TECHNICKÁ UNIVERZITA V KOŠICIACH
FAKULTA ELEKTRONIKY A INFORMATIKY
Hodnotenie vyhľadávania modelu
2022
Michal Stromko
# Úvod
Cieľom tejto práce je zoznámenie sa s možnosťami hodnotenia modelov. Natrénovaný model dokáže vyhodnocovať viacerými technikami s použitím rôzdnych open source riešení. Každé z riešení nám ponúkne iné výsledky. V tejto práci bližšie opíšem základné pojmy, ktoré je potrebné poznať pri hodnotení. Opíšem základné informácie o technikách hodnotenia od základných pojmov ako Vektorové vyhľadávania, DPR, Sentence Transformers, BM-25, Faiss a mnoho ďalších.
# Základné znalosti
Na začiatok je potrebné povedať, že pri spracovaní prirodzeného jazyka dokážeme používať rôzne metódy prístupu hodnotenia modelu, poprípade aj vyhľadávanie v modeli. V poslených rokoch sa v praxi stretávame s vyhľadávaním na základe vypočítania vektorov. Následne na takto vypočítané vektory dokážeme pomocou kosínusovej vzdialenosti nájsť vektory, inak povedané dve čísla, ktoré sú k sebe najblyžšie. Jedno z čísel je z množiny vektorov, ktoré patria hľadanému výrazu, druhé číslo patrí slovu, alebo vete, ktorá sa nacháza v indexe.
Vyhodnotenie vyhľadávana v modeli dôležité z hľadiska budúceho použitia modelu do produkcie. Pokiaľ sa do produkcie dostane model, ktorí bude mať nízke ohodnotenie bude sa stávať, že vyhľadávanie bude nepresné to znamená, výskedky nebudú relevantné k tomu čo sme vyhľadávali.
## Zameranie práce
V tejto práci som realizoval viaceré experimenty, v ktorých som hodnotil vyhľadávanie pomocou modelov do ktorých bol zaembedovaný text. Každý text obsahuje ďalšie atribúty ako otázky a odpovede. Otázky sa následne pošlú na vyhľadanie a čaká sa na výsledok vyhľadávania. Výsledky ktoré prídu sa následne porovnajú s očakávanými odpoveďami. Najdôležitejšie je nájsť v jednej odpovedi čo najviac správnych výsledkov. Následne je potrebné spočítať počet správnych výsledkov a použiť správne vzpočítať presnosť a návratnosť vyhľadávania. V tomto prípade presnosť a návratnosť počítame pre hodnotenie všetkých otázok. Čím sú hodnoty vyššie, tak konštatujeme že vyhľadávanie pomocou danej metódy je presné a dokážeme ho používať v produkcii.
Dôležtým atribútom s ktorým sme vykonávali testovanie bola menenie parametra **top_k**. Tento parameter znamená počet najlepších odpovedí na výstupe vyhľadávania. Čím je tento paramter väčší môžeme očakávať, že sa v ňom bude nachádzať väčšie množstvo správnych odpovedí. V konečnom dôledku to vôbec nemusí byť pravda, pretože ak máme kvalitne natrénovaný model a dobre zaembedované dokumenty dokážeme mať správne výsledky na prvých miestach, čo nám ukazuje že parameter *top_k* može mať menšiu hodnotu.
Najčastejšie je táto hodnota nastavovaná na top 10 najlepších výsledkov vyhľadávania. Pri experimentoch som túto hodnotu nastavoval na hodnoty **5, 10, 15, 20, 30**. Každá metóda ktorá bola pouťitá na vyhľadávanie dosiahla iné výsledky.
### Použité metódy vyhľadávania v experimentoch
V tejto práci som použil na vyhľadávanie 4 rôzne metódy, ktorým som postupne nastavoval parameter **top_k** od 5 až 30.
Použil som vyhľadávanie pomocou:
- Faiss
- BM25
- LaBSE
- sts-slovakbert-stst
Každá jedna metóda pracuje s úplne iným modelom. Modely LaBSE a sts-slovakbert-stst používali rovnakú knižnicu na vytvorenie vektorov aj vyhľadávanie.
Faiss používal knižnicu spacy, do ktorej parameter model_name vstupoval model ktorý bol natrénovaný pre slovenské dáta na mojej katedre. Následne dáta boli indexované pomocou knižnice faiss, ktorá má funkciu indexovania dát. Vyhľadávanie dát bolo tak isto realizované pomocou funkcie *faiss.search()* ktorej parametre sú otázka a počet očakávaných dokumentov, alebo inak povedané odpovedí.
BM25 je jeden z najstarších možností vyhľadávania v neuónových sieťach, napriek tomu je to stále stabilná a relatívne presná aj v dnešnej dobe
??? Aký model som používal???
Evaluovanie pomocou modelu LaBSE a sts-slovakbert-stst som realizoval použítím knižnice **Sentence tranformers**. Práca s touto knižnicou je veľmi jednoduchá, pretože v dokumentácii, ktorú obsahuje, vieme veľmi jednodochu zaembedovať dokumenty a zároveň aj vyhľadávať.
Ako môžete vidieť v práci som použil model LaBSE aj keď som mal k dispozícii priamo natrénovaný model pre slovenčinu. Bolo to z dôvodu zistiť ako sa bude správať model LaBSE oproti modelu, ktorý bol natrénovaný pre Sloveský jazyk. Model LaBSE nebol vybratý len tak náhodou, je to špecifický model, ktorý bol natrénovaný tak, aby podporoval vyhľadávanie, klasifikáciu textu a ďalšie aplikácie vo viacerých jazykoch. Vo všeobecnosti je označovaný ako multilangual embedding model. Je to model ktorý je prispôsobený rôznym jazykom nielen pri indexovaní, ale aj vyľadávaní. Nájväčšou výhodou modelu je že môžeme mať dokument, v ktorom sa nachádzajú vety vo vicacerých jazykoch. Pre niektoré modeli je to veľké obmedzenie s ktorým si neporadiam avšak LaBSE je stavaný na takéto situácie a tak si ľahko poradí a zaindexuje tento dokument.
slovakbert-sts-stsb
- popísať na akom princípe je založený
### Výsledky experimentov
Spolu bolo realizovananých 20 experimentov vyhnotenia vyhľadávania na trénovacom datasete skquad. Každý jeden experiment pozostával z indexovania datasetu a následním vyhľadávaním na vopred vytvorených otázkach. Meódy medzi sebou mali spoločný počet experimentov a pri každej metóde boli vypočítané metriky Precission a Recall.Zároveň na každej metóde bolo vykonaných 5 experimentov s rôznymi parametrami top_k. Z týchto experimentov vznikla jedna veľká nie moc prehľadná tabuľka, ktorú môžete vidieť nižšie.
| Evaluation mode | 5 Precision | 5 Recall | 10 Precision | 10 Recall | 15 Precision | 15 Recall | 20 Precision | 20 Recall | 30 Precision | 30 Recall |
|----------------- |------------- |---------- |-------------- |----------- |-------------- |----------- |-------------- |----------- |-------------- |----------- |
| FAISS | 0.0015329215534271926 | 0.007664607767135963 | 0.0012403410938007953 | 0.012403410938007953 | 0.0010902998324539249 | 0.016354497486808874 | 0.001007777138713146 | 0.020155542774262923 | 0.0008869105670726116 | 0.02660731701217835 |
| BM 25 | 0.113256145439996 | 0.56628072719998 | 0.06176698592112831 | 0.6176698592112831 | 0.043105187259829786 | 0.6465778088974468 | 0.033317912425917126 | 0.6663582485183426 | 0.023139696749939567 | 0.694190902498187 |
| LABSE | 0.09462602215609292 | 0.47313011078046463 | 0.05531896271474655 | 0.5531896271474656 | 0.039858461076796116 | 0.5978769161519418 | 0.031433644252169345 | 0.6286728850433869 | 0.022339059908141407 | 0.6701717972442421 |
|slovakbert-sts-stsb | 0.08082472679986996 | 0.4041236339993498 | 0.04856210457875916 | 0.4856210457875916 | 0.03553810631256929 | 0.5330715946885394 | 0.028241516417014677 | 0.5648303283402936 | 0.020285578534096876 | 0.6085673560229063 |
V poslednom kroku je potrebné vyhodnotiť experimenty. Z takejto neprehľadnej tabuľky je to zložité, preto som zvolil prístup vytvorenia grafov, na ktorých presne vidno ktorá metóda je najlepšia. Boli vytvorené grafy ktoré ukazujú výskedky presnosti a návratnosti na rovnakom počte vrátaných odpovedí medzi métódami. Posledné 4 grafy znázorňujú každp metódu samostatne s narastajúcim počtom odpovedí.
#### Správanie metód pri rovnkakom počte najlepších odpovedí
- Top 5 odpovedí
V tomto grafe môžete vidieť, že pri vyhľadávaní top 5 odpovedí najlepšiu presnosť a návratnosť mala metóda BM25 dosiahla najlepšie výsledky. Najhoršie výsledky boli dosiahnuté metódou Faiss. Metóda sentence transformers s použitím LaBSE dosiahla druhý najlepší výsledok.

- Top 10 odpovedí
Pri 10 najlepších odpovediach BM25 dosiahlo lepší výsledok Recall ako pri top 5 výsledkoch, ale zároveň Precision sa zhoršila. Faiss má naďalej najhoršie výsledky. Sentence tranformers s použitím slovenského modelu slovakbert-sts-stsb sa zlepšila oproti predchádzajúcemu grafu

- Top 15 odpovedí
Na tomoto grafe ďalej môžeme sledovať zlepšovanie Recall pre BM25, ale treba si však všimnúť, že Precission klesá. Dôležtým mýlnikom pri tomto grafe je porovnanie modelu LaBSE s slovakbert-sts-stsb pretože slovakbert sa začína správať pri najlepších 15 odpovediach ako model LaBSE, to nám môže aj naznačit, že s rastúcim počtom odpovedí pre model LaBSE neprichádza viac správnych dokumentov, ako by sa očakávalo. Najviac priblíženie modelu slovakbert modelu k LaBSE môžete vidieť na metrike Precision.

- Top 20 odpovedí
Na tomto grafe už môžeme vidieť, že model LaBSE a slovakbert majú skoro rovnaké hodnoty Precision a Recall. To nám môže nazanačovať, že použitie modelu slovakbert bude silnejšie pri vracaní väčšieho počtu výsledkov.
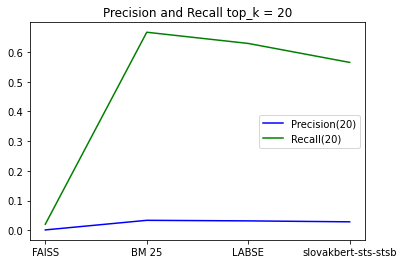
- Top 30 odpovedí
Posledný graf v tejto kategórii nám ukazuje, že aj pri 30 odpovediach má metóda BM25 najlepší Recall, ale treba sa pozrieť na model slovakbert ktorí pri top 30 odpovedach má minimálnu odchýlku od modelu LaBSE.

#### Správanie metódy s narastajúcim počtom najlepších odpovedí
V tejto časti práce skúsim bližšie zobraziť dva grafy na ktorých môžete vidieť správanie metódy hodnotenia vyhľadávania s narastajúcim počtom výsledkov z vyhľadávania. Nižšie sa nachádzajú iba 2 metódy, ktoré podľa mňa v experimentoch dosiahli najlepšie výsledky.
- Metódou BM25
Metóda BM25 počas všetkých experimentov vykazovala najlepšie výsledky nie len Precission, ale aj Recall. Na grafe môžete vidieť, že s narastajúcim počtom výsledkov Precission klesal, ale zároveň Recall stúpal. Pri tejto metóde vidím môžnosti experimentovania napríklad pri 50, alebo 100 odpovediach z vyhľadávania
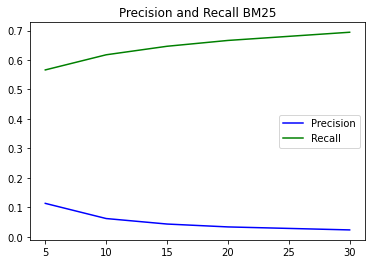
- Metódou sentence transformers s použitím slovakbert-sts-sts
Model slovakbert, ktorý bol zverejnený na konci minulého roka, dosiahol pri poskytnutom datasete perfektné výsledky. Dovoľujem si to tvrdiť z toho dôvodu, že nebol trénovaný na datasete, ktorým bol hodnotený. V budúnosti by mohlo byť zaujímavé dotrénovať tento model pomocou použitého datasetu a následne takýto model ohodnotiť. Predpokladám, že tento model by mohol lepšie vyhľadávať aj pri menšom množstve najlepších výsledkov z vyhľadávania.

### Záver vyhodnotenia experimentov
V tejto práci sa mi podarilo úspešne vykonať 20 experimentov, ktoré ukázali, že dokážeme efektívne využiť natrénovaný slovenský model na iných dátach. Zároveň môžeme vidieť aj efektívne vyhľadávanie metódou BM25, ktorá dosahovala nadpriemerné výsledky.
Pokračovanie v práci by som mohol realizovať použitím dvoch techník vyhľadávania. Ideálnym prípadom môže byť použitie oboch metód, je dôležité, aby metódy išli v správnom poradí. Po prvom vyhľadávan by bolo ideálne použiť text similarity pre efektívne zoradenie výsledkov.