Compare commits
1542 Commits
knowledgeb
...
master
| Author | SHA1 | Date | |
|---|---|---|---|
| 922906146b | |||
| e08a6d253b | |||
| 576dc43627 | |||
| fe78cd0f9b | |||
| 50f4205743 | |||
| 670c89d4cb | |||
| dbbac1f125 | |||
| d7f39c528f | |||
| d64df15f33 | |||
| 708b3b8ae2 | |||
| b5d1cc40df | |||
| 78ba13aa59 | |||
| 38c65bb735 | |||
| ca13fbd359 | |||
| fc24d25d03 | |||
| e12e139143 | |||
| 13d98987c4 | |||
| c47eaec6ac | |||
| 4936ab1e93 | |||
| d22679dab6 | |||
| 97e4f327c8 | |||
| 58659f217c | |||
| fae1be974e | |||
| 10c5517013 | |||
| 0534b21a1a | |||
| 52255aec0f | |||
| c62fe1f3ed | |||
| 4aa4ff8d46 | |||
| 498aaaccf4 | |||
| a3e9d0c9df | |||
| fc30546f7f | |||
| dce18ad848 | |||
| 9ce49ff66f | |||
| 5509f9c143 | |||
| bd987ff9f2 | |||
| 5208ea17f0 | |||
| 2f2f770fb9 | |||
| 1229f4bda7 | |||
| 22eec496fd | |||
| 0c5094133f | |||
| 15c82dbf31 | |||
| a2c9baa731 | |||
| 906510a66f | |||
| 6cbce1139b | |||
| 2e95faf73a | |||
| cacf1872e1 | |||
| 3cdf28843b | |||
| b9bf125809 | |||
| 3d172dbe10 | |||
| 878733dec1 | |||
| b15765bb22 | |||
| b27f66b38b | |||
| a29ca8833a | |||
| ab6865ecaa | |||
| 87ba0e3dd3 | |||
| e39200ee7f | |||
| 48f8d348b5 | |||
| 9e4799fc1d | |||
| 4297a48520 | |||
| 369acec5f0 | |||
| 61785a9438 | |||
| a717c8333d | |||
| 138250b5c0 | |||
|
|
140e15191a | ||
| b76d500026 | |||
| 6b72a975e8 | |||
|
|
42e71e2dd9 | ||
|
|
946bc7f9f1 | ||
| b06eb9c21c | |||
| d57316ea1c | |||
| 156fc07b79 | |||
| d58d4dfb69 | |||
| 9e65785250 | |||
| 1d93bc6b88 | |||
| de59c44ae8 | |||
| 2036b817d3 | |||
|
|
b9d48f1295 | ||
| 82a789f03d | |||
| f27d3035e7 | |||
| eb6f1414d0 | |||
| 91044d842e | |||
| 93464ea6f4 | |||
| 4a773587c5 | |||
| ff74724afa | |||
| 2d57819456 | |||
| 8ad2446551 | |||
| 14219bb803 | |||
| fab240a113 | |||
| a7434babd6 | |||
| 9c4d430f50 | |||
| 97c6100dd8 | |||
| ed0603679a | |||
| 57ac07b858 | |||
| f1b4128614 | |||
| c3e2b89bdb | |||
| cd3159da34 | |||
| 99c3630651 | |||
| 7bd199056e | |||
| abbced8914 | |||
| 5244c3ba37 | |||
| 68a2950c80 | |||
| 99b2567b83 | |||
|
|
8fcff43616 | ||
|
|
5d6075672c | ||
| d9ded4c56a | |||
| 6e55139ffc | |||
| ec7e0f9702 | |||
| 9a3d26f474 | |||
| 5d9122dad8 | |||
| ea3cf0455b | |||
| 5a3033991b | |||
| 56535a22d3 | |||
| 32230d93e4 | |||
| bd728b347f | |||
| 6a251795b3 | |||
|
|
0854127b94 | ||
|
|
517b2acdce | ||
| 582ec7de93 | |||
| af65f29a56 | |||
| 237a787b19 | |||
| fdf720fd08 | |||
| f08f95e1c7 | |||
| 17012a6998 | |||
| 9b37357264 | |||
| 9736cc5b8f | |||
| 9dacd8eab3 | |||
| 849eb5188d | |||
| 55ad30bdaf | |||
| 624de1cc22 | |||
| a16ce8de2b | |||
| 4939bf781d | |||
| 4fa9922d7d | |||
| b0c087653c | |||
| 069db4e233 | |||
| b1226fadf9 | |||
| 7c539430bb | |||
| 11361bddf9 | |||
| 0ad9a351df | |||
| 79f30ce433 | |||
| 23a6f1fe1a | |||
| 41da6bd005 | |||
| b13b158f6c | |||
| 0d8fd39491 | |||
| 14d9da2af3 | |||
| 42b4395329 | |||
| 18c270c9ff | |||
| d0fdb99f43 | |||
| 26f7a860eb | |||
| 4f4a66e067 | |||
| a5a6855bcb | |||
| 4f43917680 | |||
| 15f9bc7e23 | |||
| 9764b95549 | |||
| a3d49dc7a9 | |||
| 39b3d6f5ef | |||
| e579083c4c | |||
| 89ad49be09 | |||
| d54e37787e | |||
| e975c1305d | |||
| 32546e03d2 | |||
| 9522887db7 | |||
| 9a6c81083e | |||
| 369543e606 | |||
| 38007e9b2f | |||
| 5a6c0f038e | |||
| 67f20bb84a | |||
| df53b4af35 | |||
| 26f5198070 | |||
| 80b87c13b3 | |||
| d8b36e8e16 | |||
| 94422ee832 | |||
| ccded68704 | |||
| 0e1bf24a01 | |||
| 635abb25e1 | |||
| e244502cdd | |||
| 6d426239bb | |||
| 0968b18d78 | |||
| de2e164040 | |||
| b77288fa85 | |||
| 7208d12af2 | |||
| e9a09c427f | |||
| 9065b1effd | |||
| 93990295ec | |||
| ed45d9fceb | |||
| 80cef12276 | |||
| bcab212f34 | |||
| eadf0b71fe | |||
| 7293cd877a | |||
| cc5307000f | |||
| 2f8c425f9d | |||
| da19f64d07 | |||
| b7ea1ea43d | |||
| 1887ffd153 | |||
| 0c81fc8076 | |||
| 4db2a23226 | |||
| bf46c12e69 | |||
| 11393f2bad | |||
| acb779d298 | |||
| e10c0c8896 | |||
| 2f21819f22 | |||
| eb4f8def32 | |||
| b79f78cc8e | |||
| ece560f2ff | |||
| 7f09df3968 | |||
| 5af69cfa2c | |||
| 97364a71e0 | |||
| 4db145504d | |||
| d51b32b692 | |||
| 09f086625e | |||
| f5e0e2cacd | |||
| 0abf1e0243 | |||
| 38f8b31b58 | |||
| 289aa70b91 | |||
| c4047e488c | |||
| 08b435b191 | |||
| 21606fff97 | |||
| 4da4e9bc8a | |||
| 687e7c8183 | |||
| af79987f2e | |||
| c552ebe754 | |||
| 49023656d3 | |||
| 7f4281c0c7 | |||
| 79b0289f72 | |||
| f111a07b7c | |||
| b7d09419db | |||
| cac1df1b02 | |||
| 2278572956 | |||
| f516a886e9 | |||
| 84f7990e3b | |||
| 4bf9d7eb82 | |||
| 08aff172ed | |||
| 2ad90801df | |||
| b49168fc83 | |||
| 236018a74f | |||
| b81177028a | |||
| 70d6ac1a44 | |||
| 71ca8d8e55 | |||
| e429df9a83 | |||
| 37384f4bf2 | |||
| d7f3920bc4 | |||
| 74b9c90856 | |||
| cf3ca04242 | |||
| 8b06a8eb76 | |||
| a95e93cdfd | |||
| 8e59a3c08a | |||
| 1a9b421b5e | |||
| 0759352656 | |||
| 641ce0d453 | |||
| 55e2b15928 | |||
| 8e7a30d6eb | |||
| 8d1d728241 | |||
| dfbf9f0d34 | |||
| 670cf1a222 | |||
| ae45f0467a | |||
| cbab37d7a6 | |||
| 70510dc906 | |||
| 7d005f7894 | |||
| b620d8454e | |||
| 54c801c0bc | |||
| d5888fd98f | |||
| 19b77d22cf | |||
| 8c23357eb4 | |||
| 738c5220aa | |||
| 6c5ab7e7db | |||
| 13660e80f1 | |||
| 98359fe3c5 | |||
| db7890b061 | |||
| c7cd410f7d | |||
| 270b5f7944 | |||
| e14dc631c5 | |||
| 8c458cf6e7 | |||
| 290abefa3c | |||
| 0793a45b32 | |||
| 6eaef23ffd | |||
| 05a1a0830d | |||
| f202afe564 | |||
| 94f6a18dbd | |||
| 8b04e06d0e | |||
| 7bc29bc310 | |||
| 8d03d79a43 | |||
| 888f08f7ea | |||
| 7889c710d0 | |||
| 051ef6fbf3 | |||
| 1244e03ca8 | |||
| 1321ff8ef3 | |||
| eb510a665b | |||
| ce0aa244b3 | |||
| 462bb97028 | |||
| f02b578ad4 | |||
| a8389a1748 | |||
| bd02969944 | |||
| 18ad2b3e2e | |||
| ca24fe5a58 | |||
| b841543d06 | |||
| e1722ce583 | |||
| b8f3c29d58 | |||
| 1906920e0f | |||
| 9feade3a56 | |||
| 431ecad829 | |||
| fe1160531f | |||
| 97bf0c71e2 | |||
| 2658cd723d | |||
| 3843b1868e | |||
| 3ebba9181a | |||
| 7906f71afe | |||
| 976f57094c | |||
| b4c3aeb7b0 | |||
| a51e3c0330 | |||
| 5a6dd420ad | |||
| 465c5fca2f | |||
| 03b0a0fc4f | |||
| 6a88da919e | |||
| 3b6cb298dd | |||
| 1acf509cd5 | |||
| b013eae5ff | |||
| 297a2d0fd0 | |||
| 5805ccc88d | |||
| 065104678a | |||
| 64cd72834f | |||
| 3b69e68c68 | |||
| 96714cf86f | |||
| ac85d71c09 | |||
| a183810ec0 | |||
| 6e769db305 | |||
| 5f48040f68 | |||
| 67cd24be8c | |||
| 7ce7770fd9 | |||
| 95f1777282 | |||
| 19eb0489b1 | |||
| 7be98d80fe | |||
| 2ab2ebdac3 | |||
| ea8b11bf66 | |||
| 37ea275bb3 | |||
| 30f25a1ba6 | |||
| 4e73c3673f | |||
| 4eaf719563 | |||
| 75d6563d88 | |||
| e2f5af01ca | |||
| f17685b6af | |||
| b1bb64c130 | |||
| 4d81829a7d | |||
| 425a07c453 | |||
| 967567a82d | |||
| dd10986c2a | |||
| 1b79126c95 | |||
| 23565f6494 | |||
| b6de5e9024 | |||
| cdb4302794 | |||
| 3466cae684 | |||
| 650c359280 | |||
| 9914034a16 | |||
| 75f985b727 | |||
| bf16cd8874 | |||
| 43790f1ef1 | |||
| 0503d1500a | |||
| d624e1b9e2 | |||
| 4f8404b180 | |||
| 7a75e080c9 | |||
| 46836c436f | |||
| fb75959d0a | |||
| 24eec48dfb | |||
| 69275ddf3c | |||
| 914c8b0d3c | |||
| f5745a4b43 | |||
| 6e7db225aa | |||
| 42846fc2c6 | |||
| df308ff8fa | |||
| 48e6cba92d | |||
| 607b500a20 | |||
| 7f7ed6b851 | |||
| d519291a6f | |||
| e50cc2d517 | |||
| e93104dc31 | |||
| 7c0493590d | |||
| 65e4b3dfc3 | |||
| 56d9b16765 | |||
| 94a0b9bbd8 | |||
| 326fcb088e | |||
| a70ecb4bac | |||
| 990335d73b | |||
| 22dce13975 | |||
| 6d5579ab93 | |||
| 8262accfa8 | |||
| 018e294592 | |||
| 1b3bcf5dd9 | |||
| a0ea885b44 | |||
| 5d4f2d724a | |||
| 9f827d4138 | |||
| a2d5579560 | |||
| bcd2fe3b24 | |||
| 8b254bc6f1 | |||
| 713ef1b3f3 | |||
| 8a1b7c01a5 | |||
| a9ed0f3a04 | |||
| 5df7c705f6 | |||
| 7bc2147c32 | |||
| fdbb633b7c | |||
| 025a444027 | |||
| 8f34de0f5e | |||
| a94df966d6 | |||
| ad38cf5973 | |||
| a163da80cd | |||
| cc8452ef41 | |||
| 47f56e9eab | |||
| 14779680b6 | |||
| 3c12261123 | |||
| ad6fb599c6 | |||
| c046bc0dfd | |||
| 7ce7063e70 | |||
| bf94f4b7fa | |||
| 6a3d7ff793 | |||
| 376a8db290 | |||
| c28de252be | |||
| 37ad32d82c | |||
| d425a1b64b | |||
| 36851f4d8c | |||
| 5fd78c2e28 | |||
| 2ad4bd283c | |||
| 857734f725 | |||
| d640ff2c17 | |||
| 89504d718a | |||
| 2a398b18be | |||
| b4aad5d442 | |||
| bf509acc4b | |||
| 81b9a37659 | |||
| 07563ae39d | |||
| 023b5a759c | |||
| 870a494434 | |||
| 5210ba5989 | |||
| 01bbdbd871 | |||
| 4e988eb1d5 | |||
| 1dd44d87f3 | |||
| e2a5a6e07f | |||
| 1cc689607f | |||
| b97ccf69a1 | |||
| 79ec7d1a71 | |||
| 62c30e5405 | |||
| 05eeddad6a | |||
| 7e1fccbc1f | |||
| 1b59e3931b | |||
| 8225a94b2a | |||
| 5df5b672c8 | |||
| cd7cdf0d7f | |||
| ae824caeb5 | |||
| de34985d85 | |||
| d6ccd33659 | |||
| 09c19da0b4 | |||
| 758fa7b609 | |||
| 6a3a90cfc8 | |||
| 20b3a8c24f | |||
| 8b31786a99 | |||
| 1677cfc7bd | |||
| 31b2756ea4 | |||
| caffd2ffd0 | |||
| d26ba7a260 | |||
| 3d042fedb5 | |||
| cf1f45d1f1 | |||
| 3b73f2ec66 | |||
| a067accf1f | |||
| d71e1dd711 | |||
| f42be61cb7 | |||
| a0eebc2829 | |||
| 634b32e6f6 | |||
| a3b6cbdc35 | |||
| f343ab27fc | |||
| 43ddc7a199 | |||
| 8b0de16542 | |||
| 9fe8dd9221 | |||
| d58a0976f9 | |||
| d1c1cf9a88 | |||
| 41b08e6dae | |||
| 3bfbe0d902 | |||
| a4b526f10b | |||
| 791de5d962 | |||
| 56aab9cd60 | |||
| 5e391d8034 | |||
| b0ab648a84 | |||
| e5049bf745 | |||
| 634ca5ed66 | |||
| f0b0a292de | |||
| 3360fc9987 | |||
| 945f0ec273 | |||
| 0c615320af | |||
| 9e8641e5c9 | |||
| fbd511101e | |||
| c5b35646f7 | |||
| d76800b16d | |||
| a423ce391a | |||
| 6c20b11439 | |||
| fc184ce27a | |||
| a67f15374b | |||
| bc91f11049 | |||
| 20fe1b96a2 | |||
| 23cf241a87 | |||
| f9e7d0eaf1 | |||
| 67b8fffafb | |||
| a8694b8de7 | |||
| aeb9c4174e | |||
| 7fa2c5ba7f | |||
| 8d132a7fe0 | |||
| 5deb5e0177 | |||
| fcfbf6e317 | |||
| 830425a99f | |||
| 243a461dc6 | |||
| 8c88c44684 | |||
| 8ceb2ef2aa | |||
| 8e1f7c3989 | |||
| bc67b44c67 | |||
| 0618cd7610 | |||
| e80a20c38c | |||
| b9ca3c5679 | |||
| 2244c154f9 | |||
| 5ed58223c3 | |||
| a6848cace3 | |||
| 665d43c6da | |||
| f5af4be555 | |||
| 63ad60f2ca | |||
| 16690600ba | |||
| e71f213555 | |||
| ca58249d62 | |||
| 0e662ff2c8 | |||
| 6dc09aa381 | |||
| 62480ac786 | |||
| eaad73df7c | |||
| 1cfb5f0d4a | |||
| 87d89eb2b0 | |||
| 06fec23f6b | |||
| fbe064ecb4 | |||
| d981396f28 | |||
| 8b7ac79ba0 | |||
| 297c746fa2 | |||
| 68fb45f2e7 | |||
| 54446db373 | |||
| c026422601 | |||
| 552d2e265b | |||
| da55365f81 | |||
| 561423c04d | |||
| db92d0b8ad | |||
| e6b63c5f4c | |||
| 68f84e57dc | |||
| 6fcf640ecb | |||
| 18ddd8ec33 | |||
| f381e49918 | |||
| 8457edcd52 | |||
| b40c253814 | |||
| a18bc7cf65 | |||
| 4103ad2cea | |||
| 66f41d824f | |||
| 8bcae47773 | |||
| 66fa011570 | |||
| 5ea1c96a20 | |||
| 1396272f18 | |||
| f647915eab | |||
| 1b3c522227 | |||
| ce2d8034e0 | |||
| fb71aa80af | |||
| e6d905f298 | |||
| e9b906c401 | |||
| f06b3f7005 | |||
| 008f8514d1 | |||
| e97723fe7c | |||
| 3e85a63006 | |||
| 517d7b1fc3 | |||
| 7faec6987f | |||
| fc13c9a2f3 | |||
| 8d3ce15207 | |||
| b1cf1e6857 | |||
| ffb046b1e8 | |||
| 5142ac9e82 | |||
| c6d5c4a29f | |||
| 8f2777c7bf | |||
| 74a42e9112 | |||
| 55f9e170a4 | |||
| 6484768109 | |||
| 881afd4d93 | |||
| e7a7897e78 | |||
| 04b5ac602b | |||
| d0d73d000e | |||
| 60f109d22e | |||
| 1a3e7b0d63 | |||
| e59e89f787 | |||
| 915bd89914 | |||
| 5c875ee08b | |||
| 8b58311a45 | |||
| 2792a31f7e | |||
| 2613c53226 | |||
| a209c4562e | |||
| 5ba87c6544 | |||
| 8f01867706 | |||
| 0e1761cd53 | |||
| 6c2aec3fa9 | |||
| 4910123b3d | |||
| d7a9c85954 | |||
| c05d698c66 | |||
| 0a69b329b8 | |||
| 502c91e3c4 | |||
| e95865c48e | |||
| a71d71e63f | |||
| 7b43f1391c | |||
| 6430bc9fe3 | |||
| c9ae443d5f | |||
| aa3f803c37 | |||
| 6977c4ccd9 | |||
| d66c3665ee | |||
| 4a532daff3 | |||
| e4cae78b84 | |||
| af7117af28 | |||
| 7aaa583268 | |||
| ad8348166a | |||
| abfe66c888 | |||
| 3c7c795756 | |||
| 4213f05c92 | |||
| fc91208134 | |||
| ed12581bd2 | |||
| 67571f22f6 | |||
| e1b18c8dc1 | |||
| a5cb65f583 | |||
| 3a6210c3a7 | |||
| a9900f5747 | |||
| e1637bffb3 | |||
| 5229e6b576 | |||
| 0f405f933b | |||
| 90565214c3 | |||
| 0f23f2e051 | |||
| 9aaa261651 | |||
| 6cb61bc3a4 | |||
| 66982fc3c8 | |||
| 52b098de60 | |||
| 1cfaaaf75e | |||
| bbcba016fe | |||
| 64d5d4fd77 | |||
| a5ef24c3e6 | |||
| 7c94a35874 | |||
| 59bab4ed5f | |||
| 2912a19ffb | |||
| 02dd2ec720 | |||
| ef2b53f291 | |||
| 82b58ebebc | |||
| 31ca371a97 | |||
| 6bd64554c2 | |||
| 9e0d01cff0 | |||
| ece7403da7 | |||
| 4d30a875ef | |||
| 8e7c1ccd6f | |||
| 18d8519f8e | |||
| c65c18ea69 | |||
| 364dd2a47b | |||
| f7f11abbf3 | |||
| dcfc3203dd | |||
| e437f80330 | |||
| 9024af9c7b | |||
| 4ddb1c615d | |||
| e0f2b6dbe0 | |||
| d81d8e4e2a | |||
| 0f32b08cb8 | |||
| 6fec24e50d | |||
| 1b4b97ced0 | |||
| ce315e90a5 | |||
| b7701994a4 | |||
| 410cce25eb | |||
| e38fd6da6f | |||
| 0a21fc26bf | |||
| 8900908632 | |||
| 1732b20210 | |||
| 7fdb10d2fc | |||
| 0853fde213 | |||
| 3a4efa2e88 | |||
| 048e8bacce | |||
| 96ec1fee8c | |||
| e4dcdcc3b3 | |||
| 0ab43b0950 | |||
| dd3e672668 | |||
| 6ea2cda987 | |||
| 21b9c8ddc8 | |||
| 9d961f88ef | |||
| 38a7c9458b | |||
| 7a72226cb2 | |||
| 2dec3b7fd7 | |||
| ee19dddded | |||
| 2aa1ed8ba8 | |||
| d382204501 | |||
| 1f2f0017ac | |||
| 26b53449aa | |||
| 7cf5363108 | |||
| b9ead554d0 | |||
| d3ac0e1b0d | |||
| 497e92219c | |||
| 425141198c | |||
| b4056d6580 | |||
| 84b82b6923 | |||
| 3cba26c9ae | |||
| 4823550169 | |||
| f9d5552f8a | |||
| ba571b1ef1 | |||
| 102abf2648 | |||
| 8833ded20f | |||
| 18d8e2cdff | |||
| 314f3b6679 | |||
| 3df446fe8e | |||
| bdfb6c3aec | |||
| 4a2a3e6023 | |||
| 1d3354282f | |||
| b8fdf1077a | |||
| 7cbb518aae | |||
| c3b3c58a28 | |||
| 1769d5094e | |||
| b8721a1a8c | |||
| a241ca48f0 | |||
| ee90ebd09f | |||
| 2adff72160 | |||
| 72eeb87937 | |||
| 7df587e6ad | |||
| 903cc387a6 | |||
| 4ab8719c50 | |||
| 2a3901cc38 | |||
| c2390cfe2f | |||
| 0720bbb09e | |||
| fe33b511de | |||
| 570fdf6494 | |||
| 3f75d311e8 | |||
| 68293b2f36 | |||
| 9f6c746d7e | |||
| 2e9e34d69e | |||
| 88e2456c00 | |||
| 1e96a3ab80 | |||
| 19468c3577 | |||
| 901b531c8a | |||
| 0e03c1ee44 | |||
| 00f6179838 | |||
| 7820b3b70e | |||
| 6aa580cea0 | |||
| 9f62c35d5b | |||
| b46698b166 | |||
| 77296a745c | |||
| c64f78be4a | |||
| 07414d4e8a | |||
| e8c3a2eec5 | |||
| 9fcd64dcce | |||
| b65f895234 | |||
| e4851a5bc8 | |||
| 512f3adff4 | |||
| 8c54fbe98e | |||
| 2f325e4557 | |||
| ddd4b8f0ad | |||
| efc3b54774 | |||
| 4e11da80ac | |||
| d4bc0e46bc | |||
| acdefd6a86 | |||
| fc54dc1595 | |||
| c6a5a52003 | |||
| ace77db192 | |||
| dc394917dd | |||
| 7745acb46e | |||
| 569efca5f1 | |||
| 1d6350abad | |||
| d023d4d16a | |||
| 89bdfcbea7 | |||
| c71112f500 | |||
| ecad4bf462 | |||
| 37ddc70929 | |||
| 5cca092842 | |||
| 074d1b438b | |||
| 19b3be94d4 | |||
| 0d4bb047c6 | |||
| 8c85bda12a | |||
| 81d53ed746 | |||
| 562bca06cb | |||
| 419e2efd39 | |||
| 8512254b6c | |||
| dd8fee1544 | |||
| 9527967eb7 | |||
| cc8ff64199 | |||
| d689a11f07 | |||
| a94fdcd91c | |||
| 6fe40f1fd5 | |||
| c6a8d257a7 | |||
| 2d58891978 | |||
| 6cd8597aea | |||
| 7b3cea4c1b | |||
| a34220248b | |||
| c37e1187b7 | |||
| 98b34a632c | |||
| 13faa91944 | |||
| 218e472e17 | |||
| d71c92f784 | |||
| db4ec908e8 | |||
| a21ea5f5de | |||
| bb490cc1d9 | |||
| 6fa381d950 | |||
| 4eba69fa2f | |||
| a2f8b2b110 | |||
| 87828f160b | |||
| aa0b318d7f | |||
| 978c0380a9 | |||
| 4be86aea47 | |||
| 09032933e9 | |||
| e79bbd3b03 | |||
| 6d0186d562 | |||
| ea8087dcc4 | |||
| eb7cbaeab8 | |||
| f17be7c6fb | |||
| 339320f090 | |||
| 4531ed2e3f | |||
| a7e50d42cb | |||
| ff3cfd0f12 | |||
| 3f841b7037 | |||
| 6fe606ebf3 | |||
| f02e25f7ba | |||
| cae31d838f | |||
| 83a473375a | |||
| b4801adcbf | |||
| fdfa9ffa2a | |||
| 1ef18587e3 | |||
| 3e3603a0cf | |||
| 9c51cfc8f6 | |||
| 5c2545f1d5 | |||
| 6a84fe0b2f | |||
| 5a3ac61cfe | |||
| 73715eab13 | |||
| f827083935 | |||
| ef3c214738 | |||
| 4d301b2df0 | |||
| d0403bfa94 | |||
| e4e8b8f532 | |||
| 893013d81e | |||
| 6295d04d22 | |||
| 90ef560f9e | |||
| 0527e13e6c | |||
| 096e6ed4be | |||
| 58de5eec00 | |||
| 73a5a03295 | |||
| c4c4e4dd2c | |||
| 0886550ac7 | |||
| d68a35bae7 | |||
| 2292aacf83 | |||
| c153863808 | |||
| 59b4477e77 | |||
| e8ff9c3e7d | |||
| 9e26d2ee6d | |||
| 2b2d1d5db1 | |||
| 7e9510b55a | |||
| 3944e119d5 | |||
| b2bd5d5e20 | |||
| c93753a9c6 | |||
| 6e7c76f127 | |||
| c0408388fb | |||
| 0f9c622417 | |||
| a05f1391e9 | |||
| 968f19556c | |||
| 22f60d730e | |||
| 3c437c979d | |||
| ca8df714c6 | |||
| 975f47e02e | |||
| 9f98902a90 | |||
| 83869a9ee1 | |||
| 6a2c45d33a | |||
| 26a9c16005 | |||
| 2849260b88 | |||
| 7375808a61 | |||
| c71b1a5a68 | |||
| 33502f0480 | |||
| 68e2b24cc1 | |||
| 123e03aec2 | |||
| cf68aaab06 | |||
| b666d78720 | |||
| 37f485c922 | |||
| 2f771889fb | |||
| 59afbf4e42 | |||
| 9872a8d9ef | |||
| 8c993bd4b9 | |||
| f5a0403207 | |||
| c0df74aede | |||
| f5516a4aef | |||
| 051d9aa994 | |||
| a2e71f6ceb | |||
| 0a123912de | |||
| 8df27eaee9 | |||
| d44e59b0d5 | |||
| 34fa1f7421 | |||
| 0868ef694e | |||
| 89ef614a6b | |||
| 062755729b | |||
| b2769ff1fd | |||
| 9797bc1c14 | |||
| 7b779cf0e3 | |||
| 09451511c1 | |||
| c363adc181 | |||
| aa43c5c8a5 | |||
| 1f1c066e07 | |||
| 8d644dfa28 | |||
| fbe23700ab | |||
| 82b583ae69 | |||
| 0648967e3e | |||
| 4d87a1f415 | |||
| 7215f04eae | |||
| 6c7f0e8bcc | |||
| 054568b9b4 | |||
| ded72f92de | |||
| ebc7be87ff | |||
| c5f60b04ad | |||
| 2b72af0ab6 | |||
| 73b808d46a | |||
| 9d80468b4d | |||
| 7e86f29f70 | |||
| 98a17099e8 | |||
| 0e3e1c4ab7 | |||
| 7854930bd6 | |||
| dfba197a6b | |||
| c2c18e4ca2 | |||
| c83bf23bb7 | |||
| 885c346cae | |||
| e0ad4de223 | |||
| 2e311b6480 | |||
| 6f057f16e2 | |||
| b01f76aa23 | |||
| f6a58da662 | |||
| 3861a9d8eb | |||
| 5b433edad0 | |||
| e8119f251e | |||
| f6c6cbd4be | |||
| dde8bdf7cf | |||
| ad0a55005e | |||
| a2da1dc7a1 | |||
| 5be09e1102 | |||
| 0bcb302eb0 | |||
| 95c31eb071 | |||
| 24369dad05 | |||
| 0d0d81d0fd | |||
| dfaaecefda | |||
| abf90b64b5 | |||
| 1912ad0b34 | |||
| e32243c759 | |||
| 8a75765281 | |||
| 17b46f9faf | |||
| 4d25bab3e6 | |||
| 2435418f85 | |||
| 5284249ce7 | |||
| bd23fbc194 | |||
| 394eb21baa | |||
| c74f2f4bc3 | |||
| ba759f18b8 | |||
| 7b3fd334bd | |||
| f62842870e | |||
| 691fd19974 | |||
| b12972b2e4 | |||
| 7c2a704d7e | |||
| 0535339d2c | |||
| dcabf34c65 | |||
| 797d0ac06c | |||
| 2b9f69dc2d | |||
| 18465f2347 | |||
| f3777c684d | |||
| e3ec0cb80f | |||
| 9803e7200c | |||
| 314ce2e563 | |||
| fc54a5aae5 | |||
| 634f0f8a63 | |||
| e864c7cd55 | |||
| 8549f8b118 | |||
| edbf38f703 | |||
| fbe7d535f4 | |||
| 37b34dbb1d | |||
| 861a490b21 | |||
| f921cd394c | |||
| 85c501d61e | |||
| 4c17afa487 | |||
| e66a016281 | |||
| 9e57c38984 | |||
| 442fcae3d5 | |||
| af7ff557e1 | |||
| 61717c03ce | |||
| ff191e8acf | |||
| 27accaf5e6 | |||
| 90728cc7e8 | |||
| b3e56a148f | |||
| 9b5d44a8fa | |||
| 891e13ece2 | |||
| f1a39d07c3 | |||
| 8c7285244f | |||
| 347c863ff1 | |||
| 242368cb66 | |||
| b3bd5f4785 | |||
| d7e7d8251d | |||
| 158224425d | |||
| caf355f307 | |||
| ff6dfc11b4 | |||
| 810f938471 | |||
| da757ed1a0 | |||
| b966e27ba3 | |||
| 32e3e08705 | |||
| 101df1a587 | |||
| 85715981e9 | |||
| e67cb7741b | |||
| a67410ffc4 | |||
| 131feb3f33 | |||
| ede1838d25 | |||
| 8f46a593b4 | |||
| e3ea99a562 | |||
| 7d214ce66f | |||
| 7ee516df9b | |||
| 9d3882e054 | |||
| a1173346db | |||
| 0c69977419 | |||
| 35199e1d3e | |||
| d952eba50c | |||
| 774ee284c6 | |||
| ea60e496ab | |||
| 754854ef71 | |||
| c5fe7da9ec | |||
| 420087ea5b | |||
| 414f716108 | |||
| b01f281902 | |||
| 97b274c067 | |||
| 4c77a7428e | |||
| 3e02649eae | |||
| 91700bd5b2 | |||
| a0cf06cdb7 | |||
| f6aa5abb18 | |||
| 21338e0ca4 | |||
| ec39d26900 | |||
| d8ee1f1723 | |||
| 67b635adac | |||
| bb4d87423a | |||
| b42980c915 | |||
| 3ef3f64a49 | |||
| aba6693aac | |||
| e9427de276 | |||
| 8ce0739586 | |||
| b34e4cf50b | |||
| d96cd37ced | |||
| d589fc83ee | |||
| 2c01ee379e | |||
| b545ab4046 | |||
| e6ae844e0f | |||
| e75f585e8d | |||
| 0d17ab4e7e | |||
| 0a16a09b4d | |||
| abafc5f6f0 | |||
| 3e9e6daca8 | |||
| 1ea1d0f328 | |||
| ae5bb1806a | |||
| 72204ea545 | |||
| 2af93cef7a | |||
| 80d68abc92 | |||
| 173966414d | |||
| 2af8745ba6 | |||
| 1387e67666 | |||
| f5c52828aa | |||
| 3e9ad055fd | |||
| 4e0f1b93ef | |||
| 392f1ca74a | |||
| 4f5672ed2b | |||
| 3f09d22d57 | |||
| 98a175801d | |||
| 2d599725ea | |||
| ea01861142 | |||
| 8fbf9d5965 | |||
| 6aa7352124 | |||
| d6d18dba5a | |||
| 70e4fe4049 | |||
| 852c112973 | |||
| e643ddd0ac | |||
| feee342fa3 | |||
| ae22901fc8 | |||
| 259e9f73f7 | |||
| 78216c5e05 | |||
| 06be826264 | |||
| 9cce46069b | |||
| bcbd3184ac | |||
| 057941f5d2 | |||
| 489c9451c2 | |||
| c7ee0aeb72 | |||
| a33ee69fb7 | |||
| f3f41999bc | |||
| 853dec0695 | |||
| 1500330b69 | |||
| 99a7272f9d | |||
| 9d8654aa06 | |||
| b7a1a09fc3 | |||
| 65a062a479 | |||
| 7a3d3e7653 | |||
| 62a44abed3 | |||
| 6cf1bed3ad | |||
| b21d7a85c0 | |||
| 56308369c3 | |||
| a9f4afd9b8 | |||
| ab375e73b2 | |||
| b937113cb8 | |||
| a073ef4c8c | |||
| 595ac13128 | |||
| 8f1f63e2dd | |||
| 402461582b | |||
| 0eab7e37e9 | |||
| 2fa5e67836 | |||
| c6bf45ca89 | |||
| 9556cb46c3 | |||
| 430dc3657e | |||
| 69a2fd460a | |||
| abf708daec | |||
| 21116ab4ce | |||
| cb26d4416b | |||
| 541ed68c74 | |||
| 0901ff1f4e | |||
| 68ec7c3a4b | |||
| 3148930da0 | |||
| ec8785a398 | |||
| 9b5f9a2cdb | |||
| ced3fb3883 | |||
| fd9a0f2015 | |||
| 99f36d3050 | |||
| 9de29ed2b0 | |||
| 40ed01c744 | |||
| 56a87f8f80 | |||
| b72e02acb7 | |||
| 4220b7974c | |||
| 48047d1ce6 | |||
| 6b358c865a | |||
| 6b9a3e506a | |||
| 92d4fa63a0 | |||
| 7f7bb16b45 | |||
| c2c10edf51 | |||
| 48522742f3 | |||
| 549b8b70dd | |||
| e3e9c49e64 | |||
| aa743bed88 | |||
| e8956b2a95 | |||
| 4653dee6a0 | |||
| 61cd1cecce | |||
| 22b7b6958a | |||
| 3bdfdf0d46 | |||
| cc21346534 | |||
| 01852ee24b | |||
| a5cac847f4 | |||
| ec27c99cfb | |||
| bdbfbd88cc | |||
| 04af589356 | |||
| 7da0a39ff8 | |||
| 60599f35b4 | |||
| 8207462b0e | |||
| fcc7f3e1ec | |||
| 5862b5d56e | |||
| 15d6f61c7a | |||
| 6c27f94b1c | |||
| 3729953305 | |||
| 3a06afca13 | |||
| 49a4e1fd0d | |||
| 38c098ed26 | |||
| f31fd88707 | |||
| 01af2420bd | |||
| 1371072424 | |||
| f44c5de258 | |||
| fb97286ee8 | |||
| d22325b465 | |||
| f952cd1bbe | |||
| 5dfc29d1c2 | |||
| 16af997cff | |||
| f1672122c3 | |||
| 18b817e10c | |||
| b206db73f1 | |||
| a10b54b46f | |||
| 249dfe8af8 | |||
| 7f87917ce3 | |||
| 24e3b79e73 | |||
| d2d8f8bd38 | |||
| 4819c16d6c | |||
| 711ed0b5af | |||
| d3f978adb0 | |||
| f555d21e00 | |||
| 51403c9634 | |||
| 53bb746b5c | |||
| 7d48c765c6 | |||
| a7ac574a1f | |||
| b9bb24dc7d | |||
| 859726965c | |||
| 81b9692a70 | |||
| 49f85e8430 | |||
| 06579199e8 | |||
| a8a4c49dfb | |||
| 266b7fd85d | |||
| 12b389be3d | |||
| fee914ac18 | |||
| 168f8e0f7c | |||
| 491ae275d2 | |||
| 7517e1e040 | |||
| 70f2fa8a17 | |||
| 19935ed495 | |||
| 190fe1079d | |||
| 33bc139883 | |||
| 4197c0f93d | |||
| 3b49a1288d | |||
| 0ce9836241 | |||
| a496371f87 | |||
| fce34e5be1 | |||
| 84e87bb4b2 | |||
| 4725ca375b | |||
| f16a2068be | |||
| 4c5ec09b6a | |||
| c3bd7dca0c | |||
| edcf658880 | |||
| 57f9ae0fb2 | |||
| 5f1ced18d2 | |||
| a9dac24b42 | |||
| c33695c947 | |||
| 31346be087 | |||
| f9e50f0ae9 | |||
| 5134c49afa | |||
| 6a60613825 | |||
| 3c5c855d45 | |||
| 93620c8eaf | |||
| 68f13722d8 | |||
| 16c48c43a5 | |||
| edb0f93909 | |||
| 84b45bd536 | |||
| f46a9256d7 | |||
| 042ee32b5a | |||
| 27bb73976f | |||
| 6ad3443e50 | |||
| e8134cab2b | |||
| b06d1d9983 | |||
| 54c97c25d1 | |||
| 953eb288b7 | |||
| ee2a634b6b | |||
| 97657301f9 | |||
| fb0efb504a | |||
| 0e266b1e92 | |||
| 453646d286 | |||
| b8b5900be3 | |||
| 3c6fa4853c | |||
| 5d76ac6474 | |||
| 9fdaab37d2 | |||
| 6ebab7c0e5 | |||
| f35e8fb165 | |||
| 42f7e9664c | |||
| 313b49704e | |||
| 176a680500 | |||
| 16c4b8d14d | |||
| fe06be7349 | |||
| d1e3b007bc | |||
| ef136fa74c | |||
| 1e3b3cdf46 | |||
| 7521b3ffea | |||
| 7a44696d42 | |||
| 9cda33cc7b | |||
| 83c59ecb2a | |||
| d397d8e8f2 | |||
| cf79d5873a | |||
| decae588d2 | |||
| 5b40aed1e1 | |||
| 759662d7ef | |||
| 7d2e8a0b1c | |||
| 0a1398e79a | |||
| cbeea9b429 | |||
| 537439e700 | |||
| ce8397a4a5 | |||
| 83ee389916 | |||
| 6c0e4ff515 | |||
| 05752fa367 | |||
| 78e1a79a4a | |||
| ff7fa4aeb7 | |||
| 9c44b6d3b8 | |||
| b4419993f5 | |||
| 14171ceb1f | |||
| bcbf880677 | |||
| ff770c6f1f | |||
| fde9baf901 | |||
| 6eadabbf91 | |||
| 3a3f48963a | |||
| 2c49931b8e | |||
| 90bc4f3571 | |||
| 8e89e8cb7c | |||
| 4604ea2951 | |||
| 317bebe9af | |||
| cfe6e6a52c | |||
| 4989384544 | |||
| 7dd72f0760 | |||
| 557890d3d9 | |||
| 2e2d4441cf | |||
| a9bed67d10 | |||
| 410bc5a397 | |||
| 893bb38cba | |||
| 40f201d751 | |||
| d1506a8ea2 | |||
| dc9303c1cf | |||
| 6e83d9dd18 | |||
| b17ece2864 | |||
| 2060cffb67 | |||
| 50b15abbff | |||
| bb1f8b9fb6 | |||
| cc16df6c8c | |||
| f6c3bbd653 | |||
| 20721196bf | |||
| 6530b27e0e | |||
| 114a376feb | |||
| b7c54f77a3 | |||
| 0383550847 | |||
| 09a6828e79 | |||
| d504a1e2ed | |||
| 164169dd9f | |||
| 8486a66ba6 | |||
| cc8cc2a830 | |||
| 069e5d30ba | |||
| 04c56a2af3 | |||
| 0a88645b04 | |||
| f23f3c1bc0 | |||
| 300fea9dfe | |||
| e84e585d52 | |||
| fefcf2fc0a | |||
| f842409325 | |||
| ec96c1c4d7 | |||
| 61e2c0bd4b | |||
| afb1779083 | |||
| f132b27720 | |||
| 4c395752be | |||
| 2bd26027e0 | |||
| e023b6214e | |||
| 54c51b246a | |||
| f13ee85209 | |||
| aad5764eff | |||
| 45ba0b09f6 | |||
| a92b39ad18 | |||
| ad6457e9ab | |||
| 7d9141ec93 | |||
| b52a95d714 | |||
| 0d990272c5 | |||
| 9418fa5139 | |||
| b37c4fc563 | |||
| feca1a0515 | |||
| 3e91ccd89c | |||
| 993c46eade | |||
| 4d796d74f3 | |||
| 2eaba62836 | |||
| 1c5d3203ef | |||
| 80914e5c44 | |||
| d61bddcde1 | |||
| da46528b59 | |||
| 45be53a4d4 | |||
| ff8282e81d | |||
| ffa7a068d9 | |||
| 22fa195fa6 | |||
| 893a25d5f0 | |||
| d3442d01f7 | |||
| d411d8075f | |||
| 4c51c907dc | |||
| 5bb64a4deb | |||
| 520a1faa31 | |||
| 756b3ebda6 | |||
| 797dafcf30 | |||
| a0c272d315 | |||
| 3562c7fb6f | |||
| 4df28a63d8 | |||
| 07e71d6752 | |||
| ac5a5738e8 | |||
| 0521513d86 | |||
| a3f7cb81e4 | |||
| e3c36324bd | |||
| f2053c88d2 | |||
| 5d5f0cb149 | |||
| 697cc3c165 | |||
| 3b5a288e3e | |||
| 8616fe455d | |||
| 946b4b3f9a | |||
| f7244a79e0 | |||
| 42044ee625 | |||
| 20246378bc | |||
| 222000638e | |||
| 2a4a1f61e3 | |||
| b2083cf40b | |||
| f29e081814 | |||
| 334a3b66e8 | |||
| 5268d94a99 | |||
| c39fbf8748 | |||
| 849832b67e | |||
| f5455a89b3 | |||
| 36dd4ec638 | |||
| 550b764fd9 | |||
| 86a354a78b | |||
| 8f5f573bc3 | |||
| 182db4f70c | |||
| 4dca468612 | |||
| 526fe93ff9 | |||
| 35f3889338 | |||
| c157c29f5c | |||
| 5edae07650 | |||
| a99e6fc1b4 | |||
| 4c267de0e4 | |||
| 4d653b703f | |||
| 53a3d87168 | |||
| 642f2f8ec4 | |||
| 18104fb4b0 | |||
| a09225a1a6 | |||
| 037c3bfaa5 | |||
| db47f300c8 | |||
| 33e81bc427 | |||
| 0fcb3d7f2d | |||
| 027c9e3f50 | |||
| a42378c39a | |||
| 420d0d8a7c | |||
| b88a3b6872 | |||
| 1895c1b2a5 | |||
| 086b343e71 | |||
| c1f5673794 | |||
| b733d3acb2 | |||
| 9ddf17ab0c | |||
| 2f4e291dac | |||
| fff28b0213 | |||
| 88879a45fe | |||
| 34084f16db | |||
| 9857ed328d | |||
| b149af2958 | |||
| c237a1bdb6 | |||
| 6695045cb5 | |||
| d2feb5351e | |||
| 65053e455d | |||
| d417b90429 | |||
| 77e74d9468 | |||
| c6d2921a4b | |||
| 98c7f33ca9 | |||
| 2ea7d0751f | |||
| 9eb1f408a0 | |||
| cd1d67aab5 | |||
| cbf483d729 | |||
| 2503cb5cb2 | |||
| aaab9f4c25 | |||
| eedc072e6b | |||
| 25466a79f0 | |||
| fb5f5dcf6d | |||
| b8e15e9fa4 | |||
| 3dbec4e474 | |||
| e4bf004c74 | |||
| fe02c66cc0 | |||
| c685201ebc | |||
| f254e53fec | |||
| 34104a963d | |||
| 2e9c90806b | |||
| dcc78f63f2 | |||
| 8c86049d95 | |||
| 7ecf62a0f2 | |||
| 232aa15473 | |||
| 707aab566d | |||
| ddcdb921f1 | |||
| bfcb654518 | |||
| 10651af917 | |||
| 395a885b21 | |||
| 676c0d1a70 | |||
| b9544548fa | |||
| b3d9de06ef | |||
| 5e1d666f70 | |||
| 0a7da9c3a2 | |||
| 17a417b4fc | |||
| 58c064b75d | |||
| 0f34bd79cd | |||
| aa89495c93 | |||
| 4e8975525b | |||
| 554ddca615 | |||
| d726e16147 | |||
| 70deb4496c | |||
| 219f4b148f | |||
| 735551e746 | |||
| 1607316f9b | |||
| d74fc035f7 | |||
| 66f43de15b | |||
| ce71f4712d | |||
| 2d39988b4d | |||
| 5cb0779797 | |||
| 8de49f8921 | |||
| 4a5a8fff6e | |||
| fa7e74a876 | |||
| 649ee42595 | |||
| dcdb5d7213 | |||
| dbd6a29c10 | |||
| 4664203cda | |||
| d1e79774fe | |||
| 1351d8c4ce | |||
| 85324279a7 | |||
| 185feb3b63 | |||
| ffddf40f5a | |||
| 840f529f28 | |||
| dca8f0b136 | |||
| 14c142f736 | |||
| ea142ba03b | |||
| 50724ae928 | |||
| b8813426db | |||
| 5a68c9cddc | |||
| 9cca223d82 | |||
| bed8aa6278 | |||
| 1f1afde634 | |||
| 1b96a3d1d0 | |||
| a2f4f5aff4 | |||
| 329551610e | |||
| d83bab6465 | |||
| e5d03a6ab5 | |||
| d57af17c37 | |||
| c45eea33b8 | |||
| d47730580e | |||
| 859e7c5d19 | |||
| febce03328 | |||
| 7b4a270078 | |||
| b96c768ca3 | |||
| da11c2dda0 | |||
| b2267c22dd | |||
| 7b3621d0cc | |||
| d9b8121114 | |||
| 794854bb5b | |||
| f42504d49f | |||
| 1630708714 | |||
| b4f879db7c | |||
| 641453858c | |||
| 5573c4a9cf | |||
| 4fac6ce2bd | |||
| 48e421f389 | |||
| 8205ed17f4 | |||
| 68924222ef | |||
| 37a5718793 | |||
| 8c2bbd9b19 | |||
| 2e85053a7f | |||
| d0b6c20935 | |||
| 4a7479ace0 | |||
| 993395ba78 | |||
| 01d5c30776 | |||
| 70624b3630 | |||
| 78623e11a3 | |||
| 29723746cc | |||
|
|
7ae6e5797c | ||
|
|
8e9d248ce0 | ||
| ed73e0a429 | |||
| eade3121a4 | |||
| 2feaaf5415 | |||
| 521286e247 | |||
| ac16063f84 | |||
| 692e40e5d6 | |||
| 77305ade9a | |||
| 7056046c82 | |||
| 1f4828eb40 | |||
| 6bb57661c7 | |||
| 97be57f6aa | |||
| 403e8b7fa8 | |||
| 3552ba0b2b | |||
| d69711059f | |||
| 085e993301 | |||
| 4438836115 | |||
| 16e17fdcc9 | |||
| f1a3514fbd |
0
config/backups.yaml
Normal file
0
config/media.yaml
Normal file
30
config/plugins/git-sync.yaml
Normal file
@ -0,0 +1,30 @@
|
||||
enabled: true
|
||||
folders:
|
||||
- pages
|
||||
- themes
|
||||
- config
|
||||
sync:
|
||||
on_save: true
|
||||
on_delete: true
|
||||
on_media: true
|
||||
cron_enable: false
|
||||
cron_at: '0 12,23 * * *'
|
||||
local_repository: null
|
||||
repository: 'git@git.kemt.fei.tuke.sk:KEMT/zpwiki.git'
|
||||
no_user: '0'
|
||||
user: zpwikiuser
|
||||
password: gitsync-def502001df1df627230ddf8dbdcf2e009a33ef7eb2378430c12aabb4de1dc42d30c522473512dbeccab4782d87d16488303c5062a05a4fc155fa5379268f878650d714188f5614a7bf10a8d465410f276913bd9c28cda221a8deab71c6701fb
|
||||
webhook: /_git-sync-9ad6430986a6
|
||||
webhook_enabled: '0'
|
||||
webhook_secret: 58488c5ff4bad574a21fc3f34b71d275ffbdaa0b1cdcafe4
|
||||
branch: master
|
||||
remote:
|
||||
name: origin
|
||||
branch: master
|
||||
git:
|
||||
author: gravuser
|
||||
message: '(Grav GitSync) Automatic Commit'
|
||||
name: GitSync
|
||||
email: git-sync@trilby.media
|
||||
bin: git
|
||||
logging: false
|
||||
4
config/plugins/page-toc.yaml
Normal file
@ -0,0 +1,4 @@
|
||||
enabled: true
|
||||
active: true
|
||||
start: '1'
|
||||
depth: '6'
|
||||
0
config/scheduler.yaml
Normal file
1
config/security.yaml
Normal file
@ -0,0 +1 @@
|
||||
salt: xZBMvDjawspOYb
|
||||
20
config/site.yaml
Normal file
@ -0,0 +1,20 @@
|
||||
title: 'Záverečné práce'
|
||||
default_lang: en
|
||||
author:
|
||||
name: 'Joe Bloggs'
|
||||
email: joe@example.com
|
||||
taxonomies:
|
||||
- category
|
||||
- tag
|
||||
- author
|
||||
metadata:
|
||||
description: 'Grav is an easy to use, yet powerful, open source flat-file CMS'
|
||||
summary:
|
||||
enabled: true
|
||||
format: short
|
||||
size: 300
|
||||
delimiter: '==='
|
||||
redirects: null
|
||||
routes: null
|
||||
blog:
|
||||
route: /blog
|
||||
0
config/streams.yaml
Normal file
179
config/system.yaml
Normal file
@ -0,0 +1,179 @@
|
||||
absolute_urls: false
|
||||
timezone: ''
|
||||
default_locale: null
|
||||
param_sep: ':'
|
||||
wrapped_site: false
|
||||
reverse_proxy_setup: false
|
||||
force_ssl: false
|
||||
force_lowercase_urls: true
|
||||
custom_base_url: ''
|
||||
username_regex: '^[a-z0-9_-]{3,16}$'
|
||||
pwd_regex: '(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,}'
|
||||
intl_enabled: true
|
||||
http_x_forwarded:
|
||||
protocol: true
|
||||
host: false
|
||||
port: true
|
||||
ip: true
|
||||
languages:
|
||||
supported: { }
|
||||
default_lang: null
|
||||
include_default_lang: true
|
||||
pages_fallback_only: false
|
||||
translations: true
|
||||
translations_fallback: true
|
||||
session_store_active: false
|
||||
http_accept_language: false
|
||||
override_locale: false
|
||||
home:
|
||||
alias: /home
|
||||
hide_in_urls: false
|
||||
pages:
|
||||
theme: mytheme
|
||||
order:
|
||||
by: default
|
||||
dir: asc
|
||||
list:
|
||||
count: 20
|
||||
dateformat:
|
||||
default: null
|
||||
short: 'jS M Y'
|
||||
long: 'F jS \a\t g:ia'
|
||||
publish_dates: true
|
||||
process:
|
||||
markdown: true
|
||||
twig: false
|
||||
twig_first: false
|
||||
never_cache_twig: false
|
||||
events:
|
||||
page: true
|
||||
twig: true
|
||||
markdown:
|
||||
extra: false
|
||||
auto_line_breaks: false
|
||||
auto_url_links: false
|
||||
escape_markup: false
|
||||
special_chars:
|
||||
'>': gt
|
||||
'<': lt
|
||||
valid_link_attributes:
|
||||
- rel
|
||||
- target
|
||||
- id
|
||||
- class
|
||||
- classes
|
||||
types:
|
||||
- html
|
||||
- htm
|
||||
- xml
|
||||
- txt
|
||||
- json
|
||||
- rss
|
||||
- atom
|
||||
append_url_extension: ''
|
||||
expires: 604800
|
||||
cache_control: null
|
||||
last_modified: false
|
||||
etag: false
|
||||
vary_accept_encoding: false
|
||||
redirect_default_route: false
|
||||
redirect_default_code: 302
|
||||
redirect_trailing_slash: true
|
||||
ignore_files:
|
||||
- .DS_Store
|
||||
ignore_folders:
|
||||
- .git
|
||||
- .idea
|
||||
ignore_hidden: true
|
||||
hide_empty_folders: false
|
||||
url_taxonomy_filters: true
|
||||
frontmatter:
|
||||
process_twig: false
|
||||
ignore_fields:
|
||||
- form
|
||||
- forms
|
||||
cache:
|
||||
enabled: true
|
||||
check:
|
||||
method: file
|
||||
driver: auto
|
||||
prefix: g
|
||||
purge_at: '0 4 * * *'
|
||||
clear_at: '0 3 * * *'
|
||||
clear_job_type: standard
|
||||
clear_images_by_default: true
|
||||
cli_compatibility: false
|
||||
lifetime: 604800
|
||||
gzip: false
|
||||
allow_webserver_gzip: false
|
||||
redis:
|
||||
socket: false
|
||||
twig:
|
||||
cache: true
|
||||
debug: true
|
||||
auto_reload: true
|
||||
autoescape: false
|
||||
undefined_functions: true
|
||||
undefined_filters: true
|
||||
umask_fix: false
|
||||
assets:
|
||||
css_pipeline: false
|
||||
css_pipeline_include_externals: true
|
||||
css_pipeline_before_excludes: true
|
||||
css_minify: true
|
||||
css_minify_windows: false
|
||||
css_rewrite: true
|
||||
js_pipeline: false
|
||||
js_pipeline_include_externals: true
|
||||
js_pipeline_before_excludes: true
|
||||
js_minify: true
|
||||
enable_asset_timestamp: false
|
||||
collections:
|
||||
jquery: 'system://assets/jquery/jquery-2.x.min.js'
|
||||
errors:
|
||||
display: true
|
||||
log: true
|
||||
log:
|
||||
handler: file
|
||||
syslog:
|
||||
facility: local6
|
||||
debugger:
|
||||
enabled: false
|
||||
shutdown:
|
||||
close_connection: true
|
||||
twig: true
|
||||
images:
|
||||
default_image_quality: 85
|
||||
cache_all: false
|
||||
cache_perms: '0755'
|
||||
debug: false
|
||||
auto_fix_orientation: false
|
||||
seofriendly: false
|
||||
media:
|
||||
enable_media_timestamp: false
|
||||
unsupported_inline_types: { }
|
||||
allowed_fallback_types: { }
|
||||
auto_metadata_exif: false
|
||||
upload_limit: 2097152
|
||||
session:
|
||||
enabled: true
|
||||
initialize: true
|
||||
timeout: 1800
|
||||
name: grav-site
|
||||
uniqueness: path
|
||||
secure: false
|
||||
httponly: true
|
||||
split: true
|
||||
path: null
|
||||
gpm:
|
||||
releases: stable
|
||||
proxy_url: null
|
||||
method: auto
|
||||
verify_peer: true
|
||||
official_gpm_only: true
|
||||
accounts:
|
||||
type: data
|
||||
storage: file
|
||||
strict_mode:
|
||||
yaml_compat: true
|
||||
twig_compat: true
|
||||
13
config/themes/mytheme.yaml
Normal file
@ -0,0 +1,13 @@
|
||||
streams:
|
||||
schemes:
|
||||
theme:
|
||||
type: ReadOnlyStream
|
||||
prefixes:
|
||||
'': [user/themes/mytheme, user/themes/knowledge-base]
|
||||
display_of_git_sync_repo_link: page
|
||||
type_of_git_sync_repo_link: edit
|
||||
custom_git_sync_repo_link_icon: null
|
||||
custom_git_sync_repo_link_text: null
|
||||
git_sync_edit_note_text: null
|
||||
custom_git_sync_repo_presentation_link_text: null
|
||||
git_sync_repo_link: 'https://git.kemt.fei.tuke.sk/KEMT/zpwiki/src/branch/master'
|
||||
112
migrater_skudal.py
Normal file
@ -0,0 +1,112 @@
|
||||
import os
|
||||
import sys
|
||||
import re
|
||||
import posixpath
|
||||
import argparse
|
||||
from pathlib import Path
|
||||
from shutil import copyfile
|
||||
import yaml
|
||||
|
||||
name_reg = re.compile(r"(/[0-9][0-9]\.)+")
|
||||
|
||||
|
||||
def filter_string(string, string_replace='/', regex=name_reg):
|
||||
return re.sub(regex, string_replace, string)
|
||||
|
||||
|
||||
# Input: dirname_from: where you want to migrate from. migrate_rootpath: path including the new root dir of the structure
|
||||
def transform_wiki(dirname_from, migrate_rootpath):
|
||||
|
||||
# New file structure
|
||||
Path(migrate_rootpath).mkdir(parents=True, exist_ok=True)
|
||||
dir_path_new = None
|
||||
|
||||
for root, dirs, files in os.walk('./' + dirname_from, topdown=False):
|
||||
|
||||
# Filter the new names i dst
|
||||
root_src = root
|
||||
root_dst = filter_string(root, '/', name_reg)
|
||||
|
||||
# Make a new regural dirs (without bottom dir which is replaced by .md file)
|
||||
path = '/'.join(root_dst.split('/')[2:-1]) # The path following the root dir (./Pages)
|
||||
dir_path_new = migrate_rootpath + '/' + path
|
||||
Path(dir_path_new).mkdir(parents=True, exist_ok=True)
|
||||
|
||||
for file_name in files:
|
||||
# File path in original structure
|
||||
file_path_scr = root_src + "/" + file_name
|
||||
|
||||
# Test for only altering .md-files
|
||||
if not file_name.endswith(".md"):
|
||||
# Copy other files from scr
|
||||
src = file_path_scr
|
||||
dst = '/'.join([dir_path_new, file_name])
|
||||
copyfile(src, dst)
|
||||
continue
|
||||
|
||||
# Open original file
|
||||
with open(file_path_scr) as f_from:
|
||||
|
||||
try:
|
||||
# New name convention for .md-files migrated to new structure
|
||||
new_filepath = dir_path_new + '/' + os.path.basename(root_dst) + '.md'
|
||||
with open(new_filepath, 'w') as f_to:
|
||||
lines = []
|
||||
yamlfront = []
|
||||
inyamlfront = False
|
||||
for l in f_from:
|
||||
line = l.rstrip()
|
||||
if len(lines) == 0 and line.startswith("---"):
|
||||
inyamlfront = True
|
||||
elif inyamlfront:
|
||||
if line.startswith("---"):
|
||||
inyamlfront = False
|
||||
print(yamlfront)
|
||||
front = yaml.load("\n".join(yamlfront))
|
||||
if "taxonomy" in front:
|
||||
taxonomy = front["taxonomy"]
|
||||
del front["taxonomy"]
|
||||
tags = []
|
||||
if "tags" in taxonomy:
|
||||
tags = taxonomy["tags"]
|
||||
if "categories" in taxonomy:
|
||||
for tag in taxonomy["categories"]:
|
||||
tags.append("cat:" + tag)
|
||||
del taxonomy["categories"]
|
||||
if len(tags) > 0:
|
||||
taxonomy["tags"] = tags
|
||||
for k,v in taxonomy.items():
|
||||
front[k] = v
|
||||
del yamlfront[:]
|
||||
yamlfront.append("---")
|
||||
yamlfront.append(yaml.dump(front))
|
||||
yamlfront.append("---")
|
||||
else:
|
||||
yamlfront.append(line)
|
||||
else:
|
||||
lines.append(line)
|
||||
if len(yamlfront) > 0:
|
||||
for line in yamlfront:
|
||||
print(line,file=f_to)
|
||||
for line in lines:
|
||||
print(line,file=f_to)
|
||||
|
||||
except UnicodeDecodeError:
|
||||
print("UnocodeError in :" + file_path_scr)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
'''
|
||||
path = 'pages_migrated_example/55.usaa/cvicenia/05.linked.md'
|
||||
#path = '05.linked.md'
|
||||
print(path)
|
||||
path = filter_string(path, '/', name_reg)
|
||||
print(path)
|
||||
'''
|
||||
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("dirname", type=str)
|
||||
parser.add_argument("migrate_root",type=str)
|
||||
args = parser.parse_args()
|
||||
transform_wiki(args.dirname, args.migrate_root)
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
---
|
||||
title: Bakalárske práce 2018/2019
|
||||
category: bp2021
|
||||
category: bp2019
|
||||
published: true
|
||||
---
|
||||
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
---
|
||||
title: Bakalárska práca 2020
|
||||
title: Bakalárska práca 2019/2020
|
||||
category: bp2020
|
||||
published: true
|
||||
---
|
||||
|
||||
@ -1,3 +1,7 @@
|
||||
---
|
||||
title: Bakalárske práce 2020/2021
|
||||
category: bp2021
|
||||
---
|
||||
# Bakalárske práce 2021
|
||||
|
||||
## Témy
|
||||
@ -20,3 +24,4 @@
|
||||
|
||||
- natrénovanie modelu QA s databázy SQUAD?
|
||||
- Využitie existujúceho anglického modelu?
|
||||
|
||||
|
||||
76
pages/04.categories/bp2022/category.md
Normal file
@ -0,0 +1,76 @@
|
||||
---
|
||||
title: Bakalárske práce 2021/2022
|
||||
category: bp2022
|
||||
---
|
||||
# Bakalárske práce 2022
|
||||
|
||||
Ak ste študentom 2. alebo 3. ročníka odboru Počítačové siete na KEMT a máte záujem o niektorú z týchto tém, napíšte e-mail na daniel.hladek@tuke.sk.
|
||||
|
||||
Naučíte sa:
|
||||
|
||||
- niečo o spracovaní prirodzeného jazyka
|
||||
- vytvárať webové aplikácie
|
||||
- pracovať s nástrojmi v jazyku Python
|
||||
- prekonávať technické problémy
|
||||
|
||||
Požiadavky:
|
||||
|
||||
- chcieť sa naučiť niečo nové
|
||||
|
||||
## Témy
|
||||
|
||||
### Automatické odpovede z Wikipédie
|
||||
|
||||
1. Vypracujte prehľad aktuálnych metód pre generovanie odpovede na otázku v prirodzenom jazyku
|
||||
2. Natrénujte existujúci systém pre generovanie odpovede na otázku v prirodzenom jazyku.
|
||||
3. Vytvorte demonštračnú webovú aplikáciu.
|
||||
4. Navrhnite zlepšenia systému pre generovanie odpovede.
|
||||
|
||||
- Natrénujte existujúci systém pre generovanie odpovede na otázku v prirodzenom jazyku.
|
||||
- Vytvorte demonštračnú webovú aplikáciu.
|
||||
|
||||
### Strojový preklad slovenského jazyka
|
||||
|
||||
- Zoberte existujúci systém pre strojový preklad.
|
||||
- Pripravte existujúci paralelný korpus pre trénovanie.
|
||||
- Vytvorte model pre strojový preklad slovenského jazyka.
|
||||
|
||||
1. Vypracujte prehľad aktuálnych metód pre generovanie odpovede na otázku v prirodzenom jazyku
|
||||
2. Natrénujte existujúci systém pre generovanie odpovede na otázku v prirodzenom jazyku.
|
||||
3. Vytvorte demonštračnú webovú aplikáciu.
|
||||
4. Navrhnite zlepšenia systému pre generovanie odpovede.
|
||||
|
||||
### Rozpoznávanie pomenovaných entít v slovenskom jazyku
|
||||
|
||||
- Zlepšite model pre rozpoznávanie pomenovaných entít.
|
||||
- Anotujte korpus, navrhnite lepší klasifikátor.
|
||||
|
||||
Pomenované entity sú väčšinou vlastné podstatné mená v texte. Ich rozpoznanie nám pomôže určiť o čom text je. To sa často využíva v chatbotoch alebo vo vyhľadávaní v texte.
|
||||
|
||||
1. Vypracujte prehľad metód rpre rozpoznávanie pomenovaných entít v texte.
|
||||
2. Vyberte vhodnú metódu a natrénujte model pre rozpoznávanie pomenovaných entít.
|
||||
3. Vykonajte viacero experimentov a zistite s akými parametrami má model najvyššiu presnosť.
|
||||
4. Navrhnite ďalšie zlepšenia modelu pre rozpoznávanie pomenovaných entít.
|
||||
|
||||
### Vyhľadávač na slovenskom internete
|
||||
|
||||
Databáza dokumentov je k dispozícii. Na vytvorenie indexu je možné použiť Elasticsearch alebo podobný systém.
|
||||
Dokument je potrebné spracovať pomocou skriptu v jazyku Python alebo Javascript.
|
||||
|
||||
- Vytvorte index pre vyhľadávanie v databáze slovenských stránok (Cassandra, Elasticseaech).
|
||||
- Vytvorte webové rozhranie k vyhľadávaču.
|
||||
|
||||
1. Vypracujte prehľad metód pre získavanie informácií.
|
||||
2. Vytvorte vyhľadávací index dokumentov zo slovenského internetu.
|
||||
3. Vytvorte demonštračnú webovú aplikáciu pre vyhľadávanie na slovenskom internete.
|
||||
4. Navrhnite zlepšenia vyhľadávania.
|
||||
|
||||
### Model Spacy pre spracovanie prirodzeného jazyka
|
||||
|
||||
Knižnica Spacy je často používaný nástroj na spracovanie prirodzeného jazyka.
|
||||
Dobrý model slovenčiny pomože pri vývoji virtuálnych asistentov a iných nástrojov.
|
||||
|
||||
1. Zistite ako pracuje knižnica Spacy a opíšte metódy ktoré používa.
|
||||
2. Natrénujte model pre spracovanie slovenského prirodzeného jazyka.
|
||||
3. Indentifikujte slabé miesta a zlepšite presnosť spracovania.
|
||||
4. Vykonajte viacero experimentov a zistite presnosť pri rôznych parametroch.
|
||||
@ -1,51 +1,7 @@
|
||||
---
|
||||
title: Spracovanie prirodzeného jazyka a jazyk Python
|
||||
title: Diplomové práce 2020/2021
|
||||
category: dp2021
|
||||
published: true
|
||||
---
|
||||
|
||||
# Tímový projekt 2019
|
||||
|
||||
[Daniel Hládek](../) - odporúčaný čas konzultácie: štvrtok o 9:00
|
||||
|
||||
Ciele:
|
||||
|
||||
- [Spracovanie prirodzeného jazyka](/topics/nlp), [Programovanie v jazyku Python](/topics/python)
|
||||
- špecifikovať zadanie diplomovej práce
|
||||
- naučiť sa pracovať s [odbornou literatúrou](../zp)
|
||||
- oboznámiť kolegov s obsahom vykonanej práce
|
||||
|
||||
## Podmienky na zápočet
|
||||
|
||||
- Vypracovaný tutoriál alebo rešerš vybranej metódy (8. a 13. týždeň). Rozsah výstupu min. 3 A4 kvalitného textu, vypracovaný prehľad literatúry vybranej metódy (min. 10 odkazov) ,odovzdanie textu cez [MOOODLE](https://moodle.tuke.sk/moodle35/course/view.php?id=874) kľúč je TP2019 a cez Váš osobný profil
|
||||
- Vypracovanie osobného profilu podľa [šablóny](../../../../students/2016/vzorny_student).
|
||||
- Dohodnuté znenie názvu a zadania záverečnej práce
|
||||
|
||||
|
||||
## Študenti a témy
|
||||
|
||||
- [Maroš Harahus](../../../../students/2016/maros_harahus) "Part of Speet Tagging" pomocou Spacy
|
||||
- [Lukáš Pokrývka](../../../../students/2016/lukas_pokryvka) "Paralelné trénovanie sémantických modelov prirodzeného jazyka" (word2vec, word embeddings, GloVe, fastText)
|
||||
- [Ján Holp](../../../../students/2016/jan_holp) (získavanie informácií)
|
||||
- [Dárius Lindvai](../../../../students/2016/darius_lindvai) (punctuation restoration, [tutorial](https://medium.com/@praneethbedapudi/deepcorrection2-automatic-punctuation-restoration-ac4a837d92d9), pytorch, LSTM tutorial)
|
||||
- [Jakub Maruniak](../../../../students/2016/jakub_maruniak) (prodigy, vytvorenie korpusu, [named-entity](../prodigy),
|
||||
- [Dominik Nagy](../../../../students/2016/dominik_nagy) (spelling correction, fairseq)
|
||||
|
||||
|
||||
## Dátumy stretnutí
|
||||
|
||||
- 10.10 - Harahus, Holp
|
||||
- 14.10. - Nagy, Maruniak, Pokrývka (prečítať knihu, vybrať tému)
|
||||
- 17.10 - Harahus, Lindvai (Prečítať knihu, prejsť Spacy tutoriál, nainštalovať Anaconda)
|
||||
- 24.10 - Pracovná cesta
|
||||
- 28.10 o 9:00, Holp, Harahus
|
||||
- 31.10 - Dekanské voľno
|
||||
- 4.11 - Maruniak
|
||||
- 7.11 o 13:40 - Lindvai, Nagy, Pokrývka, Harahus
|
||||
- 14.11 - Lindvai, Harahus, Holp
|
||||
- 21.11 - Lindvai
|
||||
- 28.11 - Harahus, Holp
|
||||
- 5.12. - Harahus
|
||||
- 12.12. - Holp, Harahus
|
||||
- 15.1. Nagy
|
||||
- 23.1. Harahus, Pokrývka, Holp, Maruniak, Nagy, Lindvai
|
||||
|
||||
|
||||
30
pages/04.categories/dp2022/category.md
Normal file
@ -0,0 +1,30 @@
|
||||
---
|
||||
title: Diplomové práce 2021/2022
|
||||
category: dp2022
|
||||
published: true
|
||||
---
|
||||
|
||||
Naučíte sa:
|
||||
|
||||
- Niečo viac o neurónových sieťach.
|
||||
- Vytvárať jednoduché programy na úpravu dát.
|
||||
- Zapojiť sa do reálneho výskumu.
|
||||
|
||||
### Morfologická analýza s podporou predtrénovania
|
||||
|
||||
- Zoberte existujúci model pre morfologickú analýzu slovenského jazyka a vyhodnotte ho.
|
||||
- Použite BERT model na natrénovanie morfologickej anotácie a porovnajte presnosť so základným modelom.
|
||||
|
||||
### Slovné jednotky v predspracovaní pre strojový preklad
|
||||
|
||||
- Natrénujte systém pre strojový preklad
|
||||
- Vytvorte niekoľko modelov pre rozdelenie slov na menšie jednotky v slovenskom jazyku. Pre každý model rozdelenia slov natrénujte systém pre strojový preklad.
|
||||
- Porovnajte výsledky strojového prekladu s rôznymi rozdeleniami slov.
|
||||
|
||||
|
||||
### Spracovanie veľkých dát pre účely získavania informácií
|
||||
|
||||
- Naučte sa pracovať s databázou Cassandra a Python
|
||||
- indexujte dáta z webu
|
||||
- implementujte techniku vyhodnotenia dokumentov
|
||||
|
||||
13
pages/04.categories/dp2023/category.md
Normal file
@ -0,0 +1,13 @@
|
||||
---
|
||||
title: Diplomové práce 2022/2023
|
||||
category: dp2023
|
||||
---
|
||||
# Diplomové práce 2022/2023
|
||||
|
||||
## Témy
|
||||
|
||||
1. Strojový preklad pomocou neurónových sietí (Jancura)
|
||||
2. Generatívne jazykové modely (Megela)
|
||||
3. Detekcia emócií z textu:
|
||||
- https://github.com/savan77/EmotionDetectionBERT
|
||||
|
||||
52
pages/04.categories/tp2020/category.md
Normal file
@ -0,0 +1,52 @@
|
||||
---
|
||||
title: Tímový projekt 2020
|
||||
category: tp2020
|
||||
---
|
||||
|
||||
# Tímový projekt 2020
|
||||
|
||||
[Daniel Hládek](../) - odporúčaný čas konzultácie: štvrtok o 9:00
|
||||
|
||||
Ciele:
|
||||
|
||||
- [Spracovanie prirodzeného jazyka](/topics/nlp), [Programovanie v jazyku Python](/topics/python)
|
||||
- špecifikovať zadanie diplomovej práce
|
||||
- naučiť sa pracovať s [odbornou literatúrou](../zp)
|
||||
- oboznámiť kolegov s obsahom vykonanej práce
|
||||
|
||||
## Podmienky na zápočet
|
||||
|
||||
- Vypracovaný tutoriál alebo rešerš vybranej metódy (8. a 13. týždeň). Rozsah výstupu min. 3 A4 kvalitného textu, vypracovaný prehľad literatúry vybranej metódy (min. 10 odkazov) ,odovzdanie textu cez [MOOODLE](https://moodle.tuke.sk/moodle35/course/view.php?id=874) kľúč je TP2019 a cez Váš osobný profil
|
||||
- Vypracovanie osobného profilu podľa [šablóny](../../../../students/2016/vzorny_student).
|
||||
- Dohodnuté znenie názvu a zadania záverečnej práce
|
||||
|
||||
## Študenti a témy
|
||||
|
||||
- [Maroš Harahus](../../../../students/2016/maros_harahus) "Part of Speet Tagging" pomocou Spacy
|
||||
- [Lukáš Pokrývka](../../../../students/2016/lukas_pokryvka) "Paralelné trénovanie sémantických modelov prirodzeného jazyka" (word2vec, word embeddings, GloVe, fastText)
|
||||
- [Ján Holp](../../../../students/2016/jan_holp) (získavanie informácií)
|
||||
- [Dárius Lindvai](../../../../students/2016/darius_lindvai) (punctuation restoration, [tutorial](https://medium.com/@praneethbedapudi/deepcorrection2-automatic-punctuation-restoration-ac4a837d92d9), pytorch, LSTM tutorial)
|
||||
- [Jakub Maruniak](../../../../students/2016/jakub_maruniak) (prodigy, vytvorenie korpusu, [named-entity](../prodigy),
|
||||
- [Dominik Nagy](../../../../students/2016/dominik_nagy) (spelling correction, fairseq)
|
||||
|
||||
|
||||
## Dátumy stretnutí
|
||||
|
||||
- 10.10 - Harahus, Holp
|
||||
- 14.10. - Nagy, Maruniak, Pokrývka (prečítať knihu, vybrať tému)
|
||||
- 17.10 - Harahus, Lindvai (Prečítať knihu, prejsť Spacy tutoriál, nainštalovať Anaconda)
|
||||
- 24.10 - Pracovná cesta
|
||||
- 28.10 o 9:00, Holp, Harahus
|
||||
- 31.10 - Dekanské voľno
|
||||
- 4.11 - Maruniak
|
||||
- 7.11 o 13:40 - Lindvai, Nagy, Pokrývka, Harahus
|
||||
- 14.11 - Lindvai, Harahus, Holp
|
||||
- 21.11 - Lindvai
|
||||
- 28.11 - Harahus, Holp
|
||||
- 5.12. - Harahus
|
||||
- 12.12. - Holp, Harahus
|
||||
- 15.1. Nagy
|
||||
- 23.1. Harahus, Pokrývka, Holp, Maruniak, Nagy, Lindvai
|
||||
|
||||
|
||||
|
||||
17
pages/04.categories/tp2021/category.md
Normal file
@ -0,0 +1,17 @@
|
||||
---
|
||||
title: Tímový projekt 2021
|
||||
category: tp2021
|
||||
---
|
||||
|
||||
# Tímový projekt 2021
|
||||
|
||||
Ciele:
|
||||
|
||||
- špecifikovať zadanie diplomovej práce
|
||||
- naučiť sa pracovať s odbornou literatúrou
|
||||
- oboznámiť kolegov s obsahom vykonanej práce
|
||||
|
||||
## Podmienky na zápočet
|
||||
|
||||
- Vypracovaný tutoriál alebo rešerš vybranej metódy (8. a 13. týždeň). Rozsah výstupu min. 4 A4 kvalitného textu, vypracovaný prehľad literatúry vybranej metódy (min. 10 odkazov) ,odovzdanie textu cez [MOOODLE](https://moodle.tuke.sk/moodle35/course/view.php?id=874) kľúč je TP2019 a cez Váš osobný profil
|
||||
- Dohodnuté znenie názvu a zadania záverečnej práce
|
||||
41
pages/04.categories/vp2021/category.md
Normal file
@ -0,0 +1,41 @@
|
||||
---
|
||||
title: Vedecký projekt 2020/2021
|
||||
category: vp2021
|
||||
---
|
||||
## Vedecký projekt 2021
|
||||
|
||||
Príprava na bakalársky projekt pre študentov 2. ročníka programu Počítačové siete. Letný semester.
|
||||
|
||||
Vedúci: Ing. Daniel Hládek PhD.
|
||||
|
||||
Požiadavky:
|
||||
|
||||
- Chuť naučiť sa niečo nové.
|
||||
|
||||
### Dialógový systém pomocou RASA framework
|
||||
|
||||
Cieľom projektu je naučiť sa niečo o dialógových systémoch a oboznámiť sa so základnými nástrojmi.
|
||||
|
||||
- Nainštalujte a oboznámte sa s [RASA frameworkom](https://rasa.com/docs/). Pri inštalácii využite systém [Anaconda](https://docs.anaconda.com/anaconda/user-guide/getting-started/).
|
||||
- Vyberte a prejdite najmenej jeden tutoriál pre prácu s RASA frameworkom.
|
||||
- Napíšte krátky report na 2 strany kde napíšete čo ste urobili a čo ste sa dozvedeli.
|
||||
|
||||
### Klaudové služby pre získavanie informácií
|
||||
|
||||
Cieľom projektu je zistiť ako fungujú klaudové služby pre umelú inteligenciu
|
||||
a ako fungujú webové vyhľadávače.
|
||||
|
||||
- Zistite čo je to získavanie informácií.
|
||||
- Oboznámte sa s [Azure Cognitive Search](https://azure.microsoft.com/en-us/services/search/) a získajte prístup k službe. Pre prihlásenie môžete použiť Váše študentské prihlasovacie údaje.
|
||||
- Vypracujte minimálne jeden tutoriál pre prácu s Azure Cognitive Search.
|
||||
- Vypracujte krátky report na 2 strany kde napíšete čo ste robili a čo ste sa dozvedeli.
|
||||
|
||||
### Rozpoznávanie pomenovaných entít
|
||||
|
||||
Cieľom projektu je zistiť ako sa robia základné úlohy spracovania prirodzeného jazyka - rozpoznávanie vlastných podstatných mien a oboznámenie sa zo základnými nástrojmi.
|
||||
|
||||
- Zistite čo je to pomenovaná entita a prečo je rozpoznávanie pomenovaných entít v prirodzenom jazyku dôležité.
|
||||
- Vyznačte [pomenované entity v textoch z Wikipédie](https://zp.kemt.fei.tuke.sk/topics/named-entity/navod).
|
||||
- Nainštalujte si [framework Spacy](https://spacy.io/) a vyskúšajte, ako funguje rozpoznávanie pomenovaných entít v anglickom jazyku. Pri inštalácii využite systém [Anaconda](https://docs.anaconda.com/anaconda/user-guide/getting-started/).
|
||||
- Napíšte krátku správu na cca 2 strany kde napíšete čo ste robili a čo ste sa dozvedeli.
|
||||
|
||||
31
pages/04.categories/vp2022/category.md
Normal file
@ -0,0 +1,31 @@
|
||||
---
|
||||
title: Vedecký projekt 2021/2022
|
||||
category: vp2022
|
||||
---
|
||||
## Vedecký projekt 2022
|
||||
|
||||
Príprava na bakalársky projekt pre študentov 2. ročníka programu Počítačové siete. Letný semester.
|
||||
|
||||
Vedúci: Ing. Daniel Hládek PhD.
|
||||
|
||||
Požiadavky:
|
||||
|
||||
- Chuť naučiť sa niečo nové.
|
||||
|
||||
Obsah:
|
||||
|
||||
- Naštudujete si zadanú problematiku.
|
||||
- Naučte sa základy jazyka Python.
|
||||
- Podrobne si prejdite minimálne dva tutoriály.
|
||||
- Napíšte krátky report na 2 strany kde napíšete čo ste urobili a čo ste sa dozvedeli.
|
||||
|
||||
### Extrakcia informácií z webových stránok
|
||||
|
||||
- Naštudujete si knižnicu BeautifulSoup a navrhnete skripty pre parsovanie niekoľkých webových stránok
|
||||
|
||||
### Dotrénovanie jazykových modelov
|
||||
|
||||
- Naučte sa pracovať s knižnicou HuggingFace transformers.
|
||||
- Naučíte sa základy neurónových jazykových modelov.
|
||||
- Dorénujete neurónovú sieť na vybraný problém.
|
||||
|
||||
@ -3,5 +3,3 @@ title: Daniel Hladek
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
Duis cotidieque an vel, ex impetus suscipit consetetur duo. Mutat vivendo ex sit! Eu quas iusto putant eum, amet modo vix ne, ne nam habeo inimicus? An civibus intellegat ius, etiam invidunt dignissim vix an, habeo vocent ocurreret in ius! Ei nec augue populo, decore accusamus cotidieque nec an. Ne vis unum nusquam, pertinax sententiae quaerendum his in!
|
||||
|
||||
|
||||
5
pages/authors/maros-harahus/author.md
Normal file
@ -0,0 +1,5 @@
|
||||
---
|
||||
title: Maroš Harahus
|
||||
author: Maroš Harahus
|
||||
---
|
||||
|
||||
@ -12,21 +12,61 @@ taxonomy:
|
||||
|
||||
Wiki stánka pre spoluprácu na záverečných prácach.
|
||||
|
||||
- [Často kladené otázky](/info/faq)
|
||||
- [Ako napíšem záverečnú prácu](/info/akopisat)
|
||||
- [Často kladené otázky](/topics/faq)
|
||||
- [Ako napíšem záverečnú prácu](/topics/akopisat)
|
||||
- [Prostredie Anaconda a jazyk Python pre strojové učenie](/topics/python)
|
||||
|
||||
## Vedúci
|
||||
|
||||
- [Daniel Hládek](/authors/daniel-hladek)
|
||||
- [Maroš Harahus](/authors/maros-harahus)
|
||||
|
||||
## Predmety
|
||||
|
||||
- [Bakalárske práce 2020](/categories/bp2020)
|
||||
- [Diplomové práce 2024](/categories/dp2024)
|
||||
- [Bakalárske práce 2024](/categories/bp2024)
|
||||
|
||||
## Vedecké projekty
|
||||
|
||||
- [Dialógový systém](/topics/chatbot)
|
||||
- Rozpoznávanie nenávistnej reči (Hate Speech Detection)
|
||||
- [Hate Speech Project Page](/topics/hatespeech)
|
||||
- Rozpoznávanie pomenovaných entít
|
||||
- [Projektová stránka](/topics/named-entity)
|
||||
- [Anotujte korpus](/topics/named-entity/navod)
|
||||
- [Ostatné projekty](/categories/projects)
|
||||
|
||||
## Ukončené projekty
|
||||
|
||||
- [Podpora slovenčiny v knižnici Spacy](/topics/spacy)
|
||||
- [Slovenský BERT model](/topics/bert)
|
||||
- [AI4Steel](/topics/steel)
|
||||
- Korpus otázok a odpovedí
|
||||
- [Projektová stránka](/topics/question)
|
||||
- [Vytvorte otázky a odpovede](/topics/question/navod)
|
||||
- [Validujte otázky a odpovede](/topics/question/validacie)
|
||||
- [Vytvorte nezodpovedateľné otázky a odpovede](/topics/question/nezodpovedatelne)
|
||||
|
||||
## Uzavreté predmety
|
||||
|
||||
## 2023
|
||||
|
||||
- [Diplomové práce 2023](/categories/dp2023)
|
||||
- [Bakalárske práce 2023](/categories/bp2023)
|
||||
|
||||
## 2022
|
||||
|
||||
- [Diplomové práce 2022](/categories/dp2022)
|
||||
- [Bakalárske práce 2022](/categories/bp2022)
|
||||
|
||||
## 2021
|
||||
|
||||
- [Bakalárske práce 2021](/categories/bp2021)
|
||||
- [Vedecký projekt 2021](/categories/vp2021)
|
||||
- [Bakalárske práce 2021](/categories/bp2021)
|
||||
- [Diplomové práce 2021](/categories/dp2021)
|
||||
|
||||
## Projekty
|
||||
|
||||
- [Spracovanie prirodzeného jazyka](/topics/nlp)
|
||||
- [Podpora slovenčiny v knižnici Spacy](/topics/spacy)
|
||||
- [Anotácia textových korpusov](/topics/prodigy)
|
||||
- [Rozpoznávanie pomenovaných entít](/topics/named-entity)
|
||||
- [Dialógový systém](/topics/chatbot)
|
||||
|
||||
|
||||
## 2020
|
||||
|
||||
- [Výsledky Tímového projektu 2020](/categories/tp2020)
|
||||
- [Bakalárske práce 2020](/categories/bp2020)
|
||||
|
||||
@ -1,5 +1,16 @@
|
||||
---
|
||||
title: Cesar Abascal Gutierrez
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [iaeste]
|
||||
tag: [ner,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
## Named entity annotations
|
||||
|
||||
Intern, probably summer 2019
|
||||
|
||||
Cesar Abascal Gutierrez <cesarbielva1994@gmail.com>
|
||||
|
||||
## Goals
|
||||
|
||||
66
pages/interns/oliver_pejic/README.md
Normal file
@ -0,0 +1,66 @@
|
||||
---
|
||||
title: Oliver Pejic
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [iaeste]
|
||||
tag: [hatespeech,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
Oliver Pejic
|
||||
|
||||
IAESTE Intern Summer 2024, 12 weeks in August, September and October.
|
||||
|
||||
Goal:
|
||||
|
||||
- Help with the [Hate Speech Project](/topics/hatespeech)
|
||||
- Help with evaluation of sentence transformer models using toolkit [MTEB](https://github.com/embeddings-benchmark/mteb)
|
||||
|
||||
Final Tasks:
|
||||
|
||||
- Prepare an MTEB evaluation task for [Slovak HATE speech](https://huggingface.co/datasets/TUKE-KEMT/hate_speech_slovak).
|
||||
- Prepare an MTEB evaluation task for [Slovak question answering](https://huggingface.co/datasets/TUKE-KEMT/retrieval-skquad).
|
||||
- [Machine translate](https://huggingface.co/google/madlad400-3b-mt) an SBERT evaluation set for multiple slavic languages.
|
||||
- Write a short scientific paper with results.
|
||||
|
||||
Meeting 3.10.:
|
||||
|
||||
State:
|
||||
|
||||
- Prepared a pull request for Retrieval SK Quad.
|
||||
- Prepared a pull request for Hate Speech Slovak.
|
||||
|
||||
Tasks:
|
||||
|
||||
- Make the pull request compatible with the MTEB Contribution guidelines. Discuss it when it is done.
|
||||
- Submit pull requests to MTEB project.
|
||||
- Machine Translate a database (HotpotQA, DB Pedia, FEVER) . Pick a database that is short, because translation might be slow.
|
||||
|
||||
Non priority tasks:
|
||||
|
||||
- Prepare databse and subnit it to HuggingFace Hub.
|
||||
- Prepare a MTEB PR for the databse.
|
||||
|
||||
Meeting 3.9:
|
||||
|
||||
State: Studied MTEB framework and transformers.
|
||||
|
||||
Tasks:
|
||||
|
||||
- Prepare and try MTEB evaluation tasks for the database. For evaluation you can try me5-base model.
|
||||
- Make a fork of MTEB and do necessary modification, including the documentation references for the task.
|
||||
- Prepare 2 GITHUB pull requests for the databases, preliminary BEIR script given.
|
||||
|
||||
Future tasks:
|
||||
|
||||
- Prepare a machine translation system to create another slovak/multilingual evaluation task from English task.
|
||||
|
||||
Preparation (7.8.2024):
|
||||
|
||||
- Get familiar with [SentenceTransformer](https://sbert.net/) framework, study fundamental papers and write down notes.
|
||||
- Get familiar with [MTEB](https://github.com/embeddings-benchmark/mteb) evaluation framework.
|
||||
- Prepare a working environment on Google Colab or on school server or Anaconda.
|
||||
- Get familiar with [existing finetuning scripts](https://git.kemt.fei.tuke.sk/dano/slovakretrieval).
|
||||
|
||||
|
||||
|
||||
104
pages/interns/sevval_bulburu/README.md
Normal file
@ -0,0 +1,104 @@
|
||||
---
|
||||
title: Sevval Bulburu
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [iaeste]
|
||||
tag: [hatespeech,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
|
||||
Sevval Bulburu
|
||||
|
||||
|
||||
IAESTE Intern Summer 2023, two months
|
||||
|
||||
Goal: Help with the [Hate Speech Project](/topics/hatespeech)
|
||||
|
||||
Meeting 12.10.2023
|
||||
|
||||
[Github Repo with results](https://github.com/sevvalbulburu/Hate_Speech_Detection_Slovak)
|
||||
|
||||
State:
|
||||
|
||||
- Proposed and tried extra layers above BERT model to make a classifier in seriees of experiments. There is a single sigmoid neuron on the output.
|
||||
- Manually adjusted the slovak HS dataset. Slovak dataset is not balanced. Tried some methods for "balancing" the dataset. By google translate - augmentation. Other samples are "generated" by translation into random langauge and translating back. This creates "paraphrases" of the original samples. It helps.
|
||||
- Tried SMOTE upsampling, it did not work.
|
||||
- Is date and user name an important feature?
|
||||
- tried some grid search for hyperparameter of the neural network - learning rate, dropout, epoch size, batch size. Batch size 64 no good.
|
||||
- Tried multilingal models for Slovak dataset (cnerg), result are not good.
|
||||
|
||||
Tasks:
|
||||
|
||||
- Please send me your work report. Please upload your scripts and notebooks on git and send me a link. git is git.kemt.fei.tuke.sk or github. Prepare some short comment about scripts.You can also upload the slovak datasetthere is some work done on it.
|
||||
|
||||
Ideas for a paper:
|
||||
|
||||
Possible names:
|
||||
|
||||
- "Data set balancing for Multilingual Hate Speech Detection"
|
||||
- "BERT embeddings for HS Detection in Low Resource Languages" (Turkish and Slovak).
|
||||
|
||||
(Possible) Tasks for paper:
|
||||
|
||||
- Create a shared draft document, e.g. on Overleaf or Google Doc
|
||||
- Write a good introduction and literature overview (Zuzka).
|
||||
- Try 2 or 3 class Softmax Layer for neural network.
|
||||
- Change the dataset for 3 class classification.
|
||||
- Prepare classifier for Slovak, English, Turkish and for multiple BERT models. Try to use multilingual BERT model for baseline embeddings.
|
||||
- Measure the effect of balancing the dataset by generation of additional examples.
|
||||
- Summarize experiments in tables.
|
||||
|
||||
|
||||
|
||||
|
||||
Meeting 5.9.2023
|
||||
|
||||
State:
|
||||
|
||||
- Proposed own Flask application
|
||||
- Created Django application with data model https://github.com/hladek/hate-annot
|
||||
|
||||
Tasks:
|
||||
|
||||
Meeting 22.8.2023
|
||||
|
||||
State:
|
||||
|
||||
- Familiar with Python, Anaconda, Tensorflow, AI projects
|
||||
- created account at idoc.fei.tuke.sk and installed anaconda.
|
||||
- Continue with previous open tasks.
|
||||
- Read a website and pick a dataset from https://hatespeechdata.com/
|
||||
- Evaluate (calculate p r f1) existing multilingual model. E.G. https://huggingface.co/Andrazp/multilingual-hate-speech-robacofi with any data
|
||||
- Get familiar with Django.
|
||||
|
||||
|
||||
Notes:
|
||||
|
||||
- ssh bulbur@idoc.fei.tuke.sk
|
||||
- nvidia-smi command to check status of GPU.
|
||||
- Use WinSCP to Copy Files. Use anaconda virtual env to create and activate a new python virtual environment. Use Visual Studio Code Remote to delvelop on your computer and run on remote computer (idoc.fei.tuke.sk). Use the same credentials for idoc server.
|
||||
- Use WSL2 to have local linux just to play.
|
||||
|
||||
Tasks:
|
||||
|
||||
- [ ] Get familiar with the task of Hate speech detection. Find out how can we use Transformer neural networks to detect and categorize hate speech in internet comments created by random people.
|
||||
- [ ] Get familiar with the basic tools: Huggingface Transformers, Learn how to use https://huggingface.co/Andrazp/multilingual-hate-speech-robacofi in Python script. Learn something about Transformer neural networks.
|
||||
|
||||
- [x] get familiar with Prodi.gy annotation tool.
|
||||
- [-] Set up web-based annotation environment for students (open, cooperation with [Vladimir Ferko](/students/2021/vladimir_ferko) ).
|
||||
|
||||
Ideas for annotation tools:
|
||||
|
||||
- https://github.com/UniversalDataTool/universal-data-tool
|
||||
- https://www.johnsnowlabs.com/top-6-text-annotation-tools/
|
||||
- https://app.labelbox.com/
|
||||
- https://github.com/recogito/recogito-js
|
||||
- https://github.com/topics/text-annotation?l=javascript
|
||||
|
||||
Future tasks (to be decided):
|
||||
|
||||
- Translate existing English dataset into Slovak. Use OPUS English Slovak Marian NMT model. Train Slovak munolingual model.
|
||||
- Prepare existing Slovak Twitter dataaset, train evaluate a model.
|
||||
|
||||
|
||||
|
||||
@ -11,13 +11,63 @@ Rok začiatku štúdia: 2016
|
||||
|
||||
Repozitár so [zdrojovými kódmi](https://git.kemt.fei.tuke.sk/dl874wn/dp2021)
|
||||
|
||||
Názov: Obnovenie interpunkcie pomocou hlbokých neurónových sietí
|
||||
|
||||
1. Vypracujte prehľad metód na obnovenie interpunkcie pomocou neurónových sietí.
|
||||
2. Vyberte vhodnú metódu obnovenia interpunkcie pomocou neurónových sietí.
|
||||
3. Pripravte množinu dát na trénovanie neurónovej siete, navrhnite a vykonajte sadu experimentov s rôznymi parametrami.
|
||||
4. Vyhodnoťte experimenty a navrhnite možné zlepšenia.
|
||||
|
||||
|
||||
## Diplomový projekt 2 2020
|
||||
|
||||
Stretnutie 25.1.2021
|
||||
|
||||
Stav:
|
||||
|
||||
- Vypracovaný report experimentov
|
||||
- Prezentácia
|
||||
|
||||
Do ďalšieho stretnutia:
|
||||
|
||||
- Dopísať časť kde opíšete Vašu metódu
|
||||
- Rozšíriť teoretickú časť - zistite a napíšte čo je Transformer, BERT, RNN a Adversarial (kontradiktórne učenie) learning.
|
||||
|
||||
|
||||
Virtuálne stretnutie 20.11.2020
|
||||
|
||||
Stav:
|
||||
|
||||
- Urobené úlohy z ďalšieho stretnutia
|
||||
- Práca na písomnej časti, ešte treba spracovať experimenty.
|
||||
|
||||
Do ďalšieho stretnutia:
|
||||
|
||||
- Finalizovať text.
|
||||
|
||||
|
||||
Virtuálne stretnutie 6.11.2020
|
||||
|
||||
Stav:
|
||||
|
||||
- Vypracovaná tabuľka s 5 experimentami.
|
||||
- vytvorený repozitár.
|
||||
|
||||
Na ďalšie stretnutie:
|
||||
|
||||
- nahrať kódy na repozitár.
|
||||
- závislosťi (názvy balíčkov) poznačte do súboru requirements.txt.
|
||||
- Prepracujte experiment tak aby akceptoval argumenty z príkazového riadka. (sys.argv)
|
||||
- K experimentom zapísať skript na spustenie. V skripte by mali byť parametre s ktorými ste spustili experiment.
|
||||
- dopracujte report.
|
||||
- do teorie urobte prehľad metód punctuation restoration a opis Vašej metódy.
|
||||
|
||||
|
||||
Virtuálne stretnutie 25.9.2020
|
||||
|
||||
Urobené:
|
||||
|
||||
- skript pre vyhodnotenie experimentov
|
||||
- skript pre vyhodnotenie experimentov.
|
||||
|
||||
|
||||
Úlohy do ďalšieho stretnutia:
|
||||
@ -37,12 +87,6 @@ Urobené:
|
||||
- 3. Vykonať sadu experimentov na overenie presnosti klasifikácie zvolenej neurónovej siete
|
||||
|
||||
|
||||
Názov: Obnovenie interpunkcie pomocou neurónových sietí
|
||||
|
||||
1. Vypracujte prehľad metód na obnovenie interpunkcie pomocou neurónových sietí.
|
||||
2. Vyberte vhodnú metódu obnovenia interpunkcie pomocou neurónových sietí.
|
||||
3. Pripravte množinu dát na trénovanie neurónovej siete, navrhnite a vykonajte sadu experimentov s rôznymi parametrami.
|
||||
4. Vyhodnoťte experimenty a navrhnite možné zlepšenia.
|
||||
|
||||
## Zápis o činnosti
|
||||
|
||||
|
||||
@ -1,4 +1,11 @@
|
||||
|
||||
---
|
||||
title: Novinky v oblasti “Punctuation Restoration”
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [tp2020]
|
||||
tag: [interpunction,nlp]
|
||||
author: Dárius Lindvai
|
||||
---
|
||||
# Novinky v oblasti “Punctuation Restoration”
|
||||
|
||||
Keďže interpunkcia a veľké písmená v slovách nemajú vplyv na výslovnosť slov, sú z výstupu **ASR** (*automatic speech recognition = automatické rozpoznávanie reči*) odstraňované, výsledkom čoho sú iba sekvencie slov alebo písmen. Systémy vykonávajúce doplňovanie **interpunkčných znamienok** a veľkých písmen sú potrebné najmä preto, lebo tieto výstupy bez interpunkcie a veľkých písmen väčšinou pre ľudí nie sú zrozumiteľné (v textovej forme). Interpunkcia a veľké písmená sú taktiež dôležité prvky aj pri **NLP** (*natural language processing = spracovanie prirodzeného jazyka*).
|
||||
|
||||
@ -1,4 +1,11 @@
|
||||
|
||||
---
|
||||
title: PYTORCH - LSTM TUTORIÁL
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [tp2020]
|
||||
tag: [python,lstm,nn,nlp,pytorch,anaconda]
|
||||
author: Dárius Lindvai
|
||||
---
|
||||
# PYTORCH - LSTM TUTORIÁL
|
||||
|
||||
### Čo je to Pytorch?
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
title: Dominik Nagy
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [dp2021,bp2019]
|
||||
category: [dp2022,bp2019]
|
||||
tag: [translation,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
@ -10,8 +10,99 @@ taxonomy:
|
||||
|
||||
*Rok začiatku štúdia*: 2016
|
||||
|
||||
## Diplomová práca 2022
|
||||
|
||||
[GIT repozitár](https://git.kemt.fei.tuke.sk/dn161mb/dp2022)
|
||||
|
||||
*Názov diplomovej práce*: Neurónový strojový preklad pomocou knižnice Fairseq
|
||||
|
||||
*Meno vedúceho*: Ing. Daniel Hládek, PhD.
|
||||
|
||||
*Zadanie diplomovej práce*:
|
||||
|
||||
1. Vypracujte teoretický prehľad metód neurónového strojového prekladu.
|
||||
2. Podrobne opíšte vybranú metódu neurónového strojového prekladu.
|
||||
3. Natrénujte viacero modelov pre strojový preklad pomocou nástroja Fairseq a vyhodnoťte ich.
|
||||
4. Na základe výsledkov experimentov navrhnite zlepšenia.
|
||||
|
||||
|
||||
Stretnutie 11.1.2022
|
||||
|
||||
- Urobené všetky úlohy z minulého stretnutia, okrem textu a gitu.
|
||||
- Natrénované modely fairseq pre obojsmerný preklad angličtina slovenčina.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- dajte všetky skripty do repozitára dp2022
|
||||
- Napíšte si osnovu diplomovej práce.
|
||||
- Vypracujte draft (hrubý text) diplomovej práce.
|
||||
- V texte DP sumarizujte vykonané experimenty.
|
||||
- Pripravte si prezentáciu na obhajoby.
|
||||
- Skontrolovať či sa robí tokenizácia správne pri vyhodnotení.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Pripravte článok (pre vedúceho).
|
||||
- Urobte experiment s architektúrou MBART. Porovnajte Vaše výsledky s výsledkami v článku MBART (Liu et al. : Multilingual Denoising Pre-training for Neural Machine Translation).
|
||||
|
||||
|
||||
Stretnutie 17.12.2021
|
||||
|
||||
Stav:
|
||||
|
||||
- rozbehané trénovanie na slovensko-anglickom (LinDat) paralelnom korpuse.
|
||||
- model z angličtiny do slovenčiny.
|
||||
- tokenizácia subword NMT.
|
||||
- rozbehané trénovanie na GPU, bez anaconda.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Cieľ je aby Vaše experimenty boli zopakovateľné. Pridajte všetky trénovacie skripty do git repozitára. Nepridávajte dáta. Pridajte skripty alebo návody na to ako pripraviť dáta.
|
||||
- [x] Zostavte tabuľku kde zapíšete parametre trénovania a dosiahnuté výsledky.
|
||||
- Napíšte prehľad aktuálnych metód strojového prekladu pomocou neurónových sietí kde prečítate viacero vedeckých článkov a ku každému uvediete názov a čo ste sa z neho dozvedeli. Vyhľadávajte kľúčové slovíčka: "Survey of neural machine translation". Chceme sa dozvedieť aj o transformeroch a neurónových jazykových modeloch.
|
||||
- [x] vyskúšajte trénovanie aj s inými architektúrami. Ku každému trénovaniu si poznačte skript, výsledky a dajte to na git.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- [x] Výskúšajte preklad v opačnom smere.
|
||||
- [x] Vyskúšanie inej metódy tokenizácie (BPE, sentencepiece, wordpiece - huggingface tokenizers).
|
||||
|
||||
Stretnutie 6.7.2021
|
||||
|
||||
Stav:
|
||||
|
||||
- Podarilo sa rozbehať setup pre trénovanie slovensko anglického prekladu na korpuse 10 viet pomocou fairseq.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v trénovaní na servri IDOC, použite skript na príápravu prostredia ktorý som Vám dal.
|
||||
- Pripravte veľký slovensko-anglický paralelný korpus a natrénujte z neho model.
|
||||
- Model vyhodnotťe pomocou metriky BLEU. Naštudujte si metriku BLEU.
|
||||
|
||||
## Príprava na Diplomový projekt 2 2021
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Využiť BERT model pri strojovom preklade zo slovenčiny
|
||||
|
||||
Stretnutie 17.2.2021
|
||||
|
||||
Stav:
|
||||
|
||||
- Plán ukončiť v roku 2022
|
||||
- Vypracovaný tutoriál https://fairseq.readthedocs.io/en/latest/getting_started.html#training-a-new-model a https://fairseq.readthedocs.io/en/latest/tutorial_simple_lstm.html
|
||||
|
||||
Do ďalšieho stretnutia:
|
||||
|
||||
- Treba zlepšiť teoretickú prípravu a písanie.
|
||||
- Pripraviť slovensko-anglický korpus do podoby vhodnej na trénovanie. Zistite v akej podobe je potrebné dáta mať.
|
||||
- Natrénovať model fairseq pre strojový preklad zo slovenčiny.
|
||||
- Zistite ako prebieha neurónový strojový preklad, čo je to neurónová sieť, čo je to enkóder, dekóder model a napíšte to vlastnými slovami. Napíšte aj odkiaľ ste to zistili.
|
||||
- Prečítajte si https://arxiv.org/abs/1705.03122 a https://arxiv.org/abs/1611.02344 a napíšte čo ste sa dozvedeli.
|
||||
|
||||
## Diplomový projekt 2
|
||||
|
||||
|
||||
Virtuálne stretnutie 25.9.
|
||||
|
||||
- Možnosť predĺženia štúdia
|
||||
@ -59,18 +150,6 @@ Stretnutie 6.3.2020.
|
||||
- Pozrieť článok [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://www.aclweb.org/anthology/N19-4009/)
|
||||
- Pozrieť prístup a článok https://github.com/pytorch/fairseq/blob/master/examples/joint_alignment_translation/README.md
|
||||
|
||||
## Diplomová práca 2021
|
||||
|
||||
*Názov diplomovej práce*: Prepis postupností pomocou neurónových sietí pre strojový preklad
|
||||
|
||||
*Meno vedúceho*: Ing. Daniel Hládek, PhD.
|
||||
|
||||
*Zadanie diplomovej práce*:
|
||||
|
||||
1. Vypracujte teoretický prehľad metód "sequence to sequence".
|
||||
2. Pripravte si dátovú množinu na trénovanie modelu sequence to sequence pre úlohu strojového prekladu.
|
||||
3. Vyberte minimálne dva rôzne modely a porovnajte ich presnosť na vhodnej dátovej množine.
|
||||
4. Na základe výsledkov experimentov navrhnite zlepšenia.
|
||||
|
||||
## Tímový projekt 2019
|
||||
|
||||
|
||||
@ -1,3 +1,11 @@
|
||||
---
|
||||
title: Sequence-to-sequence
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [tp2020]
|
||||
tag: [nn,seq2seq,translation,nlp]
|
||||
author: Dominik Nagy
|
||||
---
|
||||
# Sequence-to-sequence
|
||||
|
||||
Hlboké neurónové siete (Deep Neural Networks – DNN) sú veľmi výkonné modely strojového
|
||||
@ -3,22 +3,162 @@ title: Jakub Maruniak
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [dp2021,bp2019]
|
||||
tag: [spacy,ner,nlp]
|
||||
tag: [spacy,ner,annotation,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
# Jakub Maruniak
|
||||
|
||||
|
||||
*Rok začiatku štúdia*: 2016
|
||||
|
||||
*Návrh na názov DP*:
|
||||
|
||||
Anotácia a rozpoznávanie pomenovaných entít v slovenskom jazyku.
|
||||
|
||||
[CRZP](https://opac.crzp.sk/?fn=detailBiblioForm&sid=ECC3D3F0B3159C4F3217EC027BE4)
|
||||
|
||||
1. Vypracujte teoretický úvod, kde vysvetlíte čo je to rozpoznávanie pomenovaných entít a akými najnovšími metódami sa robí. Vysvetlite, ako pracuje klasifikátor pre rozpoznávanie pomenovaných entít v knižnici Spacy.
|
||||
2. Pripravte postup na anotáciu textového korpusu pre systém Prodigy pre trénovanie modelu vo vybranej úlohe spracovania prirodzeného jazyka.
|
||||
3. Vytvorte množinu textových dát v slovenskom jazyku vhodných na trénovanie štatistického modelu spracovania prirodzeného jazyka pomocou knižnice Spacy.
|
||||
4. Natrénujte štatistický model pomocou knižnice Spacy a zistite, aký vplyv má veľkosť trénovacej množiny na presnosť klasifikátora.
|
||||
|
||||
*Spolupráca s projektom*:
|
||||
|
||||
- [Podpora slovenčiny v Spacy](/topics/spacy)
|
||||
- [Anotácia textových dát](/topics/prodigy)
|
||||
- [Rozpoznávanie pomenovaných entít](/topics/named-entity)
|
||||
- [Spracovanie prir. jazyka](/topics/nlp)
|
||||
- [Programovanie v jazyku Python](/topics/python)
|
||||
|
||||
|
||||
## Diplomová práca 2021
|
||||
|
||||
|
||||
Stretnutie 12.3.
|
||||
|
||||
Stav:
|
||||
|
||||
- Anotovanie dát, vykonané experimenty s trénovaním.
|
||||
- Dosiahli sme presnosť cca 72 percent.
|
||||
- Výsledky sú zhrnuté v tabuľke.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Píšte prácu.
|
||||
- Uložte trénovacie skripty na GIT.
|
||||
|
||||
|
||||
|
||||
## Diplomový projekt 2
|
||||
|
||||
Ciele:
|
||||
|
||||
- Anotovať sadu dát s použitím produkčnej anotačnej schémy, natrénovať a vyhodnotiť model.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Anotovať sadu dát s použitím produkčnej anotačnej schémy
|
||||
- Použiť model na podporu anotácie
|
||||
- Do konca ZS vytvoriť report vo forme článku.
|
||||
|
||||
Stretnutie 12.2.:
|
||||
|
||||
- Prebrali sme článok. Treba vyhodiť a popresúvať niektoré časti, inak v poriadku.
|
||||
|
||||
Do budúceho stretnutia:
|
||||
|
||||
- Vybrať vhodný časopis na publikovanie
|
||||
- Využiť pri trénovaní ďalšie anotované dáta.
|
||||
|
||||
|
||||
|
||||
|
||||
Stretnutie 20.1.
|
||||
|
||||
Preberanie draftu práce.
|
||||
|
||||
- Do článku vyradiť príliš všeobecné časti - napr. o strojovom učení.
|
||||
- V úvode zadefinujte problém, pojmy a bežné spôsoby riešenia problému. Čo je korpus? Ako sa vyrába? Na čo a ako sa používa?
|
||||
- V jadre predstavte Vaše riešenie. Ako vyzerá korpus? Ako ste ho urobili?
|
||||
- Na konci definujte metodiku vyhodnotenia, vyhodnotte riešenie a navrhnite zlepšenia. Akú presnosť má model vytvorený s pomocou korpusu?
|
||||
|
||||
Virtuálne stretnutie 18.12.2021:
|
||||
|
||||
Stav:
|
||||
|
||||
- Vytvorené anotácie do databázy, cca 1700 jednotiek.
|
||||
- Začiatok článku.
|
||||
|
||||
Virtuálne stretnutie 27.11.2020:
|
||||
|
||||
- Zatiaľ zostávame pri ručnej extrakcii dát z anotačnej schémy.
|
||||
- Vypracovaná [tabuľka s experimentami](./dp2021/train_experiments)
|
||||
- [Dáta a skripty](./dp2021/annotation)
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pracovať na ďalších anotáciách, zlepšiť presnosť modelu.
|
||||
- Urobiť ďalšie experimenty.
|
||||
- Začať pracovať na článku. Niečo podobné ako [Znalosti](https://hi.kkui.fei.tuke.sk/daz2019/), alebo [AEI](http://www.aei.tuke.sk/). šablóna ieee alebo llncs.
|
||||
|
||||
Stretnutie 20.1.2021
|
||||
|
||||
- Draft článku
|
||||
|
||||
Virtuálne stretnutie 13.11.2020:
|
||||
|
||||
- výsledky skopírované do [adresára](./dp2021)
|
||||
- prečítané 3 články - porovnanie manuálnej anotácie a poloautomatickej.
|
||||
- začiatok práce na skripte pre počítanie anotovaných entít, treba ešte vylepšiť aby vznikla tabuľka.
|
||||
- anotačná schéma vyzerá byť v poriadku, niektoré články treba odfiltrovať (zoznam obrázkov, prázdna kategória, nadpis).
|
||||
|
||||
Úlohy do ďalšieho stretnutia:
|
||||
|
||||
- vytvoriť spôsob pre získanie dát z produkčnej anotačnej schémy. (pre vedúceho)
|
||||
- vytvorte ďalšie anotácie.
|
||||
- Spísať pravidlá pre validáciu. Aký výsledok anotácie je dobrý? Je potrebné anotované dáta skontrolovať?
|
||||
- Vytvorte tabuľku kde uvediete presnosť modelu s rôznym množstvom anotovaných dát.
|
||||
- Aký je najlepší spôsob vyhodnotnenia? Vytvoriť jednotnú testovaciu množinu. Druhý spôsob je použiť "10 fold cross validation" (Všetky dáta sa rozdelia na 10 častí, 9 sa využije pri trénovaní, 1 pri testovaní. Trénovanie sa opakuje 10 krát stále pre inú testovaciu množinu, výsledky sa spriemerujú).
|
||||
|
||||
|
||||
Virtuálne stretnutie 30.10.2020:
|
||||
|
||||
Stav:
|
||||
|
||||
- Vylepšený návod
|
||||
- Vyskúšaný export dát a trénovanie modelu z databázy. Problém pri trénovaní Spacy - iné výsledky ako cez Prodigy trénovanie
|
||||
- Práca na textovej časti.
|
||||
|
||||
Úlohy do ďalšieho stretnutia:
|
||||
- Vytvorte si repozitár s názvom dp2021 a tam pridajte skripty a poznámky.
|
||||
- Pokračujte v písaní práce. Vykonajte prieskum literatúry "named entity corpora" aj poznámky.
|
||||
- Vytvorte systém pre zistenie množstva a druhu anotovaných dát. Koľko článkov? Koľko entít jednotlivvých typov? Výsledná tabuľka pôjde do práce.
|
||||
- Pripraviť sa na produkčné anotácie. Je schéma pripravená?
|
||||
|
||||
Virtuálne stretnutie 16.10.2020:
|
||||
|
||||
Stav:
|
||||
- Spísané stručné poznámky k procesu anotácie
|
||||
- Pokusne anotovaných niekoľko článkov
|
||||
|
||||
Úlohy na ďálšie stretnutie:
|
||||
- Vylepšiť oficiálny návod na anotáciu NER https://zp.kemt.fei.tuke.sk/topics/named-entity/navod podľa poznámok a skúsenosti pri anotácii. Pridajte pravidlá pre učenie Accept a Reject článku. Ktorý paragraf je vhodný na anotáciu?
|
||||
- Pripraviť skript na výber anotovaných dát z databázy a úpravu do podoby vhodnej pre trénovanie.
|
||||
- Spísať pravidlá pre validáciu. Aký výsledok anotácie je dobrý? Je potrebné anotované dáta skontrolovať?
|
||||
- Pokračujte v písaní DP.
|
||||
|
||||
Virtuálne stretnutie 9.10.2020:
|
||||
|
||||
Stav:
|
||||
|
||||
- Vyskúšané trénovanie modelu podľa repozitára spacy-skmodel
|
||||
- Začiatok práce na textovej časti (vo Worde do šablóny ZP).
|
||||
|
||||
Úlophy na ďalšie stretnutie:
|
||||
|
||||
- Prečítajte si návod na anotáciu a navrhnite zlepšenia návodu. Cieľ je napísať presnú metodiku anotácie.
|
||||
- Pokusne antujte niekoľko článkov, spíšte problémové miesta.
|
||||
|
||||
Stretnutie 25.9.2020:
|
||||
|
||||
Urobené:
|
||||
|
||||
Oboznámenie sa procesom anotácie NER
|
||||
@ -33,7 +173,6 @@ Návrhny na zlepšenie:
|
||||
Je potrebné rozbehať produkčnú anotáciu NER
|
||||
|
||||
|
||||
|
||||
## Diplomový projekt 1 2020
|
||||
|
||||
Výstupy (18.6.2020):
|
||||
@ -112,21 +251,3 @@ Návrh možných entít na anotáciu:
|
||||
|
||||
*Písomná práca*: [Rešerš](./timovy_projekt)
|
||||
|
||||
*Návrh na zadanie DP*:
|
||||
|
||||
1. Vypracujte prehľad metód prípravy textových korpusov pomocou crowdsourcingu.
|
||||
2. Pripravte postup na anotáciu textového korpusu pre systém Prodigy pre trénovanie modelu vo vybranej úlohe spracovania prirodzeného jazyka.
|
||||
3. Vytvorte množinu textových dát v slovenskom jazyku vhodných na trénovanie štatistického modelu spracovania prirodzeného jazyka pomocou knižnice Spacy.
|
||||
4. Natrénujte štatistický model pomocou knižnice Spacy a zistite, aký vplyv má veľkosť trénovacej množiny na presnosť klasifikátora.
|
||||
|
||||
*Návrh na názov DP*:
|
||||
|
||||
Anotácia textových dát v slovenskom jazyku pomocou metódy crowdsourcingu
|
||||
|
||||
*Spolupráca s projektom*:
|
||||
|
||||
- [Podpora slovenčiny v Spacy](/topics/spacy)
|
||||
- [Anotácia textových dát](/topics/prodigy)
|
||||
- [Rozpoznávanie pomenovaných entít](/topics/named-entity)
|
||||
- [Spracovanie prir. jazyka](/topics/nlp)
|
||||
- [Programovanie v jazyku Python](/topics/python)
|
||||
|
||||
@ -1 +1,40 @@
|
||||
DP2021
|
||||
## Diplomový projekt 2 2020
|
||||
Stav:
|
||||
- aktualizácia anotačnej schémy (jedná sa o testovaciu schému s vlastnými dátami)
|
||||
- vykonaných niekoľko anotácii, trénovanie v Prodigy - nízka presnosť = malé množstvo anotovaných dát. Trénovanie v spacy zatiaľ nefunguje.
|
||||
- Štatistiky o množstve prijatých a odmietnutých anotácii získame z Prodigy: prodigy stats wikiart. Zatiaľ 156 anotácii (151 accept, 5 reject). Na získanie prehľadu o množstve anotácii jednotlivých entít potrebujeme vytvoriť skript.
|
||||
- Prehľad literatúry Named Entity Corpus
|
||||
- Budovanie korpusu pre NER – automatické vytvorenie už anotovaného korpusu z Wiki pomocou DBpedia – jedná sa o anglický korpus, ale možno spomenúť v porovnaní postupov
|
||||
- Building a Massive Corpus for Named Entity Recognition using Free Open Data Sources - Daniel Specht Menezes, Pedro Savarese, Ruy L. Milidiú
|
||||
- Porovnanie postupov pre anotáciu korpusu (z hľadiska presnosti aj času) - Manual, SemiManual
|
||||
- Comparison of Annotating Methods for Named Entity Corpora - Kanako Komiya, Masaya Suzuki
|
||||
- Čo je korpus, vývojový cyklus, analýza korpusu (Už využitá literatúra – cyklus MATTER)
|
||||
- Natural Language Annotation for Machine Learning – James Pustejovsky, Amber Stubbs
|
||||
|
||||
Aktualizácia 09.11.2020:
|
||||
- Vyriešený problém, kedy nefungovalo trénovanie v spacy
|
||||
- Vykonaná testovacia anotácia cca 500 viet. Výsledky trénovania pri 20 iteráciách: F-Score 47% (rovnaké výsledky pri trénovaní v Spacy aj Prodigy)
|
||||
- Štatistika o počte jednotlivých entít: skript count.py
|
||||
|
||||
|
||||
## Diplomový projekt 1 2020
|
||||
|
||||
- vytvorenie a spustenie docker kontajneru
|
||||
|
||||
|
||||
```
|
||||
./build-docker.sh
|
||||
docker run -it -p 8080:8080 -v ${PWD}:/work prodigy bash
|
||||
# (v mojom prípade:)
|
||||
winpty docker run --name prodigy -it -p 8080:8080 -v C://Users/jakub/Desktop/annotation/work prodigy bash
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
### Spustenie anotačnej schémy
|
||||
- `dataminer.csv` články stiahnuté z wiki
|
||||
- `cd ner`
|
||||
- `./01_text_to_sent.sh` spustenie skriptu *text_to_sent.py*, ktorý rozdelí články na jednotlivé vety
|
||||
- `./02_ner_correct.sh` spustenie anotačného procesu pre NER s návrhmi od modelu
|
||||
- `./03_ner_export.sh` exportovanie anotovaných dát vo formáte jsonl potrebnom pre spracovanie vo spacy
|
||||
|
||||
@ -1,17 +1,16 @@
|
||||
# > docker run -it -p 8080:8080 -v ${PWD}:/work prodigy bash
|
||||
# > winpty docker run --name prodigy -it -p 8080:8080 -v C://Users/jakub/Desktop/annotation/work prodigy bash
|
||||
# > winpty docker run --name prodigy -it -p 8080:8080 -v C://Users/jakub/Desktop/annotation-master/annotation/work prodigy bash
|
||||
|
||||
FROM python:3.8
|
||||
RUN mkdir /prodigy
|
||||
WORKDIR /prodigy
|
||||
COPY ./prodigy-1.9.6-cp36.cp37.cp38-cp36m.cp37m.cp38-linux_x86_64.whl /prodigy
|
||||
RUN mkdir /work
|
||||
COPY ./ner /work
|
||||
RUN pip install prodigy-1.9.6-cp36.cp37.cp38-cp36m.cp37m.cp38-linux_x86_64.whl
|
||||
COPY ./ner /work/ner
|
||||
RUN pip install uvicorn==0.11.5 prodigy-1.9.6-cp36.cp37.cp38-cp36m.cp37m.cp38-linux_x86_64.whl
|
||||
RUN pip install https://files.kemt.fei.tuke.sk/models/spacy/sk_sk1-0.0.1.tar.gz
|
||||
RUN pip install nltk
|
||||
EXPOSE 8080
|
||||
ENV PRODIGY_HOME /work
|
||||
ENV PRODIGY_HOST 0.0.0.0
|
||||
WORKDIR /work
|
||||
|
||||
|
||||
@ -1,13 +1,11 @@
|
||||
## Diplomový projekt 1 2020
|
||||
## Diplomový projekt 2 2020
|
||||
|
||||
- vytvorenie a spustenie docker kontajneru
|
||||
|
||||
|
||||
```
|
||||
./build-docker.sh
|
||||
docker run -it -p 8080:8080 -v ${PWD}:/work prodigy bash
|
||||
# (v mojom prípade:)
|
||||
winpty docker run --name prodigy -it -p 8080:8080 -v C://Users/jakub/Desktop/annotation/work prodigy bash
|
||||
winpty docker run --name prodigy -it -p 8080:8080 -v C://Users/jakub/Desktop/annotation-master/annotation/work prodigy bash
|
||||
```
|
||||
|
||||
|
||||
@ -17,5 +15,33 @@ winpty docker run --name prodigy -it -p 8080:8080 -v C://Users/jakub/Desktop/ann
|
||||
- `dataminer.csv` články stiahnuté z wiki
|
||||
- `cd ner`
|
||||
- `./01_text_to_sent.sh` spustenie skriptu *text_to_sent.py*, ktorý rozdelí články na jednotlivé vety
|
||||
- `./02_ner_correct.sh` spustenie anotačného procesu pre NER s návrhmi od modelu
|
||||
- `./03_ner_export.sh` exportovanie anotovaných dát vo formáte jsonl potrebnom pre spracovanie vo spacy
|
||||
- `./02_ner_manual.sh` spustenie manuálneho anotačného procesu pre NER
|
||||
- `./03_export.sh` exportovanie anotovaných dát vo formáte json potrebnom pre spracovanie vo spacy. Možnosť rozdelenia na trénovacie (70%) a testovacie dáta (30%) (--eval-split 0.3).
|
||||
Pozn. aby --eval-split fungoval správne, je potrebné v inštalácii prodigy (cestu zistíme pomocou `prodigy stats`) v súbore `recipes/train.py` upraviť funkciu `data_to_spacy` (mal by byť riadok 327). V novej verzii by to malo byť opravené. Do riadku treba pridať parameter eval_split.
|
||||
`json_data, eval_data, split = train_eval_split(json_data, eval_split)`
|
||||
|
||||
### Anotované databázy
|
||||
- `./ner/skner/sknerv4.jsonl` - Aktuálna anotovaná databáza z https://skner.tukekemt.xyz/ (Celkovo cca 5000 článkov)
|
||||
- `./ner/wikiart/wikiart2.jsonl` - Vlastná databáza, články rozdelené na vety (Celkovo cca 1300 viet)
|
||||
- Presná štatistika o databázach bude doplnená
|
||||
|
||||
### Štatistika o anotovaných dátach
|
||||
- `prodigy stats wikiart` - informácie o počte prijatých a odmietnutých článkov pre konkrétny dataset v prodigy
|
||||
|
||||
### Vizualizácia anotovaných dát
|
||||
- `streamlit run visualizer.py visualize ./dataset.jsonl` - Vypíše anotácie zo zvolenej databázy na lokálnej adrese http://192.168.1.26:8501
|
||||
|
||||
### Trénovanie modelu
|
||||
Založené na: https://git.kemt.fei.tuke.sk/dano/spacy-skmodel
|
||||
- Na trénovanie NER využitá vstavaná funkcia spacy train
|
||||
- Testované aj s custom skriptom na trénovanie - `custom_train.py` - približne rovnaké výsledky, neporovnateľne dlhší čas trénovania
|
||||
|
||||
|
||||
### Scripts
|
||||
`python scripts.py [command] [arguments]`
|
||||
|
||||
| Príkaz | Popis | Argumenty |
|
||||
| ---------- | ------------------ | ------------------- |
|
||||
| `count` | Vypíše štatistiky o databáze vo formáte JSONL z Prodigy.| dataset_path|
|
||||
| `delete_annot` | Vytvorí samostatnú databázu s anotáciami iba od zvoleného anotátora.| annotator, dataset_path, new_dataset_path|
|
||||
| `modelinfo`| Vypíše informácie o natrénovanom modeli (Precision, Recall a F-skóre), zároveň aj o jednotlivých entitách. | - |
|
||||
|
||||
@ -0,0 +1,152 @@
|
||||
"""Scripts used for training and evaluation of NER models
|
||||
Usage example:
|
||||
$ python custom_train.py train ./model ./train.jsonl ./eval.jsonl -o ./output_dir -n 15
|
||||
Requirements:
|
||||
spacy>=2.2.3
|
||||
https://github.com/explosion/projects/tree/master/ner-drugs
|
||||
"""
|
||||
import spacy
|
||||
from spacy.cli.train import _load_pretrained_tok2vec
|
||||
from timeit import default_timer as timer
|
||||
from pathlib import Path
|
||||
import srsly
|
||||
from wasabi import msg
|
||||
import random
|
||||
import plac
|
||||
import sys
|
||||
import tqdm
|
||||
|
||||
|
||||
def format_data(data):
|
||||
result = []
|
||||
labels = set()
|
||||
for eg in data:
|
||||
if eg["answer"] != "accept":
|
||||
continue
|
||||
ents = [(s["start"], s["end"], s["label"]) for s in eg.get("spans", [])]
|
||||
labels.update([ent[2] for ent in ents])
|
||||
result.append((eg["text"], {"entities": ents}))
|
||||
return result, labels
|
||||
|
||||
|
||||
@plac.annotations(
|
||||
model=("The base model to load or blank:lang", "positional", None, str),
|
||||
train_path=("The training data (Prodigy JSONL)", "positional", None, str),
|
||||
eval_path=("The evaluation data (Prodigy JSONL)", "positional", None, str),
|
||||
n_iter=("Number of iterations", "option", "n", int),
|
||||
output=("Optional output directory", "option", "o", str),
|
||||
tok2vec=("Pretrained tok2vec weights to initialize model", "option", "t2v", str),
|
||||
)
|
||||
def train_model(
|
||||
model, train_path, eval_path, n_iter=10, output=None, tok2vec=None,
|
||||
):
|
||||
"""
|
||||
Train a model from Prodigy annotations and optionally save out the best
|
||||
model to disk.
|
||||
"""
|
||||
spacy.util.fix_random_seed(0)
|
||||
with msg.loading(f"Loading '{model}'..."):
|
||||
if model.startswith("blank:"):
|
||||
nlp = spacy.blank(model.replace("blank:", ""))
|
||||
else:
|
||||
nlp = spacy.load(model)
|
||||
msg.good(f"Loaded model '{model}'")
|
||||
train_data, labels = format_data(srsly.read_jsonl(train_path))
|
||||
eval_data, _ = format_data(srsly.read_jsonl(eval_path))
|
||||
ner = nlp.create_pipe("ner")
|
||||
for label in labels:
|
||||
ner.add_label(label)
|
||||
nlp.add_pipe(ner)
|
||||
t2v_cfg = {
|
||||
"embed_rows": 10000,
|
||||
"token_vector_width": 128,
|
||||
"conv_depth": 8,
|
||||
"nr_feature_tokens": 3,
|
||||
}
|
||||
optimizer = nlp.begin_training(component_cfg={"ner": t2v_cfg} if tok2vec else {})
|
||||
if tok2vec:
|
||||
_load_pretrained_tok2vec(nlp, Path(tok2vec))
|
||||
batch_size = spacy.util.compounding(1.0, 32.0, 1.001)
|
||||
best_acc = 0
|
||||
best_model = None
|
||||
row_widths = (2, 8, 8, 8, 8)
|
||||
msg.row(("#", "L", "P", "R", "F"), widths=row_widths)
|
||||
for i in range(n_iter):
|
||||
random.shuffle(train_data)
|
||||
losses = {}
|
||||
data = tqdm.tqdm(train_data, leave=False)
|
||||
for batch in spacy.util.minibatch(data, size=batch_size):
|
||||
texts, annots = zip(*batch)
|
||||
nlp.update(texts, annots, drop=0.2, losses=losses)
|
||||
with nlp.use_params(optimizer.averages):
|
||||
sc = nlp.evaluate(eval_data)
|
||||
if sc.ents_f > best_acc:
|
||||
best_acc = sc.ents_f
|
||||
if output:
|
||||
best_model = nlp.to_bytes()
|
||||
acc = (f"{sc.ents_p:.3f}", f"{sc.ents_r:.3f}", f"{sc.ents_f:.3f}")
|
||||
msg.row((i + 1, f"{losses['ner']:.2f}", *acc), widths=row_widths)
|
||||
msg.text(f"Best F-Score: {best_acc:.3f}")
|
||||
if output and best_model:
|
||||
with msg.loading("Saving model..."):
|
||||
nlp.from_bytes(best_model).to_disk(output)
|
||||
msg.good("Saved model", output)
|
||||
|
||||
|
||||
@plac.annotations(
|
||||
model=("The model to evaluate", "positional", None, str),
|
||||
eval_path=("The evaluation data (Prodigy JSONL)", "positional", None, str),
|
||||
)
|
||||
def evaluate_model(model, eval_path):
|
||||
"""
|
||||
Evaluate a trained model on Prodigy annotations and print the accuracy.
|
||||
"""
|
||||
with msg.loading(f"Loading model '{model}'..."):
|
||||
nlp = spacy.load(model)
|
||||
data, _ = format_data(srsly.read_jsonl(eval_path))
|
||||
sc = nlp.evaluate(data)
|
||||
result = [
|
||||
("Precision", f"{sc.ents_p:.3f}"),
|
||||
("Recall", f"{sc.ents_r:.3f}"),
|
||||
("F-Score", f"{sc.ents_f:.3f}"),
|
||||
]
|
||||
msg.table(result)
|
||||
|
||||
|
||||
@plac.annotations(
|
||||
model=("The model to evaluate", "positional", None, str),
|
||||
data=("Raw data as JSONL", "positional", None, str),
|
||||
)
|
||||
def wps(model, data):
|
||||
"""
|
||||
Measure the processing speed in words per second. It's recommended to
|
||||
use a larger corpus of raw text here (e.g. a few million words).
|
||||
"""
|
||||
with msg.loading(f"Loading model '{model}'..."):
|
||||
nlp = spacy.load(model)
|
||||
texts = (eg["text"] for eg in srsly.read_jsonl(data))
|
||||
n_docs = 0
|
||||
n_words = 0
|
||||
start_time = timer()
|
||||
for doc in nlp.pipe(texts):
|
||||
n_docs += 1
|
||||
n_words += len(doc)
|
||||
end_time = timer()
|
||||
wps = int(n_words / (end_time - start_time))
|
||||
result = [
|
||||
("Docs", f"{n_docs:,}"),
|
||||
("Words", f"{n_words:,}"),
|
||||
("Words/s", f"{wps:,}"),
|
||||
]
|
||||
msg.table(result, widths=(7, 12), aligns=("l", "r"))
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
opts = {"train": train_model, "evaluate": evaluate_model, "wps": wps}
|
||||
cmd = sys.argv.pop(1)
|
||||
if cmd not in opts:
|
||||
msg.fail(f"Unknown command: {cmd}", f"Available: {', '.join(opts)}", exits=1)
|
||||
try:
|
||||
plac.call(opts[cmd])
|
||||
except KeyboardInterrupt:
|
||||
msg.warn("Stopped.", exits=1)
|
||||
@ -1,3 +0,0 @@
|
||||
|
||||
prodigy ner.correct wikiart sk_sk1 ./textfile.csv --label OSOBA,MIESTO,ORGANIZACIA,PRODUKT
|
||||
|
||||
@ -0,0 +1,2 @@
|
||||
prodigy ner.manual wikiart sk_sk1 ./textfile.csv --label PER,LOC,ORG,MISC
|
||||
|
||||
@ -0,0 +1 @@
|
||||
prodigy data-to-spacy ./train.json ./eval.json --lang sk --ner wikiart --eval-split 0.3
|
||||
@ -1 +0,0 @@
|
||||
prodigy db-out wikiart > ./annotations.jsonl
|
||||
160
pages/students/2016/jakub_maruniak/dp2021/annotation/scripts.py
Normal file
@ -0,0 +1,160 @@
|
||||
"""
|
||||
Usage example:
|
||||
$ python scripts.py delete_annot jakub.maruniak ./dataset.jsonl ./new_dataset.jsonl
|
||||
|
||||
To see available commands:
|
||||
$ python scripts.py help
|
||||
|
||||
To see available arguments:
|
||||
$ python scripts.py [command] --help
|
||||
"""
|
||||
import spacy
|
||||
import srsly
|
||||
from wasabi import msg
|
||||
import plac
|
||||
import sys
|
||||
import re
|
||||
import itertools
|
||||
|
||||
@plac.annotations(
|
||||
dataset_path=("Path to dataset (Prodigy JSONL format)", "positional", None, str),
|
||||
)
|
||||
def count(
|
||||
dataset_path
|
||||
):
|
||||
"""
|
||||
Print statistics about Prodigy JSONL dataset.
|
||||
Prints number of accepted, rejected and ignored articles.
|
||||
Prints number of annotations of each entity type.
|
||||
Prints how much annotations were made by each annotator.
|
||||
"""
|
||||
# load data
|
||||
# filename = 'ner/skner/sknerv4spans.jsonl'
|
||||
file = open(sys.argv[1], 'rt', encoding='utf-8')
|
||||
text = file.read()
|
||||
|
||||
# count articles
|
||||
countAccept = text.count('accept')
|
||||
countReject = text.count('reject')
|
||||
countSkip = text.count('ignore')
|
||||
countSpans = text.count('tokens')
|
||||
# count entities
|
||||
countPER = text.count('PER')
|
||||
countLOC = text.count('LOC')
|
||||
countORG = text.count('ORG')
|
||||
countMISC = text.count('MISC')
|
||||
|
||||
underline = '\033[04m'
|
||||
reset = '\033[0m'
|
||||
red = '\033[31m'
|
||||
green='\033[32m'
|
||||
gray='\033[37m'
|
||||
|
||||
# table v1
|
||||
#from lib import TableIt
|
||||
#table1 = [
|
||||
# ['Prijatých', countAccept],
|
||||
# ['Zamietnutých', countReject],
|
||||
# ['Preskočených', countSkip],
|
||||
# ['------------', '------------'],
|
||||
# ['Spolu', countSpans]
|
||||
#]
|
||||
#
|
||||
#table = [
|
||||
# ['Entita', 'Počet'],
|
||||
# ['PER', countPER],
|
||||
# ['LOC', countLOC],
|
||||
# ['ORG', countORG],
|
||||
# ['MISC', countMISC]
|
||||
#]
|
||||
#print('\nPočet anotovaných článkov:')
|
||||
#TableIt.printTable(table1)
|
||||
#print('\nPočet jednotlivých entít:')
|
||||
#TableIt.printTable(table, useFieldNames=True, color=(26, 156, 171))
|
||||
|
||||
# table v2
|
||||
print(underline + '\nPočet anotovaných článkov:' + reset)
|
||||
print(green + "%-15s %-20s" %("Prijatých", countAccept) + reset)
|
||||
print(red + "%-15s %-15s" %("Zamietnutých", countReject) + reset)
|
||||
print(gray + "%-15s %-15s" %("Preskočených", countSkip) + reset)
|
||||
print("%-15s" %("---------------------"))
|
||||
print("%-15s %-15s" %("Spolu", countSpans))
|
||||
|
||||
print(underline + '\nPočet jednotlivých entít:' + reset)
|
||||
print("%-10s %-10s" %("Entita:", "Počet:"))
|
||||
print("%-10s" %("----------------"))
|
||||
print("%-10s %-10s" %("PER", countPER))
|
||||
print("%-10s %-10s" %("LOC", countLOC))
|
||||
print("%-10s %-10s" %("ORG", countORG))
|
||||
print("%-10s %-10s" %("MISC", countMISC))
|
||||
|
||||
# kto anotoval koľko?
|
||||
frequency = {}
|
||||
#Open the sample text file in read mode.
|
||||
#document_text = open('sample.txt', 'r')
|
||||
#convert the string of the document in lowercase and assign it to text_string variable.
|
||||
#text = document_text.read().lower()
|
||||
regex1 = '"_session_id":(.*?),'
|
||||
pattern = re.findall(regex1, text)
|
||||
for word in pattern:
|
||||
count = frequency.get(word,0)
|
||||
frequency[word] = count + 1
|
||||
frequency_list = frequency.keys()
|
||||
print(underline + '\nKto anotoval koľko článkov?' + reset)
|
||||
for words in frequency_list:
|
||||
print(words, frequency[words])
|
||||
|
||||
|
||||
@plac.annotations(
|
||||
annotator=("Keep annotations from this annotator (email address or nickname)", "positional", None, str),
|
||||
dataset_path=("Path to dataset (Prodigy JSONL format)", "positional", None, str),
|
||||
new_dataset_path=("Path to save new dataset(Prodigy JSONL format)", "positional", None, str),
|
||||
)
|
||||
def delete_annot(
|
||||
annotator, dataset_path, new_dataset_path
|
||||
):
|
||||
"""
|
||||
Load Prodigy JSONL dataset,
|
||||
and keep annotations only from one annotator.
|
||||
"""
|
||||
file1 = open(sys.argv[2], 'r', encoding='utf-8')
|
||||
file2 = open(sys.argv[3],'w', encoding='utf-8')
|
||||
|
||||
for line in file1.readlines():
|
||||
x = re.findall(sys.argv[1], line)
|
||||
if x:
|
||||
print(line)
|
||||
file2.write(line)
|
||||
|
||||
file1.close()
|
||||
file2.close()
|
||||
|
||||
def modelinfo(
|
||||
):
|
||||
"""
|
||||
Print information about trained model (Precision, Recall and F-Score)
|
||||
"""
|
||||
with open('build/train/nerposparser/model-best/meta.json', 'rt') as f:
|
||||
for line in itertools.islice(f, 31, 54):
|
||||
print(line, end =" ")
|
||||
|
||||
def helpme(
|
||||
):
|
||||
print("Available commands:",
|
||||
"\ncount - Print statistics about Prodigy JSONL dataset",
|
||||
"\ndelete_annot - Create dataset with annotations from only specific annotator",
|
||||
"\nmodelinfo - Prints informations about trained model (Precision, Recall and F-Score)")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
opts = {"count": count,
|
||||
"delete_annot": delete_annot,
|
||||
"modelinfo": modelinfo,
|
||||
"help": helpme}
|
||||
cmd = sys.argv.pop(1)
|
||||
if cmd not in opts:
|
||||
msg.fail(f"Unknown command: {cmd}", f"Available: {', '.join(opts)}", exits=1)
|
||||
try:
|
||||
plac.call(opts[cmd])
|
||||
except KeyboardInterrupt:
|
||||
msg.warn("Stopped.", exits=1)
|
||||
@ -0,0 +1,24 @@
|
||||
set -e
|
||||
OUTDIR=build/train/output
|
||||
TRAINDIR=build/train
|
||||
|
||||
# Delete old training results
|
||||
rm -r $TRAINDIR
|
||||
|
||||
mkdir -p $TRAINDIR
|
||||
mkdir -p $OUTDIR
|
||||
mkdir -p dist
|
||||
# Delete old training results
|
||||
rm -rf $OUTDIR/*
|
||||
# Train dependency and POS
|
||||
spacy train sk $OUTDIR ./build/input/slovak-treebank ./build/input/ud-artificial-gapping --n-iter 15 -p tagger,parser
|
||||
rm -rf $TRAINDIR/posparser
|
||||
mv $OUTDIR/model-best $TRAINDIR/posparser
|
||||
# Train NER
|
||||
# custom script for training, but it takes too long... input is JSONL file (db from Prodigy)
|
||||
# python custom_train.py train ./build/train/posparser ./train.jsonl ./eval.jsonl -o ./build/train/nerposparser -n 15
|
||||
spacy train sk $TRAINDIR/nerposparser ./ner/experiments/34sknerfull.json ./ner/experiments/34wikiartfull.json --n-iter 15 -p ner
|
||||
# Package model
|
||||
spacy package $TRAINDIR/nerposparser dist --meta-path ./meta.json --force
|
||||
cd dist/sk_sk1-0.2.0
|
||||
python ./setup.py sdist --dist-dir ../
|
||||
@ -0,0 +1,80 @@
|
||||
"""
|
||||
Visualize the data with Streamlit and spaCy.
|
||||
https://github.com/explosion/projects/blob/master/ner-drugs/streamlit_visualizer.py
|
||||
|
||||
Usage example:
|
||||
$ streamlit run visualizer.py visualize ./dataset.jsonl
|
||||
"""
|
||||
import streamlit as st
|
||||
from spacy import displacy
|
||||
import srsly
|
||||
import sys
|
||||
import plac
|
||||
from wasabi import msg
|
||||
|
||||
@plac.annotations(
|
||||
dataset_path=("Path to dataset (Prodigy JSONL format)", "positional", None, str),
|
||||
)
|
||||
def visualize(
|
||||
dataset_path
|
||||
):
|
||||
FILES = [sys.argv[1]]
|
||||
MISC = "MISC"
|
||||
|
||||
HTML_WRAPPER = "<div style='border-bottom: 1px solid #ccc; padding: 20px 0'>{}</div>"
|
||||
HTML_WRAPPER1 = "<div style='border-bottom: 2px solid #000; padding: 0 0 20px 0'>{}</div>"
|
||||
SETTINGS = {"style": "ent", "manual": True, "options": {"colors": {MISC: "#d1bcff"}}}
|
||||
|
||||
@st.cache(allow_output_mutation=True)
|
||||
def load_data(filepath):
|
||||
return list(srsly.read_jsonl(filepath))
|
||||
|
||||
st.sidebar.title("Data visualizer")
|
||||
st.sidebar.markdown(
|
||||
"Visualize the annotations using [displaCy](https://spacy.io/usage/visualizers) "
|
||||
"and view stats about the datasets."
|
||||
)
|
||||
data_file = st.sidebar.selectbox("Dataset", FILES)
|
||||
data = load_data(data_file)
|
||||
n_no_ents = 0
|
||||
n_total_ents = 0
|
||||
accepted = 0
|
||||
rejected = 0
|
||||
|
||||
st.header(f"Dataset: {data_file} ({len(data)})")
|
||||
st.markdown(HTML_WRAPPER1.format("Visualize only accepted examples and their annotations."), unsafe_allow_html=True)
|
||||
for eg in data:
|
||||
if eg["answer"] == "accept":
|
||||
accepted += 1
|
||||
if eg["answer"] != "accept":
|
||||
rejected += 1
|
||||
continue
|
||||
row = {"text": eg["text"], "ents": eg.get("spans", [])}
|
||||
answer = {"answer": eg.get("answer", [])}
|
||||
n_total_ents += len(row["ents"])
|
||||
if not row["ents"]:
|
||||
n_no_ents += 1
|
||||
html = displacy.render(row, **SETTINGS).replace("\n\n", "\n")
|
||||
st.markdown(HTML_WRAPPER.format(html), unsafe_allow_html=True)
|
||||
|
||||
st.sidebar.markdown(
|
||||
f"""
|
||||
| `{data_file}` | |
|
||||
| --- | ---: |
|
||||
| Total examples | {len(data):,} |
|
||||
| Accepted examples | {accepted:,} |
|
||||
| Rejected examples | {rejected:,} |
|
||||
| Total entities | {n_total_ents:,} |
|
||||
| Examples with no entities | {n_no_ents:,} |
|
||||
""", unsafe_allow_html=True
|
||||
)
|
||||
|
||||
if __name__ == "__main__":
|
||||
opts = {"visualize": visualize}
|
||||
cmd = sys.argv.pop(1)
|
||||
if cmd not in opts:
|
||||
msg.fail(f"Unknown command: {cmd}", f"Available: {', '.join(opts)}", exits=1)
|
||||
try:
|
||||
plac.call(opts[cmd])
|
||||
except KeyboardInterrupt:
|
||||
msg.warn("Stopped.", exits=1)
|
||||
@ -0,0 +1,137 @@
|
||||
# Trénovacie experimenty
|
||||
|
||||
Do tohto súboru sa budú postupne zapisovať štatistiky a poznámky ku vykonaným trénovacím experimentom.
|
||||
|
||||
V rámci experimentu pracujeme s dvomi databázami:
|
||||
- Wikiart - vlastná anotovaná databáza článkov. Každý článok = 1 veta.
|
||||
- Skner - anotovaná databáza z https://skner.tukekemt.xyz/ . Počet viet v jednotlivých článkoch je rôzny.
|
||||
### Trénovanie Wikiart
|
||||
1. Experiment - trénovanie modelu pomocou databázy Wikiart
|
||||
|
||||

|
||||
|
||||
Celkovo 501 článkov.
|
||||
351 použitých na trénovanie, 150 na testovanie.
|
||||
15 iterácii trénovania.
|
||||
F-skóre natrénovaného modelu: 55,55%
|
||||
|
||||
| Entita | Počet anotácii | F-skóre |
|
||||
|--|--|--|
|
||||
|PER|85|41,66%|
|
||||
|LOC|240|65,51%|
|
||||
|ORG|30|0,0%|
|
||||
|MISC|42|44,44%|
|
||||
|
||||
|
||||
### Trénovanie Skner
|
||||
2. Experiment - trénovanie modelu pomocou databázy skner.
|
||||
|
||||

|
||||
|
||||
1.
|
||||
Celkovo 488 článkov.
|
||||
342 použitých na trénovanie, 146 na testovanie.
|
||||
15 iterácii trénovania.
|
||||
F-skóre natrénovaného modelu: 60,99%
|
||||
|
||||
| Entita | Počet anotácii | F-skóre |
|
||||
|--|--|--|
|
||||
|PER|376|60,07%|
|
||||
|LOC|885|67,39%|
|
||||
|ORG|149|42,10%|
|
||||
|MISC|80|8,69%|
|
||||
|
||||
2.
|
||||
Celkovo 976 článkov.
|
||||
684 použitých na trénovanie, 292 na testovanie.
|
||||
15 iterácii trénovania.
|
||||
F-skóre natrénovaného modelu: 62,9%%
|
||||
|
||||
| Entita | Počet anotácii | F-skóre |
|
||||
|--|--|--|
|
||||
|PER|684|60,68%|
|
||||
|LOC|1417|70,45%|
|
||||
|ORG|280|40,87%|
|
||||
|MISC|416|43,08%|
|
||||
|
||||
|
||||
3.
|
||||
Celkovo 2696 článkov.
|
||||
1871 použitých na trénovanie, 801 na testovanie.
|
||||
15 iterácii trénovania.
|
||||
F-skóre natrénovaného modelu: 70.33%
|
||||
|
||||
| Entita | Počet anotácii | F-skóre |
|
||||
|--|--|--|
|
||||
|PER|1886|71,08%|
|
||||
|LOC|3678|79,01%|
|
||||
|ORG|820|48,81%|
|
||||
|MISC|1171|52,38%|
|
||||
|
||||
|
||||
### 3. Experiment
|
||||
3. Experiment - na natrénovanie modelu je využitá kompletná databáza Skner. Na testovanie modelu je využitá databáza Wikiart.
|
||||
|
||||
1.verzia databázy skner - 488 článkov
|
||||
15 iterácii trénovania.
|
||||
F-skóre natrénovaného modelu: 49,67%
|
||||
|
||||
| Entita | F-skóre |
|
||||
|--|--|
|
||||
|PER|39,08%|
|
||||
|LOC|60,99%|
|
||||
|ORG|27,77%|
|
||||
|MISC|4,44%|
|
||||
|
||||
2.verzia databázy skner - 976 článkov
|
||||
15 iterácii trénovania.
|
||||
F-skóre natrénovaného modelu: 51,08%
|
||||
|
||||
| Entita | F-skóre |
|
||||
|--|--|
|
||||
|PER|38,22%|
|
||||
|LOC|60,83%|
|
||||
|ORG|33,33%|
|
||||
|MISC|30,30%|
|
||||
|
||||
3.verzia databázy skner - 2672 článkov
|
||||
15 iterácii trénovania.
|
||||
F-skóre natrénovaného modelu: 56,26%
|
||||
|
||||
| Entita | F-skóre |
|
||||
|--|--|
|
||||
|PER|45,35%|
|
||||
|LOC|67,25%|
|
||||
|ORG|31,58%|
|
||||
|MISC|39,47%|
|
||||
|
||||
### 4. Experiment
|
||||
4. Experiment - Obe databázy sme zlúčili.
|
||||
|
||||

|
||||
|
||||
1. verzia
|
||||
Celkovo 989 článkov.
|
||||
693 použitých na trénovanie, 296 na testovanie.
|
||||
15 iterácii trénovania.
|
||||
F-skóre natrénovaného modelu: 61,90%
|
||||
|
||||
| Entita | Počet anotácii | F-skóre |
|
||||
|--|--|--|
|
||||
|PER|461|54,00%|
|
||||
|LOC|1125|71,87%|
|
||||
|ORG|179|42,00%|
|
||||
|MISC|122|18,18%|
|
||||
|
||||
2. verzia
|
||||
Celkovo 3197 článkov.
|
||||
2222 použitých na trénovanie, 951 na testovanie.
|
||||
15 iterácii trénovania.
|
||||
F-skóre natrénovaného modelu: 70,48%
|
||||
|
||||
| Entita | Počet anotácii | F-skóre |
|
||||
|--|--|--|
|
||||
|PER|1971|69,18%|
|
||||
|LOC|3918|80,52%|
|
||||
|ORG|850|42,33%|
|
||||
|MISC|1213|50,24%|
|
||||
{kind=link}
|
After Width: | Height: | Size: 4.8 KiB |
{kind=link}
|
After Width: | Height: | Size: 4.9 KiB |
{kind=link}
|
After Width: | Height: | Size: 4.9 KiB |
@ -1,3 +1,11 @@
|
||||
---
|
||||
title: Crowdsourcing
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [tp2020]
|
||||
tag: [annotation,nlp]
|
||||
author: Jakub Maruniak
|
||||
---
|
||||
**Crowdsourcing**
|
||||
|
||||
Čo je to crowdsourcing? Výraz _crowdsourcing_ bol prvý krát použitý v júni 2006, kedy editor magazínu Wired, Jeff Howe, vydal článok „The Rise of Crowdsourcing" [1]. V tomto článku a v ďalších príspevkoch na svojom blogu popisuje novú organizačnú formu, koncept, pri ktorom je problém zadaný neznámej skupine riešiteľov. Zákazníci, alebo žiadatelia môžu uverejniť požadované úlohy na crowdsourcingovú platformu, kde dodávatelia – skupina, alebo jednotlivci vykonajú tieto úlohy na základe ich záujmov a schopností [2].
|
||||
|
||||
@ -3,14 +3,13 @@ title: Ján Holp
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [dp2021,bp2019]
|
||||
tag: [ir,nlp]
|
||||
tag: [ir,nlp,pagerank]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
# Ján Holp
|
||||
|
||||
*Rok začiatku štúdia*: 2016
|
||||
|
||||
|
||||
## Diplomová práca 2021
|
||||
|
||||
*Názov diplomovej práce*: Systém získavania informácií v slovenskom jazyku.
|
||||
@ -24,16 +23,121 @@ taxonomy:
|
||||
3. Navrhnite a vypracujte experimenty, v ktorých vyhodnotíte vybrané metódy odhodnotenia dokumentov.
|
||||
4. Navrhnite možné zlepšenia presnosti vyhľadávania.
|
||||
|
||||
## Diplomový projekt 2020
|
||||
Stretnutie 12.3.
|
||||
|
||||
Stav:
|
||||
|
||||
- Implementovaný PageRank, indexovanie webových stránok
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pripravte experiment s PageRank, databáza SCNC2, vyhodnotenie pomocou P-R-F1
|
||||
- Pozrite do knihy na metódy vyhodnotenta s PageRank
|
||||
- Pozrite do knihy a skúste pripraviť inú metriku.
|
||||
- Popri tom priprave demonštráciu s webovým rozhraním.
|
||||
|
||||
## Diplomový projekt 2 2020
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Urobiť verejné demo - nasadenie pomocou systému Docker
|
||||
- Urobiť verejné demo - nasadenie pomocou systému Docker. Využiť veľké slovenské dáta z internetu.
|
||||
- zlepšenie Web UI
|
||||
- vytvoriť REST api pre indexovanie dokumentu.
|
||||
- V indexe prideliť ohodnotenie každému dokumentu podľa viacerých metód, napr. PageRank
|
||||
- Využiť vyhodnotenie pri vyhľadávaní
|
||||
|
||||
- **Použiť overovaciu databázu SCNC na vyhodnotenie každej metódy**
|
||||
- **Do konca zimného semestra vytvoriť "Mini Diplomovú prácu" vo forme článku**
|
||||
- **Do konca zimného semestra vytvoriť "Mini Diplomovú prácu cca 8 strán s experimentami" vo forme článku**
|
||||
|
||||
Virtuálne stretnutie 7.1.2020:
|
||||
|
||||
Dohoda na zmene smerovania práce. Chceme:
|
||||
- Rozšíriť BP o vyhľadávanie pomocou PageRank
|
||||
- Doplniť pagerank do indexu z BP
|
||||
- zakomponovať Pagerank do vyhľadávania a zistiť ako to ovplyvnilo P-R
|
||||
- Implementovať podobným spôsobom minimálne jednu ďalšiu metriku zo študijnej literatúry
|
||||
- Zásobník úloh ostáva ak bude čas. Napr. vyrobiť demo aj z BP.
|
||||
|
||||
Virtuálne stretnutie 18.12:2020:
|
||||
|
||||
Žiaden pokrok.
|
||||
|
||||
Virtuálne stretnutie 3.1ľ:2020:
|
||||
|
||||
Riešenie technických problémov ako implementovať PageRank.
|
||||
|
||||
Virtuálne stretnutie 13.11:2020:
|
||||
|
||||
Stav:
|
||||
|
||||
- Vyriešené technické problémy s cassandrou. Vieme indexovať z Cassandra do ES.
|
||||
|
||||
Úlohy na ďalšie stretnutie:
|
||||
|
||||
- urobte návrh metódy PageRank.
|
||||
- priprave Vaše kódy do formy web aplikácie a dajte ich do repozitára.
|
||||
- backend s REST API.
|
||||
- frontend s Javascriptom.
|
||||
- skúste pripraviť Dockerfile s Vašou aplikáciou.
|
||||
|
||||
Virtuálne stretnutie 6.11:2020:
|
||||
|
||||
Stav:
|
||||
|
||||
- Riešenie problémov s cassandrou a javascriptom. Ako funguje funkcia then?
|
||||
|
||||
Úlohy na ďalšie stretnutie:
|
||||
|
||||
- vypracujte funkciu na indexovanie. Vstup je dokument (objekt s textom a metainformáciami). Fukcia zaindexuje dokument do ES.
|
||||
- Naštudujte si ako funguje funkcia then a čo je to callback.
|
||||
- Naštudujte si ako sa používa Promise.
|
||||
- Naštudujte si ako funguje async - await.
|
||||
- https://developer.mozilla.org/en-US/docs/Learn/JavaScript/Asynchronous/
|
||||
|
||||
|
||||
|
||||
Virtuálne stretnutie 23.10:2020:
|
||||
|
||||
Stav:
|
||||
- Riešenie problémov s cassandrou. Ako vybrať dáta podľa primárneho kľúča.
|
||||
|
||||
Do ďalšiehio stretnutia:
|
||||
|
||||
- pokračovať v otvorených úlohách.
|
||||
- urobte funkciu pre indexovanie jedného dokumentu.
|
||||
|
||||
Virtuálne stretnutie 16.10.
|
||||
|
||||
Stav:
|
||||
|
||||
- Riešenie problémov s pripojením na Cassandru.
|
||||
- Riešenie spôsobu výberu dát z databázy a indexovanie.
|
||||
|
||||
Do ďalšieho stretnutia:
|
||||
|
||||
- Pokračovať v otvorených úlohách z minulého stretnutia.
|
||||
|
||||
Virtuálne stretnutie 2.10.2020
|
||||
|
||||
Urobené:
|
||||
|
||||
- Výber a indexovanie dát z Cassandry
|
||||
|
||||
Do ďalšieho stretnutia:
|
||||
|
||||
- pracovať ďalej na indexovaní, použite Cassandra Javascript API
|
||||
- urobte návrh metódy PageRank
|
||||
- urobte si GIT repozitár nazvite ho dp2021 a dajte tam zdrojové kódy
|
||||
- priprave Vaše kódy do formy web aplikácie
|
||||
- backend s REST API
|
||||
- frontend s Javascriptom
|
||||
- skúste pripraviť Dockerfile s Vašou aplikáciou
|
||||
|
||||
|
||||
|
||||
|
||||
## Diplomový projekt 2020
|
||||
|
||||
|
||||
Virtuálne stretnutie 23.6.2020:
|
||||
|
||||
|
||||
@ -0,0 +1,82 @@
|
||||
//index.js
|
||||
//require the Elasticsearch librray
|
||||
const elasticsearch = require('elasticsearch');
|
||||
// instantiate an elasticsearch client
|
||||
const client = new elasticsearch.Client({
|
||||
hosts: [ 'http://localhost:9200']
|
||||
});
|
||||
//require Express
|
||||
const express = require( 'express' );
|
||||
// instanciate an instance of express and hold the value in a constant called app
|
||||
const app = express();
|
||||
//require the body-parser library. will be used for parsing body requests
|
||||
const bodyParser = require('body-parser')
|
||||
//require the path library
|
||||
const path = require( 'path' );
|
||||
|
||||
//consts
|
||||
|
||||
// ping the client to be sure Elasticsearch is up
|
||||
client.ping({
|
||||
requestTimeout: 30000,
|
||||
}, function(error) {
|
||||
// at this point, eastic search is down, please check your Elasticsearch service
|
||||
if (error) {
|
||||
console.error('elasticsearch cluster is down!');
|
||||
} else {
|
||||
console.log('Everything is ok');
|
||||
}
|
||||
});
|
||||
|
||||
|
||||
// use the bodyparser as a middleware
|
||||
app.use(bodyParser.json())
|
||||
// set port for the app to listen on
|
||||
app.set( 'port', process.env.PORT || 3001 );
|
||||
// set path to serve static files
|
||||
app.use( express.static( path.join( __dirname, 'public' )));
|
||||
// enable CORS
|
||||
app.use(function(req, res, next) {
|
||||
res.header("Access-Control-Allow-Origin", "*");
|
||||
res.header('Access-Control-Allow-Methods', 'PUT, GET, POST, DELETE, OPTIONS');
|
||||
res.header("Access-Control-Allow-Headers", "Origin, X-Requested-With, Content-Type, Accept");
|
||||
next();
|
||||
});
|
||||
|
||||
// defined the base route and return with an HTML file called tempate.html
|
||||
app.get('/', function(req, res){
|
||||
res.sendFile('template2.html', {
|
||||
root: path.join( __dirname, 'views' )
|
||||
});
|
||||
})
|
||||
|
||||
// define the /search route that should return elastic search results
|
||||
app.get('/search', function (req, res){
|
||||
// declare the query object to search elastic search and return only 200 results from the first result found.
|
||||
// also match any data where the name is like the query string sent in
|
||||
let body = {
|
||||
size: 200,
|
||||
from: 0,
|
||||
query: {
|
||||
match: {
|
||||
body: req.query['q'] // demo veryia, tato cast skriptu sa upravi abz vzhladavalo v titulkoch a tele
|
||||
}
|
||||
}
|
||||
}
|
||||
// perform the actual search passing in the index, the search query and the type
|
||||
client.search({index:'skweb2', body:body, type:'web_page'})
|
||||
.then(results => {
|
||||
res.send(results.hits.hits);
|
||||
})
|
||||
.catch(err=>{
|
||||
console.log(err)
|
||||
res.send([]);
|
||||
});
|
||||
|
||||
})
|
||||
// listen on the specified port
|
||||
app .listen( app.get( 'port' ), function(){
|
||||
console.log( 'Express server listening on port ' + app.get( 'port' ));
|
||||
} );
|
||||
|
||||
|
||||
@ -0,0 +1,143 @@
|
||||
//Jan Holp, DP 2021
|
||||
|
||||
|
||||
//client2 = cassandra
|
||||
//client1 = elasticsearch
|
||||
//-----------------------------------------------------------------
|
||||
|
||||
//require for PageRank
|
||||
var Pagerank = require('../lib/pagerank')
|
||||
var fs = require('fs')
|
||||
var path = require('path')
|
||||
|
||||
//require the Elasticsearch librray
|
||||
const elasticsearch = require('elasticsearch');
|
||||
const client1 = new elasticsearch.Client({
|
||||
hosts: [ 'localhost:9200']
|
||||
});
|
||||
client1.ping({
|
||||
requestTimeout: 30000,
|
||||
}, function(error) {
|
||||
// at this point, eastic search is down, please check your Elasticsearch service
|
||||
if (error) {
|
||||
console.error('Elasticsearch cluster is down!');
|
||||
} else {
|
||||
console.log('ELasticSearch is ok');
|
||||
}
|
||||
});
|
||||
|
||||
//create new index - skweb2
|
||||
client1.indices.create({
|
||||
index: 'skweb2'
|
||||
}, function(error, response, status) {
|
||||
if (error) {
|
||||
console.log(error);
|
||||
} else {
|
||||
console.log("created a new index", response);
|
||||
}
|
||||
});
|
||||
|
||||
//indexing method
|
||||
const bulkIndex = function bulkIndex(index, type, data) {
|
||||
let bulkBody = [];
|
||||
//id = 1;
|
||||
const errorCount = 0;
|
||||
data.forEach(item => {
|
||||
bulkBody.push({
|
||||
index: {
|
||||
_index: index,
|
||||
_type: type,
|
||||
_id : item.target_link, // documents id is url
|
||||
}
|
||||
});
|
||||
bulkBody.push(item);
|
||||
});
|
||||
console.log(bulkBody);
|
||||
//console.log(object_list.id);
|
||||
|
||||
client1.bulk({body: bulkBody})
|
||||
.then(response => {
|
||||
|
||||
response.items.forEach(item => {
|
||||
if (item.index && item.index.error) {
|
||||
console.log(++errorCount, item.index.error);
|
||||
}
|
||||
});
|
||||
console.log(
|
||||
`Successfully indexed ${data.length - errorCount}
|
||||
out of ${data.length} items`
|
||||
);
|
||||
})
|
||||
.catch(console.err);
|
||||
};
|
||||
|
||||
|
||||
const cassandra = require('cassandra-driver');
|
||||
const client2 = new cassandra.Client({ contactPoints: ['localhost:9042'], localDataCenter: 'datacenter1', keyspace: 'websucker' });
|
||||
const query1 = 'SELECT domain_name FROM websucker.domain_quality WHERE good_count > 0 ALLOW FILTERING';
|
||||
//const query2 = 'SELECT * from websucker.content WHERE domain_name = ' + domain_name[i] + 'ALLOW FILTERING'; // body_size > 0
|
||||
|
||||
//-------------------------------------------------------------------------
|
||||
|
||||
var domain_name = []; // pole domain name
|
||||
var object_list = []; // pole ktore obsahuje vsetky dokumenty pre jednotilive domain name
|
||||
const linkProb = 0.85; // high numbers are more stable (Pagerank)
|
||||
const tolerance = 0.0001; // sensitivity for accuracy of convergence
|
||||
|
||||
|
||||
client2.execute(query1) // vyselektujeme vsetky domenove mena a ulozime do pola
|
||||
.then(result => {
|
||||
let pole = result.rows.map(r => {
|
||||
domain_name.push(r.domain_name)
|
||||
});
|
||||
console.log("Vsetky domenove mena : " , domain_name);
|
||||
domain_name.forEach(name => { // pre kazde domenove meno spustime select nizsie, kt. vyberie vsetky clanky ktore niesu prazdne
|
||||
let query = 'SELECT * from websucker.content WHERE domain_name = ' + "'" + name + "'" + ' and body_size > 0 ALLOW FILTERING';
|
||||
client2.execute(query).then( res => {
|
||||
object_list = res.rows.map(rr => {
|
||||
return {
|
||||
domain_name: rr.domain_name,
|
||||
title: rr.title,
|
||||
body: rr.body,
|
||||
links: rr.links,
|
||||
target_link: rr.target_link,
|
||||
// pagerank: Pagerank(rr.links ,linkProb,tolerance, function (err, res) {
|
||||
// return res;
|
||||
// })
|
||||
}
|
||||
|
||||
|
||||
|
||||
});
|
||||
//console.log(object_list);
|
||||
bulkIndex('skweb2', 'web_page', object_list);
|
||||
}).catch(error => console.log(error));
|
||||
})
|
||||
|
||||
}).catch(err => console.log(err));
|
||||
|
||||
//volanie funkcie pre vypocet Pageranku a definovane premenne
|
||||
|
||||
//Larger numbers (0.85) //var linkProb = 0.85;
|
||||
//accuracy at which we terminate
|
||||
//--------------Pagerank
|
||||
// const linkProb = 0.85; // high numbers are more stable (Pagerank)
|
||||
// const tolerance = 0.0001; // sensitivity for accuracy of convergence
|
||||
/*
|
||||
var nodeMatrix = [
|
||||
[object_list.links]
|
||||
];
|
||||
*/
|
||||
/*
|
||||
|
||||
const PR = function PR(nodeMatrix,linkProb,tolerance){
|
||||
|
||||
Pagerank(nodeMatrix, linkProb, tolerance, function (err, res) {
|
||||
|
||||
|
||||
return res;
|
||||
//console.log(res);
|
||||
|
||||
});
|
||||
}
|
||||
*/
|
||||
@ -0,0 +1,28 @@
|
||||
(function () {
|
||||
'use strict';
|
||||
|
||||
const elasticsearch = require('elasticsearch');
|
||||
const esClient = new elasticsearch.Client({
|
||||
host: '127.0.0.1:9200',
|
||||
log: 'error'
|
||||
});
|
||||
|
||||
const indices = function indices() {
|
||||
return esClient.cat.indices({v: true})
|
||||
.then(console.log)
|
||||
.catch(err => console.error(`Error connecting to the es client: ${err}`));
|
||||
};
|
||||
|
||||
// only for testing purposes
|
||||
// all calls should be initiated through the module
|
||||
const test = function test() {
|
||||
console.log(`elasticsearch indices information:`);
|
||||
indices();
|
||||
};
|
||||
|
||||
test();
|
||||
|
||||
module.exports = {
|
||||
indices
|
||||
};
|
||||
} ());
|
||||
@ -0,0 +1,97 @@
|
||||
// From https://github.com/douglascrockford/JSON-js/blob/master/json2.js
|
||||
if (typeof JSON.parse !== "function") {
|
||||
var rx_one = /^[\],:{}\s]*$/;
|
||||
var rx_two = /\\(?:["\\\/bfnrt]|u[0-9a-fA-F]{4})/g;
|
||||
var rx_three = /"[^"\\\n\r]*"|true|false|null|-?\d+(?:\.\d*)?(?:[eE][+\-]?\d+)?/g;
|
||||
var rx_four = /(?:^|:|,)(?:\s*\[)+/g;
|
||||
var rx_dangerous = /[\u0000\u00ad\u0600-\u0604\u070f\u17b4\u17b5\u200c-\u200f\u2028-\u202f\u2060-\u206f\ufeff\ufff0-\uffff]/g;
|
||||
JSON.parse = function(text, reviver) {
|
||||
|
||||
// The parse method takes a text and an optional reviver function, and returns
|
||||
// a JavaScript value if the text is a valid JSON text.
|
||||
|
||||
var j;
|
||||
|
||||
function walk(holder, key) {
|
||||
|
||||
// The walk method is used to recursively walk the resulting structure so
|
||||
// that modifications can be made.
|
||||
|
||||
var k;
|
||||
var v;
|
||||
var value = holder[key];
|
||||
if (value && typeof value === "object") {
|
||||
for (k in value) {
|
||||
if (Object.prototype.hasOwnProperty.call(value, k)) {
|
||||
v = walk(value, k);
|
||||
if (v !== undefined) {
|
||||
value[k] = v;
|
||||
} else {
|
||||
delete value[k];
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
return reviver.call(holder, key, value);
|
||||
}
|
||||
|
||||
|
||||
// Parsing happens in four stages. In the first stage, we replace certain
|
||||
// Unicode characters with escape sequences. JavaScript handles many characters
|
||||
// incorrectly, either silently deleting them, or treating them as line endings.
|
||||
|
||||
text = String(text);
|
||||
rx_dangerous.lastIndex = 0;
|
||||
if (rx_dangerous.test(text)) {
|
||||
text = text.replace(rx_dangerous, function(a) {
|
||||
return (
|
||||
"\\u" +
|
||||
("0000" + a.charCodeAt(0).toString(16)).slice(-4)
|
||||
);
|
||||
});
|
||||
}
|
||||
|
||||
// In the second stage, we run the text against regular expressions that look
|
||||
// for non-JSON patterns. We are especially concerned with "()" and "new"
|
||||
// because they can cause invocation, and "=" because it can cause mutation.
|
||||
// But just to be safe, we want to reject all unexpected forms.
|
||||
|
||||
// We split the second stage into 4 regexp operations in order to work around
|
||||
// crippling inefficiencies in IE's and Safari's regexp engines. First we
|
||||
// replace the JSON backslash pairs with "@" (a non-JSON character). Second, we
|
||||
// replace all simple value tokens with "]" characters. Third, we delete all
|
||||
// open brackets that follow a colon or comma or that begin the text. Finally,
|
||||
// we look to see that the remaining characters are only whitespace or "]" or
|
||||
// "," or ":" or "{" or "}". If that is so, then the text is safe for eval.
|
||||
|
||||
if (
|
||||
rx_one.test(
|
||||
text
|
||||
.replace(rx_two, "@")
|
||||
.replace(rx_three, "]")
|
||||
.replace(rx_four, "")
|
||||
)
|
||||
) {
|
||||
|
||||
// In the third stage we use the eval function to compile the text into a
|
||||
// JavaScript structure. The "{" operator is subject to a syntactic ambiguity
|
||||
// in JavaScript: it can begin a block or an object literal. We wrap the text
|
||||
// in parens to eliminate the ambiguity.
|
||||
|
||||
j = eval("(" + text + ")");
|
||||
|
||||
// In the optional fourth stage, we recursively walk the new structure, passing
|
||||
// each name/value pair to a reviver function for possible transformation.
|
||||
|
||||
return (typeof reviver === "function") ?
|
||||
walk({
|
||||
"": j
|
||||
}, "") :
|
||||
j;
|
||||
}
|
||||
|
||||
// If the text is not JSON parseable, then a SyntaxError is thrown.
|
||||
|
||||
throw new SyntaxError("JSON.parse");
|
||||
};
|
||||
}
|
||||
@ -0,0 +1,109 @@
|
||||
//data.js
|
||||
|
||||
const fs = require('fs');
|
||||
const readline = require('readline');
|
||||
|
||||
|
||||
|
||||
//require the Elasticsearch librray
|
||||
const elasticsearch = require('elasticsearch');
|
||||
// instantiate an Elasticsearch client
|
||||
const client = new elasticsearch.Client({
|
||||
hosts: [ 'http://localhost:9200']
|
||||
});
|
||||
// ping the client to be sure Elasticsearch is up
|
||||
client.ping({
|
||||
requestTimeout: 30000,
|
||||
}, function(error) {
|
||||
// at this point, eastic search is down, please check your Elasticsearch service
|
||||
if (error) {
|
||||
console.error('Elasticsearch cluster is down!');
|
||||
} else {
|
||||
console.log('Everything is ok');
|
||||
}
|
||||
});
|
||||
|
||||
|
||||
|
||||
client.indices.create({
|
||||
index: 'skweb'
|
||||
}, function(error, response, status) {
|
||||
if (error) {
|
||||
console.log(error);
|
||||
} else {
|
||||
console.log("created a new index", response);
|
||||
}
|
||||
});
|
||||
|
||||
const bulkIndex = function bulkIndex(index, type, data) {
|
||||
let bulkBody = [];
|
||||
id = 1;
|
||||
const errorCount = 0;
|
||||
data.forEach(item => {
|
||||
bulkBody.push({
|
||||
index: {
|
||||
_index: index,
|
||||
_type: type,
|
||||
_id : id++,
|
||||
}
|
||||
});
|
||||
bulkBody.push(item);
|
||||
});
|
||||
console.log(bulkBody);
|
||||
client.bulk({body: bulkBody})
|
||||
.then(response => {
|
||||
|
||||
response.items.forEach(item => {
|
||||
if (item.index && item.index.error) {
|
||||
console.log(++errorCount, item.index.error);
|
||||
}
|
||||
});
|
||||
console.log(
|
||||
`Successfully indexed ${data.length - errorCount}
|
||||
out of ${data.length} items`
|
||||
);
|
||||
})
|
||||
.catch(console.err);
|
||||
};
|
||||
|
||||
async function indexData() {
|
||||
|
||||
let documents = [];
|
||||
const readInterface = readline.createInterface({
|
||||
input: fs.createReadStream('/home/jan/Documents/skweb/skusobny_subor.txt'),
|
||||
// output: process.stdout,
|
||||
console: false
|
||||
});
|
||||
readInterface.on('line', function(line) {
|
||||
//const article = JSON.parse(line);
|
||||
|
||||
try {
|
||||
const article = JSON.parse(line);
|
||||
documents.push(article);
|
||||
//console.log(JSON.parse(line));
|
||||
} catch (article) {
|
||||
if (article instanceof SyntaxError) {
|
||||
console.log( "Chyba, neplatny JSON" );
|
||||
} //else {
|
||||
//console.log(article, "bezchyby");
|
||||
//}
|
||||
}
|
||||
|
||||
// documents.push(article);
|
||||
|
||||
});
|
||||
readInterface.on('close', function() {
|
||||
//console.log(documents);
|
||||
bulkIndex('skweb', 'web_page', documents);
|
||||
});
|
||||
|
||||
|
||||
}
|
||||
|
||||
|
||||
indexData();
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
792
pages/students/2016/jan_holp/dp2021/dp2021 zdrojove subory/package-lock.json
generated
Normal file
@ -0,0 +1,792 @@
|
||||
{
|
||||
"name": "elastic-node",
|
||||
"version": "1.0.0",
|
||||
"lockfileVersion": 1,
|
||||
"requires": true,
|
||||
"dependencies": {
|
||||
"@types/long": {
|
||||
"version": "4.0.1",
|
||||
"resolved": "https://registry.npmjs.org/@types/long/-/long-4.0.1.tgz",
|
||||
"integrity": "sha512-5tXH6Bx/kNGd3MgffdmP4dy2Z+G4eaXw0SE81Tq3BNadtnMR5/ySMzX4SLEzHJzSmPNn4HIdpQsBvXMUykr58w=="
|
||||
},
|
||||
"@types/node": {
|
||||
"version": "14.11.10",
|
||||
"resolved": "https://registry.npmjs.org/@types/node/-/node-14.11.10.tgz",
|
||||
"integrity": "sha512-yV1nWZPlMFpoXyoknm4S56y2nlTAuFYaJuQtYRAOU7xA/FJ9RY0Xm7QOkaYMMmr8ESdHIuUb6oQgR/0+2NqlyA=="
|
||||
},
|
||||
"accepts": {
|
||||
"version": "1.3.7",
|
||||
"resolved": "https://registry.npmjs.org/accepts/-/accepts-1.3.7.tgz",
|
||||
"integrity": "sha512-Il80Qs2WjYlJIBNzNkK6KYqlVMTbZLXgHx2oT0pU/fjRHyEp+PEfEPY0R3WCwAGVOtauxh1hOxNgIf5bv7dQpA==",
|
||||
"requires": {
|
||||
"mime-types": "~2.1.24",
|
||||
"negotiator": "0.6.2"
|
||||
}
|
||||
},
|
||||
"adm-zip": {
|
||||
"version": "0.4.16",
|
||||
"resolved": "https://registry.npmjs.org/adm-zip/-/adm-zip-0.4.16.tgz",
|
||||
"integrity": "sha512-TFi4HBKSGfIKsK5YCkKaaFG2m4PEDyViZmEwof3MTIgzimHLto6muaHVpbrljdIvIrFZzEq/p4nafOeLcYegrg=="
|
||||
},
|
||||
"agentkeepalive": {
|
||||
"version": "3.5.2",
|
||||
"resolved": "https://registry.npmjs.org/agentkeepalive/-/agentkeepalive-3.5.2.tgz",
|
||||
"integrity": "sha512-e0L/HNe6qkQ7H19kTlRRqUibEAwDK5AFk6y3PtMsuut2VAH6+Q4xZml1tNDJD7kSAyqmbG/K08K5WEJYtUrSlQ==",
|
||||
"requires": {
|
||||
"humanize-ms": "^1.2.1"
|
||||
}
|
||||
},
|
||||
"ansi-regex": {
|
||||
"version": "2.1.1",
|
||||
"resolved": "https://registry.npmjs.org/ansi-regex/-/ansi-regex-2.1.1.tgz",
|
||||
"integrity": "sha1-w7M6te42DYbg5ijwRorn7yfWVN8="
|
||||
},
|
||||
"ansi-styles": {
|
||||
"version": "2.2.1",
|
||||
"resolved": "https://registry.npmjs.org/ansi-styles/-/ansi-styles-2.2.1.tgz",
|
||||
"integrity": "sha1-tDLdM1i2NM914eRmQ2gkBTPB3b4="
|
||||
},
|
||||
"array-filter": {
|
||||
"version": "1.0.0",
|
||||
"resolved": "https://registry.npmjs.org/array-filter/-/array-filter-1.0.0.tgz",
|
||||
"integrity": "sha1-uveeYubvTCpMC4MSMtr/7CUfnYM="
|
||||
},
|
||||
"array-flatten": {
|
||||
"version": "1.1.1",
|
||||
"resolved": "https://registry.npmjs.org/array-flatten/-/array-flatten-1.1.1.tgz",
|
||||
"integrity": "sha1-ml9pkFGx5wczKPKgCJaLZOopVdI="
|
||||
},
|
||||
"assert": {
|
||||
"version": "2.0.0",
|
||||
"resolved": "https://registry.npmjs.org/assert/-/assert-2.0.0.tgz",
|
||||
"integrity": "sha512-se5Cd+js9dXJnu6Ag2JFc00t+HmHOen+8Q+L7O9zI0PqQXr20uk2J0XQqMxZEeo5U50o8Nvmmx7dZrl+Ufr35A==",
|
||||
"requires": {
|
||||
"es6-object-assign": "^1.1.0",
|
||||
"is-nan": "^1.2.1",
|
||||
"object-is": "^1.0.1",
|
||||
"util": "^0.12.0"
|
||||
}
|
||||
},
|
||||
"available-typed-arrays": {
|
||||
"version": "1.0.2",
|
||||
"resolved": "https://registry.npmjs.org/available-typed-arrays/-/available-typed-arrays-1.0.2.tgz",
|
||||
"integrity": "sha512-XWX3OX8Onv97LMk/ftVyBibpGwY5a8SmuxZPzeOxqmuEqUCOM9ZE+uIaD1VNJ5QnvU2UQusvmKbuM1FR8QWGfQ==",
|
||||
"requires": {
|
||||
"array-filter": "^1.0.0"
|
||||
}
|
||||
},
|
||||
"body-parser": {
|
||||
"version": "1.19.0",
|
||||
"resolved": "https://registry.npmjs.org/body-parser/-/body-parser-1.19.0.tgz",
|
||||
"integrity": "sha512-dhEPs72UPbDnAQJ9ZKMNTP6ptJaionhP5cBb541nXPlW60Jepo9RV/a4fX4XWW9CuFNK22krhrj1+rgzifNCsw==",
|
||||
"requires": {
|
||||
"bytes": "3.1.0",
|
||||
"content-type": "~1.0.4",
|
||||
"debug": "2.6.9",
|
||||
"depd": "~1.1.2",
|
||||
"http-errors": "1.7.2",
|
||||
"iconv-lite": "0.4.24",
|
||||
"on-finished": "~2.3.0",
|
||||
"qs": "6.7.0",
|
||||
"raw-body": "2.4.0",
|
||||
"type-is": "~1.6.17"
|
||||
}
|
||||
},
|
||||
"bytes": {
|
||||
"version": "3.1.0",
|
||||
"resolved": "https://registry.npmjs.org/bytes/-/bytes-3.1.0.tgz",
|
||||
"integrity": "sha512-zauLjrfCG+xvoyaqLoV8bLVXXNGC4JqlxFCutSDWA6fJrTo2ZuvLYTqZ7aHBLZSMOopbzwv8f+wZcVzfVTI2Dg=="
|
||||
},
|
||||
"cassandra-driver": {
|
||||
"version": "4.6.0",
|
||||
"resolved": "https://registry.npmjs.org/cassandra-driver/-/cassandra-driver-4.6.0.tgz",
|
||||
"integrity": "sha512-OCYJ3Zuy2La0qf+7dfeYlG3X4C0ns1cbPu0hhpC3xyUWqTy1Ai9a4mlQjSBqbcHi51gdFB5UbS0fWJzZIY6NXw==",
|
||||
"requires": {
|
||||
"@types/long": "^4.0.0",
|
||||
"@types/node": ">=8",
|
||||
"adm-zip": "^0.4.13",
|
||||
"long": "^2.2.0"
|
||||
}
|
||||
},
|
||||
"chalk": {
|
||||
"version": "1.1.3",
|
||||
"resolved": "https://registry.npmjs.org/chalk/-/chalk-1.1.3.tgz",
|
||||
"integrity": "sha1-qBFcVeSnAv5NFQq9OHKCKn4J/Jg=",
|
||||
"requires": {
|
||||
"ansi-styles": "^2.2.1",
|
||||
"escape-string-regexp": "^1.0.2",
|
||||
"has-ansi": "^2.0.0",
|
||||
"strip-ansi": "^3.0.0",
|
||||
"supports-color": "^2.0.0"
|
||||
}
|
||||
},
|
||||
"content-disposition": {
|
||||
"version": "0.5.3",
|
||||
"resolved": "https://registry.npmjs.org/content-disposition/-/content-disposition-0.5.3.tgz",
|
||||
"integrity": "sha512-ExO0774ikEObIAEV9kDo50o+79VCUdEB6n6lzKgGwupcVeRlhrj3qGAfwq8G6uBJjkqLrhT0qEYFcWng8z1z0g==",
|
||||
"requires": {
|
||||
"safe-buffer": "5.1.2"
|
||||
}
|
||||
},
|
||||
"content-type": {
|
||||
"version": "1.0.4",
|
||||
"resolved": "https://registry.npmjs.org/content-type/-/content-type-1.0.4.tgz",
|
||||
"integrity": "sha512-hIP3EEPs8tB9AT1L+NUqtwOAps4mk2Zob89MWXMHjHWg9milF/j4osnnQLXBCBFBk/tvIG/tUc9mOUJiPBhPXA=="
|
||||
},
|
||||
"cookie": {
|
||||
"version": "0.4.0",
|
||||
"resolved": "https://registry.npmjs.org/cookie/-/cookie-0.4.0.tgz",
|
||||
"integrity": "sha512-+Hp8fLp57wnUSt0tY0tHEXh4voZRDnoIrZPqlo3DPiI4y9lwg/jqx+1Om94/W6ZaPDOUbnjOt/99w66zk+l1Xg=="
|
||||
},
|
||||
"cookie-signature": {
|
||||
"version": "1.0.6",
|
||||
"resolved": "https://registry.npmjs.org/cookie-signature/-/cookie-signature-1.0.6.tgz",
|
||||
"integrity": "sha1-4wOogrNCzD7oylE6eZmXNNqzriw="
|
||||
},
|
||||
"debug": {
|
||||
"version": "2.6.9",
|
||||
"resolved": "https://registry.npmjs.org/debug/-/debug-2.6.9.tgz",
|
||||
"integrity": "sha512-bC7ElrdJaJnPbAP+1EotYvqZsb3ecl5wi6Bfi6BJTUcNowp6cvspg0jXznRTKDjm/E7AdgFBVeAPVMNcKGsHMA==",
|
||||
"requires": {
|
||||
"ms": "2.0.0"
|
||||
}
|
||||
},
|
||||
"define-properties": {
|
||||
"version": "1.1.3",
|
||||
"resolved": "https://registry.npmjs.org/define-properties/-/define-properties-1.1.3.tgz",
|
||||
"integrity": "sha512-3MqfYKj2lLzdMSf8ZIZE/V+Zuy+BgD6f164e8K2w7dgnpKArBDerGYpM46IYYcjnkdPNMjPk9A6VFB8+3SKlXQ==",
|
||||
"requires": {
|
||||
"object-keys": "^1.0.12"
|
||||
}
|
||||
},
|
||||
"depd": {
|
||||
"version": "1.1.2",
|
||||
"resolved": "https://registry.npmjs.org/depd/-/depd-1.1.2.tgz",
|
||||
"integrity": "sha1-m81S4UwJd2PnSbJ0xDRu0uVgtak="
|
||||
},
|
||||
"destroy": {
|
||||
"version": "1.0.4",
|
||||
"resolved": "https://registry.npmjs.org/destroy/-/destroy-1.0.4.tgz",
|
||||
"integrity": "sha1-l4hXRCxEdJ5CBmE+N5RiBYJqvYA="
|
||||
},
|
||||
"ee-first": {
|
||||
"version": "1.1.1",
|
||||
"resolved": "https://registry.npmjs.org/ee-first/-/ee-first-1.1.1.tgz",
|
||||
"integrity": "sha1-WQxhFWsK4vTwJVcyoViyZrxWsh0="
|
||||
},
|
||||
"elasticsearch": {
|
||||
"version": "16.7.1",
|
||||
"resolved": "https://registry.npmjs.org/elasticsearch/-/elasticsearch-16.7.1.tgz",
|
||||
"integrity": "sha512-PL/BxB03VGbbghJwISYvVcrR9KbSSkuQ7OM//jHJg/End/uC2fvXg4QI7RXLvCGbhBuNQ8dPue7DOOPra73PCw==",
|
||||
"requires": {
|
||||
"agentkeepalive": "^3.4.1",
|
||||
"chalk": "^1.0.0",
|
||||
"lodash": "^4.17.10"
|
||||
}
|
||||
},
|
||||
"encodeurl": {
|
||||
"version": "1.0.2",
|
||||
"resolved": "https://registry.npmjs.org/encodeurl/-/encodeurl-1.0.2.tgz",
|
||||
"integrity": "sha1-rT/0yG7C0CkyL1oCw6mmBslbP1k="
|
||||
},
|
||||
"es-abstract": {
|
||||
"version": "1.18.0-next.1",
|
||||
"resolved": "https://registry.npmjs.org/es-abstract/-/es-abstract-1.18.0-next.1.tgz",
|
||||
"integrity": "sha512-I4UGspA0wpZXWENrdA0uHbnhte683t3qT/1VFH9aX2dA5PPSf6QW5HHXf5HImaqPmjXaVeVk4RGWnaylmV7uAA==",
|
||||
"requires": {
|
||||
"es-to-primitive": "^1.2.1",
|
||||
"function-bind": "^1.1.1",
|
||||
"has": "^1.0.3",
|
||||
"has-symbols": "^1.0.1",
|
||||
"is-callable": "^1.2.2",
|
||||
"is-negative-zero": "^2.0.0",
|
||||
"is-regex": "^1.1.1",
|
||||
"object-inspect": "^1.8.0",
|
||||
"object-keys": "^1.1.1",
|
||||
"object.assign": "^4.1.1",
|
||||
"string.prototype.trimend": "^1.0.1",
|
||||
"string.prototype.trimstart": "^1.0.1"
|
||||
}
|
||||
},
|
||||
"es-to-primitive": {
|
||||
"version": "1.2.1",
|
||||
"resolved": "https://registry.npmjs.org/es-to-primitive/-/es-to-primitive-1.2.1.tgz",
|
||||
"integrity": "sha512-QCOllgZJtaUo9miYBcLChTUaHNjJF3PYs1VidD7AwiEj1kYxKeQTctLAezAOH5ZKRH0g2IgPn6KwB4IT8iRpvA==",
|
||||
"requires": {
|
||||
"is-callable": "^1.1.4",
|
||||
"is-date-object": "^1.0.1",
|
||||
"is-symbol": "^1.0.2"
|
||||
}
|
||||
},
|
||||
"es6-object-assign": {
|
||||
"version": "1.1.0",
|
||||
"resolved": "https://registry.npmjs.org/es6-object-assign/-/es6-object-assign-1.1.0.tgz",
|
||||
"integrity": "sha1-wsNYJlYkfDnqEHyx5mUrb58kUjw="
|
||||
},
|
||||
"escape-html": {
|
||||
"version": "1.0.3",
|
||||
"resolved": "https://registry.npmjs.org/escape-html/-/escape-html-1.0.3.tgz",
|
||||
"integrity": "sha1-Aljq5NPQwJdN4cFpGI7wBR0dGYg="
|
||||
},
|
||||
"escape-string-regexp": {
|
||||
"version": "1.0.5",
|
||||
"resolved": "https://registry.npmjs.org/escape-string-regexp/-/escape-string-regexp-1.0.5.tgz",
|
||||
"integrity": "sha1-G2HAViGQqN/2rjuyzwIAyhMLhtQ="
|
||||
},
|
||||
"etag": {
|
||||
"version": "1.8.1",
|
||||
"resolved": "https://registry.npmjs.org/etag/-/etag-1.8.1.tgz",
|
||||
"integrity": "sha1-Qa4u62XvpiJorr/qg6x9eSmbCIc="
|
||||
},
|
||||
"express": {
|
||||
"version": "4.17.1",
|
||||
"resolved": "https://registry.npmjs.org/express/-/express-4.17.1.tgz",
|
||||
"integrity": "sha512-mHJ9O79RqluphRrcw2X/GTh3k9tVv8YcoyY4Kkh4WDMUYKRZUq0h1o0w2rrrxBqM7VoeUVqgb27xlEMXTnYt4g==",
|
||||
"requires": {
|
||||
"accepts": "~1.3.7",
|
||||
"array-flatten": "1.1.1",
|
||||
"body-parser": "1.19.0",
|
||||
"content-disposition": "0.5.3",
|
||||
"content-type": "~1.0.4",
|
||||
"cookie": "0.4.0",
|
||||
"cookie-signature": "1.0.6",
|
||||
"debug": "2.6.9",
|
||||
"depd": "~1.1.2",
|
||||
"encodeurl": "~1.0.2",
|
||||
"escape-html": "~1.0.3",
|
||||
"etag": "~1.8.1",
|
||||
"finalhandler": "~1.1.2",
|
||||
"fresh": "0.5.2",
|
||||
"merge-descriptors": "1.0.1",
|
||||
"methods": "~1.1.2",
|
||||
"on-finished": "~2.3.0",
|
||||
"parseurl": "~1.3.3",
|
||||
"path-to-regexp": "0.1.7",
|
||||
"proxy-addr": "~2.0.5",
|
||||
"qs": "6.7.0",
|
||||
"range-parser": "~1.2.1",
|
||||
"safe-buffer": "5.1.2",
|
||||
"send": "0.17.1",
|
||||
"serve-static": "1.14.1",
|
||||
"setprototypeof": "1.1.1",
|
||||
"statuses": "~1.5.0",
|
||||
"type-is": "~1.6.18",
|
||||
"utils-merge": "1.0.1",
|
||||
"vary": "~1.1.2"
|
||||
}
|
||||
},
|
||||
"finalhandler": {
|
||||
"version": "1.1.2",
|
||||
"resolved": "https://registry.npmjs.org/finalhandler/-/finalhandler-1.1.2.tgz",
|
||||
"integrity": "sha512-aAWcW57uxVNrQZqFXjITpW3sIUQmHGG3qSb9mUah9MgMC4NeWhNOlNjXEYq3HjRAvL6arUviZGGJsBg6z0zsWA==",
|
||||
"requires": {
|
||||
"debug": "2.6.9",
|
||||
"encodeurl": "~1.0.2",
|
||||
"escape-html": "~1.0.3",
|
||||
"on-finished": "~2.3.0",
|
||||
"parseurl": "~1.3.3",
|
||||
"statuses": "~1.5.0",
|
||||
"unpipe": "~1.0.0"
|
||||
}
|
||||
},
|
||||
"foreach": {
|
||||
"version": "2.0.5",
|
||||
"resolved": "https://registry.npmjs.org/foreach/-/foreach-2.0.5.tgz",
|
||||
"integrity": "sha1-C+4AUBiusmDQo6865ljdATbsG5k="
|
||||
},
|
||||
"forwarded": {
|
||||
"version": "0.1.2",
|
||||
"resolved": "https://registry.npmjs.org/forwarded/-/forwarded-0.1.2.tgz",
|
||||
"integrity": "sha1-mMI9qxF1ZXuMBXPozszZGw/xjIQ="
|
||||
},
|
||||
"fresh": {
|
||||
"version": "0.5.2",
|
||||
"resolved": "https://registry.npmjs.org/fresh/-/fresh-0.5.2.tgz",
|
||||
"integrity": "sha1-PYyt2Q2XZWn6g1qx+OSyOhBWBac="
|
||||
},
|
||||
"function-bind": {
|
||||
"version": "1.1.1",
|
||||
"resolved": "https://registry.npmjs.org/function-bind/-/function-bind-1.1.1.tgz",
|
||||
"integrity": "sha512-yIovAzMX49sF8Yl58fSCWJ5svSLuaibPxXQJFLmBObTuCr0Mf1KiPopGM9NiFjiYBCbfaa2Fh6breQ6ANVTI0A=="
|
||||
},
|
||||
"has": {
|
||||
"version": "1.0.3",
|
||||
"resolved": "https://registry.npmjs.org/has/-/has-1.0.3.tgz",
|
||||
"integrity": "sha512-f2dvO0VU6Oej7RkWJGrehjbzMAjFp5/VKPp5tTpWIV4JHHZK1/BxbFRtf/siA2SWTe09caDmVtYYzWEIbBS4zw==",
|
||||
"requires": {
|
||||
"function-bind": "^1.1.1"
|
||||
}
|
||||
},
|
||||
"has-ansi": {
|
||||
"version": "2.0.0",
|
||||
"resolved": "https://registry.npmjs.org/has-ansi/-/has-ansi-2.0.0.tgz",
|
||||
"integrity": "sha1-NPUEnOHs3ysGSa8+8k5F7TVBbZE=",
|
||||
"requires": {
|
||||
"ansi-regex": "^2.0.0"
|
||||
}
|
||||
},
|
||||
"has-symbols": {
|
||||
"version": "1.0.1",
|
||||
"resolved": "https://registry.npmjs.org/has-symbols/-/has-symbols-1.0.1.tgz",
|
||||
"integrity": "sha512-PLcsoqu++dmEIZB+6totNFKq/7Do+Z0u4oT0zKOJNl3lYK6vGwwu2hjHs+68OEZbTjiUE9bgOABXbP/GvrS0Kg=="
|
||||
},
|
||||
"http-errors": {
|
||||
"version": "1.7.2",
|
||||
"resolved": "https://registry.npmjs.org/http-errors/-/http-errors-1.7.2.tgz",
|
||||
"integrity": "sha512-uUQBt3H/cSIVfch6i1EuPNy/YsRSOUBXTVfZ+yR7Zjez3qjBz6i9+i4zjNaoqcoFVI4lQJ5plg63TvGfRSDCRg==",
|
||||
"requires": {
|
||||
"depd": "~1.1.2",
|
||||
"inherits": "2.0.3",
|
||||
"setprototypeof": "1.1.1",
|
||||
"statuses": ">= 1.5.0 < 2",
|
||||
"toidentifier": "1.0.0"
|
||||
}
|
||||
},
|
||||
"humanize-ms": {
|
||||
"version": "1.2.1",
|
||||
"resolved": "https://registry.npmjs.org/humanize-ms/-/humanize-ms-1.2.1.tgz",
|
||||
"integrity": "sha1-xG4xWaKT9riW2ikxbYtv6Lt5u+0=",
|
||||
"requires": {
|
||||
"ms": "^2.0.0"
|
||||
}
|
||||
},
|
||||
"iconv-lite": {
|
||||
"version": "0.4.24",
|
||||
"resolved": "https://registry.npmjs.org/iconv-lite/-/iconv-lite-0.4.24.tgz",
|
||||
"integrity": "sha512-v3MXnZAcvnywkTUEZomIActle7RXXeedOR31wwl7VlyoXO4Qi9arvSenNQWne1TcRwhCL1HwLI21bEqdpj8/rA==",
|
||||
"requires": {
|
||||
"safer-buffer": ">= 2.1.2 < 3"
|
||||
}
|
||||
},
|
||||
"inherits": {
|
||||
"version": "2.0.3",
|
||||
"resolved": "https://registry.npmjs.org/inherits/-/inherits-2.0.3.tgz",
|
||||
"integrity": "sha1-Yzwsg+PaQqUC9SRmAiSA9CCCYd4="
|
||||
},
|
||||
"ipaddr.js": {
|
||||
"version": "1.9.1",
|
||||
"resolved": "https://registry.npmjs.org/ipaddr.js/-/ipaddr.js-1.9.1.tgz",
|
||||
"integrity": "sha512-0KI/607xoxSToH7GjN1FfSbLoU0+btTicjsQSWQlh/hZykN8KpmMf7uYwPW3R+akZ6R/w18ZlXSHBYXiYUPO3g=="
|
||||
},
|
||||
"is-arguments": {
|
||||
"version": "1.0.4",
|
||||
"resolved": "https://registry.npmjs.org/is-arguments/-/is-arguments-1.0.4.tgz",
|
||||
"integrity": "sha512-xPh0Rmt8NE65sNzvyUmWgI1tz3mKq74lGA0mL8LYZcoIzKOzDh6HmrYm3d18k60nHerC8A9Km8kYu87zfSFnLA=="
|
||||
},
|
||||
"is-callable": {
|
||||
"version": "1.2.2",
|
||||
"resolved": "https://registry.npmjs.org/is-callable/-/is-callable-1.2.2.tgz",
|
||||
"integrity": "sha512-dnMqspv5nU3LoewK2N/y7KLtxtakvTuaCsU9FU50/QDmdbHNy/4/JuRtMHqRU22o3q+W89YQndQEeCVwK+3qrA=="
|
||||
},
|
||||
"is-date-object": {
|
||||
"version": "1.0.2",
|
||||
"resolved": "https://registry.npmjs.org/is-date-object/-/is-date-object-1.0.2.tgz",
|
||||
"integrity": "sha512-USlDT524woQ08aoZFzh3/Z6ch9Y/EWXEHQ/AaRN0SkKq4t2Jw2R2339tSXmwuVoY7LLlBCbOIlx2myP/L5zk0g=="
|
||||
},
|
||||
"is-generator-function": {
|
||||
"version": "1.0.7",
|
||||
"resolved": "https://registry.npmjs.org/is-generator-function/-/is-generator-function-1.0.7.tgz",
|
||||
"integrity": "sha512-YZc5EwyO4f2kWCax7oegfuSr9mFz1ZvieNYBEjmukLxgXfBUbxAWGVF7GZf0zidYtoBl3WvC07YK0wT76a+Rtw=="
|
||||
},
|
||||
"is-nan": {
|
||||
"version": "1.3.0",
|
||||
"resolved": "https://registry.npmjs.org/is-nan/-/is-nan-1.3.0.tgz",
|
||||
"integrity": "sha512-z7bbREymOqt2CCaZVly8aC4ML3Xhfi0ekuOnjO2L8vKdl+CttdVoGZQhd4adMFAsxQ5VeRVwORs4tU8RH+HFtQ==",
|
||||
"requires": {
|
||||
"define-properties": "^1.1.3"
|
||||
}
|
||||
},
|
||||
"is-negative-zero": {
|
||||
"version": "2.0.0",
|
||||
"resolved": "https://registry.npmjs.org/is-negative-zero/-/is-negative-zero-2.0.0.tgz",
|
||||
"integrity": "sha1-lVOxIbD6wohp2p7UWeIMdUN4hGE="
|
||||
},
|
||||
"is-regex": {
|
||||
"version": "1.1.1",
|
||||
"resolved": "https://registry.npmjs.org/is-regex/-/is-regex-1.1.1.tgz",
|
||||
"integrity": "sha512-1+QkEcxiLlB7VEyFtyBg94e08OAsvq7FUBgApTq/w2ymCLyKJgDPsybBENVtA7XCQEgEXxKPonG+mvYRxh/LIg==",
|
||||
"requires": {
|
||||
"has-symbols": "^1.0.1"
|
||||
}
|
||||
},
|
||||
"is-symbol": {
|
||||
"version": "1.0.3",
|
||||
"resolved": "https://registry.npmjs.org/is-symbol/-/is-symbol-1.0.3.tgz",
|
||||
"integrity": "sha512-OwijhaRSgqvhm/0ZdAcXNZt9lYdKFpcRDT5ULUuYXPoT794UNOdU+gpT6Rzo7b4V2HUl/op6GqY894AZwv9faQ==",
|
||||
"requires": {
|
||||
"has-symbols": "^1.0.1"
|
||||
}
|
||||
},
|
||||
"is-typed-array": {
|
||||
"version": "1.1.3",
|
||||
"resolved": "https://registry.npmjs.org/is-typed-array/-/is-typed-array-1.1.3.tgz",
|
||||
"integrity": "sha512-BSYUBOK/HJibQ30wWkWold5txYwMUXQct9YHAQJr8fSwvZoiglcqB0pd7vEN23+Tsi9IUEjztdOSzl4qLVYGTQ==",
|
||||
"requires": {
|
||||
"available-typed-arrays": "^1.0.0",
|
||||
"es-abstract": "^1.17.4",
|
||||
"foreach": "^2.0.5",
|
||||
"has-symbols": "^1.0.1"
|
||||
},
|
||||
"dependencies": {
|
||||
"es-abstract": {
|
||||
"version": "1.17.7",
|
||||
"resolved": "https://registry.npmjs.org/es-abstract/-/es-abstract-1.17.7.tgz",
|
||||
"integrity": "sha512-VBl/gnfcJ7OercKA9MVaegWsBHFjV492syMudcnQZvt/Dw8ezpcOHYZXa/J96O8vx+g4x65YKhxOwDUh63aS5g==",
|
||||
"requires": {
|
||||
"es-to-primitive": "^1.2.1",
|
||||
"function-bind": "^1.1.1",
|
||||
"has": "^1.0.3",
|
||||
"has-symbols": "^1.0.1",
|
||||
"is-callable": "^1.2.2",
|
||||
"is-regex": "^1.1.1",
|
||||
"object-inspect": "^1.8.0",
|
||||
"object-keys": "^1.1.1",
|
||||
"object.assign": "^4.1.1",
|
||||
"string.prototype.trimend": "^1.0.1",
|
||||
"string.prototype.trimstart": "^1.0.1"
|
||||
}
|
||||
}
|
||||
}
|
||||
},
|
||||
"lodash": {
|
||||
"version": "4.17.15",
|
||||
"resolved": "https://registry.npmjs.org/lodash/-/lodash-4.17.15.tgz",
|
||||
"integrity": "sha512-8xOcRHvCjnocdS5cpwXQXVzmmh5e5+saE2QGoeQmbKmRS6J3VQppPOIt0MnmE+4xlZoumy0GPG0D0MVIQbNA1A=="
|
||||
},
|
||||
"long": {
|
||||
"version": "2.4.0",
|
||||
"resolved": "https://registry.npmjs.org/long/-/long-2.4.0.tgz",
|
||||
"integrity": "sha1-n6GAux2VAM3CnEFWdmoZleH0Uk8="
|
||||
},
|
||||
"media-typer": {
|
||||
"version": "0.3.0",
|
||||
"resolved": "https://registry.npmjs.org/media-typer/-/media-typer-0.3.0.tgz",
|
||||
"integrity": "sha1-hxDXrwqmJvj/+hzgAWhUUmMlV0g="
|
||||
},
|
||||
"merge-descriptors": {
|
||||
"version": "1.0.1",
|
||||
"resolved": "https://registry.npmjs.org/merge-descriptors/-/merge-descriptors-1.0.1.tgz",
|
||||
"integrity": "sha1-sAqqVW3YtEVoFQ7J0blT8/kMu2E="
|
||||
},
|
||||
"methods": {
|
||||
"version": "1.1.2",
|
||||
"resolved": "https://registry.npmjs.org/methods/-/methods-1.1.2.tgz",
|
||||
"integrity": "sha1-VSmk1nZUE07cxSZmVoNbD4Ua/O4="
|
||||
},
|
||||
"mime": {
|
||||
"version": "1.6.0",
|
||||
"resolved": "https://registry.npmjs.org/mime/-/mime-1.6.0.tgz",
|
||||
"integrity": "sha512-x0Vn8spI+wuJ1O6S7gnbaQg8Pxh4NNHb7KSINmEWKiPE4RKOplvijn+NkmYmmRgP68mc70j2EbeTFRsrswaQeg=="
|
||||
},
|
||||
"mime-db": {
|
||||
"version": "1.44.0",
|
||||
"resolved": "https://registry.npmjs.org/mime-db/-/mime-db-1.44.0.tgz",
|
||||
"integrity": "sha512-/NOTfLrsPBVeH7YtFPgsVWveuL+4SjjYxaQ1xtM1KMFj7HdxlBlxeyNLzhyJVx7r4rZGJAZ/6lkKCitSc/Nmpg=="
|
||||
},
|
||||
"mime-types": {
|
||||
"version": "2.1.27",
|
||||
"resolved": "https://registry.npmjs.org/mime-types/-/mime-types-2.1.27.tgz",
|
||||
"integrity": "sha512-JIhqnCasI9yD+SsmkquHBxTSEuZdQX5BuQnS2Vc7puQQQ+8yiP5AY5uWhpdv4YL4VM5c6iliiYWPgJ/nJQLp7w==",
|
||||
"requires": {
|
||||
"mime-db": "1.44.0"
|
||||
}
|
||||
},
|
||||
"ms": {
|
||||
"version": "2.0.0",
|
||||
"resolved": "https://registry.npmjs.org/ms/-/ms-2.0.0.tgz",
|
||||
"integrity": "sha1-VgiurfwAvmwpAd9fmGF4jeDVl8g="
|
||||
},
|
||||
"negotiator": {
|
||||
"version": "0.6.2",
|
||||
"resolved": "https://registry.npmjs.org/negotiator/-/negotiator-0.6.2.tgz",
|
||||
"integrity": "sha512-hZXc7K2e+PgeI1eDBe/10Ard4ekbfrrqG8Ep+8Jmf4JID2bNg7NvCPOZN+kfF574pFQI7mum2AUqDidoKqcTOw=="
|
||||
},
|
||||
"object-inspect": {
|
||||
"version": "1.8.0",
|
||||
"resolved": "https://registry.npmjs.org/object-inspect/-/object-inspect-1.8.0.tgz",
|
||||
"integrity": "sha512-jLdtEOB112fORuypAyl/50VRVIBIdVQOSUUGQHzJ4xBSbit81zRarz7GThkEFZy1RceYrWYcPcBFPQwHyAc1gA=="
|
||||
},
|
||||
"object-is": {
|
||||
"version": "1.1.3",
|
||||
"resolved": "https://registry.npmjs.org/object-is/-/object-is-1.1.3.tgz",
|
||||
"integrity": "sha512-teyqLvFWzLkq5B9ki8FVWA902UER2qkxmdA4nLf+wjOLAWgxzCWZNCxpDq9MvE8MmhWNr+I8w3BN49Vx36Y6Xg==",
|
||||
"requires": {
|
||||
"define-properties": "^1.1.3",
|
||||
"es-abstract": "^1.18.0-next.1"
|
||||
}
|
||||
},
|
||||
"object-keys": {
|
||||
"version": "1.1.1",
|
||||
"resolved": "https://registry.npmjs.org/object-keys/-/object-keys-1.1.1.tgz",
|
||||
"integrity": "sha512-NuAESUOUMrlIXOfHKzD6bpPu3tYt3xvjNdRIQ+FeT0lNb4K8WR70CaDxhuNguS2XG+GjkyMwOzsN5ZktImfhLA=="
|
||||
},
|
||||
"object.assign": {
|
||||
"version": "4.1.1",
|
||||
"resolved": "https://registry.npmjs.org/object.assign/-/object.assign-4.1.1.tgz",
|
||||
"integrity": "sha512-VT/cxmx5yaoHSOTSyrCygIDFco+RsibY2NM0a4RdEeY/4KgqezwFtK1yr3U67xYhqJSlASm2pKhLVzPj2lr4bA==",
|
||||
"requires": {
|
||||
"define-properties": "^1.1.3",
|
||||
"es-abstract": "^1.18.0-next.0",
|
||||
"has-symbols": "^1.0.1",
|
||||
"object-keys": "^1.1.1"
|
||||
}
|
||||
},
|
||||
"on-finished": {
|
||||
"version": "2.3.0",
|
||||
"resolved": "https://registry.npmjs.org/on-finished/-/on-finished-2.3.0.tgz",
|
||||
"integrity": "sha1-IPEzZIGwg811M3mSoWlxqi2QaUc=",
|
||||
"requires": {
|
||||
"ee-first": "1.1.1"
|
||||
}
|
||||
},
|
||||
"pagerank.js": {
|
||||
"version": "1.0.2",
|
||||
"resolved": "https://registry.npmjs.org/pagerank.js/-/pagerank.js-1.0.2.tgz",
|
||||
"integrity": "sha1-jw2LK2jrb63eCq14DfBF0ib3dYQ="
|
||||
},
|
||||
"parseurl": {
|
||||
"version": "1.3.3",
|
||||
"resolved": "https://registry.npmjs.org/parseurl/-/parseurl-1.3.3.tgz",
|
||||
"integrity": "sha512-CiyeOxFT/JZyN5m0z9PfXw4SCBJ6Sygz1Dpl0wqjlhDEGGBP1GnsUVEL0p63hoG1fcj3fHynXi9NYO4nWOL+qQ=="
|
||||
},
|
||||
"path-to-regexp": {
|
||||
"version": "0.1.7",
|
||||
"resolved": "https://registry.npmjs.org/path-to-regexp/-/path-to-regexp-0.1.7.tgz",
|
||||
"integrity": "sha1-32BBeABfUi8V60SQ5yR6G/qmf4w="
|
||||
},
|
||||
"proxy-addr": {
|
||||
"version": "2.0.6",
|
||||
"resolved": "https://registry.npmjs.org/proxy-addr/-/proxy-addr-2.0.6.tgz",
|
||||
"integrity": "sha512-dh/frvCBVmSsDYzw6n926jv974gddhkFPfiN8hPOi30Wax25QZyZEGveluCgliBnqmuM+UJmBErbAUFIoDbjOw==",
|
||||
"requires": {
|
||||
"forwarded": "~0.1.2",
|
||||
"ipaddr.js": "1.9.1"
|
||||
}
|
||||
},
|
||||
"qs": {
|
||||
"version": "6.7.0",
|
||||
"resolved": "https://registry.npmjs.org/qs/-/qs-6.7.0.tgz",
|
||||
"integrity": "sha512-VCdBRNFTX1fyE7Nb6FYoURo/SPe62QCaAyzJvUjwRaIsc+NePBEniHlvxFmmX56+HZphIGtV0XeCirBtpDrTyQ=="
|
||||
},
|
||||
"range-parser": {
|
||||
"version": "1.2.1",
|
||||
"resolved": "https://registry.npmjs.org/range-parser/-/range-parser-1.2.1.tgz",
|
||||
"integrity": "sha512-Hrgsx+orqoygnmhFbKaHE6c296J+HTAQXoxEF6gNupROmmGJRoyzfG3ccAveqCBrwr/2yxQ5BVd/GTl5agOwSg=="
|
||||
},
|
||||
"raw-body": {
|
||||
"version": "2.4.0",
|
||||
"resolved": "https://registry.npmjs.org/raw-body/-/raw-body-2.4.0.tgz",
|
||||
"integrity": "sha512-4Oz8DUIwdvoa5qMJelxipzi/iJIi40O5cGV1wNYp5hvZP8ZN0T+jiNkL0QepXs+EsQ9XJ8ipEDoiH70ySUJP3Q==",
|
||||
"requires": {
|
||||
"bytes": "3.1.0",
|
||||
"http-errors": "1.7.2",
|
||||
"iconv-lite": "0.4.24",
|
||||
"unpipe": "1.0.0"
|
||||
}
|
||||
},
|
||||
"safe-buffer": {
|
||||
"version": "5.1.2",
|
||||
"resolved": "https://registry.npmjs.org/safe-buffer/-/safe-buffer-5.1.2.tgz",
|
||||
"integrity": "sha512-Gd2UZBJDkXlY7GbJxfsE8/nvKkUEU1G38c1siN6QP6a9PT9MmHB8GnpscSmMJSoF8LOIrt8ud/wPtojys4G6+g=="
|
||||
},
|
||||
"safer-buffer": {
|
||||
"version": "2.1.2",
|
||||
"resolved": "https://registry.npmjs.org/safer-buffer/-/safer-buffer-2.1.2.tgz",
|
||||
"integrity": "sha512-YZo3K82SD7Riyi0E1EQPojLz7kpepnSQI9IyPbHHg1XXXevb5dJI7tpyN2ADxGcQbHG7vcyRHk0cbwqcQriUtg=="
|
||||
},
|
||||
"send": {
|
||||
"version": "0.17.1",
|
||||
"resolved": "https://registry.npmjs.org/send/-/send-0.17.1.tgz",
|
||||
"integrity": "sha512-BsVKsiGcQMFwT8UxypobUKyv7irCNRHk1T0G680vk88yf6LBByGcZJOTJCrTP2xVN6yI+XjPJcNuE3V4fT9sAg==",
|
||||
"requires": {
|
||||
"debug": "2.6.9",
|
||||
"depd": "~1.1.2",
|
||||
"destroy": "~1.0.4",
|
||||
"encodeurl": "~1.0.2",
|
||||
"escape-html": "~1.0.3",
|
||||
"etag": "~1.8.1",
|
||||
"fresh": "0.5.2",
|
||||
"http-errors": "~1.7.2",
|
||||
"mime": "1.6.0",
|
||||
"ms": "2.1.1",
|
||||
"on-finished": "~2.3.0",
|
||||
"range-parser": "~1.2.1",
|
||||
"statuses": "~1.5.0"
|
||||
},
|
||||
"dependencies": {
|
||||
"ms": {
|
||||
"version": "2.1.1",
|
||||
"resolved": "https://registry.npmjs.org/ms/-/ms-2.1.1.tgz",
|
||||
"integrity": "sha512-tgp+dl5cGk28utYktBsrFqA7HKgrhgPsg6Z/EfhWI4gl1Hwq8B/GmY/0oXZ6nF8hDVesS/FpnYaD/kOWhYQvyg=="
|
||||
}
|
||||
}
|
||||
},
|
||||
"serve-static": {
|
||||
"version": "1.14.1",
|
||||
"resolved": "https://registry.npmjs.org/serve-static/-/serve-static-1.14.1.tgz",
|
||||
"integrity": "sha512-JMrvUwE54emCYWlTI+hGrGv5I8dEwmco/00EvkzIIsR7MqrHonbD9pO2MOfFnpFntl7ecpZs+3mW+XbQZu9QCg==",
|
||||
"requires": {
|
||||
"encodeurl": "~1.0.2",
|
||||
"escape-html": "~1.0.3",
|
||||
"parseurl": "~1.3.3",
|
||||
"send": "0.17.1"
|
||||
}
|
||||
},
|
||||
"setprototypeof": {
|
||||
"version": "1.1.1",
|
||||
"resolved": "https://registry.npmjs.org/setprototypeof/-/setprototypeof-1.1.1.tgz",
|
||||
"integrity": "sha512-JvdAWfbXeIGaZ9cILp38HntZSFSo3mWg6xGcJJsd+d4aRMOqauag1C63dJfDw7OaMYwEbHMOxEZ1lqVRYP2OAw=="
|
||||
},
|
||||
"statuses": {
|
||||
"version": "1.5.0",
|
||||
"resolved": "https://registry.npmjs.org/statuses/-/statuses-1.5.0.tgz",
|
||||
"integrity": "sha1-Fhx9rBd2Wf2YEfQ3cfqZOBR4Yow="
|
||||
},
|
||||
"string.prototype.trimend": {
|
||||
"version": "1.0.1",
|
||||
"resolved": "https://registry.npmjs.org/string.prototype.trimend/-/string.prototype.trimend-1.0.1.tgz",
|
||||
"integrity": "sha512-LRPxFUaTtpqYsTeNKaFOw3R4bxIzWOnbQ837QfBylo8jIxtcbK/A/sMV7Q+OAV/vWo+7s25pOE10KYSjaSO06g==",
|
||||
"requires": {
|
||||
"define-properties": "^1.1.3",
|
||||
"es-abstract": "^1.17.5"
|
||||
},
|
||||
"dependencies": {
|
||||
"es-abstract": {
|
||||
"version": "1.17.7",
|
||||
"resolved": "https://registry.npmjs.org/es-abstract/-/es-abstract-1.17.7.tgz",
|
||||
"integrity": "sha512-VBl/gnfcJ7OercKA9MVaegWsBHFjV492syMudcnQZvt/Dw8ezpcOHYZXa/J96O8vx+g4x65YKhxOwDUh63aS5g==",
|
||||
"requires": {
|
||||
"es-to-primitive": "^1.2.1",
|
||||
"function-bind": "^1.1.1",
|
||||
"has": "^1.0.3",
|
||||
"has-symbols": "^1.0.1",
|
||||
"is-callable": "^1.2.2",
|
||||
"is-regex": "^1.1.1",
|
||||
"object-inspect": "^1.8.0",
|
||||
"object-keys": "^1.1.1",
|
||||
"object.assign": "^4.1.1",
|
||||
"string.prototype.trimend": "^1.0.1",
|
||||
"string.prototype.trimstart": "^1.0.1"
|
||||
}
|
||||
}
|
||||
}
|
||||
},
|
||||
"string.prototype.trimstart": {
|
||||
"version": "1.0.1",
|
||||
"resolved": "https://registry.npmjs.org/string.prototype.trimstart/-/string.prototype.trimstart-1.0.1.tgz",
|
||||
"integrity": "sha512-XxZn+QpvrBI1FOcg6dIpxUPgWCPuNXvMD72aaRaUQv1eD4e/Qy8i/hFTe0BUmD60p/QA6bh1avmuPTfNjqVWRw==",
|
||||
"requires": {
|
||||
"define-properties": "^1.1.3",
|
||||
"es-abstract": "^1.17.5"
|
||||
},
|
||||
"dependencies": {
|
||||
"es-abstract": {
|
||||
"version": "1.17.7",
|
||||
"resolved": "https://registry.npmjs.org/es-abstract/-/es-abstract-1.17.7.tgz",
|
||||
"integrity": "sha512-VBl/gnfcJ7OercKA9MVaegWsBHFjV492syMudcnQZvt/Dw8ezpcOHYZXa/J96O8vx+g4x65YKhxOwDUh63aS5g==",
|
||||
"requires": {
|
||||
"es-to-primitive": "^1.2.1",
|
||||
"function-bind": "^1.1.1",
|
||||
"has": "^1.0.3",
|
||||
"has-symbols": "^1.0.1",
|
||||
"is-callable": "^1.2.2",
|
||||
"is-regex": "^1.1.1",
|
||||
"object-inspect": "^1.8.0",
|
||||
"object-keys": "^1.1.1",
|
||||
"object.assign": "^4.1.1",
|
||||
"string.prototype.trimend": "^1.0.1",
|
||||
"string.prototype.trimstart": "^1.0.1"
|
||||
}
|
||||
}
|
||||
}
|
||||
},
|
||||
"strip-ansi": {
|
||||
"version": "3.0.1",
|
||||
"resolved": "https://registry.npmjs.org/strip-ansi/-/strip-ansi-3.0.1.tgz",
|
||||
"integrity": "sha1-ajhfuIU9lS1f8F0Oiq+UJ43GPc8=",
|
||||
"requires": {
|
||||
"ansi-regex": "^2.0.0"
|
||||
}
|
||||
},
|
||||
"supports-color": {
|
||||
"version": "2.0.0",
|
||||
"resolved": "https://registry.npmjs.org/supports-color/-/supports-color-2.0.0.tgz",
|
||||
"integrity": "sha1-U10EXOa2Nj+kARcIRimZXp3zJMc="
|
||||
},
|
||||
"toidentifier": {
|
||||
"version": "1.0.0",
|
||||
"resolved": "https://registry.npmjs.org/toidentifier/-/toidentifier-1.0.0.tgz",
|
||||
"integrity": "sha512-yaOH/Pk/VEhBWWTlhI+qXxDFXlejDGcQipMlyxda9nthulaxLZUNcUqFxokp0vcYnvteJln5FNQDRrxj3YcbVw=="
|
||||
},
|
||||
"type-is": {
|
||||
"version": "1.6.18",
|
||||
"resolved": "https://registry.npmjs.org/type-is/-/type-is-1.6.18.tgz",
|
||||
"integrity": "sha512-TkRKr9sUTxEH8MdfuCSP7VizJyzRNMjj2J2do2Jr3Kym598JVdEksuzPQCnlFPW4ky9Q+iA+ma9BGm06XQBy8g==",
|
||||
"requires": {
|
||||
"media-typer": "0.3.0",
|
||||
"mime-types": "~2.1.24"
|
||||
}
|
||||
},
|
||||
"unpipe": {
|
||||
"version": "1.0.0",
|
||||
"resolved": "https://registry.npmjs.org/unpipe/-/unpipe-1.0.0.tgz",
|
||||
"integrity": "sha1-sr9O6FFKrmFltIF4KdIbLvSZBOw="
|
||||
},
|
||||
"util": {
|
||||
"version": "0.12.3",
|
||||
"resolved": "https://registry.npmjs.org/util/-/util-0.12.3.tgz",
|
||||
"integrity": "sha512-I8XkoQwE+fPQEhy9v012V+TSdH2kp9ts29i20TaaDUXsg7x/onePbhFJUExBfv/2ay1ZOp/Vsm3nDlmnFGSAog==",
|
||||
"requires": {
|
||||
"inherits": "^2.0.3",
|
||||
"is-arguments": "^1.0.4",
|
||||
"is-generator-function": "^1.0.7",
|
||||
"is-typed-array": "^1.1.3",
|
||||
"safe-buffer": "^5.1.2",
|
||||
"which-typed-array": "^1.1.2"
|
||||
}
|
||||
},
|
||||
"utils-merge": {
|
||||
"version": "1.0.1",
|
||||
"resolved": "https://registry.npmjs.org/utils-merge/-/utils-merge-1.0.1.tgz",
|
||||
"integrity": "sha1-n5VxD1CiZ5R7LMwSR0HBAoQn5xM="
|
||||
},
|
||||
"vary": {
|
||||
"version": "1.1.2",
|
||||
"resolved": "https://registry.npmjs.org/vary/-/vary-1.1.2.tgz",
|
||||
"integrity": "sha1-IpnwLG3tMNSllhsLn3RSShj2NPw="
|
||||
},
|
||||
"which-typed-array": {
|
||||
"version": "1.1.2",
|
||||
"resolved": "https://registry.npmjs.org/which-typed-array/-/which-typed-array-1.1.2.tgz",
|
||||
"integrity": "sha512-KT6okrd1tE6JdZAy3o2VhMoYPh3+J6EMZLyrxBQsZflI1QCZIxMrIYLkosd8Twf+YfknVIHmYQPgJt238p8dnQ==",
|
||||
"requires": {
|
||||
"available-typed-arrays": "^1.0.2",
|
||||
"es-abstract": "^1.17.5",
|
||||
"foreach": "^2.0.5",
|
||||
"function-bind": "^1.1.1",
|
||||
"has-symbols": "^1.0.1",
|
||||
"is-typed-array": "^1.1.3"
|
||||
},
|
||||
"dependencies": {
|
||||
"es-abstract": {
|
||||
"version": "1.17.7",
|
||||
"resolved": "https://registry.npmjs.org/es-abstract/-/es-abstract-1.17.7.tgz",
|
||||
"integrity": "sha512-VBl/gnfcJ7OercKA9MVaegWsBHFjV492syMudcnQZvt/Dw8ezpcOHYZXa/J96O8vx+g4x65YKhxOwDUh63aS5g==",
|
||||
"requires": {
|
||||
"es-to-primitive": "^1.2.1",
|
||||
"function-bind": "^1.1.1",
|
||||
"has": "^1.0.3",
|
||||
"has-symbols": "^1.0.1",
|
||||
"is-callable": "^1.2.2",
|
||||
"is-regex": "^1.1.1",
|
||||
"object-inspect": "^1.8.0",
|
||||
"object-keys": "^1.1.1",
|
||||
"object.assign": "^4.1.1",
|
||||
"string.prototype.trimend": "^1.0.1",
|
||||
"string.prototype.trimstart": "^1.0.1"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
@ -0,0 +1,19 @@
|
||||
{
|
||||
"name": "elastic-node",
|
||||
"version": "1.0.0",
|
||||
"main": "index.js",
|
||||
"scripts": {
|
||||
"test": "echo \"Error: no test specified\" && exit 1"
|
||||
},
|
||||
"author": "",
|
||||
"license": "ISC",
|
||||
"dependencies": {
|
||||
"assert": "^2.0.0",
|
||||
"body-parser": "^1.19.0",
|
||||
"cassandra-driver": "^4.6.0",
|
||||
"elasticsearch": "^16.7.1",
|
||||
"express": "^4.17.1",
|
||||
"pagerank.js": "^1.0.2"
|
||||
},
|
||||
"description": ""
|
||||
}
|
||||
@ -0,0 +1,149 @@
|
||||
//"use strict";
|
||||
// pagerank.js 0.0.1
|
||||
|
||||
//Use a random surfer algorithm to determine the relative
|
||||
//rank of nodes. The importance of each node is determined
|
||||
//by the number of incoming links as well as the importance
|
||||
//of those incoming links.
|
||||
|
||||
// Expose
|
||||
// ----------
|
||||
|
||||
//Expose our library to be called externally
|
||||
module.exports = function (nodeMatrix, linkProb, tolerance, callback, debug) {
|
||||
if (!nodeMatrix || !linkProb || !tolerance || !callback) {
|
||||
throw new Error("Provide 4 arguments: "+
|
||||
"nodeMatrix, link probability, tolerance, callback");
|
||||
}
|
||||
//If debug is unset set it to false
|
||||
if (!debug) {
|
||||
debug=false;
|
||||
}
|
||||
return new Pagerank(nodeMatrix, linkProb, tolerance, callback, debug);
|
||||
};
|
||||
|
||||
// Initialize
|
||||
// ----------
|
||||
function Pagerank(nodeMatrix, linkProb, tolerance, callback, debug) {
|
||||
//**OutgoingNodes:** represents an array of nodes. Each node in this
|
||||
//array contains an array of nodes to which the corresponding node has
|
||||
//outgoing links.
|
||||
this.outgoingNodes = nodeMatrix;
|
||||
|
||||
//console.log(this.outgoingNodes);
|
||||
//**LinkProb:** a value ??
|
||||
this.linkProb = linkProb;
|
||||
//**Tolerance:** the point at which a solution is deemed optimal.
|
||||
//Higher values are more accurate, lower values are faster to computer.
|
||||
this.tolerance = tolerance;
|
||||
this.callback = callback;
|
||||
|
||||
//Number of outgoing nodes
|
||||
this.pageCount = Object.keys(this.outgoingNodes).length;
|
||||
//console.log(this.pageCount);
|
||||
//**Coeff:** coefficient for the likelihood that a page will be visited.
|
||||
this.coeff = (1-linkProb)/this.pageCount;
|
||||
|
||||
this.probabilityNodes = !(nodeMatrix instanceof Array) ? {} : [];
|
||||
this.incomingNodes = !(nodeMatrix instanceof Array) ? {} : [];
|
||||
//console.log(this.incomingNodes);
|
||||
this.debug=debug;
|
||||
|
||||
this.startRanking();
|
||||
}
|
||||
|
||||
//Start ranking
|
||||
// ----------
|
||||
Pagerank.prototype.startRanking = function () {
|
||||
|
||||
//we initialize all of our probabilities
|
||||
var initialProbability = 1/this.pageCount,
|
||||
outgoingNodes = this.outgoingNodes, i, a, index;
|
||||
|
||||
//rearray the graph and generate initial probability
|
||||
for (i in outgoingNodes) {
|
||||
this.probabilityNodes[i]=initialProbability;
|
||||
for (a in outgoingNodes[i]) {
|
||||
index = outgoingNodes[i][a];
|
||||
if (!this.incomingNodes[index]) {
|
||||
this.incomingNodes[index]=[];
|
||||
}
|
||||
this.incomingNodes[index].push(i);
|
||||
// console.log(this.incomingNodes);
|
||||
|
||||
}
|
||||
}
|
||||
|
||||
//if debug is set, print each iteration
|
||||
if (this.debug) this.reportDebug(1)
|
||||
|
||||
this.iterate(1);
|
||||
};
|
||||
|
||||
//Log iteration to console
|
||||
// ----------
|
||||
Pagerank.prototype.reportDebug = function (count) {
|
||||
//console.log("____ITERATION "+count+"____");
|
||||
//console.log("Pages: " + Object.keys(this.outgoingNodes).length);
|
||||
//console.log("outgoing %j", this.outgoingNodes);
|
||||
//console.log("incoming %j",this.incomingNodes);
|
||||
//console.log("probability %j",this.probabilityNodes);
|
||||
};
|
||||
|
||||
|
||||
//Calculate new weights
|
||||
// ----------
|
||||
Pagerank.prototype.iterate = function(count) {
|
||||
var result = [];
|
||||
var resultHash={};
|
||||
var prob, ct, b, a, sum, res, max, min;
|
||||
|
||||
//For each node, we look at the incoming edges and
|
||||
//the weight of the node connected via each edge.
|
||||
//This weight is divided by the total number of
|
||||
//outgoing edges from each weighted node and summed to
|
||||
//determine the new weight of the original node.
|
||||
for (b in this.probabilityNodes) {
|
||||
|
||||
sum = 0;
|
||||
if( this.incomingNodes[b] ) {
|
||||
for ( a=0; a<this.incomingNodes[b].length; a++) {
|
||||
prob = this.probabilityNodes[ this.incomingNodes[b][a] ];
|
||||
ct = this.outgoingNodes[ this.incomingNodes[b][a] ].length;
|
||||
sum += (prob/ct) ;
|
||||
}
|
||||
}
|
||||
|
||||
//determine if the new probability is within tolerance.
|
||||
res = this.coeff+this.linkProb*sum;
|
||||
max = this.probabilityNodes[b]+this.tolerance;
|
||||
min = this.probabilityNodes[b]-this.tolerance;
|
||||
|
||||
//if the result has changed push that result
|
||||
if (min <= res && res<= max) {
|
||||
resultHash[b]=res;
|
||||
result.push(res);
|
||||
}
|
||||
|
||||
//update the probability for node *b*
|
||||
this.probabilityNodes[b]=res;
|
||||
//console.log(this.probabilityNodes[b]);
|
||||
//console.log(res);
|
||||
}
|
||||
|
||||
//When we have all results (no weights are changing) we return via callback
|
||||
if (result.length == this.pageCount) {
|
||||
if( !(this.outgoingNodes instanceof Array)) {
|
||||
return this.callback(null, resultHash);
|
||||
}
|
||||
return this.callback(null, result);
|
||||
}
|
||||
|
||||
//if debug is set, print each iteration
|
||||
if (this.debug) {
|
||||
this.reportDebug(count);
|
||||
}
|
||||
|
||||
++count;
|
||||
return this.iterate(count);
|
||||
};
|
||||
@ -0,0 +1,20 @@
|
||||
funguje indexovanie z cassandry do ES
|
||||
funguje vyhladavanie
|
||||
|
||||
|
||||
navod na spustenie :
|
||||
|
||||
1. vymazanie indexu :
|
||||
curl -XDELETE http://localhost:9200/skweb2/
|
||||
|
||||
2. spustenie indexovania :
|
||||
|
||||
nodejs cassandra.js
|
||||
|
||||
3. spustenie web aplikacie
|
||||
|
||||
nodejs app.js
|
||||
|
||||
4. otvorime prehliadac
|
||||
|
||||
http://localhost:3001/
|
||||
@ -0,0 +1,124 @@
|
||||
<!-- template.html -->
|
||||
<link rel="stylesheet" type="text/css" href="https://maxcdn.bootstrapcdn.com/bootstrap/3.3.7/css/bootstrap.min.css">
|
||||
<script src="https://unpkg.com/axios/dist/axios.min.js"></script>
|
||||
<script src="https://cdn.jsdelivr.net/npm/vue"></script>
|
||||
<div class="container" id="app">
|
||||
<div class="row">
|
||||
<div class="col-md-6 col-md-offset-3">
|
||||
<h1>Search engine for Slovak internet</h1>
|
||||
</div>
|
||||
</div>
|
||||
<div class="row">
|
||||
<div class="col-md-4 col-md-offset-3">
|
||||
<form action="" class="search-form">
|
||||
<div class="form-group has-feedback">
|
||||
<label for="search" class="sr-only">Search</label>
|
||||
<input type="text" class="form-control" name="search" id="search" placeholder="search" v-model="query" >
|
||||
<span class="glyphicon glyphicon-search form-control-feedback"></span>
|
||||
</div>
|
||||
</form>
|
||||
</div>
|
||||
</div>
|
||||
<div class="row">
|
||||
<div class="col-md-3" v-for="result in results">
|
||||
<div class="panel panel-default">
|
||||
<div class="panel-heading">
|
||||
{{ result._source.target_link}}
|
||||
</div>
|
||||
<div class="panel-heading">
|
||||
{{ result._source.title}}
|
||||
</div>
|
||||
<div class="panel-body">
|
||||
<!-- display the latitude and longitude of the city -->
|
||||
<p>{{ result._source.body }}</p>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
<!--- styling -->
|
||||
<style>
|
||||
.search-form .form-group {
|
||||
float: right !important;
|
||||
transition: all 0.35s, border-radius 0s;
|
||||
width: 32px;
|
||||
height: 32px;
|
||||
background-color: #fff;
|
||||
box-shadow: 0 1px 1px rgba(0, 0, 0, 0.075) inset;
|
||||
border-radius: 25px;
|
||||
border: 1px solid #ccc;
|
||||
}
|
||||
|
||||
.search-form .form-group input.form-control {
|
||||
padding-right: 20px;
|
||||
border: 0 none;
|
||||
background: transparent;
|
||||
box-shadow: none;
|
||||
display: block;
|
||||
}
|
||||
|
||||
.search-form .form-group input.form-control::-webkit-input-placeholder {
|
||||
display: none;
|
||||
}
|
||||
|
||||
.search-form .form-group input.form-control:-moz-placeholder {
|
||||
/* Firefox 18- */
|
||||
display: none;
|
||||
}
|
||||
|
||||
.search-form .form-group input.form-control::-moz-placeholder {
|
||||
/* Firefox 19+ */
|
||||
display: none;
|
||||
}
|
||||
|
||||
.search-form .form-group input.form-control:-ms-input-placeholder {
|
||||
display: none;
|
||||
}
|
||||
|
||||
.search-form .form-group:hover,
|
||||
.search-form .form-group.hover {
|
||||
width: 100%;
|
||||
border-radius: 4px 25px 25px 4px;
|
||||
}
|
||||
|
||||
.search-form .form-group span.form-control-feedback {
|
||||
position: absolute;
|
||||
top: -1px;
|
||||
right: -2px;
|
||||
z-index: 2;
|
||||
display: block;
|
||||
width: 34px;
|
||||
height: 34px;
|
||||
line-height: 34px;
|
||||
text-align: center;
|
||||
color: #3596e0;
|
||||
left: initial;
|
||||
font-size: 14px;
|
||||
}
|
||||
</style>
|
||||
|
||||
<script>
|
||||
var app = new Vue({
|
||||
el: '#app',
|
||||
data: {
|
||||
results: [],
|
||||
query: ''
|
||||
},
|
||||
methods: {
|
||||
search: function() {
|
||||
axios.get("http://127.0.0.1:3001/search?q=" + this.query)
|
||||
.then(response => {
|
||||
this.results = response.data;
|
||||
console.log(response.data);
|
||||
|
||||
})
|
||||
}
|
||||
},
|
||||
watch: {
|
||||
query: function() {
|
||||
this.search();
|
||||
}
|
||||
}
|
||||
|
||||
})
|
||||
</script>
|
||||
105
pages/students/2016/jan_holp/dp2021/zdrojove_subory/cassandra.js
Normal file
@ -0,0 +1,105 @@
|
||||
//Jan Holp, DP 2021
|
||||
|
||||
|
||||
//client1 = cassandra
|
||||
//client2 = elasticsearch
|
||||
//-----------------------------------------------------------------
|
||||
|
||||
//require the Elasticsearch librray
|
||||
const elasticsearch = require('elasticsearch');
|
||||
const client2 = new elasticsearch.Client({
|
||||
hosts: [ 'localhost:9200']
|
||||
});
|
||||
client2.ping({
|
||||
requestTimeout: 30000,
|
||||
}, function(error) {
|
||||
// at this point, eastic search is down, please check your Elasticsearch service
|
||||
if (error) {
|
||||
console.error('Elasticsearch cluster is down!');
|
||||
} else {
|
||||
console.log('Everything is ok');
|
||||
}
|
||||
});
|
||||
|
||||
//create new index skweb2
|
||||
client2.indices.create({
|
||||
index: 'skweb2'
|
||||
}, function(error, response, status) {
|
||||
if (error) {
|
||||
console.log(error);
|
||||
} else {
|
||||
console.log("created a new index", response);
|
||||
}
|
||||
});
|
||||
|
||||
const cassandra = require('cassandra-driver');
|
||||
const client1 = new cassandra.Client({ contactPoints: ['localhost:9042'], localDataCenter: 'datacenter1', keyspace: 'websucker' });
|
||||
const query = 'SELECT title FROM websucker.content WHERE body_size > 0 ALLOW FILTERING';
|
||||
client1.execute(query)
|
||||
.then(result => console.log(result)),function(error) {
|
||||
if(error){
|
||||
console.error('Something is wrong!');
|
||||
console.log(error);
|
||||
} else{
|
||||
console.log('Everything is ok');
|
||||
}
|
||||
};
|
||||
|
||||
/*
|
||||
async function indexData() {
|
||||
|
||||
var i = 0;
|
||||
const query = 'SELECT title FROM websucker.content WHERE body_size > 0 ALLOW FILTERING';
|
||||
client1.execute(query)
|
||||
.then((result) => {
|
||||
try {
|
||||
//for ( i=0; i<15;i++){
|
||||
console.log('%s', result.row[0].title)
|
||||
//}
|
||||
} catch (query) {
|
||||
if (query instanceof SyntaxError) {
|
||||
console.log( "Neplatne query" );
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
|
||||
});
|
||||
|
||||
|
||||
}
|
||||
|
||||
/*
|
||||
|
||||
//indexing method
|
||||
const bulkIndex = function bulkIndex(index, type, data) {
|
||||
let bulkBody = [];
|
||||
id = 1;
|
||||
const errorCount = 0;
|
||||
data.forEach(item => {
|
||||
bulkBody.push({
|
||||
index: {
|
||||
_index: index,
|
||||
_type: type,
|
||||
_id : id++,
|
||||
}
|
||||
});
|
||||
bulkBody.push(item);
|
||||
});
|
||||
console.log(bulkBody);
|
||||
client.bulk({body: bulkBody})
|
||||
.then(response => {
|
||||
|
||||
response.items.forEach(item => {
|
||||
if (item.index && item.index.error) {
|
||||
console.log(++errorCount, item.index.error);
|
||||
}
|
||||
});
|
||||
console.log(
|
||||
`Successfully indexed ${data.length - errorCount}
|
||||
out of ${data.length} items`
|
||||
);
|
||||
})
|
||||
.catch(console.err);
|
||||
};
|
||||
*/
|
||||
@ -1,3 +1,11 @@
|
||||
---
|
||||
title: Získavanie informácií
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [tp2020]
|
||||
tag: [ir,nlp]
|
||||
author: Ján Holp
|
||||
---
|
||||
# Tímový projekt
|
||||
|
||||
# Learning to Rank for Information Retrieval and Natural Language Processing
|
||||
|
||||
@ -10,22 +10,117 @@ taxonomy:
|
||||
|
||||
*Rok začiatku štúdia:* 2016
|
||||
|
||||
|
||||
Názov: Paralelné trénovanie neurónových sietí
|
||||
|
||||
*Meno vedúceho:* Ing. Daniel Hládek, PhD.
|
||||
|
||||
## Diplomová práca 2021
|
||||
|
||||
1. Vypracujte prehľad literatúry na tému "Paralelné trénovanie neurónových sietí".
|
||||
2. Vyberte vhodnú metódu paralelného trénovania.
|
||||
3. Pripravte dáta a vykonajte sadu experimentov pre overenie funkčnosti a výkonu paralelného trénovania.
|
||||
4. Navrhnite možné zlepšenia paralelného trénovania neurónových sietí.
|
||||
|
||||
|
||||
|
||||
Stretnutie: 5.3.2021
|
||||
|
||||
Stav:
|
||||
|
||||
- Urobené trénovanie na dvoch servroch pomocou distributed_data_parallel MNIST.
|
||||
- Funguje LUNA dataset (na 1 stroji a na viacerých kartách).
|
||||
|
||||
|
||||
|
||||
## Diplomový projekt 2 2020
|
||||
|
||||
Ciele na semester:
|
||||
- Pripraviť tabuľku s výsledkami experimentov v rôznych konfiguráciách
|
||||
- Napísať stručný report (cca 8 strán) vo forme článku.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Ten istý scenár spustiť v rôznych podmienkach a zmerať čas.
|
||||
- Trénovanie na jednej karte na jednom stroji
|
||||
- tesla
|
||||
- xavier
|
||||
- Trénovanie na dvoch kartách na jednom stroji
|
||||
- idoc DONE
|
||||
- titan
|
||||
- možno trénovanie na 4 kartách na jednom
|
||||
- quadra
|
||||
- *Trénovanie na dvoch kartách na dvoch strojoch pomocou NCCL (idoc, tesla)*
|
||||
- možno trénovanie na 2 kartách na dvoch strojoch (quadra plus idoc).
|
||||
|
||||
Virtuálne stretnutie 4.12.2020
|
||||
|
||||
Stav:
|
||||
- Vyriešený problém s CUDA Compute Capability. Každý conda baliček podporuje inú verziu CC. Aktuálna verzia Pytorch pracuje iba s Compute Capability 3.7 a viac. Conda Pytorch 1.3 vyžaduje CC 3.7. Tesla karta podporuje iba 3.5. Podpora CC sa dá pridať inštaláciou zo zdroja. Funguje cuda 10.0.
|
||||
- Podarilo sa natrénovať MNIST na dvoch strojoch naraz - idoc + tesla. Pytorch 1.4, wrapper distributed_data_paralel. NCCL backend. Na každom stroji sa používa rovnaký počet GPU. GPU môžu byť rôzne.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Doplniť tabuľku podpory CC v Pytorch.
|
||||
- Opísať problém s Compute Capability. Čo je to CC?
|
||||
- Napísať "tutoriál" ako paralelne trénovať pomocou distributed_data_parallel a NCCL. Napíšte aký setup (verzia pytorch, verzia cuda, požiaadavky na GPU ..) si paralelné trénovanie vyžaduje.
|
||||
- Opísať testovacie úlohy ktoré používate
|
||||
- Vypracujte tabuľku s vykonanými experimentami.
|
||||
- Skúste trénovanie na xavier, skompilovaný Pytorch je v adresári hladek.
|
||||
- Quadru prediskutovať (vedúci).
|
||||
|
||||
|
||||
Virtuálne stretnutie 13.11.2020
|
||||
|
||||
Stav:
|
||||
|
||||
- Preštudovaná kniha "Deep Learning with PyTorch" o multi GPU tréningu.
|
||||
- vyskúšaný LUNA dataset, CT torza pre detekciu rakoviny pľúc - 60GB dát. Dáta sa predpripravia a uložia do cache. 10 epoch trvá 1 hod na bežnom počítači. Nastal problém s "Compute Capability" - kompatibilita verzie CUDA, Pytorch a GPU Tesla V40.
|
||||
- vyskúšaný wrapper data_paralel, distribute_data_parallel (trénovanie pytorch v klastri).
|
||||
- Pytorch Lightning - cluster trénovanie Pytorch cez Slurm.
|
||||
|
||||
Úlohy na ďalšie stretnutie:
|
||||
|
||||
- Pracujte na písomnej časti.
|
||||
- Pokračujte na benchmark experimentoch - trénovanie na viacerých strojoch (idoc a tesla) naraz.
|
||||
|
||||
Virtuálne stretnutie 27.10.2020
|
||||
|
||||
Stav:
|
||||
|
||||
- Trénovanie na procesore, na 1 GPU, na 2 GPU na idoc
|
||||
- Príprava podkladov na trénovanie na dvoch strojoch pomocou Pytorch.
|
||||
- Vytvorený prístup na teslu a xavier.
|
||||
|
||||
Úlohy na ďďalšie stretnutie:
|
||||
- Štdúdium odbornej literatúry a vypracovanie poznámok.
|
||||
- Pokračovať v otvorených úlohách zo zásobníka
|
||||
- Vypracované skripty uložiť na GIT repozitár
|
||||
- vytvorte repozitár dp2021
|
||||
|
||||
Stretnutie 2.10.2020
|
||||
|
||||
Urobené https://github.com/LukasPokryvka/YELP-on-GPU
|
||||
|
||||
- demonštračná úloha pre automatické hodnotenie reštaurácií na základe recenzie v anglickom jazyku, dátová sada yelp.
|
||||
- preštudovaná kniha NLP with Pytorch, NLP in Action.
|
||||
- trénovanie na NVIDIA RTX2070 Super.
|
||||
|
||||
Úlohy do ďalšieho stretnutia:
|
||||
- Prejsť odborné publikácie na tému "benchmarking" a "parallel training of neural networks".
|
||||
- Zapísať si relevantné bibliografické odkazy.
|
||||
- Zapísať poznámky
|
||||
- Použiť index scopus alebo scholar
|
||||
- Trénovanie na jednej karte na jednom stroji
|
||||
- tesla.fei.tuke.sk
|
||||
- Trénovanie na dvoch kartách na jednom stroji - zistite čas trénovania a spotrebu pamäte.
|
||||
- idoc
|
||||
|
||||
|
||||
|
||||
## Diplomový projekt 1 2020
|
||||
|
||||
Paralelné trénovanie neurónových sietí pomocou knižnice Pytorch.
|
||||
|
||||
Zásobník úloh na ďalší semester:
|
||||
|
||||
- Vybrať a prejsť scenár trénovania neurónových sietí pomocou nástroja [Fairseq](https://github.com/pytorch/fairseq/tree/master/examples), napr. (https://github.com/pytorch/fairseq/blob/master/examples/roberta/README.pretraining.md)
|
||||
- Prejsť odborné publikácie na tému "benchmarking" a "parallel training of neural networks".
|
||||
- Ten istý scenár spustiť v rôznych podmienkach a zmerať čas.
|
||||
|
||||
- Trénovanie na jednej karte na jednom stroji (máme rôzne - idoc, nový xavier)
|
||||
- Trénovanie na dvoch kartách na jednom stroji (idoc, nový server)
|
||||
- *Trénovanie na dvoch kartách na dvoch strojoch pomocou NCCL (idoc, tesla)*
|
||||
- možno trénovanie na 4 kartách na jednom stroji (quadra).
|
||||
- možno trénovanie na 2 kartách na dvoch strojoch (quadra plus idoc).
|
||||
|
||||
Úlohy na semester:
|
||||
|
||||
- podrobne si naštudovať vybranú metódu trénovania neurónových sietí
|
||||
@ -103,18 +198,6 @@ Stretnutie 9.3.2020
|
||||
|
||||
*Písomná práca:* [Paralelné spracovanie prirodzeného jazyka](./timovy_projekt)
|
||||
|
||||
## Diplomová práca 2021
|
||||
|
||||
### Paralelné trénovanie neurónových sietí
|
||||
|
||||
*Meno vedúceho:* Ing. Daniel Hládek, PhD.
|
||||
|
||||
*Návrh na zadanie DP:*
|
||||
|
||||
1. Vypracujte prehľad literatúry na tému "Paralelné trénovanie neurónových sietí".
|
||||
2. Vyberte vhodnú metódu paralelného trénovania.
|
||||
3. Pripravte dáta a vykonajte sadu experimentov pre overenie funkčnosti a výkonu paralelného trénovania.
|
||||
4. Navrhnite možné zlepšenia paralelného trénovania neurónových sietí.
|
||||
|
||||
|
||||
- Zaujímavá príručka [Word2vec na Spark](http://spark.apache.org/docs/latest/ml-features.html#word2vec)
|
||||
|
||||
@ -1 +1,4 @@
|
||||
## Všetky skripty, súbory a konfigurácie
|
||||
|
||||
https://github.com/pytorch/examples/tree/master/imagenet
|
||||
- malo by fungovat pre DDP, nedostupny imagenet subor z oficialnej stranky
|
||||
@ -0,0 +1,76 @@
|
||||
import argparse
|
||||
import datetime
|
||||
import os
|
||||
import socket
|
||||
import sys
|
||||
|
||||
import numpy as np
|
||||
from torch.utils.tensorboard import SummaryWriter
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.optim
|
||||
|
||||
from torch.optim import SGD, Adam
|
||||
from torch.utils.data import DataLoader
|
||||
|
||||
from util.util import enumerateWithEstimate
|
||||
from p2ch13.dsets import Luna2dSegmentationDataset, TrainingLuna2dSegmentationDataset, getCt
|
||||
from util.logconf import logging
|
||||
from util.util import xyz2irc
|
||||
from p2ch13.model_seg import UNetWrapper, SegmentationAugmentation
|
||||
from p2ch13.train_seg import LunaTrainingApp
|
||||
|
||||
log = logging.getLogger(__name__)
|
||||
# log.setLevel(logging.WARN)
|
||||
# log.setLevel(logging.INFO)
|
||||
log.setLevel(logging.DEBUG)
|
||||
|
||||
class BenchmarkLuna2dSegmentationDataset(TrainingLuna2dSegmentationDataset):
|
||||
def __len__(self):
|
||||
# return 500
|
||||
return 5000
|
||||
return 1000
|
||||
|
||||
class LunaBenchmarkApp(LunaTrainingApp):
|
||||
def initTrainDl(self):
|
||||
train_ds = BenchmarkLuna2dSegmentationDataset(
|
||||
val_stride=10,
|
||||
isValSet_bool=False,
|
||||
contextSlices_count=3,
|
||||
# augmentation_dict=self.augmentation_dict,
|
||||
)
|
||||
|
||||
batch_size = self.cli_args.batch_size
|
||||
if self.use_cuda:
|
||||
batch_size *= torch.cuda.device_count()
|
||||
|
||||
train_dl = DataLoader(
|
||||
train_ds,
|
||||
batch_size=batch_size,
|
||||
num_workers=self.cli_args.num_workers,
|
||||
pin_memory=self.use_cuda,
|
||||
)
|
||||
|
||||
return train_dl
|
||||
|
||||
def main(self):
|
||||
log.info("Starting {}, {}".format(type(self).__name__, self.cli_args))
|
||||
|
||||
train_dl = self.initTrainDl()
|
||||
|
||||
for epoch_ndx in range(1, 2):
|
||||
log.info("Epoch {} of {}, {}/{} batches of size {}*{}".format(
|
||||
epoch_ndx,
|
||||
self.cli_args.epochs,
|
||||
len(train_dl),
|
||||
len([]),
|
||||
self.cli_args.batch_size,
|
||||
(torch.cuda.device_count() if self.use_cuda else 1),
|
||||
))
|
||||
|
||||
self.doTraining(epoch_ndx, train_dl)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
LunaBenchmarkApp().main()
|
||||
@ -0,0 +1,401 @@
|
||||
import copy
|
||||
import csv
|
||||
import functools
|
||||
import glob
|
||||
import math
|
||||
import os
|
||||
import random
|
||||
|
||||
from collections import namedtuple
|
||||
|
||||
import SimpleITK as sitk
|
||||
import numpy as np
|
||||
import scipy.ndimage.morphology as morph
|
||||
|
||||
import torch
|
||||
import torch.cuda
|
||||
import torch.nn.functional as F
|
||||
from torch.utils.data import Dataset
|
||||
|
||||
from util.disk import getCache
|
||||
from util.util import XyzTuple, xyz2irc
|
||||
from util.logconf import logging
|
||||
|
||||
log = logging.getLogger(__name__)
|
||||
# log.setLevel(logging.WARN)
|
||||
# log.setLevel(logging.INFO)
|
||||
log.setLevel(logging.DEBUG)
|
||||
|
||||
raw_cache = getCache('part2ch13_raw')
|
||||
|
||||
MaskTuple = namedtuple('MaskTuple', 'raw_dense_mask, dense_mask, body_mask, air_mask, raw_candidate_mask, candidate_mask, lung_mask, neg_mask, pos_mask')
|
||||
|
||||
CandidateInfoTuple = namedtuple('CandidateInfoTuple', 'isNodule_bool, hasAnnotation_bool, isMal_bool, diameter_mm, series_uid, center_xyz')
|
||||
|
||||
@functools.lru_cache(1)
|
||||
def getCandidateInfoList(requireOnDisk_bool=True):
|
||||
# We construct a set with all series_uids that are present on disk.
|
||||
# This will let us use the data, even if we haven't downloaded all of
|
||||
# the subsets yet.
|
||||
mhd_list = glob.glob('data-unversioned/subset*/*.mhd')
|
||||
presentOnDisk_set = {os.path.split(p)[-1][:-4] for p in mhd_list}
|
||||
|
||||
candidateInfo_list = []
|
||||
with open('data/annotations_with_malignancy.csv', "r") as f:
|
||||
for row in list(csv.reader(f))[1:]:
|
||||
series_uid = row[0]
|
||||
annotationCenter_xyz = tuple([float(x) for x in row[1:4]])
|
||||
annotationDiameter_mm = float(row[4])
|
||||
isMal_bool = {'False': False, 'True': True}[row[5]]
|
||||
|
||||
candidateInfo_list.append(
|
||||
CandidateInfoTuple(
|
||||
True,
|
||||
True,
|
||||
isMal_bool,
|
||||
annotationDiameter_mm,
|
||||
series_uid,
|
||||
annotationCenter_xyz,
|
||||
)
|
||||
)
|
||||
|
||||
with open('data/candidates.csv', "r") as f:
|
||||
for row in list(csv.reader(f))[1:]:
|
||||
series_uid = row[0]
|
||||
|
||||
if series_uid not in presentOnDisk_set and requireOnDisk_bool:
|
||||
continue
|
||||
|
||||
isNodule_bool = bool(int(row[4]))
|
||||
candidateCenter_xyz = tuple([float(x) for x in row[1:4]])
|
||||
|
||||
if not isNodule_bool:
|
||||
candidateInfo_list.append(
|
||||
CandidateInfoTuple(
|
||||
False,
|
||||
False,
|
||||
False,
|
||||
0.0,
|
||||
series_uid,
|
||||
candidateCenter_xyz,
|
||||
)
|
||||
)
|
||||
|
||||
candidateInfo_list.sort(reverse=True)
|
||||
return candidateInfo_list
|
||||
|
||||
@functools.lru_cache(1)
|
||||
def getCandidateInfoDict(requireOnDisk_bool=True):
|
||||
candidateInfo_list = getCandidateInfoList(requireOnDisk_bool)
|
||||
candidateInfo_dict = {}
|
||||
|
||||
for candidateInfo_tup in candidateInfo_list:
|
||||
candidateInfo_dict.setdefault(candidateInfo_tup.series_uid,
|
||||
[]).append(candidateInfo_tup)
|
||||
|
||||
return candidateInfo_dict
|
||||
|
||||
class Ct:
|
||||
def __init__(self, series_uid):
|
||||
mhd_path = glob.glob(
|
||||
'data-unversioned/subset*/{}.mhd'.format(series_uid)
|
||||
)[0]
|
||||
|
||||
ct_mhd = sitk.ReadImage(mhd_path)
|
||||
self.hu_a = np.array(sitk.GetArrayFromImage(ct_mhd), dtype=np.float32)
|
||||
|
||||
# CTs are natively expressed in https://en.wikipedia.org/wiki/Hounsfield_scale
|
||||
# HU are scaled oddly, with 0 g/cc (air, approximately) being -1000 and 1 g/cc (water) being 0.
|
||||
|
||||
self.series_uid = series_uid
|
||||
|
||||
self.origin_xyz = XyzTuple(*ct_mhd.GetOrigin())
|
||||
self.vxSize_xyz = XyzTuple(*ct_mhd.GetSpacing())
|
||||
self.direction_a = np.array(ct_mhd.GetDirection()).reshape(3, 3)
|
||||
|
||||
candidateInfo_list = getCandidateInfoDict()[self.series_uid]
|
||||
|
||||
self.positiveInfo_list = [
|
||||
candidate_tup
|
||||
for candidate_tup in candidateInfo_list
|
||||
if candidate_tup.isNodule_bool
|
||||
]
|
||||
self.positive_mask = self.buildAnnotationMask(self.positiveInfo_list)
|
||||
self.positive_indexes = (self.positive_mask.sum(axis=(1,2))
|
||||
.nonzero()[0].tolist())
|
||||
|
||||
def buildAnnotationMask(self, positiveInfo_list, threshold_hu = -700):
|
||||
boundingBox_a = np.zeros_like(self.hu_a, dtype=np.bool)
|
||||
|
||||
for candidateInfo_tup in positiveInfo_list:
|
||||
center_irc = xyz2irc(
|
||||
candidateInfo_tup.center_xyz,
|
||||
self.origin_xyz,
|
||||
self.vxSize_xyz,
|
||||
self.direction_a,
|
||||
)
|
||||
ci = int(center_irc.index)
|
||||
cr = int(center_irc.row)
|
||||
cc = int(center_irc.col)
|
||||
|
||||
index_radius = 2
|
||||
try:
|
||||
while self.hu_a[ci + index_radius, cr, cc] > threshold_hu and \
|
||||
self.hu_a[ci - index_radius, cr, cc] > threshold_hu:
|
||||
index_radius += 1
|
||||
except IndexError:
|
||||
index_radius -= 1
|
||||
|
||||
row_radius = 2
|
||||
try:
|
||||
while self.hu_a[ci, cr + row_radius, cc] > threshold_hu and \
|
||||
self.hu_a[ci, cr - row_radius, cc] > threshold_hu:
|
||||
row_radius += 1
|
||||
except IndexError:
|
||||
row_radius -= 1
|
||||
|
||||
col_radius = 2
|
||||
try:
|
||||
while self.hu_a[ci, cr, cc + col_radius] > threshold_hu and \
|
||||
self.hu_a[ci, cr, cc - col_radius] > threshold_hu:
|
||||
col_radius += 1
|
||||
except IndexError:
|
||||
col_radius -= 1
|
||||
|
||||
# assert index_radius > 0, repr([candidateInfo_tup.center_xyz, center_irc, self.hu_a[ci, cr, cc]])
|
||||
# assert row_radius > 0
|
||||
# assert col_radius > 0
|
||||
|
||||
boundingBox_a[
|
||||
ci - index_radius: ci + index_radius + 1,
|
||||
cr - row_radius: cr + row_radius + 1,
|
||||
cc - col_radius: cc + col_radius + 1] = True
|
||||
|
||||
mask_a = boundingBox_a & (self.hu_a > threshold_hu)
|
||||
|
||||
return mask_a
|
||||
|
||||
def getRawCandidate(self, center_xyz, width_irc):
|
||||
center_irc = xyz2irc(center_xyz, self.origin_xyz, self.vxSize_xyz,
|
||||
self.direction_a)
|
||||
|
||||
slice_list = []
|
||||
for axis, center_val in enumerate(center_irc):
|
||||
start_ndx = int(round(center_val - width_irc[axis]/2))
|
||||
end_ndx = int(start_ndx + width_irc[axis])
|
||||
|
||||
assert center_val >= 0 and center_val < self.hu_a.shape[axis], repr([self.series_uid, center_xyz, self.origin_xyz, self.vxSize_xyz, center_irc, axis])
|
||||
|
||||
if start_ndx < 0:
|
||||
# log.warning("Crop outside of CT array: {} {}, center:{} shape:{} width:{}".format(
|
||||
# self.series_uid, center_xyz, center_irc, self.hu_a.shape, width_irc))
|
||||
start_ndx = 0
|
||||
end_ndx = int(width_irc[axis])
|
||||
|
||||
if end_ndx > self.hu_a.shape[axis]:
|
||||
# log.warning("Crop outside of CT array: {} {}, center:{} shape:{} width:{}".format(
|
||||
# self.series_uid, center_xyz, center_irc, self.hu_a.shape, width_irc))
|
||||
end_ndx = self.hu_a.shape[axis]
|
||||
start_ndx = int(self.hu_a.shape[axis] - width_irc[axis])
|
||||
|
||||
slice_list.append(slice(start_ndx, end_ndx))
|
||||
|
||||
ct_chunk = self.hu_a[tuple(slice_list)]
|
||||
pos_chunk = self.positive_mask[tuple(slice_list)]
|
||||
|
||||
return ct_chunk, pos_chunk, center_irc
|
||||
|
||||
@functools.lru_cache(1, typed=True)
|
||||
def getCt(series_uid):
|
||||
return Ct(series_uid)
|
||||
|
||||
@raw_cache.memoize(typed=True)
|
||||
def getCtRawCandidate(series_uid, center_xyz, width_irc):
|
||||
ct = getCt(series_uid)
|
||||
ct_chunk, pos_chunk, center_irc = ct.getRawCandidate(center_xyz,
|
||||
width_irc)
|
||||
ct_chunk.clip(-1000, 1000, ct_chunk)
|
||||
return ct_chunk, pos_chunk, center_irc
|
||||
|
||||
@raw_cache.memoize(typed=True)
|
||||
def getCtSampleSize(series_uid):
|
||||
ct = Ct(series_uid)
|
||||
return int(ct.hu_a.shape[0]), ct.positive_indexes
|
||||
|
||||
|
||||
class Luna2dSegmentationDataset(Dataset):
|
||||
def __init__(self,
|
||||
val_stride=0,
|
||||
isValSet_bool=None,
|
||||
series_uid=None,
|
||||
contextSlices_count=3,
|
||||
fullCt_bool=False,
|
||||
):
|
||||
self.contextSlices_count = contextSlices_count
|
||||
self.fullCt_bool = fullCt_bool
|
||||
|
||||
if series_uid:
|
||||
self.series_list = [series_uid]
|
||||
else:
|
||||
self.series_list = sorted(getCandidateInfoDict().keys())
|
||||
|
||||
if isValSet_bool:
|
||||
assert val_stride > 0, val_stride
|
||||
self.series_list = self.series_list[::val_stride]
|
||||
assert self.series_list
|
||||
elif val_stride > 0:
|
||||
del self.series_list[::val_stride]
|
||||
assert self.series_list
|
||||
|
||||
self.sample_list = []
|
||||
for series_uid in self.series_list:
|
||||
index_count, positive_indexes = getCtSampleSize(series_uid)
|
||||
|
||||
if self.fullCt_bool:
|
||||
self.sample_list += [(series_uid, slice_ndx)
|
||||
for slice_ndx in range(index_count)]
|
||||
else:
|
||||
self.sample_list += [(series_uid, slice_ndx)
|
||||
for slice_ndx in positive_indexes]
|
||||
|
||||
self.candidateInfo_list = getCandidateInfoList()
|
||||
|
||||
series_set = set(self.series_list)
|
||||
self.candidateInfo_list = [cit for cit in self.candidateInfo_list
|
||||
if cit.series_uid in series_set]
|
||||
|
||||
self.pos_list = [nt for nt in self.candidateInfo_list
|
||||
if nt.isNodule_bool]
|
||||
|
||||
log.info("{!r}: {} {} series, {} slices, {} nodules".format(
|
||||
self,
|
||||
len(self.series_list),
|
||||
{None: 'general', True: 'validation', False: 'training'}[isValSet_bool],
|
||||
len(self.sample_list),
|
||||
len(self.pos_list),
|
||||
))
|
||||
|
||||
def __len__(self):
|
||||
return len(self.sample_list)
|
||||
|
||||
def __getitem__(self, ndx):
|
||||
series_uid, slice_ndx = self.sample_list[ndx % len(self.sample_list)]
|
||||
return self.getitem_fullSlice(series_uid, slice_ndx)
|
||||
|
||||
def getitem_fullSlice(self, series_uid, slice_ndx):
|
||||
ct = getCt(series_uid)
|
||||
ct_t = torch.zeros((self.contextSlices_count * 2 + 1, 512, 512))
|
||||
|
||||
start_ndx = slice_ndx - self.contextSlices_count
|
||||
end_ndx = slice_ndx + self.contextSlices_count + 1
|
||||
for i, context_ndx in enumerate(range(start_ndx, end_ndx)):
|
||||
context_ndx = max(context_ndx, 0)
|
||||
context_ndx = min(context_ndx, ct.hu_a.shape[0] - 1)
|
||||
ct_t[i] = torch.from_numpy(ct.hu_a[context_ndx].astype(np.float32))
|
||||
|
||||
# CTs are natively expressed in https://en.wikipedia.org/wiki/Hounsfield_scale
|
||||
# HU are scaled oddly, with 0 g/cc (air, approximately) being -1000 and 1 g/cc (water) being 0.
|
||||
# The lower bound gets rid of negative density stuff used to indicate out-of-FOV
|
||||
# The upper bound nukes any weird hotspots and clamps bone down
|
||||
ct_t.clamp_(-1000, 1000)
|
||||
|
||||
pos_t = torch.from_numpy(ct.positive_mask[slice_ndx]).unsqueeze(0)
|
||||
|
||||
return ct_t, pos_t, ct.series_uid, slice_ndx
|
||||
|
||||
|
||||
class TrainingLuna2dSegmentationDataset(Luna2dSegmentationDataset):
|
||||
def __init__(self, *args, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
|
||||
self.ratio_int = 2
|
||||
|
||||
def __len__(self):
|
||||
return 300000
|
||||
|
||||
def shuffleSamples(self):
|
||||
random.shuffle(self.candidateInfo_list)
|
||||
random.shuffle(self.pos_list)
|
||||
|
||||
def __getitem__(self, ndx):
|
||||
candidateInfo_tup = self.pos_list[ndx % len(self.pos_list)]
|
||||
return self.getitem_trainingCrop(candidateInfo_tup)
|
||||
|
||||
def getitem_trainingCrop(self, candidateInfo_tup):
|
||||
ct_a, pos_a, center_irc = getCtRawCandidate(
|
||||
candidateInfo_tup.series_uid,
|
||||
candidateInfo_tup.center_xyz,
|
||||
(7, 96, 96),
|
||||
)
|
||||
pos_a = pos_a[3:4]
|
||||
|
||||
row_offset = random.randrange(0,32)
|
||||
col_offset = random.randrange(0,32)
|
||||
ct_t = torch.from_numpy(ct_a[:, row_offset:row_offset+64,
|
||||
col_offset:col_offset+64]).to(torch.float32)
|
||||
pos_t = torch.from_numpy(pos_a[:, row_offset:row_offset+64,
|
||||
col_offset:col_offset+64]).to(torch.long)
|
||||
|
||||
slice_ndx = center_irc.index
|
||||
|
||||
return ct_t, pos_t, candidateInfo_tup.series_uid, slice_ndx
|
||||
|
||||
class PrepcacheLunaDataset(Dataset):
|
||||
def __init__(self, *args, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
|
||||
self.candidateInfo_list = getCandidateInfoList()
|
||||
self.pos_list = [nt for nt in self.candidateInfo_list if nt.isNodule_bool]
|
||||
|
||||
self.seen_set = set()
|
||||
self.candidateInfo_list.sort(key=lambda x: x.series_uid)
|
||||
|
||||
def __len__(self):
|
||||
return len(self.candidateInfo_list)
|
||||
|
||||
def __getitem__(self, ndx):
|
||||
# candidate_t, pos_t, series_uid, center_t = super().__getitem__(ndx)
|
||||
|
||||
candidateInfo_tup = self.candidateInfo_list[ndx]
|
||||
getCtRawCandidate(candidateInfo_tup.series_uid, candidateInfo_tup.center_xyz, (7, 96, 96))
|
||||
|
||||
series_uid = candidateInfo_tup.series_uid
|
||||
if series_uid not in self.seen_set:
|
||||
self.seen_set.add(series_uid)
|
||||
|
||||
getCtSampleSize(series_uid)
|
||||
# ct = getCt(series_uid)
|
||||
# for mask_ndx in ct.positive_indexes:
|
||||
# build2dLungMask(series_uid, mask_ndx)
|
||||
|
||||
return 0, 1 #candidate_t, pos_t, series_uid, center_t
|
||||
|
||||
|
||||
class TvTrainingLuna2dSegmentationDataset(torch.utils.data.Dataset):
|
||||
def __init__(self, isValSet_bool=False, val_stride=10, contextSlices_count=3):
|
||||
assert contextSlices_count == 3
|
||||
data = torch.load('./imgs_and_masks.pt')
|
||||
suids = list(set(data['suids']))
|
||||
trn_mask_suids = torch.arange(len(suids)) % val_stride < (val_stride - 1)
|
||||
trn_suids = {s for i, s in zip(trn_mask_suids, suids) if i}
|
||||
trn_mask = torch.tensor([(s in trn_suids) for s in data["suids"]])
|
||||
if not isValSet_bool:
|
||||
self.imgs = data["imgs"][trn_mask]
|
||||
self.masks = data["masks"][trn_mask]
|
||||
self.suids = [s for s, i in zip(data["suids"], trn_mask) if i]
|
||||
else:
|
||||
self.imgs = data["imgs"][~trn_mask]
|
||||
self.masks = data["masks"][~trn_mask]
|
||||
self.suids = [s for s, i in zip(data["suids"], trn_mask) if not i]
|
||||
# discard spurious hotspots and clamp bone
|
||||
self.imgs.clamp_(-1000, 1000)
|
||||
self.imgs /= 1000
|
||||
|
||||
|
||||
def __len__(self):
|
||||
return len(self.imgs)
|
||||
|
||||
def __getitem__(self, i):
|
||||
oh, ow = torch.randint(0, 32, (2,))
|
||||
sl = self.masks.size(1)//2
|
||||
return self.imgs[i, :, oh: oh + 64, ow: ow + 64], 1, self.masks[i, sl: sl+1, oh: oh + 64, ow: ow + 64].to(torch.float32), self.suids[i], 9999
|
||||
@ -0,0 +1,224 @@
|
||||
import math
|
||||
import random
|
||||
from collections import namedtuple
|
||||
|
||||
import torch
|
||||
from torch import nn as nn
|
||||
import torch.nn.functional as F
|
||||
|
||||
from util.logconf import logging
|
||||
from util.unet import UNet
|
||||
|
||||
log = logging.getLogger(__name__)
|
||||
# log.setLevel(logging.WARN)
|
||||
# log.setLevel(logging.INFO)
|
||||
log.setLevel(logging.DEBUG)
|
||||
|
||||
class UNetWrapper(nn.Module):
|
||||
def __init__(self, **kwargs):
|
||||
super().__init__()
|
||||
|
||||
self.input_batchnorm = nn.BatchNorm2d(kwargs['in_channels'])
|
||||
self.unet = UNet(**kwargs)
|
||||
self.final = nn.Sigmoid()
|
||||
|
||||
self._init_weights()
|
||||
|
||||
def _init_weights(self):
|
||||
init_set = {
|
||||
nn.Conv2d,
|
||||
nn.Conv3d,
|
||||
nn.ConvTranspose2d,
|
||||
nn.ConvTranspose3d,
|
||||
nn.Linear,
|
||||
}
|
||||
for m in self.modules():
|
||||
if type(m) in init_set:
|
||||
nn.init.kaiming_normal_(
|
||||
m.weight.data, mode='fan_out', nonlinearity='relu', a=0
|
||||
)
|
||||
if m.bias is not None:
|
||||
fan_in, fan_out = \
|
||||
nn.init._calculate_fan_in_and_fan_out(m.weight.data)
|
||||
bound = 1 / math.sqrt(fan_out)
|
||||
nn.init.normal_(m.bias, -bound, bound)
|
||||
|
||||
# nn.init.constant_(self.unet.last.bias, -4)
|
||||
# nn.init.constant_(self.unet.last.bias, 4)
|
||||
|
||||
|
||||
def forward(self, input_batch):
|
||||
bn_output = self.input_batchnorm(input_batch)
|
||||
un_output = self.unet(bn_output)
|
||||
fn_output = self.final(un_output)
|
||||
return fn_output
|
||||
|
||||
class SegmentationAugmentation(nn.Module):
|
||||
def __init__(
|
||||
self, flip=None, offset=None, scale=None, rotate=None, noise=None
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
self.flip = flip
|
||||
self.offset = offset
|
||||
self.scale = scale
|
||||
self.rotate = rotate
|
||||
self.noise = noise
|
||||
|
||||
def forward(self, input_g, label_g):
|
||||
transform_t = self._build2dTransformMatrix()
|
||||
transform_t = transform_t.expand(input_g.shape[0], -1, -1)
|
||||
transform_t = transform_t.to(input_g.device, torch.float32)
|
||||
affine_t = F.affine_grid(transform_t[:,:2],
|
||||
input_g.size(), align_corners=False)
|
||||
|
||||
augmented_input_g = F.grid_sample(input_g,
|
||||
affine_t, padding_mode='border',
|
||||
align_corners=False)
|
||||
augmented_label_g = F.grid_sample(label_g.to(torch.float32),
|
||||
affine_t, padding_mode='border',
|
||||
align_corners=False)
|
||||
|
||||
if self.noise:
|
||||
noise_t = torch.randn_like(augmented_input_g)
|
||||
noise_t *= self.noise
|
||||
|
||||
augmented_input_g += noise_t
|
||||
|
||||
return augmented_input_g, augmented_label_g > 0.5
|
||||
|
||||
def _build2dTransformMatrix(self):
|
||||
transform_t = torch.eye(3)
|
||||
|
||||
for i in range(2):
|
||||
if self.flip:
|
||||
if random.random() > 0.5:
|
||||
transform_t[i,i] *= -1
|
||||
|
||||
if self.offset:
|
||||
offset_float = self.offset
|
||||
random_float = (random.random() * 2 - 1)
|
||||
transform_t[2,i] = offset_float * random_float
|
||||
|
||||
if self.scale:
|
||||
scale_float = self.scale
|
||||
random_float = (random.random() * 2 - 1)
|
||||
transform_t[i,i] *= 1.0 + scale_float * random_float
|
||||
|
||||
if self.rotate:
|
||||
angle_rad = random.random() * math.pi * 2
|
||||
s = math.sin(angle_rad)
|
||||
c = math.cos(angle_rad)
|
||||
|
||||
rotation_t = torch.tensor([
|
||||
[c, -s, 0],
|
||||
[s, c, 0],
|
||||
[0, 0, 1]])
|
||||
|
||||
transform_t @= rotation_t
|
||||
|
||||
return transform_t
|
||||
|
||||
|
||||
# MaskTuple = namedtuple('MaskTuple', 'raw_dense_mask, dense_mask, body_mask, air_mask, raw_candidate_mask, candidate_mask, lung_mask, neg_mask, pos_mask')
|
||||
#
|
||||
# class SegmentationMask(nn.Module):
|
||||
# def __init__(self):
|
||||
# super().__init__()
|
||||
#
|
||||
# self.conv_list = nn.ModuleList([
|
||||
# self._make_circle_conv(radius) for radius in range(1, 8)
|
||||
# ])
|
||||
#
|
||||
# def _make_circle_conv(self, radius):
|
||||
# diameter = 1 + radius * 2
|
||||
#
|
||||
# a = torch.linspace(-1, 1, steps=diameter)**2
|
||||
# b = (a[None] + a[:, None])**0.5
|
||||
#
|
||||
# circle_weights = (b <= 1.0).to(torch.float32)
|
||||
#
|
||||
# conv = nn.Conv2d(1, 1, kernel_size=diameter, padding=radius, bias=False)
|
||||
# conv.weight.data.fill_(1)
|
||||
# conv.weight.data *= circle_weights / circle_weights.sum()
|
||||
#
|
||||
# return conv
|
||||
#
|
||||
#
|
||||
# def erode(self, input_mask, radius, threshold=1):
|
||||
# conv = self.conv_list[radius - 1]
|
||||
# input_float = input_mask.to(torch.float32)
|
||||
# result = conv(input_float)
|
||||
#
|
||||
# # log.debug(['erode in ', radius, threshold, input_float.min().item(), input_float.mean().item(), input_float.max().item()])
|
||||
# # log.debug(['erode out', radius, threshold, result.min().item(), result.mean().item(), result.max().item()])
|
||||
#
|
||||
# return result >= threshold
|
||||
#
|
||||
# def deposit(self, input_mask, radius, threshold=0):
|
||||
# conv = self.conv_list[radius - 1]
|
||||
# input_float = input_mask.to(torch.float32)
|
||||
# result = conv(input_float)
|
||||
#
|
||||
# # log.debug(['deposit in ', radius, threshold, input_float.min().item(), input_float.mean().item(), input_float.max().item()])
|
||||
# # log.debug(['deposit out', radius, threshold, result.min().item(), result.mean().item(), result.max().item()])
|
||||
#
|
||||
# return result > threshold
|
||||
#
|
||||
# def fill_cavity(self, input_mask):
|
||||
# cumsum = input_mask.cumsum(-1)
|
||||
# filled_mask = (cumsum > 0)
|
||||
# filled_mask &= (cumsum < cumsum[..., -1:])
|
||||
# cumsum = input_mask.cumsum(-2)
|
||||
# filled_mask &= (cumsum > 0)
|
||||
# filled_mask &= (cumsum < cumsum[..., -1:, :])
|
||||
#
|
||||
# return filled_mask
|
||||
#
|
||||
#
|
||||
# def forward(self, input_g, raw_pos_g):
|
||||
# gcc_g = input_g + 1
|
||||
#
|
||||
# with torch.no_grad():
|
||||
# # log.info(['gcc_g', gcc_g.min(), gcc_g.mean(), gcc_g.max()])
|
||||
#
|
||||
# raw_dense_mask = gcc_g > 0.7
|
||||
# dense_mask = self.deposit(raw_dense_mask, 2)
|
||||
# dense_mask = self.erode(dense_mask, 6)
|
||||
# dense_mask = self.deposit(dense_mask, 4)
|
||||
#
|
||||
# body_mask = self.fill_cavity(dense_mask)
|
||||
# air_mask = self.deposit(body_mask & ~dense_mask, 5)
|
||||
# air_mask = self.erode(air_mask, 6)
|
||||
#
|
||||
# lung_mask = self.deposit(air_mask, 5)
|
||||
#
|
||||
# raw_candidate_mask = gcc_g > 0.4
|
||||
# raw_candidate_mask &= air_mask
|
||||
# candidate_mask = self.erode(raw_candidate_mask, 1)
|
||||
# candidate_mask = self.deposit(candidate_mask, 1)
|
||||
#
|
||||
# pos_mask = self.deposit((raw_pos_g > 0.5) & lung_mask, 2)
|
||||
#
|
||||
# neg_mask = self.deposit(candidate_mask, 1)
|
||||
# neg_mask &= ~pos_mask
|
||||
# neg_mask &= lung_mask
|
||||
#
|
||||
# # label_g = (neg_mask | pos_mask).to(torch.float32)
|
||||
# label_g = (pos_mask).to(torch.float32)
|
||||
# neg_g = neg_mask.to(torch.float32)
|
||||
# pos_g = pos_mask.to(torch.float32)
|
||||
#
|
||||
# mask_dict = {
|
||||
# 'raw_dense_mask': raw_dense_mask,
|
||||
# 'dense_mask': dense_mask,
|
||||
# 'body_mask': body_mask,
|
||||
# 'air_mask': air_mask,
|
||||
# 'raw_candidate_mask': raw_candidate_mask,
|
||||
# 'candidate_mask': candidate_mask,
|
||||
# 'lung_mask': lung_mask,
|
||||
# 'neg_mask': neg_mask,
|
||||
# 'pos_mask': pos_mask,
|
||||
# }
|
||||
#
|
||||
# return label_g, neg_g, pos_g, lung_mask, mask_dict
|
||||
@ -0,0 +1,69 @@
|
||||
import timing
|
||||
import argparse
|
||||
import sys
|
||||
|
||||
import numpy as np
|
||||
|
||||
import torch.nn as nn
|
||||
from torch.autograd import Variable
|
||||
from torch.optim import SGD
|
||||
from torch.utils.data import DataLoader
|
||||
|
||||
from util.util import enumerateWithEstimate
|
||||
from .dsets import PrepcacheLunaDataset, getCtSampleSize
|
||||
from util.logconf import logging
|
||||
# from .model import LunaModel
|
||||
|
||||
log = logging.getLogger(__name__)
|
||||
# log.setLevel(logging.WARN)
|
||||
log.setLevel(logging.INFO)
|
||||
# log.setLevel(logging.DEBUG)
|
||||
|
||||
|
||||
class LunaPrepCacheApp:
|
||||
@classmethod
|
||||
def __init__(self, sys_argv=None):
|
||||
if sys_argv is None:
|
||||
sys_argv = sys.argv[1:]
|
||||
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('--batch-size',
|
||||
help='Batch size to use for training',
|
||||
default=1024,
|
||||
type=int,
|
||||
)
|
||||
parser.add_argument('--num-workers',
|
||||
help='Number of worker processes for background data loading',
|
||||
default=8,
|
||||
type=int,
|
||||
)
|
||||
# parser.add_argument('--scaled',
|
||||
# help="Scale the CT chunks to square voxels.",
|
||||
# default=False,
|
||||
# action='store_true',
|
||||
# )
|
||||
|
||||
self.cli_args = parser.parse_args(sys_argv)
|
||||
|
||||
def main(self):
|
||||
log.info("Starting {}, {}".format(type(self).__name__, self.cli_args))
|
||||
|
||||
self.prep_dl = DataLoader(
|
||||
PrepcacheLunaDataset(
|
||||
# sortby_str='series_uid',
|
||||
),
|
||||
batch_size=self.cli_args.batch_size,
|
||||
num_workers=self.cli_args.num_workers,
|
||||
)
|
||||
|
||||
batch_iter = enumerateWithEstimate(
|
||||
self.prep_dl,
|
||||
"Stuffing cache",
|
||||
start_ndx=self.prep_dl.num_workers,
|
||||
)
|
||||
for batch_ndx, batch_tup in batch_iter:
|
||||
pass
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
LunaPrepCacheApp().main()
|
||||
@ -0,0 +1,331 @@
|
||||
import math
|
||||
import random
|
||||
import warnings
|
||||
|
||||
import numpy as np
|
||||
import scipy.ndimage
|
||||
|
||||
import torch
|
||||
from torch.autograd import Function
|
||||
from torch.autograd.function import once_differentiable
|
||||
import torch.backends.cudnn as cudnn
|
||||
|
||||
from util.logconf import logging
|
||||
log = logging.getLogger(__name__)
|
||||
# log.setLevel(logging.WARN)
|
||||
# log.setLevel(logging.INFO)
|
||||
log.setLevel(logging.DEBUG)
|
||||
|
||||
def cropToShape(image, new_shape, center_list=None, fill=0.0):
|
||||
# log.debug([image.shape, new_shape, center_list])
|
||||
# assert len(image.shape) == 3, repr(image.shape)
|
||||
|
||||
if center_list is None:
|
||||
center_list = [int(image.shape[i] / 2) for i in range(3)]
|
||||
|
||||
crop_list = []
|
||||
for i in range(0, 3):
|
||||
crop_int = center_list[i]
|
||||
if image.shape[i] > new_shape[i] and crop_int is not None:
|
||||
|
||||
# We can't just do crop_int +/- shape/2 since shape might be odd
|
||||
# and ints round down.
|
||||
start_int = crop_int - int(new_shape[i]/2)
|
||||
end_int = start_int + new_shape[i]
|
||||
crop_list.append(slice(max(0, start_int), end_int))
|
||||
else:
|
||||
crop_list.append(slice(0, image.shape[i]))
|
||||
|
||||
# log.debug([image.shape, crop_list])
|
||||
image = image[crop_list]
|
||||
|
||||
crop_list = []
|
||||
for i in range(0, 3):
|
||||
if image.shape[i] < new_shape[i]:
|
||||
crop_int = int((new_shape[i] - image.shape[i]) / 2)
|
||||
crop_list.append(slice(crop_int, crop_int + image.shape[i]))
|
||||
else:
|
||||
crop_list.append(slice(0, image.shape[i]))
|
||||
|
||||
# log.debug([image.shape, crop_list])
|
||||
new_image = np.zeros(new_shape, dtype=image.dtype)
|
||||
new_image[:] = fill
|
||||
new_image[crop_list] = image
|
||||
|
||||
return new_image
|
||||
|
||||
|
||||
def zoomToShape(image, new_shape, square=True):
|
||||
# assert image.shape[-1] in {1, 3, 4}, repr(image.shape)
|
||||
|
||||
if square and image.shape[0] != image.shape[1]:
|
||||
crop_int = min(image.shape[0], image.shape[1])
|
||||
new_shape = [crop_int, crop_int, image.shape[2]]
|
||||
image = cropToShape(image, new_shape)
|
||||
|
||||
zoom_shape = [new_shape[i] / image.shape[i] for i in range(3)]
|
||||
|
||||
with warnings.catch_warnings():
|
||||
warnings.simplefilter("ignore")
|
||||
image = scipy.ndimage.interpolation.zoom(
|
||||
image, zoom_shape,
|
||||
output=None, order=0, mode='nearest', cval=0.0, prefilter=True)
|
||||
|
||||
return image
|
||||
|
||||
def randomOffset(image_list, offset_rows=0.125, offset_cols=0.125):
|
||||
|
||||
center_list = [int(image_list[0].shape[i] / 2) for i in range(3)]
|
||||
center_list[0] += int(offset_rows * (random.random() - 0.5) * 2)
|
||||
center_list[1] += int(offset_cols * (random.random() - 0.5) * 2)
|
||||
center_list[2] = None
|
||||
|
||||
new_list = []
|
||||
for image in image_list:
|
||||
new_image = cropToShape(image, image.shape, center_list)
|
||||
new_list.append(new_image)
|
||||
|
||||
return new_list
|
||||
|
||||
|
||||
def randomZoom(image_list, scale=None, scale_min=0.8, scale_max=1.3):
|
||||
if scale is None:
|
||||
scale = scale_min + (scale_max - scale_min) * random.random()
|
||||
|
||||
new_list = []
|
||||
for image in image_list:
|
||||
# assert image.shape[-1] in {1, 3, 4}, repr(image.shape)
|
||||
|
||||
with warnings.catch_warnings():
|
||||
warnings.simplefilter("ignore")
|
||||
# log.info([image.shape])
|
||||
zimage = scipy.ndimage.interpolation.zoom(
|
||||
image, [scale, scale, 1.0],
|
||||
output=None, order=0, mode='nearest', cval=0.0, prefilter=True)
|
||||
image = cropToShape(zimage, image.shape)
|
||||
|
||||
new_list.append(image)
|
||||
|
||||
return new_list
|
||||
|
||||
|
||||
_randomFlip_transform_list = [
|
||||
# lambda a: np.rot90(a, axes=(0, 1)),
|
||||
# lambda a: np.flip(a, 0),
|
||||
lambda a: np.flip(a, 1),
|
||||
]
|
||||
|
||||
def randomFlip(image_list, transform_bits=None):
|
||||
if transform_bits is None:
|
||||
transform_bits = random.randrange(0, 2 ** len(_randomFlip_transform_list))
|
||||
|
||||
new_list = []
|
||||
for image in image_list:
|
||||
# assert image.shape[-1] in {1, 3, 4}, repr(image.shape)
|
||||
|
||||
for n in range(len(_randomFlip_transform_list)):
|
||||
if transform_bits & 2**n:
|
||||
# prhist(image, 'before')
|
||||
image = _randomFlip_transform_list[n](image)
|
||||
# prhist(image, 'after ')
|
||||
|
||||
new_list.append(image)
|
||||
|
||||
return new_list
|
||||
|
||||
|
||||
def randomSpin(image_list, angle=None, range_tup=None, axes=(0, 1)):
|
||||
if range_tup is None:
|
||||
range_tup = (0, 360)
|
||||
|
||||
if angle is None:
|
||||
angle = range_tup[0] + (range_tup[1] - range_tup[0]) * random.random()
|
||||
|
||||
new_list = []
|
||||
for image in image_list:
|
||||
# assert image.shape[-1] in {1, 3, 4}, repr(image.shape)
|
||||
|
||||
image = scipy.ndimage.interpolation.rotate(
|
||||
image, angle, axes=axes, reshape=False,
|
||||
output=None, order=0, mode='nearest', cval=0.0, prefilter=True)
|
||||
|
||||
new_list.append(image)
|
||||
|
||||
return new_list
|
||||
|
||||
|
||||
def randomNoise(image_list, noise_min=-0.1, noise_max=0.1):
|
||||
noise = np.zeros_like(image_list[0])
|
||||
noise += (noise_max - noise_min) * np.random.random_sample(image_list[0].shape) + noise_min
|
||||
noise *= 5
|
||||
noise = scipy.ndimage.filters.gaussian_filter(noise, 3)
|
||||
# noise += (noise_max - noise_min) * np.random.random_sample(image_hsv.shape) + noise_min
|
||||
|
||||
new_list = []
|
||||
for image_hsv in image_list:
|
||||
image_hsv = image_hsv + noise
|
||||
|
||||
new_list.append(image_hsv)
|
||||
|
||||
return new_list
|
||||
|
||||
|
||||
def randomHsvShift(image_list, h=None, s=None, v=None,
|
||||
h_min=-0.1, h_max=0.1,
|
||||
s_min=0.5, s_max=2.0,
|
||||
v_min=0.5, v_max=2.0):
|
||||
if h is None:
|
||||
h = h_min + (h_max - h_min) * random.random()
|
||||
if s is None:
|
||||
s = s_min + (s_max - s_min) * random.random()
|
||||
if v is None:
|
||||
v = v_min + (v_max - v_min) * random.random()
|
||||
|
||||
new_list = []
|
||||
for image_hsv in image_list:
|
||||
# assert image_hsv.shape[-1] == 3, repr(image_hsv.shape)
|
||||
|
||||
image_hsv[:,:,0::3] += h
|
||||
image_hsv[:,:,1::3] = image_hsv[:,:,1::3] ** s
|
||||
image_hsv[:,:,2::3] = image_hsv[:,:,2::3] ** v
|
||||
|
||||
new_list.append(image_hsv)
|
||||
|
||||
return clampHsv(new_list)
|
||||
|
||||
|
||||
def clampHsv(image_list):
|
||||
new_list = []
|
||||
for image_hsv in image_list:
|
||||
image_hsv = image_hsv.clone()
|
||||
|
||||
# Hue wraps around
|
||||
image_hsv[:,:,0][image_hsv[:,:,0] > 1] -= 1
|
||||
image_hsv[:,:,0][image_hsv[:,:,0] < 0] += 1
|
||||
|
||||
# Everything else clamps between 0 and 1
|
||||
image_hsv[image_hsv > 1] = 1
|
||||
image_hsv[image_hsv < 0] = 0
|
||||
|
||||
new_list.append(image_hsv)
|
||||
|
||||
return new_list
|
||||
|
||||
|
||||
# def torch_augment(input):
|
||||
# theta = random.random() * math.pi * 2
|
||||
# s = math.sin(theta)
|
||||
# c = math.cos(theta)
|
||||
# c1 = 1 - c
|
||||
# axis_vector = torch.rand(3, device='cpu', dtype=torch.float64)
|
||||
# axis_vector -= 0.5
|
||||
# axis_vector /= axis_vector.abs().sum()
|
||||
# l, m, n = axis_vector
|
||||
#
|
||||
# matrix = torch.tensor([
|
||||
# [l*l*c1 + c, m*l*c1 - n*s, n*l*c1 + m*s, 0],
|
||||
# [l*m*c1 + n*s, m*m*c1 + c, n*m*c1 - l*s, 0],
|
||||
# [l*n*c1 - m*s, m*n*c1 + l*s, n*n*c1 + c, 0],
|
||||
# [0, 0, 0, 1],
|
||||
# ], device=input.device, dtype=torch.float32)
|
||||
#
|
||||
# return th_affine3d(input, matrix)
|
||||
|
||||
|
||||
|
||||
|
||||
# following from https://github.com/ncullen93/torchsample/blob/master/torchsample/utils.py
|
||||
# MIT licensed
|
||||
|
||||
# def th_affine3d(input, matrix):
|
||||
# """
|
||||
# 3D Affine image transform on torch.Tensor
|
||||
# """
|
||||
# A = matrix[:3,:3]
|
||||
# b = matrix[:3,3]
|
||||
#
|
||||
# # make a meshgrid of normal coordinates
|
||||
# coords = th_iterproduct(input.size(-3), input.size(-2), input.size(-1), dtype=torch.float32)
|
||||
#
|
||||
# # shift the coordinates so center is the origin
|
||||
# coords[:,0] = coords[:,0] - (input.size(-3) / 2. - 0.5)
|
||||
# coords[:,1] = coords[:,1] - (input.size(-2) / 2. - 0.5)
|
||||
# coords[:,2] = coords[:,2] - (input.size(-1) / 2. - 0.5)
|
||||
#
|
||||
# # apply the coordinate transformation
|
||||
# new_coords = coords.mm(A.t().contiguous()) + b.expand_as(coords)
|
||||
#
|
||||
# # shift the coordinates back so origin is origin
|
||||
# new_coords[:,0] = new_coords[:,0] + (input.size(-3) / 2. - 0.5)
|
||||
# new_coords[:,1] = new_coords[:,1] + (input.size(-2) / 2. - 0.5)
|
||||
# new_coords[:,2] = new_coords[:,2] + (input.size(-1) / 2. - 0.5)
|
||||
#
|
||||
# # map new coordinates using bilinear interpolation
|
||||
# input_transformed = th_trilinear_interp3d(input, new_coords)
|
||||
#
|
||||
# return input_transformed
|
||||
#
|
||||
#
|
||||
# def th_trilinear_interp3d(input, coords):
|
||||
# """
|
||||
# trilinear interpolation of 3D torch.Tensor image
|
||||
# """
|
||||
# # take clamp then floor/ceil of x coords
|
||||
# x = torch.clamp(coords[:,0], 0, input.size(-3)-2)
|
||||
# x0 = x.floor()
|
||||
# x1 = x0 + 1
|
||||
# # take clamp then floor/ceil of y coords
|
||||
# y = torch.clamp(coords[:,1], 0, input.size(-2)-2)
|
||||
# y0 = y.floor()
|
||||
# y1 = y0 + 1
|
||||
# # take clamp then floor/ceil of z coords
|
||||
# z = torch.clamp(coords[:,2], 0, input.size(-1)-2)
|
||||
# z0 = z.floor()
|
||||
# z1 = z0 + 1
|
||||
#
|
||||
# stride = torch.tensor(input.stride()[-3:], dtype=torch.int64, device=input.device)
|
||||
# x0_ix = x0.mul(stride[0]).long()
|
||||
# x1_ix = x1.mul(stride[0]).long()
|
||||
# y0_ix = y0.mul(stride[1]).long()
|
||||
# y1_ix = y1.mul(stride[1]).long()
|
||||
# z0_ix = z0.mul(stride[2]).long()
|
||||
# z1_ix = z1.mul(stride[2]).long()
|
||||
#
|
||||
# # input_flat = th_flatten(input)
|
||||
# input_flat = x.contiguous().view(x[0], x[1], -1)
|
||||
#
|
||||
# vals_000 = input_flat[:, :, x0_ix+y0_ix+z0_ix]
|
||||
# vals_001 = input_flat[:, :, x0_ix+y0_ix+z1_ix]
|
||||
# vals_010 = input_flat[:, :, x0_ix+y1_ix+z0_ix]
|
||||
# vals_011 = input_flat[:, :, x0_ix+y1_ix+z1_ix]
|
||||
# vals_100 = input_flat[:, :, x1_ix+y0_ix+z0_ix]
|
||||
# vals_101 = input_flat[:, :, x1_ix+y0_ix+z1_ix]
|
||||
# vals_110 = input_flat[:, :, x1_ix+y1_ix+z0_ix]
|
||||
# vals_111 = input_flat[:, :, x1_ix+y1_ix+z1_ix]
|
||||
#
|
||||
# xd = x - x0
|
||||
# yd = y - y0
|
||||
# zd = z - z0
|
||||
# xm1 = 1 - xd
|
||||
# ym1 = 1 - yd
|
||||
# zm1 = 1 - zd
|
||||
#
|
||||
# x_mapped = (
|
||||
# vals_000.mul(xm1).mul(ym1).mul(zm1) +
|
||||
# vals_001.mul(xm1).mul(ym1).mul(zd) +
|
||||
# vals_010.mul(xm1).mul(yd).mul(zm1) +
|
||||
# vals_011.mul(xm1).mul(yd).mul(zd) +
|
||||
# vals_100.mul(xd).mul(ym1).mul(zm1) +
|
||||
# vals_101.mul(xd).mul(ym1).mul(zd) +
|
||||
# vals_110.mul(xd).mul(yd).mul(zm1) +
|
||||
# vals_111.mul(xd).mul(yd).mul(zd)
|
||||
# )
|
||||
#
|
||||
# return x_mapped.view_as(input)
|
||||
#
|
||||
# def th_iterproduct(*args, dtype=None):
|
||||
# return torch.from_numpy(np.indices(args).reshape((len(args),-1)).T)
|
||||
#
|
||||
# def th_flatten(x):
|
||||
# """Flatten tensor"""
|
||||
# return x.contiguous().view(x[0], x[1], -1)
|
||||
@ -0,0 +1,136 @@
|
||||
import gzip
|
||||
|
||||
from diskcache import FanoutCache, Disk
|
||||
from diskcache.core import BytesType, MODE_BINARY, BytesIO
|
||||
|
||||
from util.logconf import logging
|
||||
log = logging.getLogger(__name__)
|
||||
# log.setLevel(logging.WARN)
|
||||
log.setLevel(logging.INFO)
|
||||
# log.setLevel(logging.DEBUG)
|
||||
|
||||
|
||||
class GzipDisk(Disk):
|
||||
def store(self, value, read, key=None):
|
||||
"""
|
||||
Override from base class diskcache.Disk.
|
||||
|
||||
Chunking is due to needing to work on pythons < 2.7.13:
|
||||
- Issue #27130: In the "zlib" module, fix handling of large buffers
|
||||
(typically 2 or 4 GiB). Previously, inputs were limited to 2 GiB, and
|
||||
compression and decompression operations did not properly handle results of
|
||||
2 or 4 GiB.
|
||||
|
||||
:param value: value to convert
|
||||
:param bool read: True when value is file-like object
|
||||
:return: (size, mode, filename, value) tuple for Cache table
|
||||
"""
|
||||
# pylint: disable=unidiomatic-typecheck
|
||||
if type(value) is BytesType:
|
||||
if read:
|
||||
value = value.read()
|
||||
read = False
|
||||
|
||||
str_io = BytesIO()
|
||||
gz_file = gzip.GzipFile(mode='wb', compresslevel=1, fileobj=str_io)
|
||||
|
||||
for offset in range(0, len(value), 2**30):
|
||||
gz_file.write(value[offset:offset+2**30])
|
||||
gz_file.close()
|
||||
|
||||
value = str_io.getvalue()
|
||||
|
||||
return super(GzipDisk, self).store(value, read)
|
||||
|
||||
|
||||
def fetch(self, mode, filename, value, read):
|
||||
"""
|
||||
Override from base class diskcache.Disk.
|
||||
|
||||
Chunking is due to needing to work on pythons < 2.7.13:
|
||||
- Issue #27130: In the "zlib" module, fix handling of large buffers
|
||||
(typically 2 or 4 GiB). Previously, inputs were limited to 2 GiB, and
|
||||
compression and decompression operations did not properly handle results of
|
||||
2 or 4 GiB.
|
||||
|
||||
:param int mode: value mode raw, binary, text, or pickle
|
||||
:param str filename: filename of corresponding value
|
||||
:param value: database value
|
||||
:param bool read: when True, return an open file handle
|
||||
:return: corresponding Python value
|
||||
"""
|
||||
value = super(GzipDisk, self).fetch(mode, filename, value, read)
|
||||
|
||||
if mode == MODE_BINARY:
|
||||
str_io = BytesIO(value)
|
||||
gz_file = gzip.GzipFile(mode='rb', fileobj=str_io)
|
||||
read_csio = BytesIO()
|
||||
|
||||
while True:
|
||||
uncompressed_data = gz_file.read(2**30)
|
||||
if uncompressed_data:
|
||||
read_csio.write(uncompressed_data)
|
||||
else:
|
||||
break
|
||||
|
||||
value = read_csio.getvalue()
|
||||
|
||||
return value
|
||||
|
||||
def getCache(scope_str):
|
||||
return FanoutCache('data-unversioned/cache/' + scope_str,
|
||||
disk=GzipDisk,
|
||||
shards=64,
|
||||
timeout=1,
|
||||
size_limit=3e11,
|
||||
# disk_min_file_size=2**20,
|
||||
)
|
||||
|
||||
# def disk_cache(base_path, memsize=2):
|
||||
# def disk_cache_decorator(f):
|
||||
# @functools.wraps(f)
|
||||
# def wrapper(*args, **kwargs):
|
||||
# args_str = repr(args) + repr(sorted(kwargs.items()))
|
||||
# file_str = hashlib.md5(args_str.encode('utf8')).hexdigest()
|
||||
#
|
||||
# cache_path = os.path.join(base_path, f.__name__, file_str + '.pkl.gz')
|
||||
#
|
||||
# if not os.path.exists(os.path.dirname(cache_path)):
|
||||
# os.makedirs(os.path.dirname(cache_path), exist_ok=True)
|
||||
#
|
||||
# if os.path.exists(cache_path):
|
||||
# return pickle_loadgz(cache_path)
|
||||
# else:
|
||||
# ret = f(*args, **kwargs)
|
||||
# pickle_dumpgz(cache_path, ret)
|
||||
# return ret
|
||||
#
|
||||
# return wrapper
|
||||
#
|
||||
# return disk_cache_decorator
|
||||
#
|
||||
#
|
||||
# def pickle_dumpgz(file_path, obj):
|
||||
# log.debug("Writing {}".format(file_path))
|
||||
# with open(file_path, 'wb') as file_obj:
|
||||
# with gzip.GzipFile(mode='wb', compresslevel=1, fileobj=file_obj) as gz_file:
|
||||
# pickle.dump(obj, gz_file, pickle.HIGHEST_PROTOCOL)
|
||||
#
|
||||
#
|
||||
# def pickle_loadgz(file_path):
|
||||
# log.debug("Reading {}".format(file_path))
|
||||
# with open(file_path, 'rb') as file_obj:
|
||||
# with gzip.GzipFile(mode='rb', fileobj=file_obj) as gz_file:
|
||||
# return pickle.load(gz_file)
|
||||
#
|
||||
#
|
||||
# def dtpath(dt=None):
|
||||
# if dt is None:
|
||||
# dt = datetime.datetime.now()
|
||||
#
|
||||
# return str(dt).rsplit('.', 1)[0].replace(' ', '--').replace(':', '.')
|
||||
#
|
||||
#
|
||||
# def safepath(s):
|
||||
# s = s.replace(' ', '_')
|
||||
# return re.sub('[^A-Za-z0-9_.-]', '', s)
|
||||
@ -0,0 +1,19 @@
|
||||
import logging
|
||||
import logging.handlers
|
||||
|
||||
root_logger = logging.getLogger()
|
||||
root_logger.setLevel(logging.INFO)
|
||||
|
||||
# Some libraries attempt to add their own root logger handlers. This is
|
||||
# annoying and so we get rid of them.
|
||||
for handler in list(root_logger.handlers):
|
||||
root_logger.removeHandler(handler)
|
||||
|
||||
logfmt_str = "%(asctime)s %(levelname)-8s pid:%(process)d %(name)s:%(lineno)03d:%(funcName)s %(message)s"
|
||||
formatter = logging.Formatter(logfmt_str)
|
||||
|
||||
streamHandler = logging.StreamHandler()
|
||||
streamHandler.setFormatter(formatter)
|
||||
streamHandler.setLevel(logging.DEBUG)
|
||||
|
||||
root_logger.addHandler(streamHandler)
|
||||
@ -0,0 +1,143 @@
|
||||
# From https://github.com/jvanvugt/pytorch-unet
|
||||
# https://raw.githubusercontent.com/jvanvugt/pytorch-unet/master/unet.py
|
||||
|
||||
# MIT License
|
||||
#
|
||||
# Copyright (c) 2018 Joris
|
||||
#
|
||||
# Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
# of this software and associated documentation files (the "Software"), to deal
|
||||
# in the Software without restriction, including without limitation the rights
|
||||
# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
# copies of the Software, and to permit persons to whom the Software is
|
||||
# furnished to do so, subject to the following conditions:
|
||||
#
|
||||
# The above copyright notice and this permission notice shall be included in all
|
||||
# copies or substantial portions of the Software.
|
||||
#
|
||||
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
# SOFTWARE.
|
||||
|
||||
# Adapted from https://discuss.pytorch.org/t/unet-implementation/426
|
||||
|
||||
import torch
|
||||
from torch import nn
|
||||
import torch.nn.functional as F
|
||||
|
||||
|
||||
class UNet(nn.Module):
|
||||
def __init__(self, in_channels=1, n_classes=2, depth=5, wf=6, padding=False,
|
||||
batch_norm=False, up_mode='upconv'):
|
||||
"""
|
||||
Implementation of
|
||||
U-Net: Convolutional Networks for Biomedical Image Segmentation
|
||||
(Ronneberger et al., 2015)
|
||||
https://arxiv.org/abs/1505.04597
|
||||
|
||||
Using the default arguments will yield the exact version used
|
||||
in the original paper
|
||||
|
||||
Args:
|
||||
in_channels (int): number of input channels
|
||||
n_classes (int): number of output channels
|
||||
depth (int): depth of the network
|
||||
wf (int): number of filters in the first layer is 2**wf
|
||||
padding (bool): if True, apply padding such that the input shape
|
||||
is the same as the output.
|
||||
This may introduce artifacts
|
||||
batch_norm (bool): Use BatchNorm after layers with an
|
||||
activation function
|
||||
up_mode (str): one of 'upconv' or 'upsample'.
|
||||
'upconv' will use transposed convolutions for
|
||||
learned upsampling.
|
||||
'upsample' will use bilinear upsampling.
|
||||
"""
|
||||
super(UNet, self).__init__()
|
||||
assert up_mode in ('upconv', 'upsample')
|
||||
self.padding = padding
|
||||
self.depth = depth
|
||||
prev_channels = in_channels
|
||||
self.down_path = nn.ModuleList()
|
||||
for i in range(depth):
|
||||
self.down_path.append(UNetConvBlock(prev_channels, 2**(wf+i),
|
||||
padding, batch_norm))
|
||||
prev_channels = 2**(wf+i)
|
||||
|
||||
self.up_path = nn.ModuleList()
|
||||
for i in reversed(range(depth - 1)):
|
||||
self.up_path.append(UNetUpBlock(prev_channels, 2**(wf+i), up_mode,
|
||||
padding, batch_norm))
|
||||
prev_channels = 2**(wf+i)
|
||||
|
||||
self.last = nn.Conv2d(prev_channels, n_classes, kernel_size=1)
|
||||
|
||||
def forward(self, x):
|
||||
blocks = []
|
||||
for i, down in enumerate(self.down_path):
|
||||
x = down(x)
|
||||
if i != len(self.down_path)-1:
|
||||
blocks.append(x)
|
||||
x = F.avg_pool2d(x, 2)
|
||||
|
||||
for i, up in enumerate(self.up_path):
|
||||
x = up(x, blocks[-i-1])
|
||||
|
||||
return self.last(x)
|
||||
|
||||
|
||||
class UNetConvBlock(nn.Module):
|
||||
def __init__(self, in_size, out_size, padding, batch_norm):
|
||||
super(UNetConvBlock, self).__init__()
|
||||
block = []
|
||||
|
||||
block.append(nn.Conv2d(in_size, out_size, kernel_size=3,
|
||||
padding=int(padding)))
|
||||
block.append(nn.ReLU())
|
||||
# block.append(nn.LeakyReLU())
|
||||
if batch_norm:
|
||||
block.append(nn.BatchNorm2d(out_size))
|
||||
|
||||
block.append(nn.Conv2d(out_size, out_size, kernel_size=3,
|
||||
padding=int(padding)))
|
||||
block.append(nn.ReLU())
|
||||
# block.append(nn.LeakyReLU())
|
||||
if batch_norm:
|
||||
block.append(nn.BatchNorm2d(out_size))
|
||||
|
||||
self.block = nn.Sequential(*block)
|
||||
|
||||
def forward(self, x):
|
||||
out = self.block(x)
|
||||
return out
|
||||
|
||||
|
||||
class UNetUpBlock(nn.Module):
|
||||
def __init__(self, in_size, out_size, up_mode, padding, batch_norm):
|
||||
super(UNetUpBlock, self).__init__()
|
||||
if up_mode == 'upconv':
|
||||
self.up = nn.ConvTranspose2d(in_size, out_size, kernel_size=2,
|
||||
stride=2)
|
||||
elif up_mode == 'upsample':
|
||||
self.up = nn.Sequential(nn.Upsample(mode='bilinear', scale_factor=2),
|
||||
nn.Conv2d(in_size, out_size, kernel_size=1))
|
||||
|
||||
self.conv_block = UNetConvBlock(in_size, out_size, padding, batch_norm)
|
||||
|
||||
def center_crop(self, layer, target_size):
|
||||
_, _, layer_height, layer_width = layer.size()
|
||||
diff_y = (layer_height - target_size[0]) // 2
|
||||
diff_x = (layer_width - target_size[1]) // 2
|
||||
return layer[:, :, diff_y:(diff_y + target_size[0]), diff_x:(diff_x + target_size[1])]
|
||||
|
||||
def forward(self, x, bridge):
|
||||
up = self.up(x)
|
||||
crop1 = self.center_crop(bridge, up.shape[2:])
|
||||
out = torch.cat([up, crop1], 1)
|
||||
out = self.conv_block(out)
|
||||
|
||||
return out
|
||||
105
pages/students/2016/lukas_pokryvka/dp2021/mnist/mnist-dist.py
Normal file
@ -0,0 +1,105 @@
|
||||
import os
|
||||
from datetime import datetime
|
||||
import argparse
|
||||
import torch.multiprocessing as mp
|
||||
import torchvision
|
||||
import torchvision.transforms as transforms
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.distributed as dist
|
||||
from apex.parallel import DistributedDataParallel as DDP
|
||||
from apex import amp
|
||||
|
||||
|
||||
def main():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N',
|
||||
help='number of data loading workers (default: 4)')
|
||||
parser.add_argument('-g', '--gpus', default=1, type=int,
|
||||
help='number of gpus per node')
|
||||
parser.add_argument('-nr', '--nr', default=0, type=int,
|
||||
help='ranking within the nodes')
|
||||
parser.add_argument('--epochs', default=2, type=int, metavar='N',
|
||||
help='number of total epochs to run')
|
||||
args = parser.parse_args()
|
||||
args.world_size = args.gpus * args.nodes
|
||||
os.environ['MASTER_ADDR'] = '147.232.47.114'
|
||||
os.environ['MASTER_PORT'] = '8888'
|
||||
mp.spawn(train, nprocs=args.gpus, args=(args,))
|
||||
|
||||
|
||||
class ConvNet(nn.Module):
|
||||
def __init__(self, num_classes=10):
|
||||
super(ConvNet, self).__init__()
|
||||
self.layer1 = nn.Sequential(
|
||||
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),
|
||||
nn.BatchNorm2d(16),
|
||||
nn.ReLU(),
|
||||
nn.MaxPool2d(kernel_size=2, stride=2))
|
||||
self.layer2 = nn.Sequential(
|
||||
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),
|
||||
nn.BatchNorm2d(32),
|
||||
nn.ReLU(),
|
||||
nn.MaxPool2d(kernel_size=2, stride=2))
|
||||
self.fc = nn.Linear(7*7*32, num_classes)
|
||||
|
||||
def forward(self, x):
|
||||
out = self.layer1(x)
|
||||
out = self.layer2(out)
|
||||
out = out.reshape(out.size(0), -1)
|
||||
out = self.fc(out)
|
||||
return out
|
||||
|
||||
|
||||
def train(gpu, args):
|
||||
rank = args.nr * args.gpus + gpu
|
||||
dist.init_process_group(backend='nccl', init_method='env://', world_size=args.world_size, rank=rank)
|
||||
torch.manual_seed(0)
|
||||
model = ConvNet()
|
||||
torch.cuda.set_device(gpu)
|
||||
model.cuda(gpu)
|
||||
batch_size = 10
|
||||
# define loss function (criterion) and optimizer
|
||||
criterion = nn.CrossEntropyLoss().cuda(gpu)
|
||||
optimizer = torch.optim.SGD(model.parameters(), 1e-4)
|
||||
# Wrap the model
|
||||
model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu])
|
||||
# Data loading code
|
||||
train_dataset = torchvision.datasets.MNIST(root='./data',
|
||||
train=True,
|
||||
transform=transforms.ToTensor(),
|
||||
download=True)
|
||||
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset,
|
||||
num_replicas=args.world_size,
|
||||
rank=rank)
|
||||
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
|
||||
batch_size=batch_size,
|
||||
shuffle=False,
|
||||
num_workers=0,
|
||||
pin_memory=True,
|
||||
sampler=train_sampler)
|
||||
|
||||
start = datetime.now()
|
||||
total_step = len(train_loader)
|
||||
for epoch in range(args.epochs):
|
||||
for i, (images, labels) in enumerate(train_loader):
|
||||
images = images.cuda(non_blocking=True)
|
||||
labels = labels.cuda(non_blocking=True)
|
||||
# Forward pass
|
||||
outputs = model(images)
|
||||
loss = criterion(outputs, labels)
|
||||
|
||||
# Backward and optimize
|
||||
optimizer.zero_grad()
|
||||
loss.backward()
|
||||
optimizer.step()
|
||||
if (i + 1) % 100 == 0 and gpu == 0:
|
||||
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch + 1, args.epochs, i + 1, total_step,
|
||||
loss.item()))
|
||||
if gpu == 0:
|
||||
print("Training complete in: " + str(datetime.now() - start))
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
torch.multiprocessing.set_start_method('spawn')
|
||||
main()
|
||||
92
pages/students/2016/lukas_pokryvka/dp2021/mnist/mnist.py
Normal file
@ -0,0 +1,92 @@
|
||||
import os
|
||||
from datetime import datetime
|
||||
import argparse
|
||||
import torch.multiprocessing as mp
|
||||
import torchvision
|
||||
import torchvision.transforms as transforms
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.distributed as dist
|
||||
from apex.parallel import DistributedDataParallel as DDP
|
||||
from apex import amp
|
||||
|
||||
|
||||
def main():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N',
|
||||
help='number of data loading workers (default: 4)')
|
||||
parser.add_argument('-g', '--gpus', default=1, type=int,
|
||||
help='number of gpus per node')
|
||||
parser.add_argument('-nr', '--nr', default=0, type =int,
|
||||
help='ranking within the nodes')
|
||||
parser.add_argument('--epochs', default=2, type=int, metavar='N',
|
||||
help='number of total epochs to run')
|
||||
args = parser.parse_args()
|
||||
train(0, args)
|
||||
|
||||
|
||||
class ConvNet(nn.Module):
|
||||
def __init__(self, num_classes=10):
|
||||
super(ConvNet, self).__init__()
|
||||
self.layer1 = nn.Sequential(
|
||||
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),
|
||||
nn.BatchNorm2d(16),
|
||||
nn.ReLU(),
|
||||
nn.MaxPool2d(kernel_size=2, stride=2))
|
||||
self.layer2 = nn.Sequential(
|
||||
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),
|
||||
nn.BatchNorm2d(32),
|
||||
nn.ReLU(),
|
||||
nn.MaxPool2d(kernel_size=2, stride=2))
|
||||
self.fc = nn.Linear(7*7*32, num_classes)
|
||||
|
||||
def forward(self, x):
|
||||
out = self.layer1(x)
|
||||
out = self.layer2(out)
|
||||
out = out.reshape(out.size(0), -1)
|
||||
out = self.fc(out)
|
||||
return out
|
||||
|
||||
|
||||
def train(gpu, args):
|
||||
model = ConvNet()
|
||||
torch.cuda.set_device(gpu)
|
||||
model.cuda(gpu)
|
||||
batch_size = 50
|
||||
# define loss function (criterion) and optimizer
|
||||
criterion = nn.CrossEntropyLoss().cuda(gpu)
|
||||
optimizer = torch.optim.SGD(model.parameters(), 1e-4)
|
||||
# Data loading code
|
||||
train_dataset = torchvision.datasets.MNIST(root='./data',
|
||||
train=True,
|
||||
transform=transforms.ToTensor(),
|
||||
download=True)
|
||||
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
|
||||
batch_size=batch_size,
|
||||
shuffle=True,
|
||||
num_workers=0,
|
||||
pin_memory=True)
|
||||
|
||||
start = datetime.now()
|
||||
total_step = len(train_loader)
|
||||
for epoch in range(args.epochs):
|
||||
for i, (images, labels) in enumerate(train_loader):
|
||||
images = images.cuda(non_blocking=True)
|
||||
labels = labels.cuda(non_blocking=True)
|
||||
# Forward pass
|
||||
outputs = model(images)
|
||||
loss = criterion(outputs, labels)
|
||||
|
||||
# Backward and optimize
|
||||
optimizer.zero_grad()
|
||||
loss.backward()
|
||||
optimizer.step()
|
||||
if (i + 1) % 100 == 0 and gpu == 0:
|
||||
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch + 1, args.epochs, i + 1, total_step,
|
||||
loss.item()))
|
||||
if gpu == 0:
|
||||
print("Training complete in: " + str(datetime.now() - start))
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
748
pages/students/2016/lukas_pokryvka/dp2021/yelp/script.py
Normal file
@ -0,0 +1,748 @@
|
||||
from argparse import Namespace
|
||||
from collections import Counter
|
||||
import json
|
||||
import os
|
||||
import re
|
||||
import string
|
||||
|
||||
import numpy as np
|
||||
import pandas as pd
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
import torch.optim as optim
|
||||
from torch.utils.data import Dataset, DataLoader
|
||||
from tqdm.notebook import tqdm
|
||||
|
||||
|
||||
class Vocabulary(object):
|
||||
"""Class to process text and extract vocabulary for mapping"""
|
||||
|
||||
def __init__(self, token_to_idx=None, add_unk=True, unk_token="<UNK>"):
|
||||
"""
|
||||
Args:
|
||||
token_to_idx (dict): a pre-existing map of tokens to indices
|
||||
add_unk (bool): a flag that indicates whether to add the UNK token
|
||||
unk_token (str): the UNK token to add into the Vocabulary
|
||||
"""
|
||||
|
||||
if token_to_idx is None:
|
||||
token_to_idx = {}
|
||||
self._token_to_idx = token_to_idx
|
||||
|
||||
self._idx_to_token = {idx: token
|
||||
for token, idx in self._token_to_idx.items()}
|
||||
|
||||
self._add_unk = add_unk
|
||||
self._unk_token = unk_token
|
||||
|
||||
self.unk_index = -1
|
||||
if add_unk:
|
||||
self.unk_index = self.add_token(unk_token)
|
||||
|
||||
|
||||
def to_serializable(self):
|
||||
""" returns a dictionary that can be serialized """
|
||||
return {'token_to_idx': self._token_to_idx,
|
||||
'add_unk': self._add_unk,
|
||||
'unk_token': self._unk_token}
|
||||
|
||||
@classmethod
|
||||
def from_serializable(cls, contents):
|
||||
""" instantiates the Vocabulary from a serialized dictionary """
|
||||
return cls(**contents)
|
||||
|
||||
def add_token(self, token):
|
||||
"""Update mapping dicts based on the token.
|
||||
|
||||
Args:
|
||||
token (str): the item to add into the Vocabulary
|
||||
Returns:
|
||||
index (int): the integer corresponding to the token
|
||||
"""
|
||||
if token in self._token_to_idx:
|
||||
index = self._token_to_idx[token]
|
||||
else:
|
||||
index = len(self._token_to_idx)
|
||||
self._token_to_idx[token] = index
|
||||
self._idx_to_token[index] = token
|
||||
return index
|
||||
|
||||
def add_many(self, tokens):
|
||||
"""Add a list of tokens into the Vocabulary
|
||||
|
||||
Args:
|
||||
tokens (list): a list of string tokens
|
||||
Returns:
|
||||
indices (list): a list of indices corresponding to the tokens
|
||||
"""
|
||||
return [self.add_token(token) for token in tokens]
|
||||
|
||||
def lookup_token(self, token):
|
||||
"""Retrieve the index associated with the token
|
||||
or the UNK index if token isn't present.
|
||||
|
||||
Args:
|
||||
token (str): the token to look up
|
||||
Returns:
|
||||
index (int): the index corresponding to the token
|
||||
Notes:
|
||||
`unk_index` needs to be >=0 (having been added into the Vocabulary)
|
||||
for the UNK functionality
|
||||
"""
|
||||
if self.unk_index >= 0:
|
||||
return self._token_to_idx.get(token, self.unk_index)
|
||||
else:
|
||||
return self._token_to_idx[token]
|
||||
|
||||
def lookup_index(self, index):
|
||||
"""Return the token associated with the index
|
||||
|
||||
Args:
|
||||
index (int): the index to look up
|
||||
Returns:
|
||||
token (str): the token corresponding to the index
|
||||
Raises:
|
||||
KeyError: if the index is not in the Vocabulary
|
||||
"""
|
||||
if index not in self._idx_to_token:
|
||||
raise KeyError("the index (%d) is not in the Vocabulary" % index)
|
||||
return self._idx_to_token[index]
|
||||
|
||||
def __str__(self):
|
||||
return "<Vocabulary(size=%d)>" % len(self)
|
||||
|
||||
def __len__(self):
|
||||
return len(self._token_to_idx)
|
||||
|
||||
|
||||
|
||||
|
||||
class ReviewVectorizer(object):
|
||||
""" The Vectorizer which coordinates the Vocabularies and puts them to use"""
|
||||
def __init__(self, review_vocab, rating_vocab):
|
||||
"""
|
||||
Args:
|
||||
review_vocab (Vocabulary): maps words to integers
|
||||
rating_vocab (Vocabulary): maps class labels to integers
|
||||
"""
|
||||
self.review_vocab = review_vocab
|
||||
self.rating_vocab = rating_vocab
|
||||
|
||||
def vectorize(self, review):
|
||||
"""Create a collapsed one-hit vector for the review
|
||||
|
||||
Args:
|
||||
review (str): the review
|
||||
Returns:
|
||||
one_hot (np.ndarray): the collapsed one-hot encoding
|
||||
"""
|
||||
one_hot = np.zeros(len(self.review_vocab), dtype=np.float32)
|
||||
|
||||
for token in review.split(" "):
|
||||
if token not in string.punctuation:
|
||||
one_hot[self.review_vocab.lookup_token(token)] = 1
|
||||
|
||||
return one_hot
|
||||
|
||||
@classmethod
|
||||
def from_dataframe(cls, review_df, cutoff=25):
|
||||
"""Instantiate the vectorizer from the dataset dataframe
|
||||
|
||||
Args:
|
||||
review_df (pandas.DataFrame): the review dataset
|
||||
cutoff (int): the parameter for frequency-based filtering
|
||||
Returns:
|
||||
an instance of the ReviewVectorizer
|
||||
"""
|
||||
review_vocab = Vocabulary(add_unk=True)
|
||||
rating_vocab = Vocabulary(add_unk=False)
|
||||
|
||||
# Add ratings
|
||||
for rating in sorted(set(review_df.rating)):
|
||||
rating_vocab.add_token(rating)
|
||||
|
||||
# Add top words if count > provided count
|
||||
word_counts = Counter()
|
||||
for review in review_df.review:
|
||||
for word in review.split(" "):
|
||||
if word not in string.punctuation:
|
||||
word_counts[word] += 1
|
||||
|
||||
for word, count in word_counts.items():
|
||||
if count > cutoff:
|
||||
review_vocab.add_token(word)
|
||||
|
||||
return cls(review_vocab, rating_vocab)
|
||||
|
||||
@classmethod
|
||||
def from_serializable(cls, contents):
|
||||
"""Instantiate a ReviewVectorizer from a serializable dictionary
|
||||
|
||||
Args:
|
||||
contents (dict): the serializable dictionary
|
||||
Returns:
|
||||
an instance of the ReviewVectorizer class
|
||||
"""
|
||||
review_vocab = Vocabulary.from_serializable(contents['review_vocab'])
|
||||
rating_vocab = Vocabulary.from_serializable(contents['rating_vocab'])
|
||||
|
||||
return cls(review_vocab=review_vocab, rating_vocab=rating_vocab)
|
||||
|
||||
def to_serializable(self):
|
||||
"""Create the serializable dictionary for caching
|
||||
|
||||
Returns:
|
||||
contents (dict): the serializable dictionary
|
||||
"""
|
||||
return {'review_vocab': self.review_vocab.to_serializable(),
|
||||
'rating_vocab': self.rating_vocab.to_serializable()}
|
||||
|
||||
|
||||
|
||||
class ReviewDataset(Dataset):
|
||||
def __init__(self, review_df, vectorizer):
|
||||
"""
|
||||
Args:
|
||||
review_df (pandas.DataFrame): the dataset
|
||||
vectorizer (ReviewVectorizer): vectorizer instantiated from dataset
|
||||
"""
|
||||
self.review_df = review_df
|
||||
self._vectorizer = vectorizer
|
||||
|
||||
self.train_df = self.review_df[self.review_df.split=='train']
|
||||
self.train_size = len(self.train_df)
|
||||
|
||||
self.val_df = self.review_df[self.review_df.split=='val']
|
||||
self.validation_size = len(self.val_df)
|
||||
|
||||
self.test_df = self.review_df[self.review_df.split=='test']
|
||||
self.test_size = len(self.test_df)
|
||||
|
||||
self._lookup_dict = {'train': (self.train_df, self.train_size),
|
||||
'val': (self.val_df, self.validation_size),
|
||||
'test': (self.test_df, self.test_size)}
|
||||
|
||||
self.set_split('train')
|
||||
|
||||
@classmethod
|
||||
def load_dataset_and_make_vectorizer(cls, review_csv):
|
||||
"""Load dataset and make a new vectorizer from scratch
|
||||
|
||||
Args:
|
||||
review_csv (str): location of the dataset
|
||||
Returns:
|
||||
an instance of ReviewDataset
|
||||
"""
|
||||
review_df = pd.read_csv(review_csv)
|
||||
train_review_df = review_df[review_df.split=='train']
|
||||
return cls(review_df, ReviewVectorizer.from_dataframe(train_review_df))
|
||||
|
||||
@classmethod
|
||||
def load_dataset_and_load_vectorizer(cls, review_csv, vectorizer_filepath):
|
||||
"""Load dataset and the corresponding vectorizer.
|
||||
Used in the case in the vectorizer has been cached for re-use
|
||||
|
||||
Args:
|
||||
review_csv (str): location of the dataset
|
||||
vectorizer_filepath (str): location of the saved vectorizer
|
||||
Returns:
|
||||
an instance of ReviewDataset
|
||||
"""
|
||||
review_df = pd.read_csv(review_csv)
|
||||
vectorizer = cls.load_vectorizer_only(vectorizer_filepath)
|
||||
return cls(review_df, vectorizer)
|
||||
|
||||
@staticmethod
|
||||
def load_vectorizer_only(vectorizer_filepath):
|
||||
"""a static method for loading the vectorizer from file
|
||||
|
||||
Args:
|
||||
vectorizer_filepath (str): the location of the serialized vectorizer
|
||||
Returns:
|
||||
an instance of ReviewVectorizer
|
||||
"""
|
||||
with open(vectorizer_filepath) as fp:
|
||||
return ReviewVectorizer.from_serializable(json.load(fp))
|
||||
|
||||
def save_vectorizer(self, vectorizer_filepath):
|
||||
"""saves the vectorizer to disk using json
|
||||
|
||||
Args:
|
||||
vectorizer_filepath (str): the location to save the vectorizer
|
||||
"""
|
||||
with open(vectorizer_filepath, "w") as fp:
|
||||
json.dump(self._vectorizer.to_serializable(), fp)
|
||||
|
||||
def get_vectorizer(self):
|
||||
""" returns the vectorizer """
|
||||
return self._vectorizer
|
||||
|
||||
def set_split(self, split="train"):
|
||||
""" selects the splits in the dataset using a column in the dataframe
|
||||
|
||||
Args:
|
||||
split (str): one of "train", "val", or "test"
|
||||
"""
|
||||
self._target_split = split
|
||||
self._target_df, self._target_size = self._lookup_dict[split]
|
||||
|
||||
def __len__(self):
|
||||
return self._target_size
|
||||
|
||||
def __getitem__(self, index):
|
||||
"""the primary entry point method for PyTorch datasets
|
||||
|
||||
Args:
|
||||
index (int): the index to the data point
|
||||
Returns:
|
||||
a dictionary holding the data point's features (x_data) and label (y_target)
|
||||
"""
|
||||
row = self._target_df.iloc[index]
|
||||
|
||||
review_vector = \
|
||||
self._vectorizer.vectorize(row.review)
|
||||
|
||||
rating_index = \
|
||||
self._vectorizer.rating_vocab.lookup_token(row.rating)
|
||||
|
||||
return {'x_data': review_vector,
|
||||
'y_target': rating_index}
|
||||
|
||||
def get_num_batches(self, batch_size):
|
||||
"""Given a batch size, return the number of batches in the dataset
|
||||
|
||||
Args:
|
||||
batch_size (int)
|
||||
Returns:
|
||||
number of batches in the dataset
|
||||
"""
|
||||
return len(self) // batch_size
|
||||
|
||||
def generate_batches(dataset, batch_size, shuffle=True,
|
||||
drop_last=True, device="cpu"):
|
||||
"""
|
||||
A generator function which wraps the PyTorch DataLoader. It will
|
||||
ensure each tensor is on the write device location.
|
||||
"""
|
||||
dataloader = DataLoader(dataset=dataset, batch_size=batch_size,
|
||||
shuffle=shuffle, drop_last=drop_last)
|
||||
|
||||
for data_dict in dataloader:
|
||||
out_data_dict = {}
|
||||
for name, tensor in data_dict.items():
|
||||
out_data_dict[name] = data_dict[name].to(device)
|
||||
yield out_data_dict
|
||||
|
||||
|
||||
|
||||
class ReviewClassifier(nn.Module):
|
||||
""" a simple perceptron based classifier """
|
||||
def __init__(self, num_features):
|
||||
"""
|
||||
Args:
|
||||
num_features (int): the size of the input feature vector
|
||||
"""
|
||||
super(ReviewClassifier, self).__init__()
|
||||
self.fc1 = nn.Linear(in_features=num_features,
|
||||
out_features=1)
|
||||
|
||||
def forward(self, x_in, apply_sigmoid=False):
|
||||
"""The forward pass of the classifier
|
||||
|
||||
Args:
|
||||
x_in (torch.Tensor): an input data tensor.
|
||||
x_in.shape should be (batch, num_features)
|
||||
apply_sigmoid (bool): a flag for the sigmoid activation
|
||||
should be false if used with the Cross Entropy losses
|
||||
Returns:
|
||||
the resulting tensor. tensor.shape should be (batch,)
|
||||
"""
|
||||
y_out = self.fc1(x_in).squeeze()
|
||||
if apply_sigmoid:
|
||||
y_out = torch.sigmoid(y_out)
|
||||
return y_out
|
||||
|
||||
|
||||
|
||||
|
||||
def make_train_state(args):
|
||||
return {'stop_early': False,
|
||||
'early_stopping_step': 0,
|
||||
'early_stopping_best_val': 1e8,
|
||||
'learning_rate': args.learning_rate,
|
||||
'epoch_index': 0,
|
||||
'train_loss': [],
|
||||
'train_acc': [],
|
||||
'val_loss': [],
|
||||
'val_acc': [],
|
||||
'test_loss': -1,
|
||||
'test_acc': -1,
|
||||
'model_filename': args.model_state_file}
|
||||
|
||||
def update_train_state(args, model, train_state):
|
||||
"""Handle the training state updates.
|
||||
|
||||
Components:
|
||||
- Early Stopping: Prevent overfitting.
|
||||
- Model Checkpoint: Model is saved if the model is better
|
||||
|
||||
:param args: main arguments
|
||||
:param model: model to train
|
||||
:param train_state: a dictionary representing the training state values
|
||||
:returns:
|
||||
a new train_state
|
||||
"""
|
||||
|
||||
# Save one model at least
|
||||
if train_state['epoch_index'] == 0:
|
||||
torch.save(model.state_dict(), train_state['model_filename'])
|
||||
train_state['stop_early'] = False
|
||||
|
||||
# Save model if performance improved
|
||||
elif train_state['epoch_index'] >= 1:
|
||||
loss_tm1, loss_t = train_state['val_loss'][-2:]
|
||||
|
||||
# If loss worsened
|
||||
if loss_t >= train_state['early_stopping_best_val']:
|
||||
# Update step
|
||||
train_state['early_stopping_step'] += 1
|
||||
# Loss decreased
|
||||
else:
|
||||
# Save the best model
|
||||
if loss_t < train_state['early_stopping_best_val']:
|
||||
torch.save(model.state_dict(), train_state['model_filename'])
|
||||
|
||||
# Reset early stopping step
|
||||
train_state['early_stopping_step'] = 0
|
||||
|
||||
# Stop early ?
|
||||
train_state['stop_early'] = \
|
||||
train_state['early_stopping_step'] >= args.early_stopping_criteria
|
||||
|
||||
return train_state
|
||||
|
||||
def compute_accuracy(y_pred, y_target):
|
||||
y_target = y_target.cpu()
|
||||
y_pred_indices = (torch.sigmoid(y_pred)>0.5).cpu().long()#.max(dim=1)[1]
|
||||
n_correct = torch.eq(y_pred_indices, y_target).sum().item()
|
||||
return n_correct / len(y_pred_indices) * 100
|
||||
|
||||
|
||||
|
||||
|
||||
def set_seed_everywhere(seed, cuda):
|
||||
np.random.seed(seed)
|
||||
torch.manual_seed(seed)
|
||||
if cuda:
|
||||
torch.cuda.manual_seed_all(seed)
|
||||
|
||||
def handle_dirs(dirpath):
|
||||
if not os.path.exists(dirpath):
|
||||
os.makedirs(dirpath)
|
||||
|
||||
|
||||
|
||||
|
||||
args = Namespace(
|
||||
# Data and Path information
|
||||
frequency_cutoff=25,
|
||||
model_state_file='model.pth',
|
||||
review_csv='data/yelp/reviews_with_splits_lite.csv',
|
||||
# review_csv='data/yelp/reviews_with_splits_full.csv',
|
||||
save_dir='model_storage/ch3/yelp/',
|
||||
vectorizer_file='vectorizer.json',
|
||||
# No Model hyper parameters
|
||||
# Training hyper parameters
|
||||
batch_size=128,
|
||||
early_stopping_criteria=5,
|
||||
learning_rate=0.001,
|
||||
num_epochs=100,
|
||||
seed=1337,
|
||||
# Runtime options
|
||||
catch_keyboard_interrupt=True,
|
||||
cuda=True,
|
||||
expand_filepaths_to_save_dir=True,
|
||||
reload_from_files=False,
|
||||
)
|
||||
|
||||
if args.expand_filepaths_to_save_dir:
|
||||
args.vectorizer_file = os.path.join(args.save_dir,
|
||||
args.vectorizer_file)
|
||||
|
||||
args.model_state_file = os.path.join(args.save_dir,
|
||||
args.model_state_file)
|
||||
|
||||
print("Expanded filepaths: ")
|
||||
print("\t{}".format(args.vectorizer_file))
|
||||
print("\t{}".format(args.model_state_file))
|
||||
|
||||
# Check CUDA
|
||||
if not torch.cuda.is_available():
|
||||
args.cuda = False
|
||||
if torch.cuda.device_count() > 1:
|
||||
print("Pouzivam", torch.cuda.device_count(), "graficke karty!")
|
||||
|
||||
args.device = torch.device("cuda" if args.cuda else "cpu")
|
||||
|
||||
# Set seed for reproducibility
|
||||
set_seed_everywhere(args.seed, args.cuda)
|
||||
|
||||
# handle dirs
|
||||
handle_dirs(args.save_dir)
|
||||
|
||||
|
||||
|
||||
|
||||
if args.reload_from_files:
|
||||
# training from a checkpoint
|
||||
print("Loading dataset and vectorizer")
|
||||
dataset = ReviewDataset.load_dataset_and_load_vectorizer(args.review_csv,
|
||||
args.vectorizer_file)
|
||||
else:
|
||||
print("Loading dataset and creating vectorizer")
|
||||
# create dataset and vectorizer
|
||||
dataset = ReviewDataset.load_dataset_and_make_vectorizer(args.review_csv)
|
||||
dataset.save_vectorizer(args.vectorizer_file)
|
||||
vectorizer = dataset.get_vectorizer()
|
||||
|
||||
classifier = ReviewClassifier(num_features=len(vectorizer.review_vocab))
|
||||
|
||||
|
||||
|
||||
classifier = nn.DataParallel(classifier)
|
||||
classifier = classifier.to(args.device)
|
||||
|
||||
loss_func = nn.BCEWithLogitsLoss()
|
||||
optimizer = optim.Adam(classifier.parameters(), lr=args.learning_rate)
|
||||
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer=optimizer,
|
||||
mode='min', factor=0.5,
|
||||
patience=1)
|
||||
|
||||
train_state = make_train_state(args)
|
||||
|
||||
epoch_bar = tqdm(desc='training routine',
|
||||
total=args.num_epochs,
|
||||
position=0)
|
||||
|
||||
dataset.set_split('train')
|
||||
train_bar = tqdm(desc='split=train',
|
||||
total=dataset.get_num_batches(args.batch_size),
|
||||
position=1,
|
||||
leave=True)
|
||||
dataset.set_split('val')
|
||||
val_bar = tqdm(desc='split=val',
|
||||
total=dataset.get_num_batches(args.batch_size),
|
||||
position=1,
|
||||
leave=True)
|
||||
|
||||
try:
|
||||
for epoch_index in range(args.num_epochs):
|
||||
train_state['epoch_index'] = epoch_index
|
||||
|
||||
# Iterate over training dataset
|
||||
|
||||
# setup: batch generator, set loss and acc to 0, set train mode on
|
||||
dataset.set_split('train')
|
||||
batch_generator = generate_batches(dataset,
|
||||
batch_size=args.batch_size,
|
||||
device=args.device)
|
||||
running_loss = 0.0
|
||||
running_acc = 0.0
|
||||
classifier.train()
|
||||
|
||||
for batch_index, batch_dict in enumerate(batch_generator):
|
||||
# the training routine is these 5 steps:
|
||||
|
||||
# --------------------------------------
|
||||
# step 1. zero the gradients
|
||||
optimizer.zero_grad()
|
||||
|
||||
# step 2. compute the output
|
||||
y_pred = classifier(x_in=batch_dict['x_data'].float())
|
||||
|
||||
# step 3. compute the loss
|
||||
loss = loss_func(y_pred, batch_dict['y_target'].float())
|
||||
loss_t = loss.item()
|
||||
running_loss += (loss_t - running_loss) / (batch_index + 1)
|
||||
|
||||
# step 4. use loss to produce gradients
|
||||
loss.backward()
|
||||
|
||||
# step 5. use optimizer to take gradient step
|
||||
optimizer.step()
|
||||
# -----------------------------------------
|
||||
# compute the accuracy
|
||||
acc_t = compute_accuracy(y_pred, batch_dict['y_target'])
|
||||
running_acc += (acc_t - running_acc) / (batch_index + 1)
|
||||
|
||||
# update bar
|
||||
train_bar.set_postfix(loss=running_loss,
|
||||
acc=running_acc,
|
||||
epoch=epoch_index)
|
||||
train_bar.update()
|
||||
|
||||
train_state['train_loss'].append(running_loss)
|
||||
train_state['train_acc'].append(running_acc)
|
||||
|
||||
# Iterate over val dataset
|
||||
|
||||
# setup: batch generator, set loss and acc to 0; set eval mode on
|
||||
dataset.set_split('val')
|
||||
batch_generator = generate_batches(dataset,
|
||||
batch_size=args.batch_size,
|
||||
device=args.device)
|
||||
running_loss = 0.
|
||||
running_acc = 0.
|
||||
classifier.eval()
|
||||
|
||||
for batch_index, batch_dict in enumerate(batch_generator):
|
||||
|
||||
# compute the output
|
||||
y_pred = classifier(x_in=batch_dict['x_data'].float())
|
||||
|
||||
# step 3. compute the loss
|
||||
loss = loss_func(y_pred, batch_dict['y_target'].float())
|
||||
loss_t = loss.item()
|
||||
running_loss += (loss_t - running_loss) / (batch_index + 1)
|
||||
|
||||
# compute the accuracy
|
||||
acc_t = compute_accuracy(y_pred, batch_dict['y_target'])
|
||||
running_acc += (acc_t - running_acc) / (batch_index + 1)
|
||||
|
||||
val_bar.set_postfix(loss=running_loss,
|
||||
acc=running_acc,
|
||||
epoch=epoch_index)
|
||||
val_bar.update()
|
||||
|
||||
train_state['val_loss'].append(running_loss)
|
||||
train_state['val_acc'].append(running_acc)
|
||||
|
||||
train_state = update_train_state(args=args, model=classifier,
|
||||
train_state=train_state)
|
||||
|
||||
scheduler.step(train_state['val_loss'][-1])
|
||||
|
||||
train_bar.n = 0
|
||||
val_bar.n = 0
|
||||
epoch_bar.update()
|
||||
|
||||
if train_state['stop_early']:
|
||||
break
|
||||
|
||||
train_bar.n = 0
|
||||
val_bar.n = 0
|
||||
epoch_bar.update()
|
||||
except KeyboardInterrupt:
|
||||
print("Exiting loop")
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
classifier.load_state_dict(torch.load(train_state['model_filename']))
|
||||
classifier = classifier.to(args.device)
|
||||
|
||||
dataset.set_split('test')
|
||||
batch_generator = generate_batches(dataset,
|
||||
batch_size=args.batch_size,
|
||||
device=args.device)
|
||||
running_loss = 0.
|
||||
running_acc = 0.
|
||||
classifier.eval()
|
||||
|
||||
for batch_index, batch_dict in enumerate(batch_generator):
|
||||
# compute the output
|
||||
y_pred = classifier(x_in=batch_dict['x_data'].float())
|
||||
|
||||
# compute the loss
|
||||
loss = loss_func(y_pred, batch_dict['y_target'].float())
|
||||
loss_t = loss.item()
|
||||
running_loss += (loss_t - running_loss) / (batch_index + 1)
|
||||
|
||||
# compute the accuracy
|
||||
acc_t = compute_accuracy(y_pred, batch_dict['y_target'])
|
||||
running_acc += (acc_t - running_acc) / (batch_index + 1)
|
||||
|
||||
train_state['test_loss'] = running_loss
|
||||
train_state['test_acc'] = running_acc
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
print("Test loss: {:.3f}".format(train_state['test_loss']))
|
||||
print("Test Accuracy: {:.2f}".format(train_state['test_acc']))
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
def preprocess_text(text):
|
||||
text = text.lower()
|
||||
text = re.sub(r"([.,!?])", r" \1 ", text)
|
||||
text = re.sub(r"[^a-zA-Z.,!?]+", r" ", text)
|
||||
return text
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
def predict_rating(review, classifier, vectorizer, decision_threshold=0.5):
|
||||
"""Predict the rating of a review
|
||||
|
||||
Args:
|
||||
review (str): the text of the review
|
||||
classifier (ReviewClassifier): the trained model
|
||||
vectorizer (ReviewVectorizer): the corresponding vectorizer
|
||||
decision_threshold (float): The numerical boundary which separates the rating classes
|
||||
"""
|
||||
review = preprocess_text(review)
|
||||
|
||||
vectorized_review = torch.tensor(vectorizer.vectorize(review))
|
||||
result = classifier(vectorized_review.view(1, -1))
|
||||
|
||||
probability_value = F.sigmoid(result).item()
|
||||
index = 1
|
||||
if probability_value < decision_threshold:
|
||||
index = 0
|
||||
|
||||
return vectorizer.rating_vocab.lookup_index(index)
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
test_review = "this is a pretty awesome book"
|
||||
|
||||
classifier = classifier.cpu()
|
||||
prediction = predict_rating(test_review, classifier, vectorizer, decision_threshold=0.5)
|
||||
print("{} -> {}".format(test_review, prediction))
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
# Sort weights
|
||||
fc1_weights = classifier.fc1.weight.detach()[0]
|
||||
_, indices = torch.sort(fc1_weights, dim=0, descending=True)
|
||||
indices = indices.numpy().tolist()
|
||||
|
||||
# Top 20 words
|
||||
print("Influential words in Positive Reviews:")
|
||||
print("--------------------------------------")
|
||||
for i in range(20):
|
||||
print(vectorizer.review_vocab.lookup_index(indices[i]))
|
||||
|
||||
print("====\n\n\n")
|
||||
|
||||
# Top 20 negative words
|
||||
print("Influential words in Negative Reviews:")
|
||||
print("--------------------------------------")
|
||||
indices.reverse()
|
||||
for i in range(20):
|
||||
print(vectorizer.review_vocab.lookup_index(indices[i]))
|
||||
@ -1,3 +1,12 @@
|
||||
---
|
||||
title: Paralelné spracovanie
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [tp2020]
|
||||
tag: [gpu,nlp]
|
||||
author: Lukáš Pokrývka
|
||||
---
|
||||
|
||||
**Paralelné spracovanie**
|
||||
|
||||
Systémy na spracovanie prirodzeného jazyka (_z angl. Natural Language Processing_ – ďalej už len NLP), boli ešte v nedávnej minulosti založené na sériových algoritmoch, ktoré simulovali spôsob, ktorým ľudia čítajú text – slovo za slovom, riadok po riadku [1]. Keďže týmto štýlom boli prezentované všetky gramatické teórie, programátori ich týmto štýlom aj implementovali.
|
||||
|
||||
133
pages/students/2016/mark_feher/README.md
Normal file
@ -0,0 +1,133 @@
|
||||
---
|
||||
title: Márk Fehér
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [dp2022]
|
||||
tag: [scikit,nlp,klasifikácia]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
# Diplomová práca 2022
|
||||
|
||||
Názov diplomovej práce: Klasifikácia textu metódami strojového učenia
|
||||
|
||||
- [GIT repozitár](https://git.kemt.fei.tuke.sk/mf425hk/dp2022)
|
||||
|
||||
## Návrh na zadanie DP
|
||||
|
||||
1. Vypracujte prehľad metód klasifikácie textu metódami strojového učenia.
|
||||
2. Pripravte slovenské trénovacie dáta vo vhodnom formáte a natrénujte viacero modelov pre klasifikáciu textu do viacerých kategórií
|
||||
3. Navrhnite, vykonajte a vyhodnoťte experimenty pre porovnanie presnosti klasifikácie textu.
|
||||
4. Navrhnite zlepšenia presnosti klasifikácie textu.
|
||||
|
||||
18.3.
|
||||
|
||||
- Práca na texte pokračuje
|
||||
- Podarilo sa spustiť finetning huggingface glue s scnc datasetom.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračovať v texte.
|
||||
- LSTM trénovanie urobené, výsledky sú v práci.
|
||||
- Pokúsiť sa urobiť dataset interface na vlastné dáta.
|
||||
|
||||
4.3.2022
|
||||
|
||||
- Stretnutie bolo aj minulý týždeň.
|
||||
- LSTM trénovanie beží (skoro ukončené).
|
||||
- SlovakBert na colab prvé výsledky cca 65 percent na scnc (asi tam je chyba).
|
||||
- Práca na texte pokračuje.
|
||||
- Vedúcim dodaný skript na scnc datasets rozhranie
|
||||
- Vedúcim dodaný skript na trénovanie run_glue.py
|
||||
- Dodaný skript na inštaláciu pytorch a cuda 11.3
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Práca na texte - sumarizácia experimentov do tabuľky
|
||||
- Vyskúšať dotrénovanie na idoc pomocou dodaných skriptov.
|
||||
- Na trénovanie na pozadí použiť `tmux a -t 0`.
|
||||
|
||||
## Diplomový projekt 2021
|
||||
|
||||
Stretnutie 3.12.
|
||||
|
||||
- Dopracované vyhodnotenie pomocou SCNC. Výsledkom je konfúzna matica a grafy presnosti so štatistickými modelmi.
|
||||
- Rozpracovaná klasifikácia LSTM (Keras).
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pridať klasifikáciu pomocou Huggingface Transformers, model SlovakBert, multilingualBert, alebo aj iné multilinguálne modely.
|
||||
- dokončiť LSTM.
|
||||
- Pokračovať na textovej časti.
|
||||
- Zobrazte aj F1
|
||||
|
||||
|
||||
Stretnutie 5.11.2021
|
||||
|
||||
- Práca na texte, štúdium literatúry
|
||||
- pridané kódy na GIT
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zopakujte experimenty na korpuse scnc. Slovak Categorized News Corpus.
|
||||
- Pokračujte v otvorených úlohách
|
||||
- Upravte skripty do opakovateľnej podoby, pripravte dokumentáciu k skriptom.
|
||||
|
||||
|
||||
Stretnutie 15.10.
|
||||
|
||||
- trénovanie pomocou LSTM, zatiaľ nie je na gite
|
||||
- písanie do šabóny práce (cca 35 strán).
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Doplniť na GIT.
|
||||
- Zabrániť overfittingu LSTM. Early stopping alebo dropout.
|
||||
|
||||
Stretnutie 1.10.
|
||||
|
||||
Stav:
|
||||
|
||||
- modifikácia trénovacích skriptov na vypisovanie pomocných štatistík.
|
||||
- Vytvorený GIT repozitár
|
||||
- Práca na text (cca 22 strán)
|
||||
- Pridaná referenčná literatúra.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Stiahnite si šablónu práce a vložte text čo máte pripravené, vrátane bibliografie.
|
||||
- [x] Doplňte zdrojové kódy na GITe, tak aby boli opakovateľné.
|
||||
- [x] Zoznam knižníc zapíšte do súboru requirements.txt.
|
||||
- Alebo zapíšte zoznam conda balíčkov.
|
||||
- Vyberte jednu úlohu zo zásobníka a vypracujte ju.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vyskúšajte klasifikáciu pomocou neurónových sietí.
|
||||
- Vytvorte web demo pomocou Docker
|
||||
- [x] Skúste klasifikáciu pomocou neurónovej siete.
|
||||
|
||||
|
||||
|
||||
|
||||
Stretnutie 23.9.
|
||||
|
||||
Stav:
|
||||
|
||||
- vypracovaný draft diplomovej práce
|
||||
- pripravené dáta z BeautifulSoup - z rôznych webov (sme.sk)
|
||||
- vypracované experimenty pomocou scikit-learn na klasifikátoroch:
|
||||
- multinomial Bayes
|
||||
- random forest
|
||||
- support vector machine
|
||||
- Stochastic Gradient Descent Classifier
|
||||
- k-neighbours
|
||||
- decision tree
|
||||
- vypracované vyhodnotenie pomocou konfúznej matice,
|
||||
|
||||
|
||||
Ciele na ďalšie stretnutie:
|
||||
|
||||
- Vytvoríte si repozitár dp2022 na školskom gite, kde dáte dáta, zdrojové kódy aj texty.
|
||||
- Vybrať jeden odborný článok alebo knihu o klasifikácii textu a vypracujte poznámky.
|
||||
|
||||
@ -3,13 +3,477 @@ title: Maroš Harahus
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [dp2021,bp2019]
|
||||
tag: [spacy,nlp]
|
||||
tag: [spelling,spacy,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
# Maroš Harahus
|
||||
|
||||
- [Git repozitár ai4steel](https://git.kemt.fei.tuke.sk/ai4steel/ai4steel) (pre členov skupiny)
|
||||
- [GIT repozitár s poznámkami](https://git.kemt.fei.tuke.sk/mh496vd/Doktorandske) (súkromný)
|
||||
|
||||
|
||||
## Dizertačná práca
|
||||
|
||||
v roku 2023/24
|
||||
|
||||
Automatické opravy textu a spracovanie prirodzeného jazyka
|
||||
|
||||
Ciele:
|
||||
|
||||
- Zverejniť a obhájiť minimovku
|
||||
- Napísať dizertačnú prácu
|
||||
- Publikovať 2 články triedy Q2-Q3
|
||||
|
||||
Súvisiaca BP [Vladyslav Krupko](/students/2020/vladyslav_krupko)
|
||||
|
||||
|
||||
## Druhý rok doktorandského štúdia
|
||||
|
||||
Ciele:
|
||||
|
||||
- *Publikovanie článku Q2/Q3* - podmienka pre pokračovanie v štúdiu.
|
||||
- *Obhájiť minimovku*. Minimovka by mala obsahovať definíciu riešenej úlohy, prehľad problematiky, tézy dizertačnej práce - vedecké prínosy.
|
||||
- Poskytnite najnovší prehľad.
|
||||
- Popísať vedecký prínos dizertačnej práce
|
||||
- Zverejniť min. 1 príspevok na školskej konferencii.
|
||||
- Publikovať min. 1 riadny konferenčný príspevok.
|
||||
- Pripraviť demo.
|
||||
- Pomáhať s výukou, projektami a výskumom.
|
||||
|
||||
### Návrh na tézy dizertačnej práce
|
||||
|
||||
Automatické opravy textu pri spracovaní prirodzeného jazyka
|
||||
|
||||
Hlavným cieľom dizertačnej práce je návrh, implementácia a overenie modelu pre automatickú opravu textov.
|
||||
|
||||
Na splnenie tohto cieľa je potrebné vykonať tieto úlohy:
|
||||
|
||||
1. Analyzovať súčasný stav modelov pre opravu gramatických chýb a preklepov.
|
||||
2. Vybrať vhodné metódy a navrhnúť vlastný model pre automatickú opravu textov v slovenskom jazyku.
|
||||
3. Navrhnúť a pripraviť metódu augumentácie dát generovaním chýb v texte.
|
||||
4. Zozbierať dáta a pripraviť ich do podoby vhodnej na overenie modelu pre automatickú opravu slovenského textu.
|
||||
5. Navrhnúť a vykonať viacero experimentov pre overenie a porovnanie navrhnutého modelu.
|
||||
|
||||
|
||||
|
||||
Plán činosti na semester:
|
||||
|
||||
1. Prediskutovať a vybrať definitívnu tému. Obidve témy sú komplikované.
|
||||
- Trénovanie jazykových modelov. Cieľom by bolo zlepšenie jazykového modelovania.
|
||||
- [x] Dá sa nadviazať na existujúce trénovacie skripty.
|
||||
- [x] Dá sa využiť webový korpus.
|
||||
- [x] Dá sa využiť naša GPU infraštruktúra. (Na trénovanie menších modelov)
|
||||
- [x] Veľký praktický prínos.
|
||||
- [ ] Teoretický prínos je otázny.
|
||||
- [ ] Naša infraštruktúra je asi slabá na väčšie modely.
|
||||
- Oprava gramatických chýb.
|
||||
- [x] Dá sa nadviazať na "spelling correction" výskum a skripty.
|
||||
- [x] Teoretický prínos je väčší.
|
||||
- [x] Trénovanie by bolo jednoduchšie na našom HW.
|
||||
- Posledné review je z [2020](https://scholar.google.sk/scholar?hl=en&as_sdt=0%2C5&q=grammatical+error+correction+survey&btnG=)
|
||||
|
||||
|
||||
2. Napísať prehľadový článok.
|
||||
- Prečítať existujúce prehľady na danú tému. Zistitť ako boli napísané, kde boli uverejnené, čo je ich prínos. Je dobré použiť metodiku https://www.prisma-statement.org//
|
||||
- Identifikovať v čom by bol náš prehľad originálny a kde by bolo možné uverejniť.
|
||||
- Prečítať a zotriediť aspoň 200 článkov na danú tému.
|
||||
- Zistiť, aké metódy, datasety a spôsoby vyhodnotenia sa používajú.
|
||||
- Rozšíriť prehľadový článok do formy minimovky.
|
||||
|
||||
3. Priebežne pracovať na experimentoch.
|
||||
- Vybrať vhodnú dátovú množinu a metriku vyhodotenia.
|
||||
- Vybrať základnú metódu a vyhodnotiť.
|
||||
- Vyskúšať modifikáciu základnej metódy a vyhodotiť.
|
||||
|
||||
4. Napísať 2 konferenčné články.
|
||||
- Písať si poznámky pri experimentoch.
|
||||
- Predbežné experimenty zverejniť v krátkom článku.
|
||||
- Prediskutovať spôsob financovania.
|
||||
|
||||
Stretnutie 27.10.
|
||||
|
||||
Stav:
|
||||
|
||||
- Prečítaných a spoznámkovaných cca 4O článkov na tému "Grammar Error Correction".
|
||||
- Experimenty strojový preklad s Fairseq. Z toho vznikol článok SAMI.
|
||||
- Poznámky o Transfer Leaarning. Preštudované GPT3.
|
||||
- Sú rozpracované ďalšie modely pre strojový preklad. Česko-slovenský.
|
||||
- https://github.com/KaushalBajaj11/GEC--Grammatical-Error-Correction
|
||||
- https://github.com/LukasStankevicius/Towards-Lithuanian-Grammatical-Error-Correction
|
||||
- https://github.com/yuantiku/fairseq-gec
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Rozbehať fairseq GEC a porozmýšľať ako by a to dalo zlepšiť.
|
||||
- Pozrieť si prehľad https://scholar.google.sk/scholar?hl=en&as_sdt=0%2C5&q=question+generation&btnG=&oq=question+ge a napísať niekoľko poznámok. Vedeli by sme nájsť prínos?
|
||||
|
||||
Nápady:
|
||||
|
||||
- Smerovať to na inú generatívnu úlohu podobnú strojovému prekladu. Napríklad "Question generation".
|
||||
- question generation by sa dalo použiť na zlepšenie QA-IR systémov.
|
||||
- Možno "multilingual question generation"?
|
||||
|
||||
Stretnutie 9.9.2022
|
||||
|
||||
Stav:
|
||||
|
||||
Počas prázdnin sa pracovalo na experimentoch s fairseq - strojový preklad a Spacy trénovanie, štúdium literatúry.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [x] Prečítať niekoľko prehľadov na tému Grammar Correction, zistiť ako sú napísané a čo je v nich napísané.
|
||||
- [x] Prečítať niekoľko prehľadov (survey) na tému Neural Language Modelling - BERT Type models. Zistiť, kde je priestor na vedecký prínos.
|
||||
- [x] Zistiť čo je to Transfer Learning. https://ieeexplore.ieee.org/abstract/document/9134370
|
||||
- Na obe témy vyhľadať a prečítať niekoľko článkov. Uložiť záznam do databázy, napísať poznánky ku článku.
|
||||
- [ ] Porozmýšľať nad témou práce.
|
||||
- [x] Pokračovať v experimenotch fairseq so strojovým prekladom. Vieme pripraviť experiment na tému "spelling", "grammar" alebo training "roberta small", "bart small" na web korpuse? Toto by sa mohlo publikovať na konferenčnom článku do konca roka. treba vybrať dátovú množinu, metodiku vyhodnoteia, metódu trénovania.
|
||||
- [-] Čítať knihy - Bishop-Patter Recognition. Yang: Transfer Learning.
|
||||
|
||||
|
||||
|
||||
## Prvý ročník PhD štúdia
|
||||
|
||||
29.6.
|
||||
|
||||
- Vyskúšané https://github.com/NicGian/text_VAE, podľa článku https://arxiv.org/pdf/1511.06349.pdf
|
||||
Tento prístup je pôvodne na Question Generation. Využíva GLOVE embeding a VAE. Možno by sa to dalo využiť ako chybový model.
|
||||
- So skriptami fairseq sú zatiaľ problémy.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračovať v otvorených úlohách.
|
||||
- Vyskúšať tutoriál https://fairseq.readthedocs.io/en/latest/getting_started.html#training-a-new-model.
|
||||
- Prečítať knihu "Bishop: Pattern Recognition".
|
||||
|
||||
|
||||
17.6.
|
||||
|
||||
- Končí financovanie USsteel , je potrebné zmeniť tému.
|
||||
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Do konca ďalšieho školského roka submitovať karent článok. To je podmienka pre ďalšie pokračovanie. Článok by mal nadviazať na predošlý výskum v oblasti "spelling correction".
|
||||
- Preštudovať články:
|
||||
* Survey of automatic spelling correction
|
||||
* Learning string distance with smoothing for OCR spelling correction
|
||||
* Sequence to Sequence Convolutional Neural Network for Automatic Spelling Correction
|
||||
* Iné súvisiace články. Kľúčové slová: "automatic spelling correction."
|
||||
- Naučiť sa pracovať s fairseq. Naučiť sa ako funguje strojový preklad.
|
||||
- Zopakovať experiment OCR Trec-5 Confusion Track. Pridaný prístup do repozitára https://git.kemt.fei.tuke.sk/dano/correct
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vymyslieť systém pre opravu gramatických chýb. Aka Grammarly.
|
||||
- Využiť GAN-VAE sieť na generovanie chybového textu. To by mohlo pomôcť pri učení NS.
|
||||
|
||||
|
||||
|
||||
3.6.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pripraviť experiment pri ktorom sa vyhodnotia rôzne spôsoby zhlukovania pre rôzne veľkosti priestoru (PCA, k-means, DBSCAN, KernelPCA - to mi padalo). Základ je v súbore embed.py
|
||||
- Do tabuľky spísať najdôležitejšie a najmenej dôležité parametre pre rôzne konvertory a pre všetky konvertory naraz (furnace-linear.py).
|
||||
- Vypočítanie presnosti pre každý konvertor zo spojeného modelu, pokračovať.
|
||||
|
||||
27.5.
|
||||
|
||||
- Našli sme medzné hodnoty pre dáta zo skriptov USS.
|
||||
- Urobený skript, polynómová transformácia príznakov nepomáha.
|
||||
- rozrobený skript na generovanie dát GAN.
|
||||
|
||||
Otvorené úlohy:
|
||||
|
||||
- Pokračovať v otvorených úlohách.
|
||||
- (3) Urobiť zhlukovanie a pridať informáciu do dátovej množiny. Zistiť, či informácia o zhlukoch zlepšuje presnosť. Informácia o grade umožňuje predikciu.
|
||||
|
||||
Stretnutie 20.5.
|
||||
|
||||
Otvorené úlohy:
|
||||
|
||||
- [ ] (1) Vypočítanie presnosti pre každý konvertor zo spojeného modelu a porovnanie s osobitnými modelmi. Chceme potvrdiť či je spojený model lepší vo všetkých prípadoch.
|
||||
- [ ] (2) Doplniť fyzické limity pre jednotlivé kolónky do anotácie. Ktoré kolónky nemôžu byť negatívne? Tieto fyzické limity by mali byť zapracované do testu robustnosti.
|
||||
- [ ] (4) Overenie robustnosti modelu. Vymyslieť testy invariantnosti, ktoré overia ako sa model správa v extrémnej situácii. Urobiť funkciu, kotrá otestuje parametre lineárnej regresie a povie či je model validný. Urobiť funkciu, ktorá navrhne nejaké vstupy a otestuje, či je výstup validný.
|
||||
|
||||
Neprioritné úlohy:
|
||||
|
||||
- [o] Preskúmať možnosti zníženia rozmeru vstupného priestoru. PCA? alebo zhlukovanie? Zistiť, či vôbec má zmysel používať autoenóder (aj VAE). (Asi to nemá zmysel)
|
||||
- [x] Vyradenie niektorých kolóniek, podľa koeficientu lineárnej regresie (daniel, funguje ale nezlepšuje presnosť).
|
||||
- Generovať umelé "extrémne" dáta. Sledovať, ako sa model správa. Extrémne dáta by mali byť fyzicky možné.
|
||||
|
||||
|
||||
Urobené úlohy:
|
||||
|
||||
- Hľadanie hyperparametrov pre neurónku a náhodný les.
|
||||
|
||||
Report 29.4.2022
|
||||
|
||||
- Práca na VE.
|
||||
- Čítanie článkov.
|
||||
|
||||
Report 8.4.2022
|
||||
|
||||
- Študovanie teórie
|
||||
- Práca na VAE kóde rozpracovaný
|
||||
|
||||
Report 1.4.2022
|
||||
|
||||
- práca na DH neurónovej sieťi
|
||||

|
||||
- študovanie o Deep Belief Network
|
||||
|
||||
Stretnutie 28.3.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Dokončiť podrobnú anotáciu dát. Aké sú kazuálne súvisosti medzi atribútmi?
|
||||
- Zopakovať a vylepšiť DH neurónovú sieť na predikciu síry
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Zvážiť použitie Deep Belief Network.
|
||||
|
||||
Report 25.3.2022
|
||||
|
||||
- Porovnávanie dát január, február (subor je na gite)
|
||||
- Hodnotenie ešte nemám spisujem čo tým chcem dosiahnuť ci to ma vôbec zmysel na tom pracovať
|
||||
|
||||
Report 18.3.2022
|
||||
|
||||
- práca na dátach (príprava na TS, zisťovanie súvislosti, hľadanie hraničných hodnôt)
|
||||
- študovanie timesesries (https://heartbeat.comet.ml/building-deep-learning-model-to-predict-stock-prices-part-1-2-58e62ad754dd,)
|
||||
- študovanie o reinforcement learning (https://github.com/dennybritz/reinforcement-learning
|
||||
https://github.com/ShangtongZhang/reinforcement-learning-an-introduction)
|
||||
- študovanie o transfer learning
|
||||
- študovanie feature selection (https://machinelearningmastery.com/feature-selection-machine-learning-python/
|
||||
https://www.kdnuggets.com/2021/12/alternative-feature-selection-methods-machine-learning.html)
|
||||
|
||||
Report 11.3.2022
|
||||
|
||||
- Data Preprocessing (inspirácia- https://www.kaggle.com/tajuddinkh/drugs-prediction-data-preprocessing-json-to-csv)
|
||||
- Analyzovanie dát (inspirácia- https://www.kaggle.com/rounakbanik/ted-data-analysis, https://www.kaggle.com/lostinworlds/analysing-pokemon-dataset
|
||||
https://www.kaggle.com/kanncaa1/data-sciencetutorial-for-beginners)
|
||||
- Pracovanie na scripte jsnol --> csv
|
||||
|
||||
- Študovanie time series (https://www.machinelearningplus.com/time-series/time-series-analysis-python/
|
||||
Python Live - 1| Time Series Analysis in Python | Data Science with Python Training | Edureka
|
||||
Complete Python Pandas Data Science Tutorial! (Reading CSV/Excel files, Sorting, Filtering, Groupby)
|
||||
https://www.kaggle.com/kashnitsky/topic-9-part-1-time-series-analysis-in-python)
|
||||
- Time series články (https://ieeexplore.ieee.org/abstract/document/8853246
|
||||
https://ieeexplore.ieee.org/abstract/document/8931714
|
||||
https://ieeexplore.ieee.org/abstract/document/8942842
|
||||
https://arxiv.org/abs/2103.01904)
|
||||
|
||||
Working on:
|
||||
- Neurónovej siete pre GAN time series (stále mam nejaké errory)
|
||||
- klasickej neuronke
|
||||
|
||||
Stretnutie 1.3.2022
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zapracovať wandB pre reporting experimentov
|
||||
- Textovo opísať dáta
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vyskúšať predtrénovanie pomocou "historických dát".
|
||||
|
||||
Report 25.02.2022
|
||||
|
||||
- Prehlaď o jazykových modeloch (BERT, RoBERTa, BART, XLNet, GPT-3) (spracovane poznámky na gite)
|
||||
- Prehlaď o time-series GAN
|
||||
- Úprava skriptu z peci jsnol -- > csv
|
||||
- Skúšanie programu GAN na generovanie obrázkov (na pochopenie ako to funguje)
|
||||
- Hľadanie vhodnej implementácie na generovanie dát
|
||||
- Rozpracovaná (veľmi malo) analýza datasetu peci
|
||||
|
||||
Stretnutie 2.2.2022
|
||||
|
||||
In progress:
|
||||
|
||||
- Práca na prehľade článkov VAE-GAN
|
||||
- na (súkromný) git pridaný náhľad dát a tavný list
|
||||
- práca na Pandas skripte
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Dokončiť spacy článok
|
||||
- Dokončiť prehľad článkov
|
||||
- Pripraviť prezentáciu na spoločné stretnutie. Do prezentácie uveď čo si sa dozvedel o metódach VAE a GAN. Vysvetli, ako funguje "autoenkóder".
|
||||
- Napísať krátky blog vrátane odkazov nal literatúru o tom ako funguje neurónový jazykový model (BERT, Roberta, BART, GPT-3, XLNet). Ako funguje? Na čo všetko sa používa?
|
||||
|
||||
|
||||
Stretnutie 18.1.2022
|
||||
|
||||
Úlohy:
|
||||
|
||||
- [ ] Do git repozitára pridať súbor s podrobným popisom jednotlivých kolóniek v dátovej množine.
|
||||
- [-] Do git repozitára pridať skript na načítanie dát do Pandas formátu.
|
||||
- [ ] Vypracovať písomný prehľad metód modelovania procesov v oceliarni (kyslíkového konvertora BOS-basic oxygen steelmaking).
|
||||
- [x] Nájsť oznam najnovších článkov k vyhľadávaciuemu heslu "gan time series", "vae time series", "sequence modeling,prediction" napísať ku nim komentár (abstrakt z abstraktu) a dať na git.
|
||||
- [x] Preformulovať zadanie BP Stromp.
|
||||
- [-] Dokončiť draft článok spacy.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- [-] Získať prehľad o najnovších metódach NLP - transformers,GAN, VAE a nájsť súvis s modelovaním BOS.
|
||||
- [ ] nájsť vhodnú implementáciu gan-vae v pythone pre analýzu časových radov alebo postupnosti.
|
||||
|
||||
Stretnutie 17.1.2022
|
||||
|
||||
- Mame dáta z vysokej pece (500GB)
|
||||
- Zlepšený konvolučný autoenkóder - dosahuje state-of-the-art.
|
||||
- Prečítané niečo o transformers a word2vec.
|
||||
|
||||
Stretnutie 9.12.2021
|
||||
|
||||
- Natrénovaný autoenkóder (feed-forward) pre predikciu celkovej váhy Fe a obsahu S.
|
||||
- dát je celkom dosť.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vyskúšať iné neurónové siete (keras?).
|
||||
- Pohľadať dátové množiny, ktoré sú podobné riešenej úlohe. Napr. Open Data.
|
||||
|
||||
Stretnutie 26.11.2021
|
||||
|
||||
Dáta z US Steel:
|
||||
|
||||
- Najprv sa do vysokej pece nasypú suroviny.
|
||||
- Z tavby sa postupne odoberajú vzorky a meria sa množstvo jednotlivých vzoriek.
|
||||
- Na konci tavby sa robí finálna analýza taveniny.
|
||||
- Priebeh procesu závisí od vlastností konkrétnej pece. Sú vlastnosti pece stacionárne? Je možné , že vlastnosti pece sa v čase menia.
|
||||
- Cieľom je predpovedať výsledky anaýzy finálnej tavby na základe predošlých vzoriek?
|
||||
- Cieľom je predpovedať výsledky nasledujúceho odberu na základe predchádzajúcich?
|
||||
- Čo znamená "dobrá tavba"?
|
||||
- Čo znamená "dobrá predpoveď výsledkov"?
|
||||
- Je dôležitý čas odbery vzorky?
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Formulovať problém ako "predikcia časových radov" - sequence prediction.
|
||||
- Nápad: The analysis of time series : an introduction / Chris Chatfield. 5th ed. Boca Raton : Chapman and Hall, 1996. xii, 283 s. (Chapman & Hall texts in statistical science series). - ISBN 0-412-71640-2 (brož.).
|
||||
- Prezrieť literatúru a zistiť najnovšie metódy na predikciu.
|
||||
- Navrhnúť metódu konverzie dát na vektor príznakov. Sú potrebné binárne vektory?
|
||||
- Navrhnúť metódu výpočtu chybovej funkcie - asi euklidovská vzdialenosť medzi výsledkov a očakávaním.
|
||||
- Vyskúšať navrhnúť rekurentnú neurónovú sieť - RNN, GRU, LSTM.
|
||||
- Nápad: Transformer network, Generative Adversarial Network.
|
||||
- Nápad: Vyskúšať klasické štatistické modely (scikit-learn) - napr. aproximácia polynómom, alebo SVM.
|
||||
|
||||
Stretnutie 1.10.
|
||||
|
||||
Stav:
|
||||
|
||||
- Štúdium základov neurónových sietí
|
||||
- Úvodné stretnutie s US Steel
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vypracovať prehľad aktuálnych metód grafových neurónových sietí
|
||||
- Nájsť a vyskúšať toolkit na GNN.
|
||||
- Vytvoriť pracovný repozitár na GITe.
|
||||
- Naštudovať dáta z US Steel.
|
||||
- Publikovať diplomovú prácu.
|
||||
|
||||
|
||||
## Diplomová práca 2021
|
||||
|
||||
- [CRZP](https://opac.crzp.sk/?fn=detailBiblioForm&sid=ECC3D3F0B3159C4F3216E2027BE4)
|
||||
- [Zdrojové kódy](https://git.kemt.fei.tuke.sk/mh496vd/diplomovka/)
|
||||
|
||||
Názov diplomovej práce: Neurónová morfologická anotácia slovenského jazyka
|
||||
|
||||
1. Vysvetlite, ako funguje neurónová morfologická anotácia v knižnici Spacy. Vysvetlite, ako funguje predtrénovanie v knižnici Spacy.
|
||||
2. Pripravte slovenské trénovacie dáta vo vhodnom formáte a natrénujte základný model morfologickej anotácie pomocou knižnice Spacy.
|
||||
3. Pripravte model pre morfologickú anotáciu s pomocou predtrénovania.
|
||||
4. Vyhodnoťte presnosť značkovania modelov vo viacerých experimentoch a navrhnite možné zlepšenia.
|
||||
|
||||
## Diplomový projekt 2 2020
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- skúsiť prezentovať na lokálnej konferencii, (Data, Znalosti and WIKT) alebo fakultný zborník (krátka verzia diplomovky).
|
||||
- Využiť korpus Multext East pri trénovaní. Vytvoriť mapovanie Multext Tagov na SNK Tagy.
|
||||
- vykonať a opísať viac experinentov s rôznymi nastaveniami.
|
||||
|
||||
Stretnutie 12.2.
|
||||
|
||||
Stav:
|
||||
|
||||
- Práca na texte
|
||||
|
||||
Do ďalšieho stretnutia:
|
||||
|
||||
- Opraviť text podľa ústnej spätnej väzby
|
||||
- Vysvetlite čo je to morfologická anotácia.
|
||||
- Vystvetlite ako sa robí? Ako funguje spacy neurónová sieť?
|
||||
- atď. predošlé textové úlohy z 30.10. 2020
|
||||
|
||||
|
||||
Stretnutie 25.1.2021
|
||||
|
||||
Stav:
|
||||
|
||||
- Urobená prezentácia, spracované experimenty do tabuľky.
|
||||
|
||||
Do ďalšieho stretnutia:
|
||||
|
||||
- Pracovať na súvislom texte.
|
||||
|
||||
Virtuálne stretnutie 6.11.2020
|
||||
|
||||
Stav:
|
||||
|
||||
- Prečítané (podrobne) 2 články a urobené poznámky. Poznánky sú na GITe.
|
||||
- Dorobené ďalšie experimenty.
|
||||
|
||||
Úlohy do ďalšieho stretnutia:
|
||||
|
||||
- Pokračovať v otvorených úlohách.
|
||||
|
||||
|
||||
Virtuálne stretnutie 30.10.2020
|
||||
|
||||
Stav:
|
||||
|
||||
- Súbory sú na GIte
|
||||
- Vykonané experimenty, Výsledky experimentov sú v tabuľke
|
||||
- Návod na spustenie
|
||||
- Vyriešenie technických problémov. Je k dispozicíí Conda prostredie.
|
||||
|
||||
Úlohy na ďalšie stretnutie:
|
||||
|
||||
- Preštudovať literatúru na tému "pretrain" a "word embedding"
|
||||
- [Healthcare NER Models Using Language Model Pretraining](http://ceur-ws.org/Vol-2551/paper-04.pdf)
|
||||
- [Design and implementation of an open source Greek POS Tagger and Entity Recognizer using spaCy](https://ieeexplore.ieee.org/abstract/document/8909591)
|
||||
- https://arxiv.org/abs/1909.00505
|
||||
- https://arxiv.org/abs/1607.04606
|
||||
- LSTM, recurrent neural network,
|
||||
- Urobte si poznámky z viacerých čnánkov, poznačte si zdroj a čo ste sa dozvedeli.
|
||||
- Vykonať viacero experimentov s pretrénovaním - rôzne modely, rôzne veľkosti adaptačných dát a zostaviť tabuľku
|
||||
- Opísať pretrénovanie, zhrnúť vplyv pretrénovania na trénovanie v krátkom článku cca 10 strán.
|
||||
|
||||
|
||||
Virtuálne stretnutie 8.10.2020
|
||||
|
||||
Stav:
|
||||
- Podarilo sa vykonať pretrénovanie aj trénovanie, prvé výsledky experimentov.
|
||||
- pretrénovanie funguje na GPU, použila sa verzia spacy 2.2, trénovanie na IDOC
|
||||
- trénovanie ide lepšie na CPU
|
||||
- vyskytol sa problém že nevie alokovať viac ako 2GB RAM
|
||||
- 200 iterácií pretrénovania, 4000 riadkov viet
|
||||
|
||||
Úlohy do ďalšieho stretnutia:
|
||||
- Dať zdrojáky na GIT
|
||||
- Urobiť porovnanie voči presnosti bez pretrain
|
||||
- Výsledky dajte do tabuľky - aké parametre ste použili pri trénovaní a pretrénovaí?
|
||||
- experimenty si poznačte do skriptu aby sa dali zopakovať
|
||||
- Do článku (do súboru README na GIte) presne opíšte nastavenie experimentu - parametre, dáta a spôsob overenia, aspoň rozpracovať.
|
||||
- Začnite spisovať teoretickú časť článku, aspoň rozpracovať.
|
||||
|
||||
Stretnutie 25.9.2020
|
||||
|
||||
Stav:
|
||||
@ -57,18 +521,6 @@ K zápočtu:
|
||||
- Porovnajte s presnosťou bez pretrénovania.
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Preštudovať literatúru na tému "pretrain" a "word embedding"
|
||||
- [Healthcare NERModelsUsing Language Model Pretraining](http://ceur-ws.org/Vol-2551/paper-04.pdf)
|
||||
- [Design and implementation of an open source Greek POS Tagger and Entity Recognizer using spaCy](https://ieeexplore.ieee.org/abstract/document/8909591)
|
||||
- https://arxiv.org/abs/1909.00505
|
||||
- https://arxiv.org/abs/1607.04606
|
||||
- LSTM, recurrent neural network,
|
||||
- Vykonať viacero experimentov s pretrénovaním - rôzne modely, rôzne veľkosti adaptačných dát a zostaviť tabuľku
|
||||
- Opísať pretrénovanie, zhrnúť vplyv pretrénovania na trénovanie v krátkom článku cca 10 strán.
|
||||
- skúsiť prezentovať na lokálnej konferencii, (Data, Znalosti and WIKT) alebo fakultný zborník (krátka verzia diplomovky).
|
||||
- Využiť korpus Multext East pri trénovaní. Vytvoriť mapovanie Multext Tagov na SNK Tagy.
|
||||
|
||||
|
||||
Virtuálne stretnutie 15.5.2020:
|
||||
@ -130,15 +582,6 @@ Stretnutie: 20.2.2020:
|
||||
|
||||
|
||||
|
||||
## Návrh na zadanie DP
|
||||
|
||||
Názov diplomovej práce: Štatistická morfologická anotácia slovenského jazyka
|
||||
|
||||
1. Vypracujte prehľad spôsobov morfologickej anotácie slovenského jazyka.
|
||||
2. Pripravte trénovacie dáta vo vhodnom formáte a natrénujte štatistický model morfologického značkovania
|
||||
3. Vyhodnoťte presnosť značkovania a navrhnite možné zlepšenia.
|
||||
|
||||
|
||||
## Tímový projekt 2019
|
||||
|
||||
Projektové stránky:
|
||||
|
||||
@ -1,3 +1,11 @@
|
||||
---
|
||||
title: Spracovanie prirodzeného jazyka
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [tp2020]
|
||||
tag: [spacy,nlp]
|
||||
author: Maroš Harahus
|
||||
---
|
||||
# NLP
|
||||
|
||||
Je založený na umelej inteligencii, ktorá sa zaoberá interakciami medzi počítačom a jazykmi. NLP uľahčuje proces analýzy a
|
||||
|
||||
BIN
pages/students/2016/maros_harahus/uss.PNG
Normal file
{kind=link}
|
After Width: | Height: | Size: 35 KiB |
@ -2,13 +2,246 @@
|
||||
title: Patrik Pavlišin
|
||||
published: true
|
||||
taxonomy:
|
||||
category: [dp2021,bp2019]
|
||||
tag: [translation,nlp]
|
||||
category: [dp2022,bp2020,tp2021]
|
||||
tag: [nmt,translation,nlp]
|
||||
author: Daniel Hladek
|
||||
---
|
||||
# Patrik Pavlišin
|
||||
|
||||
## Bakalárksa práca 2019
|
||||
# Diplomová práca 2022
|
||||
|
||||
|
||||
Predbežný názov: Neurónový strojový preklad
|
||||
|
||||
Návrh na nástroje pre strojový preklad:
|
||||
|
||||
- OpenNMT-py
|
||||
- Fairseq
|
||||
- Hugging Face Transformers
|
||||
|
||||
|
||||
## Návrh na zadanie diplomovej práce
|
||||
|
||||
1. Pripraviť prehľad aktuálnych metód strojového prekladu pomocou neurónových sietí.
|
||||
2. Vybrať konkrétnu metódu strojového prekladu pomocou neurónových sietí a podrobne ju opísať.
|
||||
3. Pripraviť vybraný paralelný korpus do vhodnej podoby a pomocou vybranej metódy natrénovať model pre strojový preklad.
|
||||
4. Vyhodnotiť experimenty a navrhnúť možnosti na zlepšenie.
|
||||
|
||||
## Diplomový projekt 2
|
||||
|
||||
Ciele na semester:
|
||||
|
||||
1. Natrénovať "kvalitný model" na preklad z angličtiny do slovenčiny.
|
||||
2. Napísať draft diplomovej práce.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- natrénovať aj iné preklady (z a do češtiny).
|
||||
|
||||
18.2.2022
|
||||
|
||||
- Beží trénovanie na idoc
|
||||
|
||||
Úlohy:
|
||||
|
||||
Zmeňte štruktúru práce podľa tohoto myšienkového postupu.
|
||||
Pridajte nové časti a vyradte nerelevantné časti.
|
||||
|
||||
1. Vysvetlite čo je to neurónový strojovyý preklad.
|
||||
2. Vysvetlite, čo je to neurónová sieť.
|
||||
3. Povedze aké typy neurónových sietí sa používajú na strojový preklad.
|
||||
4. Vyberte konkrétnu neurónovú sieť (tú ktorá sa používa v OPennmt) a podrobne opíšte ako funguje.
|
||||
5. Predstavte Open NMT.
|
||||
6. Povedzte o dátach ktoré ste použili (dorobiť).
|
||||
7. Vysvetlite, ako ste pripravili experimenty, ako ste ich spustili a aké výlsekdy ste dosiahli (dorobiť).
|
||||
8. Sumarizujte experimenty a určite miesto na zlepšenie (dorobiť).
|
||||
|
||||
27.1.2022
|
||||
|
||||
- Hotovy model na CZ-EN
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Aktualizujte trénovacie skripty na gite.
|
||||
- Rozbehajte GPU trénovnaie na idoc. Vyriešte technické problémy.
|
||||
- Natrénujte viacero modelov s viacerými nastaveniami a výsledkyž dajte do tabuľky. Ku každému modelu si poznačte výsledné BLEU. Výsledky skontrolujte aj osobne.
|
||||
- Pokračujte na texte práce. Odstrániť nezmyselné časti. Pri ďalšom stretnutí prezentujte stav textovej časti.
|
||||
|
||||
|
||||
17.12.2021
|
||||
|
||||
- Vylepšený draft práce.
|
||||
- Nové vyhodnotenie a výsledky modelu.
|
||||
- Trénovanie na česko-anglickom korpuse.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- natrénujte na tomto EN-SK korpuse: https://lindat.mff.cuni.cz/repository/xmlui/handle/11858/00-097C-0000-0006-AAE0-A
|
||||
- Pokračujte v otvorených úlohách z minulého stretnutia.
|
||||
- Výsledky experiemntov zhrňte do tabuľky. Poznačte architektúru neurónovej siete, parametre trénovania.
|
||||
- Skúste rozbehať trénovanie na GPU.
|
||||
|
||||
1. Vytvorte nové conda prostredie. Spustite:
|
||||
|
||||
conda install pytorch=1.8.1cudatoolkit=10.1 -c pytorch
|
||||
|
||||
2. Nainštalujte OpenNMT.
|
||||
|
||||
|
||||
26.11.2021
|
||||
|
||||
Natrénovaný prvý model OpenNMT na korpuse europarlament.
|
||||
Výslekdy vyzerajú OK, ale sú chaotické. Pravdepodobne bolo trénovanie prerušené predčasne. Zatiaľ nefunguje trénovanie na GPU.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v trénovaní Europarl. Modelu, skúste vylepšiť výsledky.
|
||||
- Trénovanie robte opakovateľným spôsobom - dajte na git nastavenia a trénovacie skripty, ale nie textové dáta. Len poznačte odkiaľ ste ich stiahli.
|
||||
- Pokračujte v práci na texte - myšlienky by mali logicky nasledovať za sebou.
|
||||
|
||||
|
||||
12.11.2021
|
||||
|
||||
Práca na texte
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zlepšiť štruktúru práce
|
||||
- Dotrénovať a vyhodnotiť model slovenčina-angličtina.
|
||||
|
||||
28.10.
|
||||
|
||||
Stav:
|
||||
|
||||
- Vypracovaný draft článoku o transformeroch, treba vylepšiť. Článok je na ZP Wiki
|
||||
- Problém pri príprave trénovacích dát.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Naučte sa pripravovať textové dáta. Prejdite si knihu https://diveintopython3.net aspoň do 4 kapitoly. Vypracujte všetky príklady z nej.
|
||||
- Pokračujte v práci na článku. Treba doplniť odkazy do textu. Treba zlepšiť štruktúru a logickú náväznosť viet. Vysvetlite neznáme pojmy.
|
||||
- Zmente článok na draft diplomovej práce. Vypracujte osnovu diplomovej práce - napíšte názvy kapitol a ich obsah. Zaraďte tam text o transformeroch ktorý ste vypracovali.
|
||||
- Pripravte textové dáta do vhodnej podoby a spustite trénovanie.
|
||||
|
||||
|
||||
Stretnutie 30.9.
|
||||
|
||||
Stav:
|
||||
|
||||
- Len začaté štúdium článkov, ostatné úlohy zostávajú otvorené.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračovať v úlohách zo 17.6.
|
||||
- Na trénovanie použite OpenNMT.
|
||||
- Vytvorte si repozitár dp2022 a do neho dajte skripty na natrénovanie modelov. Nedávajte tam veľké dáta, ale dajte tam skript na ich stiahnutie, napr. pomocou wget.
|
||||
- prepare-env.sh : ako ste vyttvorili Vaše prostredie - nainštalovali programy.
|
||||
- download-data.sh: ako ste získali dáta
|
||||
- prepare-data.sh: ako ste pripravili dáta
|
||||
- train1.sh: ako ste natrénovali model
|
||||
- evaluate1.sh: ako ste vyhodnotili model.
|
||||
|
||||
## Diplomový projekt 1
|
||||
|
||||
Stretnutie 17.6.
|
||||
|
||||
- Splnené podmienky na zápočet.
|
||||
- Napísaný tutoriál a úvod do NMT
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Skúste zlepšiť presnosť strojového prekladu. Modifikujte setup tak, aby sa výsledky zlepšili.
|
||||
- Preštudujte si architektúru neurónovej siete typu Transformer. Prečítajte si blogy a urobte poznámky,
|
||||
Prečítajte si článok s názvom "Attention is all you need.". Urobte si poznámky čo ste sa dozvedeli.
|
||||
- Preštudujte si architektúru typu enkóder-dekóder. Urobte si poznámky čo ste sa dozvedeli a z akých zdrojov.
|
||||
Využívajte vyhľadávač Scholar.
|
||||
|
||||
Stretnutie 9.4.
|
||||
|
||||
Stav:
|
||||
|
||||
- Problém pri OpenNMT-py Quickstart - Nvidia driver nefunguje v prostredí WSL1. riešenie - vypnúť GPU training alebo trénovať na IDOC.
|
||||
- Napísané poznámky o NMT na cca 3 strany, na zpwiki
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vysvetlite vlastnými slovami čo to je neurónová sieť. Ak sa niečo dozviete z článku, povedzte vlastnými slovami čo ste sa dozvedeli a z akého článku ste sa to dozvedeli.
|
||||
- Vysvetlite vlastnými slovami ako prebieha neurónový preklad. Vysvetlite, ako sa text premení do formy ktorá je zrozumiteľná pre neurónovú sieť. Vysvetlite čo je výstupom neurónovej siete a ako sa ten výstup premení na text.
|
||||
- Napíšte to do markdown súboru na zpwiki.
|
||||
- Dokončite tutoriál OpenNMT-py.
|
||||
|
||||
|
||||
Stretnutie 12.3.
|
||||
|
||||
Stav:
|
||||
|
||||
- poznámky k článku "Google’s neural machine translation system .
|
||||
- Śtúdium ostatných článkov pokračuje.
|
||||
- Problém - aktuálna verzia OpenNMT-py nefunguje s pythonom 3.5. Je potrebné využit Anacondu.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Vypracujte poznámky k článkom
|
||||
- Pokračujte v tutoriáli OpenNMT-py cez prostredie Anaconda.
|
||||
- Poznámky pridajte na zpWiki vo formáte Markdown
|
||||
|
||||
|
||||
|
||||
Stretnutie 18.2.
|
||||
|
||||
Stav:
|
||||
- Vypracovaný článok z minulého semestra
|
||||
|
||||
Úlohy:
|
||||
|
||||
- V linuxovom prostredí (napr. idoc) si vytvorte python virtuálne prostredie:
|
||||
- vytvorte si adresár s projektom
|
||||
- mkdir ./venv
|
||||
- python3 -m virtualenv ./venv
|
||||
- source ./venv/bin/activate
|
||||
- Keď skončíte: deactivate
|
||||
- Prejdite si tutoriál https://github.com/OpenNMT/OpenNMT-py
|
||||
- Prečítjte si články z https://opennmt.net/OpenNMT-py/ref.html
|
||||
- Vypracujte poznámky k článku "Google’s neural machine translation system: bridging the gap between human and machine translation. arXiv preprint arXiv:1609.08144, 2016". Čo ste sa z čánku dozvedeli?
|
||||
|
||||
|
||||
## Tímový projekt 2021
|
||||
|
||||
Ciel:
|
||||
- vytvoriť článok s témou "Štatistický preklad".
|
||||
- vytvoriť článok, publikovateľný na konferencii
|
||||
|
||||
Virtuálne stretnutie 4.12.2020
|
||||
|
||||
Stav:
|
||||
|
||||
- Vypracovaný prehľad na tri strany, prečítané 3 články.
|
||||
- Prístup treba zlepšiť.
|
||||
|
||||
Úlohy na ďalšie stretnutie:
|
||||
|
||||
- Pokračujte v písaní. Prečítajte si min. 10 článok na tému strojový preklad a ku každému napíšte čo ste sa dozvedeli.
|
||||
- Zamerajte sa na články o neurónovom strojovom preklade. Zistite a napíšte čo je to archtektúra encoder-decoder. Napíšte aké neurónové siete sa najviac používajú.
|
||||
- Pozrite [Ondrej Megela](/students/2018/ondrej_megela), [Martin Jancura](/students/2017/martin_jancura), [Dominik Nagy](/students/2016/dominik_nagy)
|
||||
- Navrhnite zadanie diplomovej práce.
|
||||
|
||||
|
||||
Virtuálne stretnutie 2.10.2020
|
||||
|
||||
Prečítajte si a vypracujte poznámky:
|
||||
|
||||
- https://apps.dtic.mil/sti/pdfs/ADA466330.pdf
|
||||
- https://arxiv.org/abs/1409.1259
|
||||
|
||||
Pozrite si aj niektoré články ktoré sú v bibliografii.
|
||||
|
||||
Zistitie, aké najnovšie voľne šíriteľné systémy na strojový preklad sú dostupné a napíšte ku nim krátku charakteristiku. Na akej metóde sú založené? V ktorom článku je táto metóda opísaná? Používajte scopus alebo scholar.
|
||||
Zapíšte si zaujímavé bibliografické odkazy a poznačte si, čo zaujímavé sa v nich nachádza.
|
||||
|
||||
|
||||
## Bakalárska práca 2020
|
||||
|
||||
https://opac.crzp.sk/?fn=detailBiblioForm&sid=AFB64E0160B4F4E92146D39F9648
|
||||
|
||||
Názov bakalárskej práce: Metódy automatického prekladu
|
||||
|
||||
|
||||
@ -0,0 +1 @@
|
||||
data downloaded from " https://lindat.mff.cuni.cz/repository/xmlui/discover "
|
||||
1
pages/students/2016/patrik_pavlisin/dp2022/evaluate1.sh
Normal file
@ -0,0 +1 @@
|
||||
nohup perl tools/multi-bleu.perl dp2022/sk-en/europarl-v7.clean.sk-en.sk < dp2022/sk-en/pred_10000.txt2 > prekladsk&
|
||||
11
pages/students/2016/patrik_pavlisin/dp2022/prepare-data.sh
Normal file
@ -0,0 +1,11 @@
|
||||
import sys
|
||||
|
||||
for l in sys.stdin:
|
||||
line = l.rstrip()
|
||||
tokens = line.split()
|
||||
result = []
|
||||
for token in tokens:
|
||||
items = token.split("|")
|
||||
print(items)
|
||||
result.append(items[0])
|
||||
print(" ".join(result))
|
||||
@ -0,0 +1,6 @@
|
||||
onmt_build_vocab -config dp2022/sk-en/trainsk.yaml -n_sample 10000
|
||||
|
||||
onmt_train -config dp2022/sk-en/trainsk.yaml
|
||||
|
||||
onmt_translate -model dp2022/sk-en/run/model_step_1000.pt -src dp2022/sk-en/src-test.txt -output dp2022/sk-en/pred_1000.txt -verbose
|
||||
|
||||
33
pages/students/2016/patrik_pavlisin/dp2022/train1.yaml
Normal file
@ -0,0 +1,33 @@
|
||||
# train.yaml
|
||||
|
||||
## Where the samples will be written
|
||||
save_data: dp2022/run2/example
|
||||
## Where the vocab(s) will be written
|
||||
src_vocab: dp2022/run2/example.vocab.src
|
||||
tgt_vocab: dp2022/run2/example.vocab.tgt
|
||||
# Prevent overwriting existing files in the folder
|
||||
overwrite: False
|
||||
|
||||
|
||||
# Corpus opts
|
||||
data:
|
||||
corpus_1:
|
||||
path_src: dp2022/europarl-v7.sk-en.en
|
||||
path_tgt: dp2022/europarl-v7.sk-en.sk
|
||||
valid:
|
||||
path_src: dp2022/europarl-v7.clean.sk-en.en
|
||||
path_tgt: dp2022/europarl-v7.clean.sk-en.sk
|
||||
|
||||
# Vocabulary files that were just created
|
||||
src_vocab: dp2022/run2/example.vocab.src
|
||||
tgt_vocab: dp2022/run2/example.vocab.tgt
|
||||
|
||||
# Train on a single GPU
|
||||
world_size: 1
|
||||
gpu_ranks: [0]
|
||||
|
||||
# Where to save the checkpoints
|
||||
save_model: dp2022/run2/model
|
||||
save_checkpoint_steps: 1000
|
||||
train_steps: 20000
|
||||
valid_steps: 10000
|
||||
BIN
pages/students/2016/patrik_pavlisin/dp21/.README.md.swp
Normal file
173
pages/students/2016/patrik_pavlisin/dp21/README.md
Normal file
@ -0,0 +1,173 @@
|
||||
## Úvod
|
||||
|
||||
Neurónový strojový preklad (NMT) je prístup k strojovému prekladu, ktorý využíva umelú neurónovú sieť na predpovedanie pravdepodobnosti postupnosti slov, typicky modelovaním celých viet v jednom integrovanom modeli. NMT nie je drastickým krokom nad rámec toho, čo sa tradične robí v štatistickom strojovom preklade (SMT). Štruktúra modelov je jednoduchšia ako frázové modely. Neexistuje žiadny samostatný jazykový model, prekladový model a model zmeny poradia, ale iba jeden sekvenčný model, ktorý predpovedá jedno slovo po druhom. Táto predikcia postupnosti je však podmienená celou zdrojovou vetou a celou už vyprodukovanou cieľovou sekvenciou.
|
||||
|
||||
## Neurónová sieť
|
||||
|
||||
Neurónovú sieť tvoria neuróny, ktoré sú medzi sebou poprepájané. Všeobecne môžeme poprepájať ľubovoľný počet neurónov, pričom okrem pôvodných vstupov môžu byť za vstupy brané aj výstupy iných neurónov. Počet neurónov a ich vzájomné poprepájanie v sieti určuje tzv. architektúru (topológiu) neurónovej siete. Neurónová sieť sa v čase vyvíja, preto je potrebné celkovú dynamiku neurónovej siete rozdeliť do troch dynamík a potom uvažovať tri režimy práce siete: organizačná (zmena topológie), aktívna (zmena stavu) a adaptívna (zmena konfigurácie). Jednotlivé dynamiky neurónovej siete sú obvykle zadané počiatočným stavom a matematickou rovnicou, resp. pravidlom, ktoré určuje vývoj príslušnej charakteristiky sieti v čase.
|
||||
|
||||
Synaptické váhy patria medzi dôležité časti Neurónovej siete. Tieto váhy ovplyvňujú celú sieť tým, že ovplyvňujú vstupy do neurónov a tým aj ich stavy. Synaptické váhy medzi neurónmi i, j označujeme wi,j. Najdôležitejším momentom pri činnosti Neurónovej siete je práve zmena váh delta wi,j. Vo všeobecnosti ich rozdeľujeme na kladné (excitačné) a záporné (inhibičné).
|
||||
|
||||
Neurón je základným prvkom Neurónovej siete. Rozdiel medzi umelým a ľudským je v tom, že v súčasnosti je možné vytvoriť oveľa rýchlejší neurón, ako ľudský. Avšak čo sa týka počtu neurónov, ľudský mozog sa skladá z 10 na 11 až 10 na 14 neurónov a každý neurón má 10 na 3 až 10 na 4 neurónových spojení. V súčasnej dobe nie je možné nasimulovať v rámci jednej Neurónovej siete také množstvo neurónov. V tomto ohľade je ľudský mozog podstatne silnejší oproti nasimulovanej Neurónovej siete. [3]
|
||||
|
||||
|
||||
|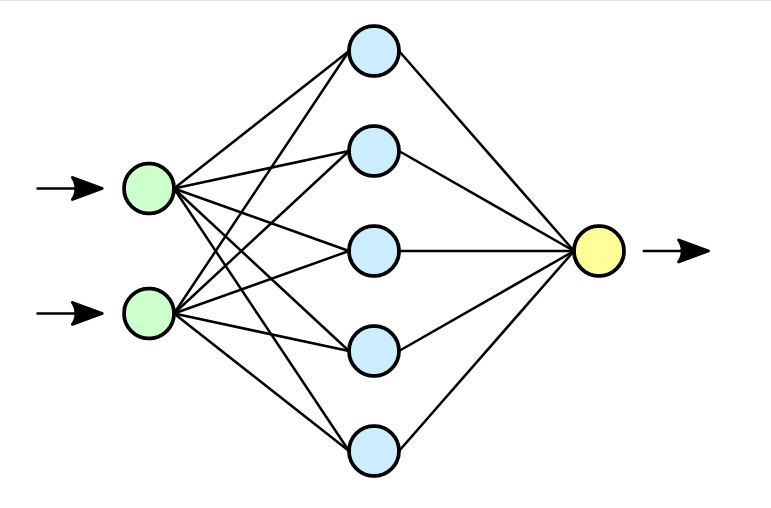|
|
||||
|:--:|
|
||||
|Obr 1. základné zobrazenie Neurónovej siete|
|
||||
|
||||
Činnosť Neurónových sieti rozdeľujeme na :
|
||||
|
||||
- Fáza učenia – v tejto fáze sa znalosti ukladajú do synaptických váh neurónovej siete, ktoré sa menia podľa stanovených pravidiel počas procesu učenia. V prípade neurónových sieti môžeme pojem učenie chápať ako adaptáciu neurónových sieti, teda zbieranie a uchovávanie poznatkov.
|
||||
|
||||
- Fáza života – dochádza ku kontrole a využitiu nadobudnutých poznatkov na riešenie určitého problému (napr. transformáciu signálov, problémy riadenia procesov, aproximáciu funkcií, klasifikácia do tried a podobne). V tejto fáze sa už nemenia synaptické váhy.
|
||||
|
||||
Neurónová sieť by vo všeobecnosti mala mať pravidelnú štruktúru pre ľahší popis a analýzu. Viacvrstvová štruktúra patrí k pomerne dobre preskúmaným štruktúram Neurónovej siete a skladá sa z :
|
||||
|
||||
- Vstupná vrstva (angl. Input layer) – na vstup prichádzajú len vzorky z vonkajšieho sveta a výstupy posiela k ďalším neurónom
|
||||
|
||||
- Skrytá vrstva (angl. Hidden layer) – vstupom sú neuróny z ostatných neurónov z vonkajšieho sveta (pomocou prahového prepojenia) a výstupy posiela opäť ďalším neurónom
|
||||
|
||||
- Výstupná vrstva (angl. Output layer) – prijíma vstupy z iných neurónov a výstupy posiela do vonkajšieho prostredia
|
||||
|
||||
Reprezentatívna vzorka je jedným zo základných pojmov Neurónových sieti. Jedná sa o usporiadanú množinu usporiadaných dvojíc, pričom ku každému vstupu je priradený vyhovujúci výstup. Poznáme dva typy reprezentatívnych vzoriek :
|
||||
|
||||
- Trénovaciu vzorku – využíva sa pri fáze učenia (pri tejto vzorke je dôležité vybrať tú najvhodnejšiu a najkvalitnejšiu, pretože získané poznatky sa ukladajú učením do synaptických váh neurónovej siete)
|
||||
|
||||
- Testovacia vzorka – používa sa vo fáze života
|
||||
|
||||
|
||||
Topológiu Neurónových sieti rozdeľujeme na :
|
||||
|
||||
- Dopredné Neurónové siete (angl. feed-forward neural network), ktoré sa ďalej delia na kontrolované a nekontrolované učenie, v tejto topológií je signál šírený iba jedným smerom. U dopredných sietí neexistujú spojenia medzi neurónmi tej istej vrstvy, ani medzi neurónmi vzdialených vrstiev.
|
||||
|
||||
|
||||
|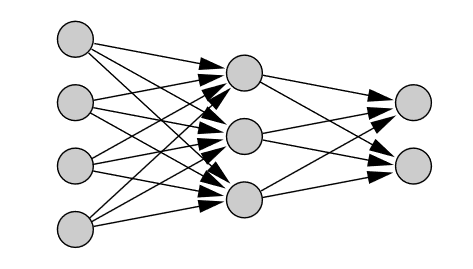|
|
||||
|:--:|
|
||||
|Obr 2. Dopredná Neurónová sieť|
|
||||
|
||||
- Rekurentné Neurónové siete (angl. recurrent neural network), ktoré sa ďalej delia na kontrolované a nekontrolované učenie, signál sa šíry obojsmerne (neuróny sa môžu správať ako vstupné aj výstupné). [3]
|
||||
|
||||
|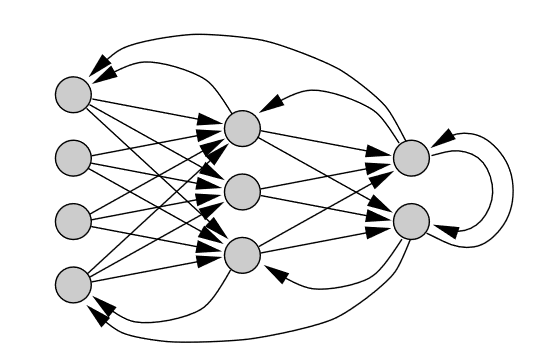|
|
||||
|:--:|
|
||||
|Obr 3. Rekurentná Neurónová sieť|
|
||||
|
||||
**Exploding and vanishing gradient problems**
|
||||
|
||||
V strojovom učení sa s problémom miznúceho gradientu stretávame pri trénovaní umelých neurónových sietí metódami učenia založenými na gradiente a spätnou propagáciou. V takýchto metódach dostáva každá z váh neurónovej siete aktualizáciu úmernú čiastočnej derivácii chybovej funkcie vzhľadom na aktuálnu váhu v každej iterácii trénovania. Problém je v tom, že v niektorých prípadoch bude gradient zbytočne malý, čo účinne zabráni tomu, aby váha zmenila svoju hodnotu. V najhoršom prípade to môže úplne zabrániť neurónovej sieti v ďalšom trénovaní. Ako jeden príklad príčiny problému majú tradičné aktivačné funkcie, ako je hyperbolická tangenciálna funkcia, gradienty v rozsahu (0, 1) a spätné šírenie počíta gradienty podľa pravidla reťazca. To má za následok znásobenie n týchto malých čísel na výpočet gradientov prvých vrstiev v sieti n-vrstiev, čo znamená, že gradient (chybový signál) exponenciálne klesá s n, zatiaľ čo prvé vrstvy trénujú veľmi pomaly.
|
||||
Ak sa použijú aktivačné funkcie, ktorých deriváty môžu nadobúdať väčšie hodnoty, riskujeme, že narazíme na súvisiaci problém s explodujúcim gradientom. Problém s explodujúcim gradientom je problém, ktorý sa môže vyskytnúť pri trénovaní umelých neurónových sietí pomocou gradientného klesania spätným šírením. Problém s explodujúcim gradientom je možné vyriešiť prepracovaním sieťového modelu, použitím usmernenej lineárnej aktivácie, využitím sietí s LSTM, orezaním gradientu a regularizáciou váh. Ďalším riešením problému s explodujúcim gradientom je zabrániť tomu, aby sa gradienty zmenili na 0, a to pomocou procesu známeho ako orezávanie gradientov, ktorý kladie na každý gradient vopred definovanú hranicu. Orezávanie prechodov zaisťuje, že prechody budú smerovať rovnakým smerom, ale s kratšími dĺžkami. [2]
|
||||
|
||||
**Neurónový preklad**
|
||||
|
||||
Neurónový strojový preklad vo všeobecnosti zahŕňa všetky typy strojového prekladu, kde sa na predpovedanie postupnosti čísel používa umelá neurónová sieť. V prípade prekladu je každé slovo vo vstupnej vete zakódované na číslo, ktoré neurónová sieť prepošle do výslednej postupnosti čísel predstavujúcich preloženú cieľovú vetu. Prekladový model následne funguje prostredníctvom zložitého matematického vzorca (reprezentovaného ako neurónová sieť). Tento vzorec prijíma reťazec čísel ako vstupy a výstupy výsledného reťazca čísel. Parametre tejto neurónovej siete sú vytvárané a vylepšované trénovaním siete s miliónmi vetných párov. Každý takýto pár viet tak mierne upravuje a vylepšuje neurónovú sieť, keď prechádza každým vetným párom pomocou algoritmu nazývaným spätné šírenie. [3]
|
||||
|
||||
**Systém neurónového strojového prekladu spoločnosti Google**
|
||||
|
||||
Neurónový strojový preklad (angl. NMT - neural machine translation) používa end-to-end učenie pre strojový preklad, ktorého cieľom je prekonať slabé stránky konvenčných frázových systémov. End-to-end učenie je typ Deep Learningu, v ktorom sú všetky parametre trénované spoločne, a nie krok za krokom. Bohužiaľ systémy NMT výpočtovo náročné počas trénovania ako aj pri samotnom preklade (je to kvôli ochrane napr. pri vysokom množstve veľkých súborov a veľkých modelov). Niekoľko autorov tiež uviedlo (odkaz na [1]), že systémom NMT chýba robustnosť, najmä keď vstupné vety obsahujú zriedkavé, alebo zastaralé slová. Tieto problémy bránili používaniu NMT v praktických nasadeniach a službách, kde je nevyhnutná presnosť aj rýchlosť.
|
||||
|
||||
Spoločnosť Google preto predstavila GNMT (google´s neural machine translation) systém , ktorý sa pokúša vyriešiť mnohé z týchto problémov. Tento model sa skladá z hlbokej siete Long Short-Term Memory (LSTM) s 8 kódovacími a 8 dekódovacími vrstvami, ktoré využívajú zvyškové spojenia, ako aj pozorovacie spojenia zo siete dekodéra ku kódovaciemu zariadeniu. Aby sa zlepšila paralelnosť a tým pádom skrátil čas potrebný na trénovanie, tento mechanizmus pozornosti spája spodnú vrstvu dekodéra s hornou vrstvou kódovacieho zariadenia. Na urýchlenie konečnej rýchlosti prekladu používame pri odvodzovacích výpočtoch aritmetiku s nízkou presnosťou. Aby sa vylepšila práca so zriedkavými slovami, slová sa delia na vstup aj výstup na obmedzenú množinu bežných podslovných jednotiek („wordpieces“). Táto metóda poskytuje dobrú rovnováhu medzi flexibilitou modelov oddelených znakom a účinnosťou modelov oddelených slovom, prirodzene zvláda preklady zriedkavých slov a v konečnom dôsledku zvyšuje celkovú presnosť systému.
|
||||
|
||||
Štatistický strojový preklad (SMT - statistical machine translation) je po celé desaťročia dominantnou paradigmou strojového prekladu. Implementáciami SMT sú vo všeobecnosti systémy založené na frázach (PBMT - phrase-based machine translation), ktoré prekladajú postupnosti slov alebo frázy, kde sa môžu dĺžky líšiť. Ešte pred príchodom priameho neurónového strojového prekladu sa neurónové siete s určitým úspechom používali ako súčasť systémov SMT. Možno jeden z najpozoruhodnejších pokusov spočíval v použití spoločného jazykového modelu na osvojenie frázových reprezentácií, čo prinieslo pozoruhodné zlepšenie v kombinácii s prekladom založeným na frázach. Tento prístup však vo svojej podstate stále využíva frázové prekladové systémy, a preto dedí ich nedostatky.
|
||||
|
||||
O koncepciu end-to-end učenia pre strojový preklad sa v minulosti pokúšali s obmedzeným úspechom. Po mnohých seminárnych prácach v tejto oblasti sa kvalita prekladu NMT priblížila k úrovni frázových prekladových systémov pre bežné výskumné kritériá. V anglickom a francúzskom jazyku WMT’14 dosiahol tento systém zlepšenie o 0,5 BLEU (je algoritmus na hodnotenie kvality textu) v porovnaní s najmodernejším frázovým systémom. Odvtedy bolo navrhnutých veľa nových techník na ďalšie vylepšenie NMT ako napríklad použitie mechanizmu pozornosti na riešenie zriedkavých slov, mechanizmu na modelovanie pokrytia prekladu, rôznymi druhmi mechanizmov pozornosti, minimalizáciou strát na úrovni vety.
|
||||
|
||||
LSTM sú špeciálny typ Rekurentných neurónových sietí (RNN), ktorý slúži na dosiahnutie dlhodobého kontextu (napr. Pri doplnení chýbajúcej interpunkcie alebo veľkých písmen). Najväčšie využitie LSTM je v oblasti strojového učenia a hlbokého učenia.
|
||||
Vlastnosti LSTM:
|
||||
- pripravený spracovať nielen jednoduché dáta, ale aj celé sekvenčné dáta (napr. reč alebo video),
|
||||
- sú vhodné na klasifikáciu, spracovanie a vytváranie predikcií na základe časových údajov
|
||||
- LSTM boli definované tak, aby si na rozdiel od RNN vedeli pomôcť s problémom, ktorý sa nazýva „Exploding and vanishing gradient problems“. [1]
|
||||
|
||||
|
||||
**Wordpiece Model**
|
||||
|
||||
Tento prístup je založený výlučne na dátach a je zaručené, že pre každú možnú postupnosť znakov vygeneruje deterministickú segmentáciu (segmenty používateľov založené na nejakej hypotéze následne sa dáta analyzujú, aby sa zistilo, či sú segmenty zaujímavé a užitočné). Je to podobné ako metóda použitá pri riešení zriedkavých slov v strojovom preklade neurónov. Na spracovanie ľubovoľných slov najskôr rozdelíme slová na slovné druhy, ktoré sú dané trénovaným modelom slovných spojení. Pred cvičením modelu sú pridané špeciálne symboly hraníc slov, aby bolo možné pôvodnú sekvenciu slov získať z postupnosti slovných spojení bez nejasností. V čase dekódovania model najskôr vytvorí sekvenciu slovných spojení, ktorá sa potom prevedie na zodpovedajúcu sekvenciu slov.
|
||||
|
||||
|
||||
|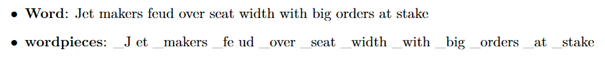|
|
||||
|:--:|
|
||||
|Obr 4. Príklad postupnosti slov a príslušná postupnosť slovných spojení|
|
||||
|
||||
|
||||
Vo vyššie uvedenom príklade je slovo „Jet“ rozdelené na dve slovné spojenia „_J“ a „et“ a slovo „feud“ je rozdelené na dve slovné spojenia „_fe“ a „ud“. Ostatné slová zostávajú ako jednotlivé slová. „_“ Je špeciálny znak pridaný na označenie začiatku slova.
|
||||
Wordpiece model sa generuje pomocou prístupu založeného na údajoch, aby sa maximalizovala pravdepodobnosť jazykových modelov cvičných údajov, vzhľadom na vyvíjajúcu sa definíciu slova. Vzhľadom na cvičný korpus a množstvo požadovaných tokenov D je problémom optimalizácie výber wordpieces D tak, aby výsledný korpus bol minimálny v počte wordpieces, ak sú segmentované podľa zvoleného wordpiece modelu. V tejto implementácii používame špeciálny symbol iba na začiatku slov, a nie na oboch koncoch. Počet základných znakov tiež znížime na zvládnuteľný počet v závislosti na údajoch (zhruba 500 pre západné jazyky, viac pre ázijské jazyky). Zistili sme, že použitím celkovej slovnej zásoby medzi 8 000 a 32 000 slovnými jednotkami sa dosahuje dobrá presnosť (BLEU skóre) aj rýchlosť dekódovania pre dané jazykové páry.
|
||||
|
||||
V preklade má často zmysel kopírovať zriedkavé názvy entít alebo čísla priamo zo zdroja do cieľa. Na uľahčenie tohto typu priameho kopírovania vždy používame wordpiece model pre zdrojový aj cieľový jazyk. Použitím tohto prístupu je zaručené, že rovnaký reťazec vo zdrojovej a cieľovej vete bude segmentovaný presne rovnakým spôsobom, čo uľahčí systému naučiť sa kopírovať tieto tokeny. Wordpieces dosahujú rovnováhu medzi flexibilitou znakov a efektívnosťou slov. Zistili sme tiež, že naše modely dosahujú lepšie celkové skóre BLEU pri používaní wordpieces - pravdepodobne kvôli tomu, že naše modely teraz efektívne pracujú v podstate s nekonečnou slovnou zásobou bez toho, aby sa uchýlili iba k znakom. [1]
|
||||
|
||||
## OpenNMT-py tutoriál
|
||||
|
||||
Pri práci na tomto tutoriáli som použil školský server idoc, rovnako ako aj voľne dostupné linuxové prostredie Ubuntu.
|
||||
Predtým než začneme so samotným tutoriálom je nutné si nainštalovať PyTorch (rámec pre preklad neurónových strojov s otvoreným zdrojom) verziu projektu OpenNMT rovnako ako inštaláciu najnovšej dostupnej verzie knižnice pip. To vykonáme zadaním nasledujúcich príkazov:
|
||||
|
||||
- pip install --upgrade pip
|
||||
- pip install OpenNMT-py
|
||||
|
||||
Prvým krokom v tutoriáli je príprava dát, na to nám poslúži predpripravená vzorka dát v anglicko-nemeckom jazyku voľne dostupná na internete obsahujúca 10 000 tokenizovaných viet (tokenizovanie je rozdelenie frázy, vety, odseku alebo celého textu na menšie jednotky teda tokeny,). Údaje pozostávajú z paralelných zdrojových (src) a cieľových (tgt) údajov obsahujúcich jednu vetu na riadok s tokenmi oddelenými medzerou.
|
||||
|
||||
- wget https://s3.amazonaws.com/opennmt-trainingdata/toy-ende.tar.gz
|
||||
- tar xf toy-ende.tar.gz
|
||||
- cd toy-ende
|
||||
|
||||
Pre pokračovanie si musíme pripraviť konfiguračný súbor YAML, aby sme určili údaje, ktoré sa použijú:
|
||||
|
||||
- -# toy_en_de.yaml
|
||||
- -## Where the samples will be written
|
||||
- save_data: toy-ende/run/example
|
||||
- -## Where the vocab(s) will be written
|
||||
- src_vocab: toy-ende/run/example.vocab.src
|
||||
- tgt_vocab: toy-ende/run/example.vocab.tgt
|
||||
- -# Prevent overwriting existing files in the folder
|
||||
- overwrite: False
|
||||
|
||||
- -# Corpus opts:
|
||||
- data:
|
||||
- corpus_1:
|
||||
- path_src: toy-ende/src-train.txt
|
||||
- path_tgt: toy-ende/tgt-train.txt
|
||||
- valid:
|
||||
- path_src: toy-ende/src-val.txt
|
||||
- path_tgt: toy-ende/tgt-val.txt
|
||||
|
||||
...
|
||||
|
||||
Z tejto konfigurácie môžeme zostaviť slovnú zásobu, ktorá bude potrebná na trénovanie modelu:
|
||||
|
||||
- onmt_build_vocab -config toy-ende/toy_en_de.yaml -n_sample 10000
|
||||
|
||||
|
||||
Aby sme mohli model trénovať, musíme do konfiguračného súboru YAML pridať:
|
||||
|
||||
-- cesty slovnej zásoby, ktoré sa budú používať (v tomto prípade cesty vygenerované programom onmt_build_vocab)
|
||||
|
||||
-- tréning špecifických parametrov.
|
||||
|
||||
Pridáme do YAML konfiguračného súboru nasledujúce riadky:
|
||||
|
||||
- -# Vocabulary files that were just created
|
||||
- src_vocab: toy-ende/run/example.vocab.src
|
||||
- tgt_vocab: toy-ende/run/example.vocab.tgt
|
||||
- -# Where to save the checkpoints
|
||||
- save_model: toy-ende/run/model
|
||||
- save_checkpoint_steps: 500
|
||||
- train_steps: 1000
|
||||
- valid_steps: 500
|
||||
|
||||
Potom už len stačí spustiť proces trénovania:
|
||||
|
||||
- onmt_train -config toy-ende/toy_en_de.yaml
|
||||
|
||||
V tejto konfigurácii bude bežať predvolený model, ktorý sa skladá z dvojvrstvového modulu LSTM s 500 skrytými jednotkami v kodéri aj v dekodéri.
|
||||
|
||||
Posledným krokom je samotný preklad, ktorý vykonáme zadaním nasledujúceho príkazu:
|
||||
|
||||
- onmt_translate -model toy-ende/run/model_step_1000.pt -src toy-ende/src-test.txt -output toy-ende/pred_1000.txt -verbose
|
||||
|
||||
Výsledkom je model, ktorý môžeme použiť na predpovedanie nových údajov. To prebieha spustením tzv. Beam search. Beam search sa využíva za účelom udržania ľahšieho ovládania vo veľkých systémoch s nedostatkom pamäte na uloženie celého vyhľadávacieho stromu. To vygeneruje predpovede do výstupného súboru toy-ende/pred_1000.txt . V mojom prípade proces prekladu trval na školskom serveri idoc približne 5 hodín zatiaľ čo v Linuxovom prostredí Ubuntu 1 hodinu. V obidvoch prípadoch boli výsledky podpriemerné, pretože demo súbor údajov bol dosť malý.
|
||||
|
||||
|
||||
## Zoznam použitej literatúry
|
||||
|
||||
[1]. WU Y., SCHUSTER M., CHEN Z., LE V. Q., NOROUZI M.: _Google’s Neural Machine Translation System: Bridging the Gapbetween Human and Machine Translation._ [online]. [citované 08-09-2016].
|
||||
|
||||
[2]. PYKES K.: _The Vanishing/Exploding Gradient Problem in Deep Neural Networks._ [online]. [citované 17-05-2020].
|
||||
|
||||
[3]. ŠÍMA J., NERUDA R.: Teoretické otázky neurónových sítí [online]. [1996].
|
||||
|
||||
{kind=link}
|
After Width: | Height: | Size: 98 KiB |
{kind=link}
|
After Width: | Height: | Size: 32 KiB |
BIN
pages/students/2016/patrik_pavlisin/dp22/R-Transformer.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 42 KiB |
127
pages/students/2016/patrik_pavlisin/dp22/README.md
Normal file
@ -0,0 +1,127 @@
|
||||
## Attention, The Transformer
|
||||
|
||||
**Úvod**
|
||||
|
||||
Transformer je modelová architektúra, ktorá sa vyhýba opakovaniu a namiesto toho sa úplne spolieha na mechanizmus pozornosti na kreslenie globálnych závislostí medzi vstupom a výstupom. Je to prvý transdukčný model, ktorý sa spolieha úplne na vlastnú pozornosť pri výpočte reprezentácii vstupu a výstupu bez použitia RNN (Recurrent Neural Network) alebo CNN (Convolution Neural Network). Používa sa predovšetkým v oblasti NLP (Natural Language Processing) a CV (Computer Vision). Mechanizmy pozornosti sa stali súčasťou presvedčivého modelovania sekvencií a prenosových modelov v rôznych úlohách, ktoré umožňujú modelovanie závislostí bez ohľadu na ich vzdialenosť vo vstupných alebo výstupných sekvenciách. Takmer vo všetkých prípadoch sa však takéto mechanizmy pozornosti používajú v spojení s rekurentnou sieťou. Systémy počítačového videnia (CV) založené na CNN môžu tiež ťažiť z mechanizmov pozornosti. Hlavnou vlastnosťou tzv. “mechanizmus pozornosti” je že vie na základe vstupnej postupnosti v každom kroku rozhodnúť, ktoré časti postupnosti sú dôležité. Je to technika, ktorá napodobňuje kognitívnu pozornosť.
|
||||
|
||||
Najmä Multi-head attention mechanizmus v Transformeri umožňuje, aby bola každá pozícia priamo spojená s akýmikoľvek inými pozíciami v sekvencii. Informácie tak môžu prúdiť cez pozície bez akejkoľvek medzistraty. Napriek tomu existujú dva problémy, ktoré môžu poškodiť účinnosť Multi-head attention pri sekvenčnom učení. Prvý pochádza zo straty sekvenčných informácií o pozíciách, pretože s každou pozíciou zaobchádza rovnako. Na zmiernenie tohto problému Transformer zavádza vkladanie pozícií, ktorých účinky sa však ukázali ako obmedzené. [4]
|
||||
|
||||
Na vyriešenie vyššie uvedených obmedzení štandardného Transformera bol navrhnutý nový model sekvenčného učenia R-Transformer. Ide o viacvrstvovú architektúru postavenú na RNN a štandardnom Transformeri, pričom využíva výhody oboch svetov, ale zároveň sa vyhýba ich príslušným nevýhodám. Konkrétnejšie, pred výpočtom globálnych závislostí pozícii pomocou Multi-head attention najskôr spresníme znázornenie každej polohy tak, aby sa sekvenčné a lokálne informácie v jej susedstve mohli v reprezentácii skomprimovať. Aby sa to dosiahlo bola zavedená lokálna rekurentná neurónová sieť, označená ako LocalRNN, na spracovanie signálov v rámci lokálneho okna končiaceho na danej pozícii. LocalRNN navyše pracuje na miestnych oknách všetkých pozícií identicky a nezávisle a pre každú z nich vytvára skrytú reprezentáciu. Okrem toho, keďže sa lokálne okno posúva pozdĺž sekvencie jednu pozíciu za druhou, sú zahrnuté aj globálne sekvenčné informácie. Dôležité najme je, že nakoľko LocalRNN sa používa iba na lokálne okná, vyššie uvedené nevýhody RNN je možné zmierniť. [1][6]
|
||||
|
||||
Rekurentné neurónové siete, najmä long short-term pamäť (LSMT, špeciálny druh RNN, vytvorený na riešenie problémov s miznúcim gradientom) a uzavreté rekurentné neurónové siete, boli pevne zavedené ako najmodernejšie prístupy k problémom sekvenčného modelovania a prenosov, ako je jazykové modelovanie a strojový preklad. LSTM je architektúra umelej rekurentnej neurónovej siete (RNN), ktorá sa používa v oblasti deep-learning učenia. Na rozdiel od štandardných dopredných neurónových sietí (ang. Feedforward neural network) má LSTM spätnú väzbu. Dokáže spracovať nielen jednotlivé dátové body (napríklad obrázky), ale aj celé sekvencie dát (napríklad reč alebo video). Početné snahy odvtedy pokračujú v posúvaní hraníc rekurentných jazykových modelov a architektúr encoder-decoder. Sieťové pamäte typu end-to-end sú založené na RNN (Recurrent Neural Network) mechanizme namiesto opakovania zarovnaného podľa sekvencie a ukázalo sa, že fungujú dobre pri úlohách zodpovedajúcich otázky v jednoduchom jazyku a pri modelovaní jazykov. End-to-end učenie je typ Deep Learningu, v ktorom sú všetky parametre trénované spoločne, a nie krok za krokom. [7] [8]
|
||||
|
||||
RNN boli dlhodobo dominantnou voľbou pre sekvenčné modelovanie, závažne však trpia najme dvoma problémami. Po prvé, ľahko trpí problémami s miznutím a explodovaním gradientu, čo do značnej miery obmedzuje schopnosť naučiť sa veľmi dlhodobé závislosti. Po druhé, sekvenčná povaha prechodov dopredu aj dozadu veľmi sťažuje, ak nie priam znemožňuje, paralelizáciu výpočtu, čo dramaticky zvyšuje časovú zložitosť v tréningovom aj testovacom postupe. Preto mnohé nedávno vyvinuté modely sekvenčného učenia úplne vypustili rekurentnú štruktúru a spoliehajú sa iba na konvolučnú (Convolution Neural Network) alebo mechanizmus pozornosti, ktoré sa dajú ľahko paralelizovať a umožňujú tok informácií v ľubovoľnej dĺžke. Dva reprezentatívne modely, ktoré pritiahli veľkú pozornosť, sú Temporal Convolution Networks (TCN) a Transformer. V rôznych úlohách sekvenčného učenia preukázali porovnateľný alebo dokonca lepší výkon ako výkonnosť RNN. [8]
|
||||
|
||||
**Modelová architektúra**
|
||||
|
||||
Väčšina konkurenčných prenosových modelov neurónovej sekvencie má štruktúru encoder-decoder. V tomto prípade encoder mapuje vstupnú sekvenciu symbolových reprezentácií (x1, ..., xn) na sekvenciu spojitých reprezentácií z = (z1, ..., zn). Vzhľadom na z, decoder potom generuje výstupnú sekvenciu (y1, ..., ym) symbolov jeden po druhom. V každom kroku je model automaticky regresívny a pri generovaní ďalšieho spotrebuje predtým vygenerované symboly ako ďalší vstup. [1]
|
||||
|
||||
|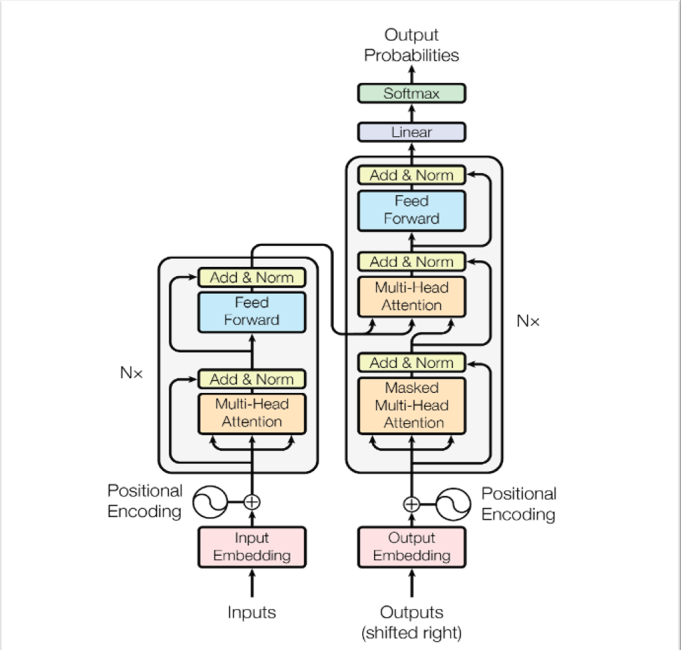|
|
||||
|:--:|
|
||||
|Obr 1. Modelová architektúra Transformer|
|
||||
|
||||
## Encoder-Decoder architektúra
|
||||
|
||||
Rovnako ako predchádzajúce modely, Transformer používa architektúru encoder-decoder. Encoder-Decoder architektúra je spôsob použitia rekurentných neurónových sietí na problémy s predikciou sekvencie k sekvencii. Pôvodne bol vyvinutý pre problémy so strojovým prekladom, aj keď sa osvedčil pri súvisiacich problémoch s predikciou sekvencie k sekvencii, ako je zhrnutie textu a zodpovedanie otázok. Skladá sa z 3 častí (encoder, intermediate vector a decoder).
|
||||
|
||||
Encoder – prijme jeden prvok vstupnej sekvencie v každom časovom kroku, spracuje ho, zhromaždí informácie o danom prvku a šíri ho ďalej.
|
||||
|
||||
Intermediate vector – konečný vnútorný stav vytvorený z časti encoder modelu. Obsahuje informácie o celej vstupnej sekvencii, ktoré pomôžu decoderu robiť presné predpovede.
|
||||
|
||||
Decoder – predpovedá výstup v každom časovom kroku.
|
||||
|
||||
Encoder pozostáva z kódovacích vrstiev, ktoré spracovávajú vstup iteračne jednu vrstvu za druhou, zatiaľ čo decoder pozostáva z dekódovacích vrstiev, ktoré robia to isté s výstupom encodera. Funkciou každej vrstvy encodera je generovať kódovanie, ktoré obsahuje informácie o tom, ktoré časti vstupov sú navzájom relevantné. Odošle svoje kódovanie do ďalšej vrstvy encodera ako vstupy. Každá decoderová vrstva robí opak, pričom použije všetky kódovania a na začlenenie výstupnej sekvencie použije svoje začlenené kontextové informácie. Aby sa to dosiahlo, každá vrstva encodera a decodera využíva mechanizmus pozornosti.
|
||||
|
||||
Pri každom vstupe pozornosť zvažuje relevanciu každého ďalšieho vstupu a čerpá z neho pri vytváraní výstupu. Každá decoderová vrstva má mechanizmus dodatočnej pozornosti, ktorý čerpá informácie z výstupov predchádzajúcich decoderov, než vrstva decodera čerpá informácie z kódovaní.
|
||||
|
||||
Obe vrstvy encodera a decodera majú feed-forward neurónovú sieť (umelá neurónová sieť, v ktorej spojenia medzi uzlami netvoria cyklus) na dodatočné spracovanie výstupov a obsahujú zvyškové spojenia a kroky na normalizácie vrstiev. [3]
|
||||
|
||||
|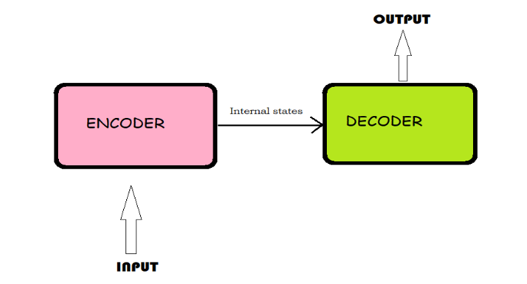|
|
||||
|:--:|
|
||||
|Obr 2. Štruktúra modelu sequence to sequence (encoder-decoder)|
|
||||
|
||||
**Transformer Encoder**
|
||||
|
||||
Encoder sa skladá zo zásobníka _N = 6_ rovnakých vrstiev. Každá vrstva má dve podvrstvy. Prvým je multi-head self-attention mechanizmus a druhým je jednoduchá polohovo plne prepojená sieť spätnej väzby. Multi-head Attention je modul pre mechanizmy pozornosti, ktorý prechádza mechanizmom pozornosti niekoľkokrát paralelne. Self-attention, tiež známy ako Intra-attention, je mechanizmus pozornosti, ktorý spája rôzne polohy jednej sekvencie s cieľom vypočítať reprezentáciu tej istej sekvencie. Okolo každej z dvoch čiastkových vrstiev sa používa zvyškové spojenie, po ktorom nasleduje normalizácia vrstvy. To znamená, že výstupom každej podvrstvy je _LayerNorm (x + Sublayer (x))_, kde _Sublayer (x)_ je funkcia implementovaná samotnou podvrstvou. Aby sa uľahčili tieto zvyškové spojenia, všetky podvrstvy v modeli, ako aj vkladacie vrstvy, produkujú výstupy dimenzie _dmodel_ = 512. [1]
|
||||
|
||||
**Transformer Decoder**
|
||||
|
||||
Decoder je tiež zložený zo zásobníka _N = 6_ rovnakých vrstiev. Okrem dvoch podvrstiev v každej vrstve encodera, decoder vkladá tretiu podvrstvu, ktorá vykonáva multi-head attention nad výstupom encoder zásobníka. Podobne ako encoder, používa zvyškové spojenia okolo každej z podvrstiev, po ktorých nasleduje normalizácia vrstvy. Toto maskovanie v kombinácii so skutočnosťou, že vloženia výstupov sú posunuté o jednu pozíciu, zaisťuje, že predpovede pre polohu _i_ môžu závisieť iba od známych výstupov v polohách menších ako _i_. [1]
|
||||
|
||||
**Scaled Dot-Product Attention**
|
||||
|
||||
Našu osobitnú pozornosť nazývame „Pozornosť zameraná na produkt“ (obrázok 2). Vstup pozostáva z dotazov a kľúčov dimenzie _dk_ a hodnôt dimenzie _dv_. Bodové produkty dotazu vypočítame všetkými klávesmi, každý vydelíme √_dk_ a použijeme funkciu _softmax_, aby sme získali váhy hodnôt.
|
||||
|
||||
|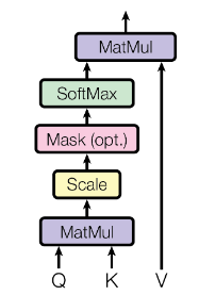|
|
||||
|:--:|
|
||||
|Obr 3. Scaled Dot-Production Attention|
|
||||
|
||||
V praxi počítame funkciu pozornosti pre množinu dotazov súčasne zabalených do matice _Q_. Kľúče a hodnoty sú tiež zabalené spolu do matíc _K_ a _V_. Maticu výstupov vypočítame ako:
|
||||
|
||||
||
|
||||
|:--:|
|
||||
|
||||
Dve najčastejšie používané funkcie pozornosti sú additive attention a dot-product attention. Dot-product attention je identická s naším algoritmom, s výnimkou faktora mierky 1/$\sqrt{dk}$. Additive attention počíta funkciu kompatibility pomocou siete spätnej väzby s jednou skrytou vrstvou. Aj keď sú tieto dva teoreticky náročné, dot-product attention je v praxi oveľa rýchlejšia a priestorovo efektívnejšia, pretože je možné ich implementovať pomocou vysoko optimalizovaného maticového multiplikačného kódu.
|
||||
|
||||
Zatiaľ čo pri malých hodnotách dk tieto dva mechanizmy fungujú podobne, additive attention prevyšuje pozornosť produktu bez toho, aby sa škálovala pri väčších hodnotách _dk_. Je pravdepodobné, že pri veľkých hodnotách _dk_ sa bodové produkty zväčšujú a tlačia funkciu _softmax_ do oblastí, kde má extrémne malé gradienty (v strojovom učení je gradient derivátom funkcie, ktorá má viac ako jednu vstupnú premennú). Aby sa tomuto efektu zabránilo, škálujeme bodové produkty o 1/$\sqrt{dk}$ [1] [4]
|
||||
|
||||
**Multi-Head Attention**
|
||||
|
||||
Namiesto toho, aby sme vykonávali funkciu jedinej pozornosti s _dmodel_-dimenzionálnymi kľúčmi, hodnotami a dotazmi, považuje sa za výhodné lineárne premietať dotazy, kľúče a hodnoty _h_-krát s rôznymi, naučenými lineárnymi projekciami do dimenzií _dk_, _dk_ a _dv_. Na každej z týchto predpokladaných verzií dotazov, kľúčov a hodnôt potom paralelne vykonávame funkciu pozornosti, čím sme získali _dv_-dimenzionálne výstupné hodnoty. Tieto sú zreťazené a znova premietnuté, výsledkom sú konečné hodnoty (obrázok 4).
|
||||
|
||||
|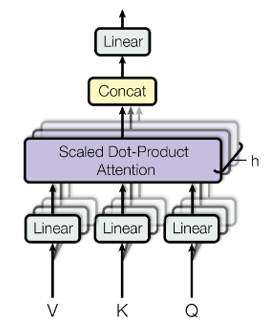|
|
||||
|:--:|
|
||||
|Obr 4. Multi-Head Attention|
|
||||
|
||||
Multi-head attention umožňuje modelu spoločne sa zaoberať informáciami z rôznych reprezentačných podpriestorov na rôznych pozíciách. Pri použití single-head attention to priemerovanie bráni.
|
||||
|
||||
|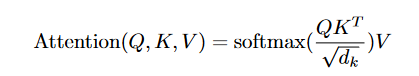|
|
||||
|:--:|
|
||||
|
||||
|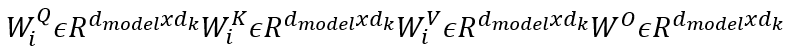|
|
||||
|:--:|
|
||||
|Obr 5. matice parametrov|
|
||||
|
||||
V tomto prípade si za _h_ dosadíme 8 paralelných vrstiev pozornosti, alebo „heads“. Pre každý z nich používame _dk_ = _dv_ = _dmodel/h_ = _64_. Vzhľadom na zmenšený rozmer každej hlavy sú celkové výpočtové náklady podobné nákladom na pozornosť single-head s plnou dimenzionalitou (koľko atribútov má množina údajov).
|
||||
|
||||
The Transformer využíva Multi-head attention tromi rôznymi spôsobmi:
|
||||
|
||||
Vo vrstvách „encoder-decoder attention“ pochádzajú dotazy z predchádzajúcej vrstvy decodera a pamäťové kľúče a hodnoty sú z výstupu encodera. To umožňuje každej pozícii v decoderi zúčastniť sa na všetkých pozíciách vo vstupnej sekvencii.
|
||||
|
||||
Encoder obsahuje vrstvy self-attention. Vo vrstve self-attention pochádzajú všetky kľúče, hodnoty a dotazy z rovnakého miesta, teda predchádzajúcej vrstvy v encoderu. Každá pozícia v encoderi sa môže venovať všetkým polohám v predchádzajúcej vrstve encodera.
|
||||
|
||||
Vrstvy self-attention v decoderi umožňujú každej pozícii v decoderi zúčastniť sa na všetkých polohách v decoderi až do danej polohy. Musí sa zabrániť toku informácii v decoderi, aby sa zachovala autoregresívna vlastnosť (model časových radov, ktorý používa pozorovania z predchádzajúcich časových krokov ako vstup do regresnej rovnice na predpovedanie hodnoty v nasledujúcom časovom kroku). To implementujeme do scaled dot-product attention pomocou maskovania (nastavením na -∞) všetkých hodnôt na vstupe softmax, ktoré zodpovedajú nezákonným spojeniam. [1] [4]
|
||||
|
||||
## R-Transformer
|
||||
|
||||
|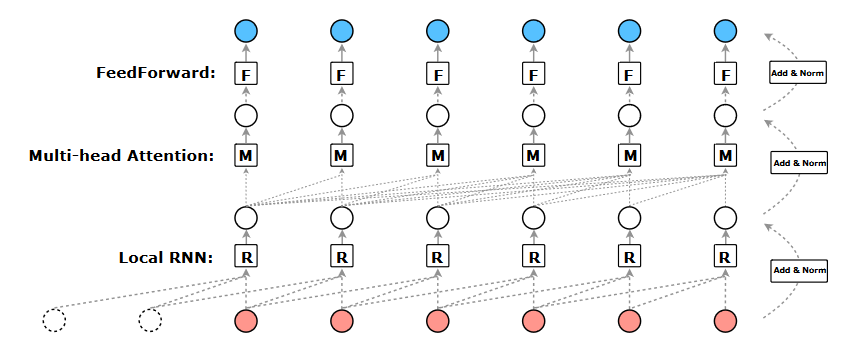|
|
||||
|:--:|
|
||||
|Obr 5. R-Transformer|
|
||||
|
||||
Navrhovaný transformátor R sa skladá zo stohu rovnakých vrstiev. Každá vrstva má 3 komponenty, ktoré sú usporiadané hierarchicky. Ako je znázornené na obrázku, nižšou úrovňou sú lokálne rekurentné neurónové siete, ktoré sú určené na modelovanie lokálnych štruktúr v sekvencii, stredná úroveň je Multi-head attention, ktorá je schopná zachytiť globálne dlhodobé závislosti a horná úroveň je position-wise feedforward sieť, ktorá vykonáva nelineárnu transformáciu prvkov. [2]
|
||||
|
||||
**Porovnanie s TCN**
|
||||
|
||||
R-Transformer je čiastočne motivovaný hierarchickou štruktúrou v TCN, v TCN je lokalita v sekvenciách zachytená konvolučnými filtrami. Sekvenčné informácie v rámci každého receptívneho poľa sú však pri konvolučných operáciách ignorované. Na rozdiel od toho, štruktúra LocalRNN v R-Transformer ju môže plne začleniť vďaka sekvenčnej povahe RNN. Pre modelovanie globálnych dlhodobých závislostí to TCN dosahuje pomocou rozšírených konvolúcií, ktoré fungujú na nenásledných pozíciách. Aj keď táto operácia vedie k väčším receptívnym poliam v nižších vrstvách, chýba značné množstvo informácií z veľkej časti pozícií v každej vrstve. [2]
|
||||
|
||||
**Porovnanie s Transformerom**
|
||||
|
||||
R-Transformer a štandardný Transformer majú podobnú kapacitu dlhodobého zapamätania vďaka Multi-head attention mechanizmu. Dve dôležité vlastnosti však odlišujú R-Transformer od štandardného Transformera. Po prvé, R-Transformer explicitne a efektívne zachytáva lokalitu v sekvenciách s novou štruktúrou LocalRNN, zatiaľ čo štandardný Transformer ju modeluje veľmi nepresne pomocou Multi-head attention, ktorá pôsobí na všetkých pozíciách. Po druhé, R-Transformer sa nespolieha na žiadne vloženie polohy ako Transformer. V skutočnosti sú výhody jednoduchého polohového zabudovania veľmi obmedzené a vyžaduje značné úsilie na navrhnutie efektívnych polohových zabudovaní, ako aj správnych spôsobov ich začlenenia. [2] [4]
|
||||
|
||||
## Zoznam použitej literatúry
|
||||
|
||||
[1]. VASWANI A., SHAZEER N., PARMAR N., USZKOREIT J., JONES L., GOMEZ N.A., KASIER L., POLUSUKHIN.I.: _Attention Is All You Need._ [online]. [citované 2017].
|
||||
|
||||
[2]. WANG Z., MA Y., LIU Z., TANG J.: _R-Transformer: Recurrent Neural Network Enhanced Transformer._ [online]. [citované 12-07-2019].
|
||||
|
||||
[3]. SRIVASTAVA S.: _Machine Translation (Encoder-Decoder Model)!._ [online]. [citované 31-10-2019].
|
||||
|
||||
[4]. ALAMMAR J.: _The Illustrated Transformer._ [online]. [citované 27-06-2018].
|
||||
|
||||
[5]. _Sequence Modeling with Neural Networks (Part 2): Attention Models_ [online]. [citované 18-04-2016].
|
||||
|
||||
[6]. GIACAGLIA G.: _How Transformers Work._ [online]. [citované 11-03-2019].
|
||||
|
||||
[7]. _Understanding LSMT Networks_ [online]. [citované 27-08-2015].
|
||||
|
||||
[8]. _6 Types of Artifical Neural Networks Currently Being Used in Machine Translation_ [online]. [citované 15-01-201].
|
||||