Update 'pages/students/2016/patrik_pavlisin/dp22/README.md'
This commit is contained in:
parent
19b3be94d4
commit
074d1b438b
@ -15,11 +15,6 @@ Na vyriešenie vyššie uvedených obmedzení štandardného Transformera bol na
|
||||
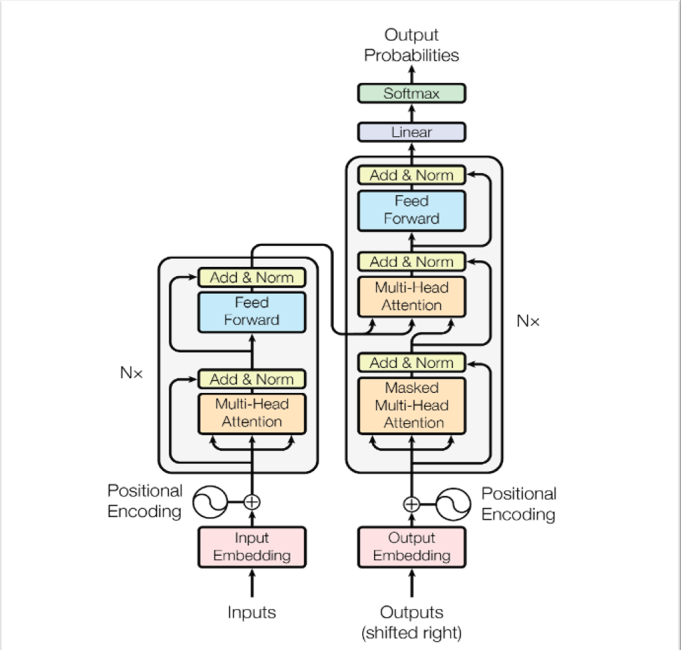
**Modelová architektúra**
|
||||
|
||||
Väčšina konkurenčných prenosových modelov neurónovej sekvencie má štruktúru encoder-decoder. V tomto prípade encoder mapuje vstupnú sekvenciu symbolových reprezentácií (x1, ..., xn) na sekvenciu spojitých reprezentácií z = (z1, ..., zn). Vzhľadom na z, decoder potom generuje výstupnú sekvenciu (y1, ..., ym) symbolov jeden po druhom. V každom kroku je model automaticky regresívny a pri generovaní ďalšieho spotrebuje predtým vygenerované symboly ako ďalší vstup.
|
||||
|
||||
**Pozornosť**
|
||||
|
||||
Funkciu pozornosti je možné opísať ako mapovanie dotazu a sady párov kľúčov a hodnôt na výstup, kde dotaz, kľúče, hodnoty a výstup sú všetko vektory. Výstup sa vypočíta ako vážený súčet hodnôt, pričom hmotnosť priradená každej hodnote sa vypočíta pomocou funkcie kompatibility dotazu so zodpovedajúcim kľúčom.
|
||||
|
||||
|
||||
|
||||
||
|
||||
|
||||
Loading…
Reference in New Issue
Block a user