forked from KEMT/zpwiki
Update 'pages/students/2016/patrik_pavlisin/dp22/README.md'
This commit is contained in:
parent
4e11da80ac
commit
efc3b54774
@ -4,19 +4,18 @@
|
||||
|
||||
Transformer je modelová architektúra, ktorá sa vyhýba opakovaniu a namiesto toho sa úplne spolieha na mechanizmus pozornosti na kreslenie globálnych závislostí medzi vstupom a výstupom. Je to prvý transdukčný model, ktorý sa spolieha úplne na vlastnú pozornosť pri výpočte reprezentácii vstupu a výstupu bez použitia RNN (Recurrent Neural Network) alebo CNN (Convolution Neural Network). Používa sa predovšetkým v oblasti NLP (Natural Language Processing) a CV (Computer Vision). Mechanizmy pozornosti sa stali súčasťou presvedčivého modelovania sekvencií a prenosových modelov v rôznych úlohách, ktoré umožňujú modelovanie závislostí bez ohľadu na ich vzdialenosť vo vstupných alebo výstupných sekvenciách. Takmer vo všetkých prípadoch sa však takéto mechanizmy pozornosti používajú v spojení s rekurentnou sieťou. Systémy počítačového videnia (CV) založené na CNN môžu tiež ťažiť z mechanizmov pozornosti. Hlavnou vlastnosťou tzv. “mechanizmus pozornosti” je že vie na základe vstupnej postupnosti v každom kroku rozhodnúť, ktoré časti postupnosti sú dôležité. Je to technika, ktorá napodobňuje kognitívnu pozornosť.
|
||||
|
||||
Najmä Multi-head attention mechanizmus v Transformeri umožňuje, aby bola každá pozícia priamo spojená s akýmikoľvek inými pozíciami v sekvencii. Informácie tak môžu prúdiť cez pozície bez akejkoľvek medzistraty. Napriek tomu existujú dva problémy, ktoré môžu poškodiť účinnosť Multi-head attention pri sekvenčnom učení. Prvý pochádza zo straty sekvenčných informácií o pozíciách, pretože s každou pozíciou zaobchádza rovnako. Na zmiernenie tohto problému Transformer zavádza vkladanie pozícií, ktorých účinky sa však ukázali ako obmedzené.
|
||||
Najmä Multi-head attention mechanizmus v Transformeri umožňuje, aby bola každá pozícia priamo spojená s akýmikoľvek inými pozíciami v sekvencii. Informácie tak môžu prúdiť cez pozície bez akejkoľvek medzistraty. Napriek tomu existujú dva problémy, ktoré môžu poškodiť účinnosť Multi-head attention pri sekvenčnom učení. Prvý pochádza zo straty sekvenčných informácií o pozíciách, pretože s každou pozíciou zaobchádza rovnako. Na zmiernenie tohto problému Transformer zavádza vkladanie pozícií, ktorých účinky sa však ukázali ako obmedzené. [4]
|
||||
|
||||
Na vyriešenie vyššie uvedených obmedzení štandardného Transformera bol navrhnutý nový model sekvenčného učenia R-Transformer. Ide o viacvrstvovú architektúru postavenú na RNN a štandardnom Transformeri, pričom využíva výhody oboch svetov, ale zároveň sa vyhýba ich príslušným nevýhodám. Konkrétnejšie, pred výpočtom globálnych závislostí pozícii pomocou Multi-head attention najskôr spresníme znázornenie každej polohy tak, aby sa sekvenčné a lokálne informácie v jej susedstve mohli v reprezentácii skomprimovať. Aby sa to dosiahlo bola zavedená lokálna rekurentná neurónová sieť, označená ako LocalRNN, na spracovanie signálov v rámci lokálneho okna končiaceho na danej pozícii. LocalRNN navyše pracuje na miestnych oknách všetkých pozícií identicky a nezávisle a pre každú z nich vytvára skrytú reprezentáciu. Okrem toho, keďže sa lokálne okno posúva pozdĺž sekvencie jednu pozíciu za druhou, sú zahrnuté aj globálne sekvenčné informácie. Dôležité najme je, že nakoľko LocalRNN sa používa iba na lokálne okná, vyššie uvedené nevýhody RNN je možné zmierniť.
|
||||
Na vyriešenie vyššie uvedených obmedzení štandardného Transformera bol navrhnutý nový model sekvenčného učenia R-Transformer. Ide o viacvrstvovú architektúru postavenú na RNN a štandardnom Transformeri, pričom využíva výhody oboch svetov, ale zároveň sa vyhýba ich príslušným nevýhodám. Konkrétnejšie, pred výpočtom globálnych závislostí pozícii pomocou Multi-head attention najskôr spresníme znázornenie každej polohy tak, aby sa sekvenčné a lokálne informácie v jej susedstve mohli v reprezentácii skomprimovať. Aby sa to dosiahlo bola zavedená lokálna rekurentná neurónová sieť, označená ako LocalRNN, na spracovanie signálov v rámci lokálneho okna končiaceho na danej pozícii. LocalRNN navyše pracuje na miestnych oknách všetkých pozícií identicky a nezávisle a pre každú z nich vytvára skrytú reprezentáciu. Okrem toho, keďže sa lokálne okno posúva pozdĺž sekvencie jednu pozíciu za druhou, sú zahrnuté aj globálne sekvenčné informácie. Dôležité najme je, že nakoľko LocalRNN sa používa iba na lokálne okná, vyššie uvedené nevýhody RNN je možné zmierniť. [1][6]
|
||||
|
||||
Rekurentné neurónové siete, najmä long short-term pamäť (LSMT, špeciálny druh RNN, vytvorený na riešenie problémov s miznúcim gradientom) a uzavreté rekurentné neurónové siete, boli pevne zavedené ako najmodernejšie prístupy k problémom sekvenčného modelovania a prenosov, ako je jazykové modelovanie a strojový preklad. Početné snahy odvtedy pokračujú v posúvaní hraníc rekurentných jazykových modelov a architektúr encoder-decoder. Sieťové pamäte typu end-to-end sú založené na RNN (Recurrent Neural Network) mechanizme namiesto opakovania zarovnaného podľa sekvencie a ukázalo sa, že fungujú dobre pri úlohách zodpovedajúcich otázky v jednoduchom jazyku a pri modelovaní jazykov. End-to-end učenie je typ Deep Learningu, v ktorom sú všetky parametre trénované spoločne, a nie krok za krokom.
|
||||
Rekurentné neurónové siete, najmä long short-term pamäť (LSMT, špeciálny druh RNN, vytvorený na riešenie problémov s miznúcim gradientom) a uzavreté rekurentné neurónové siete, boli pevne zavedené ako najmodernejšie prístupy k problémom sekvenčného modelovania a prenosov, ako je jazykové modelovanie a strojový preklad. LSTM je architektúra umelej rekurentnej neurónovej siete (RNN), ktorá sa používa v oblasti deep-learning učenia. Na rozdiel od štandardných dopredných neurónových sietí (ang. Feedforward neural network) má LSTM spätnú väzbu. Dokáže spracovať nielen jednotlivé dátové body (napríklad obrázky), ale aj celé sekvencie dát (napríklad reč alebo video). Početné snahy odvtedy pokračujú v posúvaní hraníc rekurentných jazykových modelov a architektúr encoder-decoder. Sieťové pamäte typu end-to-end sú založené na RNN (Recurrent Neural Network) mechanizme namiesto opakovania zarovnaného podľa sekvencie a ukázalo sa, že fungujú dobre pri úlohách zodpovedajúcich otázky v jednoduchom jazyku a pri modelovaní jazykov. End-to-end učenie je typ Deep Learningu, v ktorom sú všetky parametre trénované spoločne, a nie krok za krokom. [7] [8]
|
||||
|
||||
RNN boli dlhodobo dominantnou voľbou pre sekvenčné modelovanie, závažne však trpia najme dvoma problémami. Po prvé, ľahko trpí problémami s miznutím a explodovaním gradientu, čo do značnej miery obmedzuje schopnosť naučiť sa veľmi dlhodobé závislosti. Po druhé, sekvenčná povaha prechodov dopredu aj dozadu veľmi sťažuje, ak nie priam znemožňuje, paralelizáciu výpočtu, čo dramaticky zvyšuje časovú zložitosť v tréningovom aj testovacom postupe. Preto mnohé nedávno vyvinuté modely sekvenčného učenia úplne vypustili rekurentnú štruktúru a spoliehajú sa iba na konvolučnú (Convolution Neural Network) alebo mechanizmus pozornosti, ktoré sa dajú ľahko paralelizovať a umožňujú tok informácií v ľubovoľnej dĺžke. Dva reprezentatívne modely, ktoré pritiahli veľkú pozornosť, sú Temporal Convolution Networks (TCN) a Transformer. V rôznych úlohách sekvenčného učenia preukázali porovnateľný alebo dokonca lepší výkon ako výkonnosť RNN.
|
||||
RNN boli dlhodobo dominantnou voľbou pre sekvenčné modelovanie, závažne však trpia najme dvoma problémami. Po prvé, ľahko trpí problémami s miznutím a explodovaním gradientu, čo do značnej miery obmedzuje schopnosť naučiť sa veľmi dlhodobé závislosti. Po druhé, sekvenčná povaha prechodov dopredu aj dozadu veľmi sťažuje, ak nie priam znemožňuje, paralelizáciu výpočtu, čo dramaticky zvyšuje časovú zložitosť v tréningovom aj testovacom postupe. Preto mnohé nedávno vyvinuté modely sekvenčného učenia úplne vypustili rekurentnú štruktúru a spoliehajú sa iba na konvolučnú (Convolution Neural Network) alebo mechanizmus pozornosti, ktoré sa dajú ľahko paralelizovať a umožňujú tok informácií v ľubovoľnej dĺžke. Dva reprezentatívne modely, ktoré pritiahli veľkú pozornosť, sú Temporal Convolution Networks (TCN) a Transformer. V rôznych úlohách sekvenčného učenia preukázali porovnateľný alebo dokonca lepší výkon ako výkonnosť RNN. [8]
|
||||
|
||||
**Modelová architektúra**
|
||||
|
||||
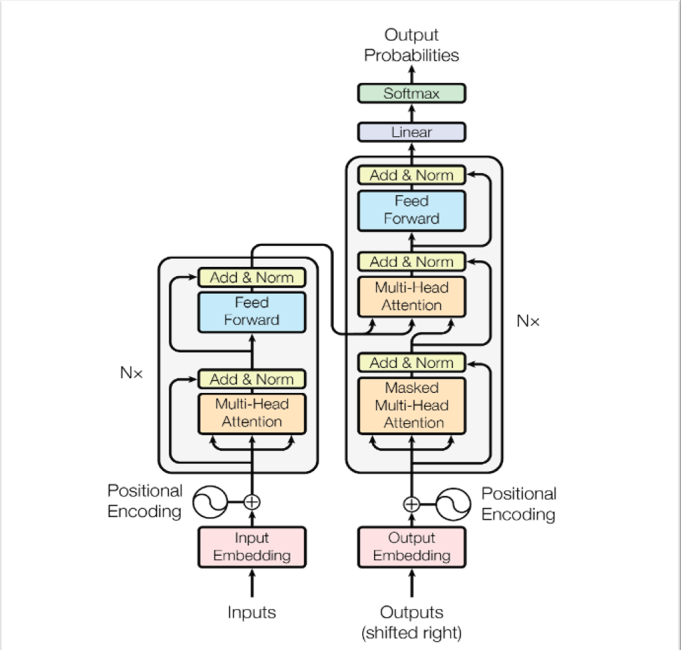
Väčšina konkurenčných prenosových modelov neurónovej sekvencie má štruktúru encoder-decoder. V tomto prípade encoder mapuje vstupnú sekvenciu symbolových reprezentácií (x1, ..., xn) na sekvenciu spojitých reprezentácií z = (z1, ..., zn). Vzhľadom na z, decoder potom generuje výstupnú sekvenciu (y1, ..., ym) symbolov jeden po druhom. V každom kroku je model automaticky regresívny a pri generovaní ďalšieho spotrebuje predtým vygenerované symboly ako ďalší vstup.
|
||||
Väčšina konkurenčných prenosových modelov neurónovej sekvencie má štruktúru encoder-decoder. V tomto prípade encoder mapuje vstupnú sekvenciu symbolových reprezentácií (x1, ..., xn) na sekvenciu spojitých reprezentácií z = (z1, ..., zn). Vzhľadom na z, decoder potom generuje výstupnú sekvenciu (y1, ..., ym) symbolov jeden po druhom. V každom kroku je model automaticky regresívny a pri generovaní ďalšieho spotrebuje predtým vygenerované symboly ako ďalší vstup. [1]
|
||||
|
||||
|
||||
||
|
||||
|:--:|
|
||||
|Obr 1. Modelová architektúra Transformer|
|
||||
@ -35,7 +34,7 @@ Encoder pozostáva z kódovacích vrstiev, ktoré spracovávajú vstup iteračne
|
||||
|
||||
Pri každom vstupe pozornosť zvažuje relevanciu každého ďalšieho vstupu a čerpá z neho pri vytváraní výstupu. Každá decoderová vrstva má mechanizmus dodatočnej pozornosti, ktorý čerpá informácie z výstupov predchádzajúcich decoderov, než vrstva decodera čerpá informácie z kódovaní.
|
||||
|
||||
Obe vrstvy encodera a decodera majú feed-forward neurónovú sieť (umelá neurónová sieť, v ktorej spojenia medzi uzlami netvoria cyklus) na dodatočné spracovanie výstupov a obsahujú zvyškové spojenia a kroky na normalizácie vrstiev.
|
||||
Obe vrstvy encodera a decodera majú feed-forward neurónovú sieť (umelá neurónová sieť, v ktorej spojenia medzi uzlami netvoria cyklus) na dodatočné spracovanie výstupov a obsahujú zvyškové spojenia a kroky na normalizácie vrstiev. [3]
|
||||
|
||||
||
|
||||
|:--:|
|
||||
@ -43,11 +42,11 @@ Obe vrstvy encodera a decodera majú feed-forward neurónovú sieť (umelá neur
|
||||
|
||||
**Transformer Encoder**
|
||||
|
||||
Encoder sa skladá zo zásobníka _N = 6_ rovnakých vrstiev. Každá vrstva má dve podvrstvy. Prvým je multi-head self-attention mechanizmus a druhým je jednoduchá polohovo plne prepojená sieť spätnej väzby. Multi-head Attention je modul pre mechanizmy pozornosti, ktorý prechádza mechanizmom pozornosti niekoľkokrát paralelne. Self-attention, tiež známy ako Intra-attention, je mechanizmus pozornosti, ktorý spája rôzne polohy jednej sekvencie s cieľom vypočítať reprezentáciu tej istej sekvencie. Okolo každej z dvoch čiastkových vrstiev sa používa zvyškové spojenie, po ktorom nasleduje normalizácia vrstvy. To znamená, že výstupom každej podvrstvy je _LayerNorm (x + Sublayer (x))_, kde _Sublayer (x)_ je funkcia implementovaná samotnou podvrstvou. Aby sa uľahčili tieto zvyškové spojenia, všetky podvrstvy v modeli, ako aj vkladacie vrstvy, produkujú výstupy dimenzie _dmodel_ = 512.
|
||||
Encoder sa skladá zo zásobníka _N = 6_ rovnakých vrstiev. Každá vrstva má dve podvrstvy. Prvým je multi-head self-attention mechanizmus a druhým je jednoduchá polohovo plne prepojená sieť spätnej väzby. Multi-head Attention je modul pre mechanizmy pozornosti, ktorý prechádza mechanizmom pozornosti niekoľkokrát paralelne. Self-attention, tiež známy ako Intra-attention, je mechanizmus pozornosti, ktorý spája rôzne polohy jednej sekvencie s cieľom vypočítať reprezentáciu tej istej sekvencie. Okolo každej z dvoch čiastkových vrstiev sa používa zvyškové spojenie, po ktorom nasleduje normalizácia vrstvy. To znamená, že výstupom každej podvrstvy je _LayerNorm (x + Sublayer (x))_, kde _Sublayer (x)_ je funkcia implementovaná samotnou podvrstvou. Aby sa uľahčili tieto zvyškové spojenia, všetky podvrstvy v modeli, ako aj vkladacie vrstvy, produkujú výstupy dimenzie _dmodel_ = 512. [1]
|
||||
|
||||
**Transformer Decoder**
|
||||
|
||||
Decoder je tiež zložený zo zásobníka _N = 6_ rovnakých vrstiev. Okrem dvoch podvrstiev v každej vrstve encodera, decoder vkladá tretiu podvrstvu, ktorá vykonáva multi-head attention nad výstupom encoder zásobníka. Podobne ako encoder, používa zvyškové spojenia okolo každej z podvrstiev, po ktorých nasleduje normalizácia vrstvy. Toto maskovanie v kombinácii so skutočnosťou, že vloženia výstupov sú posunuté o jednu pozíciu, zaisťuje, že predpovede pre polohu _i_ môžu závisieť iba od známych výstupov v polohách menších ako _i_.
|
||||
Decoder je tiež zložený zo zásobníka _N = 6_ rovnakých vrstiev. Okrem dvoch podvrstiev v každej vrstve encodera, decoder vkladá tretiu podvrstvu, ktorá vykonáva multi-head attention nad výstupom encoder zásobníka. Podobne ako encoder, používa zvyškové spojenia okolo každej z podvrstiev, po ktorých nasleduje normalizácia vrstvy. Toto maskovanie v kombinácii so skutočnosťou, že vloženia výstupov sú posunuté o jednu pozíciu, zaisťuje, že predpovede pre polohu _i_ môžu závisieť iba od známych výstupov v polohách menších ako _i_. [1]
|
||||
|
||||
**Scaled Dot-Product Attention**
|
||||
|
||||
@ -64,7 +63,7 @@ V praxi počítame funkciu pozornosti pre množinu dotazov súčasne zabalených
|
||||
|
||||
Dve najčastejšie používané funkcie pozornosti sú additive attention a dot-product attention. Dot-product attention je identická s naším algoritmom, s výnimkou faktora mierky 1/$\sqrt{dk}$. Additive attention počíta funkciu kompatibility pomocou siete spätnej väzby s jednou skrytou vrstvou. Aj keď sú tieto dva teoreticky náročné, dot-product attention je v praxi oveľa rýchlejšia a priestorovo efektívnejšia, pretože je možné ich implementovať pomocou vysoko optimalizovaného maticového multiplikačného kódu.
|
||||
|
||||
Zatiaľ čo pri malých hodnotách dk tieto dva mechanizmy fungujú podobne, additive attention prevyšuje pozornosť produktu bez toho, aby sa škálovala pri väčších hodnotách _dk_. Je pravdepodobné, že pri veľkých hodnotách _dk_ sa bodové produkty zväčšujú a tlačia funkciu _softmax_ do oblastí, kde má extrémne malé gradienty (v strojovom učení je gradient derivátom funkcie, ktorá má viac ako jednu vstupnú premennú). Aby sa tomuto efektu zabránilo, škálujeme bodové produkty o 1/$\sqrt{dk}$
|
||||
Zatiaľ čo pri malých hodnotách dk tieto dva mechanizmy fungujú podobne, additive attention prevyšuje pozornosť produktu bez toho, aby sa škálovala pri väčších hodnotách _dk_. Je pravdepodobné, že pri veľkých hodnotách _dk_ sa bodové produkty zväčšujú a tlačia funkciu _softmax_ do oblastí, kde má extrémne malé gradienty (v strojovom učení je gradient derivátom funkcie, ktorá má viac ako jednu vstupnú premennú). Aby sa tomuto efektu zabránilo, škálujeme bodové produkty o 1/$\sqrt{dk}$ [1] [4]
|
||||
|
||||
**Multi-Head Attention**
|
||||
|
||||
@ -91,7 +90,7 @@ Vo vrstvách „encoder-decoder attention“ pochádzajú dotazy z predchádzaj
|
||||
|
||||
Encoder obsahuje vrstvy self-attention. Vo vrstve self-attention pochádzajú všetky kľúče, hodnoty a dotazy z rovnakého miesta, teda predchádzajúcej vrstvy v encoderu. Každá pozícia v encoderi sa môže venovať všetkým polohám v predchádzajúcej vrstve encodera.
|
||||
|
||||
Vrstvy self-attention v decoderi umožňujú každej pozícii v decoderi zúčastniť sa na všetkých polohách v decoderi až do danej polohy. Musí sa zabrániť toku informácii v decoderi, aby sa zachovala autoregresívna vlastnosť (model časových radov, ktorý používa pozorovania z predchádzajúcich časových krokov ako vstup do regresnej rovnice na predpovedanie hodnoty v nasledujúcom časovom kroku). To implementujeme do scaled dot-product attention pomocou maskovania (nastavením na -∞) všetkých hodnôt na vstupe softmax, ktoré zodpovedajú nezákonným spojeniam.
|
||||
Vrstvy self-attention v decoderi umožňujú každej pozícii v decoderi zúčastniť sa na všetkých polohách v decoderi až do danej polohy. Musí sa zabrániť toku informácii v decoderi, aby sa zachovala autoregresívna vlastnosť (model časových radov, ktorý používa pozorovania z predchádzajúcich časových krokov ako vstup do regresnej rovnice na predpovedanie hodnoty v nasledujúcom časovom kroku). To implementujeme do scaled dot-product attention pomocou maskovania (nastavením na -∞) všetkých hodnôt na vstupe softmax, ktoré zodpovedajú nezákonným spojeniam. [1] [4]
|
||||
|
||||
## R-Transformer
|
||||
|
||||
@ -99,15 +98,15 @@ Vrstvy self-attention v decoderi umožňujú každej pozícii v decoderi zúčas
|
||||
|:--:|
|
||||
|Obr 5. R-Transformer|
|
||||
|
||||
Navrhovaný transformátor R sa skladá zo stohu rovnakých vrstiev. Každá vrstva má 3 komponenty, ktoré sú usporiadané hierarchicky. Ako je znázornené na obrázku, nižšou úrovňou sú lokálne rekurentné neurónové siete, ktoré sú určené na modelovanie lokálnych štruktúr v sekvencii, stredná úroveň je Multi-head attention, ktorá je schopná zachytiť globálne dlhodobé závislosti a horná úroveň je position-wise feedforward sieť, ktorá vykonáva nelineárnu transformáciu prvkov.
|
||||
Navrhovaný transformátor R sa skladá zo stohu rovnakých vrstiev. Každá vrstva má 3 komponenty, ktoré sú usporiadané hierarchicky. Ako je znázornené na obrázku, nižšou úrovňou sú lokálne rekurentné neurónové siete, ktoré sú určené na modelovanie lokálnych štruktúr v sekvencii, stredná úroveň je Multi-head attention, ktorá je schopná zachytiť globálne dlhodobé závislosti a horná úroveň je position-wise feedforward sieť, ktorá vykonáva nelineárnu transformáciu prvkov. [2]
|
||||
|
||||
**Porovnanie s TCN**
|
||||
|
||||
R-Transformer je čiastočne motivovaný hierarchickou štruktúrou v TCN, v TCN je lokalita v sekvenciách zachytená konvolučnými filtrami. Sekvenčné informácie v rámci každého receptívneho poľa sú však pri konvolučných operáciách ignorované. Na rozdiel od toho, štruktúra LocalRNN v R-Transformer ju môže plne začleniť vďaka sekvenčnej povahe RNN. Pre modelovanie globálnych dlhodobých závislostí to TCN dosahuje pomocou rozšírených konvolúcií, ktoré fungujú na nenásledných pozíciách. Aj keď táto operácia vedie k väčším receptívnym poliam v nižších vrstvách, chýba značné množstvo informácií z veľkej časti pozícií v každej vrstve.
|
||||
R-Transformer je čiastočne motivovaný hierarchickou štruktúrou v TCN, v TCN je lokalita v sekvenciách zachytená konvolučnými filtrami. Sekvenčné informácie v rámci každého receptívneho poľa sú však pri konvolučných operáciách ignorované. Na rozdiel od toho, štruktúra LocalRNN v R-Transformer ju môže plne začleniť vďaka sekvenčnej povahe RNN. Pre modelovanie globálnych dlhodobých závislostí to TCN dosahuje pomocou rozšírených konvolúcií, ktoré fungujú na nenásledných pozíciách. Aj keď táto operácia vedie k väčším receptívnym poliam v nižších vrstvách, chýba značné množstvo informácií z veľkej časti pozícií v každej vrstve. [2]
|
||||
|
||||
**Porovnanie s Transformerom**
|
||||
|
||||
R-Transformer a štandardný Transformer majú podobnú kapacitu dlhodobého zapamätania vďaka Multi-head attention mechanizmu. Dve dôležité vlastnosti však odlišujú R-Transformer od štandardného Transformera. Po prvé, R-Transformer explicitne a efektívne zachytáva lokalitu v sekvenciách s novou štruktúrou LocalRNN, zatiaľ čo štandardný Transformer ju modeluje veľmi nepresne pomocou Multi-head attention, ktorá pôsobí na všetkých pozíciách. Po druhé, R-Transformer sa nespolieha na žiadne vloženie polohy ako Transformer. V skutočnosti sú výhody jednoduchého polohového zabudovania veľmi obmedzené a vyžaduje značné úsilie na navrhnutie efektívnych polohových zabudovaní, ako aj správnych spôsobov ich začlenenia.
|
||||
R-Transformer a štandardný Transformer majú podobnú kapacitu dlhodobého zapamätania vďaka Multi-head attention mechanizmu. Dve dôležité vlastnosti však odlišujú R-Transformer od štandardného Transformera. Po prvé, R-Transformer explicitne a efektívne zachytáva lokalitu v sekvenciách s novou štruktúrou LocalRNN, zatiaľ čo štandardný Transformer ju modeluje veľmi nepresne pomocou Multi-head attention, ktorá pôsobí na všetkých pozíciách. Po druhé, R-Transformer sa nespolieha na žiadne vloženie polohy ako Transformer. V skutočnosti sú výhody jednoduchého polohového zabudovania veľmi obmedzené a vyžaduje značné úsilie na navrhnutie efektívnych polohových zabudovaní, ako aj správnych spôsobov ich začlenenia. [2] [4]
|
||||
|
||||
## Zoznam použitej literatúry
|
||||
|
||||
|
||||
Loading…
Reference in New Issue
Block a user