5.0 KiB
TECHNICKÁ UNIVERZITA V KOŠICIACH
FAKULTA ELEKTRONIKY A INFORMATIKY
Hodnotenie vyhľadávania modelu
2022 Michal Stromko
Úvod
Cieľom tejto práce je zoznámenie sa s možnosťami hodnotenia modelov. Natrénovaný model dokáže vyhodnocovať viacerými technikami s použitím rôzdnych open source riešení. Každé z riešení nám ponúkne iné výsledky. V tejto práci bližšie opíšem základné pojmy, ktoré je potrebné poznať pri hodnotení. Opíšem základné informácie o technikách hodnotenia od základných pojmov ako Vektorové vyhľadávania, DPR, Sentence Transformers, BM-25, Faiss a mnoho ďalších.
Základné znalosti
Na začiatok je potrebné povedať, že pri spracovaní prirodzeného jazyka dokážeme používať rôzne metódy prístupu hodnotenia modelu, poprípade aj vyhľadávanie v modeli. V poslených rokoch sa v praxi stretávame s vyhľadávaním na základe vypočítania vektorov. Následne na takto vypočítané vektory dokážeme pomocou kosínusovej vzdialenosti nájsť vektory, inak povedané dve čísla, ktoré sú k sebe najblyžšie. Jedno z čísel je z množiny vektorov, ktoré patria hľadanému výrazu, druhé číslo patrí slovu, alebo vete, ktorá sa nacháza v indexe.
Pre uľahčenie pochopenia tejto problematiky, postupne vysvetlím vypočítanie a následné hladanie dvoch vektorov v tomto článku. Treba však poznamenať, že každá metóda má vlastné vypočítanie vektora spolu s hľadaním podobného vektora.
Dense Passage Retriever (DPR)
DPR nazývame ako typ systému, spracovania prirodzeného jazyka (NLP). Tento systém získava relevantné časti, inak povedané pasáže z veľkého korpusu textu. V kombinácii s sémantickou analýzou a algoritmom strojového učenia, ktorý idenetifikuje najrelevantnejšie pasáže pre daný dopyt. DPR je založený na používaní správneho enkódera, ktorý mapuje text na dimenzionálne vektory skutočnej hodnoty a vytvára index M, ktorý sa používa pre vyhľadávanie. Treba však povedať, že počas behu DPR sa aplikuje aj iný enkóder EQ, ktorý mapuje vstupnú otázku na d-rozmerný vektor a následne hľadá tie vektory, ktoré sú najbližšie k vektoru otázky. Podobnosť medzi otázkou a časťou odpovede definujeme pomocou Bodového súčinu ich vektorov.
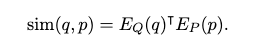
Aj keď existujú silnejšie modelové formy na meranie podobnosti medzi otázkou a pasážou, ako sú siete pozostávajúce z viacerých vrstiev krížovej pozornosti, ktorá musí byť rozložiteľná, aby sme mohli vopred vypočítať kolekcie pasáží. Väčšina rozložiteľných funkcii podobnosti používa transformácie euklidovskej vzdialenosti.
Cross Attentions (krížová pozornosť) Cross Attentions v DPR je technika, ktorá sa používa na zlepšenie presnosti procesu vyhľadávania. Funguje tak, že umožňuje modelu pracovať s viacerými pasížami naraz, čo umožňuje identifikovanie najrelevantnejších pasáží. Pre pre správne identifikovanie DPR berie do úvahy kontext každej pasáže. V prvom kroku najskôr model identifikuje kľúčové výrazy v dotaze a následne použije sémantickú analýzu na identifikáciu súvisiacich výrazov. Mechanizmus pozornisti umožňuje modelu zamerať sa na najdôležitejšie slová v každej pasáži, zatiaľ čo algoritmu strojového učenia pomáha modelu s identifikáciou.
V ďalšom kroku Cross Attentions používa systém bodovania na hodnotenie získaných pasáží. Bodovací systém berie do úvahy relevantnosť pasáží k dopytu, dĺžku pasáží a počet výskytov dopytovacích výrazov v pasážach. Posledným dôležitým atribútom, ktorý sa zisťuje je miera súvislosti nájdeného výrazu k výrazu dopytu.
Pozitívne a negatívne pasáže (Positive and Negative passages) Časté problémy, ktoré vznikajú pri vyhľadávaní sú spojené s opakujúcimi sa pozitívnymi výsledkami, zatiaľ čo negatívne výsledky sa vyberajú z veľkej množiny. Ako príklad si môžeme uviesť pasáž, ktorá súvisí s otázkou a nachádza sa v súbore QA a dá sa nájsť pomocou odpovede. Všetky ostatné pasáže aj keď nie sú explicitne špecifikované, môžu byť predvolene považované za irelevantné. Poznáme tri typy negatívnych odpovedí:
- Náhodný (Random)
- Je to akákoľvek náhodná pasáž z korpusu
- BM25
- Top pasáže vracajúce BM25, ktoré neobsahujú odpoveď, ale zodpovedajú väčšine otázkou
- Zlato (Gold)
- Pozitívne pasáže párované s ostatnými otázkami, ktoré sa objavili v trénovacom súbore
Sentence Transformers
- je Python framework
Semantic Search
Word Embedding
Semantic Search
### BM25
Faiss
### LABSE