14 KiB
TECHNICKÁ UNIVERZITA V KOŠICIACH
FAKULTA ELEKTRONIKY A INFORMATIKY
Hodnotenie vyhľadávania modelu
2022 Michal Stromko
Úvod
Cieľom tejto práce je zoznámenie sa s možnosťami hodnotenia modelov. Natrénovaný model dokáže vyhodnocovať viacerými technikami s použitím rôzdnych open source riešení. Každé z riešení nám ponúkne iné výsledky. V tejto práci bližšie opíšem základné pojmy, ktoré je potrebné poznať pri hodnotení. Opíšem základné informácie o technikách hodnotenia od základných pojmov ako Vektorové vyhľadávania, DPR, Sentence Transformers, BM-25, Faiss a mnoho ďalších.
Základné znalosti
Na začiatok je potrebné povedať, že pri spracovaní prirodzeného jazyka dokážeme používať rôzne metódy prístupu hodnotenia modelu, poprípade aj vyhľadávanie v modeli. V poslených rokoch sa v praxi stretávame s vyhľadávaním na základe vypočítania vektorov. Následne na takto vypočítané vektory dokážeme pomocou kosínusovej vzdialenosti nájsť vektory, inak povedané dve čísla, ktoré sú k sebe najblyžšie. Jedno z čísel je z množiny vektorov, ktoré patria hľadanému výrazu, druhé číslo patrí slovu, alebo vete, ktorá sa nacháza v indexe.
Vyhodnotenie vyhľadávana v modeli dôležité z hľadiska budúceho použitia modelu do produkcie. Pokiaľ sa do produkcie dostane model, ktorí bude mať nízke ohodnotenie bude sa stávať, že vyhľadávanie bude nepresné to znamená, výskedky nebudú relevantné k tomu čo sme vyhľadávali.
Zameranie práce
V tejto práci som realizoval viaceré experimenty, v ktorých som hodnotil vyhľadávanie pomocou modelov do ktorých bol zaembedovaný text. Každý text obsahuje ďalšie atribúty ako otázky a odpovede. Otázky sa následne pošlú na vyhľadanie a čaká sa na výsledok vyhľadávania. Výsledky ktoré prídu sa následne porovnajú s očakávanými odpoveďami. Najdôležitejšie je nájsť v jednej odpovedi čo najviac správnych výsledkov. Následne je potrebné spočítať počet správnych výsledkov a použiť správne vzpočítať presnosť a návratnosť vyhľadávania. V tomto prípade presnosť a návratnosť počítame pre hodnotenie všetkých otázok. Čím sú hodnoty vyššie, tak konštatujeme že vyhľadávanie pomocou danej metódy je presné a dokážeme ho používať v produkcii.
Dôležtým atribútom s ktorým sme vykonávali testovanie bola menenie parametra top_k. Tento parameter znamená počet najlepších odpovedí na výstupe vyhľadávania. Čím je tento paramter väčší môžeme očakávať, že sa v ňom bude nachádzať väčšie množstvo správnych odpovedí. V konečnom dôledku to vôbec nemusí byť pravda, pretože ak máme kvalitne natrénovaný model a dobre zaembedované dokumenty dokážeme mať správne výsledky na prvých miestach, čo nám ukazuje že parameter top_k može mať menšiu hodnotu.
Najčastejšie je táto hodnota nastavovaná na top 10 najlepších výsledkov vyhľadávania. Pri experimentoch som túto hodnotu nastavoval na hodnoty 5, 10, 15, 20, 30. Každá metóda ktorá bola pouťitá na vyhľadávanie dosiahla iné výsledky.
Použité metódy vyhľadávania v experimentoch
V tejto práci som použil na vyhľadávanie 4 rôzne metódy, ktorým som postupne nastavoval parameter top_k od 5 až 30. Použil som vyhľadávanie pomocou: - Faiss - BM25 - LaBSE - sts-slovakbert-stst
Každá jedna metóda pracuje s úplne iným modelom. Modely LaBSE a sts-slovakbert-stst používali rovnakú knižnicu na vytvorenie vektorov aj vyhľadávanie.
Faiss používal knižnicu spacy, do ktorej parameter model_name vstupoval model ktorý bol natrénovaný pre slovenské dáta na mojej katedre. Následne dáta boli indexované pomocou knižnice faiss, ktorá má funkciu indexovania dát. Vyhľadávanie dát bolo tak isto realizované pomocou funkcie faiss.search() ktorej parametre sú otázka a počet očakávaných dokumentov, alebo inak povedané odpovedí.
BM25 je jeden z najstarších možností vyhľadávania v neuónových sieťach, napriek tomu je to stále stabilná a relatívne presná aj v dnešnej dobe ??? Aký model som používal???
Evaluovanie pomocou modelu LaBSE a sts-slovakbert-stst som realizoval použítím knižnice Sentence tranformers. Práca s touto knižnicou je veľmi jednoduchá, pretože v dokumentácii, ktorú obsahuje, vieme veľmi jednodochu zaembedovať dokumenty a zároveň aj vyhľadávať.
Ako môžete vidieť v práci som použil model LaBSE aj keď som mal k dispozícii priamo natrénovaný model pre slovenčinu. Bolo to z dôvodu zistiť ako sa bude správať model LaBSE oproti modelu, ktorý bol natrénovaný pre Sloveský jazyk. Model LaBSE nebol vybratý len tak náhodou, je to špecifický model, ktorý bol natrénovaný tak, aby podporoval vyhľadávanie, klasifikáciu textu a ďalšie aplikácie vo viacerých jazykoch. Vo všeobecnosti je označovaný ako multilangual embedding model. Je to model ktorý je prispôsobený rôznym jazykom nielen pri indexovaní, ale aj vyľadávaní. Nájväčšou výhodou modelu je že môžeme mať dokument, v ktorom sa nachádzajú vety vo vicacerých jazykoch. Pre niektoré modeli je to veľké obmedzenie s ktorým si neporadiam avšak LaBSE je stavaný na takéto situácie a tak si ľahko poradí a zaindexuje tento dokument.
slovakbert-sts-stsb
- popísať na akom princípe je založený
Výsledky experimentov
Spolu bolo realizovananých 20 experimentov vyhnotenia vyhľadávania na trénovacom datasete skquad. Každý jeden experiment pozostával z indexovania datasetu a následním vyhľadávaním na vopred vytvorených otázkach. Meódy medzi sebou mali spoločný počet experimentov a pri každej metóde boli vypočítané metriky Precission a Recall.Zároveň na každej metóde bolo vykonaných 5 experimentov s rôznymi parametrami top_k. Z týchto experimentov vznikla jedna veľká nie moc prehľadná tabuľka, ktorú môžete vidieť nižšie.
| Evaluation mode | 5 Precision | 5 Recall | 10 Precision | 10 Recall | 15 Precision | 15 Recall | 20 Precision | 20 Recall | 30 Precision | 30 Recall |
|---|---|---|---|---|---|---|---|---|---|---|
| FAISS | 0.0015329215534271926 | 0.007664607767135963 | 0.0012403410938007953 | 0.012403410938007953 | 0.0010902998324539249 | 0.016354497486808874 | 0.001007777138713146 | 0.020155542774262923 | 0.0008869105670726116 | 0.02660731701217835 |
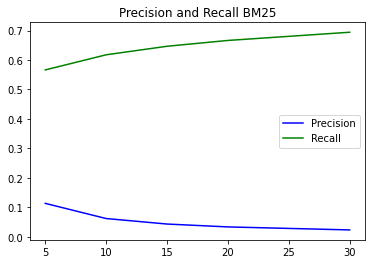
| BM 25 | 0.113256145439996 | 0.56628072719998 | 0.06176698592112831 | 0.6176698592112831 | 0.043105187259829786 | 0.6465778088974468 | 0.033317912425917126 | 0.6663582485183426 | 0.023139696749939567 | 0.694190902498187 |
| LABSE | 0.09462602215609292 | 0.47313011078046463 | 0.05531896271474655 | 0.5531896271474656 | 0.039858461076796116 | 0.5978769161519418 | 0.031433644252169345 | 0.6286728850433869 | 0.022339059908141407 | 0.6701717972442421 |
| slovakbert-sts-stsb | 0.08082472679986996 | 0.4041236339993498 | 0.04856210457875916 | 0.4856210457875916 | 0.03553810631256929 | 0.5330715946885394 | 0.028241516417014677 | 0.5648303283402936 | 0.020285578534096876 | 0.6085673560229063 |
V poslednom kroku je potrebné vyhodnotiť experimenty. Z takejto neprehľadnej tabuľky je to zložité, preto som zvolil prístup vytvorenia grafov, na ktorých presne vidno ktorá metóda je najlepšia. Boli vytvorené grafy ktoré ukazujú výskedky presnosti a návratnosti na rovnakom počte vrátaných odpovedí medzi métódami. Posledné 4 grafy znázorňujú každp metódu samostatne s narastajúcim počtom odpovedí.
Správanie metód pri rovnkakom počte najlepších odpovedí
- Top 5 odpovedí

- Top 10 odpovedí

- Top 15 odpovedí

- Top 20 odpovedí

- Top 30 odpovedí

Správanie metódy s narastajúcim počtom najlepších odpovedí
- Metódou BM25
- Metódou sentence transformers s použitím slovakbert-sts-sts

Záver vyhodnotenia experimentov
Dense Passage Retriever (DPR)
DPR nazývame ako typ systému, spracovania prirodzeného jazyka (NLP). Tento systém získava relevantné časti, inak povedané pasáže z veľkého korpusu textu. V kombinácii s sémantickou analýzou a algoritmom strojového učenia, ktorý idenetifikuje najrelevantnejšie pasáže pre daný dopyt. DPR je založený na používaní správneho enkódera, ktorý mapuje text na dimenzionálne vektory skutočnej hodnoty a vytvára index M, ktorý sa používa pre vyhľadávanie. Treba však povedať, že počas behu DPR sa aplikuje aj iný enkóder EQ, ktorý mapuje vstupnú otázku na d-rozmerný vektor a následne hľadá tie vektory, ktoré sú najbližšie k vektoru otázky. Podobnosť medzi otázkou a časťou odpovede definujeme pomocou Bodového súčinu ich vektorov.

Aj keď existujú silnejšie modelové formy na meranie podobnosti medzi otázkou a pasážou, ako sú siete pozostávajúce z viacerých vrstiev krížovej pozornosti, ktorá musí byť rozložiteľná, aby sme mohli vopred vypočítať kolekcie pasáží. Väčšina rozložiteľných funkcii podobnosti používa transformácie euklidovskej vzdialenosti.
Cross Attentions (krížová pozornosť) Cross Attentions v DPR je technika, ktorá sa používa na zlepšenie presnosti procesu vyhľadávania. Funguje tak, že umožňuje modelu pracovať s viacerými pasížami naraz, čo umožňuje identifikovanie najrelevantnejších pasáží. Pre pre správne identifikovanie DPR berie do úvahy kontext každej pasáže. V prvom kroku najskôr model identifikuje kľúčové výrazy v dotaze a následne použije sémantickú analýzu na identifikáciu súvisiacich výrazov. Mechanizmus pozornisti umožňuje modelu zamerať sa na najdôležitejšie slová v každej pasáži, zatiaľ čo algoritmu strojového učenia pomáha modelu s identifikáciou.
V ďalšom kroku Cross Attentions používa systém bodovania na hodnotenie získaných pasáží. Bodovací systém berie do úvahy relevantnosť pasáží k dopytu, dĺžku pasáží a počet výskytov dopytovacích výrazov v pasážach. Posledným dôležitým atribútom, ktorý sa zisťuje je miera súvislosti nájdeného výrazu k výrazu dopytu.
Pozitívne a negatívne pasáže (Positive and Negative passages) Časté problémy, ktoré vznikajú pri vyhľadávaní sú spojené s opakujúcimi sa pozitívnymi výsledkami, zatiaľ čo negatívne výsledky sa vyberajú z veľkej množiny. Ako príklad si môžeme uviesť pasáž, ktorá súvisí s otázkou a nachádza sa v súbore QA a dá sa nájsť pomocou odpovede. Všetky ostatné pasáže aj keď nie sú explicitne špecifikované, môžu byť predvolene považované za irelevantné. Poznáme tri typy negatívnych odpovedí:
- Náhodný (Random)
- Je to akákoľvek náhodná pasáž z korpusu
- BM25
- Top pasáže vracajúce BM25, ktoré neobsahujú odpoveď, ale zodpovedajú väčšine otázkou
- Zlato (Gold)
- Pozitívne pasáže párované s ostatnými otázkami, ktoré sa objavili v trénovacom súbore
Sentence Transformers
- je Python framework
- dokázeme vypočítať Embeddingy vo vyše 100 jazykoch a dajú sa použíť na bežné úlohy ako napríklad semantic text similarity, sementic search, paraphrase mining
- framework je založený na PyTorch a Transformers a ponúka veľkú zbierku predtrénovyných modelov, ktoré sú vyladené pre rôzdne úlohy
Word Embedding
Požívanie Word Embedings závisí od dobre vypočítaných Embedingov. Pokiaľ máme dobre vypočítané Embeddingy dokážeme veľmi jednoducho dostávať správne odpovede napríklad pri vyhľadávaní. Word Embedding môžeme poznať aj pod slovným spojením ako distribuovaná reprezentácia slov. Dokážeme pomocou neho zachytiť sémantické aj systaktické informácie o slovách z veľkého neoznačeného korpusu.
Word Emedding používa tri kritické komponenty pri trénovaní a to model, korpus a trénovacie parametre. Aby sme mohli navrhnút efektívne word-embedding metódy je potrebné na začiatku objasniť konštrukciu modelu. Takmer všetky metódy trénovania word embeddings sú založené na rovnakej distribučnej hypotéze: Slové, ktoré sa vyskytujú v podobných kontextoch, majú tendenciu mať podobné významy
Vzhľadom na vyšie napísanú hypotézu rôzne metódy modelujú vzťah medzi cieľovým slovom w a jeho kontextom c v korpuse s rôzymi spôsobmi, pričom w a c sú vložené do vektorov. Vo všeobecnosti môžeme povedať, že existujúce metódy sa líšia v dvoch hlavných aspektoch modelu konštrukcii a to vzťah medzi cieľovým slovom a jeho kontextom a reprezentácia kontextu
Treba brať na vedomie, že trénovanie presných word embeddingov silne, inak povedané výrazne súvisí s tréningovým korpusom. Rôzne tréningové korpusy s rôznou veľkosťou a pochádzajúcej z rôzdnej oblasti môžu výrazne ovplyvniť konečné výsledky.
Nakoniec presné trénovanie word embeddingov silne závisí od parametrov akými sú:
- počet iterácii
- dimenzionalita embeddingov
Bol uvedený pre širokú verejnosť v roku 2021