Collection
|
||||
- ClueWeb Datasets, existujú viacré verzie.
|
||||
- ClueWeb09 - 1 040 809 705 webových stránok v 10 tich jazykoch
|
||||
- ClueWeb12 - 733 019 372 webových stránok v angličtine
|
||||
- ClueWeb22 - projekt Lemur 10 miliárd webových stránok
|
||||
- MS MARCO - dataset zameraný na hĺbkové učenie, prvý súbor obsahoval 100 tisíc skutočných otázok BING a odpovede generované ľuďmi
|
||||
- CORD-19 - je to databáza súboru údajov, ktorá bola vytvorená výskumnými skupinami na tému COVID 19. Jej zdroje tvoria viac ako jeden milión článkov
|
||||
- SQUAD dataset
|
||||
- je tvorený dátami z Wikipédie, kde existuje na každú otázku opoveď vo verzii jeden.
|
||||
- vo verzii 2 sa nachádza 100 000 otázok zo SQuAD1.1 s viac ako 50 000 nezodpovedateľnými otázkami, ale sú napísané tak, aby to vyzeralo, že na danú otázku odpoveď existuje
|
||||
- bol vytvorený v anglickom jazyku a existujú aj jeho iné varianty v iných jazykoch
|
||||
- je vytorený aj multijazyčný squad má názov xquad skladá sa z jazykov Angličtina, Nemčina, Španielčina, Turečtina a ďalšie
|
||||
- ako posledný je squad v slovenčine squad-sk
|
||||
@ -0,0 +1,23 @@
|
||||
# Slovak Categorized News Corpus
|
||||
|
||||
## Poznámky
|
||||
- článok opisuje vytvorenie a používanie slovenského kategorizovaného korpusu z novynových článkov pre rôzne v NLP
|
||||
- dáta boli zbierané pomocou bota a boli použité funkcie, ktoré realizovali detekciu hraníc slov a viet, rozpoznávanie entít, morfologické zakončenia, lemantizáciu do hovorenej formy.
|
||||
- Výsledný korpus obsahuje 1,5 milióna tokenov a 102 tisíc viet, rozdelených do šiestich kategórii.
|
||||
- Kategórie korpusu:
|
||||
- politika
|
||||
- šport
|
||||
- kultúra
|
||||
- ekonomika
|
||||
- zdravotníctvo
|
||||
- svet
|
||||
|
||||
- Korpus môže byť použitý na automatické extrahovanie entít, hodnotenie jazykových modelov, kategorizáciu dokumentov, lingvistický výskum
|
||||
|
||||
### Lemantizácia
|
||||
- je proces v NLP, ktoré zahŕňa premenovanie slov na ich základnú formu (koreň slova), tento proces je užitočný pri analýze textu, pretože umožňuje porovnávať a analyzovať rôzne formy toho istého slova ako jednu entitu.
|
||||
- pre tento článok môžeme povedať, žš každý token (slovo, alebo časť slova) v korpuse má priradenú najpravdepodobnejšiu lemu
|
||||
|
||||
# Transcription to a Spoken Form
|
||||
- je sémantické zobrazenie hovoreného jazyka vo forme písaného textu. Transkripcia by nemala byť zamieňaná s prekladom, ktorý znamená preloženie významu textu z jedného jazyka do druhého jazyka
|
||||
- transkripcia sa často používa pri prepisovaní audio a video súborov
|
||||
{kind=link}
|
After Width: | Height: | Size: 113 KiB |
149
pages/students/2019/michal_stromko/vp2023/Dokumentacia.md
Normal file
@ -0,0 +1,149 @@
|
||||
<h1 align="center">
|
||||
<b>TECHNICKÁ UNIVERZITA V KOŠICIACH <br>
|
||||
FAKULTA ELEKTRONIKY A INFORMATIKY</b>
|
||||
</h1>
|
||||
<br> <br> <br> <br>
|
||||
|
||||
<p align="center", style="font-size:35px; line-height:normal;" > <b>Hodnotenie vyhľadávania modelu </b></p>
|
||||
<br> <br> <br> <br> <br> <br> <br>
|
||||
|
||||
<b>
|
||||
<p style="text-align:left;">
|
||||
2022
|
||||
<span style="float:right;">
|
||||
Michal Stromko
|
||||
</span>
|
||||
</p>
|
||||
</b>
|
||||
|
||||
<br> <br>
|
||||
|
||||
# Úvod
|
||||
|
||||
Cieľom tejto práce je zoznámenie s možnosťami hodnotenia modelov. Natrénovaný model dokážeme vyhodnotiť viacerými technickými metódami s použitím rôzdnych open source riešení. Každé z riešení nám ponúkne iné výsledky. V tejto práci bližšie opíšem základné pojmy, ktoré je potrebné poznať pri hodnotení. Opíšem základné informácie o technikách hodnotenia od základných pojmov ako napríklad Vektorové vyhľadávania, DPR, Sentence Transformers, BM-25, Faiss a mnoho ďalších.
|
||||
|
||||
|
||||
# Základné znalosti
|
||||
|
||||
Na začiatok je potrebné povedať, že pri spracovaní prirodzeného jazyka dokážeme používať rôzne metódy prístupu hodnotenia modelu, poprípade aj vyhľadávanie v modeli. V poslených rokoch sa v praxi stretávame s vyhľadávaním na základe vypočítania vektorov. Následne na takto vypočítané vektory dokážeme pomocou kosínusovej vzdialenosti nájsť vektory, inak povedané dve čísla, ktoré sú k sebe najbližšie. Jedno z čísel je z množiny vektorov, ktoré patria hľadanému výrazu, druhé číslo patrí slovu alebo vete, ktorá sa nacháza v indexe.
|
||||
|
||||
Vyhodnotenie vyhľadávania je v modeli dôležité z hľadiska budúceho použitia modelu do produkcie. Pokiaľ sa do produkcie dostane model, ktorý bude mať nízke ohodnotenie bude sa stávať, že vyhľadávanie bude nepresné čo znamená, že výsledky nebudú relevantné k tomu čo sme vyhľadávali.
|
||||
|
||||
## Zameranie práce
|
||||
|
||||
V tejto práci som realizoval viaceré experimenty, v ktorých som hodnotil vyhľadávanie pomocou modelov, do ktorých bol zaembedovaný text. Každý text obsahuje ďalšie atribúty, ako otázky a odpovede. Otázky sa následne pošlú na vyhľadanie a čaká sa na výsledok vyhľadávania. Výsledky, ktoré prídu sa následne porovnajú s očakávanými odpoveďami. Najdôležitejšie je nájsť v jednej odpovedi čo najviac správnych výsledkov. Následne je potrebné spočítať počet správnych výsledkov a použiť správne vypočítanú presnosť a návratnosť vyhľadávania. V tomto prípade presnosť a návratnosť počítame pre hodnotenie všetkých otázok. Čím sú hodnoty vyššie, tak môžeme konštatovať, že vyhľadávanie pomocou danej metódy je presné a dokážeme ho používať v produkcii.
|
||||
|
||||
Dôležtým atribútom, s ktorým sme vykonávali testovanie bolo menenie parametra **top_k**. Tento parameter znamená počet najlepších odpovedí na výstupe vyhľadávania. Čím je tento paramter väčší, tým môžeme očakávať, že sa v ňom bude nachádzať väčšie množstvo správnych odpovedí. V konečnom dôledku to vôbec nemusí byť pravda, pretože ak máme kvalitne natrénovaný model a dobre zaembedované dokumenty dokážeme mať správne výsledky na prvých miestach čo nám ukazuje, že parameter *top_k* može mať menšiu hodnotu.
|
||||
|
||||
Najčastejšie je táto hodnota nastavovaná na top 10 najlepších výsledkov vyhľadávania. Pri experimentoch som túto hodnotu nastavoval na hodnoty **5, 10, 15, 20, 30**. Každá metóda, ktorá bola pouťitá na vyhľadávanie dosiahla iné výsledky.
|
||||
|
||||
### Použité metódy vyhľadávania v experimentoch
|
||||
|
||||
V tejto práci som použil na vyhľadávanie 4 rôzne metódy, ktorým som postupne nastavoval parameter **top_k** od 5 až 30.
|
||||
Použil som vyhľadávanie pomocou:
|
||||
- Faiss
|
||||
- BM25
|
||||
- LaBSE
|
||||
- sts-slovakbert-stsb
|
||||
|
||||
Každá jedna metóda pracuje s úplne iným modelom. Modely LaBSE a sts-slovakbert-stsb používali rovnakú knižnicu na vytvorenie vektorov aj vyhľadávanie.
|
||||
|
||||
#### Faiss
|
||||
|
||||
Faiss používal knižnicu spacy, do ktorej parameter model_name vstupoval model ktorý bol natrénovaný pre slovenské dáta na mojej katedre. Následne boli dáta indexované pomocou knižnice faiss, ktorá má funkciu indexovania dát. Vyhľadávanie dát bolo tak isto realizované pomocou funkcie *faiss.search()*, ktorej parametre sú otázka a počet očakávaných dokumentov, inak povedané odpovedí.
|
||||
|
||||
#### BM25
|
||||
|
||||
BM25 je jeden z najstarších možností vyhľadávania v neuónových sieťach, napriek tomu je stále stabilný a relatívne presní aj v dnešnej dobe.
|
||||
|
||||
Pri vyhľadávaní informácii v BM25, označený Okapi je navrhnutý tak, že vyhľadáva na základe najlepšej zhody. Vyhľadávanie funguje na nájdení najlepších dokumentov, ktoré sú zoradené podľa relevantnosti k vyhľadanej požiadavke. Je založený na zoradení na pravdepodobnostnom rámci. BM 25 bol v priebehu rokov modifikovaný a vylepšovaný.
|
||||
|
||||
Pre vypočítanie skóra používa Inverse documents frequency (IDF). Vypočíta sa ako N a značí celkový počet dokumentov. Pri výpočte sa používa maximálna hodnota zo všetkých indexov, ktorá pochádza z najväčšieho indexu disku. Pre lepšie pochopenie IDF vypočítava uzol obsahu a index, treba však rátať s tým, že sa môžu vyskytovať mierne odchylky.
|
||||
|
||||
Jedným z dôležitých atribútov je či sa konenčný výsledný dokument vyskytne viackrát v relevantých odpovediach. Čím viackrát sa opakuje jeden dokument, tým je väčšia pravdepodobnoť, že bude označený za jeden z najlepších výsledkov vyhľadávania.
|
||||
|
||||
|
||||
Evaluovanie pomocou modelu LaBSE a sts-slovakbert-stsb som realizoval použítím knižnice **Sentence tranformers**. Práca s touto knižnicou je veľmi jednoduchá, pretože v dokumentácii, ktorú obsahuje, vieme veľmi jednoducho zaembedovať dokumenty a zároveň aj vyhľadávať.
|
||||
|
||||
Ako môžete vidieť v práci som použil model LaBSE aj keď som mal k dispozícii priamo natrénovaný model pre slovenčinu. Bolo to z dôvodu zistiť ako sa bude správať model LaBSE oproti modelu, ktorý bol natrénovaný pre Sloveský jazyk. Model LaBSE nebol vybratý len tak náhodou. Je to špecifický model, ktorý bol natrénovaný tak, aby podporoval vyhľadávanie, klasifikáciu textu a ďalšie aplikácie vo viacerých jazykoch. Vo všeobecnosti je označovaný ako multilangual embedding model. Je to model, ktorý je prispôsobený rôznym jazykom nielen pri indexovaní, ale aj vyľadávaní. Nájväčšou výhodou modelu je, že môžeme mať dokument, v ktorom sa nachádzajú vety vo vicacerých jazykoch. Pre niektoré modeli je to veľké obmedzenie, s ktorým si neporadia, avšak LaBSE je stavaný na takéto situácie, a tak si ľahko poradí a zaindexuje tento dokument.
|
||||
|
||||
#### slovakbert-sts-stsb
|
||||
Môžeme ho označiť ako sentence similarity model založený na SlovakBERT. Model bol dotrénovaný na STSbenchmark a preložený do slovenčniny pomocou M2M100. Model používa univerzálny sentence enkóder pre slovenské vety. Autory článku, ktorý trénovali SlovakBERT uvádzajú, že model je založený na large-scale transformers-based a používa 19,35 GB dát získaných z crawlovania webov so slovenským textom. Autori nakoniec vyhodnotili a prirovnali tento model ku ostatným veľkým jayzykovým modelom, ako napríklad XLM-R-Large.
|
||||
|
||||
Je to síce prvý model, ktorý dosahuje najlepšie výsledky oproti ostatným jazykovým modelom pre slovenčinu, ale treba si všimnúť, že stále tu existujú viacjazyčné jazykové modely, ktoré sú stále konkurencieschopné.
|
||||
|
||||
Hodnotenie modelu prebiehalo hlavne pomocou metriky F1. F1 bola priemerovaná zo súborov údajov. Autori modelu uvádzajú, že pri použití nízkych hodnôť hyperparametrov sa váhy moc nemenia, čo znamená lepšie výsledky hodnotenia.
|
||||
|
||||
Nevýhodou tohto jazykového modelu je nedostatok hodnotiacich benchmarkov. Ďalej vznikal problém s korpusom textov, tento model bol natrénovaný na dátach, ktoré boli vytvorené strojovým prekladom. Práve kvôli tomu vznikali chyby ako *noisy datasets (v prípade analýzy sentimentu)*.
|
||||
|
||||
|
||||
|
||||
### Výsledky experimentov
|
||||
|
||||
Spolu bolo realizovananých 20 experimentov vyhnotenia vyhľadávania na trénovacom datasete skquad. Každý jeden experiment pozostával z indexovania datasetu a následním vyhľadávaním na vopred vytvorených otázkach. Metódy medzi sebou mali spoločný počet experimentov a pri každej metóde boli vypočítané metriky Precission a Recall.Zároveň na každej metóde bolo vykonaných 5 experimentov s rôznymi parametrami top_k. Z týchto experimentov vznikla jedna veľká, nie moc prehľadná tabuľka, ktorú môžete vidieť nižšie.
|
||||
|
||||
| Evaluation mode | 5 Precision | 5 Recall | 10 Precision | 10 Recall | 15 Precision | 15 Recall | 20 Precision | 20 Recall | 30 Precision | 30 Recall |
|
||||
|----------------- |------------- |---------- |-------------- |----------- |-------------- |----------- |-------------- |----------- |-------------- |----------- |
|
||||
| FAISS | 0.0015329215534271926 | 0.007664607767135963 | 0.0012403410938007953 | 0.012403410938007953 | 0.0010902998324539249 | 0.016354497486808874 | 0.001007777138713146 | 0.020155542774262923 | 0.0008869105670726116 | 0.02660731701217835 |
|
||||
| BM 25 | 0.113256145439996 | 0.56628072719998 | 0.06176698592112831 | 0.6176698592112831 | 0.043105187259829786 | 0.6465778088974468 | 0.033317912425917126 | 0.6663582485183426 | 0.023139696749939567 | 0.694190902498187 |
|
||||
| LABSE | 0.09462602215609292 | 0.47313011078046463 | 0.05531896271474655 | 0.5531896271474656 | 0.039858461076796116 | 0.5978769161519418 | 0.031433644252169345 | 0.6286728850433869 | 0.022339059908141407 | 0.6701717972442421 |
|
||||
|slovakbert-sts-stsb | 0.08082472679986996 | 0.4041236339993498 | 0.04856210457875916 | 0.4856210457875916 | 0.03553810631256929 | 0.5330715946885394 | 0.028241516417014677 | 0.5648303283402936 | 0.020285578534096876 | 0.6085673560229063 |
|
||||
|
||||
V poslednom kroku je potrebné vyhodnotiť experimenty. Z takejto neprehľadnej tabuľky je to zložité, preto som zvolil prístup vytvorenia grafov, na ktorých presne vidno, ktorá metóda je najlepšia. Boli vytvorené grafy, ktoré ukazujú výskedky presnosti a návratnosti na rovnakom počte vrátaných odpovedí medzi métódami. Posledné 4 grafy znázorňujú každú metódu samostatne s narastajúcim počtom odpovedí.
|
||||
|
||||
#### Správanie metód pri rovnkakom počte najlepších odpovedí
|
||||
- Top 5 odpovedí
|
||||
|
||||
V tomto grafe môžete vidieť, že pri vyhľadávaní top 5 odpovedí najlepšiu presnosť a návratnosť mala metóda BM25, ktorá dosiahla najlepšie výsledky. Najhoršie výsledky boli dosiahnuté metódou Faiss. Metóda sentence transformers s použitím LaBSE dosiahla druhý najlepší výsledok.
|
||||
|
||||

|
||||
|
||||
- Top 10 odpovedí
|
||||
|
||||
Pri 10 najlepších odpovediach BM25 dosiahlo lepší výsledok Recall, ako pri top 5 výsledkoch, ale zároveň Precision sa zhoršila. Faiss má naďalej najhoršie výsledky. Sentence tranformers s použitím slovenského modelu slovakbert-sts-stsb sa zlepšila oproti predchádzajúcemu grafu.
|
||||
|
||||

|
||||
|
||||
- Top 15 odpovedí
|
||||
|
||||
Na tomoto grafe ďalej môžeme sledovať zlepšovanie Recall pre BM25, ale treba si však všimnúť, že Precission klesá. Dôležtým mýlnikom pri tomto grafe je porovnanie modelu LaBSE s slovakbert-sts-stsb, pretože slovakbert sa začína správať pri najlepších 15 odpovediach ako model LaBSE, to nám môže aj naznačit, že s rastúcim počtom odpovedí pre model LaBSE neprichádza viac správnych dokumentov, ako by sa očakávalo. Najväčšie priblíženie modelu slovakbert k modelu LaBSE môžete vidieť na metrike Precision.
|
||||
|
||||

|
||||
|
||||
- Top 20 odpovedí
|
||||
|
||||
Na tomto grafe už môžeme vidieť, že model LaBSE a slovakbert majú skoro rovnaké hodnoty Precision a Recall. To nám môže nazanačovať, že použitie modelu slovakbert bude silnejšie pri vracaní väčšieho počtu výsledkov.
|
||||
|
||||

|
||||
|
||||
- Top 30 odpovedí
|
||||
|
||||
Posledný graf v tejto kategórii nám ukazuje, že aj pri 30 odpovediach má metóda BM25 najlepší Recall, ale treba sa pozrieť na model slovakbert, ktorý má pri top 30 odpovedach minimálnu odchýlku od modelu LaBSE.
|
||||
|
||||

|
||||
|
||||
|
||||
#### Správanie metódy s narastajúcim počtom najlepších odpovedí
|
||||
|
||||
V tejto časti práce skúsim bližšie zobraziť dva grafy, na ktorých môžete vidieť správanie metódy hodnotenia vyhľadávania s narastajúcim počtom výsledkov z vyhľadávania. Nižšie sa nachádzajú iba 2 metódy, ktoré podľa mňa v experimentoch dosiahli najlepšie výsledky.
|
||||
|
||||
- Metódou BM25
|
||||
|
||||
Metóda BM25 počas všetkých experimentov vykazovala najlepšie výsledky, nie len Precission, ale aj Recall. Na grafe môžete vidieť, že s narastajúcim počtom výsledkov Precission klesal, ale zároveň Recall stúpal. Pri tejto metóde vidím môžnosti experimentovania, napríklad pri 50 alebo 100 odpovediach z vyhľadávania
|
||||
|
||||

|
||||
|
||||
- Metódou sentence transformers s použitím slovakbert-sts-stsb
|
||||
|
||||
Model slovakbert, ktorý bol zverejnený na konci minulého roka, dosiahol pri poskytnutom datasete perfektné výsledky. Dovoľujem si to tvrdiť z toho dôvodu, že nebol trénovaný na datasete, ktorým bol hodnotený. V budúnosti by mohlo byť zaujímavé dotrénovať tento model pomocou použitého datasetu a následne takýto model ohodnotiť. Predpokladám, že tento model by mohol lepšie vyhľadávať aj pri menšom množstve najlepších výsledkov z vyhľadávania.
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
### Záver vyhodnotenia experimentov
|
||||
|
||||
V tejto práci sa mi podarilo úspešne vykonať 20 experimentov, ktoré ukázali, že dokážeme efektívne využiť natrénovaný slovenský model na iných dátach. Zároveň môžeme vidieť aj efektívne vyhľadávanie metódou BM25, ktorá dosahovala nadpriemerné výsledky.
|
||||
|
||||
Pokračovanie v práci by som mohol realizovať použitím dvoch techník vyhľadávania. Ideálnym prípadom môže byť použitie oboch metód. Je dôležité, aby metódy išli v správnom poradí. Po prvom vyhľadávan by bolo ideálne použiť text similarity pre efektívne zoradenie výsledkov.
|
||||
|
||||
@ -0,0 +1,12 @@
|
||||
# Dense Passage Retrieval for Open-Domain Question Answering
|
||||
## Clanok č.1
|
||||
|
||||
### Dense Passage Retriever (DPR)
|
||||
- výskum tejto práce je zameraný na zlepšenie vyhľadávania v QA.
|
||||
- pre používanie DPR je dôležité používať správny Encoder, ktorý mapuje text na dimenzionálne vektory skutočnej hodnoty a vytvára index __M__, ktorý sa používa pre vyhľadávanie
|
||||
- pri behu DPR sa aplikuje iný Enkóder, ktorý mapuje vstupnú otázku na d-rozmerný vektor, a vyhľadáva podľa toho ktorý vektor je najbližšie k vektoru otázky. Podobnosť medzi otázkou a pasážou definujeme pomocou bodového súčinu ich vektorov.
|
||||
- doležitou súčasťou takéhoto vyhľadávania je správne vypočítanie kosínusovej vzdialenosti.
|
||||
- trénovanie Encodera sa vykonáva z dôvodu lepšieho vypočítania metrických údajov.
|
||||
- cieľ trénovania je vytvorenie dvoch vektorov, tak aby tieto dve relevantné dvojice otázok a odpovedí mali najmenšiu vzdialenosť medzi sebou.
|
||||
__Pozitívne a negatívne pasáže__
|
||||
- pri vyhľadávaní sa často stretávame s pozitívnymi výsledkami ktoré sú k dispozícii explicitne, zatiaľ čo negatívne výsledky je potrebné vybrať z veľkého súboru.
|
||||
@ -0,0 +1,8 @@
|
||||
# Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation
|
||||
|
||||
## Abstrak
|
||||
- tento článok predstavuje vylepšenia vyhľadávania, na základe rozšírenia modelu, pomocou pridania nových viet do modelu.
|
||||
- tieto vety su podobne tym ktore sa uz nachadzali v modeli, a vypocitane vektory by mali byt umiestnene, tak aby boli blyzko pri predtym vypocitanom embedingu.
|
||||
- pri takomto trenovani pouzivame trenovanie viacjazycnych viet.
|
||||
- vyhodou takéhoto použitia je jednoduché rozšírenie existujúcich modelov s relatívne malým počtom vzoriek.
|
||||
- článok je zameraný na ukážku účinosti vyhľadávania pre viac ako 50 jazykov z rôznych rodín, v konečnom dôsledku to môže znamenať aj zahrnutie slovenského jazyka.
|
||||
BIN
pages/students/2019/michal_stromko/vp2023/img/bm25.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 9.6 KiB |
BIN
pages/students/2019/michal_stromko/vp2023/img/k_10.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 15 KiB |
BIN
pages/students/2019/michal_stromko/vp2023/img/k_15.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 14 KiB |
BIN
pages/students/2019/michal_stromko/vp2023/img/k_20.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 14 KiB |
BIN
pages/students/2019/michal_stromko/vp2023/img/k_30.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 14 KiB |
BIN
pages/students/2019/michal_stromko/vp2023/img/k_5.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 15 KiB |
BIN
pages/students/2019/michal_stromko/vp2023/img/slovakbert_sts.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 11 KiB |
BIN
pages/students/2019/michal_stromko/vp2023/img/vzorec.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 7.1 KiB |
47
pages/students/2019/michal_stromko/vp2023/notes.md
Normal file
@ -0,0 +1,47 @@
|
||||
### Dense Passage Retriever (DPR)
|
||||
|
||||
DPR nazývame ako typ systému, spracovania prirodzeného jazyka (NLP). Tento systém získava relevantné časti, inak povedané pasáže z veľkého korpusu textu. V kombinácii s sémantickou analýzou a algoritmom strojového učenia, ktorý idenetifikuje najrelevantnejšie pasáže pre daný dopyt. DPR je založený na používaní správneho enkódera, ktorý mapuje text na dimenzionálne vektory skutočnej hodnoty a vytvára index M, ktorý sa používa pre vyhľadávanie. Treba však povedať, že počas behu DPR sa aplikuje aj iný enkóder **EQ**, ktorý mapuje vstupnú otázku na d-rozmerný vektor a následne hľadá tie vektory, ktoré sú najbližšie k vektoru otázky. Podobnosť medzi otázkou a časťou odpovede definujeme pomocou **Bodového súčinu ich vektorov**.
|
||||
|
||||

|
||||
|
||||
Aj keď existujú silnejšie modelové formy na meranie podobnosti medzi otázkou a pasážou, ako sú siete pozostávajúce z viacerých vrstiev krížovej pozornosti, ktorá musí byť rozložiteľná, aby sme mohli vopred vypočítať kolekcie pasáží. Väčšina rozložiteľných funkcii podobnosti používa transformácie euklidovskej vzdialenosti.
|
||||
|
||||
**Cross Attentions** (krížová pozornosť)
|
||||
Cross Attentions v DPR je technika, ktorá sa používa na zlepšenie presnosti procesu vyhľadávania. Funguje tak, že umožňuje modelu pracovať s viacerými pasížami naraz, čo umožňuje identifikovanie najrelevantnejších pasáží. Pre pre správne identifikovanie DPR berie do úvahy kontext každej pasáže. V prvom kroku najskôr model identifikuje kľúčové výrazy v dotaze a následne použije sémantickú analýzu na identifikáciu súvisiacich výrazov. Mechanizmus pozornisti umožňuje modelu zamerať sa na najdôležitejšie slová v každej pasáži, zatiaľ čo algoritmu strojového učenia pomáha modelu s identifikáciou.
|
||||
|
||||
V ďalšom kroku _Cross Attentions_ používa systém bodovania na hodnotenie získaných pasáží. Bodovací systém berie do úvahy relevantnosť pasáží k dopytu, dĺžku pasáží a počet výskytov dopytovacích výrazov v pasážach. Posledným dôležitým atribútom, ktorý sa zisťuje je miera súvislosti nájdeného výrazu k výrazu dopytu.
|
||||
|
||||
**Pozitívne a negatívne pasáže** (Positive and Negative passages)
|
||||
Časté problémy, ktoré vznikajú pri vyhľadávaní sú spojené s opakujúcimi sa pozitívnymi výsledkami, zatiaľ čo negatívne výsledky sa vyberajú z veľkej množiny. Ako príklad si môžeme uviesť pasáž, ktorá súvisí s otázkou a nachádza sa v súbore QA a dá sa nájsť pomocou odpovede. Všetky ostatné pasáže aj keď nie sú explicitne špecifikované, môžu byť predvolene považované za irelevantné.
|
||||
Poznáme tri typy negatívnych odpovedí:
|
||||
- **Náhodný (Random)**
|
||||
- Je to akákoľvek náhodná pasáž z korpusu
|
||||
- **BM25**
|
||||
- Top pasáže vracajúce BM25, ktoré neobsahujú odpoveď, ale zodpovedajú väčšine otázkou
|
||||
- **Zlato (Gold)**
|
||||
- Pozitívne pasáže párované s ostatnými otázkami, ktoré sa objavili v trénovacom súbore
|
||||
|
||||
### Sentence Transformers
|
||||
|
||||
- je Python framework
|
||||
- dokázeme vypočítať Embeddingy vo vyše 100 jazykoch a dajú sa použíť na bežné úlohy ako napríklad semantic text similarity, sementic search, paraphrase mining
|
||||
- framework je založený na PyTorch a Transformers a ponúka veľkú zbierku predtrénovyných modelov, ktoré sú vyladené pre rôzdne úlohy
|
||||
|
||||
|
||||
### Word Embedding
|
||||
|
||||
Požívanie Word Embedings závisí od dobre vypočítaných Embedingov. Pokiaľ máme dobre vypočítané Embeddingy dokážeme veľmi jednoducho dostávať správne odpovede napríklad pri vyhľadávaní. Word Embedding môžeme poznať aj pod slovným spojením ako distribuovaná reprezentácia slov. Dokážeme pomocou neho zachytiť sémantické aj systaktické informácie o slovách z veľkého neoznačeného korpusu.
|
||||
|
||||
Word Emedding používa tri kritické komponenty pri trénovaní a to model, korpus a trénovacie parametre. Aby sme mohli navrhnút efektívne word-embedding metódy je potrebné na začiatku objasniť konštrukciu modelu. Takmer všetky metódy trénovania word embeddings sú založené na rovnakej distribučnej hypotéze: **Slové, ktoré sa vyskytujú v podobných kontextoch, majú tendenciu mať podobné významy**
|
||||
|
||||
Vzhľadom na vyšie napísanú hypotézu rôzne metódy modelujú vzťah medzi cieľovým slovom _w_ a jeho kontextom _c_ v korpuse s rôzymi spôsobmi, pričom _w_ a _c_ sú vložené do vektorov. Vo všeobecnosti môžeme povedať, že existujúce metódy sa líšia v dvoch hlavných aspektoch modelu konštrukcii a to **vzťah medzi cieľovým slovom a jeho kontextom a reprezentácia kontextu**
|
||||
|
||||
Treba brať na vedomie, že trénovanie presných word embeddingov silne, inak povedané výrazne súvisí s tréningovým korpusom. Rôzne tréningové korpusy s rôznou veľkosťou a pochádzajúcej z rôzdnej oblasti môžu výrazne ovplyvniť konečné výsledky.
|
||||
|
||||
Nakoniec presné trénovanie word embeddingov silne závisí od parametrov akými sú:
|
||||
- počet iterácii
|
||||
- dimenzionalita embeddingov
|
||||
|
||||
|
||||
|
||||
Bol uvedený pre širokú verejnosť v roku 2021
|
||||
111
pages/students/2019/patrik_pokrivcak/README.md
Normal file
@ -0,0 +1,111 @@
|
||||
---
|
||||
title: Patrik Pokrivčák
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [dp2025]
|
||||
tag: [nlp, hate]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
rok začiatku štúdia: 2019
|
||||
|
||||
# Diplomová práca
|
||||
|
||||
|
||||
Téma:
|
||||
|
||||
Rozpoznávanie nenávistnej reči pomocou veľkých jazykových modelov
|
||||
|
||||
Zadanie:
|
||||
|
||||
1. Vypracujte prehľad veľkých jazykových modelov s podporou slovenčiny.
|
||||
2. Vypracujte prehľad metód rozpoznávania nenávistnej reči pomocou veľkých jazykových modelov.
|
||||
3. Vyberte vhodnú dátovú množinu pre rozpoznávanie nenávistnej reči a pomocou nej vhodnou metrikou porovnajte viacero jazykových modelov pre úlohu rozpoznávania nenávistnej reči.
|
||||
4. Vyhodnoťte experimenty a navrhnite zlepšenia rozpoznávania.
|
||||
|
||||
Cieľe:
|
||||
|
||||
- Naučiť sa rozpoznávať nenávistnú reči HS pomocou LLM - lokálnych alebo komerčných.
|
||||
- Zlepšiť chopnosti LLM pre rozpoznávanie HS - dotrénovaním alebo promptingom.
|
||||
- Vytvoriť demo
|
||||
- Výsledky prezentovať na konferencii - alebo článku.
|
||||
|
||||
Nápad:
|
||||
|
||||
- Generovanie nenávistnej reči pre účely trénovania.
|
||||
- Rozpoznávanie HS pomocou embeding modelov, few shot alebo dotrénovanie.
|
||||
|
||||
Súvisiaca téma:
|
||||
|
||||
- [Python](/topics/python)
|
||||
- [Hate Speech](/topics/hatespeech)
|
||||
- [Tetiana Mahorian](/students/2022/tetiana_mohorian)
|
||||
|
||||
|
||||
Stretnutie 15.10.
|
||||
|
||||
Stav:
|
||||
|
||||
- Staré poznámky.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Navrhnite prompt na klasifikáciu nenávistnej reči a vyhodnotte, aký presný je model na množine https://huggingface.co/datasets/TUKE-KEMT/hate_speech_slovak. Vyskúšajte viac modelov. Vyskúšajte aj https://huggingface.co/slovak-nlp/mistral-sk-7b
|
||||
- Pokračujte v písaní DP. Použite odkazy na odborné články,
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Dotrénujte model na klasifikáciu nenávistnej reči.
|
||||
- Dotrénujte model na generovanie nenávistnej reči.
|
||||
- Vyskúšajte SentenceTransformer (me5) na klasifikáciu.
|
||||
|
||||
|
||||
|
||||
## Diplomový projekt 2024
|
||||
|
||||
Stretnutie 10.5.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Poznámky o neurónových sieťach a rozbehané HF transformers.
|
||||
- Práca s Kaggle.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračovať v otvorených úlohách a štúdiu.
|
||||
- [ ] Zistite čo je to SentenceTransformer. Prejdite si tutoriál https://sbert.net/docs/usage/semantic_textual_similarity.html Ako model použite multilingual e5 base alebo slovakbert-mnlr.
|
||||
- Prečítajte si niekoľko vedeckých článkov o klasifikácii HS, poznačte si ich informácie a urobte si poznámky. Na vyhľadanie článkov použite google scholar.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vyskúšajte Ollama a niekoľko jazykových modelov (LLAMA3, mistral, ) pre few-shot rozpoznávanie HS.
|
||||
- Dotrénujte embedding model na HS detection
|
||||
- Pripravte dáta na vyhodnotenie few shot klasifikácie.
|
||||
|
||||
|
||||
Stretnutie 5.4.
|
||||
|
||||
Stav:
|
||||
|
||||
- Začiatok štúdia Python a LMM.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Pokračujte v štúdiu neurónových sietí a klasifikácie nenávsistnej reči podľa otvorených úloh. Píšte si poznámky.
|
||||
- [-] Zistite, ako pracuje model GPT. Zistite čo je to prompting. Navrhnite "prompt" pre ChatGPT ktorý by klasifikoval nenávistnú reč.
|
||||
- [x] Oboznámte sa s knižnicou HF transformers. Nainštalujte si ju. Prejdite si jeden alebo 2 tutoriály.
|
||||
- [ ] Zistite ako funguje "few shot" alebo "zero shot" learning s GPT modelom. Vyskúšajte si to z HF Transformers. napr. https://huggingface.co/blog/few-shot-learning-gpt-neo-and-inference-api
|
||||
|
||||
Stretnutie 15.2.
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Nainštalujte si prostredie Anaconda. Naučiť sa lepšie programovať v jazyku Python.
|
||||
- [x] Prečítajte si Dive into Python 3.
|
||||
- [x] Priečítajte si Dive into Deep learning.
|
||||
- [x] Zistite si čo je to nenávistná reč a ako sa rozpoznáva pomocou neurónových sietí. Napíšte si o tom poznámky na dve strany.
|
||||
- [-] Zistite, aké existujú veľké jazykové modely a ako pracujú. Napíšte o tom poznámky na 2 strany.
|
||||
|
||||
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
title: Samuel Horáni
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [vp2021]
|
||||
category: [vp2021,bp2022]
|
||||
tag: [chatbot,rasa,dialog,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
@ -24,6 +24,163 @@ Nápady na balakársku prácu:
|
||||
- dá sa dorobiť aj rečové rozhranie.
|
||||
- dá sa to prepojiť aj na QA systém.
|
||||
|
||||
Výsledky:
|
||||
|
||||
- [Repozitár s webovou aplikáciou](https://git.kemt.fei.tuke.sk/sh662er/rasa-flask-website)
|
||||
- [Repozitár s chatbotom](https://git.kemt.fei.tuke.sk/sh662er/Rasa)
|
||||
|
||||
## Bakalársky projekt 2021
|
||||
|
||||
Ciele:
|
||||
|
||||
- Vypracovať draft B. práce.
|
||||
- Mať funkčné demo vo forme nasadenej webovej aplikácie.
|
||||
|
||||
|
||||
|
||||
---
|
||||
|
||||
6.1.2022
|
||||
|
||||
- Chatbot vie "rezervovať" stôl - rozpoznať entitu s názvom stola.
|
||||
- Urobený Dockerfile pre Rasa bot
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Dorobiť Dockerfile pre Flask App
|
||||
- Skúsiť urobiť docker-compose.yaml (Swarm Mode Docker)
|
||||
- Pre deployment je dobré zmeniť databázu na Postgres. Postgres sa robí "jednoducho" cez compose.
|
||||
- Upraviť konfiguráciu do podoby vhodnej na nasadenie. Nasadenie aplikácia bude mať inú konfiguráciu (napr. databázu) ako aplikácia vo vývoji.
|
||||
- Naučte robota hovoriť o aktuálnom jedálnom lístku.
|
||||
- čo mi ponúknete na obed?
|
||||
- Aké máte menu na pondelok?
|
||||
- čo obsahuje "čiernohorský rezeň"?
|
||||
- Naučte robota hiečo o reštaurácii.
|
||||
- Ako sa tam dostanem?
|
||||
- Naučte robota aby vedel pomôcť človeku.
|
||||
- Čo vieš urobiť?
|
||||
- Pracujte na prezentácii.
|
||||
- Pracujte na písomnej časti.
|
||||
|
||||
|
||||
|
||||
---
|
||||
|
||||
Stretnutie 17.12.2021
|
||||
|
||||
Stav:
|
||||
|
||||
- Pridané testy na RASA test, urobené vyhodnotenie pomocou konfúznej matice.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Pridajte schopnosť rozlišovať pomenované entity typu LOC. Spacy model by to mal vedieť.
|
||||
- [ ] Vylepšite chatbota do prvej funkčnej verzie.
|
||||
- [x] Pripravte deployment pomocou Docker.
|
||||
- [ ] Dajte vyskúšať chatbota tretej osobe a zapíšte si story.
|
||||
|
||||
---
|
||||
|
||||
Stretnutie 10.12.
|
||||
|
||||
- Naštudujte si https://rasa.com/docs/rasa/testing-your-assistant
|
||||
- Pokračujte v otvorených úlohách.
|
||||
|
||||
---
|
||||
|
||||
Stretnutie 3.12.2021
|
||||
|
||||
Stav:
|
||||
|
||||
- Teoretická čast BP je v celkom dobrom stave. Prebehlo viacero stretnutí k BP.
|
||||
|
||||
Ulohy:
|
||||
|
||||
1. [x] Navrhnite a napíšte intenty a utterance pre chatbota
|
||||
2. [x] Natrénujte model, výskúšajte ho, opravte ho.
|
||||
3. [x] Vytvorte testovacie stories a vyhonotte model.
|
||||
4. [x] Kódy dajte na GIT
|
||||
5. [x] Pripravte deployment pomocou Docker.
|
||||
|
||||
|
||||
- - -
|
||||
|
||||
Stretnutie 12.11.2021
|
||||
|
||||
Vyhodnotenie zatiaľ nefunguje.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Pokračovať v písaní práce.
|
||||
- [x] Dokončiť web demo.
|
||||
- [x] Vytvorte dockerfile.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vyhdonotiť NLU (úlohy z 12.10.)
|
||||
|
||||
Stretnutie 22.10.2021
|
||||
|
||||
- Urobené webové rozhranie pre analýzu konverzácií.
|
||||
|
||||
Pokračovať v otvorených úlohách.
|
||||
|
||||
Stretnutie 12.10.
|
||||
|
||||
Stav:
|
||||
|
||||
- Vytvorené prepojenie s databázou a RASA pre uchovanie logov z konverzácií.
|
||||
- Rozpracovaná knižnica pre prácu s databázou konverzácií.
|
||||
- Vyskúšaný nový Spacy jazykový model.
|
||||
- Vypracovaný report pre odovzdanie v 4. týždni - šablóna, osnova, krátky článok.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Vyhodnotiť NLU model.
|
||||
- [x] Pripraviť sadu na vyhodnotenie NLU a spôsob ako ju v skripte vykonať. Vytvoriť niekoľko modelových situácií a sledovať, ako "dobre" bude chatbot reagovať.
|
||||
- [x] Zistiť z odbornej literatúry akým spôsobom sa zvyčajne vyhodnocuje NLU úloha. Prečítajte si článok o NLU a napíšte ako sa vyhodnocuje NLU model. Nájdite anglickú databázu na vyhdonotenie NLU a pozrite sa ako vyzerá. [blog rasa](https://rasa.com/blog/evaluating-rasa-nlu-models-in-jupyter/).
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- [x] Analyzovať logy z konverzácií. Pripraviť export konverzácií v JSON pre spracovanie a HTML formáte pre zobrazenie.
|
||||
|
||||
- - -
|
||||
|
||||
Stretnutie 1.10.
|
||||
|
||||
Stav:
|
||||
|
||||
- Minulé úlohy dokončené: Osnova,
|
||||
- flask aplikácia je rozpracovaná a komunikuje s RASA.
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Vytvoriť Word s osnovou práce a do neho zapísať relevantné texty.
|
||||
- [x] Pokračujte na Flask aplikácii
|
||||
- [x] Zistite čo je to Dockerfile.
|
||||
|
||||
|
||||
|
||||
- - -
|
||||
|
||||
Stretnutie 24.9.
|
||||
|
||||
Stav:
|
||||
|
||||
- Rozpracovaná flask aplikácia pre napojenie sa na RASA chatbota
|
||||
- Veľmi základná ale funkčná verzia RASA bota
|
||||
- Odovzdaný nový jazykový model Spacy.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Dorobiť komunikáciu Flask a RASA s novým jazykovým modelom. Zdrojáky na GIT.
|
||||
- [x] Vytvorte draft práce, napíšte osnovu a pridajte tam relevantné texty ktoré máte.
|
||||
- [x] Nájdite aspoň jeden vedecký článok na tému "dialogue management" a napíšte čo ste sa dozvedeli.
|
||||
|
||||
- - -
|
||||
|
||||
## Vedecký projekt 2021
|
||||
|
||||
Dialógový systém pomocou RASA framework
|
||||
@ -34,7 +191,14 @@ Cieľom projektu je naučiť sa niečo o dialógových systémoch a oboznámiť
|
||||
- Vyberte a prejdite najmenej jeden tutoriál pre prácu s RASA frameworkom.
|
||||
- Napíšte krátky report na 2 strany kde napíšete čo ste urobili a čo ste sa dozvedeli.
|
||||
- Výstup je tu https://git.kemt.fei.tuke.sk/sh662er/Rasa
|
||||
- - -
|
||||
Stretnutie 16.6.2021
|
||||
|
||||
Stav:
|
||||
|
||||
- Stránka s UI je vo Flask
|
||||
- Problém je so stavom spojenia s RASA servrom.
|
||||
- - -
|
||||
Stretnutie 6.5.2021
|
||||
|
||||
- prebehla aj Komunikácia cez teams a email.
|
||||
@ -42,15 +206,8 @@ Stretnutie 6.5.2021
|
||||
|
||||
Úlohy:
|
||||
|
||||
- podmienky na zápočet sú splnené - ale poprosím dokumentáciu konvertovať do Markdown a nahrať na GIT.
|
||||
|
||||
Stretnutie 16.6.2021
|
||||
|
||||
Stav:
|
||||
|
||||
- Stránka s UI je vo Flask
|
||||
- Problém je so stavom spojenia s RASA servrom.
|
||||
|
||||
- [x] podmienky na zápočet sú splnené - ale poprosím dokumentáciu konvertovať do Markdown a nahrať na GIT.
|
||||
- - -
|
||||
Stretnutie 9.4.2021
|
||||
|
||||
Stav:
|
||||
@ -61,9 +218,8 @@ Stav:
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vyskúšať slovenský spacy model od vedúceho.
|
||||
|
||||
|
||||
- [x] Vyskúšať slovenský spacy model od vedúceho.
|
||||
- - -
|
||||
Stretnutie 26.3.2021
|
||||
|
||||
Stav:
|
||||
@ -73,17 +229,14 @@ Stav:
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Fast tex model implememntovať
|
||||
- napísať dokumentáciu
|
||||
|
||||
|
||||
|
||||
- [x] Fast tex model implememntovať
|
||||
- [x] napísať dokumentáciu
|
||||
- - -
|
||||
Stretnutie 19.3.2021
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Doplniť podporu slovenčiny do fr. RASA
|
||||
|
||||
- [x] Doplniť podporu slovenčiny do fr. RASA
|
||||
|
||||
Stav:
|
||||
|
||||
@ -93,5 +246,5 @@ Stav:
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Skúsiť vytvoriť agenta ktorý komunikuje po slovensky. Najprv by sa preložili trénovacie príklady.
|
||||
- Zistiť ako doplniť podporu slovenčiny do RASA. Komponenty ktoré máme k dispozícii sú: spacy model, fastext a glove word embedding model, BERT model (fresh and secret).
|
||||
- [x] Skúsiť vytvoriť agenta ktorý komunikuje po slovensky. Najprv by sa preložili trénovacie príklady.
|
||||
- [x] Zistiť ako doplniť podporu slovenčiny do RASA. Komponenty ktoré máme k dispozícii sú: spacy model, fastext a glove word embedding model, BERT model (fresh and secret).
|
||||
|
||||
91
pages/students/2020/david_kostilnik/README.md
Normal file
@ -0,0 +1,91 @@
|
||||
---
|
||||
title: Dávid Kostilník
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [dp2025]
|
||||
tag: [ir]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
rok začiatku štúdia: 2020
|
||||
|
||||
# Diplomová práca 2025
|
||||
|
||||
Téma:
|
||||
|
||||
Sémantické vyhľadávanie pomocou veľkých modelov
|
||||
|
||||
- Tvorba datasetu prekladom, využitie existujúcich datasetov
|
||||
- Dotrénovanie existujúceho modelu typu BERT pomocou preloženého MS MARCO.
|
||||
|
||||
Ciele:
|
||||
|
||||
- Zlepšiť RAG.
|
||||
|
||||
Zadanie:
|
||||
|
||||
1. Vypracujte prehľad metód a modelov sémantického vyhľadávania pomocou neurónových sietí.
|
||||
2. Vyberte vhodnú dátovú množinu a dotrénujte jazykový model pre úlohu sémantického vyhľadávania v slovenčine.
|
||||
3. Navrhnite a vykonajte experimenty pre vyhodnotenie dotrénovaného modelu.
|
||||
4. Vyhodnotťte experimenty a navrhnite zlepšenia.
|
||||
|
||||
Stretnutie 13.2.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Napísaná teória - neviem?
|
||||
- Práca na trénovaní mbert pomocou MS MARCO na úlohe extraktívnej QA čo nesedí so zadaním.
|
||||
- Fuzzy matching na vyhľadanie odpovede v datasete.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v otvorených úlohách týkajúcich sa SBERT, pracujte na texte DP.
|
||||
- Pozrite si a vyskúšajte repozitár https://github.com/hladek/slovak-retrieval, skript train-bi-mnlr.py. Upravte skript pre trénovnaie na MS MARCO. Natrénujte a vyhodnotte viac modelov.
|
||||
- Naštudujte si metódy vyodnotenia vektorových modelov (MTEB a beir). Vyskúšajte skripty pre vyhodnotenie v danom repozitári (MTEB a BEIR).
|
||||
- Skripty dajte na KEMT GIT.
|
||||
|
||||
Stretnutie 29.10.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Prečítané nejaké články. Inak nič.
|
||||
|
||||
Úlohy:
|
||||
|
||||
|
||||
- Podrobne si naštudujte a vyskúšajte framework Sentence Transformers https://sbert.net/index.html. Využite Google Colab na príklady.
|
||||
- Podrobne si naštudujte databázu MS MARCO. Zistite a vyskúšajte dotrénovanie anglického modelu typu BERT (bert, roberta, xlm, deberta ...) na databáze MS Marco.
|
||||
- Píšte si poznámky o tom čo ste zistili o SBERT. Použite odkazy na vedecké články. Vedecké články nájdete na Google Scholar.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- pracujte na servri quadro a prostredí Anaconda.
|
||||
- Natrénujte slovenský BERT model na preloženej databáze MS MARCO (WIP K. Sopkovič).
|
||||
|
||||
|
||||
|
||||
## Diplomový projekt 2024
|
||||
|
||||
Stretnutie 4.4. 2024
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Oboznámte sa s tým, ako funguje neurónová sieť typu Transformer. Urobte si poznámky. Poznačete si zdroje, uprednostnite vedecké články.
|
||||
- Oboznámte sa ako funguje rekurentná neurónová sieť. Sústreďte sa na typ RWKV. Urobte si poznmámy.
|
||||
- Vyskúšajte si túto NN. Začnite tu https://wiki.rwkv.com/basic/play.html
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Oboznámte sa ako funguje NN Mamba.
|
||||
- Zostavte RAG systém s pomocou RWKV.
|
||||
- Oboznámte sa ako funguje Sentence Transformer.
|
||||
- Porovnajte embeddingy RWKV s inými metódami (Sentence Transformers)
|
||||
|
||||
|
||||
Stretnutie 15.2.2024
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Oboznámte sa s prácou [K. Sopkovič](/students/2019/kristian_sopkovic) a [M. Stromko](/students/2019/michal_stromko).
|
||||
|
||||
|
||||
71
pages/students/2020/jakub_kristian_lukas/README.md
Normal file
@ -0,0 +1,71 @@
|
||||
---
|
||||
title: Jakub Kristián Lukas
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [bp2023]
|
||||
tag: [hatespeech]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
rok začiatku štúdia: 2020
|
||||
|
||||
# Bakalárska práca 2023
|
||||
|
||||
Téma: Systém pre rozpoznávanie nenávistnej reči v online diskusiách
|
||||
|
||||
Súvisí s PhD prácou [Manohar Gowdru Shridhara](students/2021/manohar_gowdru_shridharu)
|
||||
|
||||
Návrh na zadanie:
|
||||
|
||||
- Preštudovať teóriu.
|
||||
- Zopakovať jednoduchý experiment pre rozpoznávanie nenávistnej reči v anglickom jazyku s pomocou frameworku HuggingFace transformers.
|
||||
- Vypracovať webové demo.
|
||||
|
||||
Stretnutie 3.111.
|
||||
|
||||
Stav:
|
||||
|
||||
- štúdium Python.
|
||||
- Vyskúšané niektoré HF HS modely.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Prejdite si Streamlit tutoriál.
|
||||
- Pokračovať v otvorených úlohách. Spojazdnite streamlit HS demo. Píšte si poznámky z prehľadového článku, Prečítajte si súvisiace články a napíšte poznánky.
|
||||
|
||||
|
||||
Stretnutie 7.10.
|
||||
|
||||
Stav:
|
||||
|
||||
- Nainštalované prostredie Anadonda, HF, Pytorch
|
||||
- Zdieľaný priečinok [google drive](https://drive.google.com/drive/folders/1voblyxpAwsjNWBSFB-8F_heQCb5cGakJ?usp=sharing)
|
||||
- Vypracovaný text na 2 strany o BERT modeli.
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [ ] Prečítať a napísať poznámky na jednu stranu. Pozrite si aj súvisiace články,
|
||||
- https://arxiv.org/abs/2004.06465
|
||||
- [ ] Prejdite si HF Tutoriál.
|
||||
- [ ] Pozrite si https://git.kemt.fei.tuke.sk/mg240ia/Hate-Speech-Detector-Streamlit
|
||||
- [x] Prejdite si knihu Dive into Python 3.
|
||||
- [x] Vyskúšať a preštudovať tieto modely
|
||||
- https://huggingface.co/Hate-speech-CNERG/dehatebert-mono-english
|
||||
- https://huggingface.co/Narrativa/byt5-base-tweet-hate-detection
|
||||
|
||||
|
||||
Stretnutie 29.9.
|
||||
|
||||
Stav:
|
||||
- Oboznamili sme sa s projektom.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zistiť ako funguje model BERT. Napísať o tom správu na 2 strany. Priložiť odkazy na odborné články.
|
||||
- Nainštalovať si HuggingFace Transformers a vypracovať tutoriál. HF Transformers bude vyžadovať CUDA a Pytorch. Dostupné to je na školskom servri idoc.
|
||||
- [x] Nainštalovať Anaconda
|
||||
- [x] Nainštalovať Pytorch
|
||||
- [x] nainštalujete transformers.
|
||||
- [ ] prejdide si tutoriál
|
||||
|
||||
84
pages/students/2020/kamil_tomcufcik/README.md
Normal file
@ -0,0 +1,84 @@
|
||||
---
|
||||
title: Kamil Tomčufčík
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [dp2025]
|
||||
tag: [lm]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
rok začiatku štúdia: 2020
|
||||
|
||||
# Diplomová práca 2025
|
||||
|
||||
Ciel:
|
||||
|
||||
Overiť a zlepšiť možnosti generovania jednotkových testov
|
||||
|
||||
Zadanie:
|
||||
|
||||
1. Vypracujte prehľad veľkých jazykových modelov s podporou generovania programového kódu.
|
||||
2. Vyberte vhodnú dátovú množinu a metriku na vyhodnotenie generovania kódu.
|
||||
3. Navrhnite a vyhodnoťte experimenty s generovaním kódu s pomocou veľkého jazykového modelu.
|
||||
4. Identifikujte slabé miesta a navrhnite zlepšenia.
|
||||
|
||||
Stretnutie 12.12.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Metrika Pass@K sa používa na vyhodnotenie generovaného kódu. Meria, koľko automatických textov bolo splnených. Používa sa aj BLEU, verzia CodeBLEU. CodeJudge.
|
||||
- Na testovanie generovaných testov sa používajú: vykonanie produkčného kódu, pokrytie testov, mutácie kódu, statická analýza generovaného kódu.
|
||||
- Vyskúšaný model polycoder (na C),codeparrot (na python) na kaggle. Code T5 zatiaľ nie je vyskúšaný.
|
||||
- Copilot by mal byť pre študentov zadarmo. Študneti majú aj Azure kredity.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v otvorených úlohách.
|
||||
- Pripravte sa na predobhajobu - prezentácia s výsledkami.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Pomocou vybranej množiny porovnajte vybrané modely pre generovanie kódu.
|
||||
|
||||
Stretnutie 14.11. 2924
|
||||
|
||||
Stav:
|
||||
|
||||
- Vyhľadané modely na generovanie kódu. Nie sú vyskúšané. Codex, CodeParrot a Incoder. Na unittesty CodeT5 a AthenaTest.
|
||||
- Rozčítané knihy podľa pokynov.
|
||||
|
||||
Úlohy:
|
||||
|
||||
Zistite odpovede na tieto otázky:
|
||||
- [x] Ako zistíme, že vygenerovaný kód je dobrý.
|
||||
- [x] Ako zistíme, že vygenerovaný test vyhovuje špecifikácii?
|
||||
- [-] Vypracujte písomný prehľad modelov pre generovanie kódu. Napíšte aké modely sa používajú, Akým spôsobom sa vyhodnocujú. Napíšte na akej neurónovej sieti sú založené, aké sú veľk=, aké jazyky podporujú, aké výsledky dosahujú. Použite odborné články. Odborné články nájdete na google scholar alebo scopus.
|
||||
- [-] Pripravte vzorovú dátovú množinu. Hotové testy, implementácie aj dokumentáciu. Možno vybrať existujúci open source projekt alebo hotovú dátovú množinu.
|
||||
- [-] Vyskúšajte niekoľko jazykových modelov pre generovanie kódu aj generovanie testov.
|
||||
- [ ] Do diplomovej práce vypracujte experimenty kde vyhodnotíte jazykové modely pre generovanie testov v rôznych prostrediach.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Dotrénujte model pre lepšie generovansie testov.
|
||||
|
||||
|
||||
|
||||
Stretnutie online 5.2.2024:
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Nainštalujte si prostredie Anaconda, pozrite si knihu https://diveintopython3.net/
|
||||
Dive Into Python 3
|
||||
- pre úvod do neurónových sietí si prečítajte knihu https://d2l.ai/index.html Dive into Deep Learning — Dive into Deep Learning 1.0.3 documentation
|
||||
- vyskúšajte viac modelov pre generovanie kódu. Codex, Copilot, ChatGPT
|
||||
- zistite ako funguje veľký jazykový model
|
||||
|
||||
|
||||
Zásobník úloh (zadanie na ďalšie stretnutie):
|
||||
|
||||
- Zistite zoznam open source modelov pre generovanie kódu a porovnajte ich možnosti. Zoznam zapíšte do textového súboru.
|
||||
- Vyberte si jeden z modelov na generovanie kódu, nainštalujte si ho a vyskúšajte.
|
||||
- Zistite, ako sa číselne vyjadrí kvalita generovania počítačového kódu. Aké metriky sa používajú? Zistie aké trénovacie a vyhodnocovacie množiny sa používaju. Zoznam zapíšte do súboru.
|
||||
- Zistite, ako sa dá taký model "dotrénovať" na špecifickú úlohu generovania testov.
|
||||
|
||||
|
||||
109
pages/students/2020/matej_kobylan/README.md
Normal file
@ -0,0 +1,109 @@
|
||||
---
|
||||
title: Matej Kobyľan
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [bp2023]
|
||||
tag: [ir]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
rok začiatku štúdia: 2020
|
||||
|
||||
# Bakalárska práca 2024
|
||||
|
||||
Cieľ: Vytvoriť dialógový systém pre podporu komunikácie občana s mestom Košice
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zistite, čo je to Natural Language Understanding. Napíšte o tom správu na 2 strany.
|
||||
- Prečítajte si BP Samuel Horáni. https://opac.crzp.sk/?fn=detailBiblioForm&sid=A770A18E340C6018B48DE7BDD5C2 Napíšte čo ste sa dozvedeli.
|
||||
- Prečítajte si článok https://link.springer.com/article/10.1007/s10462-022-10248-8 a napíšte, čo ste sa dozvedeli.
|
||||
- Vyskúšajte si chatbota z repozitára https://git.kemt.fei.tuke.sk/sh662er/Rasa.
|
||||
Nainštalujte si https://pytorch.org/get-started/locally/
|
||||
Nainštalujte si https://github.com/hladek/spacy-skmodel
|
||||
- Skúste ho upraviť tak, aby dával informácie o meste Košice.
|
||||
|
||||
|
||||
|
||||
# Bakalárska práca 2023
|
||||
|
||||
Systém pre monitoring médií
|
||||
|
||||
Práca súvisí s [DP Michal Stromko](/students/2019/michal_stromko)
|
||||
|
||||
Návrh na zadanie:
|
||||
|
||||
- Navrhnite a implementuje systém pre extrakciu textu a metainfrmácií z webových stránok alebo sociálnych sietí
|
||||
- Modifikujte agenta pre získavanie textu tak aby do databázy ukladal sledované webové stránky v pravidelných intervaloch.
|
||||
- Aplikujte neurónovú sieť na klasifikáciu získaných článkov.
|
||||
|
||||
Analýza úlohy:
|
||||
|
||||
Chceme vytvoriť databázu novinových článkov.
|
||||
|
||||
Pre článok chceme evidovať:
|
||||
|
||||
- zdroj
|
||||
- autor
|
||||
- titulok
|
||||
- text rozdelený na odseky
|
||||
- odkazy na iné články
|
||||
- autorská sekcia
|
||||
- autorské tagy alebo kľúčové slovíčka.
|
||||
- perex
|
||||
- dátum vydania.
|
||||
- pôvodné html
|
||||
|
||||
Ku databáze chceme vytvoriť agenta ktorý by v pravidelných intervaloch dopĺňal nové články. Agenta pre zber textu stačí modifikovať.
|
||||
|
||||
Ku databáze chceme vytvoriť webové rozhranie.
|
||||
|
||||
V databáze chceme vedieť vyhľadávať.
|
||||
|
||||
Chceme vedieť automaticky zistiť tému článku.
|
||||
|
||||
Chceme automaticky zistiť sumár článku.
|
||||
|
||||
- Vyberte vhodnú databázu.
|
||||
- Postgres, Cassandra.
|
||||
- Navrhnite schému.
|
||||
- Modifikujte agenta pre zber textu.
|
||||
- Implementujte webové rozhranie na prístup k databáze.
|
||||
|
||||
|
||||
Stretnutie 24.1.2022
|
||||
|
||||
Stav:
|
||||
|
||||
- Začiatok štúdia Python.
|
||||
- Prečítané články: "COVID a kľúčové slová", o Elasticsearch.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračovať v otvorených úlohách z 30.9.
|
||||
- Zistite, čo je to systém RASA a ako pracuje.
|
||||
- Skúste prejsť tutoriál https://rasa.com/blog/category/tutorials/
|
||||
- Zvážiť zmenu témy na "RASA" dialógový systém.
|
||||
|
||||
|
||||
Stretnutie 30.9.2022
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Prečítajte si záverečné práce J. Holp, M. Stromko.
|
||||
- [ ] Nainštalujte si systém Anaconda. Naučte sa pracovať s virtuálnymi prostrediami.
|
||||
- [x] Prejdite si Python tutoriál.
|
||||
- [ ] Zistite ako pracuje agent pre zber textu - web crawler. Vyhľadajte odborné články alebo knihy na túto tému a urobte si poznámky.
|
||||
- [ ] Oboznámte sa s kódom agenta websucker https://git.kemt.fei.tuke.sk/dano/websucker-pip.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Pozrieť sa na https://github.com/microsoft/playwright-python
|
||||
- Zistite, ako funguje knižnica BeautifulSoup, vypracujte tutoriál.
|
||||
- Vypracujte prehľad literatúry na tému "Monitorovanie médií". Otvorte si google scholar, hyhľadajte heslo "news monitoring" , "social media monitoring". Vyberte články ktoré sa Vám zadajú zaujímavé, prečítajte si ch a napíšte na min. jednu stranu poznámky čo ste sa dozvedeli. Uveďte zdroje - názy článkov a autorov.
|
||||
- Zistite si, čo je systém Elasticsearch a ako pracuje. Napíšte o tom správu na jednu stranu.
|
||||
- Pomocou systému Docker si nainštalujte Elasticsearch 8.4
|
||||
- Prejdite si tutoriál https://elasticsearch-dsl.readthedocs.io/en/latest/index.html
|
||||
- Urobte si GIT repozitár, kde budeme dávať kódy.
|
||||
|
||||
138
pages/students/2020/matus_suchanic/README.md
Normal file
@ -0,0 +1,138 @@
|
||||
---
|
||||
title: Matúš Suchanič
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [vp2022,bp2023]
|
||||
tag: [ir]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
rok začiatku štúdia: 2020
|
||||
|
||||
# Bakalárska práca 2023
|
||||
|
||||
Téma: Vyhľadávanie na slovenskej Wikipédii
|
||||
|
||||
Úloha:
|
||||
|
||||
- Implementujte systém na kategorizáciu slovenských novinových článkov. Systém by mal kategorizovať ľubovoľný článok do wiki kategórií.
|
||||
- Vytvorte dátovú množinu pre vyhodnotenie kategorizácie na základe wiki kategórií.
|
||||
|
||||
Názov:
|
||||
|
||||
Automatická kategorizácia slovenského textu
|
||||
|
||||
1. Vypracujte prehľad najnovších metód kategorizácie textu pomocou neurónových sietí aj pomocou štatistických metód.
|
||||
2. Vyberte a pripravte vhodnú dátovú množinu pre otestovanie kategorizácie.
|
||||
3. Vyberte vhodnú metódu kategorizácie, pripravte a vykonajte experimenty na jej vyhodnotnie.
|
||||
4. Vyhodnoťte experimenty a identifikujte slabé miesta zvoleného prístupu.
|
||||
|
||||
Práca súvisí s:
|
||||
|
||||
- [DP Michal Stromko](/students/2019/michal_stromko)
|
||||
- [BP Matej Kobyľan](/students/2020/matej_kobylan)
|
||||
|
||||
Stretnutie 27.1.2023
|
||||
|
||||
Podmienky na zápočet:
|
||||
|
||||
- Pripravte slovenskú databázu na trénovanie úlohy klasifikácie článkov.
|
||||
- Zopakujte experiment pre klasifikáciu článkov v prostredí HF transformers.
|
||||
- Natrénujte vlastný model na HF transformers na klasifikáciu článkov.
|
||||
- Vykonaný experiment opíšte na min. 2 strany. Napíšte aký model sa používa, aký druh neurónovej siete. Ako prebieha dotrénovanie?
|
||||
|
||||
|
||||
Stretnutie 21.1.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Prečítané články, urobený report na cca 7 strán.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Boli vedúcim poskytnuté dáta, ktoré obsahujú názvy článkov, kategórie, aj texty článkov.
|
||||
- Urobte skript, ktorý spojí dáta tak, aby boli dáta spolu - názov, text a zoznam kategórií.
|
||||
- Natrénujte na týchto dátach neurónovú sieť pre kategorizáciu článkov.
|
||||
- Vedúci Vám poskytne ďalšiu množinu v takom istom formáte s vyhodnocovacími dátami. Na tejto množine to vyhodnotíte. Alebo rozdeľte trénovaciu množinu na dve časti a vyhodnocovaciu množinu dajte stranou.
|
||||
- Na klasifikáciu použite: toolkit transformers, model slovakbert, alebo model slovak gpt, slovak t5
|
||||
- Začnite písať BP. Do práce dajte definíciu úlohy a zoznam metód, ktorou sa táto úloha rieši. Vysvetlite, ako funguje klasifikácia dokumentov pomocou modelu BERT alebo Roberta, a GPT.
|
||||
Opíšte experiment - použitý model, použité dáta, spôsob vyhodnotenia a výsledky. Napíšte čo z toho vyplýva - kde je priestor na zlepšenie.
|
||||
|
||||
Stretnutie 28.10.2022
|
||||
|
||||
Stav:
|
||||
|
||||
- Preštudované články o text categorization, BERT, KNN. Napísaný krátky report.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v štúdiu odborných článkov o kategorizácii textu. Použite Scholar. Robte si poznámky, poznačte si bibl. odkazy. Min. 5 nových článkov. Toto pôjde do BP.
|
||||
- Pokračujte v experimente s HF transformers a kategorizáciou.
|
||||
- Pozrite si skripty na repozitári slovakretrieval a skúste ich rozbehnúť.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vytvorte skript, ktorý spracuje dump slovenskej wikipédie a zistí, ktorý článok patrí do ktorých kategórií. Cieľ je spraviť systém ktorý zaradí neznámy článok do wikipédia kategórií.
|
||||
- Spýtajte sa vedúceho na skripty ku spracovaniu dumpu wikipédie.
|
||||
|
||||
|
||||
Stretnutie 30.9.2022:
|
||||
|
||||
Stav:
|
||||
|
||||
- Je nainštalovaný Anaconda a HF transformers.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Prečítajte si BP Michal Stromko a DP Ján Holp. Napíšte z toho poznámky na pol strany.
|
||||
- [x] Zistite, čo to je model BERT a ako sa s sním pracuje. Napíšte o tom poznámku.
|
||||
- [-] Vypracujte prehľad novej odbornej literatúry na tému Text Categorization. Zistite aké štatistické a neurónové metódy sa používajú. Ako základ Vám poslúži článok nižšie. Prehľad by mal mať aspoň 2 strany.
|
||||
- [x] Prečítajte si článok "Comparison of Statistical Algorithms and Deep Learning for Slovak Document Classification" https://ieeexplore.ieee.org/abstract/document/9869155 dostupný z TUKE siete. Napíšte na pol strany čo ste sa dozvedeli.
|
||||
|
||||
- [ ] Zopakujte experiment s klasifikáciou slovenských novinových článkov. Použite knižnicu HF transformers, Skripty Vám dodá vedúci. Použite knižnicu HF transformers, Skripty Vám dodá vedúci. Použite "Slovak Categorized News Corpus" na trénovanie.
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- [ ] Pripravte skript, ktorý bude vedieť klasifikovať neznáme články uložené v databáze.
|
||||
|
||||
# Vedecký projekt 2022
|
||||
|
||||
Extrakcia informácií z webových stránok
|
||||
|
||||
Finálny cieľ:
|
||||
|
||||
- Vytvoriť skript ktorý spracuje HTML kód a identifikuje zaujímavé časti z webstránky, napr. noviny alebo diskusie (modrý koník)
|
||||
- Naučte sa niečo o spracovaní prirodzeného jazyka
|
||||
|
||||
Výstupy:
|
||||
|
||||
- Report na cca 4 strany - ako si nainštalovať anacondu, niečo o knižnici HuggingFace Transformers
|
||||
- Skript na parsovanie dvoch stránok
|
||||
|
||||
Stretnutie 3.6.
|
||||
|
||||
Stav:
|
||||
|
||||
- Odovzdaná písomná správa nie je uspokojivá.
|
||||
|
||||
Úlohy:
|
||||
|
||||
|
||||
- Nainštalujte si Hugging Face Transformers
|
||||
- Prejdite si tento tutoriál, https://huggingface.co/docs/transformers/tasks/sequence_classification. Po slovensky zapíšte vlastnými slovami čo ste urobili a čo ste zistili. Zapíšte každý krok.
|
||||
- Vlastnými slovami zapíšte, čo všetko bude potrebné urobiť, aby sme vedeli klasifikovať slovenské texty.
|
||||
- Vytvorte si GIT repozitár a dajte do neho vytvorené skripty na parsovanie stránok.
|
||||
|
||||
Stretnutie 18.3.2022
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Nainštalovať si systém Anaconda
|
||||
- Napíšte návod ako nainštalovať a používať systém Anacona
|
||||
- Nainštalovať si knižnicu BeautifulSoup4, prejsť si tutoriál
|
||||
- napíšte krátky úvod do knižnice Huggingface Transformers
|
||||
- Prečítajte si články o hlbokých neurónových sieťach a spracovaní prirodzeného jazyka
|
||||
|
||||
|
||||
|
||||
163
pages/students/2020/pavol_hudak/README.md
Normal file
@ -0,0 +1,163 @@
|
||||
---
|
||||
title: Pavol Hudák
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [dp2025]
|
||||
tag: [nlp,qa]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
rok začiatku štúdia: 2020
|
||||
|
||||
# Diplomová práca 2025
|
||||
|
||||
Dotrénovanie veľkého jazykového modelu na odpovede v slovenčine
|
||||
|
||||
Zadanie:
|
||||
|
||||
1. Vypracujte prehľad veľkých jazykových modelov v slovenčine.
|
||||
2. Vypracujte prehľad metód dotrénovania veľkých jazykových modelov.
|
||||
3. Vyberte vhodnú dátovú množinu v slovenčine a dotrénujte veľký jazykový model.
|
||||
4. Vyhodnoťte experimenty a navrhnite zlepšenia.
|
||||
|
||||
|
||||
|
||||
Ciel:
|
||||
|
||||
- Dotrénovanie LLM pre zlepšenie jeho schopnosti odpovedať na otázku v slovenskom jazyku.
|
||||
- Dotrénovanie a vyhodnotenie LLM na slovenský instruct dataset.
|
||||
- Strojový preklad vybranej množiny instruct.
|
||||
|
||||
Stretnutie 21.2.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Natrénovaný Mistral 7B Slovak Alpaca (celej, 4 epochy) na quadro.
|
||||
- Strojové preklady Seamless do angličtiny (neviem na čo).
|
||||
- Použitý model Opus na backtranslation - alpaca.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zlepšite štruktúru aj text DP.
|
||||
- Vyhodnotte výsledný model. Vedúci dodá skripty. Alebo dodajte model vedúcemu. Výsledky dajte do práce.
|
||||
|
||||
|
||||
Zásobník uloh:
|
||||
|
||||
- Dotrénujte iný model, napr. GEMMA.
|
||||
- Po vyhodnotení skúste zlepšiť model - pridať nové dáta, pridať epochy.
|
||||
- Strojovo preložte vhodné zdroje na dotrénovanie. Konzultujte vedúceho.
|
||||
|
||||
|
||||
|
||||
Stretnutie 14.11.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Dotrénovaný slovenský Mistral 7B na malej časti Slovak Alpaca ma Kaggle.
|
||||
- Pokračuje písanie.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračovať v trénovaní tak aby sa využila celá množina. Môžeme využiť školské servre. Vedúci vytvorí prístup.
|
||||
- Pokračujte v písaní
|
||||
- Zdrojové kódy dajte na GIT. Nedávajte tam dáta ani modely.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Dotrénujte aj iné modely a porovnajte výsledky.
|
||||
- Zverejnite dotrénovaný model alebo viac modelov na HF HUB. využijeme TUKE-KEMT org.
|
||||
|
||||
|
||||
Stretnutie 15.10.
|
||||
|
||||
Stav:
|
||||
|
||||
- Napísané 4 strany poznámok o Transformers.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Dotrénujte slovenský model na instruct množine. Ako model použite https://huggingface.co/slovak-nlp/mistral-sk-7b a PEFT.
|
||||
- Nainštalujte si Ctranslate2 a model https://huggingface.co/facebook/m2m100_1.2B. Skúste preložiť OpenORCA.
|
||||
Použite server quadro alebo Kaggle.
|
||||
- Pracujte na texte DP - vysvetlite ako funguje model ChatGPT, Mistral a napíšte ako funguje "instruct model", uvedte odkazy na odborné články.
|
||||
|
||||
|
||||
|
||||
|
||||
# Diplomový projekt 2024
|
||||
|
||||
Ciele na semester:
|
||||
|
||||
- Zobrať veľký jazykový model (základný alebo instruct alebo chat).
|
||||
- Skúsiť ho dotrénovať metódou PEFT pre úlohu Question Answering na korpuse SK QUAD. Vieme sa inšpirovať výsledkami E. Matovka.
|
||||
- Strojovo preložiť vybranú databázu otázok a odpovedí a pomocou nej skúsiť vylepšiť model.
|
||||
- Vyhodnotiť presnosť QA dotrénovaného modelu.
|
||||
|
||||
Ďalšie nápady:
|
||||
|
||||
- Automaticky zlepšiť "prompt" pre QA.
|
||||
|
||||
Vybrať jednu z úloh:
|
||||
|
||||
- Tvorba instruct datasetu - Anotácia alebo preklad množín
|
||||
- Dotrénovanie LLM na dostupnom hardvéri - LORA-PEFT
|
||||
|
||||
|
||||
Stretnutie 7.6.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Práca na dotrénovaní LLama3 a Phi2 cez kaggle, zatiaľ nefunguje.
|
||||
|
||||
Stretnutie 5.4.
|
||||
|
||||
Stav:
|
||||
|
||||
- Nainštalované PrivateGPT.
|
||||
- Nainštalovaná Anaconda a Python, aj štúdium a príprava.
|
||||
- Oboznámenie sa s LangChain a SlovakAlpaca aj PEFT.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Skúste dotrénovať veľký jazykový model metódou PEFT s množinou SlovakAlpaca. Vyberte vhodný model.
|
||||
- Vyskúšajte modely cez ollama.
|
||||
- Prihláste sa na quadro.kemt.fei.tuke.sk tam nainštalujte anaconda. Vedúci Vám musí urobiť prístup.
|
||||
- Kandidáti sú UMT5, TinyLLama, LLama3, Mistral, mt0, Phi alebo iné.
|
||||
- Vyhodnote presnosť dotrénovania (BLEU - založené na porovnávaní ngramov výsledku a očakávania).
|
||||
- Robte si poznámky o tom ako funguje veľký jazykový model a metóda PEFT.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Strojovo preložiť databázu OpenORCA.
|
||||
|
||||
Stretnutie 23.2.
|
||||
|
||||
Stav:
|
||||
|
||||
- Rozbehané prostredie s Pytorch aj CUDA Anaconda na vlastnom PC.
|
||||
- Vyskúšaný HF google/t5 ... na úlohu strojového prekladu
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v štúdiu podľa otvorených úloh.
|
||||
- Nainštalujte a vyskúšajte softvér PrivateGPT.
|
||||
- Prihláste sa na systém IDOC a nainštalujte si tam systém Anaconda.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Nainštalujte a vyskúšajte balíček LangChain.
|
||||
- Zistite čo je to metóda PEFT - LORA.
|
||||
- Skúste dotrénovať veľký jazykový model s množinou SlovakAlpaca.
|
||||
- Skúste vylepšiť LLM pomocou inej množiny, strojovo preloženej.
|
||||
|
||||
Stretnutie 14.2.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [ ] Oboznámiť sa s veľkými jazykovými modelmi LLM. Ako funguje ChatGPT? Čo je to LLAMA? Napíšte si poznámky.
|
||||
- [x] Nainštalujte si Anaconda.
|
||||
- [-] Pokračujte v štúdiu Python. Preštudujte si knihu Dive deep into deep learning.
|
||||
- [x] Nainštalujte si knižnicu Huggingface Transformers.
|
||||
- [ ] Vyskúšajte LLM model LLAMA https://huggingface.co/meta-llama/Llama-2-70b
|
||||
- [ ] Prejdite si tento tutoriál https://huggingface.co/blog/llama2
|
||||
181
pages/students/2020/vladyslav_krupko/README.md
Normal file
@ -0,0 +1,181 @@
|
||||
---
|
||||
title: Vladyslav Krupko
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [bp2024]
|
||||
tag: [spelling]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
rok začiatku štúdia: 2020
|
||||
|
||||
# Bakalárska práca 2024
|
||||
|
||||
|
||||
1. Napíšte prehľad existujúcich jazykových modelov pre generovanie slovenského jazyka.
|
||||
2. Získajte a pripravte korpus dát pre úlohu generovania odpovedí v slovenskom jazyku. Vyberte vhodný zdroj a pripravte ho do podoby vhodnej na trénovanie neurónových sietí. Sumarizujte získané dáta v tabuľke.
|
||||
3. Natrénujte neurónovú sieť pre úlohu generovania odpovede a vyhodnoťte výsledky.
|
||||
4. Vyhodnoťte experimenty, identifikujte slabé miesta a navrhnite vylepšenia.
|
||||
|
||||
|
||||
Na Maise je vypísaná nová téma ohľadom "konverzačnej umelej inteligencie". Je potrebné čím skôr finalizovať tému aj praconvé úlohy.
|
||||
|
||||
Ciele:
|
||||
|
||||
- Dotrénovať ChatGPT alebo iný generatívny model pre vlastnú databázu otázok a odpovedí.
|
||||
|
||||
Stretnutie 15.5.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Rozpísaná práca
|
||||
- Experimenty sú pripravené (podrobne neviem).
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Dajte prácu do šablóny a vypracujte ASAP.
|
||||
- Do práce môžete dokresliť diagramy. Dôsledne citujte - uvádzajte referencie aj pre obrázky.
|
||||
- Stiahnite si zadávací list a šablónu z ETD knižnice.
|
||||
- Zaregistrujte sa do knižnice na vytlačenie práce. Na to budete potrebovať titulný list a počet strán.
|
||||
- Pošlite vedúcemu na kontrolu čím skôr (do budúceho utorka).
|
||||
- Na vyhodnotenie generatívneho modelu použite metriku BLEU. Na to potrebujete očakávaný výstup modelu.
|
||||
|
||||
Stretnutie 26.4. 2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Práca na dátach GymBeam. Scraper ide. Máme otázky o procese objednania.
|
||||
- Vyskúšané mt5, llama 2 7B, mixtral,
|
||||
|
||||
Úloha:
|
||||
|
||||
- Pripravte dáta na úlohu odpovede na otázku. V jednej jednotke by mala byť otázka, odpoveď a dokument kde sa nachádza odpoveď. Urobte niekoľko 100 jednotiek. Dáta rozdeľte na dve skupiny - trénovaciu aj testovaciu. Dáta dajte do podoby kompatibilnej s databázou sk-quad.
|
||||
- Ku Vašim dátam môžete primešať dáta zo SK QUAD.
|
||||
- Naučte rôzne neurónové siete mt5base, Slovakbert, llama odpovedať na otázku a vyhodnnotte výsledky. Na quadro nainštaluje Anaconda.
|
||||
- Nainštalujte Pytorch, Transformers z repozitára. Použite screen alebo tmux na spustenie.Kartu vyberiete pomocou premennej prostredia CUDA_VISIBLE_DEVICES.
|
||||
- Použite skripty z https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering .
|
||||
- Pokračujte v písaní práce.
|
||||
|
||||
Zásobník:
|
||||
|
||||
- Na dotrénovanie LLAMA alebo podobného modelu musíte použiť PEFT. https://www.theaidream.com/post/fine-tuning-large-language-models-llms-using-peft
|
||||
|
||||
|
||||
Stretnutie 29.1.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Prezentácia je.
|
||||
- Získané dáta z GymBeam. Selenium Scraper je veľmi pomalý, nevieme prečo.
|
||||
- Vyskúšané ChatGPT API s dátami čo máme. Odpoveď je zatiaľ po anglicky.
|
||||
- Na prevod z csv do json je použitá LLAMA.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Na vyhdonotenie je potrebné rozdeliť dáta na dve časti, trénovaciu a testovaciu. Testovacie dáta vynechajte z trénovania. Sledujte čo generuje model a porovnajte to s tým čo je očakávané v dátach. Ako metriku porovnania použite ROUGE alebo BLEU.
|
||||
- Výsledky dajte do tabuľky do práce.
|
||||
- Pokračujte v písaní práce.
|
||||
- Pokračujte v získavaní a príprave dát.
|
||||
|
||||
Zásobník:
|
||||
|
||||
- Na rovnakých dátach natrénujte "lokálny model" pomocou skriptov Huggingface (machine translation) - mt5-base, llama-7B-4bit . Musíte nainštalovať transformers zo zdrojákov. Musíte si vytvoriť nové virtuálne prostredie a najprv nainštalovať pytorch.
|
||||
|
||||
|
||||
|
||||
Stretnutie 15.12.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Napísané texty podľa pokynov. Experimenty ešte neboli vykonané.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Z webu získajte vhodnú sadu otázok a odpovedí. Uložte ju vo formáte json - jeden dokument na jede riadok. Využite Váš scraper. Ako zdroj skúste použiť Otázky zákazníkov z GymBeam. Uložte - v jednom dokumente by mal byť informácie o produktem otázky aj odpovede. Ak sa to nepodarí, zamerajte sa na iný zdroj dát. Napríklad https://www.modrastrecha.sk/forum/ , alebo https://www.modrykonik.sk/forum.
|
||||
- Pripravte dáta do vhodnej podoby a natrénujte generatívny model - ChatGPT, T5-SMALL,
|
||||
- Vyhoddnotte všetky modely, výsledky sumarizujte v tabuľkách. Experimenty opíšte do práce.
|
||||
- Urobte si repozitár bp2024 na git.kemt.fei.tuke.sk. Skripty dávajte na git.
|
||||
|
||||
|
||||
|
||||
Stretnutie 21.11.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Napísaný text na tému Seq2Seq.
|
||||
- Napísaný scraper pre získavanie dát z E shopu.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Skúste dotrénovať model ChatGPT. Využijeme kredity [Azure pre študentov](https://azureforeducation.microsoft.com/devtools) . Prihlásite sa ako študent do MAISU. Prejdite si [tutoriál](https://learn.microsoft.com/en-us/azure/ai-services/openai/how-to/fine-tuning?tabs=turbo&pivots=programming-language-studio). Dávajte pozor, aby ste si nevyčerpali študentské kredity.
|
||||
- Zistite, ako funguje ChatGPT a ako ho dotrénovať. Prečítajte si niekoľko blogov a napíšte si poznámky. Použite aj odkazy na odborné články.
|
||||
- Zistite, ako vyhodnotiť dotrénovaný model. Ako funguje https://github.com/openai/evals ? Napíšte o tom poznánky.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Na generovanie odpovedí použijeme jednoduchý model T5-small v HF transformers.
|
||||
- Vytvorte trénovaciu databázu ktorá Vás zaujíma vo formáte ktorý je požadovaný. Druhá možnosť je využiť "Košické dáta".
|
||||
- Preštudujte si knihu https://d2l.ai/ a napíšte si z nej poznámky.
|
||||
- Zistite ako funguje model T5 a model BART a napíšte o tom správu na 3 strany. Odborné články vyhľadajte na Google Scholar. Do správy zapíšte ktoré odborné články ste prečítali.
|
||||
- Nainštalujte si prostredie Anaconda.
|
||||
- Nainštalujte si knižnicu HF transformers, prejdite si základný tutoriál.
|
||||
- Prejdite si tutoriál https://huggingface.co/docs/transformers/tasks/summarization
|
||||
|
||||
|
||||
# Bakalárska práca 2023
|
||||
|
||||
Téma: Oprava preklepov v slovenskom jazyku.
|
||||
|
||||
Súvisiaca dizertačná práca [Maroš Harahus](/students/2016/maros_harahus).
|
||||
|
||||
Cieľ:
|
||||
|
||||
- Naštudovať si problematiku opravy preklepov a napísať prehľad aktuálnych metód.
|
||||
- Vykonať jednoduchý experiment na automatickú opravu preklepov pomocou neurónovej siete.
|
||||
- Naprogramovať webovú demo aplikáciu.
|
||||
|
||||
|
||||
|
||||
Stretnutie 28.9.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Nainštalovaná Anaconda, problém s CUDA.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v otvorených úlohách z minulého roka.
|
||||
- Na inštalovanie Pytorch je potrebné nainštalovať najprv CUDa cez Anaconda.
|
||||
|
||||
conda install pytorch==1.10.0 torchvision==0.11.0 torchaudio==0.10.0 cudatoolkit=10.2 -c pytorch
|
||||
|
||||
Nápad:
|
||||
|
||||
- Natrénovať chatbota pre pomoc zákazníkom. Aké trénovacie dáta a aký model použiť?
|
||||
|
||||
Stretnutie 29.9.2022
|
||||
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [ ] Prečítajte si článok "Survey of Automatic Spelling Correction" a napíšte z neho poznámky na cca 2 strany.
|
||||
- [ ] Prečítajte si článok Comparison of recurrent neural networks for slovak punctuation restoration.
|
||||
- [ ] Zistite, ako funguje neurónový strojový preklad. Prečítajte si niekoľko blogov a napíšte si poznámky na jednu stranu, uveďte aj odkazy na články. Kľúčové slovíčko je enkóder-dekóder architektúra.
|
||||
- [x] Nainštalujte si systém Anaconda.
|
||||
- [-] Nainštalujte si knižnicu Pytorch
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- [ ] Nainštalujte si systém Fairseq
|
||||
- [ ] Prejdite si aspoň jeden fairseq tutoriál, napr. https://fairseq.readthedocs.io/en/latest/tutorial_simple_lstm.html
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vybrať dáta a urobiť experiment.
|
||||
- naprogramovať demo.
|
||||
|
||||
|
||||
|
||||
|
||||
220
pages/students/2021/artur_hyrenko/README.md
Normal file
@ -0,0 +1,220 @@
|
||||
---
|
||||
title: Artur Hyrenko
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [dp2026]
|
||||
tag: [chatbot,rasa,dialog,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
|
||||
rok začiatku štúdia: 2021
|
||||
|
||||
# Diplomová práca 2026
|
||||
|
||||
Zvýšenie bezpečnosti veľkých jazykových modelov
|
||||
|
||||
Zadanie:
|
||||
|
||||
1. Vypracujte prehľad súčasného stavu výskumu v oblasti zvyšovania bezpečnosti veľkých jazykových modelov, vrátane identifikácie známych bezpečnostných problémov a spôsobov ich vyhodnotenia.
|
||||
2. Vyberte vhodnú trénovaciu sadu a zarovnajte vybraný jazykový model s cieľom zvýšiť jeho bezpečnosť.
|
||||
3. Vyberte vhodnú testovaciu sadu a vyhodnoťte bezpečnosť viacerých modelov, vrátane zarovnaného modelu.
|
||||
4. Na základe experimentov predložte konkrétne odporúčania pre ďalšie zlepšenia bezpečnosti modelov v slovenskom jazyku.
|
||||
|
||||
Vyhodnotenie jazykových modelov
|
||||
|
||||
https://git.kemt.fei.tuke.sk/ah866cw/DP
|
||||
|
||||
(pre bezpečnostné problémy)
|
||||
|
||||
Možné ciele:
|
||||
|
||||
- Zistiť, či sú súčasné jazykové modely bezpečné. Aké problémy obsahujú? Menia bezpečnostné vlastnosti na základe jazyka?
|
||||
- Vyhodnotiť viacero jazykových modelov vo viacerých jazykoch.
|
||||
- Navrhnúť zlepšenia na zvýšenie bezpečnosti.
|
||||
|
||||
Stretnutie 3.2.
|
||||
|
||||
Stav:
|
||||
- Dotrénovaný Slovak Mistral - DPO aj SFT
|
||||
- práca na texte
|
||||
- trénovacie dáta sú založené na preklade pomocou NLLB - LIbrai/do-not-answer
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vyjadrite mieru zlepšenia v jednotlivých krokoch dotrénovania modelu Slovak Mistral vzhľadom na testovaciu množinu.
|
||||
- Urobte podobný proces aj pre iný model a porovnajte výsledky.
|
||||
- Do práce dajte tabuľku, hyperparametre trénovania, modelov aj trénovací postup v textovej podobe.
|
||||
- Pokračujte v práci na texte.
|
||||
|
||||
|
||||
Stretnutie 19.12.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Nie je progress
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v písaní a trénovaní ľubovoľného modelu.
|
||||
- Vyhodnoťte, zarovnajte a zlepšite Slovak Mistral, Slovak T5 large.
|
||||
- Možno bude potrebné vygenerovať trénovacie dáta v slovenčine. Na generovanie použite "abliterated" alebo "uncensored" modely. (napr. qwen3)
|
||||
|
||||
Stretnutie 18.11.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Preskúmané metriky: Unsafe rate, severity, toxicity, overrefusal, jailbreak. Vyžadujú si model alebo človeka.
|
||||
- Datasety: "LibrAI/do-not-answer","walledai/HarmBench","allenai/real-toxicity-prompts","toxigen/toxigen-data", "AlignmentResearch/AdvBench".
|
||||
- LLamaGuard3 je model pre detekciu nebezpečných promptov.
|
||||
- Sú vyhodnotené modely LLama, Qwen, Gemma.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Skúste zlepšiť bezpečnosť ľubovoľného modelu pomocu zarovnania DPO alebo iné. Skript dajte na git. Na trénovanie a vyhodnotenie je potrebné použiť iné dáta.
|
||||
- Pokračujte v písaní - metriky, modely, spôsob zarovnania. Opíšte experimenty - porovnanie modelov, dotrénovnaie modelov. Citujte články z Google Scholar.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vyhodnoťte, zarovnajte a zlepšite Slovak Mistral, Slovak T5 large.
|
||||
|
||||
Stretnutie 3.11.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Vyskúšané modely (mistral, openchat) pre generovanie nebezpečných odpovedí a pre detekciu nebezpečných promptov.
|
||||
- Splnená väčšina otvorených úloh.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Ako číselne vyhodnotiť "nebezpečnosť modelu"? Prečítajte si články. Aké sú metriky? Aké sú databázy?
|
||||
- [x] Nájsť alebo natrénovať model pre detekciu nebezpečných promptov a nebezpečných odpovedí.
|
||||
- [x] Číselne porovnajte nebezpečnosť viacerých modelov. llama, gemma, qwen gpt-oss, Výsledky dajte do tabuľky.
|
||||
- [x] Vybrať vhodný model pre potlačenie nebezpečných odpovedí pomocou DPO. Ako hodnotenie poslúži datababáza nebezpečných promptov, alebo iný model alebo aj náhodná hodnota.
|
||||
- [x] Skripty dávajte na GIT.
|
||||
- [x] Pokračujte v písaní.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Zarovnajte ľubovoľný model zvolenou metódou.
|
||||
- Pripravte postup pre zarovnanie slovenského modelu.
|
||||
|
||||
Stretnutie 10.10.2025:
|
||||
|
||||
Stav:
|
||||
|
||||
Preštudované:
|
||||
|
||||
- https://github.com/EleutherAI/lm-evaluation-harness?utm_source=chatgpt.com
|
||||
- https://github.com/confident-ai/deepeval?utm_source=chatgpt.com
|
||||
- https://github.com/open-compass/opencompass?utm_source=chatgpt.com
|
||||
- https://github.com/explodinggradients/ragas?utm_source=chatgpt.com
|
||||
- https://github.com/braintrustdata/autoevals?utm_source=chatgpt.com
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] pozrite si databázy PKU-Alignment/PKU-SafeRLHF alebo aurora-m/adversarial-prompts . Vyhľadajte iné databázy.
|
||||
- [x] Vyskúšajte LLM s týmito databázami. Ako sa bydú správať?
|
||||
- [x] Oboznámte sa s pojmom LLM alignment. Ako upravíme správanie jazykového modelu pomocou reinformcement learning?
|
||||
- [ ] Používajte google scholar a píšte si poznámky.
|
||||
- [-] Pokračujte v otvorených úlohách - DPO.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vybrať metódy, vybrať databázu a vybrať model. Databázu vieme aj generovať - augmentovať. Alebo ju vieme ručne upraviť.
|
||||
- Niektorú databázu viem aj preložiť. Prístup vieme použiť aj na nový jazykový model slovak-t5-large.
|
||||
- Ako sa správajú modely v rôznych jazykoch?
|
||||
- vyhodnotiť model z hľadiska bezpečnosti.
|
||||
- upraviť správanie modelu tak aby sa zlepšilo.
|
||||
|
||||
Stretnutie 2.10. :
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v otvorených úlohách. Kľúčové slovíčka: Python, TRL , LLM.
|
||||
- Zistite čo je to Reinforcement Learning, RLHF, DPO, PEFT.
|
||||
- Vyskúšajte si voľne dostupné LLM pomocou ollama. gpt-oss, gemma, qwen.
|
||||
- Pozrite si databázy "nebezpečných promptov". Prečítajte si články. Pozrite si, aké články ich citujú. Použite google scholar.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Zopakujte a vylepšite experimenty vo vybranom článku.
|
||||
- Finalizovať zadanie diplomovej práce.
|
||||
|
||||
Stretnutie 11.6. :
|
||||
|
||||
- Štúdium a vyskúšanie Python, Anaconda Transformers
|
||||
- Písomné poznámky.
|
||||
- Zistil, že ChatGPT dokáže poradiť s útokom na AP alebo na iný server. Netreba to (model) veľa presviedčať.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v praktickej príprave - Transformers
|
||||
- Vyskúšajte a naštudujte Huggingface TRL. Ako sa dá v modeloch potlačiť toxické správanie? Zistite čo je to RLHF.
|
||||
- Zistite, ako sa vyhodnocujú všeobecné jazykové modely.
|
||||
- Preštudujte si [prácu](https://dspace.cvut.cz/bitstream/handle/10467/115227/F3-DP-2024-Jirkovsky-Adam-DP-final.pdf?sequence=-1&isAllowed=y) a [článok](https://arxiv.org/abs/2412.01020)/
|
||||
- Vyhľadajte a preskúmajte existujúce dátové sady nebezpečných promptov. "corpus of dangerous-harmful prompts".
|
||||
- Zistite, ako sa vyhodnocujú modely z hľadiska bezpečnosti. Aké škody môžu spôsobiť jazykové modely? Napíšte poznámnky.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Rozšírte a preložte nebezpečné prompty. Aby sme dostali viacjazyčnú sadu (Slovensko-Anglicko-Ruská-Ukrajinská).
|
||||
- Pomocu tejto sady vyhodnoťte viacero jazykových modelov.
|
||||
- Implementujte vlastnú metódu na zvýšenie bezpečnosti modelu.
|
||||
|
||||
|
||||
Stretnutie 4.4.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Preštudované niektoré jazykové modely.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Pokračujte v štúdiu Python, Anaconda, Transformers, dive into deep learning.
|
||||
- [x] Napíšte poznámky o tom ako funguje model typu GPT, napr. LLAMA alebo DeepSeek. Napíšte ako sa trénuje - čo na to potrebujeme a v akých fázach to prebieha. Napíšte aj odkazy na odbornú literatúru.
|
||||
- [x] Zisite ako prebieha dotrénovanie pomocou PEFT-LORA a napíšte o tom poznáky,
|
||||
- [x] Zistite ako prebieha dotrénovanie typu reinforcement learning a napíšte o tom poznámky.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Môžeme riešiť problém bezpečnosti jazykových modelov. Ako upraviť model tak, aby neprezradil citlivé alebo nebezpečné informácie.
|
||||
- Dotrénujme existujúci jazykový model (napr. SlovakMistral) na úlohu instruct a využime reinforcement learning na potlačenie neželaných vlastností.
|
||||
|
||||
|
||||
Stretnutie 28.2.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Vyskúšané LM (cez ollama, aj API) Python (in progress).
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v štúdiu.
|
||||
- Pozrite sa na článok a dataset https://github.com/kinit-sk/gest . Urobte si poznámky. Zistite aké jazykové modely majú podporu slovenského jazyka. Zistite ako sa vyhodnocuje bias v jazykových modelov. Zistite, aké podobné množiny existujú pre iné jazyky.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Porovnajte viaceré modely pre mieru výskyt rodových stereotypov. Môže byť aj pre viaceré jazyky (slovenčina, angličtina, ruština).
|
||||
- Zistitie, ako je možné potlačiť neželané vlastnosti modelu. (https://huggingface.co/docs/trl/en/index, https://github.com/allenai/open-instruct).
|
||||
|
||||
Stretnutie 5.2.2025
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Oboznámte sa s problematikou veľkých jazykových modelov. Towards Data Science
|
||||
- Naučte sa Python lepšie
|
||||
- Poučte sa o strojovom účení.
|
||||
- Vyskúšajte si framework HF Transformers
|
||||
- Vyskúšajte si veľký jazykový model, napr. cez systém OLLAMA.
|
||||
- Oboznámte sa s frameworkom lm-eval-harness. Zistite, aké úlohy a aké metriky sa používajú.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Nájdite na webe zaujímavý zdroj otázok a odpovedí, ktorý by bol vhodný na vyhodnotneie jazykového modelu.
|
||||
- Vyberte úlohu vhodnú na anotáciu (spolu s vedúcim).
|
||||
|
||||
|
||||
|
||||
|
||||
191
pages/students/2021/eduard_matovka/README.md
Normal file
@ -0,0 +1,191 @@
|
||||
---
|
||||
title: Eduard Matovka
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [bp2024]
|
||||
tag: [dialog,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
rok začiatku štúdia: 2021
|
||||
|
||||
# Bakalárska práca 2024
|
||||
|
||||
Spolupráca [Vladimír Ferko](/students/2021/vladimir_ferko)
|
||||
|
||||
Nadväzuje [Martin Jancura](/students/2017/martin_jancura)
|
||||
|
||||
Názov: Slovenská konverzačná umelá inteligencia
|
||||
|
||||
Predbežný cieľ:
|
||||
|
||||
Natrénovať jazykový model pre jednoduchú slovenskú konverzáciu.
|
||||
|
||||
Zadanie BP:
|
||||
|
||||
1. Vypracujte prehľad modelov a dátových množín pre generovanie slovenského jazyka.
|
||||
2. Opíšte metódy dotrénovania generatívnych jazykových modelov.
|
||||
3. Vyberte vhodnú dátovú množinu a dotrénujte model pre plnenie jednoduchých úloh podľa zadaných inštrukcií.
|
||||
4. Vyhodnoťte natrénovaný model, identifikujte jeho slabé miesta a navrhnite zlepšenia.
|
||||
|
||||
Predbežné úlohy:
|
||||
|
||||
- Oboznámte sa s existujúcimi modelmi pre generovanie slovenského jazyka.
|
||||
- Pripravte korpus diskusií v slovenskom jazyku. Vyberte vhodný zdroj diskusí a pripravte ho do podoby vhodnej na trénovanie neurónových sietí. Napr. modrý koník, modrá strecha, íné diskusie.
|
||||
- Natrénujte neurónovú sieť pre odpovedanie v diskusiách.
|
||||
- Vytvorte webové demo.
|
||||
- Napísať vedecký článok z BP
|
||||
|
||||
|
||||
Stretnutie 12.4.
|
||||
|
||||
Stav:
|
||||
|
||||
- Vyskúšaná LLAMA2 cez HF AutoTrain (SlovakAlpaca+). Je náročná na RAM. Zatiaľ to vyzerá horšie ako LLAMA1.
|
||||
- Práca na texte.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vyskúšajte model Gemma. Vyskúšajte model RWKV (tento nie je Trannsformer, je to RNN) s množinou SlovakAlpaca. Výsledky experimentov (BLEU alebo ROUGE) dajte do tabuľky.
|
||||
- Pokračujte v písaní práce. Opíšte experimenty. Opíšte aj dataset ktorý používate. V teroetickej časti opíšte metódy neurónových sietí aj úlohu ktorú riešime. Ako súvisí s konverzáciou.
|
||||
- Pokračujte v otvorených úlohách: Zdrojáky dajte na git, dáta na školský server.
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Ako zlepšíme veľké jazykové modely pre slovenčinu?
|
||||
|
||||
|
||||
Stretnutie 8.3.
|
||||
|
||||
Stav:
|
||||
|
||||
- Práca na evaluatore - Preštudované [LLAMA evaluator od NVIDIA](https://docs.nvidia.com/nemo-framework/user-guide/latest/llama/evaluation.html).
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vyskúšajte knižnicu https://github.com/EleutherAI/lm-evaluation-harness. Zistite, ako sa dá použiť s našimi vlastnými dátami.
|
||||
- Dajte skript na reddit na git.
|
||||
- Odovzdajte reddit dáta - dajte ich školský server (titan) a povedzte kde.
|
||||
- Pokračujte v otvorených úlohách.
|
||||
|
||||
Stretnutie:
|
||||
|
||||
Stav
|
||||
|
||||
- Prezentácia
|
||||
- Skript na trénovanie funguje na vlastnom 3060Ti 8GB, funguje aj LLAMA 7B 4bit
|
||||
- Natrénované na Instruct (SlovakAlpaca) datasete.
|
||||
- Tento dataset je doplnený o dáta z redditu - r/Slovak.
|
||||
- jedno trénovanie na malom datasete trvalo 28 hod. Trénovanie sa podarilo - zbežná kontrola je ok.
|
||||
- Prečistenie textov pre výskyt vulgarizmov.
|
||||
- Začal "študovať" evaluate.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vyhodnotiť natrénovaný model. Dáta, ktoré máte k dispozícii rozdeľte na trénovaciu a testovaciu časť. Môžeme rozdeliť Instruct dáta osobitne, diskusné dáta osobitne. Vzniknú nám dve testovacie množiny. Vyhoddnotte model pred trénovaním aj po trénovaní. Možné metriky sú: ROUGE a BLEU. Zistite si čo to je. Výsledky zapíšte do tabuľky. Pre urýchlenie trénovania môžete využiť TITAN.
|
||||
- Pokračovať v písaní práce.
|
||||
- Skripty dať na GIT. Na trénovanie aj na prípravu dát. Na git nedávajte veľké dáta.
|
||||
|
||||
|
||||
Zásobnk úloh:
|
||||
|
||||
- Nájsť ďalšie tréningové údaje pre model
|
||||
- Vytvoriť rozšírené webové rozhranie, ktoré sa bude pohodlnejšie používať
|
||||
- Optimalizovať algoritmy, aby sa zvýšila účinnosť
|
||||
- Skúste na Titane natrénovať nejaký "lepší" model LLAMA ako 7B-4bit.
|
||||
|
||||
|
||||
Stretnutie 7.12.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Vytvorený skript pre trénovanie konverzácie LLAMA na datasete SlovakAlpaca na Google Colab. Využíva knižnicu HF, Na spustenie skripty nestačia zdroje na Google Colab. Skript využíva PEFT.
|
||||
- Vytvorený prístup na server Titan
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vytvorte si GIT repozitár na školskom GITe a dajte do neho Vaše skripty. Dáta tam nedávajte.
|
||||
- Skúste natrénovať LLama na servri Titan s SlovakAlpaca Datasetom.
|
||||
- Vyskúšajte natrénovať s datasetom sk-quad.
|
||||
- Zistite ako sa vyhodnocujú "instruct" generatívne modely. Preštudujte si [repozitár](https://github.com/tatsu-lab/alpaca_eval) a napíšte si poznámky.
|
||||
- Prečítajte si článok: AlpacaEval: An Automatic Evaluator of Instruction-following Models a urobte si poznámnky.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Natrénujte model SlovakT5 s Slovak Alpaca Datasetom.
|
||||
- Pozrite si skripty [text-generation](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-generation} a [seq2seq](https://github.com/huggingface/transformers/blob/main/examples/pytorch/question-answering/run_seq2seq_qa.py)
|
||||
- Natrénovaný model je potrebné vyhodnotiť. Dátovú množinu si rozdelte na 2 časti. Metrika na vyhodnotenie je BLEU alebo Rouge.
|
||||
- Pokračujte na práci na vlastnom diskusnom datasete.
|
||||
|
||||
Stretnutie 23.11.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Písomná práca pokračuje.
|
||||
- Urobený skript na získanie dát. Skript využíva Praw na získanie dát z Reddit. Skript zatiaľ nepokrýva celú konverzáciu.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Dokončiť skript pre získavanie dát. Alebo nájsť dáta a skript ktorý funguje.
|
||||
- Skúste začať trénovanie generatívneho modelu pomocou dostupných dát. Pozrite si trénovací skript https://git.kemt.fei.tuke.sk/do867bc/DIPLOMOVA_PRACA a skúste ho rozbehať so svojimi dátami.
|
||||
- Pokračujte v písaní BP.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Pozrite sa na projekt https://github.com/imartinez/privateGPT. Zisite ako to funguje. Vedeli by sme ho spustiť?
|
||||
|
||||
|
||||
Stretnutie 26.10.2023
|
||||
|
||||
|
||||
Stav:
|
||||
|
||||
- Podarilo sa spustiť pipeline pre generovanie pomocou Slovak T5 small.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [ ] Pokračovať v otvorených úlohách z minulého stretnutia.
|
||||
- [x] Prečítajte si DP O. Megela.
|
||||
- [x] V texte vysvetlite, čo je to model GPT, T5 a BART. Ku každému modelu nájdite *odborné články* a blogy, prečítajte si ich a napíšte si poznámky. Zapíšte si bibliografické údaje o článku. Odborný článok nájdete cez Google Scholar.
|
||||
|
||||
|
||||
Stretnutie 12.10.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Pripravený skript na preklad pomoocu HF transformers a Helsinki NLP modelov aj s TKInter rozhraním.
|
||||
- Písomná príprava podľa pokynov.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Dobrý model na generovanie Slov. jazyka je Slovak T5 Small.
|
||||
- [ ] Pokračujte v teoretickej príprave podľa otvorených úloh - prehľad generatívnych jazykových modelov.
|
||||
- [ ] Vytvorte dataset slovenských konverzácií. Vyberte zdroj dát, pomocou scrapera extrahujte dáta a upravte ich do vhodného formátu JSON. Stiahnite časť alebo celú webovú stránku do viacerých htmls súborov. Neposielajte veľa requestov za minútu. Dobrý nástorj na stianutie je wget. Napíšte skript, ktorý pomocu knižnice BeautifulSoup4 extrahuje diskusie a uloží ich do JSON.
|
||||
- [ ] Druhá možnosť je použiť dáta z Reditu alebo Faceboku, podľa skriptov V. Ferko.
|
||||
- [-] Generatívny model už natrénoval p. Omasta a p. Megela. Oboznámte sa s ich profilmi.
|
||||
|
||||
|
||||
Stretnutie 1.8.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Oboznámenie sa s jazykom Python
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v štúdiu jazyka Python. Pozrite si nástroje [zo stránky Python](/topics/python). Pozrite si zdroje [zo stránky NLP ](/topics/nlp).
|
||||
- Nainštalujte si prostredie Anaconda a knižnicu Huggingface transformers.
|
||||
- Prečítajte si knihu https://d2l.ai/
|
||||
- Zistite ako funguje neurónová sieť typu Transformer. https://jalammar.github.io/illustrated-transformer/
|
||||
- Zistite, čo je to generatívny jazykový model. Napíšte na 3 strany čo ste sa dozvedeli o generatívnych jazykových modeloch. Použite aj článok https://arxiv.org/abs/1910.13461
|
||||
- Napíšte jednoduchý skript na strojový preklad pomocou knižnice HF transformers.
|
||||
- Oboznámte sa s https://github.com/karpathy/minGPT
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Zoberte korpus slovenských alebo iných diskusí a natrénujte neurónový model aby podľa neho odpovedal na zadané odázky.
|
||||
- Zistite, ako sa vyhodnucujú generatívne modely pre úlohu konverzácie.
|
||||
- Oboznámte sa s frameworkom https://python.langchain.com/docs/get_started/introduction.html
|
||||
|
||||
|
||||
379
pages/students/2021/manohar_gowdru_shridharu/README.md
Normal file
@ -0,0 +1,379 @@
|
||||
---
|
||||
title: Manohar Gowdru Shridhara
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [phd2024]
|
||||
tag: [lm,nlp,hatespeech]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
# Manohar Gowdru Shridhara
|
||||
|
||||
Beginning of the study: 2021
|
||||
|
||||
repository: https://git.kemt.fei.tuke.sk/mg240ia
|
||||
|
||||
## Disertation Thesis
|
||||
|
||||
in 2023/24
|
||||
|
||||
Hate Speech Detection
|
||||
|
||||
Goals:
|
||||
|
||||
- Publish and defend a minimal thesis
|
||||
- Write a dissertaion thesis
|
||||
- Publish 2 A-class journal papers
|
||||
|
||||
## Second year of PhD study
|
||||
|
||||
Goals:
|
||||
|
||||
- Publish and defend a minimal thesis. Minimal thesis should contain PhD thesis statements - scientific contributions.
|
||||
- Provide state-of-the-art overview.
|
||||
- Formulate dissertation theses (describe scientific contribution of the thesis).
|
||||
- Prepare to reach the scientific contribution.
|
||||
- Publish Q2/Q3 paper
|
||||
- Publish 1 school conference paper.
|
||||
- Publish 1 regular conference paper.
|
||||
- Prepare a demo for hate speech detection.
|
||||
|
||||
Meeting 5.10.
|
||||
|
||||
Status:
|
||||
|
||||
Studied python and ML:
|
||||
- Basics to Advanced python is completed
|
||||
- word2vec and word embedding examples are tried
|
||||
- Basic tools (tensorflow) on Machine Learning and task are completed
|
||||
- learning on ML and Deep learning libraries and fairseq RNN, SVM BERT code samples
|
||||
|
||||
Building the datasets memes based on Dravidian languages:
|
||||
- Collected base papers on Hate speech Multilanguage troll and not troll memes with low resource languages
|
||||
|
||||
Currected the survey paper and shared for review.
|
||||
|
||||
Worked on the baseline HS expriment.
|
||||
- https://git.kemt.fei.tuke.sk/mg240ia/Hate-Speech-Detector-Streamlit
|
||||
|
||||
Tasks:
|
||||
|
||||
- Publish a paper on SAMI 2023
|
||||
- publish a paper on a school conference, ask for deadline.
|
||||
|
||||
Possible paper topics:
|
||||
|
||||
- contine to work on the baseline HS experiment. Evaluate accuracy for the classifiers. This is a possible simple publication.
|
||||
- continue to work on the horsehead experiment. This is another possible paper.
|
||||
- continue work on the dravidian dataset. this in another possible papers.
|
||||
- continue to work on the survey paper. This is another possible Q3 paper.
|
||||
|
||||
|
||||
|
||||
|
||||
Meeting 6.9.2022
|
||||
|
||||
Status:
|
||||
|
||||
- Managed to move to Kosice.
|
||||
- "A systematic review of Hate Sppech" is in progress (cca 50 pages + 100 references).
|
||||
- "Horseheard" paper is in progress.
|
||||
|
||||
Tasks:
|
||||
|
||||
- Gather feedback for "Systematic review",make new revisions according to the feedback, select a journal and publish.
|
||||
- Pick dataset, prepare several methods of HS and compare results.
|
||||
- Work on web demo of HS detection.
|
||||
- Continue working on "horseheard paper".
|
||||
- Read provided books.
|
||||
|
||||
|
||||
## First year of PhD study
|
||||
|
||||
Goals:
|
||||
|
||||
- [x] Provide state-of-the-art overview.
|
||||
- [x] Read and make notes from at least 100 scientific papers or books.
|
||||
- [ ] Publish at least 2 conference papers.
|
||||
- [x] Prepare for minimal thesis.
|
||||
|
||||
Resources:
|
||||
|
||||
- [Hate Speech Project Page](/topics/hatespeech)
|
||||
- https://hatespeechdata.com/
|
||||
- [Hate speech detection: Challenges and solutions](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6701757/)
|
||||
- [HateBase](https://hatebase.org/)
|
||||
- [Resources and benchmark corpora for hate speech detection: a systematic review]
|
||||
(https://link.springer.com/article/10.1007/s10579-020-09502-8)
|
||||
|
||||
Meeting 5.10.
|
||||
|
||||
Status:
|
||||
|
||||
Studied python and ML:
|
||||
- Basics to Advanced python is completed
|
||||
- word2vec and word embedding examples are tried
|
||||
- Basic tools (tensorflow) on Machine Learning and task are completed
|
||||
- learning on ML and Deep learning libraries and fairseq RNN, SVM BERT code samples
|
||||
|
||||
Building the datasets memes based on Dravidian languages:
|
||||
- Collected base papers on Hate speech Multilanguage troll and not troll memes with low resource languages
|
||||
|
||||
Currected the survey paper and shared for review.
|
||||
|
||||
Worked on a baseline HS experiment:
|
||||
|
||||
https://git.kemt.fei.tuke.sk/mg240ia/Hate-Speech-Detector-Streamlit
|
||||
|
||||
|
||||
Tasks:
|
||||
|
||||
- Publish a paper about the dataset on the SAMI 2023 Conference.
|
||||
- Publish a paper in school journal - ask about deadlilne.
|
||||
|
||||
|
||||
14.7:
|
||||
|
||||
Status:
|
||||
|
||||
- Worked on an horseheard implementation.
|
||||
- Picked a feasible dataset and method to start with: kannada dataset, tagging sentiment for movie reviews.
|
||||
- Worked on a paper.
|
||||
- Studied several papers,
|
||||
- started to work on a streamlit demo
|
||||
|
||||
Open tasks:
|
||||
|
||||
- Focus on making a baseline experiment for sentiment classification using classical methods, such as Transformers. PLEASE DO NOT AVOID !!!!
|
||||
- Prepare a survey paper for school journal or a conference. Use and correct the draft form the beginning. PLEASE DO NOT AVOID !!!! The goal is to identify the most current trends in methods for HS detection. Write in your own words what did you learn from the literature. Write what will be you contribution. Contribution is something new that we have to prove that is new and better.
|
||||
- Try to prepare an experiment with the selected dataset. https://git.kemt.fei.tuke.sk/mg240ia/Hate_Speech_IMAYFLY_and_HORSEHERD
|
||||
- For preparing a web application with demo, learn about streamlit. In progress: https://git.kemt.fei.tuke.sk/mg240ia/Hate-Speech-Detector-Streamlit
|
||||
|
||||
Read Papers :
|
||||
|
||||
- https://aclanthology.org/2020.peoples-1.6.pdf
|
||||
- https://aclanthology.org/2022.ltedi-1.14/
|
||||
- https://arxiv.org/abs/2108.03867
|
||||
- https://arxiv.org/pdf/2112.15417v4.pdf
|
||||
- https://arxiv.org/ftp/arxiv/papers/2202/2202.04725.pdf
|
||||
- https://github.com/manikandan-ravikiran/DOSA/blob/main/EACL_Final_Paper.pdf
|
||||
- https://aclanthology.org/2020.icon-main.13.pdf
|
||||
- http://ceur-ws.org/Vol-3159/T6-4.pdf
|
||||
- https://www.researchgate.net/publication/353819476_Hope_Speech_detection_in_under-resourced_Kannada_language
|
||||
- https://www.researchgate.net/publication/346964457_Creation_of_Corpus_and_analysis_in_Code-Mixed_Kannada-English_Twitter_data_for_Emotion_Prediction
|
||||
- https://www.semanticscholar.org/paper/Detecting-stance-in-kannada-social-media-code-mixed-SrinidhiSkanda-Kumar/f651d67211809f2036ac81c27e55d02bd061ed64
|
||||
- https://www.academia.edu/81920734/Findings_of_the_Sentiment_Analysis_of_Dravidian_Languages_in_Code_Mixed_Text
|
||||
- https://competitions.codalab.org/competitions/30642#learn_the_details
|
||||
- https://paperswithcode.com/paper/creation-of-corpus-and-analysis-in-code-mixed
|
||||
- https://paperswithcode.com/paper/hope-speech-detection-in-under-resourced#code
|
||||
|
||||
## Meeting 13.6.
|
||||
|
||||
- Implemented a Mayfly and Horse Heard Algorithms in Python and Matlab for HS datasets.
|
||||
- Written a draft of a paper.
|
||||
- Performed experiments on HS with Word2Vec, FastText, OneHot.
|
||||
|
||||
Tasks:
|
||||
|
||||
- Implement open tasks from the previous meetings !!!!!!!!
|
||||
- Share Scripts with GIT and Drafts with Online Word or Docs !!!
|
||||
- try https://huggingface.co/cardiffnlp/twitter-roberta-base-hate, try to repeat the training and evaluation
|
||||
|
||||
|
||||
|
||||
## Meeting 24.5.
|
||||
|
||||
- shared colab notebook, with on-going implementation of mayfly algorithm for preprocessing in sentiment recognition in a twitter dataset.
|
||||
|
||||
Tasks:
|
||||
|
||||
- Implement open tasks from the previous meetings !!!
|
||||
- [ ] Focus on making a baseline experiment for sentiment classification using classcal methods, such as Transformers.
|
||||
- [x] Consider using pre-trained embeddings. FastText, word2vec, sentence-transformers, Labse, Laser,
|
||||
|
||||
Supplemental tasks:
|
||||
|
||||
- [x] Fininsh the mayfly implementation
|
||||
|
||||
|
||||
## Meeting 20.5.
|
||||
|
||||
- learned about Firefly / mayfly optimization algorithm.
|
||||
- read ten papers,
|
||||
- wrote 1 page abstract about possible system, based od DBN.
|
||||
|
||||
|
||||
## Meeting 25.4.
|
||||
|
||||
- Learned aboud deep learning lifecycle / evaluation, BERT, RoBERTa, GPT
|
||||
- Tried HF transformers, Spacy, NLTK, word embeddings, sentence transformers.
|
||||
- Set up a repo with notes: https://git.kemt.fei.tuke.sk/mg240ia
|
||||
|
||||
Tasks:
|
||||
|
||||
- [ ] Publish experiments into the repository.
|
||||
- [ ] Prepare a paper for publication in faculty proceedings http://eei.fei.tuke.sk/#!/
|
||||
- [ ] Send me draft in advance.
|
||||
|
||||
Suplemental tasks:
|
||||
|
||||
- [x] For presentation of the results, learn about https://wandb.ai/. This can dispplay results (learning curve, etc.)
|
||||
- [ ] For preparing a web aplication with demo, learn about streamlit.
|
||||
|
||||
## Meeting 12.4.
|
||||
|
||||
- Created repositories, empty so far.
|
||||
- Tried to replicate the results from "Emotion and sentiment analysis of tweets using BERT" paper and "Fine-Tuning BERT Based Approach for Multi-Class Sentiment Analysis on Twitter Emotion Data".
|
||||
- The experiments are based on BERT (which kind?), Tweet Emotion Intensity.
|
||||
- Prepared colab notebook with experiments.
|
||||
|
||||
Tasks:
|
||||
|
||||
- [ ] Finish experiments, upload source codes into git, provide a description of the experiments.
|
||||
- [ ] Try to improve the results - try different kind of BERT - roberta, electra, xl-net. Can "generative models" be used? (gpt, bart, t5). Can "sentence transformers be used" - labse, laser.
|
||||
- [x] Learn about "Sentence Transformers".
|
||||
- [ ] Summarize the results in the table, publish the table on git.
|
||||
- [-] Use Markdown for formatting. There is "Typora".
|
||||
- [-] Continue to improve the SCYR paper.
|
||||
- If you have some conference in mind, tell me.
|
||||
|
||||
## Meeting 25.3.22
|
||||
|
||||
- Learned about Transformers, BERT, LSTM and RNN.
|
||||
- Tried HuggingFace transformers library
|
||||
- Started Google Colab - executing sentiment analysis, hf transformers pipeline functions.
|
||||
- prepared datasets: twitter-roberta Datasets. Experiments a re riunnig, no results yet.
|
||||
- prepared a short note about nlp and neural networks.
|
||||
- still working on the SCYR paper
|
||||
|
||||
Tasks:
|
||||
|
||||
- [-] finish experiments about sentiment and present results.
|
||||
- [-] create a repository on git.kemt.fei.tuke.sk and upload your experiments, results and notes. Use you student creadentials.
|
||||
- [-] continue working on "SCYR" review paper, consider publishing it elswhere (the firs version got rejected).
|
||||
- [-] prepare an outline for another paper with sentiment classification.
|
||||
|
||||
## Meeting 10.3.22
|
||||
|
||||
- Improvement of the report.
|
||||
- Installed Transformers and Anaconda
|
||||
|
||||
Tasks:
|
||||
|
||||
- Try [this model](https://huggingface.co/cardiffnlp/twitter-roberta-base-sentiment) with your own text.
|
||||
- Learn how Transformers Neural Network Works. Learn how Roberta Model training works. Learn how BERT model finetuning works. Write a short memo about your findings and papers read on this topic.
|
||||
- Pick a dataset:
|
||||
- https://huggingface.co/datasets/sentiment140 (english)
|
||||
- https://www.clarin.si/repository/xmlui/handle/11356/1054 (multilingua)
|
||||
- https://huggingface.co/datasets/tamilmixsentiment (english tamil code switch)
|
||||
- Grab baseline BERT type model and try to finetune it for sentiment classification.
|
||||
- For finetuning and evaluation you can use this scrip https://github.com/huggingface/transformers/tree/master/examples/pytorch/text-classification
|
||||
- For finetuning you will need to install CUDA and Pytorch. It can work on CPU or NOT.
|
||||
- If you need GPU, use the school server idoc.fei.tuke.sk or google Colab.
|
||||
- Continue working on the paper.
|
||||
- Remind me about the SCYR conference payment.
|
||||
|
||||
|
||||
|
||||
## Meeting 21.2.22
|
||||
|
||||
- Written a report about HS detection (in progress)
|
||||
|
||||
Tasks:
|
||||
|
||||
- Repair the report (rewrite copied parts, make the paragrapsh be logically ordered, teoreticaly - formaly define the HS detection, analyze te datasets in detail - how do they work. what metric do they use).
|
||||
- Install Hugging Face Transformers and come through a tutorial
|
||||
|
||||
|
||||
|
||||
## Meeting 31.1.22
|
||||
|
||||
- Read some blogs about transformers
|
||||
- Installed and tied transformers
|
||||
- Worked on the review paper
|
||||
- Picked the Twitter Dataset on keggle
|
||||
- still selecting a method
|
||||
|
||||
Open tasks:
|
||||
|
||||
- Continue to work on the paper and share the paper with us.
|
||||
- Prepare som ideas for the common discussion about the project.
|
||||
- [ ] Try to prepare an experiment with the selected dataset.
|
||||
- [ ] You can use the school CUDA infrastructre (idoc.fei.tuke.sk).
|
||||
- [ ] Set up a repository for experiments, use the school git server git.kemt.fei.tuke.sk.
|
||||
- [x] Get ready to post a paper on the school PhD conference SCYR, deadline is in the middle of February http://scyr.kpi.fei.tuke.sk/.
|
||||
|
||||
|
||||
### Meeting 10.1.22
|
||||
|
||||
- Set up a git account https://github.com/ManoGS with script to prepare "twitter" dataset and "english" dataset for HS detection.
|
||||
- confgured laptop with (Anaconda) / PyCharm, pytorch, cuda gone throug some basic python tutorials.
|
||||
- Read some blogs how to use kaggle (dataset database).
|
||||
- tutorials on huggingface transformers - understanding sentiment analysis.
|
||||
|
||||
Open tasks:
|
||||
|
||||
- [x] Continue to work on the review - with datasets and methods (specified below).
|
||||
- [x] Read and make notes about transformers, neural language models and finentuning.
|
||||
- [ ] Pick feasible dataset and method to start with.
|
||||
- [ ] You can use the school CUDA infrastructre (idoc.fei.tuke.sk).
|
||||
- [ ] Set up a repository for experiments, use the school git server git.kemt.fei.tuke.sk.
|
||||
- [ ] Get ready to post a paper on the school PhD conference SCYR, deadline is in the middle of February http://scyr.kpi.fei.tuke.sk/.
|
||||
|
||||
#### Meeting 16.12.21
|
||||
|
||||
- A report was provided (through Teams).
|
||||
- Installed Anaconda and started s Transformers tutorial
|
||||
- Started Dive into python book
|
||||
|
||||
Task:
|
||||
|
||||
- Report: Create a detailed list of available datasets for HS.
|
||||
- Report: Create a detailed description of the state of the art approaches for HS detection.
|
||||
- Practical: Continue with open tasks below. (pick datasetm, perform classification,evaluate the experiment.)
|
||||
|
||||
|
||||
#### Meeting 10.12.21
|
||||
|
||||
No report (just draft) was provided so far.
|
||||
|
||||
1. Read papers from below and make notes what you have learned fro the papers. For each note make a bibliographic citation. Write down authors of the paper, name paper of the paper, year, publisher and other important information.
|
||||
When you find out something, make a reference with a number to that paper.
|
||||
You can use a bibliografic manager software. Mendeley, Endnote, Jabref.
|
||||
2. From the papers find out answers to the questions below.
|
||||
3. Pick a hatespeech dataset.
|
||||
4. Pick an approach and Python library for HS classification.
|
||||
5. Create a [GIT](https://git.kemt.fei.tuke.sk) repository and share your experiment files. Do not commit data files, just links how to download the files.
|
||||
6. Perform and evaluate experiments.
|
||||
|
||||
#### Meeting 10.11.21
|
||||
|
||||
#### First tasks
|
||||
|
||||
Prepare a report where you will explain:
|
||||
|
||||
- what is hate speech detection,
|
||||
- where and why you can use hate-speech detection,
|
||||
- what are state-of-the-art methods for hate speech detection,
|
||||
- how can you evaluate a hate-speech detection system,
|
||||
- what datasets for hate-speech detection are available,
|
||||
|
||||
The report should properly cite scientific bibliographical sources.
|
||||
Use a bibliography manager software, such as Mendeley.
|
||||
|
||||
Create a [VPN connection](https://uvt.tuke.sk/wps/portal/uv/sluzby/vzdialeny-pristup-vpn) to the university network to have access to the scientific databses. Use scientific indexes to discover literature:
|
||||
|
||||
- [Scopus](https://www.scopus.com/) (available from TUKE VPN)
|
||||
- [Scholar](httyps://scholar.google.com)
|
||||
|
||||
Your review can start with:
|
||||
|
||||
- [Hate speech detection: Challenges and solutions](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6701757/)
|
||||
- [HateBase](https://hatebase.org/)
|
||||
- [Resources and benchmark corpora for hate speech detection: a systematic review](https://link.springer.com/article/10.1007/s10579-020-09502-8)
|
||||
|
||||
Get to know the Python programming language
|
||||
|
||||
- Read [Dive into Python](https://diveintopython3.net/)
|
||||
- Install [Anaconda](https://www.anaconda.com/)
|
||||
- Try [HuggingFace Transformers library]( https://huggingface.co/transformers/quicktour.html)
|
||||
|
||||
495
pages/students/2021/martin_sarissky/README.md
Normal file
@ -0,0 +1,495 @@
|
||||
---
|
||||
title: Martin Šarišský
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [vp2023,bp2024,dp2026]
|
||||
tag: [chatbot,rasa,dialog,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
rok začiatku štúdia: 2021
|
||||
|
||||
# Diplomová práca 2026
|
||||
|
||||
https://git.kemt.fei.tuke.sk/ms058bd/Diplomovka
|
||||
|
||||
Názov práce:
|
||||
|
||||
Agentové systémy pomocou veľkého jazykového modelu
|
||||
|
||||
Zadanie:
|
||||
|
||||
1. Vypracujte prehľad systémov generovania prirodzeného jazyka, ktoré podporujú vyhľadávanie a sú vhodné na spracovanie právnych informácií.
|
||||
2. Na základe tohto prehľadu navrhnite a implementujte agentový systém, ktorý umožní vyhľadávanie v právnych dokumentoch, odpovedanie na otázky a sumarizáciu textov.
|
||||
3. Vytvorte sadu vzorových úloh na testovanie systému a optimalizujte generovanie odpovedí pre úlohy, ktoré vyžadujú viacero krokov.
|
||||
4. Otestujte systém na navrhnutých úlohách, vyhodnoťte jeho výkonnosť a identifikujte slabé miesta.
|
||||
|
||||
Ciele:
|
||||
|
||||
- Vytvoriť systém pre spracovanie právnych informácií. Systém by mal vedieť vyhľadávať v rozsudkoch, zákonoch a vyhláškach.
|
||||
, odpovedať na otázky a sumarizovať dokumenty. Je možné, že riešenie úlohy si vyžiada viac krokov.
|
||||
- Vytvoriť sadu vzorových úloh pre vyhodnotenie takéhoto systému.
|
||||
- Zlepšiť generovanie odpovedí pre úlohy vyžadujúce viac krokov.
|
||||
|
||||
Stretnutie 23.3.2026
|
||||
|
||||
Stav:
|
||||
|
||||
- Systém funguje.
|
||||
- Vyhodnotenie Faithfulness, AnswerRelevancy a ContextualRelevancy s databázou otázok a odpovedí od právničky.
|
||||
- Písomná časť je WIP.
|
||||
- aktuálne zdrojáky sú k dispozícii na https://git.kemt.fei.tuke.sk/ms058bd/Diplomovka
|
||||
|
||||
Úlohy:
|
||||
|
||||
- aktualizovať README zdrojákov
|
||||
- pracovať na texte. Používajte google scholar a odkazy v texte.
|
||||
- vypracujte viacero experimentov pre rôzne hodnoty hyperparametrov (napr. threshold) a výsledky dajte do tabuľky, príp. grafu.
|
||||
- Opíšte experimenty - komponenty, dáta, hyperparametre. Slovne zhodnotte výsledky v tabuľkách.
|
||||
|
||||
|
||||
Stretnutie 5.2.2026
|
||||
|
||||
- Zväčšený index
|
||||
- Problém s kvalitou vyhľadávania. Problém môžu byť tabuľky - agent ich nevidí. Parsovanie bolo z html dát cez beautifulsoup.
|
||||
- Práca na texte.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vyhodnotte Váš systém pomocou viacerých metrík DeepEval - pomocou jazykového modelu.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Zlepšiť krok rozhodnovania - použiť internet, FAISS alebo API?
|
||||
- Preparsovať dáta pomocou Docling.
|
||||
|
||||
|
||||
Stretnutie 5.12.2025
|
||||
|
||||
- Zlepšenie parsovania a promptingu.
|
||||
- Funguje LangGraph pipeline - "router" vyberie index (API, FAISS alebo internet), podľa toho sa získajú dokumenty (40 nabližších). Tie sa filtrujú pomocou LM (na cca 5). Potom sa generuje sa odpoveď. Niekedy sa odfiltruje relevantný dokument (chunk) a model potom halucinuje.
|
||||
- Prerábal som chunkovanie html pre parsovanie dat. Chunk mal 512 tokenov. Prerábané kvoli vysvetlovaniu z akeho zakona, cisla, bodu… zakon je. Následne bolo potrebne preindexovanie. Model me5-large. Veľkosť indexu 26Gi. Avšak len html, prilohy neindexovane.
|
||||
- Nastavovanie promptu pre sumarizaciu čo použit(API, web search, faiss)
|
||||
- Úprava tresholdu a poctu dokumentov pre faiss retriever aby naslo spravne dokumenty a spravne odpovedl na otazku. Kazda odpoved ina a dobra v niecom, zla v niecom preto zistujem ako to upravit spravne. Vytvorenie pomocnych funkcii nieco ako router na filtrovanie zakonov, ktore sa vobec dostanu dalej na tvorbu odpovede
|
||||
- mozno bude treba iny model takze rechunk, reindex, rerank aby tam boli aj pdfka(to je dost podstatne). Povedat ze grafika 1 je obmedzena. skusit sa opytat na ine graficke karty lepsie. 1 - 30 hodin. 2,3,4 - 5 hodin cca
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Použiť reranking namiesto "filtrovania".
|
||||
- Použiť iný vektorový model - ktorý vie väčší kontext. Dá sa použiť prompting aj pre vektorový model (pre indexovanie).
|
||||
- Pracovať ďalej na texte a dávať zdrojáky na GIT.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Doplniť testy, ktoré by automaticky vyhodnotili aktuálny postup vyhľadávania (pipeline) pomocou jazykového modelu.
|
||||
- Použiť "školské API" pre generovanie aj pre indexovanie.
|
||||
- Doplniť spätnú kontrolu výsledkov pomocou jazykového modelu.
|
||||
- Dotrénovanie Rerankera.
|
||||
- Dorobiť parsovanie príloh v PDF (nie je priorita).
|
||||
- Je možné vyhodiť starú legislatívu.
|
||||
|
||||
Stretnutie 27.11.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Práca na písomnej časti (13 strán).
|
||||
- Práca s API funguje, chyba 500 je spôsobená na strane poskytovateľa.
|
||||
- WIP - vysvetlenie rozhodnutia. Je potrebné podrobne preparsovať dump slov-lex aby sme zachytili meno zákona a paragrafy.
|
||||
- Momentálne je preparsovaná časť.
|
||||
- Sú technické problémy s quadro.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zlepšite parsovanie legislatívy.
|
||||
- kódy dajte na git.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Využite lokálne nasadený veľký jazykový model, embedding model, vektorovú databázu.
|
||||
- Spätne overte vysvetlenie.
|
||||
|
||||
|
||||
|
||||
Stretnutie 7.11.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Prerobené z langChain na langGraph takže samostatné nodes a endpoints teda ja mám kontrolu kam čo pôjde
|
||||
- Pridané API Ministerstva ktoré, ale momentálne vracia chybu a teda nie je správne implementované
|
||||
- Pridanie monitoringu pomocou langSmith teda vidím kaskádový proces celého rozhodovania, počet tokenov a response time
|
||||
- pred vstupom do faiss edgu preformuluje otázku na právne položenú resp. upraví užívateľov text(reformulate_query)
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zvýšte vysvetliteľnosť. Pri výsledkoch vždy uvedte, podľa ktorého právneho predpisu sa orientujete.
|
||||
- Môžete pridať aj "odôvodnenie".
|
||||
- Pridajte viac testovacích otázok do databázy otázok.
|
||||
- Pripravte deployment pomocou Docker Compose na školskú infraštruktúru. Využitie lokálneho OpenAI compatible API.
|
||||
- Pracujte na texte práce. Aké sú najnovšie články o inteligentných agentoch?
|
||||
|
||||
Zásobík úloh:
|
||||
|
||||
- Pridajte možnosť pre spätnú kontrolu. Ak vieme odpoveď, je správna vhľadom na zadanú otázku a nájdené právne predpisy?
|
||||
- Vyčíslite kvalitu systému pre testovacie otázky.
|
||||
- Možnosť prdať vlastné dokumenty do vyhľadávania alebo do databázy.
|
||||
|
||||
|
||||
Stretnutie 30.10.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Pripravené Gradio demo, OpenAI SDK agent vie vyhľadávať v FAISS indexe.
|
||||
- Pripravená prvá verzia OpenAI agenta, pracuje s gpt4-o-mini
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Dajte zdrojáky dema a agenta na GIT
|
||||
- Naučte agenta pracovať s REST API [Obcan Justice](https://obcan.justice.sk/pilot/api/ress-isu-service/swagger-ui/index.html#)
|
||||
- agent by mal vedieť prehľadať zákony, vyhlášky, správne konania, rozsudky, relevantné webové stránky.
|
||||
- Pripravte novú databázu otázok a odpovedí ohľadom colného konania.
|
||||
- Pokračujte v práci na texte, študujte "function calling".
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Je možné že bude treba viac agentov.
|
||||
- Je možné, že výsledky bude treba overiť (grounding).
|
||||
- Možno bude treba toto urobiť bez OpenAI.
|
||||
|
||||
Stretnutie 10.10.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Štúdium podľa odporúčania. Poznámky z oblasti znalostné grafy, langchain, SBERT, function calling - agent tools. LLM.
|
||||
- Máme index zákonov.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vytvorte systém pre generovanie odpovede na základe získaných dokumentov.
|
||||
- Navrhnite agenta pre získanie relevantných informácií ku dotazu a generovanie odpovede.
|
||||
Agent bude vedieť využívať viaceré nástroje, napr. verejné REST API alebo vyhľadávanie na internete.
|
||||
- Ako modelový príklad použite otázky týkajúce sa colných konaní. Nájdite si príklady otázok z tejto oblasi.
|
||||
- Oboznámte a vyskúšajte OpenAI Agents SDK alebo nový langchain alebo CrewAI.
|
||||
- Do práce píšte o inteligentných agentoch, REACT, LLM, function calling.
|
||||
|
||||
Prázdninová Príprava:
|
||||
|
||||
- Zopakujte si Python.
|
||||
- Vyskúšajte si prácu s veľkými jazykovými modelmi. Nainštalujte si ollama.
|
||||
- Oboznámte sa s frameworkom LangChain.
|
||||
- pozrite si LangChain Transformers Agents.
|
||||
- Ako funguje FunctionCalling - AgentTools?.
|
||||
- Zistite ako funguje REACT (Reasoning and Acting) Agent - nájdite článok na Scholar.
|
||||
- Zistite ako funguje dotrénovnaie veľkých jazykových modelov. Zistite čo je to PEFT (LORA, QLORA) a čo je to kvantizácia. Zisite čo je to "few shot" prompting.
|
||||
- Čo je to inferenčný server. Zistite čo je to VLLM, na čo je to dobré. Pozri si LocalAI.
|
||||
|
||||
## Diplomový projekt 2025
|
||||
|
||||
Stretnutie 14.5.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Zaindexované zákony a vyhlášky vyhlásené v roku 2022 pomocou FAISS a SlovakBert-mnlr
|
||||
- Urobené gradio demo pomocou langchain, ktoré ku dotazu nájde a zobrazí 3 najlepšie dokumenty.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zlepšite skript pre predspracovanie dát. Pridajte ďalšie dáta, identifikujte a opravte nedostatky. Chceme mať k dispozícii právne kompletné právne predpisy v súčasnom znení.
|
||||
- Preštudujte si knižnicu LangGraph a "function calling".
|
||||
- Zistite, ako "znalostný graf - knowledge graph" dokáže vylepšiť výsledky vyhľadávania v zákonoch. Graph RAG.
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vyjadrite vnútorné a vzájomné vzťahy medzi právnymi predpismi.
|
||||
- Vytvorte "pekné" webové rozhranie a príslušné Docker skripty pre nasadenie dema.
|
||||
- Vytvorte agenta, ktorý bude vedioeť riešiť právne problémy.
|
||||
- Zostaviť testovacie dáta. Vzorovú množinu otázok, odpovedí a relevantných dokumentov. Pomocou tejto množiny vyhodnotiť systém. Vyhodnotneie sa skladá z dvoch častí - vyhdonotenie vyhľadávania a vyhodnotenie automatických odpovedí.
|
||||
- Inšpirovať sa stránkou https://aipravnik.sk/
|
||||
- Natrénujte model pre úlohu sumarizácie súdnych rozhodnutí (nízka priorita).
|
||||
|
||||
|
||||
Stretnutie 10.3.2025
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Preštudovať - ako zostaviť RAG systém pomocou LangChain
|
||||
- [-] Vytvoriť databázu právnych informácií - texty zákonov, vyhlášok a rozsudkov spolu s metainformáciami. Vedúci pridelí prístup na QUADRO. (úloha Šarišský)
|
||||
- [-] Zistiť ako fungujú agentové systémy na báze LLM - React. A volanie "nástrojov" function calling pomocou LLM.
|
||||
- Získajte prístup na QUADRO. V adresári /mnt/sharedhome/hladek/corpora/slovak_law/ sú dáta. Dáta premente do JSON.
|
||||
Extrahujte text, vytiahnite metainformácie. Na extrakciu textu využite vhodnú knižnicu. Napr. Apache TIKA.
|
||||
- [-] Vytvoriť RAG systém pre spracovanie tejto databázy. Pozrite si: Inšpirácia prácou Valerii Kutsenko, Yevhenii Leonov, [Oleh Poiasnik](/students/2022/oleh_poiasnik). Môžete sa inšpirovať [GIT BP Poiasnik](https://git.kemt.fei.tuke.sk/op405wm/Bakalarska_praca) (úloha Ščišľak)
|
||||
|
||||
Myšlienkový postup pre ZP:
|
||||
|
||||
1. Zadefinujete úlohu a pojmy.
|
||||
2. Vysvetlíte, ako sa táto úloha rieši vo svete.
|
||||
3. Napíšete, ako ste túto plohu riešlili Vy a prečo.
|
||||
4. Vyhodnottíte Vaše riešenie. Porováte výsledky so svetom a identifikujete miesta na zlepšenie.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- [x] Dáta sa vložia do databázy a zaindexujú vhodným SBERT modelom.
|
||||
- [ ] Vyhľadať na internete množinu vzorových právnych otázok a vyhodnotiť systém (Šarišský)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
# Bakalárska práca 2024
|
||||
|
||||
|
||||
[Git repo](https://git.kemt.fei.tuke.sk/ms058bd/vp2023)
|
||||
|
||||
Súvisiace materiály:
|
||||
|
||||
- [Projektová stránka](/topics/chatbot)
|
||||
- [Repozitár s webovou aplikáciou](https://git.kemt.fei.tuke.sk/sh662er/rasa-flask-website)
|
||||
- [Repozitár s chatbotom](https://git.kemt.fei.tuke.sk/sh662er/Rasa)
|
||||
- Bakalárska práca [Samuel Horáni](/students/2019/samuel_horani)
|
||||
- video kanál s [RASA tutoriálom](https://www.youtube.com/watch?v=rlAQWbhwqLA&list=PL75e0qA87dlHQny7z43NduZHPo6qd-cRc)
|
||||
- Slovenský Spacy model https://github.com/hladek/spacy-skmodel
|
||||
|
||||
Návrh na zadanie BP:
|
||||
|
||||
Dialógový systém pre zodpovedanie najčastejšie kladených otázok
|
||||
|
||||
1. Vypracujte prehľad metód dialógových systémov s použitím pravidiel a jazykových modelov.
|
||||
2. Navrhnite a overte bázu pravidiel pre dialógový systém pre pomoc pri komunikácii občana s mestským magistrátom.
|
||||
3. Vytvorte webové demo pre chatbota.
|
||||
4. Identifikujte slabé miesta a navrhnite zlepšenia dialógového systému.
|
||||
|
||||
|
||||
|
||||
Nápady na balakársku prácu:
|
||||
|
||||
- chatbot pre komunikáciu s mestom
|
||||
- vytvorenie NLU databázy.
|
||||
- Urobenie web rozhrania.
|
||||
- dá sa to prepojiť aj na QA systém.
|
||||
|
||||
Stretnutie 23.02.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Práca na text aj na pravidlách.
|
||||
|
||||
Stretnutie 9.2.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Urobené nové testovacie scenáre a vyhodnotenie modelu.
|
||||
- Pridané pravidlá pre FAQ a chitchat.
|
||||
- Vyskúšané PrivateGPT.
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vytvorte Dockerfile na nasadenie aplikácie.
|
||||
- Podľa výsledkov vyhodnotenia zlepšite bázu pravidiel.
|
||||
- Pracujte na texte
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Ďalej skúšajte PrivateGPT. Zmente "prompt" pre vyhľadávanie. Prompt zmente na slovenský. Napr. "Si asistent pre vyhľadávanie a hovoríš po slovensky." Model nastavte na LLAMA 7B 4bit. Na embedingy skúste SlovakBERT-MNLR.
|
||||
|
||||
|
||||
Stretnutie 4.1.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Splnené úlohy z minulého stretnutia.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vypracujte prezentáciu s výsledkami zo semestra.
|
||||
- Pokračujte v písaní.
|
||||
- Vytvorte nové testovacie scenáre, vyhodnotte model a doplnte výslekdy do práce.
|
||||
- Do chatbota doplňte pravidlá pre [FAQ](https://rasa.com/docs/rasa/chitchat-faqs/)
|
||||
- Zdrojové kódy dajte na GIT.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Rozbehať PrivateGPT a integrovať ho do RASA.
|
||||
|
||||
Stretnutie 8.12.
|
||||
|
||||
Stav:
|
||||
|
||||
- Práca na databáze pravidiel pre dialóg. Pravidlá obsahujú najčastejšie otázky týkajúce sa digitálnych služieb.
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Vedúci finalizuje zadanie.
|
||||
- [x] Pokračujte v písomnej práci.
|
||||
- [x] Pokračujte v tvorbe webovej aplikácie - integrujte pravidlá od kolegu Ščišľaka-
|
||||
- [x] Zistite ako pracujú veľké jazykové modely a napíšte si poznánmky.
|
||||
- [x] Zistite, čo je to "Retrieval Augumented Generation", ako to funguje a na čo je to dobré.
|
||||
- [x] Oboznámte sa so softvérom PrivateGPT. Zistite ako funguje, napíšte is poznámky-
|
||||
- [x] Pridajte kapitolu o Získavaníí dokumentov pre použitie v dialógových systémoch.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- [-] Na školský server alebo na vlastnú M1 nainštalujte PrivateGPT.
|
||||
|
||||
|
||||
Stretnutie 10.11.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Web app funguje. Frontend je HTML, CSS, Javascrip - axios.
|
||||
- Zdrojáky sú na https://git.kemt.fei.tuke.sk/ms058bd/vp2023.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte
|
||||
- Vedúci sa pozrie na build - Dockerfile.
|
||||
|
||||
Stretnutie 27.10.2023
|
||||
|
||||
- Pokračuje písomná príprava.
|
||||
- Pokračuje práca na stránke.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v otvorených úlohách.
|
||||
- Preskúmajte možnosti vytvorenia vlastného frontentu pre RASA chatbota. Zistite viaceré alternatívy.
|
||||
|
||||
Stretnutie 6.10.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Dockerfile in progress
|
||||
- Teoretická a písomná príprava in progress
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte
|
||||
|
||||
|
||||
Stretnutie 29.9.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Ten istý ako pri minulom stretnutí, kódy sú na KEMT GITe.
|
||||
- Momentálne vie chatbot poskytnúť kontakt na človeka, ktorý sa zaoberá danou agendou.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [-] Dokončiť demo do podoby vhodnej na nasadenie. Dokončiť Dockerfile, dokončiť pravidlá. Vedúci pomôže so zverejnením.
|
||||
- [-] Zistite, akým spôsobom sa vyhodnocuje-testuje chatbot. Napíšte, ktoré scenáre chatbota sú implementované a ku nim napíšte "testovacie dialógy".
|
||||
- [-] Začnite písať baklársku prácu a pripravte "draft". V práci vysvetlite, čo je to NLU, ako sa robí. Ako príklad uveďte Vášho četbota. Do práce uvedte aj priebeh a výsledky testovania.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Je potrebné aby chatbot sa vedel "učiť", resp. upraviť svoje pravidlá podľa meniacich sa skutočností. Je potrebné vymyslieť webovú aplikáciu pre úpravu bázy pravidiel aj zamestnancami magistrátu.
|
||||
- Identifikuje, aké ďalšie úlohy by mohol riešiť chatbot.
|
||||
- Zlepšite chatbota aby spolupracoval s kognitívnym vyhľadávaním, práca [Kristián Sopkovič](/students/2019/kristian_sopkovic).
|
||||
|
||||
|
||||
## Vedecký projekt 2023
|
||||
|
||||
|
||||
Ciele:
|
||||
|
||||
- Napísať krátku písomnú správu
|
||||
- Oboznámiť sa s technológiou RASA a so súvisiacimi technológiami NLP
|
||||
- Vytvoriť jednoduchého chatbota ktorý bude komunikovať po slovensky.
|
||||
|
||||
Stretnutie 5.5
|
||||
|
||||
Stav:
|
||||
|
||||
- Draft písomnej správy
|
||||
- Začiatok práce s Dockerfile
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Prepracujte "blog" na uverejnenie na stránke.
|
||||
- [-] Zlepšiť bázu pravidiel chatbota a dať na git
|
||||
- [-] Identifikovať slabé miesta, porozmýšľať ako by sa to dalo zlepšiť.
|
||||
|
||||
|
||||
|
||||
Stretnutie 21.4.
|
||||
|
||||
Stav:
|
||||
|
||||
- Chatbot funguje pre vybrané časti agendy mesta
|
||||
- Funguje aj lokálne demo pomocou RasaWebWidget. Používa sa Websocket
|
||||
- Rozpracovaný písomný report
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Dať zdrojové kódy na GIT
|
||||
- [-] Dokončiť písomnú správu. Cieľ je mať blog, ktorý oboznámi študenta o možnostiach a práci s RASA.
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- [-] Dorobiť Dockerfile.
|
||||
- [ ] Zverejniť demo na K8s (pre vedúceho).
|
||||
- [ ] Zverejniť blog vo formáte Markdown.
|
||||
- [-] Zlepšiť bázu pravidiel chatbota.
|
||||
- [-] Identifikovať slabé miesta, porozmýšľať ako by sa to dalo zlepšiť.
|
||||
|
||||
Stretnutie 12.4.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Robot komunikuje po slovensky pre jedoduchú úlohu súvisiacu s esluzby mesta Košice.
|
||||
- Zdrojáky sú na gite https://git.kemt.fei.tuke.sk/ms058bd/vp2023
|
||||
- Napísaný krátky report, draft
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zlepšiť štylistiku reportu.
|
||||
- Pripraviť jednoduchú webovú aplikáciu na demo s chatbotom. Inšpirujte sa prácou S. Horáni. alebo použite Flask, Streamlit alebo Rasa ChatWidget https://rasa.com/docs/rasa/connectors/your-own-website/ .
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Zlepšite bázu pravidiel chatbota pre esluzby.
|
||||
- Zistenie kontaktnej osoby pre agendu.
|
||||
- Najčastejšie otázky.
|
||||
- Riešenie problémov.
|
||||
- Vymyslieť postup ktorý by umožnil pretrénovať chatbota aj pracovníkom magistrátu. Editovanie pravidiel vo webovej aplikácii.
|
||||
|
||||
Stretnutie 27.3.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Chatbot funguje po anglicky cez Anaconda.
|
||||
- Napísané niektoré reporty.
|
||||
- Pripravené niektoré testovacie konverzácie.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Pozrite si stránku https://www.esluzbykosice.sk/, navrhnite chatbbota ktorý bude informovať o dostupných e-službách pre košický magistrát.
|
||||
- [x] Zdrojáky dajte na KEMT GIT, repozitár nazvite vp2023
|
||||
- [-] Pokračujte v otvorených úlohách.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- [x] Preštudujte si ako sa vyhodnocuje RASA chatbot
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Nainštalujte a oboznámte sa s RASA frameworkom. Pri inštalácii využite systém Anaconda.
|
||||
- [x] Vyberte a prejdite najmenej jeden tutoriál pre prácu s RASA frameworkom.
|
||||
- [x] Napíšte krátky report na 2 strany kde napíšete čo ste urobili a čo ste sa dozvedeli.
|
||||
- [x] Vytvorte chatbota, ktorý sa bude vedieť predstaviť a odpovedať koľko je hodín.
|
||||
- [x] Zistite čo je to NLU a napíšte o tom krátku správu.
|
||||
- [-] Prečítajte si Horániho BP.
|
||||
- [-] Zistite ako pracuje RASA a napíšte o tom krátku správu. Zistite, aké neurónové siete sa tam používajú.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Rozbehajte Horániho chatbota.
|
||||
- Pridajte podporu slovenčiny do Vášho chatbota.
|
||||
|
||||
|
||||
|
||||
|
||||
151
pages/students/2021/matej_novotny/README.md
Normal file
@ -0,0 +1,151 @@
|
||||
---
|
||||
title: Matej Novotný
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [dp2026]
|
||||
tag: [nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
|
||||
rok začiatku štúdia: 2021
|
||||
|
||||
# Diplomová práca 2026
|
||||
|
||||
Klasifikácia webových dát pre lepšie jazykové modelovanie
|
||||
|
||||
Repo https://git.kemt.fei.tuke.sk/mn180gd/diplomovka
|
||||
|
||||
Zadanie:
|
||||
|
||||
1. Vypracujte prehľad súčasných prístupov a nástrojov na klasifikáciu webových dát podľa typu a na detekciu nenávistného obsahu.
|
||||
2. Navrhnite a implementujte systém, ktorý automaticky roztriedi webové texty podľa uvedených typov a domén a zároveň vyhodnotí ich úroveň nenávisti.
|
||||
3. Zostavte kvalitný všeobecný a tematický korpus vhodný na trénovanie jazykového modelu.
|
||||
4. Štatisticky analyzujte výskyt jednotlivých kategórií textov a výskyt potenciálneho nenávistného obsahu.
|
||||
5. Slovne vyhodnoťte navrhnutý systém a navrhnite ďalšie zlepšenia pre zvýšenie kvality trénovacích dát.
|
||||
|
||||
|
||||
|
||||
Po trénovaní modelu ho otestujte na relevantných úlohách, vyhodnoťte vplyv klasifikácie a kvality dát na výkonnosť modelu, identifikujte slabé miesta (napr. nedostatočná reprezentatívnosť domén alebo nepresná detekcia nenávisti) a navrhnite konkrétne opatrenia na ich odstránenie.
|
||||
|
||||
Cieľ je lepšie pripraviť webové dáta na trénovanie jazykového modelu.
|
||||
|
||||
1. Trénovacie dáta zotriedime podľa druhu (blogy, eshopy, wikipedia, tematicka stranka, diskusie, kniha, clanok,reklama). Druhy textu vyjadrujú kvalitu. Mozeme identifikovat aj domenu (zdravie, pravo, architektura, auta, ). Na to využijeme alebo natrénujeme model. Môžeme vyhodnotiť aj mieru nenávisti v danom texte.
|
||||
2. Pomocou informacie o texte vieme zostaviť kvalitný všeobecný alebo tematický korpus. Je možné využiť HPC Devana.
|
||||
3. Z týchto textov chceme natrénovať alebo dotrénovať jazykový model.
|
||||
|
||||
Stretnutie 28.1.2026
|
||||
|
||||
Stav:
|
||||
|
||||
- Skript na vyhodnotenie hatespeech a klasifikáciu dát je pripravený.
|
||||
- Overenie - sklep dataset a mc4.
|
||||
- Slovak bert je fine tune.
|
||||
- klasifikovanie do: blogy, eshopy, wikipedia, tematicka stranka, diskusie,kniha, clanok,správy
|
||||
- Trénovanie na colab.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pridajte kategeóriu iné.
|
||||
- Dotrénujte klasifikátory. Vyhodnotte ich na testovascej množine. Dáta s príkladmi by mali byť rozdelené na térnovanie a testovacie.
|
||||
- Výsledky experimentov dajte do tabuľky. Do práce napíšte trénovací postup aj hyperarametre.
|
||||
- Aplikujte klasifikáciu na webový korpus. Štatistické výsledky dajte do tabuľky.
|
||||
- V teoretickej časti vysvetlite Váš postup a porovnajte ho s inými prístupmi, napr. hplt alebo dolma dataset.
|
||||
- Pripravte prezentáciu
|
||||
|
||||
Stretnutie 13.11.2025
|
||||
|
||||
- Pripravený skript pre rozponávanie nenávisti. Pomocou HF transformers model. Natrénovaný vlastný model na kaggle. Treba na tom ešte pracovať. Založený run_classification z HF transformers examples.
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Dajte skripty na kemt git
|
||||
- Pripravte sadu vzorových url ktoré budú reprezentovať kategórie ktoré nás zaujímajú: blogy, eshopy, wikipedia, tematicka stranka, diskusie, kniha, clanok,reklama, organizácia, pornografia, správy. Z url získajte texty, každý text bude patriť do kategórie. Množinu rozdelte na trénovaciu a testovaciu. Zabezpečte aby materiály z jedného zdroja neboli v oboch naraz.
|
||||
- Na sade natrénujte a vyhodnotte klasifikátor.
|
||||
- Pokračujte v práci na texte.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Pomocou klasifikátorov analyzujte dostupné slovenské dáta.
|
||||
- Overte či je zoznam kategórií správny.
|
||||
- Ak bude bert klasifikátor pomalý, vyskúšajte štatistické metódy z NLTK.
|
||||
|
||||
Stretnutie 9.10.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- HF transformers tutoriály na tokenizáciu.
|
||||
- spísané poznámky - LLM a tokenizácia (2 PDF z google scholar)
|
||||
- stiahnuté nejaké články v wikipédie a vyskúšaný klasifikačný skript.
|
||||
- vytvorený prístup na novotny@titan.kemt.fei.tuke.sk . Používajte adresár /mnt/sharedhome/novotny
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Oboznámte sa so skriptami a dátami v /mnt/sharedhome/hladek/bert-train corpus3, slavic1
|
||||
- Vytvorte skript pre rozpoznávanie nenávisti v texte. Cieľom je vytvoriť korpus bez "nenávistného" textu. Zistite, koľko nenávistných textov je vo webových korpusoch.
|
||||
- Ak je to potrebné, natrénujte model pre ropoznávanie slovenského nenávistného textu. Použite skript pre klasifikáciu a dáta z https://huggingface.co/TUKE-KEMT - senti-sk, toxic-sk a `hate_speech_slovak`.
|
||||
- Píšte si poznámku.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Oboznámte sa s algoritmami v https://www.nltk.org/book/ch06.html
|
||||
- Zistite, či sa nená nenávisť klasifikovať aj nejakou jednoduchšou metódou (bayes, ME) a porovnajte.
|
||||
- Vytvorte model pre klasifikáciu druhu alebo témy textu.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pošlite mi poznámky z DP v 6. týždni.
|
||||
- Kódy z DP dávajte na katedrový GIT.
|
||||
- Naučte sa pracovať s tmux alebo screen
|
||||
|
||||
|
||||
Stretnutie 4.6.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- naštudovaná klasifikácia pomocou Transformer.
|
||||
- preskúmany mc4 dataset.
|
||||
|
||||
Úloha:
|
||||
|
||||
- naučiť sa pracovať s HF Transformers. Prejdite si tutoriál na klasifikáciu dokumentov. Pozrite sa do adresára na githube examples/pytorch/classification, tam nájdete skripty pre klasifikáciu.
|
||||
- Oboznámte sa s existujúcimi modelmi pre klasifikáciu textu (nenávisť, téma, druh ...).
|
||||
- Napísať skript, ktorý nám toho povie veľa o neznámom texte - druh, téma, nenávisť. Cieľ je aby klasifikácia prebiehala rýchlo pretože textu je veľa. Bude treba odhadnúť, koľko času budeme potrebovať na spracovanie veľkého možstva textu - počet kilobajtov za sekundu.
|
||||
|
||||
|
||||
Stretnutie:
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Naučte sa Python. Nainštalujte si prostredie Anaconda.
|
||||
- Naučte sa pracovať s knižnicou Transformers a HuggingFace Hub - prejdite si jeden alebo 2 tutoriály na klasifikáciu textu.
|
||||
- Zistite čo je to jazykový model a urobte si poznámky.
|
||||
- Pozrite si knihu Deep Dive into Deep Learning a napíšte si poznámky.
|
||||
- Zistite, ako funguje neurónová sieť typu Transformer a napíšte si poznámky.
|
||||
- Zistite, čo je to korpus textov mc4.
|
||||
- Zistite, ako funguje klasifikácia textov pomocou Transformera. Zisite, čo je to tokenizácia.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vytovrte množinu príkladov textov z webu a zotriedte ich podľa kvality a druhu.
|
||||
- Natrénujte neurónovú sieť pre rozlišovanie druhov textov.
|
||||
|
||||
Stretnutie 28.3.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Naštudovaný Python, neurónové siete čiastočne.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pozrite si dataset https://huggingface.co/datasets/allenai/c4
|
||||
- Pozite si knihu https://d2l.ai/
|
||||
- Pokračujte v štúdiu HF transformers, vyskúšajte si tutoriály.
|
||||
- Sústredte sa na "Document Classification". a Document Embeddings. Tu sa používajú tzv. encoder-only modely, napr. BERT, SentenceTransformer.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- definovať kategórie, ktoré sú dôležité z hľadiska jazykového modelovania. Ku každej kategórii budú potrebné príklady.
|
||||
- Príklad kategórie: Novinový článok, blog, diskusia, urážlivý text, kniha, odborný článok, doménovo orientovaný text - právo, medicína, reklamna, eshop, inzerát, nelegálny obsah,
|
||||
|
||||
309
pages/students/2021/matej_scislak/README.md
Normal file
@ -0,0 +1,309 @@
|
||||
---
|
||||
title: Matej Ščišľak
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [bp2024, dp2026]
|
||||
tag: [chatbot,rasa,dialog,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
rok začiatku štúdia: 2021
|
||||
|
||||
|
||||
# Diplomová práca 2026
|
||||
|
||||
Názov:
|
||||
|
||||
Znalostné grafy pre zlepšenie vyhľadávania právnych informácií.
|
||||
|
||||
Zadanie:
|
||||
|
||||
1. Vypracujte prehľad súčasných prístupov k využitiu znalostných grafov na vyhľadávanie pomocou jazykových modelov.
|
||||
2. Zostavte vzorový znalostný graf z právnej oblasti.
|
||||
3. Navrhnite a implementujte systém, ktorý pomocou znalostných grafov umožní vyhľadávanie v rozsudkoch, zákonoch a vyhláškach, odpovedanie na otázky a sumarizáciu dokumentov.
|
||||
4. Otestujte systém na navrhnutých úlohách, vyhodnoťte jeho výkonnosť a identifikujte slabé miesta.
|
||||
|
||||
Ciele:
|
||||
|
||||
- Vytvoriť systém pre spracovanie právnych informácií. Systém by mal vedieť vyhľadávať v rozsudkoch, zákonoch a vyhláškac
|
||||
, odpovedať na otázky a sumarizovať dokumenty. Je možné , že riešenie úlohy si vyžiada viac krokov.
|
||||
- Vytvoriť sadu vzorových úloh pre vyhodnotenie takéhoto systému.
|
||||
- Zlepšiť generovanie odpovedí pre úlohy vyžadujúce viac krokov pomocou znalostných grafov
|
||||
|
||||
Repozitár: https://git.kemt.fei.tuke.sk/ms252gb/DP2026
|
||||
|
||||
Stretnutie 30.3.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Vytvorený GraphRAG, skladá sa z FAISS a Neo4J. Neo4J beží lokálne a spája sa so servrom.
|
||||
- Vytvorené testovanie - 110 otázok. Ku každej otázke je správna odpoveď a odpoveď ktorú generoval chatbot. Sú tam očakávané zdroje a vygenerované zdroje.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Nové kódy dajte na GIT.
|
||||
- Overte možnosti zverejnenia databázy otázok.
|
||||
- Poromýšľajte o článku.
|
||||
- Pracujte na texte.
|
||||
|
||||
|
||||
Stretnutie 10.10.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Rozbehaný agent na báze ollama.
|
||||
- naštudované RAG, function calling, retrieval, evaluation.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- zistite, čo je to znalostný graf. Študujte "graph retrieval augmented generation" na google scholar.
|
||||
- Oboznámte sa s databázou Neo4J - zistite ako ju využiť spolu s langchain.
|
||||
- Zistite, ako vieme vylepšiť RAG pomocou znalostného grafu.
|
||||
- Oboznámte sa s tezaurom slovenského práva. Konvertujte PDF s tezaurom do JSON. Použite docling alebo ollama s gpt-oss.
|
||||
a skúste to zaindexovať (do Neo4J).
|
||||
- Navrhnite prompt ktorý konvertuje otázku na Neo4J dopyt pre získanie relevantných dokumentov.
|
||||
- skripty dávajte na GIT.
|
||||
|
||||
|
||||
Letná Príprava:
|
||||
|
||||
- Zopakujte si Python.
|
||||
- Vyskúšajte si prácu s veľkými jazykovými modelmi. Nainštalujte si oollama.
|
||||
- Oboznámte sa s framewworkom LangChain.
|
||||
- pozrite si LangChain Transformers Agents.
|
||||
- Ako funguje FunctionCalling - AgentTools?.
|
||||
- Zistite ako funguje REACT (Reasoning and Acting) Agent - nájdite článok na Scholar.
|
||||
- Zistite ako funguje dotrénovnaie veľkých jazykových modelov. Zistite čo je to PEFT (LORA, QLORA) a čo je to kvantizácia. Zisite čo je to "few shot" prompting.
|
||||
- Čo je to inferenčný server. Zistite čo je to VLLM, na čo je to dobré. Pozri si LocalAI.
|
||||
|
||||
# Diplomový projekt 1 2025
|
||||
|
||||
Stretnutie 14.5.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Naštudovaný REACT
|
||||
- Vytvorený RAG - vektory do FAISS. Model Mistral - ollama inferenčný server.
|
||||
- Vyskúšané generatívne modely OLLAMA.
|
||||
- Problém s "pridávaním súborov na QUADRO".
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pridajte skripty na git.
|
||||
- Pre prácu s lepšími modelmi (väčšie generatívne modely, me5 embeddingy) použite server QUADRO - identifikujte problémy.
|
||||
- Prečítajte si články o agentových jazykových modeloch pre právne informácie a urobte si poznámky.
|
||||
- identifikujte možné zdroje dát pre riešenie právnych problémov.
|
||||
- Navrhnite agentový prístup na riešenie právnych problémov.
|
||||
- Zistite, aké databázy sa používajú na vyhodnotenie a na trénovanie "agentových" (function calling) jazykových modelov.
|
||||
- Pozrite si množinu https://huggingface.co/datasets/TUKE-KEMT/slovak-financial-exam , toto môžeme použiť na vyhodnotenie.
|
||||
|
||||
Zásobnk úloh:
|
||||
|
||||
- Bude treba pripraviť množinu na vydnotenie "agentového" prístupu.
|
||||
- Zostavte množinu vzorových otázok a odpovedí a relevantných dokumentov. Na webe môžete nájsť fóra s právnymi otázkami a na ich základe zostaviť testy.
|
||||
- Dotrénovať vhodný model.
|
||||
|
||||
|
||||
Stretnutie 10.3.2025
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Preštudovať - ako zostaviť RAG systém pomocou LangChain
|
||||
- Zistiť ako fungujú agentové systémy na báze LLM - React. A volanie "nástrojov" function calling pomocou LLM.
|
||||
- Vytvoriť databázu právnych informácií - texty zákonov, vyhlášok a rozsudkov spolu s metainformáciami. Vedúci pridelí prístup na QUADRO. (úloha Šarišský)
|
||||
- Vytvoriť RAG systém pre spracovanie tejto databázy. Inšpirácia prácou Valerii Kutsenko, Yevhenii Leonov, [Oleh Poiasnik](/students/2022/oleh_poiasnik). Môžete sa inšpirovať [GIT BP Poiasnik](https://git.kemt.fei.tuke.sk/op405wm/Bakalarska_praca) (úloha Ščišľak)
|
||||
- Vyhľadať na internete množinu vzorových právnych otázok a vyhodnotiť systém (Šarišský)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
# Bakalárska práca 2024
|
||||
|
||||
|
||||
Názov: Dialógový systém pre potreby samosprávy
|
||||
|
||||
|
||||
Zadanie:
|
||||
|
||||
1. Vypracujte teroretický úvod do modelovania dialógu a povedzte aké metódy sa aktuálne používajú.
|
||||
2. Navrhnite a vytvorte dialógový systém v slovenskom jazyku pre úlohu komunikácie občana s mestom.
|
||||
3. Vykonajte sadu experimentov a dialógovým systémom.
|
||||
4. Vyhodnoťte experimenty a identifikujte miesta pre zlepšenie.
|
||||
|
||||
|
||||
Súvisiace materiály:
|
||||
|
||||
- [Projektová stránka](/topics/chatbot)
|
||||
|
||||
Spolupráca:
|
||||
|
||||
- [Martin Šarišský](/students/2021/martin_sarissky)
|
||||
|
||||
Stretnutie 23.2:
|
||||
|
||||
Stav:
|
||||
|
||||
- Práca na pravidlách aj texte
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vypracujte pravidlá pre rozpoznanie neznámeho zámeru. Cieľ je aby chatbot vedel upozorniť na agendu ktorú nemá implementovanú a vedel ponúknuť čo vie.
|
||||
|
||||
Stretnutie 16.2.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Pridanie "domain" pravidiel pre "bežného" používateľa
|
||||
- Pridané pravidlá pre slovenské mená a ulice.
|
||||
- Zlepšenie rozpoznávanie IČO a rodné číslo.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pracujte na zlepšení rozpoznávania firiem, priezvisk. Firma sa môže volač hocijak, Je tam možnosť využiť obchodný register.
|
||||
- pridajte možnosť využiť chatgpt alebo inú službu na generovanie odpoveďe.
|
||||
- Pridajte testovacie scenáre vytvorené 3. neznalým človekom a vyhodnotte chatbota. Chceme vedieť, aký dobrý je pri rozpoznávaní intentov, a ktoré intenty a entity sú problematické. Určite ako to zlepšiť.
|
||||
- Stále píšte. Zlepšite časť o rozpoznávaní intentov a pomentovaných entít.
|
||||
|
||||
Stretnutie 9.2.
|
||||
|
||||
Stav:
|
||||
|
||||
- Zlepšený proces "rozpoznávania" druhu formulára - chatbot sa spýta, aký formulár treba vyplniť.
|
||||
- Pri vypĺnaní nastal problém s rozpoznávaním mien a adries.
|
||||
- Pridané testovacie "stories".
|
||||
- Je problém keď pri firme sa vyplňa formulára niečo iné ako pri fyzickej osobe.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zlepšite chatbota podľa výsledkov vyhodnotenia.
|
||||
- Pridajte zdrojáky na GIT.
|
||||
- Preskúmajte možnosti využitia ChatGPT
|
||||
- Zlepšite rozpoznávanie pomenovaných entít - mená, priezviská, názvy firiem. Najprv vyskúšajte riešenie cez RASA.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vyskúšajte trénovanie modelu pomocou spacy. spacy-skmodel na githube.
|
||||
- Vyskúšajte možnosť zlepšenia pomenovaných entít cez model Spacy. Pravidlový rozpoznávač alebo alebo rozpoznávač pomocou neurónovej siete.
|
||||
- Vedúci má niekde dáta.
|
||||
|
||||
|
||||
|
||||
Stretnutie 9.1
|
||||
|
||||
Stav:
|
||||
|
||||
- Rozšírenie možnosti formulárov.
|
||||
- Práca na písomnej časti.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zlepšite Vášho chatbota pomocou ChatGPT. So službou viete komunikovať pomocou Python API a "api tokenu". LLM je možné dotrénovať na vlastných dátach. Alebo LLM vie riešiť špecifickú úlohu ktorú definujete pomocou "promptu".
|
||||
- Pokračujte v písomnej časti.
|
||||
- Pripravte testovacie scenáre pre Vašu sadu pravidiel a vyhodnotte pomocou nej chatbota. Jedna množina na vyhodnotenie bude Vaša a druhá množina kolegu Šarišského.
|
||||
- Pripravte prezentáciu a pošlite texty BP na spätnú väzbu, dajte kódy na GIT.
|
||||
- Upravte kódy tak, aby ich vedúci vedel ľahko vyskúšať pomocou Docker.
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Zistite čo je to LangChain a na čo sa používa. Nainštalujte si to a vyskúšajte.
|
||||
|
||||
|
||||
|
||||
Stretnutie 8.12.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Vyriešený problem týkajúci sa SLOTov. Bola potrebná osobnitná funkcia submit.
|
||||
- Práca na písomenj časti.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Vedúci by mal finalizovať zadanie.
|
||||
- [x] Integrovať Vašu bázu pravidiel s kolegom Šarišským. Spraviť z toho jedného bota.
|
||||
- [x] Zistite si ako pracujú veľké jazykové modely LLM a napíšte si o tom poznámky.
|
||||
- [x] Preštudujte si, ako integrovať veľké jazykové modely s RASA. Veľké jazykové modely sú ChatGPT alebo BARD. Na ChatGPT máte k dispozícici študentské kredity cez Azure Dev Tools for Teaching.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- [ ] Zlepšite Vášho chatbota pomocou ChatGPT. So službou viete komunikovať pomocou Python API a "api tokenu". LLM je možné dotrénovať na vlastných dátach. Alebo LLM vie riešiť špecifickú úlohu ktorú definujete pomocou "promptu".
|
||||
|
||||
Stretnutie 14.11.
|
||||
|
||||
Stav:
|
||||
|
||||
- Vyriešený problém s Policy - problém bol asi na strane Stories.
|
||||
- Nastal problém s rozpoznávaním entít. Podarilo sa naštartovať Form, nepodarilo sa rozpoznať slot. Nevie rozpoznať typ priznania za psa.
|
||||
|
||||
|
||||
Stretnutie 3.11.
|
||||
|
||||
Stav:
|
||||
|
||||
- Práca na "Forms" v RASA. Problém s "Policy" konfiguráciou bol skonzultovaný.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Riešte problém s Policy pomocou "debug" výpisov.
|
||||
- Píšte BP. Opíšte ako funguje NLU a ako funguje rozhodovanie pomcou pravidiel v RASA.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Naštudujte si čo je to Reinforcement learning a ako to súvisí s chatbotmi. https://www.telusinternational.com/insights/ai-data/article/reinforcement-learning-primer . Napíšte si o tom aj poznámky.
|
||||
|
||||
|
||||
Stretnutie 27.10
|
||||
|
||||
Stav:
|
||||
|
||||
- Pokračuje písomná príprava a práca na kódoch chatbota.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v otvorených úlohách, aj zo zásobníka.
|
||||
- Študujte generatívne jazykové modely.
|
||||
|
||||
Zásobník:
|
||||
|
||||
- Integrujeme bázu pravidiel oboch chatbotov.
|
||||
|
||||
Stretnutie 6.10.
|
||||
|
||||
Stav:
|
||||
|
||||
- Vypracované úlohy z minulého stretnutia
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Nadviažte na prácu p. Šarišského a navrhnite a implementujte chatbota na riešenie vybraných a analyzovaných úloh. Chatbot by mal vedieť identifikovať problém, mal by vedieť či je schopný ho riešiť. Potom by mal naštartovať postup pre riešenie daného problému.
|
||||
- Naštudujte si RASA Forms aby ste vedeli pomôcť človeku vyplniť formulár.
|
||||
- Vytvorte pomôcku pre vyplnenie formulára s pomocou chatbota a RASA Forms pre viacero problémov. Vyberte jednoduché problémy s malým počtom "slotov".
|
||||
- pravidlá pre chatbota uložte na GIT repozitár s názvom bp2023. Môžete prístup zdieľať s kolegom.
|
||||
- Prečítajte si najnovšie články o chatbotoch vo verejnej správe "chatbot citizen services". Zistite aké metódy používajú a napíšte o tom do písomnej práce.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- naštudujte si ako sa vyhodnocuje RASA chatbot.
|
||||
- napíšte testovacie konverzácie pre Vaše pravidlá.
|
||||
- Zistite ako pracuje generatívny jazykový model (GPT, T5, LLAMA) a ako sa dá využiť v dialógových systémoch. Sú založené na neurónových sieťach typu Transformer.
|
||||
|
||||
Stretnutie 28.9.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Nainštalovaná RASA
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Nainštalujte si Anaconda. Do Anaconda prostredia si nainštalujte RASA.
|
||||
- [-] Pokračujte v štúdiu RASA-Python. Na servri scholar si vyhľadajte termín "natural language understanding".
|
||||
Prečítajte si niekoľko vedeckých článkov alebo kníh na túto tému a napíšte si poznámky.
|
||||
- [x] Pozrite si stránku https://www.esluzbykosice.sk/. Vyberte niekoľko vzorových problémov a ku nim implementuje asistenta na ich riešenie. Napríklad, občan chce zaplatiť za odvoz odpadu a nevie čo má robiť. Alebo občan si kúpil psa a nevie aké má povinnosti.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vytvorte pomôcku pre vyplnenie formulára s pomocou chatbota.
|
||||
|
||||
196
pages/students/2021/nikita_bodnar/README.md
Normal file
@ -0,0 +1,196 @@
|
||||
---
|
||||
title: Nikita Bodnar
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [vp2023,bp2024,bp2025]
|
||||
tag: [chatbot,rasa,dialog,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
|
||||
rok začiatku štúdia: 2021
|
||||
|
||||
# Bakalárska práca 2025
|
||||
|
||||
Zadanie:
|
||||
|
||||
1. Vypracujte prehľad neurónových sietí a metód na vykonávanie opravy textu.
|
||||
2. Vyberte a pripravte slovenské dáta do vhodnej podoby a aplikujte viacero existujúcich modelov na opravu textu.
|
||||
3. Číselne a slovne vyhodnoťte modely a navrhnite zlepšenia.
|
||||
|
||||
Stretnutie 27.3.
|
||||
|
||||
Stav:
|
||||
|
||||
- Text je v lepšom stave.
|
||||
|
||||
Stretnutie 11.3.
|
||||
|
||||
Stav:
|
||||
|
||||
- Vypracované experimenty pre obnovu interpunkcie, zatiaľ na dosť krátkom texte. Výsledky sú v nejakej prezentácii.
|
||||
- Práca na texte BP ???
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Na experimenty použite text z Wikipedia Dejiny Košic https://sk.wikipedia.org/wiki/Dejiny_Ko%C5%A1%C3%ADc
|
||||
- Do práce napíšte, že používate metódu "Zero Shot" - bez dotrénovania. Porovnajte túto metódu sFew Shot a SFT (Supervised Finetuning).
|
||||
- Do prehľadu doplnte odkazy na odborné články - nájdete ich na Google Scholar.
|
||||
- Čím skôr odovzdajte text BP pre získanie spätnej väzby
|
||||
- Nové Kódy pre experimenty nahrajte na GIT.
|
||||
|
||||
Stretnutie:
|
||||
|
||||
Stav:
|
||||
|
||||
- Vybratá množina c4
|
||||
- Vyhodnotenie SlovakBERT, mBERT a Roberta Base pre EN.
|
||||
- Naprogramované úloha doplnenie interpunkcie. Kódy sú na GITE.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [ ] Vyberte slovenské texty z množiny mC4. Na vybranom texte zopakujte experimenty.
|
||||
- [x] Doplnte ďalšie modely typu BERT s podporou slovenčiny. Modely vo veľkosti BASE: Fernet, HPLT, xlm-r, mdeberta, distilmbert
|
||||
- [x] Vypracujte tabuľky s výsledkami experimentov.
|
||||
- [-] Do práce opíšte experimenty.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vypracujte experimenty pre modely Byt5 a slovak t5.
|
||||
|
||||
|
||||
Poznámky 21.1.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Napísané skripty pre vyhodnotenie "masked" language modeling.
|
||||
- Vyhodnotené modely SlovakBERT a multilingualbert BASE.
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Vyberte vhodnú množinu slovenských textov.
|
||||
- [-] Pripravte množinu pre úlohu detekcie chýbajúcej alebo nadbytočnej interpunkcie - (bodka, čiarka, otáznik, výkričník, dvojbodka).
|
||||
- [-] Pripravte množinu pre pre úlohu opravy od identifikovaného preklepu.
|
||||
- [-] Vyhodnotte viaceré modely.
|
||||
- [ ] Pokračujte v písaní práce podľa nového zadania.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Využite modely SlovakT5 a ByT5.
|
||||
|
||||
|
||||
Stretnutie 17.12.
|
||||
|
||||
|
||||
Stav:
|
||||
|
||||
- Práca na skriptoch, nainštalovaný Pytorch, transformers, fairseq,
|
||||
- Skript na prípravu dát - spustený.
|
||||
- chyba pri spustení trénovacieho skriptu - chýba executable.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- ! Začnite pracovať na písomnej časti.
|
||||
- Nainštalujte si Marian NMT.
|
||||
- Vypýtajte si Marian Model na opravu od Ing. Maroš Harahus.
|
||||
- Vyskúšajte ho a vyhodnotte pomocou metriky WER. Zistite si čo je to WER, napíšte to do práce
|
||||
- Nainštalujte si model ByT5 z knižnice HF Transformers. Zistie čo to je, napíšte to do práce.
|
||||
- Vyskúšajte model ByT5 na korekciu textu. Vyhodnoote ho.
|
||||
- Vyskúšajte model SlovakBERT na detekciu preklepov. Model určuje pravdepodobnosť každého slova vo vete. Model vie doplniť chýbajúce slovo, alebo najpravdepodobnejšie slovo. Zistite že ako, napíšte to do práce.
|
||||
- Do práce doplnte odkazy na vedecké články.
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Natrénujte model.
|
||||
|
||||
Stav:
|
||||
|
||||
- Nainštalovaný MarianMT a rozbehaný preklad z nemčiny do angličtiny.
|
||||
- Textová časť je neuspokojivá.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Naučte sa trénovať systém pre strojový preklad.
|
||||
- Vytvorte korpus pre trénovanie systému na opravu textu. Korpus vytvoríte z webového textu (mc4-sk) do ktorého programovo pridáte chyby. Text korpusu mc4 nájdete na HuggingFace Hube. Knižnica datasets slúži na prácu s korpusmi. Korpus musí byť "dostatočne" (viac ako 1GB) veľký.
|
||||
- Natrénujte a vyhodnotte model.
|
||||
- Píšte BP do šablóny podľa pokynov. Prečítajte si odborné články a používajte odkazy. Odborné články nájdete na Google Scholar.
|
||||
|
||||
|
||||
|
||||
# Bakalárska práca 2024
|
||||
|
||||
Korekcia textu pomocou neurónových sietí
|
||||
|
||||
Spolupráca: Maroš Harahus, Andrii Pervashov
|
||||
|
||||
Zadanie BP:
|
||||
|
||||
1. Vypracujte prehľad existujúcich systémov pre neurónový strojový preklad.
|
||||
2. Definujte úlohu korekcie textu a vysvetlite, ako je možné ju riešiť pomocou systému pre strojový preklad.
|
||||
3. Vyberte a pripravte dáta do vhodnej podoby a aplikujte existujúci model pre strojový preklad na opravu textu vo vybranej úlohe.
|
||||
4. Číselne a slovne vyhodnoťte model na vybranej úlohe. Identifikujte jeho slabé miesta a navrhnite zlepšenia.
|
||||
|
||||
|
||||
Stretnutie 24.1.2024:
|
||||
|
||||
Stav:
|
||||
|
||||
- Nie je posun.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Natrénujte jednoduchý ľubovoľný model pre strojový preklad pomocou Marian NMT. Skripty su v repozitári bert-train.
|
||||
- Natrénujte model pre opravu korekcie na slovenskom texte a vyhodnoote ho.
|
||||
- Pokračujte v písaní bakalárskej práce.
|
||||
|
||||
|
||||
Stretnutie 23.11.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Prečítaný článok o Spelling a urobené poznámky
|
||||
- Ostatné úlohy: in progress. Treba pridať!!!
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vedúcim bol odovzdaný funkčný Marian na servri IDOC. Aj model pre generovanie-opravu znakov. Oboznámte sa so systémov. Spustite model pre preklad. Spustite trénovanie.
|
||||
- Vyhodnotte presnosť tohoto systému. Presnosť sa hodnotí metrikou WER, CER. Skripty nájdete v bert-train repozitári.
|
||||
- Zlepšite tento systém.
|
||||
- V texte vysvetlite, ako funguje model typu Transformer. Vysvetlite, ako funguje Marian NMT. Aké neurónové siete používa? Uvedte aj odkazy na odborné články.
|
||||
|
||||
|
||||
Stretnutie 6.10.
|
||||
|
||||
Stav:
|
||||
|
||||
- Štúdium Python a neurónové siete.
|
||||
|
||||
Stretnutie 3.7.
|
||||
|
||||
Stav:
|
||||
|
||||
Existuje model Marian NMT rep korekciu.
|
||||
|
||||
|
||||
Úloha:
|
||||
|
||||
- [-] Zistite ako funguje neurónová sieť typu Transformer.
|
||||
- [x] Nainštalujte si systém Anaconda a prejdite si knihu Dive into Pyhton 3.
|
||||
- [ ] Zistite ako funguje strojový preklad.
|
||||
- [x] Prečítajte si článok Hládek: "Survey of Automatic Spelling Correction" a *urobte si poznámky*.
|
||||
- [-] Prečítajte si knihu https://d2l.ai/
|
||||
- [ ] Vaše zistenia zapíšte do textového súboru. Pridajte odkazy na zdroje - odborné články a blogy.
|
||||
- [ ] Oboznámiť sa zo systémom Marian NMT. Nainštalujte si to a vyskúšajte nejaké demo na strojový preklad.
|
||||
- [ ] Získajte prístup na školský server idoc.
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vyskúšaje natrénovať model Marian NMT podľa návodu na stránke.
|
||||
- Získajte od vedúceho skripty pre trénovanie Marian NMT na úlohu korekcie textu.
|
||||
- Podľa nich natrénujte a vyhodnotte model.
|
||||
- Zistite s akými parametrami model pracuje najlepšie. Skúste model vylepšiť.
|
||||
- Vypracujte webové demo.
|
||||
|
||||
30
pages/students/2021/oleksandr_hryshchenko/README.md
Normal file
@ -0,0 +1,30 @@
|
||||
---
|
||||
title: Oleksandr Hryshchenko
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [dp2026]
|
||||
tag: [ir,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
|
||||
rok začiatku štúdia: 2021
|
||||
|
||||
# Diplomová práca 2026
|
||||
|
||||
Grafové neurónové siete pre získavanie informácií
|
||||
|
||||
Projekt zakončený.
|
||||
|
||||
Stretnutie 13.2.2025
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Precvičte si jazyk Python, nainštalujte si prostredie Anaconda.
|
||||
- Zistite čo sú to grafové neurónové siete. Prečítajte si odborné články a urobte si poznámky. Pozrite sa na https://scholar.google.sk/ vyhľadávajte "graph neural network".
|
||||
- Oboznámte sa s frameworkom LangChain https://python.langchain.com/docs/tutorials/graph/ https://python.langchain.com/v0.1/docs/use_cases/graph/constructing/
|
||||
- Oboznámte sa so systémami pre generovanie odpovede na základe vyľadávania. Retrieval augmented generation.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vytvorte systém pre získavanie informácií, ktorý bude vedieť pracovať s grafovými informáciami. Grafové innformácie môžu byt: slabo štruktúrované dokumenty, napr. súdne rozhodnutia alebo zdravotné informácie. Chceme vedieť spracovať dokumenty, ktoré majú vzájomné a vnútorné vzťahy.
|
||||
210
pages/students/2021/vladimir_ferko/README.md
Normal file
@ -0,0 +1,210 @@
|
||||
---
|
||||
title: Vladimír Ferko
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [bp2024]
|
||||
tag: [dialog,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
rok začiatku štúdia: 2021
|
||||
|
||||
študent KPI, pracovník DTSS
|
||||
|
||||
## Bakalárska práca 2024
|
||||
|
||||
- [Projekt HateSpeech](/topics/hatespeech)
|
||||
- [Pokyny KPI ku záverečným prácam](https://kpi.fei.tuke.sk/sk/zaverecne-prace)
|
||||
- Spolupráca: [Eduard Matovka](/students/2021/eduard_matovka)
|
||||
- Nadväzuje [Martin Jancura](/students/2017/martin_jancura)
|
||||
|
||||
Názov: Anotácia a vyhodnotenie slovenskej databázy nenávistnej reči
|
||||
|
||||
1. Napíšte prehľad existujúcich dátových zdrojov pre úlohu rozpoznávania sentimentu a nenávistnej reči v diskusiách.
|
||||
2. Pripravte korpus diskusií v slovenskom jazyku. Vyberte vhodný zdroj diskusí a pripravte ho do podoby vhodnej na anotáciu.
|
||||
3. Modifikujte existujúcu aplikáciu pre úlohu anotácie nenávistnej reči v diskusiách. Napíšte návod pre anotáciu.
|
||||
4. Anotujte čo najväčšie množstvo dát pre výskyt nenávistnej reči.
|
||||
5. Štatisticky analyzujte výskyt anotovanej nenávistnej reči v diskusiách.
|
||||
|
||||
|
||||
Predbežné zadanie - úlohy na semester:
|
||||
|
||||
- Vytvoriť slovenskú databázu diskusií. Databáza by mala byť prezentovateľná na konferencii a použiteľná pre rozpoznávanie nenávistnej reči.
|
||||
- zobrazte štatistiky získaných dát.
|
||||
- Anotovať sentiment diskusných príspevkov.
|
||||
- Možno anotovať nenávistnú reč. Toto konzultovať s p. Sokolovou.
|
||||
- Z nazbieraných dát zostavte a vyhodnoťte model
|
||||
|
||||
Stretnutie 10.5.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Natrénovaný prvý model slovakbert
|
||||
- Práca na mdeberta
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Konvertujte úlohu na binárnu klasifikáciu.
|
||||
- Zlepšite fitrovanie datasetu.
|
||||
- Natrénujte a vyhodnoťte nové modely pre viac filtrované datasety. Do práce dajte zapíšte výsledné veľkosti a výsledky.
|
||||
|
||||
Pravidlá pre filtrovanie datsetu:
|
||||
|
||||
1. "Dôveryhodní" ľudia idú do testovacej časti
|
||||
2. Máme tri hlasy ku jednému prísmevku. Na určenie triedy nám treba minimálne dva súhlasné hlasy. Ak výjde trieda neviem tak anotáciu vyradíme. Tie hlasy ktoré majú ++= tie sú plus, tieh hlasy ktorú su --=,. tie sú mínus. Ostatné príspevky zahodíme.
|
||||
3. Vyskúšať: Vyhodiť vzorku aj pri akomkoľvek vnútornom nesúhlase. Je viac filtrovaná množina lepšia?
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vytvoriť HF Dataset.
|
||||
|
||||
|
||||
Stretnutie 22.3.
|
||||
|
||||
|
||||
Stav:
|
||||
|
||||
- Práca na vlastnej Flask aplikácii
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pripravte draft práce, ktorý bude obsahovať osnovu a texty ktoré máte. Pracujte na tom ďalej, popri praktických úlohách.
|
||||
- Naštudujte si [OffensEval 2019-20](https://sites.google.com/site/offensevalsharedtask/home). Do práce pridajte časť o tom čo to je, aké články sa o tom publikovali.
|
||||
- Vyhľadajte a opíšte podobné iniciatívy pre anotáciu HS.
|
||||
- Vo vašej antotačnej schéme napodobnite vybraný prístup (OffensEval).
|
||||
- Pred tým než začnete anotovať, konzultujme vybranú anotačnú schému.
|
||||
- Čím skôr začnite anotovať podľa vybranej schémy.
|
||||
|
||||
|
||||
Stretnutie 11.3.
|
||||
|
||||
Stav:
|
||||
|
||||
- Analýza zozbieraných dát z Facebooku pred anotáciou - výber rôznych kanálov. Vo forme notebooku.
|
||||
- Dáta sú v jednom súbore JSON
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Aplikujte detekciu emócií na dataset. Do datasetu zaraďte 20 percent pozitívneho, 20 neutrálneho a 60 negatívneho obsahu.
|
||||
- [x] Dataset premiešajte. Začnite anotovať, akýmkoľvek spôsobom.
|
||||
- [-] Do písomnej časti opíšte postup pri príprave dát.
|
||||
|
||||
Stretnutie 8.2.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Práca na identifikácii podobných príspevkov pomocou embeddingov. V matici sa vyhľadá každý dokument, ktorého kosínusová podobnosť je väčšia ako konštanta.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Získajte dáta z íných zdrojov, vhodné na anotáciu. Kritériá sú: miera výskytu nenávistnej reči, druh nenávistnej reči a legálne nástrahy (osobné dáta, licencia).
|
||||
|
||||
Momentálne máme:
|
||||
|
||||
- Facebook, rôzne profily. Problém je výskyt spamu - tématicky podobných príspevkov.
|
||||
|
||||
Iné možné zdroje:
|
||||
|
||||
- Reddit-Slovakia.
|
||||
- Diskusie pod článkami.
|
||||
|
||||
|
||||
|
||||
|
||||
Stretnutie 23.1.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Práca iba na textovej časti.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pripravte dátovú množinu na anotovanie. Vyberte také dáta, ktoré obsahujú málo spamu a primerané množstvo "hatespeech". Môžete "nascrapovať" nové zdroje, také ktoré sú vhodnejšie.
|
||||
- Pripravte aplikáciu na anotovanie a skúste anotovať pár jednotiek. Zaznamenajte chyby anotačnej aplikácie.
|
||||
- Ak bude aplikácia v poriadku, anotujte viac.
|
||||
- Pokračujte v práci na textovej časti podľa inštrukcií nižšie.
|
||||
- Pokračujte v otvorených úlohách.
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Prečistenie databázy na výskyt spamu: Pomocou modelu slovak-bert-mnlr identifikujte sémanticky podobné dokumenty. Ak má jeden dokument príliš veľa podobných, označte ho ako spam. Konzultovať s Stromko alebo Sopkovič. Asi bude treba použiť vektorový index.
|
||||
- Z anotovaných dát natrénujte model.
|
||||
|
||||
|
||||
Stretnutie 27.10.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Podarilo sa rozbehať anotačnú aplikáciu a pripraviť dáta.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pripravte aplikáciu na nasadenie. Pripravte dockerfile, pridajte CSS. Vyskúšajte aplikáciu a identifikujte chyby.
|
||||
- Pokračujte v teoretickej príprave podľa pokynov nižšie. Sústredte sa na anotáciu a automatické rozpznávanie nenávistnej reči. Môžete vyjadriť aj súvis medzi rozpoznávaním sentimentu a nenávistnej reči. Na vyhľadávanie článkov použite Google scholar. Do práce si poznačte bibliografický odkaz na článok ktorý preštudujete. Ku každému článku si napíšte poznámky čo ste sa dozvedeli.
|
||||
- Oboznámte sa so skriptom https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification skúste ho rozbehať aj na iných vlastných dátach.
|
||||
- Prečítajte si knižku https://d2l.ai/
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Analyzujte anotované dáta. Výsledky zobrazte do tabuľky.
|
||||
- Natrénujte a vyhodnoťte model.
|
||||
|
||||
|
||||
Stretnutie 13.10.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Rozbehané Prodigy anotácie
|
||||
- Vyskúšaný model https://huggingface.co/kinit/slovakbert-sentiment-twitter
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [ ] Vykonať prieskum literatúry. Aké sú existujúce anglické a slovenské databázy na analýzu sentimentu? Ako sa klasifikuje sentiment pomocou neurónových sietí? Prieskum by mal mať niekoľko strán a mal by obsahovať odkazy na odbornú literatúru a iné zdroje. https://github.com/slovak-nlp/resources Tu pozrite zoznam modelov a datasetov pre sentiment. Nájdite aj niekoľko článkov na tému "crowdsourcing dataset for sentiment classification". Robte si písomné poznámky, použije sa to do BP.
|
||||
- [ ] Vytvorte KEMT GIT repo. Nastavte tam synchronizáciu s KPI Git tak aby som mal prístup k zdrojovým kódom na stiahnutie a na tvorbu modelov.
|
||||
- Preštudujte si zdrojové kódy https://github.com/hladek/hate-annot a skúste ich rozbehať na svojom počítači s Vašimi dátami.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Čím skôr rozbehať anotácie sentimentu alebo hate speech medzi študentami.
|
||||
- Zozbierané dáta využiť na natrénovanie modelu.
|
||||
- Oboznámte sa so skriptom https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification skúste ho rozbehať aj na iných vlastných dátach.
|
||||
- Prečítajte si knižku https://d2l.ai/
|
||||
|
||||
|
||||
|
||||
Stretnutie 8.8.
|
||||
|
||||
Stav:
|
||||
|
||||
- vypracovaný skript pre získanie dát z Reditt
|
||||
|
||||
Úlohy:
|
||||
|
||||
|
||||
- [x] Rozbehajte u seba jednoduché anotácie pomocou Prodigy. V texte označujte časti, ktoré sú urážlivé. Môžete to urobiť podľa skritpov v https://git.kemt.fei.tuke.sk/dano/annotation . Dáta anotujete podobne ako "named entities".
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Finalizovať dátovú množinu (facebook alebo reddit) a anotačnú schému.
|
||||
- Pripraviť návod pre anotátorov
|
||||
- Pripraviť webovú appku na sledovanie anotácií.
|
||||
- Natrénovať model.
|
||||
|
||||
Stretnutie 29.6.2023
|
||||
|
||||
Stav:
|
||||
|
||||
- Je hotový skript pre zber diskusií z Facebooku. Skript je Python, Selenium a BS4.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [ ] Vykonať prieskum literatúry. Aké sú existujúce anglické a slovenské databázy na analýzu sentimentu? Ako sa klasifikuje sentiment pomocou neurónových sietí? Prieskum by mal mať niekoľko strán a mal by obsahovať odkazy na odbornú literatúru a iné zdroje. https://github.com/slovak-nlp/resources Tu pozrite zoznam modelov a datasetov pre sentiment.
|
||||
- [ ] Skript na stiahnutie s krátkym komentárom dajte na KEMT GIT. Repo nazvite BP2024
|
||||
- [ ] Vyskúšajte rozpoznávanie sentimentu pre slovenčinu pomocou existujúceho modelu Huggingface Transformers. https://huggingface.co/kinit/slovakbert-sentiment-twitter Vyskúšajte tento model.
|
||||
- V prípade potreby Vám viem prideliť prístup na školský server s GPU.
|
||||
|
||||
|
||||
|
||||
|
||||
187
pages/students/2022/andrii_pervashov/README.md
Normal file
@ -0,0 +1,187 @@
|
||||
---
|
||||
title: Andrii Pervashov
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [bp2025,dp2027]
|
||||
tag: [rag,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
|
||||
rok začiatku štúdia: 2022
|
||||
|
||||
# Diplomová práca 2027
|
||||
|
||||
Návrh na tému:
|
||||
|
||||
Prepis reči pre tvorbu štruktúrovaného zdravotného záznamu
|
||||
|
||||
Repo https://git.kemt.fei.tuke.sk/ap565wq/diplomova_praca
|
||||
|
||||
|
||||
Ciele:
|
||||
|
||||
- Vytvorte systém pre prepis reči a naplnenie formulára pomocou lokálnych jazykových modelov
|
||||
- Zlepšite jazykový model pre extraktiu štruktúrovaných informácií z medicínskej alebo súdnej domény.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Oboznámte sa so systémom OpenWebUI - prečítajte si dokumentáciu, príp. spravte si svoju inštanciu.
|
||||
- Vytvorte jedno alebo viacero rozšírení, ktoré umožnia napňlňať formuláre pomocou rečového vstupu.
|
||||
- Agent by mal vedieť transformovať rečový vstup do štruktúrovanej podoby.
|
||||
|
||||
Teoretické úlohy:
|
||||
|
||||
- Oboznámte sa s postupmi pre dotrénovanie jazykového modelu - LORA, PEFT.
|
||||
- Oboznámte sa s metódami Information Extraction. Vyhľadajte si články na túto tému a napíšte, aké metódy sa používajú. Vstupom je text v prir. jazyku, výstupom je niečo ako JSON.
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
- Vyskúšajte ako funguje rozpoznávanie reči cez OPeWEBUI. Navrhnute zlepšenia.
|
||||
- Ako vieme zistiť, ktoré informácie nám chýbajú?
|
||||
|
||||
Stretnutie 10.6.2026
|
||||
|
||||
Stav:
|
||||
|
||||
- prepísaný kód rozhrania do knižnice next js.
|
||||
- použitie lokálnych modelov cez ollama, zatiaľ qwen3-4B beží na PC. Model nejde veľmi dobre.
|
||||
- Na PC beží aj lokálny Whisper - funguje oveľa horšie.
|
||||
- aplikácia je kontajnerizovaná - docker compose.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Oboznámte sa s postupmi pre dotrénovanie jazykového modelu - LORA, PEFT.
|
||||
- Oboznámte sa s metódami Information Extraction. Vyhľadajte si články na túto tému a napíšte, aké metódy sa používajú. Vstupom je text v prir. jazyku, výstupom je niečo ako JSON. Napíšte si poznámky.
|
||||
- Vyhľadajte články o podobných prístupoch - ako rečovo naplniť formulár.
|
||||
- Zistite podrobnosti o procese tvorby formulára "Záznam o zhodnotení zdravotného stavu osoby". Získajte vzor. Zistite otázky ktoré sú dôležité.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Zostavte testovací scenár a testovaciu množinu.
|
||||
- Nasadte aplikáciu na školskej infraštruktúre a využite kvalitnejšie jazykové modely a modely pre rozpoznávanie reči.
|
||||
- Implementujte mechanizmus spätnej väzby - kontrola správnosti a doplnenie chýbajúcich hodnôt.
|
||||
|
||||
|
||||
## Bakalárska práca 2025
|
||||
|
||||
|
||||
Návrh na tému:
|
||||
|
||||
Korekcia textu pomocou neurónových sietí
|
||||
|
||||
- Oboznámte sa s existujúcimi systémami pre neurónový strojový preklad.
|
||||
- Aplikujte existujúci model na opravu textu vo vybraných úlohách.
|
||||
- Vyhodnnotte model pomocou overovacej množiny.
|
||||
|
||||
Návrh na zadanie práce:
|
||||
|
||||
1. Napíšte prehľad metód opravy textu pomocou neurónových modelov.
|
||||
2. Zostavte trénovací korpus a natrénujte vybraný model na úlohu opravy textu v slovenskom jazyku.
|
||||
3. Navrhnite experiment a vyhodnoťte kvalitu natrénovaného neurónového modelu.
|
||||
4. Identifikujte možné zlepšenia navrhnutého modelu.
|
||||
|
||||
Stretnutie 14.2.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Pokračuje trénovanie.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Definujte problém ktorý riešite.
|
||||
- Napíšte aj stručné poznámky z článku Survey of Automatic Spelling Correction.
|
||||
- Do teoretickej časti napíšte ako funguje model transformer, model T5.
|
||||
- Do praktickej časti napíšte o tom ako ste vytvorili dátovú množinu, ako ste navrhli, vyýkonali a vyhodnotili experimenty.
|
||||
- V texte používajte odkazy na odbornú literatúru. Články z google scholar.
|
||||
|
||||
Stretnutie 31.1.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Vyskúšané byt5, problémy s pamäťou, problémy s obmedzením dĺžky.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte s obmedzením ktoré dovolí GPU pamäť (128 znakov).ň
|
||||
- Píšte prácu. Výsledky zobrazte v tabuľke.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vyskúšajte iný model, napr. slovak-t5-base.
|
||||
|
||||
Stretnutie 19.12.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Nové trénovanie Byt5 z mc4. Vyzerá, že to ide. Vlastný trénovací skript, skript od Ing. Harahusa.
|
||||
- Text prepísaný do Latex, WIP
|
||||
|
||||
|
||||
Stretnutie 22.11.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- WikiEdits nefunguje.
|
||||
- Trénovanie na korpuse 1 kníh. Program zmení písmená, urobí gramatické chyby. Problém je v tom, že dát na natrénovanie je málo. BLEU ROUGE nie sú dobré metriky.
|
||||
- Na trénovanie sa používa mt5-large.
|
||||
- Konzultácia Ing. Harahusom PhD.
|
||||
- Trénovanie modelu.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v písaní podľa pokynov nižšie.
|
||||
- Implemenujte metódu vyhodnotenia WER-CER-SER. Použite Python balíček alebo ex. kód. python-levenshtein.
|
||||
- Vyhodnnotte model "zero shot" - bez dotrénovnaia. Vyhodnotte viac modelov. Môžťete vyskúšať aj Slovak Falcon, slovak t5 base.
|
||||
- Pokračujte s "base modelmi".
|
||||
- Vyskúšajte opravu textu pomocou "promptu". Použite veľký jazykový model. Vyberte vhodný, napr. chatgpt alebo iný.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Dotrénujte model typu t5-base na väčšom množstve dát. MNôžete použiť webový korpus - mc4.
|
||||
|
||||
|
||||
|
||||
|
||||
Stretnutie 3.10.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Spustený skript WikiEdits bez úprav. Výsledkom bol (asi) dobrý súbor csv s úpravami v slovenskom jazyku.
|
||||
- Vyskúšané dotrénovanie modelu mt5-base na tejto databáze. Trénovanie sa spustí. Po zatvorení tmux sa trénovanie nepodarí obnoviť.
|
||||
|
||||
|
||||
Online update 4.9.2024
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Upravte skripty [WikiEdits](https://github.com/snukky/wikiedits/tree/master/wikiedits) na slovenský jazyk
|
||||
|
||||
Stav 14.8.2024:
|
||||
|
||||
- Nainštalovaná Anaconda, rozbehaný anglický trénovací skript s databázou WikiEdits a modelom T5small. Notebook je príliš pomalý na trénovanie.
|
||||
- Oboznámenie sa s materiálmi - d2dl aj Python.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v štúdiu modelov T5 aj GPT aj ChatGPT. Robte si písomné poznámky. Poznačte si odkazy na odborné články, napr. Arxiv.
|
||||
- Použite server google scholar a zistite ako sa robí ooprava textu pomocu modelu T5. Poznačte si články ktoré sa týkajú tejto témy a napíšte o čom tie články sú.
|
||||
- Prečítajte si môj článok Survey of Automatic Spelling Correction a urobte si poznámky,
|
||||
- dotrénujte anglický model t5 small na opravu a vyhodnotte ho. Na vyhodnotneie sa používa metrika WER, CER, SER, BLEU. Zistite čo to je.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Natrénujte model pre opravu textu v slovenskom jazyku.
|
||||
- Pripravte webové demo.
|
||||
|
||||
Stretnutie 26.4. 2024
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Nainštalujte si prostredie Anaconda.
|
||||
- Prejdite si knihu Dive Deep into Python 3.
|
||||
- Prečítajte si knihu https://d2l.ai/ a napíšte si poznámky.
|
||||
- Nainštalujte si Pytorch, a huggingface transformers a oboznámte sa ako funguje táto knižnica.
|
||||
- Zistite ako funguje tento model https://huggingface.co/docs/transformers/en/model_doc/byt5
|
||||
- Napíšte si poznámky o tom ako funguje model Transformers a ako funguje model T5.
|
||||
|
||||
126
pages/students/2022/daniil_huzenko/README.md
Normal file
@ -0,0 +1,126 @@
|
||||
---
|
||||
title: Daniil Huzenko
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [bp2025]
|
||||
tag: [klaud]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
|
||||
rok začiatku štúdia: 2022
|
||||
|
||||
# Bakalárska práca 2025
|
||||
|
||||
Vedúci: doc. Matúš Pleva PhD.
|
||||
|
||||
Predbežný názov:
|
||||
|
||||
Testovanie hybridného klaudu s využiťím kombinácie verejného a privátneho riešenia
|
||||
|
||||
Cielom práce je vytvorenie vzelávacích materiálov o Kubernetes a funkčného prototypu privátneho klastra Kubernetes .
|
||||
|
||||
Zadanie:
|
||||
|
||||
1. Napíšte prehľad metód automatizácie procesov a vypracujte úvod do platformy Kubernetes.
|
||||
2. Vypracujte prehľad domácich klastrov založených na platforme ARM.
|
||||
3. Zostavte vlastný klaster z viacerých dosiek Raspberry PI.
|
||||
4. Nakonfigurujte na klastri platformu Kubernetes opakovateľným spôsobom a porovnajte riešenie s podobným na platforme Intel.
|
||||
5. Vypracujte textový a video tutoriál (s titulkami vo viacerých jazykoch) k zostaveniu a konfigurácii klastra s Raspberry PI.
|
||||
|
||||
Stretnutie 21.2.
|
||||
|
||||
- Pridajte kapitolu o Azure Kubernetes System.
|
||||
- Porovnajte vytvorenie K8s klastra s RPI a vytovrenie klastra s AKS. Napíšte ako je možné tieto dva spôsoby kombinovať. Napíšte ako funguje hybridný klaud.
|
||||
- Pozrite si ako sa dá vytvoriť domáci klaster z RPI. Napíšte o tom do práce aké sú spôsoby.
|
||||
|
||||
Stretnutie 14.2.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Do teoretickej časti napíšte prehľad odbornej literatúry - použitie Kubernetes vo vzdelávaní. použite google scholar. Heslo je "kubernetes in education".
|
||||
|
||||
Stetnutie 22.11.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Klaster funguje. Ku každému node je možné sa pripojiť cez SSH.
|
||||
- Momentálne notebook slúži ako router.
|
||||
- Práca na DNS MASQ prideľovanie IP adries z routra.
|
||||
- Microk8s funguje
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Napíšte návod a skripty pre konfiguráciu routra pre K8s klastra SuperC.
|
||||
- Router by mal vedieť:
|
||||
- prideliť IP adresu v privátnej podsieti pre všetky uzly klastra.
|
||||
- mal by vedieť konfigurovať (resetovať) klaster pomocou Ansible.
|
||||
- Vyporacujte video a textový tutoriál k inštalácii klastra.
|
||||
- Skripty a návody dajte na GIT. Video nedávajte na GIT. (dajte na Youtube).
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Router by mal slúžiť ako rozhranie medzi verejnou a súkromnou sieťou - mal by sprostredkovať služby Kubernetes. Dorobte na to skripty Ansible a K8s konfiguráciu - Ingress, Load Balancer, Dashboard.
|
||||
|
||||
|
||||
Stretnutie 14.11
|
||||
|
||||
Stav:
|
||||
|
||||
- 1 ks klastra je zmontovany
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Napíšte o tom čo je to kontajnerizácia, čo je Kubernetes, stručne o Rpi CM4 a Super6C - opíšte HW.
|
||||
- Píšte o metódach orchestrácie. Čo je to a akými metódami sa to robí?
|
||||
- Napíšte o Ansible. Ako riadiť klaster pomocou Ansible?
|
||||
- Citujte knihy a odborné články. Nájdete to na google scholar.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Pripravte skripty Ansible pre "setup" klastra
|
||||
- Pripravte skripty pre "reinstall" klastra poocou Ansible
|
||||
- Zistite ako funguje netboot na rpi, skúste reinstall cez networkboot.
|
||||
|
||||
Stretnutie 12.11.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Písanie draftu BP
|
||||
- Vyskúšané tutoriály s Minikube.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zmontujte Raspberry Pi klaster: 1x skrinka s príslušenstvom, 6x RPI Compute Module 4, 1 doska a zdroj SUper6C.
|
||||
- Urobte videoblog o tom ako zmontovať RPI klaster. Akým jazykom? Po rusky alebo po slovensky?
|
||||
- Zistite čo je to MicroK8s
|
||||
- Pokračujte v písaní BP. Používajte citácie na odbornú literatúru ()knihy a odborné články. Do BP píšte aj o hardvéri ktorý ste dostali. Odborné články nájdete na google scholar.
|
||||
- Prihláste sa na Azure KLaud.
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Oživte klaster a nainštalujte na neho MicroK8s. Inštaláciu urobte ľahko opakovateľnú pomocou skriptu.
|
||||
- Nainštalujte monitorovacie nástroje na klaster.
|
||||
- Urobte deployment aplikácie na privány klaster aj na verejnmý klaster (AKS).
|
||||
- Urobte druhý videoblog o inštalácii softvéru na náš klaster.
|
||||
- Napíšte textový blog o tom čo ste urobili - cieľ je poučiť a inšpirovať študentov.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Stretnutie 4.10.2024
|
||||
|
||||
Stav:
|
||||
|
||||
Naštudovaný Kubernetes, nainštalované Minikube
|
||||
|
||||
Úlohy:
|
||||
|
||||
|
||||
- [x] Napíšte draft BP. Napíšte čo je to Kubernetes a ako sa používa.čo je to kontajnerizácia
|
||||
- [x] Napíšte, aké nástroje sa používajú na monitoring klastra.
|
||||
- [-] Vyskúšajte a opíšte nástroj Prometheus, Istio. Zistite čo je service-mesh. Čo je „network fabric“ – Calico.
|
||||
|
||||
|
||||
88
pages/students/2022/jakub_schwarc/README.md
Normal file
@ -0,0 +1,88 @@
|
||||
---
|
||||
title: Jakub Schwarc
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [dp2027]
|
||||
tag: [nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
|
||||
rok začiatku štúdia: 2022
|
||||
|
||||
# Diplomový projekt 2026
|
||||
|
||||
|
||||
Téma:
|
||||
|
||||
Inštrukčné dotrénovanie jazykového modelu
|
||||
|
||||
Ciele na semester:
|
||||
|
||||
- Dotrénujte a vyhodnotte Slovak Mistral.
|
||||
|
||||
Stretnutie 10.6.2026
|
||||
|
||||
Stav:
|
||||
|
||||
- kódy sú na servri titan
|
||||
- funguje dotrénovanie Slovak Mistral pomocou Slovak Alpaca na Titan, pomocou unsloth aj LlamaFactory. Používa sa qlora.
|
||||
- po dotrénovaní to je ručne vyskúšané. Nevie odborné výrazy. Model rozumie jednoduchým inštrukciám. Model je ukecaný.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vytvorte GIT repozitár a dajte tam kódy.
|
||||
- Pre LLmamaFactory dávajte na GIT konfigurácie.
|
||||
- Rozšírte trénovaciu sadu - o zdroje v https://github.com/slovak-nlp/resources Zatiaľ najlepšie vyzerá byť CohereLabs/aya_collection_language_split
|
||||
- Model zverejnite na HuggingFace hube.
|
||||
- Napíšte si poznámky o aktuálnych metódach PEFT a SFT. Preštudujte si vedecké články z Google Scholar.
|
||||
- Vyhodnotte model pomocu lm-evaluation-harness. Pozrite si výsledky https://wandb.ai/hladek/lmeval?nw=nwuserhladek
|
||||
|
||||
Príkaz na vyhodnotenie je
|
||||
```
|
||||
/home/dh343ko/miniconda3/envs/transformers/bin/lm-eval --model hf --model_args pretrained=google/mt5-large --tasks arc_sk,hellaswag_sk,m_mmlu_sk,truthfulqa_sk_mc1,truthfulqa_sk_mc2,sklegal,skquad --output_path zzz --wandb_args project=lmeval_mt5-large --device cuda:0 --batch_size 8
|
||||
```
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Možno bude potrebné použiť lepší HW.
|
||||
- Zlepšite proces vyhodnotenia. Dá sa použiť sk bech ktorý je v príprave.
|
||||
- Zistite, čo je to zarovnanie jazykových modelov. Pozrite si framework huggingface trl. Zistite, čo je to meóda DPO a RLHF. Ku tomu existuje DP práca Hyrenko.
|
||||
- Strojovo preložte vybranú množinu.
|
||||
- Vytvorte github repozitár so skriptami pre dotrénovanie jazykovéo modelu.
|
||||
|
||||
|
||||
|
||||
Stretnutie 27.2.
|
||||
|
||||
- Oboznámte sa problematikou podľa zadaných zdrojov.
|
||||
- Pozrite si https://allenai.org/olmo
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Oboznámte sa s problematikou veľkých jazykových modelov. Towards Data Science
|
||||
- Naučte sa Python lepšie. Nainštalujte si prostredie Anaconda.
|
||||
- Poučte sa o strojovom účení. Dive into deep learning.
|
||||
- Vyskúšajte si framework HF Transformers.
|
||||
- Oboznámte sa s repozitárom https://github.com/allenai/open-instruct, prečítajte si články
|
||||
- Oboznámte sa s repozitárom https://github.com/nlp-uoregon/Okapi, prečítajte si články
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Pracujte na teoretickej časti: opíšte základné pojmy, metódy a dátové množiny. Používajte google scholar a bibliografické odkazy.
|
||||
- Najprv pracujte s domácou GPU, ak nebude stačiť pracujte s Google Coolab, ak nebude stačiť požiadajte konzultanta.
|
||||
- Naštudovať a vyskúšať PEFT-QLORA.
|
||||
- Oboznámte sa s knižnicou "unsloth".
|
||||
- Oboznámte sa s Huggingface TRL.
|
||||
- Oboznámte sa s https://github.com/hiyouga/LLaMA-Factory
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
102
pages/students/2022/jan_malinovsky/README.md
Normal file
@ -0,0 +1,102 @@
|
||||
---
|
||||
title: Ján Malinovský
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [dp2027]
|
||||
tag: [rag,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
|
||||
rok začiatku štúdia: 2022
|
||||
|
||||
# Diplomový projekt 2026
|
||||
|
||||
|
||||
Téma:
|
||||
|
||||
Grafové vyhľadávanie pre podporu vzdelávania
|
||||
|
||||
Ciele na semester.
|
||||
|
||||
- Zistite čo je to Retrieval Augmented Generation
|
||||
- Zistite, čo je to znalostný graf
|
||||
- Naučte sa čo je to GraphRAG
|
||||
- Zostavte malý znalostný graf z oblasti vzdelávania. Pri zostavení môžete využiť jazykový model. Môžete preložiť existujúci znalostný graf.
|
||||
- Využite znalostný graf pre zlepšenie práce alebo vysvetliteľnosti jazkového modelu
|
||||
|
||||
Napr.
|
||||
|
||||
- výchovné opatrenia v špeciálnej pedagogike.
|
||||
- osnovy pre výuku na základnej škole.
|
||||
- spôsoby práce asistenta pedagóga.
|
||||
|
||||
Stretnutie 14.5.2026
|
||||
|
||||
Stav:
|
||||
|
||||
- Preštudované materiály podľa pokynov nižšie .
|
||||
- Získané dokumenty - osnovy pre pre základné školy: slovenčina, matematika, angličtina, informatika, fyzika, biológia, občianska náuka, telesná výchova, chémia pre všetky ročníky.
|
||||
- Extrahovaný text pomocou pypdf a docx. Sú tam aj excel tabuľky, ale tie nie sú extrahované.
|
||||
- Text sa rozdelí na chunky (cca 8000 znakov), vypočíta sa hash na deduplikáciu.
|
||||
- Pomocou LM sa dokument transformtuje na JSON. Z dokumentu LLM extrahuje "vzdelávacie koncepty" a vzťahy medzi nimi. Vzťahy sú z určenej množiny typu "implements", "depends on", "teaches", "requires".
|
||||
- Výsledok sa zobrazí vo forme grafu.
|
||||
- Vytvorený jednoduchý agent, ktorý vyhľadáva v znalostnom grafe a na základe týchto informácií generuje odpoveď.
|
||||
|
||||
|
||||
|
||||
Zdroje doumentov:
|
||||
|
||||
- https://www.minedu.sk/vzdelavacie-standardy-pre-1-stupen-zs/
|
||||
- https://www.minedu.sk/vzdelavacie-standardy-pre-2-stupen-zs/
|
||||
- https://podporneopatrenia.minedu.sk/zabezpecenie-posobenia-pedagogickeho-asistenta-v-triede/
|
||||
- https://www.upsvr.gov.sk/socialne-veci-a-rodina/rodina/opatrenia-socialnopravnej-ochrany-deti-a-socialnej-kurately/socialno-pravna-ochrana-deti/opatrenia-na-zabezpecenie-ochrany-zivota-zdravia-a-vyvinu-dietata/vychovne-opatrenia.html?page_id=1205
|
||||
- https://www.minedu.sk/pedagogicky-asistent-podporne-opatrenie/
|
||||
- https://podporneopatrenia.minedu.sk/katalog-podpornych-opatreni/
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- *dajte zdrojové kódy na GIT*.
|
||||
|
||||
Týka sa ďalšieho obdobia:
|
||||
|
||||
- Pozrite si https://github.com/hkuds/minirag . Prečítajte si článok, vyskúšajte zdrojové kódy s dátami ktoré máte.
|
||||
- Pozrite si https://github.com/HKUDS/LightRAG. Prečítajte si článok, pozrite zdrojové kódy, môžete aj vyskúšať.
|
||||
- Preštudujte si jazyk Cypher.
|
||||
- Preštudujte si embedding modely a vektorové databázy, napr. ChromaDB a multilingual e5-large.
|
||||
- Pokračujte štúdiu GraphRAG:
|
||||
- Vytovrte webové demo pre pomoco pedagógovi pri príprave na hodinu. Môžete použiť gradio alebo streamlit.
|
||||
- Vytvorte agenta pre pomoc učiteľovi alebo pedagogickému asistentovi pri príprave na vyučovanie.
|
||||
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Využite školskú infraštruktúru
|
||||
- Zlepšite proces tvorby znalostného grafu. Zlepšite druhy vzájomných vzťahov, zlepšite proces extrakcie.
|
||||
- Vytvorte proces zhlukovania konceptov (pomenovaných entít)
|
||||
- Použite grafovú datagázu Neo4J alebo inú.
|
||||
- Jeden z možných spôsobov vyhľadávnaia je použitie relačnej dabázy.
|
||||
- Preštudujte si spôsoby vyhodnotenia RAG - RAGAS, DeepEval a vyhodnnotte systém.
|
||||
|
||||
|
||||
Stretnutie 20.2.2026
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Naučte sa programovať v [Python](https://zp.kemt.fei.tuke.sk/topics/python).
|
||||
- Zistite, čo je to RAG. Zistite ako funguje generatívny model. Napíšte o tom poznámky a zdroje ktoré ste použili.
|
||||
- Prihláste sa na https://ui.tukekemt.xyz/ , api https://docs.openwebui.com/reference/api-endpoints/
|
||||
- https://docs.langchain.com/oss/python/langchain/quickstart
|
||||
- Pozrite si https://graphrag.com/concepts/intro-to-graphrag/
|
||||
- https://docs.langchain.com/oss/python/integrations/retrievers/graph_rag
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Indexujte a vyhľadávajte v databáze dokumentov z oblasti vzdelávania.
|
||||
- Oboznámte sa s https://github.com/topoteretes/cognee
|
||||
|
||||
|
||||
|
||||
72
pages/students/2022/jan_ptak/README.md
Normal file
@ -0,0 +1,72 @@
|
||||
---
|
||||
title: Ján Pták
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [dp2027]
|
||||
tag: [rag,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
|
||||
rok začiatku štúdia: 2022
|
||||
|
||||
# Diplomový projekt 2026
|
||||
|
||||
|
||||
Téma:
|
||||
|
||||
Agent pre manažment záverečných prác
|
||||
|
||||
|
||||
Ciele na semester.
|
||||
|
||||
- Zistite čo je to Retrieval Augmented Generation
|
||||
- Vytvorte agenta pre zlepšenie manažmentu záverečných prác zpwiki.
|
||||
- Ako rozhranie použite OpenWebUI.
|
||||
- Navrhnite deployment pomocou Docker. Implementujte aj synchronizáciou (pomocou WebHOOK)
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Zistite, čo je to znalostný graf
|
||||
- Naučte sa čo je to GraphRAG
|
||||
- Využite znalostný graf pre zlepšenie práce alebo vysvetliteľnosti jazykového modelu
|
||||
|
||||
Stretnutie 8.6.2026
|
||||
|
||||
Stav:
|
||||
|
||||
- Odovzdané nejaké zdrojové kódy na https://git.kemt.fei.tuke.sk/jp170na/dp-zp-agent - načítanie z markdown, indexovanie do SQLite a FastAPI.
|
||||
- Ostatné úlohy neboli vyriešené.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v otvorených úlohách. Vypracujte písomnú správu o preštudovaných materiáloch.
|
||||
- Sústredte sa na GraphRAG. Použite google scholar a https://graphrag.com/
|
||||
- Pozrite si kódy na https://github.com/hladek/kemthesis
|
||||
- Pozrite si systém https://github.com/hkuds/minirag
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Nové smerovanie môže byť spracovanie textov záverečných prác. Vytvorte RAG systém pre vyhľadávanie v záverečných prácach.
|
||||
- Napojte sa na systém CRZP a prepojte ho s LLM agentom.
|
||||
- Vytvorte vyhľadávanie v dodaných textoch záverečných prác.
|
||||
|
||||
Stretnutie 20.2.2026
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zistite, čo je to RAG. Zistite ako funguje generatívny model. Napíšte o tom poznámky a zdroje ktoré ste použili.
|
||||
- Prihláste sa na https://ui.tukekemt.xyz/ , api https://docs.openwebui.com/reference/api-endpoints/
|
||||
- Prejdite si https://docs.langchain.com/oss/python/langchain/quickstart
|
||||
- Pozrite si dokumentáciou https://docs.openwebui.com/.
|
||||
- Pozrite si https://git.kemt.fei.tuke.sk/KEMT/zpwiki/
|
||||
- Naprogramujte proces, ktorý zaindexuje Markdown súbory.
|
||||
- Naprogramujte agenta, ktorý vie vyhľadávať v zaindexovaných súboroch.
|
||||
- Vaše kódy dajte na KEMT GIT.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
254
pages/students/2022/oleh_poiasnik/README.md
Normal file
@ -0,0 +1,254 @@
|
||||
---
|
||||
title: Oleh Poiasnik
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [bp2025,dp2027]
|
||||
tag: [rag,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
|
||||
|
||||
rok začiatku štúdia: 2022
|
||||
|
||||
# Diplomová práca 2027
|
||||
|
||||
Expertný agentový systém na podporu rozhodovania v lekárni
|
||||
|
||||
Cieľ:
|
||||
|
||||
- Vylepšiť agenta pre prácu so znalostným grafom - interakcie a kontraindikácie.
|
||||
- Zostaviť znalostný graf z databázy príbalových letákov adc a s jeho pomocou zlepšiť generovanie odpovede.
|
||||
|
||||
Stretnutie 14.5.
|
||||
|
||||
Stav:
|
||||
|
||||
- Získaná databáza ADC pomocou scrapera.
|
||||
- Dáta sú transformované do JSON, je definovaná schéma.
|
||||
- Pomocou LightRAG je vytvorený znalostný graf pre niekoľko (500) liekov.
|
||||
- Prvá verzia agenta na základe LightRAG. Problém je, že znalostný graf je príliš veľký.
|
||||
- Kódy pre extrakciu aj pre krawlera sú na gite, aj konfigurácia spustenia LightRAG.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zlepšite vyhľadávanie v znalostnom grafe. Nakonfigurovať LightRAG na databázu Neo4J.
|
||||
- Preskúmajte vzniknutý KG. Nachádzajú sa v ňom duplicitné koncepty alebo vzťahy?
|
||||
- Oboznámte sa so systémom MiniRAG: https://github.com/hkuds/minirag Prečítajte si článok.
|
||||
- Oboznámte sa so systémom RAGAS a DeepEVAL.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Zostavte databázu vzorových úloh pre vyhodnotenie takéhoto systému a vyberte vhodnú metodiku vyhodnotenia.
|
||||
- Pripravte webové demo. Môžete použiť streamlit alebo gradio.
|
||||
|
||||
|
||||
Stretnutie 30.4.2026
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Oboznámte sa s pojmami na stránke https://graphrag.com/concepts/intro-to-graphrag/ . Napíšte is poznámky.
|
||||
- Vyskúšajte si softvér https://github.com/hkuds/lightrag .
|
||||
- Prečítajte si článok LightRAG: Simple and Fast Retrieval-Augmented Generation
|
||||
- Oboznámte sa so systémom https://docs.ragas.io/en/stable/
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Využite školské LLM prístupné cez API.
|
||||
- Pripravte skripty pre získanie (scarpovanie) databázy ADC.
|
||||
- Zlepšite proces parsovania do formátu JSON. Môžete použiť systém Docling.
|
||||
|
||||
|
||||
Stretnutie 30.3.
|
||||
|
||||
|
||||
Stav:
|
||||
|
||||
- Oboznámenie sa s LightRAG.
|
||||
- Vyskúšané s lokálnym minilm-paraphrase a openwebui tukekemt API.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pripravte skripty pre získanie (scrapovanie) databázy ADC.
|
||||
- Zlepšite proces parsovania do formátu JSON. Môžete použiť systém Docling.
|
||||
- Skripty dajte na GIT.
|
||||
- Vypracujte prehľad článkov zameraných na tvorbu znalostného grafu alebo exťrakcie štruktúrovaných informácií z medicínskych dát.
|
||||
- Zistite, ktoré entity sú dôležité pre databázu liekov.
|
||||
|
||||
|
||||
|
||||
# Bakalárska práca 2025
|
||||
|
||||
|
||||
Chceme vytvoriť asistenta pre farmaceuta alebo zákazníka lekárne pre vyhľadávanie v príbalových letákoch.
|
||||
|
||||
|
||||
Generovanie jazyka s podporou vyhľadávania v doménovo orientovaných dátach
|
||||
|
||||
1. Vypracujte prehľad metód a modelov generovania jazyka s pomocou vyhľadávania.
|
||||
2. Navrhnite a vytvorte systém pre zodpovedanie otázok v prirodzenom jazyku v doménovo orientovaných dátach.
|
||||
3. Vyskúšajte a vyhodnoťte vytvorený systém.
|
||||
4. Navrhnite zlepšenia pre vybranú metódu generovania odpovede.
|
||||
|
||||
|
||||
Staré zadanie:
|
||||
|
||||
Vyhľadávanie právnych informácií pomocou neurónových sietí
|
||||
|
||||
- Oboznámte sa s existujúcimi modelmi pre vyhľadávanie v texte.
|
||||
- Vytvorte systém pre vyhľadávanie v zákonoch a vyhláškach.
|
||||
- Vyhľadajte súvisiace paragrafy so zadanou otázkou
|
||||
- Vyhodnotte či je zadané tvrdenie v súlade s legislatívou alebo nie.
|
||||
|
||||
|
||||
RAG: Generovanie jazyka s pomocou vyhľadávania - Retrieval augmented generation
|
||||
|
||||
Stretnutie 28.3.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Agent funguje super.
|
||||
- Kódy sú na osobnom githube
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Kódy dajte na KEMT GIT.
|
||||
- Dopracujte Docker Compose.
|
||||
- Zverejnite demo, napr. pomocou TUKE Cloud.
|
||||
|
||||
|
||||
|
||||
13.2.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Funguje QA nad databázou liekov.
|
||||
- Autentifikacia cez Google.
|
||||
- História sa ukladá do Postgres DB na AWS.
|
||||
- Používa sa Mistral Large. Slovenský Mistral nefunguje lebo ho treba dotrénovať.
|
||||
- Vektorový model paraphrase-multilingual-MiniLM-L12-v2
|
||||
- Projekt beží cez Docker, sú hotové aj Docker skripty.
|
||||
- V texte je osnova a draft. Treba ešte pracovať hlavne na teoretickej časti - odbornej literatúre.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v práci na texte.
|
||||
- Skúste vyhodnotiť navrhnutý systém. Pripravte dotazník. Osloviť kolegov aby to vyskúšali a slovne vyhodnotili systém.
|
||||
- dajte nové kódy na git.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Zlepšite logiku dialógu. Jazykový model by sa mal správať ak inteligentný agent - mal by mať definovaný cieľ konverzácie.
|
||||
- Definujte ciele dialógu - čo by mal agent vedieť pre úspešnú odpoveď. Napr. Interakcie s liekmi. Sú lieky na predpis? Aké sú podrobnejšie symptómy choroby? Suchý kašeľ alebo vykašliavanie? Koľko rokov má pacient? Aká anamnéza je dôležitá.
|
||||
- Preštudujte si metodiku REACT a Chain of Thought. https://arxiv.org/abs/2210.03629
|
||||
|
||||
|
||||
|
||||
8.11.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Modifikovaný frontend (Tailwind)
|
||||
- Vytvorený Docker Images, Elasticsearch databáza aj index.
|
||||
- Je aj skript na indexovanie.
|
||||
- Vyskúšaný Mistral Small a Mistral Large cez API-
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pracujte na texte, pošlite mi draft.
|
||||
- Pripojte sa na server quadro.kemt.fei.tuke.sk (cez ssh z tuke siete). Použite prostredie Anaconda.
|
||||
- Na inferenciu (beh modelu) vyskúšajte vllm. Alebo ollama alebo localai. Dobrý model pre slovenčinu je Qwen2.5 alebo slovak-t5-base. Na vektorvé vyhľadávnaie je zatiaľ najlepší model multilingual E5. Možno aj BGE - nie je overený.
|
||||
|
||||
17.10.20204
|
||||
|
||||
Stav:
|
||||
|
||||
- Funguje web rozhranie aj vyhľadávanie.
|
||||
- Kódy sú na gite. Využíva sa Flask, Mistral API pre Mistral-Small (nebeží lokálne). Na vektory MiniLM2
|
||||
- Napísané poznámky o praktickej časti.
|
||||
|
||||
|
||||
Úlohy
|
||||
|
||||
- Otázka: Je to hybridné vyhľadávanie?
|
||||
- Začnite písať teoretickú časť práce.
|
||||
- Pokračujte v práci na frontende aj backende, tak aby to dobre vyzeralo aj dobre fungovalo - aby sa to dalo použiť ako demo. Treba dávať pozor na právnu zodpovednosť.
|
||||
- Vyskúšajte rôzne spôsoby vyhľadávania - aj sparse (riedke vyhľadávanie).
|
||||
- Kódy dávajte na git.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Pripravte modely na lokálne nasadenie pomocou inferenčného servra (vllm, ctranslate2). Chceme aby modely bežali cez (OpenAI) API na našej infraštruktúre.
|
||||
- Vyskúšajte Váš systém s lepšími modelmi (Slovak Mistral, iný väčší model, na vektory me5 alebo slovakbert-mnlr).
|
||||
- pripravte nasadenie aplikácie pomocou systému Docker Compose.
|
||||
- Urobte číslelné vyhodnotenie vyhľadávania. Toto má na starosti Yevhenii Leonov.
|
||||
|
||||
|
||||
27.9.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Vyskúšané generatívne modely - OpenAI aj HuggingFace Prakticky sú nepoužiteľné, kvôli tomu, že chybné požiadavky míňajú kredit. Kreditu je málo na deň.
|
||||
- Výskúšaný Slovenský Mistral "slovak-nlp/mistral-sk-7b". Výskúšané cez API skript.
|
||||
- Nainštalovaný PrivateGPT. Zaindexovaná databáza liekov cez ElasticSearch a implementovaný RAG s modelom Slovak Mistral. Funguje to celkom dobre na dopyt o bolesti hlavy.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v štúdiu LangChain. Prejdite si tutoriály.
|
||||
- Čítajte články a robte si poznámky. Pozrite si článok o modeli Mistral, o sentence transformeroch, aj o "retrieval augmented generation". Na vyhľadanie článku použite google scholar.
|
||||
- Vytvorte skript pre indexovanie a prípravu dát, dajte ho na git.
|
||||
- Konfiguračné skripty na Privategpt a skripty pre prípravu dát dajte na git repozitár. Na kemt.git.fei.tuke.sk. Skripty by mali byť opakovateľné.
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Lepšie pripraviť dáta. Bude treba vyradiť lieky pre zvieratá. Texty bude treba predpripraviť. O lieku bude treba zistiť metainformácie. Bude treba vyznačiť, či je liek na lekársky predpis alebo nie.
|
||||
- Model bude treba dotrénovať na inštrukcie, použiť databázu Slovak Alpaca.
|
||||
- Pripraviť "inteligentného agenta" pre vyhľadávanie, aby sa vedel spýtať dolnňujúce otázky. Prečítajte si článok o ReACT.
|
||||
- Pripraviť vlastné webové rozhranie a backend LangChain.
|
||||
|
||||
|
||||
|
||||
Stretnutie 18.9.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Vyskúšaný model bioBERT, cez Transformers, Anaconda na malom datasete na notebooku
|
||||
- ElasticSearch Python API
|
||||
- vlastný skript na indexovanie pomocou SBERT
|
||||
|
||||
Úlohy:
|
||||
|
||||
- vhodné modely pre slovenský jazyk: me5-base pre vektorové vyhľadávanie. Ale ako použijete ES, tak nie je potrebný. Pre generovanie: je možné použiť OpenAI API alebo HuggingfaceAPI, má obmedzenie. Otvorené modely: LLama3, RWKV, Sovenský Mistral 7B TBA.
|
||||
- Na začiatok skúste rozbehať postup s PrivateGPT, OpenAI API a vyhľadávaním (pomocou ES alebo me5-base alebo OpenAI API - ADA embedding).
|
||||
- Urobte si lokálnu inštaláciu PrivateGPT na Vašom notebooku. Zmente konfiguráciu - modely a prompty
|
||||
- Dáta dodá Kristián Sopkovič - cez Teams sa spojte.
|
||||
- Pokračujte v štúdiu Python, Transformers. Oboznámte sa s LangChain.
|
||||
- Prečítajte si tento článok https://arxiv.org/abs/1908.10084 o sentence transformers a urobte si poznámky.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Urobte množinu na vyhdnotenie. Vytvoríte množinu vzorových otázok a odpovedí. Vyhodnotte celý proces.
|
||||
- Modely by mali bežať na našej infraštruktúre. Treba pripravť vhodný inferenčný server na našom HW, vybrať a dotrénovať vhodný model.
|
||||
- Preskúmať využitie Knowledge Graph pre spracovanie medicínskych dát.
|
||||
|
||||
Stretnutie 26.4.2024
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zistite čo je to Retrieval Augmented Generation a napíšte o tom správu.
|
||||
- Naučte sa základy jazyka Python.
|
||||
- Podrobne si prejdite minimálne dva tutoriály.
|
||||
- Napíšte krátky report na 2 strany kde napíšete čo ste urobili a čo ste sa dozvedeli.
|
||||
- Nainštalujte si a vyskúšajte softvér PrivateGPT
|
||||
- Nainštalujte si prostredie Anaconda. Prejdite si knihu Dive Deep into Python 3.
|
||||
- Nainštalujte si PrivateGPT. Zistite ako funguje RAG. Zistite ako funguje ChatGPT. Zistite ako funguje vyhľadávanie pomocou SentenceTranformers. Napíšte o tom poznámky.
|
||||
- Prečítajte si knihu https://d2l.ai/ a napíšte si poznámky.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Spracujte a indexujte slovenské zákony a vyhlášky.
|
||||
- Získajte zoznam právnych tvrdení ktoré je možné overiť.
|
||||
- Existuje množina zmlúv o prenájme v slovenskom jazyku. https://huggingface.co/datasets/mtarasovic/ner-rent-sk-dataset
|
||||
|
||||
57
pages/students/2022/samuel_vasil/README.md
Normal file
@ -0,0 +1,57 @@
|
||||
---
|
||||
title: Samuel Vasiľ
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [bp2026]
|
||||
tag: [llm,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
|
||||
rok začiatku štúdia: 2022
|
||||
|
||||
|
||||
## Bakalárska práca 2026
|
||||
|
||||
konzultant Matúš Čavojský
|
||||
|
||||
Predbežný názov:
|
||||
|
||||
Orchestrácia veľkých jazykových modelov pomocou model context protokolu s využitím OpenWebUI
|
||||
|
||||
Zadanie:
|
||||
|
||||
- Vypracujte prehľad súčasných veľkých jazykových modelov s podporou slovenčiny, ktoré sa používajú na generovanie prirodzeného jazyka, generovanie programového kódu a vyhľadávanie informácií.
|
||||
- Nasaďte OpenWebUI pomocou Docker Compose a vybrať niekoľko vhodných modelov, ktoré sprístupníte prostredníctvom webového rozhrania aj REST API.
|
||||
- Rozšírte nasadený systém o podporu RAG, vyhľadávania na webe, volania funkcií a integráciu ďalších nástrojov.
|
||||
- Otestujte a vyhodnoťte celý rámec, identifikujte slabé miesta a navrhnite konkrétne opatrenia na ich odstránenie.
|
||||
|
||||
Ukončil predčasne
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vypracovať prehľad jazykových modelov s podporou slovenčiny pre úlohy generovania prirodzeného jazyka, generovania proprogramov a vyhľadávania.
|
||||
- Nasadiť OpenWebUI pomocou Docker Compose
|
||||
- Vybrať viacero vhodných modelov a sprístupniť ich pomoocou Webového rozhrania a REST API
|
||||
- Pridať podporu RAG, vyhľadávania na webe, volania funkcií a nástrojov.
|
||||
|
||||
Stretnutie 24.10.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Funguje OpenWebUI : WebUI, Proxy, MCP Adapter, OLLAMA server
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pridať RAG. Musí byť nejaká vektorová databáza.
|
||||
- Dokončiť Docker Compose Skripty aj dokumentáciu a dať ich na KEMT GIT
|
||||
- Do práce pidajte prehľad LLM Deployment - prečítaje a citujete články z Google scholar.
|
||||
|
||||
Budúce úlohy:
|
||||
|
||||
- Nasadiť systém do produkcie na školskom servri.
|
||||
- Navrhnúť politiku prístupu pre študentov, Autentifikácia pomocou LDAP?
|
||||
- Dalo by sa urobiť aj dotrénovanie?
|
||||
- Pozrieť pluginy - doplniť zaujímavé vlastnosti.
|
||||
|
||||
130
pages/students/2022/serhii_yemets/README.md
Normal file
@ -0,0 +1,130 @@
|
||||
---
|
||||
title: Serhii Yemets
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [bp2025]
|
||||
tag: [ner,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
|
||||
rok začiatku štúdia: 2022
|
||||
|
||||
# Bakalárska práca 2025
|
||||
|
||||
Cieľ:
|
||||
|
||||
- Zlepšenie slovenského modelu pre rozpoznávanie pomenovaných entít.
|
||||
|
||||
Do budúcnosti:
|
||||
|
||||
- Vypracovanie webového dema
|
||||
- Využitie modelu v nejakej zaujímavej úlohe (chatbot alebo právne texty).
|
||||
|
||||
Návrh na zadanie bakalárskej práce:
|
||||
|
||||
1. Napíšte prehľad neurónových modelov vhodných pre rozpoznávanie pomenovaných entít v slovenskom jazku.
|
||||
2. Napíšte prehľad existujúcich dátových množín, vhodných na trénovanie modelu pre rozpoznávanie pomenovaných entít.
|
||||
3. Vyberte vhodný model, dátovú množinu a natrénujte a vyhodnoťte model.
|
||||
4. Vytvorte webové demo pre rozpoznávanie pomenovaných entít.
|
||||
5. Identifikujte spôsoby možného zlepšenia natrénovaného modelu pre rozpoznávanie pomenovaných entít.
|
||||
|
||||
Stretnutie 28.3.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- spojené datasety: wikiann a conll2003. Pomohlo to. Dosiahli sme 0.9 na SLovak BERT.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Skúste zlepšiť model.
|
||||
- Zverejniť model. V spolupráci s vedúcim. Ku modelu pripravte krátky opis ako bol trénovaný a aké výsledky dosiahol.
|
||||
- Definujte a zlepšite štruktúru práce. Práca postuypuije od všeobecného ku konkrétnemu. Kapitoly by mali byť konzistentné s názvom. Prezentujte ako ste splnili zadanie. Zlepšite jazykovú úroveň práce. Dôsledne používajte jednotnú terminológiu.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Pridajte ďalšie dáta a pretrénujte model. V prípade potreby dostanete prístup na školský server.
|
||||
|
||||
Stretnutie 21.3.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Zlepšenie procesu trénovania modelu - viac epoch, použitie LORA.
|
||||
- Použitie SlovakBERT a WikiANN dataset.
|
||||
- Urobené Web DEMO.
|
||||
- Text nie je pokrok.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zdrojové texty pre trénovnanie a pre demo dajte na KEMT GIT.
|
||||
- Zlepšite výsledky trénovania. Skúste iné parametre LR. Skúste inú dátovú množinu. Skúste spojiť viaceré dátové množiny do jednej.
|
||||
- Porovnajte viacero modelov. ModernBERT, mbert, hplt bert base, slovak roberta, Výsledky dajte do tabuľky. Opíšte postup experimentov.
|
||||
- Pracujte na texte, hlavne na praktickej časti.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vyskúšajte generatívne modely Slovak T5 base, Slovak Mistral 7B.
|
||||
|
||||
Stretnutie 20.12.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Splnené úlohy z posledného stetnutia
|
||||
- Text je v dobrom stave, treba ešte použiť šablónu.
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pripravte si prezentáciu.
|
||||
- Textu dajte na moodle, skripty dajte na git.
|
||||
- Pokračujte v písaní. Doplňte časť o spôsobe anotovania NER - značkovanie BIO (beginning, inside, outside) alebo iné. Doplôte časť o vyhodnotení - precision,recall, F1. Doplňte odkazy na dátové množiny. Používajte odkazy na vedecké články.
|
||||
- Zlepšite presnosť Vášho modelu. Do BP napíšte priebeh trénovania a vyhodnotenia. Výsledky experimenotv zapíšte do tabuľky.
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Zostavte webové demo
|
||||
- Pripravte experiment pre ukrajinský a ruský jazyk.
|
||||
- Priprave Dockerfile pre Vaše demo
|
||||
- Vytvorte dátovú množinu spojením viacerých existujúcich množin do jednej. Vedúci Vám dá nejaké skripty.
|
||||
|
||||
|
||||
Stretnutie 30.10.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Napísané texty o NE.
|
||||
- Vyskúšané a naštudované veci podľa pokynov,
|
||||
- Začiatok práce na webovom deme.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Naštudujte korpusy s [NER pre slovenský jazyk](https://github.com/slovak-nlp/resources). Napíšte ich zoznam. Ku každému napíšte veľkosť (počet viet, slov) a druhy pomenovaných entít.
|
||||
- [x] Najprv budeme pracovať s ručne anotovanými dátami. Použite ich na natrénovanie modelu typu BERT (napr. SlovakBER alebo mbert) a vyhodnotte ich presnosť. Na trénovanie použite Spacy alebo Transformers.
|
||||
- [x] Pokračujte v písaní BP. Stručne (max. 1.5 strany) vysvetlite ako funguje transformer. Na google scholar nájdite vedecké články o NER a napíšte čo ste sa z nich dozvedeli. Aké majú výsledky a aké metódy používaju?
|
||||
- [x] Prejdite si tutoriál https://huggingface.co/docs/transformers/en/tasks/token_classification
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Natrénujte nový Spacy NER model ktorý by bol lepší ako pôvodný.
|
||||
- Spojte viacero dátových množin (manuálne anotovaných) do jednej a použite je na natrénovanie modelu.
|
||||
- Použite veľký jazykový model pre NER anotáciu a porovnajte ho s menším dotrénovaným NER modelom.
|
||||
- Vykonané experimenty slovne opíšte a výsledky zapíšte do tabuliek. Výsledky slovne okomentujte.
|
||||
|
||||
|
||||
Stretnutie 20.5.20204
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Zistite čo je to rozpoznávanie pomenovaných entít (named entity recognition) a napíšte o tom správu.
|
||||
- [x] Zopakujte si základy jazyka Python "Dive into Python 3". Nainštalujte si prostredie Anaconda.
|
||||
- [x] Oboznámte sa s knižnicou Spacy a vyskúšajte si skripty v https://github.com/hladek/spacy-skmodel
|
||||
- [x] Nainštalujte si knižnicu Huggingface Transformers. Oboznámte sa s ňou. Zistite, ako sa trénuje model NER pomocou takejto knižnice.
|
||||
- [x] Zistite, aké modely a jazykové zdroje sú dostupné pre túto úlohy pre slovenský jazyk https://github.com/slovak-nlp/resources
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Pripravte viacero korpusov pre NER. Môžu byť aj viacjazyčné.
|
||||
- Natrénujte model Huggingface pre NER
|
||||
|
||||
|
||||
152
pages/students/2022/tetiana_mohorian/README.md
Normal file
@ -0,0 +1,152 @@
|
||||
---
|
||||
title: Tetiana Mohorian
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [bp2025]
|
||||
tag: [rag,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
|
||||
rok začiatku štúdia: 2022
|
||||
|
||||
|
||||
## Bakalárska práca 2025
|
||||
|
||||
- Spolupráca [P. Pokrivčák](/students/2019/patrik_pokrivcak)
|
||||
- [Python](/topics/python)
|
||||
- [Hate Speech](/topics/hatespeech)
|
||||
|
||||
|
||||
Rozpoznávanie nenávistnej reči pomocou veľkých jazykových modelov.
|
||||
|
||||
Zadanie:
|
||||
|
||||
1. Vypracujte prehľad veľkých jazykových modelov s podporou slovenčiny.
|
||||
2. Vypracujte prehľad dostupných textových korpusov pre rozpoznávanie nenávistnej reči.
|
||||
3. Vyberte model a metódu rozpoznávania nenávistnej reči. Vyhodnoťte presnosť rozpoznávania nenávistnej reči na vybranej množine.
|
||||
4. Navrhnite zlepšenia vybranej metódy.
|
||||
|
||||
|
||||
Návrh na tému:
|
||||
|
||||
|
||||
- Oboznámte sa s existujúcimi veľkými jazykovými modelmi - uzatvorenými aj otvorenými.
|
||||
- Aplikujte existujúci model na úlohu detekcie nenávistnej reči.
|
||||
- Na adaptáciu použite "prompting" a "LORA".
|
||||
- Vyhodnotte model pomocou [overovacej množiny](https://huggingface.co/datasets/TUKE-KEMT/hate_speech_slovak).
|
||||
|
||||
Stretnutie 28.3.
|
||||
|
||||
|
||||
Stav:
|
||||
|
||||
- Práca na stránke, frontend backend
|
||||
- Práca na Telegram bot, vyhodnotenie s priateľmi.
|
||||
- Few Shot Learning: 0.7 F1. Slovak T5-small model.
|
||||
- Práca na lm-eval-harness, zatiaľ sa to nepodarilo. Task zatiaľ nefunguje, framework funguje.
|
||||
- Pripravená aj TK Inter aplikácia.
|
||||
- Pripravte webovú aplikáciu na zverejnenie pomocou Docker.
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vedúci môže pomôcť s Task na LM E H - pripomente mi to ďalší týždeň.
|
||||
- Využite iný model. Napr. Slovak T5 large alebo base. Alebo Slovak MIstral.
|
||||
- Updatujte kódy na GITE.
|
||||
- Do práce môžete dať screenshoty z Vašej aplikácie
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Zverejnite Vašu aplikáciu napr. pomocou TUKE Cloud.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Stretnutie 13.2.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Dotrénovaný t5 small na HS
|
||||
- Vyhodnotené viaceré modely pre úlohu detekcie HS
|
||||
- Navrhnutý prompt.
|
||||
- Práca web. deme. Funguje frontend (react), zatiaľ nefunguje backend (django).
|
||||
- Práca na telegram bote - upozornenie diskutujúcich na "nevhodné" výrazy.
|
||||
- Práca na texte.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v písaní. Je potrebné zlepšiť jazyk, vyradiť príliš všeobecné časti, pridať odkazy na odbornú literatúru, zrozumiteľne opísať experimenty a výsledky.
|
||||
- Pripravte experiment s "few shot" a veľkým jazykovým modelom. Môžete použiť lm-eval-harness.
|
||||
- Skripty dajte na kemt git.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Pripravte DEMO s pomocou Docker.
|
||||
|
||||
|
||||
Stretnutie 12.11.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Vyskúšané few shot Distillbert, BERT, GPT3, T5, najlepšie výsledky mal DistillBERT : 65F1. Problém je, že tieto modely nevedia po slovensky.
|
||||
- Na vyhodnotenie použitý svoj skript a framework llm-eval-harness.
|
||||
- Pokračuje písanie.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Pošlite mi draft BP na ďalšie stretnutie.
|
||||
- [x] Urobte si repozitár na KEMT GIT a dajte tam zdrojové kódy na spustenie experimentov.
|
||||
- [x] Pokračujte v písaní.
|
||||
- [-] Vyskúšajte vyhodnotiť modely v rôznych veľkostiach (small, base, large, 1B, 3B, 7B): mt5, slovak-t5-base, slovak-t5-small, Qwen2.5, Slovak Mistral, LLama3, SlovakBERT .
|
||||
- [x] Napíšte ChatGPT prompt na detekciu nenávistnej reči.
|
||||
- Ak Vám nebude stačiť GPU Vášho počítača, vedúci Vám pridelí prístup na školský server alebo môžete vyskúšať Google Colab.
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- [x] Zistite čo je to PEFT a kvantizácia a ako sa to používa.
|
||||
- [x] Dotrénujte jazykový model pre rozponávanie HS pomocou metódy PEFT.
|
||||
|
||||
Stretnutie 18.10.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Urobené 3 prehľadové tabuľky s modelmi - architektúra, presnosť, multilinguaglita.
|
||||
- Pozretá kniha DDIP3 a d2dl. Poznámky na 20 strán.
|
||||
- Nainštalovaná OLLama, Transformers, vyskúšaný Mistral.
|
||||
- Urobené všetko.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v písaní bakalárskej práce. Postupujte od definície úlohy, prehľad súčasného stavu, Vaše riešenie, experimenty a závery. Používajte odkazy na odbornú literatúru (vedecké články cez Google Scholar).
|
||||
- Navrhnite promt (može byť aj viac rôznych) pre veľký jazykový model pre detekciu nenávistnej reči.
|
||||
- Pomocou množiny vyhodnotte model pre detekciu HS v zero shot alebo v few shot scenári. Na vyhodnotenie použite metriku Precision-Recall-F1.
|
||||
- Oboznámte sa ako funguje overenie veľkých jazykových modelov pomocu Eleuther lm-evaluation-harness.
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- [ ] Dotrénujte vybrané modely na úlohu detekcie nenávistnej reči. Model bude vykonávať binárnu klasifikáciu.
|
||||
- [x] Pripravte skript pre overenie LLM na úlohe rozpoznávanie nenávistnej reči. Pripravte postup pre overenie pomocu existujúceho frameworku pre overenie.
|
||||
|
||||
Stretnutie 3.10.2024
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Oboznámte sa s existujúcimi veľkými jazykovými modelmi - uzatvorenými aj otvorenými. Urobte si poznámky a napíšte prehľad.
|
||||
- [x] Prejdite si knihu Dive Deep into Python 3.
|
||||
- [x] Prečítajte si knihu https://d2l.ai/ a napíšte si poznámky.
|
||||
- [x] Zistite čo je to "prompting", a "few shot learning". Napíšte si poznámky.
|
||||
- [x] Oboznámte sa s OPEN AI Python API.
|
||||
- [x] Nainštalujte si prostredie Anaconda.
|
||||
- [x] Nainštalujte si Pytorch, a huggingface transformers a oboznámte sa ako funguje táto knižnica.
|
||||
- [x] Nainštalujte si prostredie OLLAMA a vyskúšajte lokálne jazykové modely
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- [x] Nainštalujte si knižnicu LangChain a pozrite si ako fungujú [ChatModely](https://python.langchain.com/docs/modules/model_io/chat/)
|
||||
|
||||
360
pages/students/2022/valerii_kutsenko/README.md
Normal file
@ -0,0 +1,360 @@
|
||||
---
|
||||
title: Valerii Kutsenko
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [vp2024,bp2025,dp2027]
|
||||
tag: [rag,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
rok začiatku štúdia: 2022
|
||||
|
||||
# Diplomová práca 2027
|
||||
|
||||
Zlepšenie vyhľadávania pomocou znalostných grafov.
|
||||
|
||||
Myšlienky:
|
||||
|
||||
- Agent si buduje vnútornú reprezentáciu pomocu ktorej vie lepšie generovať.
|
||||
- Vnútorná reprezentácia je v človeku zrozumiteľnej podobe, napr. znalostný graf.
|
||||
|
||||
Možné úlohy:
|
||||
|
||||
- Navrhnite agenta, ktorý bude budovať a využívať znalostný graf pri vyhľadávaní.
|
||||
- Môže to byť v oblasti vzdelávania, práva alebo medicíny.
|
||||
- Zostavte multilinguálny znalostný graf, ktorý môže pomôcť pri generovaní.
|
||||
|
||||
Existujúca práca:
|
||||
|
||||
- LightRAG - pozrite si to.
|
||||
|
||||
|
||||
Stretnutie 15.5.
|
||||
|
||||
Stav:
|
||||
|
||||
- Zaindexované anglické dáta Alice in Wonderland pomocou LightRAG, zostavený znalostný graf z knihy.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pozrite sa na systém MiniRAG
|
||||
- Získajte texty Alice in Wonderland v iných jazykoch - napr. po rusky a po slovensky. Zostavte multilinguálny znalostný graf.
|
||||
- Prečítajte si najnovšie vedecké články na tému "multilingual knowledge graph construction", "multilingual entity linking (alignment)". Urobte si poznámky o spôsoboch ako urobiť takýto graf a ako ho využiť pri vyhľadávaní.
|
||||
|
||||
|
||||
|
||||
Stretnutie 27.4.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Naštudujte si problematiku.
|
||||
- Získajte vzorový znalostný graf ktorý sa bude dať použiť pri výskume.
|
||||
- Vytvorte jednoduché demo, ktoré bude demonštrovať využitie znalostného grafu pri vyhľadávaní.
|
||||
- Na právnych dátach pracujú kolegovia Šarišský a Ščišľak. Spracovali Právny Thesaurus.
|
||||
- Na lekárskych dátach pracuje doc. Bednár. Z toho sa da vytiahnuť znalostný graf.
|
||||
- Na dátach zo vzdelávania pracuje vedúci - máme ZPWIKI.
|
||||
|
||||
|
||||
Nápady na prínos:
|
||||
|
||||
- navrhnite spôsob automatického budovania znalostného grafu vo zvolenej doméne.
|
||||
- navrhnite spôsob vyhľadávania s pomocou existujúceho znalostného grafu.
|
||||
- dotrénujte jazykový model alebo navrhnite metódu promptovania pre tvorbyu znalostných grafov z dát.
|
||||
- navrhnite metódu pre dotrénovanie jazykového modelu s pomocou znalostného grafu
|
||||
- augmentácia modelu s pomocou znalostného grafu.
|
||||
|
||||
|
||||
# Diplomový projekt 2026
|
||||
|
||||
Projekt odložený.
|
||||
|
||||
|
||||
Augmentácia dát pre zlepšenie získavania informácií
|
||||
|
||||
|
||||
Ciele na prácu:
|
||||
|
||||
- Zlepšiť slovenský vektorový jazykový model pomocou umelo generovaných dát.
|
||||
- Preskúmať možnosti augmentácie pre lepšie využitie znalostných grafov
|
||||
- Preskúmať možnosti agmentácie pre vyhľadávanie v (slabo) štruktúrovaných dátach.
|
||||
- Chceme napríklad vedieť vyhľadávať priamo v JSON.
|
||||
|
||||
Ciele na semester:
|
||||
|
||||
- Dotrénovať slovenský vektorový model pre vyhľadávanie s promptom.
|
||||
- Preskúmať možnosti zlepšenia vyhľadávania pomocou promptingu.
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vyberte vhodný model pre pre základ. me5 majú pomerne malý kontext.
|
||||
- Natrénujte a vyhodnotte slovenský vektorový model pomocou dodaného skriptu.
|
||||
- Zistite, ako sa trénujú vektorové modely s podporou promptu a napíšte o tom krátku správu. Aké metódy existujú?
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Natrénujte vektorový model s podporou promptu.
|
||||
- Pozrite si https://graphrag.com/
|
||||
- Pozrite si https://github.com/topoteretes/cognee
|
||||
|
||||
|
||||
|
||||
Nápady na tému:
|
||||
|
||||
- Augmentácia dát - generovanie umelých trénovacích množín.
|
||||
- Vyskúšať nové LLM na generovanie trénovacích dát.
|
||||
- Použiť existujúce dáta - zlepšiť ich pomocou LLM alebo generovať podobné dáta.
|
||||
- Generovať a overovať dáta pre vyhodnotenie modelov.
|
||||
- Vyvmyslieť metódy pre vyhodnotenie "kvality dát" - ich "užitočnosť" pre trénovanie.
|
||||
- Preskúmať metídy "učiteľ - žiak." Ako môže jeden model pomôcť pri trénovaní iného modelu.
|
||||
- Vytvoriť novú doménovo orientovanú QA množinu. Vytvoriť Instruct množinu.
|
||||
- Vytvoriť slovenský doménovo orientovaný model.
|
||||
|
||||
Stretnutie 3.10.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Oboznámiť sa s novými metódami generovania trénovacích množín. Prečítejte si nové články na google scholar a urobte si poznámky.
|
||||
- Kľúčové slovíčka: data augmentation, distillation, question generation,
|
||||
- Pozrite si https://github.com/nlp-uoregon/Okapi
|
||||
- Vyskúšať nové LLM pre generovanie, napr. pomocou ollama. gpt-oss,
|
||||
- Pozrite si https://huggingface.co/docs/trl/en/index. Oboznámte sa s metódami GPO a SFT. Ako dokáže pomôcť existujúci model pri dotrénovaní nového modelu.
|
||||
|
||||
|
||||
# Bakalárska práca 2025
|
||||
|
||||
Automatické generovanie otázok zo zadaného textu
|
||||
|
||||
Cieľ je vylepšiť slovenský model pre generovanie vektrovej reprezentácie. vylepšiť proces RAG: Generovanie jazyka s pomocou vyhľadávania - Retrieval augmented generation
|
||||
|
||||
Zadanie BP:
|
||||
|
||||
1. Vypracujte prehľad systémov pre generovanie otázok a spôsobov ich vyhodnotenia.
|
||||
2. Vyberte vhodný systém pre generovanie otázok a vytvorte umelú množinu otázok a odpovedí.
|
||||
3. S pomocou tejto množiny natrénujte a vyhodnoťte systém pre generovanie odpovede na zadanú otázku.
|
||||
4. Identifikujte jeho slabé miesta a navrhnite zlepšenia.
|
||||
|
||||
|
||||
Nové nápady:
|
||||
|
||||
- Vytvorte systém pre generovanie otázok o zadanom texte.
|
||||
- Vytvorte umelo generovanú množinu otázok a odpovedí o liekoch.
|
||||
- Pomocou umelej množiny zlepšite existujúci systém pre otázky a odpovede o liekoch.
|
||||
|
||||
Ako na to:
|
||||
|
||||
- Natrénujte generatívny model pre generovanie otázok. Použite existujúci skript a množinu SKQUAD.
|
||||
- Určite, ktorá otázka je dobre vygenerovaná a ktorá nie. Tu môžete použiť: systém pre vyhľadávanie alebo neurónovú sieť pre otázky a odpovede. Ku otázke viete nájsť odpovede pomocou neurónovej siete. Výstupom by mala byť čo najkvalitnejšia množina otázok a odpovedí ku odsekom.
|
||||
- Výstupom by mala byť umelo generovaná databáza otázok a odpovedí.
|
||||
|
||||
Stretnutie:
|
||||
|
||||
Stav:
|
||||
|
||||
- Urobené porovnanie vplyvu agmentovaných dát na question answering.
|
||||
- Rozpísaná práca
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v písaní. Doplne text o definícii úlohy, question generation, podrobnosti o experimnentoch, podrobnosti o procese generovania množiny QA.
|
||||
- Najnovšie skripty dajte na GIT.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Doplniť experimenty s inými modelmi (Slovak Mistral).
|
||||
|
||||
|
||||
Stretnutie 7.3.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Vytvorený skkript pre prípravu nového generovaného korpusu. Obsahuje kontext, otázku aj odpoveď. Zatiaľ nevie vyznačiť odpoveĎ v kontexte.
|
||||
- Vygenerované korpusy otázok a odpovedí pre SKWIKI a prokuratúru.
|
||||
- Natrénovaný model pre QA na základe SKWIKI generovaných dát - model slovak T5 base. Augmntovaná množina má zatiaľ 30k otázok.
|
||||
- Vyzerá to tak, že model s augmentovanými dátami je o dosť lepší. Je to naozaj dobre?
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Overiť či generované množina nie je príliš podobná overovacej.
|
||||
- Pokračujte v písaní práce , opíšte experimenty, vypracujte tabuľky.
|
||||
- Pozrite sa na článok O. Megela: Fine-Tuning and Evaluation of Question Generation for Slovak Language
|
||||
- Pre porovnanie vyhodnotte modely sami (slovak-t5-base), dotrénujute na SKQUAD-train. Vyhodnocujete stále na test časti. POrovnajte s viacerými augmentovanými dátami. V niekroých testoch primiešajte aj skquad train.
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Publikovať na konferencii.
|
||||
|
||||
Stretnutie 25.2.
|
||||
|
||||
Stav:
|
||||
|
||||
- Vyskúšané rôzne metódy porovnania pomocou slovných vektorov (bge, me5, spacy word vectors).
|
||||
- https://git.kemt.fei.tuke.sk/vk202uf/bp2024/src/branch/main/stretnutie.md
|
||||
- Nová verzia BP.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pozrite si článok https://scholar.nycu.edu.tw/en/publications/fine-tuning-and-evaluation-of-question-generation-for-slovak-lang
|
||||
- Napíšte prehľad metód generovania otázok.
|
||||
- Pripravte skript na generovanie QA korpusu zo zadaných dát a modelov.
|
||||
- Pripravte viacero automaticky generovaných korpusov otázok a odpovedí. Formát vygenerovaných dát by mal byť rovnaký ako SK QUAD - jsonl.
|
||||
- Odovzdané dáta wikpedia, prokuratura, adc.
|
||||
- Skúste natrénovať nové modely pre otázky a odpovede z týchto dát.
|
||||
- Píšte prácu, skripty dajte na git.
|
||||
|
||||
|
||||
Stretnutie 21.2.2025:
|
||||
|
||||
Stav:
|
||||
|
||||
- Najprv sa generuje odpoveď. Na základe odpovede a kontextu sa generuje otázka pomocou SlovakT5. Je potrebné vyradiť "zlé" trojice.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zoberte model TUKE-DeutscheTelekom/slovakbert-skquad . Na zadanú otázku a kontext zistite odpoveď. Porovnajte ju s "vygenerovanou odpoveďou". Ako bude f1 menšie ako "threshold", vyradíte trojicu. Porovnanie sa dá urobiť aj cez vektoropvý model https://github.com/hladek/spacy-skmodel. Alebo word2vec, alebo gensim.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- NIečo podobné sa dá urobiť pomocou vektorového (embedding) modelu, napr. BGE alebo me5. Vypočítate vektory pre otázku a odpoveď, "cosínusovú vzdialenosť" medzi otázkou a odpoveďou.
|
||||
|
||||
|
||||
|
||||
Stretnutie 13.2.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Práca na texte.
|
||||
- Vyskúšané iné hyperparametre trénovania. Zväčšená veľkosť generovanej otázky.
|
||||
- "Chýbajúce odpovede" boli vyhodené.
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v písaní.
|
||||
- Vytvorte umelo generovanú množinu otázok a odpovedí z wikipédie alebo z adc.
|
||||
- Natrénujte a vyhodnotte model na umelo vytvorenej množine a úlohe zodpovedania otázky. Môžete použiť aj SlovakBERT.
|
||||
|
||||
|
||||
|
||||
Stretnutie 22.11.2024
|
||||
|
||||
Stav:
|
||||
|
||||
|
||||
- Napísané o mt5 a umt5 v BP.
|
||||
- Dotrénované 4 modely, slovakt5-base, slavict5-base, mt5-base, umt5-base.
|
||||
- Urobené dotrénovanie na generovanie otázok.
|
||||
- Napísaná tabuľka s výsledkami experimentov. Metriky BLEU a ROGUE.
|
||||
- Napísaný skript, skript je na gite.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v písaní práce. Napíšte aj o metrikách vyhodnotenia.
|
||||
- Vyhľadajte a stručne opíšte vedecké články o generovaní otázok. Na vyhľadanie použite Google scholar.
|
||||
- Pridajte slovak t5 base model do experimentov.
|
||||
- Dotrénujte Slovak Falcon. Tam bude treba iný skript.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vymyslieť systém - natrénovať meurónku na návrh "odpovede".
|
||||
- Vyskúšať generovať otázky bez zadanej odpovede. Odpoveď generujte pomocou modelu. Model pre automatické odpovede už je na HF Hube: slovakbert-skquad.
|
||||
- Vyradiť také otázky, na ktoré systém nevie dopovedať.
|
||||
- Skúsiť generovať otázky z medicínskeho textu.
|
||||
|
||||
|
||||
|
||||
Stretnutie 18.10.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Natrénovaný model SlovakT5 Base. Skripty sú na [GITe](https://git.kemt.fei.tuke.sk/vk202uf/bp2024). Trénovanie funguje.
|
||||
- Naštudované články o T5 a Falcon, napísané poznámky.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Doplnte vyhodnotenie modelu pomocu BLEU Skore. Ako testovaciu množinu použite testovaciu časť SkQUAD.
|
||||
- Natrénujte aj iné modely: mt5-base, SlavicT5-base, umt5-base. Opíšte testovací scenár - ako ste dotrénovali model . Vyhodnotte ich v tabuľke. Do práce napíšte o týchto modeloch.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- SKúste natrénovať aj modely typu GPT. Tam bude treba upraviť skript na model typu GPT - SlovakMistral 7B. Titeo modely sú veľké. Budete potrebovať prístup na školský server. Budete potrebovať použiť mnetódu: quantization (bitsandbytes) a peft (parameter efficient fine tuning).
|
||||
- Ako bude model dobrý, tak ho uverejníme na repoztári Huggingface Hub.
|
||||
- Ak bude práca dobrá, skúsime prepracovať a urobiť článok na konferencii.
|
||||
- V spolupráci Y. Leonov urobiť vyhodnotenie aj v medicínskej doméne.
|
||||
- Skúsíme poprosiť doktorov o názor.
|
||||
|
||||
|
||||
Stretnutie 27.9.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Prezereté repozitáre a články. Napísané poznámky.
|
||||
- Vytvorený prázdny git repozitár.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zistite ako sa dotrénujú generatívne modely HuggingFace. Zistite čo je to Few Shot learning a *urobte si poznámky*.
|
||||
- Prečítajte si článok o modele Falcon a napíšte ako funguje. Prečítajte si článok o modele T5 a napíšte ako funguje.
|
||||
- Dotrénujte generatívny model na generovanie otázok podľa zadaného paragrafu. Na dotrénovanie použite databázu SK QUAD. Ako model použite Slovak T5 Base alebo Slovak Mistral 7 B.
|
||||
- Oboznámte sa s Hugggingface API a OpenAI API. Na generovanie môžete použiť aj toto api.
|
||||
- Skripty na dotrénovanie dávajte do GIT repozitára.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Zoberte databázu liekov a generujte otázky o liekoch - od Ing. K. Sopkovič, alebo O. Poiasnik.
|
||||
- Možno bude treba použiť ChatGPT API a príklady z databázy SK QUAD.
|
||||
- Možno bude treba dotrénovať Slovak Mistral 7B na inštrukcie.
|
||||
|
||||
Staré Úlohy:
|
||||
|
||||
- Zistite, aké sú možné prístupy ku generovaniu otázok pomocou generatívneho modelu a aké sú možné prístupy k overeniu vygenerovanej otázky.
|
||||
- Pozrite si repozitár https://github.com/patil-suraj/question_generation
|
||||
- Pozrite si repozitár https://github.com/gauthierdmn/question_generation
|
||||
- Pozrite si článok https://telrp.springeropen.com/articles/10.1186/s41039-021-00151-1
|
||||
- Oboznámte sa s DP Ondrej Megela a článok https://aclanthology.org/2023.rocling-1.20.pdf
|
||||
- Oboznámte sa s knižnicou HF transformers - vyskúšajte si nejaký tutoriál.
|
||||
- Zistite, ako funguje model T5.
|
||||
- Pozrite si skript `generate/run_qg.py` v [repo](https://git.kemt.fei.tuke.sk/dano/slovakretrieval) a vyskúšajte ho.
|
||||
- Čítajte súvisiace odborné články a robte si poznámky.
|
||||
- Urobte si repozitár na git.kemt a dávajte tam Vaše skripty.
|
||||
- Na experimenty použite https://colab.research.google.com/
|
||||
|
||||
|
||||
|
||||
|
||||
Staré Nápady:
|
||||
- Možno pomocou vytvorenia-prekladu vlastnej trénovacej databázy.
|
||||
- alebo pomocou nekontrolovaného učenia, reps. augmentácie alebo generovania.
|
||||
- Alebo zber trénovacích dát z webového korpusu.
|
||||
- Sústrediť sa na vektrovú reprezentáciu dokumentov?
|
||||
|
||||
Úlohy na semester - "nepovinné, oficiálne sa to začne na zimný semester 2024"
|
||||
|
||||
- Zistite čo je to Retrieval Augmented Generation a napíšte o tom správu.
|
||||
- Naučte sa základy jazyka Python.
|
||||
- Napíšte krátky report na 2 strany kde napíšete čo ste urobili a čo ste sa dozvedeli.
|
||||
|
||||
Stretnutie 9.5.24
|
||||
|
||||
Stav:
|
||||
|
||||
- Naštudované Deep dive intoi Python a dl2ai, niečo o RAG.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zistite, ako funguje [Sentence Transformers](https://sbert.net/). Pozrite si dokumentáciu. Vyskúšajte zopakovať príklady pre slovenské texty a so [slovenským modelom](https://huggingface.co/TUKE-DeutscheTelekom/slovakbert-skquad-mnlr).
|
||||
- Urobe si poznámky.
|
||||
|
||||
Stretnutie 22.3.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Nainštalujte si prostredie Anaconda. Prejdite si knihu Dive Deep into Python 3.
|
||||
- Prečítajte si knihu https://d2l.ai/ a napíšte si poznámky.
|
||||
- Zistite ako funguje RAG. Zistite ako funguje ChatGPT. Zistite ako funguje vyhľadávanie pomocou SentenceTranformers. Napíšte o tom poznámky.
|
||||
- Skúste si tento tutoriál o [LangChain](https://python.langchain.com/docs/get_started/quickstart)
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Nainštalujte si PrivateGPT.
|
||||
139
pages/students/2022/vladyslav_yanchenko/README.md
Normal file
@ -0,0 +1,139 @@
|
||||
---
|
||||
title: Vladyslav Yanchenko
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [bp2025]
|
||||
tag: [klaud]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
|
||||
rok začiatku štúdia: 2022
|
||||
|
||||
# Bakalárska práca 2025
|
||||
|
||||
Názov:
|
||||
|
||||
Kontinuálne nasadenie a testovanie aplikácie v klaudovom prostredí.
|
||||
|
||||
Úlohy BP:
|
||||
|
||||
1. Vypracujte písomný prehľad verejných klaudových služieb a softvérových prosriedkov pre podporu procesu a nasadenia aplikácie.
|
||||
2. Vytvorte a opíšte webovú aplikáciu zloženú z viacerých komponentov a upravte ju do podoby vhodnej na nasadenie v klaude. K aplikácii vytvorte automatické testy.
|
||||
3. Vytvorte a opíšte proces kontinuálneho nasadenia a integrácie zmien do Vašej aplikácie pomocou vybraných klaudových služieb.
|
||||
4. Navrhnite zlepšenia Vášho procesu tak, aby bolo možné aplikáciu vylepšovať a udržiavať v prostredí softvérovej firmy.
|
||||
|
||||
|
||||
Vedúci: doc. Matúš Pleva PhD.
|
||||
|
||||
Nápad:
|
||||
|
||||
- Vytvoriť webovú aplikáciu s použitím Spring Boot, využitie klaudovej databázy Azure a klaudového úložiska. realizovať JWT, využiť CI CD.
|
||||
|
||||
Stretnutie 21.3.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Práca na obsahu BP. Stav zatiaľ nie je uspokojivý.
|
||||
- Pridaný Ingress do aplikácie.
|
||||
- Pridaný GMETER do monitorovania klastra.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zlepšite text práce. Postupujte od všeobecného ku konkrétnemu. Spojte súvisiace časti. Definujte úlohu, vysvetlite základné pojmy. Predstavte Vaše riešenie. V experimentoch vyhodnotte Vaše riešenie a napíšte záver - nápady na zlepšenie.
|
||||
- Použite generatívny model na zlepšenie gramaticky a štylistiky.
|
||||
- Dbajte aby práca spĺňala zadanie.
|
||||
|
||||
Stretnutie 27.2.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Grafana a Prometheus inštalované cez K8s
|
||||
- Práca na písomnej časti.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zjednotiť zápis slova klaud
|
||||
- Opraviť preklepy
|
||||
- Opraviť šablónu
|
||||
|
||||
|
||||
Stretnutie 31.1.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Zmena funkcionality
|
||||
- Problémy pri nasadení - pomocou GitHUb Action, containers. Na kubernetes klaster, lokálny.
|
||||
- Problém je s vlastnými K8s skriptami.
|
||||
- Práca na písomnej časti.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pracujte na písomnej časti.
|
||||
- Opravte K8S skripty.
|
||||
|
||||
Stretnutie 23.1.
|
||||
|
||||
Stav:
|
||||
|
||||
- Kód na zmenu hesla, auth JWT token.
|
||||
- komunikácia medzi frontendom a backendom cez API, ath. cez JWT.
|
||||
|
||||
|
||||
Stretnutie 13.12.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- CI-CD GIT HUB pipeline pre backend aj frontend.
|
||||
- Dockerfile je, zatiaľ to nefunguje s Azure Cloud, funguje lokalne. Registry zatiaľ nefunguje.
|
||||
- Auth cez JWT Token do LocalStorage.
|
||||
- Vyskúšaný Docker Compose, zatiaľ nefunguje na lokálny klaster.
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zistiť čo je Registry a ako to funguje.
|
||||
|
||||
|
||||
Stretnutie 8.11.2024
|
||||
|
||||
Stav:
|
||||
|
||||
- Backend SpringBoot, frontend React-Next.js.
|
||||
- Urobená základná autentifikácia pomocou HTTP Basic Auth.
|
||||
- Vyskúšaná kontajnerizácia.
|
||||
- Kódy sú na GitHUBe. https://github.com/MrSid333/bankapp.git
|
||||
- Aktivované Azure a Azure PostgreSQL aj úložisko. Zatiaľ nie je prepojené. úložisko.
|
||||
- Naštudované GITHUB CI-CD.
|
||||
- Nainštalované minikube.
|
||||
- Práca na textoch.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v otvorených úlohách.
|
||||
- Vytvorte nasadenie aplikácie pomocou Kubernetes.
|
||||
- Napíšte automatické testy a zostavte Github CI-CD pipeline.
|
||||
- Zistite aké obmedzenia má GitHUB Pipeline.
|
||||
- Píšte BP pošlite mi draft.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vytvorte nasadenie Vašej aplikácie do Azure a skritpy pre nasadenie dajte na GitHUB. Dávajte pozor aby ste nezverejnili Vaše prístupové údaje.
|
||||
- Napíšte článok do "online média" o CI CD v klaude vo forme tutoriálu pre študentov. Z tutoriálu sa študent dozvie, čo je to CI CD, ako to vytvoriť pre konkretny projekt na GITHUbe.
|
||||
- Zostavte pipeline pomocou iného nástroja (Azure, Jenkins) a porovnajte ich.
|
||||
|
||||
|
||||
|
||||
Stretnutie 3.10.2024
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Preštudujte si platformu Kubernetes. Napíšte čo je to. Napíšte čo je to kontajnerizácia.
|
||||
- [x] Nainštalujte si microk8s. Aktivujte si MS Azure a naučte sa to používať.
|
||||
- [x] Vytvorte webovú aplikáciu, kotrá sa bude zkladať z viacerých mikroslužieb a bude využívať klaudové úložisko.
|
||||
- Napíšte čo je to CI CD a na čo sa využíva. Zistitie aké CI CD nástroje existujú. Vyberte si vhodný nástroj. Napr. GIT HUB, aleo GitLAB, alebo Jenkins. Alebo použite pipeline z Azure.
|
||||
- Ku aplikácii navrhnite niekoľko automatických testov.
|
||||
- Zostavte CI CD Pipeline pre automatické zostavenie a testovanie aplikácie
|
||||
|
||||
|
||||
|
||||
126
pages/students/2022/yevhenii_leonov/README.md
Normal file
@ -0,0 +1,126 @@
|
||||
---
|
||||
title: Yevhenii Leonov
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [vp2024,bp2025]
|
||||
tag: [rag,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
|
||||
rok začiatku štúdia: 2022
|
||||
|
||||
# Bakalárska práca 2025
|
||||
|
||||
|
||||
Téma:
|
||||
|
||||
|
||||
Vyhodnotenie generovania slovenského jazyka s pomocou vyhľadávania
|
||||
|
||||
Predbežné zadanie:
|
||||
|
||||
1. Vypracujte prehľad metód a modelov generovania jazyka s pomocou vyhľadávania.
|
||||
2. Vypracujte prehľad metód ich vyhodnotenia.
|
||||
3. Vyskúšajte a vyhodnoťte vybranú metódu generovania jazyka s pomocou vyhľadávania.
|
||||
4. Navrhnite zlepšenia pre vybranú metódu generovania odpovede.
|
||||
|
||||
|
||||
Návrh na tému:
|
||||
|
||||
- Vyhodnotenie systémov RAG
|
||||
|
||||
Spolupráca Oleh Poiasnik
|
||||
|
||||
Stretnutie 4.2.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Vyriešené Závislosti projektu - cez Anaconda
|
||||
- Answer relevancy, využitý OpenAI token
|
||||
- Pripravené testovacie otázky a prepojené s RAG systémom Poiasnik.
|
||||
- Písomná časť - nie je pokrok.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pracujte na písomnej časti.
|
||||
- Rozšírte testovaciu množinu.
|
||||
- Opíšte testovací scenár. Výsledky zapíšte do tabuľky.
|
||||
|
||||
Stav 8.11.2024:
|
||||
|
||||
- Práca na úlohách z minulého stretnutia, vyskúšaný RAGAS.
|
||||
- Nainštalovaný a vyskúšaný systém od p. Poiasnika.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pripravte "vzorovú" množinu na testovanie.
|
||||
- Pripravte testovaciu množinu. Množina by sa mala skladať z čo najväčšieho množstva príkladov.
|
||||
- Vyskúšajte testovaciu množinu pomocou RAGAS a modelov ktoré používa p. Poiasnik. Vyhodnotte modely pomocou množiny.
|
||||
- Kódy dávajte na GIT (napr. branch alebo adresár p Poiasnik GIT).
|
||||
- Pokračujte v písomných úlohách. Hľadajte články cez scholar a píšte si poznámky. Do BP.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Pripravte (nakódujte, odkopírovať) postup vyhľadávania podobný ako "reálny systém", ale využíval RAGAS.
|
||||
- Pripravte testovacie API pre RAG systém. Bude to funkcia alebo URL cez ktorú sa bude dať systém testovať.
|
||||
- Pomocou metriky a množiny vyhodnotte reálny systém.
|
||||
|
||||
|
||||
Stretnutie 11.10.2024:
|
||||
|
||||
Stav:
|
||||
|
||||
- Urobené poznámky na tému RAG
|
||||
- Nainštalované PrivateGPT, Ollama na Windowse
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Budeme využívať systém RAGAS. Nainštalujte si ho a vyskúšajte. Optimálne použite systém Anaconda-Linux. V anaconda využívajte virtuálne prostredia.
|
||||
- [x] Naštudujte dokumentáciu a články https://docs.ragas.io/en/stable/index.html
|
||||
- [ ] Vyhľadajte vedecké články na tému "retrieval augmented generation evaluation" a prečítajte si aj článok o "ragas". Použite google scholar. Napíšte si poznámky.
|
||||
- [-] Zistite a opíšte aké metriky sa používajú. Ku každej metrike je potrebný odkaz na článok.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- [-] Zostavte množinu na vyhodnotenie RAG systému pre medicínsku oblasť. Množina bude vyjadrovať "testovací scenár" navštevy lekárne. V prvej fáze neriešime dialóg, ale otázky a odpovede.
|
||||
- [ ] Napíšte príklady alebo použite generatívny model
|
||||
|
||||
|
||||
|
||||
# Vedecký projekt 2024
|
||||
|
||||
|
||||
RAG: Generovanie jazyka s pomocou vyhľadávania -Retrieval augmented generation
|
||||
|
||||
|
||||
Úlohy na semester:
|
||||
|
||||
- Zistite čo je to Retrieval Augmented Generation a napíšte o tom správu.
|
||||
- Naučte sa základy jazyka Python.
|
||||
- Podrobne si prejdite minimálne dva tutoriály.
|
||||
- Napíšte krátky report na 2 strany kde napíšete čo ste urobili a čo ste sa dozvedeli.
|
||||
- Nainštalujte si a vyskúšajte softvér PrivateGPT
|
||||
|
||||
Stretnutie 12.4.
|
||||
|
||||
Stav:
|
||||
|
||||
- Učenie sa Pythonu, nainštalovaná Anaconda.
|
||||
- Urobené stručné poznámky o RAG o BERT a o GPT.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v otvorených úlohách.
|
||||
- Vyskúšajte systém OLLAMA. Keď to nejde na Windows, vyskúšajte Ubuntu WSL(2).
|
||||
- Pracujte na "článku".
|
||||
|
||||
|
||||
Stretnutie 22.3.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [-] Nainštalujte si prostredie Anaconda. Prejdite si knihu Dive Deep into Python 3.
|
||||
- [-] Nainštalujte si PrivateGPT. Zistite ako funguje RAG. Zistite ako funguje ChatGPT. Zistite ako funguje vyhľadávanie pomocou SentenceTranformers. Napíšte o tom poznámky.
|
||||
- [-] Prečítajte si knihu https://d2l.ai/ a napíšte si poznámky.
|
||||
|
||||
82
pages/students/2023/denis_le_thanh/README.md
Normal file
@ -0,0 +1,82 @@
|
||||
---
|
||||
title: Denis Le Thanh
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [bp2026]
|
||||
tag: [lm,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
|
||||
rok začiatku štúdia: 2023
|
||||
|
||||
študent KPI
|
||||
|
||||
vedúci Ing. Tomáš Kormaník
|
||||
|
||||
konzultácie: Ing. Kristián Sopkovič
|
||||
|
||||
# Bakalárska práca 2026
|
||||
|
||||
|
||||
Téma:
|
||||
|
||||
Trénovanie jazykového modelu pre spracovanie inštrukcií v prirodzenom jazyku
|
||||
|
||||
|
||||
Ciele:
|
||||
|
||||
- Skúsiť dotrénovať slovenský generatívny model (slovak-mistral-7b) pre inštrukcie.
|
||||
|
||||
Stretnutie 5.12. (K. Sopkovič)
|
||||
|
||||
Stav:
|
||||
|
||||
- Analyticka praca cca 12 stran
|
||||
- Su potrebne vyhotiv zmeny - tema musi suvisiet so studijnum odborom - kyberbezpecnost (potrebna diskusia s D.Hladek). - Navrhujeme kontrolu obsahu instrukcii? Filter? Hate Speech model do pipeline? k dispozicii je fine tunning script ktory treba este doladit
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Skuste upravit poskytnuty script p.doc. Hladekom aby spojazdnil dotrenovanie pomocou QLORA na datasete https://huggingface.co/datasets/saillab/alpaca-slovak-cleaned/
|
||||
- Pre hlbsie experimenty bude treba vubavit pristup na server (zatial je vysoko doporucena free verzia na google collab) - odporucam video z youtube ako tutorial pre pracu v collabe - popripadne kontaktovat veduceho prace Ing. Kormanika pre vybavenie pristupu na DGX / podobny server vzhaldom na vypoctovu narocnost (tutorial ako pouzivat server bude poskytnuty konzultantom Sopkovicom)
|
||||
- Urobit prieskum moznych verejnych datesetov podobnym alpace, ktore by sa mohli pouzit
|
||||
|
||||
Stretnutie 3.10.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Naštudované LLM, transformers, anaconda, Okapi, open instruct, ollama.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Naštudovať a vyskúšať PEFT-QLORA.
|
||||
- Vyskúšajte si skript pre dotrénovanie Slovak Mistral.(poslal som cez Teams)
|
||||
- Oboznámte sa s Huggingface TRL.
|
||||
- Oboznámte sa s knižnicou "unsloth".
|
||||
- Oboznámte sa s https://github.com/hiyouga/LLaMA-Factory
|
||||
- Pracujte na teoretickej časti: opíšte základné pojmy, metódy a dátové množiny. Používajte google scholar a bibliografické odkazy.
|
||||
- Najprv pracujte s domácou GPU, ak nebude stačiť pracujte s Google Coolab, ak nebude stačiť požiadajte konzultanta.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Dotrénujte a vyhodnotte Slovak Mistral.
|
||||
|
||||
Stretnutie 26.2.
|
||||
|
||||
Úlohy:
|
||||
|
||||
|
||||
- Oboznámte sa s problematikou veľkých jazykových modelov. Towards Data Science
|
||||
- Naučte sa Python lepšie. Nainštalujte si prostredie Anaconda.
|
||||
- Poučte sa o strojovom účení. Dive into deep learning.
|
||||
- Vyskúšajte si framework HF Transformers.
|
||||
- Vyskúšajte si veľký jazykový model, napr. cez systém OLLAMA.
|
||||
- Oboznámte sa s repozitárom https://github.com/allenai/open-instruct, prečítajte si články
|
||||
- Oboznámte sa s repozitárom https://github.com/nlp-uoregon/Okapi, prečítajte si články
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Strojovo preložte vybranú množinu inštrukcií a použite ju v trénovaní.
|
||||
- Vyhodnotte výsledný model a porovnajte ho.
|
||||
|
||||
|
||||
152
pages/students/2023/maksym_zatirka/README.md
Normal file
@ -0,0 +1,152 @@
|
||||
---
|
||||
title: Maksym Zatirka
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [bp2026]
|
||||
tag: [nlp,graph,db]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
|
||||
rok začiatku štúdia: 2023
|
||||
|
||||
študent KM
|
||||
|
||||
|
||||
# Bakalárska práca 2026
|
||||
|
||||
|
||||
Téma:
|
||||
|
||||
Grafová databáza pre podporu generovania slovenského jazyka
|
||||
|
||||
Zadanie:
|
||||
|
||||
1. Vypracujte prehľad metód podpory generovania prirodzeného jazyka pomocou znalostných grafov.
|
||||
2. Zostavte znalostný graf pre slovenské právo a vložte ho do vybranej grafovej databázy.
|
||||
3. Navrhnite a vytvorte inteligentného agenta, ktorý využije vytvorený znalostný graf.
|
||||
4. Vyhodnoťte agenta, identifikujte jeho slabé miesta a navrhnite zlepšenia pre prácu so znalostným grafom.
|
||||
|
||||
Ciele:
|
||||
|
||||
|
||||
Vytvorte databázu pre vyhľadávanie v právnych predpisoch s využitím grafovej informácie.
|
||||
|
||||
Stretnutie 26.5.2026
|
||||
|
||||
Stav:
|
||||
|
||||
- Agent aj parser funguje.
|
||||
- Webová aplikácia je nasadená cez streamlit.
|
||||
- grafová databáza neo4J cez neo4J aura.
|
||||
- najprv ide parsovanie štruktúry. V druhej etape ide sémantické parsovanie - langchain a llamaindex.
|
||||
- agent má viacero nástrojov.
|
||||
|
||||
```
|
||||
search_concept, # vyhľadávanie pojmov s provenienciou
|
||||
cypher_lookup, # fallback pre pokročilé Cypher dotazy
|
||||
fulltext_search, # fulltextové vyhľadávanie v texte paragrafov
|
||||
get_provision, # úplný text jedného paragrafu
|
||||
list_acts, # zoznam všetkých zákonov
|
||||
graph_traversal, # sémantické okolie konkrétneho zákona
|
||||
defines_concepts, # pojmy definované v zákone
|
||||
find_amendments, # novelizácie a zrušenia zákonov
|
||||
graph_stats, # štatistika grafu
|
||||
compare_acts, # porovnanie dvoch zákonov
|
||||
act_provisions, # štruktúra zákona (paragrafy, články atď.)
|
||||
```
|
||||
|
||||
Používa školský LLM model120-fast.
|
||||
|
||||
|
||||
|
||||
Stretnutie 6.3.
|
||||
|
||||
- Parser vie rozparsovať zákony na paragrafy a odseky, vie verzie zákonov.
|
||||
- Máme jednoduchého agenta, ktorý vie pracovať s grafovou databázou.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pripravte vzorovú datababázy zákonov - nemusia byť všetky a vložte ju do grafovej databázy..
|
||||
- Pripravte viacero testovacích scenárov pre vyhľadávanie v zákonoch. Scenár by mal byť vo forme otázky.
|
||||
- Agent by mal podľa otázky vyhľadať relevatné a súvisiace paragrafy v databáze a vygenerovať odpoveď podľa paragrafov.
|
||||
- Zobrazte aj zoznam zdrojov - relevantnej časti znalostného grafu.
|
||||
- Kódy dajte na GIT. Mal by tam byť parser. Aj agent. Aj stručná dokumentácia.
|
||||
- Pracujte na teoretickej časti práce. Napíšte o metódach GraphRAG. Používajte články z Google Scholar. Opíšte metódu zostavenia znalostného grafu, grafovú databázu aj architektúru agenta. Opíšte výsledky experimentov v testovacích scenároch.
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Pripravte pekné webové rozhranie.
|
||||
- Pripravte deployment Vašej aplikácie - dockerfile a docker compose.
|
||||
|
||||
|
||||
|
||||
|
||||
Stretnutie 4.2.
|
||||
|
||||
- Sú stiahnuté predpisy za rok 2024.
|
||||
- Hotový skript na transformáciu HTML do grafovej databázy.
|
||||
- Súbory sú na https://git.kpi.fei.tuke.sk/kpi-zp/2026/bp.maksym.zatirka/workspace/grafova-databaza-pre-podporu-generovania-slovenskeho-jazyka
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Použite model, prístupný cez OpenAI completions API.
|
||||
- Agent by mal vedieť vyhľadávať v zákonoch aj v súvisiacich predpisoch. Ku otázke zistite súvisiace právne predpisy z grafovej databázy. Porovnajte to s odpoveďou modelu.
|
||||
- Vytvorte aj jednoduché rozhranie ku agentovi. Rozhranie sa da riešiť ako modul do openwebui.
|
||||
- Napíšte niekoľko vzorových scenárov.
|
||||
- Zatiaľ použijete svoju databázu neo4j, neskôr prirobím databazu ku ui.tukekemt.xyz
|
||||
- Pokračujte v práci na texte BP - využitie znalostných grafov v LLM.
|
||||
- Rozšírte databázu pravidiel.
|
||||
|
||||
|
||||
|
||||
Stretnutie 7.11.
|
||||
|
||||
Stav:
|
||||
|
||||
- Prečítané články
|
||||
- Vyskúšaná Neo4J a Python.
|
||||
- Vyskúšaný tutoriál lagchain, intro do Neo4J.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v teoretickej príprave. Pridajte písomné poznámky z článkov a tutoriálov do práce.
|
||||
- Vytvorte znalostný graf, ktorý vyjadruje slovenské právne predpisy a vložte ho do databázy.
|
||||
- Oboznámte sa s obsahom slov-lex.sk a navrhnite štruktúru znalostného grafu pre vyjadrenie vzťahov medzi právnymi predpismi. Aké entity a aké vzťahy tam existujú? Napr. zákon má číslo, má názov.
|
||||
- Vytvorte skript, ktorý spracuje HTML súbory zo slov-lex a vytvorí znalostný graf vo formáte Neo4j. Na parsovanie html možno bude stačiť BeautifulSoup.
|
||||
- Bol aktivovaný prístup na server quadro ku súborom z slov-lex.sk .
|
||||
- Skripty dávajte na GIT.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Využite znalostný graf pri RAG a vyhľadávaní. Spolupráca Matej Ščišľak.
|
||||
|
||||
Stretnutie 2.10.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Prejdite si tutoriál https://python.langchain.com/docs/tutorials/rag/
|
||||
- Prejdite si tutoriály https://neo4j.com/docs/getting-started/appendix/tutorials/tutorials-overview/
|
||||
- Zistite, ako vieme využiť grafy pri RAG - ako skombinovať langchain a neo4j
|
||||
- Pokračujte v štúdiu Python
|
||||
- Prečítajte si články https://arxiv.org/abs/2408.08921 a https://ieeexplore.ieee.org/abstract/document/10771030 a robte si poznámky.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Pripravte databázu znalosti zo súdnej domény pre zlepšenie vyhľadávania v rozsudkoch.
|
||||
|
||||
|
||||
Predbežné úlohy:
|
||||
|
||||
- Naučte sa Python lepšie. Nainštalujte si prostredie Anaconda.
|
||||
- Poučte sa o strojovom účení. Dive into deep learning.
|
||||
- Zistite čo je to Retrieval Augmented Generation a napíšte si o tom poznámky
|
||||
- Pozrite si knižnicu [llamaindex](https://developers.llamaindex.ai/python/framework/).
|
||||
- Zistite čo je to [znalostný graf](https://en.wikipedia.org/wiki/Knowledge_graph)
|
||||
- Zistite ako funguje databáza Neo4J.
|
||||
- Zistite čo je to SparkQL.
|
||||
- Napíšte si poznámky z vecí ktoré ste sa naučili. Využívajte odborné články, ktoré nájdete na google scholar.
|
||||
|
||||
|
||||
|
||||
154
pages/students/2023/oleksandr_dorybohov/README.md
Normal file
@ -0,0 +1,154 @@
|
||||
---
|
||||
title: Oleksandr Dorybohov
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [bp2026]
|
||||
tag: [lm,nlp,agent]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
|
||||
rok začiatku štúdia: 2023
|
||||
|
||||
|
||||
# Bakalárska práca 2026
|
||||
|
||||
https://git.kemt.fei.tuke.sk/od059jr/ai-lawyer-agent
|
||||
|
||||
Téma:
|
||||
|
||||
Automatické odpovede na otázky v právnej oblasti
|
||||
|
||||
Ciele:
|
||||
|
||||
Vytvorte agenta pre spracovanie slovenských právnych textov
|
||||
|
||||
Predbežné zadanie:
|
||||
Zadanie:
|
||||
|
||||
1. Vypracujte prehľad jazykových modelov s podporou slovenčiny a s možnosťou volania nástrojov.
|
||||
2. Vyberte a opíšte vhodné verejné API pre prístup k informáciám z právnej oblasti.
|
||||
3. Navrhnite a vypracujte inteligentného agenta, ktorý bude vedieť používať toto API s cieľom pomôcť pri práci s právnou agendou.
|
||||
4. Vytvorte a vyhodnoťte webové demo pre interakciu s agentom.
|
||||
|
||||
|
||||
Spolupráca:
|
||||
|
||||
- Projekt [Právne informácie](/topics/legal).
|
||||
|
||||
|
||||
Stretnutie 23.3.2026
|
||||
|
||||
|
||||
Stav:
|
||||
|
||||
- Agent funguje.
|
||||
- Text je v príprave.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pracujte na texte práce. Používajte google scholar a odkazy v texte.
|
||||
- Rozšírte rozhranie pre prácu s verejným API.
|
||||
- Vytvorte MCP server pre prácu s verejným API.
|
||||
- Pripravte kódy na nasadenie pomocou Docker. Upravte konfiguráciu aby sa aplikácia dala používať s rôznymi modelmi cez OpenAI API. Môžete použiť LiteLLM.
|
||||
- Do práce opíšte rôzne scenáre použitia. Porovnajte aj viac jazykových modelov. Ako vedia iné jazykovvé modely spolupracovať s OpenAI Agents SDK?
|
||||
|
||||
|
||||
Stretnutie 19.12.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Urobený Dockerfile aj docker-compose, httpx namiesto requests, streamlit na chainlit
|
||||
- Zlepšený system prompt.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v písaní
|
||||
- Dajte kódy na GIT.
|
||||
- Vyskúšajte ešte raz model na mango, ak to nefunguje kontaktujte vedúceho.
|
||||
|
||||
Stretnutie 12.12.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Nová verzia projektu je na GITe. Demo funguje lokálne s lokálnym modelom. Vie vyhľadávať v súdnych rozhodnutiach a konaniach.
|
||||
- Pridané odkazy a rozhranie na API cez SWAGGER.
|
||||
- Funguje OLLAMA- gpt-oss:20B model.
|
||||
- Pokračuje písomná časť, je problém pri kompilácii.
|
||||
- Testovacie otázky sú v PDF.
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Agent by sa mal snažiť preformulovať otázku tak, aby našiel judikatúru týkajúcu sa otázky a podľa nej dal odpoveď. Podľa toho upravte prompty.
|
||||
- [x] Priprave demo na zverejnenie. Pripravte Dockerfile a docker compose pre Vášho agenta.
|
||||
- [ ] Výskúšajte API modelu na školskom servri mango.
|
||||
- [ ] Pokračujte v písomnej práci
|
||||
- [ ] Pridajte "testovacie" scenáre - otázky pre chatbota a očakávané odpovede.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Slovne alebo automaticky vyhodnotte správanie agenta.
|
||||
|
||||
Stretnutie 14.11.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Śtúdium LLM, ale ešte treba písať viac.
|
||||
- Vyskúšaná OLLAMA, treba viac panäte.
|
||||
- Vyskúšané OpenAI agents, práca s streamnlit.
|
||||
- Vyskúšané Justice.sk Swager REST Api. Funguje.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v písaní práce, kódy dajte na kemt GIT.
|
||||
- Pripravte Streamlit rozhranie
|
||||
- OpenAI agents API agenta pre volanie REST API funkcií pre získanie právnych informácií.
|
||||
- Zaujíma nás: Získavanie znenia rozsudkov, občianskych konaní, správnych konaní, zmluvy, zoznam sudcov, rozvrh súdu.
|
||||
- Pripravte testovacie otázky.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Použite školský model gpt-oss-20B alebo Qwen3-72B s OpenAI Agents
|
||||
|
||||
Stretnutie 3.10.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Štúdium Python, Anaconda, langgraph
|
||||
- Základy LLM
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [ ] Oboznámte sa so základmi LLM. Ako pracujú najnovšie modely? Zistite čo je to LLM function calling. Použite google scholar a píšte si poznámky.
|
||||
- [x] Vyskúšajte si ollama s novými modelmi. Napr. gpt-oss.
|
||||
- [x] Vyskúšajte si knižnicu openai-agents-sdk a prejdite si tutoriály.
|
||||
- [x] Treba vybrať knižnicu a model pre prácu s agentami.
|
||||
- Pozrite si https://obcan.justice.sk/pilot/api/ress-isu-service/swagger-ui/index.html a https://www.justice.gov.sk/sluzby/register-partnerov-verejneho-sektora/open-data/ Podľa týchto odkazov si vyskúšajte REST rozhranie pre prácu s verejnými súdnymi API. Napr. cez curl, alebo Python requests.
|
||||
- Zistitie, ako pracuje agent ktorý vie volať REST API.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vytvorte agenta, ktorý bude vedieť pracovať s verejne dostupným API a pomocou neho bude vedieť pomáhať právnikom a sudcom.
|
||||
- Navrhnite WEB demo ku takémuto agentovi.
|
||||
|
||||
|
||||
Stretnutie 10.4.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Oboznámte sa s problematikou veľkých jazykových modelov. Towards Data Science
|
||||
- Naučte sa Python lepšie. Nainštalujte si prostredie Anaconda.
|
||||
- Poučte sa o strojovom účení. Dive into deep learning.
|
||||
- Vyskúšajte si framework HF Transformers.
|
||||
- Vyskúšajte si veľký jazykový model.
|
||||
- Vyskúšajte si framework LangChain a LangGraph. Prejdite si základný tutoriál LangGraph.
|
||||
- Oboznámte sa so stránkou otvorenesudy.sk
|
||||
- Napíšte si poznámky z vecí ktoré ste sa naučili.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Získajte, vytvorte alebo vygenerujte databázu otázok a odpovedí z právnej oblasti.
|
||||
- Získajte a spracujte databázu právnych informácií
|
||||
- Vytvorte webovú aplikáciu pre využitie agenta pre právne informácie
|
||||
|
||||
87
pages/students/2023/ronald_zalacko/README.md
Normal file
@ -0,0 +1,87 @@
|
||||
---
|
||||
title: Ronald Zalacko
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [bp2026]
|
||||
tag: [web]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
|
||||
rok začiatku štúdia: 2023
|
||||
|
||||
|
||||
Vedúci: Matúš Pleva
|
||||
|
||||
|
||||
# Bakalárska práca 2026
|
||||
|
||||
|
||||
Téma:
|
||||
|
||||
Skórovací online systém pre robotické súťaže
|
||||
|
||||
|
||||
https://git.kemt.fei.tuke.sk/rz409st/scoring-system/src/branch/main/backend
|
||||
|
||||
Ciele:
|
||||
|
||||
- Vypracujte prehľad robotických súťaží a podporného softvéru pre robotické súťaže.
|
||||
- Vyberte jeden druh robotickej sútaže a opíšte procesy ktoré tam prebiehajú.
|
||||
- Podľa vykonanej analýzy navrhnite a vytvorte aplikáciu pre podporu a manažment robotickej súťaže.
|
||||
- Aplikáciu nasaďte pomocu systému Docker a otestujte.
|
||||
- Slovne ohodnoťte aplikáciu a identifikujte miesta pre zlepšenie. Vypracujte používateľskú a systémovú príručku.
|
||||
|
||||
Stretnutie 8.12.2025
|
||||
|
||||
- Práca na textoch podľa inštrukcií
|
||||
- Frontend React, backend Flask, DB Postgres, SQLAlchemy, Vite JS, Websocket - socket.io, JWT Token na AUTH.
|
||||
- Aplikácia funguje.
|
||||
|
||||
Úlohy - Úprava logiky:
|
||||
|
||||
- pridat Judge podla lokalneho miesta /KE, BA/. Judge by mal mať Organizáciu-Affiliation.
|
||||
- bez prihlasovania hracov, admin ako judge
|
||||
- judge aby bol pouzitelny z mobilu
|
||||
- bodovanie - čas pre obe timy, ku kazdemu timu pripisat casove skore, kolko to trvalo to prejst, napr.
|
||||
- v jednom kole môže byť N tímov
|
||||
- zvacsit pismo, primerane vsetko
|
||||
- admin, moznost jedneho timu iba, aj viac ako n
|
||||
- 1 sutaz, viac disciplin, viac kôl,
|
||||
- line following, vyjdenie z bludiska,
|
||||
|
||||
Úlohy:
|
||||
|
||||
- pokračovať v písaní podľa inštrukcií. Používajte Google scholar a odkazy v texte na odborné články.
|
||||
|
||||
Úlohy 30.10.2025:
|
||||
|
||||
- [x] Zistite čo je to REST API. Napíšte si poznámky
|
||||
- [x] Zistite aký je proces pri návrhu webovej aplikácie. Napíšte si poznánky.
|
||||
- [x] Zistite, aké Javascript Frameworky sa používajú na tvorbu webových aplikácií.
|
||||
- [x] Oboznámte sa s technológiou Docker Compose.
|
||||
- [x] Zistite, čo je to UML modelovanie.
|
||||
- [ ] Slovne opíšte robotickú súťaž. Zostavte aktivity diagram a use case diagram pre robotickú súťaž. Akí ľudia budú interagovať s aplikáciou? Akým spôsobom. Aké pohľady budú potrebovať?
|
||||
- [x] Zostavte entitno relačný diagram pre relačnú databázu.
|
||||
- [x] Navrhnite architektúru aplikácie. Aké technológie sa použijú na Frontend a aké na Backend?
|
||||
- [x] Zistite ako sa používa Copilot.
|
||||
- [x] Študujte Javascript -
|
||||
- [x] Voliteľné: Študujte Python - prejdite si Flask tutoriál
|
||||
- [x] Pozrite si https://robosteam.eu/ https://github.com/hladek/scoreboard2 https://github.com/hladek/scoreboard https://contests.nitroclubs.eu/
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- [x] Zdrojové kódy dajte na katedrový GIT.
|
||||
- [x] Implementujte frontent aj Backennd
|
||||
- [x] Implementujte databázu
|
||||
- [x] Vytvorte Dockerfile a docker-compose.
|
||||
|
||||
Úlohy 11.10.2025
|
||||
|
||||
- Urobte prehľad robotických súťaží
|
||||
- Oboznámte sa techológiami Websockets, Flask, SQLAlchemy.
|
||||
|
||||
|
||||
|
||||
|
||||
162
pages/students/2023/rostyslav_rodzhuk/README.md
Normal file
@ -0,0 +1,162 @@
|
||||
---
|
||||
title: Rostyslav Rodzhuk
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [vp2025,bp2026]
|
||||
tag: [agent,lm,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
|
||||
rok začiatku štúdia: 2023
|
||||
|
||||
|
||||
|
||||
# Bakalárska práca 2026
|
||||
|
||||
|
||||
Téma:
|
||||
|
||||
Inteligentný agent pre podporu práce špeciálneho pedagóga
|
||||
|
||||
Predbežné zadanie:
|
||||
|
||||
1. Vypracujte prehľad agentových systémov na báze veľkého jazykového modelu.
|
||||
2. Získajte dáta z internetu a vytvorte inteligentného agenta na pomoc špeciálnemu pedagógovi.
|
||||
3. Navrhnite a nasadte webové rozhranie pre inteligentného agenta.
|
||||
4. Navrhnite viacero scenárov interakcie s inteligentným agentom a slovne vyhodnoťte ich priebeh.
|
||||
|
||||
|
||||
https://github.com/RostikRd/bp2026
|
||||
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zistite, čo robí špeciálny pedagóg.
|
||||
- Pozrite si opatrenia na https://podporneopatrenia.minedu.sk/katalog-podpornych-opatreni/ a vyberte relevantné dokumenty
|
||||
- Vytvorte inteligentného agenta, ktorý by na základe dokumentov navrhol najlepšie výchovné opatrenia.
|
||||
|
||||
Stretnutie 11.5.
|
||||
|
||||
Stav:
|
||||
|
||||
- Dokončené texty aj program.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Daje zdrojáky na GIT.
|
||||
|
||||
Stretnutie 6.3.
|
||||
|
||||
Stav:
|
||||
|
||||
- Prezentovaná teoretická časť
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v písaní.
|
||||
- Dajte zdrojáky na GIT.
|
||||
|
||||
Stretnutie 6.2.2026
|
||||
|
||||
Stav:
|
||||
|
||||
- využitie internetu pre vyhľadanie aj overenie.
|
||||
- Dorobený fallback na internet.
|
||||
- texty nie je pokrok
|
||||
- možnosť pridať vlastné dokumenty.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- dajte zdroje na GIT
|
||||
- Pokračujte v práci na textoch
|
||||
|
||||
Stretnutie 12.12.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Docker compose je uroený
|
||||
- Mierne zlepšenie UI
|
||||
- Písanie o RAG.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračovať v tom čo je.
|
||||
- Dajte nové zdrojáky na GIT.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vyskúšať prácu s modelom nasadeným na školskom servri.
|
||||
- Agent môže využiť internet, ak nenájde výsledky v dokumentoch.
|
||||
- Agent môže overiť výsledky pomocným vyhľadávaním.
|
||||
- Možnosť spätnej väzby od pedagóga.
|
||||
|
||||
|
||||
Stretnutie 7.11.
|
||||
|
||||
Stav:
|
||||
|
||||
- Špeciálny pedagóg pomáha celej škole. Napíše odporúčania pre učiteľa aj pre školu o opatreniach pre študenta.
|
||||
- Vieme navrhnúť takého agenta, ktorý navrhne opatrenia.
|
||||
- Získané HTML dáta z podporneopatrenia.minedu.sk. Dáta sú konvertované do Markdown pomocu Docling.
|
||||
- Opatrenia sú roztriedené to troch skupín: všeobecné, cielené a individuálne.
|
||||
- Skript vytvorí cez langchain vektorové reprezentácie vo FAISS indexe.
|
||||
- Iný skript implementuje API RAG agenta. Je tam aj malé WEB rozhranie.
|
||||
- Je aj dockerfile pre frontend aj backend.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Zistite čo je to RAG. Hľadajte "Retrieval Augmented Generation". Napíšte si poznámky. Používajte google scholar.
|
||||
- [ ] Vypracujte prehľad odborných článkov (z google scholar) o AI agentoch pre podporu vzdelávania. Poznačte si prečítané články.
|
||||
- [ ] Zlepšite vysvetliteľnosť výsledkov agenta. Prečo agent navrhol dané opatrenia? Pridajte odkazy na opatrenia príp. na legislatívu.
|
||||
- [ ] Pridajte možnosť vlastných dokumentov (správa od lekára, psychológa, poznámky pedagóga, prospech..) o študentovi.
|
||||
- [x] Porozprávajte sa s Ing. Sopkovičom ohľadom kontaktu s reálnym špec. pedagógom.
|
||||
- [x] Pripravte možnosť nasadenia systému na školskom servri. Vytvorte Docker Compose, produkčnú konfiguráciu.
|
||||
|
||||
|
||||
Stretnutie 3.10.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Oboznámenie sa s prácou špeciálneho pedagóga.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Pokračujte v štúdiu podporných opatrení. Môžete nájsť podobné stránky aj v ukrajinčine. Čo robí špeciálny pedagóg?Ako vieme pomôcť pri ich práci? Napíšte si poznámky.
|
||||
- [x] Pripravte si množinu dát - získajte dokumenty s podpornými opatreniami https://podporneopatrenia.minedu.sk/ a indexujte ju do databázy pre vyhľadávanie. Použite langchain. Na získanie môžete použiť wget. Na prípravu dát môžete použiť "https://github.com/docling-project/docling".
|
||||
- Zistite čo je to RAG. Hľadajte "Retrieval Augmented Generation". Napíšte si poznámky. Používajte google scholar.
|
||||
- [x] Prejdite si tutoriál https://python.langchain.com/docs/tutorials/rag/
|
||||
- [x] Implementujte RAG systém pre prácu so získanými dátami.
|
||||
- Oboznámte sa s knižnicou Openai Agents SDK.
|
||||
- Kódy na prípravu dát a kódy agenta dávajte na katedrový GIT - repozitár bp2026:
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vytvorte agenta pre pomoc špeciálnemu pedagógovi. Agent vie prečítať zadané dokumenty a na základe otázok zvoliť najlepšie opatrenia.
|
||||
|
||||
# Vedecký projekt 2025
|
||||
|
||||
Veľký jazykový model ako inteligentný agent
|
||||
|
||||
- Zistite čo je to veľký jazykový model
|
||||
- Oboznámte sa frameworkom LangChain
|
||||
- Prečítajte si článok https://arxiv.org/abs/2210.03629
|
||||
- Prejdite si tutoriál https://python.langchain.com/v0.1/docs/modules/agents/agent_types/react/
|
||||
|
||||
Kontrola 23.4:
|
||||
|
||||
- Je to ok, napísaná správa.
|
||||
|
||||
Úlohy 27.3.2025:
|
||||
|
||||
- nainštalujte si prostredie Anaconda.
|
||||
- Prejdite si knihu Dive Into Python.
|
||||
- Nainštalujte si knižnicu LangChain a naučte sa ju používať.
|
||||
- Nainštalujte si a oboznámte sa s knižnicou Huggingface Transformers.
|
||||
- Naučte sa čo je to veľký jazykový model.
|
||||
- Prejdite si základy tutoriál LangChain a prejdite si tutorirál o práci s LLM Agentami.
|
||||
- Napíšte správu na min. 3 strany, kde zhrniete, čo ste sa naučili.
|
||||
|
||||
|
||||
|
||||
156
pages/students/2023/samuel_dzurina/README.md
Normal file
@ -0,0 +1,156 @@
|
||||
---
|
||||
title: Samuel Džurina
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [bp2026]
|
||||
tag: [lm,nlp,agent]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
|
||||
rok začiatku štúdia: 2023
|
||||
|
||||
|
||||
# Bakalárska práca 2026
|
||||
|
||||
|
||||
Téma:
|
||||
|
||||
Dialógový systém pre podporu firemných procesov
|
||||
|
||||
|
||||
Ciele:
|
||||
|
||||
Vytvorte agenta pre podporu činnosti zásielkovej spoločnosti.
|
||||
|
||||
Zadanie:
|
||||
|
||||
1. Vypracujte prehľad architektúr a jazykových modelov pre inteligentných agentov.
|
||||
2. Vypracujte zoznam požiadaviek na agenta pre podporu činnosti zásielkovej spoločnosti.
|
||||
3. Na základe vypracovaného prehľadu a zoznamu požiadaviek navrhnite a vypracujte inteligentného agenta.
|
||||
4. Agenta otestujte a vyhodnoťte formou dotazníka, identifikujte slabé miesta a navrhnite zlepšenia.
|
||||
|
||||
Spolupráca:
|
||||
|
||||
- Simona Bobrovčanová
|
||||
- Valerii Kutsenko
|
||||
- Oleh Poiasnik
|
||||
- Martin Šarišský
|
||||
- Matej Ščišľak
|
||||
|
||||
Stretnutie 27.2.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Zlepšenie extrakcie textu z dokumentov.
|
||||
- Chatbot je použiteľný.
|
||||
- je napísaných asi 15 strán textu. Úvod, analýza, návrh, ciele
|
||||
|
||||
Úlohy:
|
||||
|
||||
-
|
||||
|
||||
Stretnutie 17.12.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Je urobená prvá verzia chatbota - vie hľadať PDF a pristupovať na internet cez DUCKDUCK. Rozhranie je cez streamlit.
|
||||
- Urobené lokálne RAG - me5large. Indexujú sa CMR dohovory, dve verzie (8 a 15 strán). Cez langchain.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v písaní. Do teoretickej časti vysvetlite RAG (komponenty - postup, modely, databázy) a metódy ktoré sa používajú. Použite Google Schlar a odkazy na literatúru v texte.
|
||||
- V praktickej časti predstavte Vášho chatbota. Predstavte problémovú oblasť, ktorú riešite - logistickú spoločnosť a proces ktorý riešite. Aké dokumenty sú relevantné.
|
||||
- Opíšte Vášho chatbota - architektúru a použité prostriedky.
|
||||
- Pripravte znenie dotazníka, odhadovaný počet reposndentov a metódu vyhodnotenia. Definujte ciele priekumu dotazníkom.
|
||||
- Rozšírte chatbota pre ďalši vybraný proces a pridajte relevatné dokumenty. Napr. zmluvné podmienky prepravy.
|
||||
- kódy dajte na GIT.
|
||||
|
||||
Stretnutie 27.11.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Získané prepravné dokumenty z Talianska do veľkej Británie. a Z Francúzska do británie. Zatiaľ nevieme ako sa používajú.
|
||||
- Vytvorený modelový OpenAI chatbot. Agent používa openai api, gpt3.5 turbo a vie odpovedať na otázky. Asi má problém s vyhľadávaním na internete.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Do práce vysvetlite ako funguje function calling, dajte prehľad modelov ktoré sa na túto úlohu používajú. Citujte články zo scholar.
|
||||
- Zdrojáky dajte na KEMT GIT (nedávajte API kľúč).
|
||||
- Navrhnite a použite existujúce používateľské rozhranie pre Vášho agenta. Rozhranie by malo byť použiteľné na prezentáciu kolegom. napr. n8n, streamlit, gradio
|
||||
- Spýtajte sa kolegov. Aké otázky by zadávali agentovi pri ich práci. Aké informácie vyhľadávajú za akým cieľom? Výsledky prieskumu si zapíšte.
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vytvorte Dockerfile
|
||||
|
||||
|
||||
Stretnutie 30.10.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Potreba: Spedicka firma potrebuje efektivnejsie riesit colne pravidla pre prepravy z EU colneho priestoru mimo EU (napr. do Norska, Svajciarska, GB).
|
||||
|
||||
Otvorene otazky a odpovede:
|
||||
1. Pri akom konkretnom procese vie pomoct chatbot? Kto a ako sa tento proces vykonava doteraz?
|
||||
Pomoc chatbota: Chatbot by sa vyuzival na zosuladenie a zrychlenie procesov pri rieseni colneho odbavenia. Konkretne pri priprave spravnych dokumentov (kontrola faktury, dodacieho listu, priradenie spravneho colneho cisla pre vyvazany/dovazany produkt).
|
||||
Sucasny stav: Doteraz to vykonaval spediter manualne. Musel pracne hladat na webe alebo prezerat dokumenty o colnych pravidlach. To bolo zdlhave, kedze v kazdej krajine sa pravidla lisia.
|
||||
Prioritne trasy: Najviac vyuzivana trasa je z EU do GB. Riesi sa aj tranzit EU tovaru mimo priestor EU ku koncovemu zakaznikovi a naspat do EU.
|
||||
2. Ake su technicke poziadavky na nasadenie? Ma firma HW s GPU? Je mozne data poslat mimo firmy?
|
||||
Odpoved: Externe riesenie je v poriadku. Data je mozne poslat mimo firmy. (Firma teda nepotrebuje vlastny HW s GPU).
|
||||
3. Ktore konkretne data vie agent vyuzit? Ktora legislativa je relevantna?
|
||||
Odpoved: Agent musi vyuzivat cely aktualny colny dohovor a vsetky relevantne zakony (cela prislusna legislativa).
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vyberte a podrobne opíšte modelový proces pro ktorom vieme pomôcť. Napr. dovoz zeleniny z Veľkej Británie. Aké dokumenty sú potrebné na vstupe? Aké sú na výstupe?
|
||||
- Podľa toho zistite, aká legislatíva je relevantná.
|
||||
- Pokračujte v tutoriáloch OpenAI Agenta. Vytvorte agenta, ktorý vie vyhľadávať na internete, získať potrebné dokumenty a na ich základe navrhnúť odpoveď.
|
||||
- Zistite, ako funguje "function calling" a "tools" v OpenAI.
|
||||
- Čítajte články na Scholar a píšte poznámy o Agentových systémoch v business procesoch.
|
||||
|
||||
|
||||
Stretnutie 9.10.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Špedičná firma by využila colné pravidlá z EU do EU a CMR dohovor (dohovor o medzinárodnej zmluve o cestnej doprave). CMR dohovor - nákladný list, je formulár ktorý vyplní šofér alebo príjemca a je dokladom o vykonanej preprave. Niečo ako sprievodný list.
|
||||
- Aké colné pravidlá platia pre prepravu konkrétneho druhu tovaru.
|
||||
- Otázky sa týkajú colných vyhlásení.
|
||||
|
||||
Otvorené otázky:
|
||||
|
||||
- [ ] Pri akom konkrétnom procese vie pomôcť chatbot? Kto a ako sa tento proces vykonáva doteraz?
|
||||
- [ ] Ktoré konkrétne dáta vie agent využiť? Ktorá legislatíva (zákony, vyhlášky, zmluvy) je relevantná.
|
||||
- [x] Aké sú technické požiadavky na nasadenie? Má firma HW s GPU? Je možné dáta poslať mimo firmy?
|
||||
- [x] Je možná formálna spolupráca "https://uvptechnicom.sk/spolupraca/#formy" alebo https://edihcassovium.sk/ ?
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zistite, ako pracuje RAG systém. Vypracujte tutoriál https://python.langchain.com/docs/tutorials/rag/
|
||||
- Pozrite sa na gogole scholar a prečítajte si odborné články na tému "retrieval augmented generation" . Napíšte si poznámky.
|
||||
- Prečítajte si článok https://arxiv.org/abs/2401.03428 a napíšte si poznámky.
|
||||
- Navrhnite modelový príklad použitia intelignetného agenta v špedičnej firme.
|
||||
- Vyskúšajte https://openai.github.io/openai-agents-python/ a vytvorte prvú verziu agenta.
|
||||
|
||||
Stretnutie 13.5.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Hotová prvá verzia chatbota. Urobil to niekto iný. Chatbot má zoznam otázok a odpovedí. Vie sťahovať z Wikipedie a vie odpovedať z wikipedie. Chunkuje na 100 znakov. Používa OpenAI API. Nemá databázu, len CSV.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Špecifikujte oblasť použitia chatbota. Identifikujte potenciálne zdroje informácií. Alebo budeme robiť v nejakej právnej, vzdelávacej alebo lekárskej oblasti.
|
||||
- Oboznámte sa s problematikou veľkých jazykových modelov. Towards Data Science
|
||||
- Naučte sa Python lepšie. Nainštalujte si prostredie Anaconda.
|
||||
- Poučte sa o strojovom účení. Dive into deep learning.
|
||||
- Vyskúšajte si framework HF Transformers.
|
||||
- Vyskúšajte si veľký jazykový model, pomocou HF transformers alebo pomocou ollama.
|
||||
- Vyskúšajte si framework LangChain a LangGraph. Prejdite si základný tutoriál LangGraph.
|
||||
- Pozrite si knižnicu llamaindex.
|
||||
- Napíšte si poznámky z vecí ktoré ste sa naučili. Využívajte odborné ščlánky, ktoré nájdete na google scholar.
|
||||
|
||||
|
||||
|
||||
120
pages/students/2023/simona_bobrovcanova/README.md
Normal file
@ -0,0 +1,120 @@
|
||||
---
|
||||
title: Simona Bobrovčanová
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [bp2026]
|
||||
tag: [lm,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
|
||||
rok začiatku štúdia: 2023
|
||||
|
||||
|
||||
# Bakalárska práca 2026
|
||||
|
||||
Téma:
|
||||
|
||||
Automatická sumarizácia slovenského textu
|
||||
|
||||
Zadanie:
|
||||
|
||||
1. Zostavte prehľad modelov a metód vhodných na automatickú sumarizáciu textov v slovenskom jazyku.
|
||||
2. Vyberte viacero vhodných modelov a vykonajte sumarizáciu na vybranej množine.
|
||||
3. Vyhodnoťte výsledky vhodnou metódou.
|
||||
4. Identifikujte slabé miesta existujúceho spôsobu sumarizácie a navrhnite možné zlepšenia.
|
||||
|
||||
https://git.kemt.fei.tuke.sk/sb610oy/bakalarska-praca
|
||||
|
||||
Ciele:
|
||||
|
||||
Zlepšite spracovanie slovenských právnych textov - vytvorte systém pre sumarizáciu rozsudkov alebo iných právnych dokumentov.
|
||||
|
||||
Stretnutie 27.2.2026
|
||||
|
||||
Stav:
|
||||
|
||||
- Malé modely majú príliš maly kontext.
|
||||
- Vyskúšaná hierarchická sumarizácia - text je rozdelený na časti a potom sa vykoná sumár zo sumárov. Funguje to "dobre".
|
||||
- Práca na texte pokračuje
|
||||
- Bol poskytnutý prístup na ui.tukekemt.xyz
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Dajte skripty na GIT.
|
||||
- Vyskúšajte aj sumarizáciu pomocou API modelu.
|
||||
- Implementujte porovnanie pomocu ROUGE a BLEU.
|
||||
- Implementujte vyuhodnotenie aj pomocu DeepEval https://deepeval.com/docs/metrics-summarization.
|
||||
- Pokračujte v písaní - opíšte experimenty, výsledky dajte do tabuľky a okomentujte.
|
||||
|
||||
Stretnutie 5.12.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Napísané poznámky o procese dotrénovania pre sumarizáciu, prečítané články zo Scholar.
|
||||
- Pripravené dáta zo sudov pre trénovanie sumarizácie. Text rozhodnutia je vstup, výstup je poučenie. Hlavička a odôvodnenie sa momentálne neberie do úvahy.
|
||||
- Pripravený skript na LORA dotrénovanie.
|
||||
- Vyhodnotenie pomocou ROUGE and BLEU.
|
||||
- Dotrénované a vyhodnotené modely slovak-mistral 7B., Qwen3 , Gemma, Slovak-t5-base
|
||||
- Vyzerá to tak, že problémom je dĺžka kontextu. Modely často vynechajú informácie na konci.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Možné riešenie problému s kontextom je "hierarchická sumarizácia" - model najprv sumarizuje na kratších častiach a potom spojí výsledky do jedného. Sú aj iné spôsoby riešenia? (napr. pomocou vektorových modelov) Toto je možné napísať do prehľadu.
|
||||
- Vypracujte automatické vyhodnotenie sumarizácie pomocu jazykového modelu. Vedúci dodá skript .
|
||||
- Vyskúšajte "zero shot prístup" pomocou "veľkého jazykového modelu". Porovnajte veľký model a dotrénované modely.
|
||||
- Výsledky experimentov dajte do tabuľky.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Implementujte niektorý prístup na prácu s veľkým kontextom.
|
||||
|
||||
Stretnutie 6.10.2025
|
||||
|
||||
Stav:
|
||||
|
||||
- Preštudované deep learning
|
||||
- Framework HF Transformers
|
||||
- Trénovanie sumarizácie pomocou LORA v Anaconda, 4 bit kvanitizácia - llama, mt5-base, mt5 na 6GB RAM
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pozrite sa na google scholar, prečítajte si najnovšie články o sumarizácii súdnych textov a urobte si poznámky.
|
||||
- Napíšte o procese dotrénovania jazykového modelu - supervised finetuning, PEFT-LORA podľa vedeckých článkov.
|
||||
- Vytvoreny pristup bobrovcanova@titan.kemt.fei.tuke.sk.
|
||||
- Dáta sú v /mnt/sharedhome/hladek/corpora/prokuraturadb/
|
||||
- Pripravte si trénovacie a testovacie dáta, zatiaľ bez deanonymizácie a bez prípravy.
|
||||
- Natrénujte a vyhodnotte model pre generovanie poučenia na (základe rozhodnutie a-alebo odôvodnenia).
|
||||
- "Objektívne" vyhodnotenie je pomocou metriky ROUGE alebo BLEU.
|
||||
- Vyskúšajte modely: slovak-mistral 7B., Qwen3 , Gemma, Slovak-t5-base
|
||||
- skripty dajte na kemt git.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vyhodnotenie presnosti pomocou LLM
|
||||
- Lepšie predspracovanie textu
|
||||
- Generovanie rozhodnutia z odôvodnenia.
|
||||
- sumarizácia zero shot, napr. pomocou gpt-oss
|
||||
|
||||
|
||||
|
||||
Stretnutie 3.4.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Oboznámte sa s problematikou veľkých jazykových modelov. Towards Data Science
|
||||
- Naučte sa Python lepšie. Nainštalujte si prostredie Anaconda.
|
||||
- Poučte sa o strojovom účení. Dive into deep learning.
|
||||
- Vyskúšajte si framework HF Transformers.
|
||||
- Vyskúšajte si veľký jazykový model, napr. cez systém OLLAMA.
|
||||
- Oboznámte sa so stránkou otvorenesudy.sk
|
||||
- Zistite, ako vieme dotrénovať jazykový model. Zistite čo je to metóda PEFT, čo je to Supervised finetuning.
|
||||
- Oboznámte sa s databázou https://huggingface.co/datasets/NaiveNeuron/slovaksum
|
||||
- Napíšte si poznámky z vecí ktoré ste sa naučili.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
|
||||
- Spracujte slovenské súdne dáta, upravte ich do podoby vhodnej na trénovanie jazykového modelu
|
||||
- Natrénujte a vyhodnotte model pre úlohu sumarizácie.
|
||||
|
||||