| .. | ||
| def_analyzeru.PNG | ||
| odpoved.PNG | ||
| README.md | ||
| suborova_struktura.PNG | ||
| ukazka_indexovania.PNG | ||
| vyhladavanie.PNG | ||
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Diplomový projekt 2020
Návod na prácu s Elasticsearch
Inštalácia
ES je dostupný na všetky operačné systémy ako Windows, MacOs aj Linux. Pre prácu bol zvolený operačný systém Linux, ktorý je vhodnejší ako Windows. V systéme sme vytvorili adresár, ktorý bude obsahovať všetky potrebné súčasti. Do tohto adresára sme si stiahli ES, ktorý stačilo rozbaliť a je pripravený na použitie aj bez inštalácie. Pre spustením je potrebné mať prostredie Java Runtime Environment vo verzii aspoň 1.8
Podpora slovenčiny
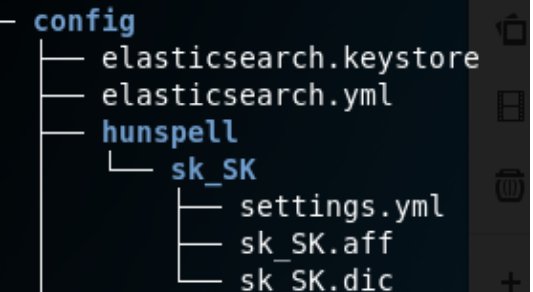
Pre použitie Hunspell token filtru, stačí jeho obsah stiahnuť z webovej stránky a rozbaliť ho. Po rozbalení obsahu je potrebné otvoriť adresár kde máme nainštalovaný ES. Konkrétne v adresári config vytvoríme nový adresár s názvom hunspell, v ňom ďalej vytvoríme adresár sk_SK. Do tohto adresára nakopírujeme súbory, ktoré sme získali rozbalením Hunspellu. Výsledná súborová štruktúru si môžeme pozrieť na obrázku :
Pre správne fungovanie už potrebujeme len nastaviť analyzér správne. Dôležité je poradie v akom sa filtre budú aplikovať na text. Na obrázku si môžeme pozrieť kompletné nastavenie analyzéru(pozn. ES musí byť spustený). Ak je všetko správne ES nám odpovie hláškou "true". Ako definovať analyzér si môžeme pozrieť na obrázku :
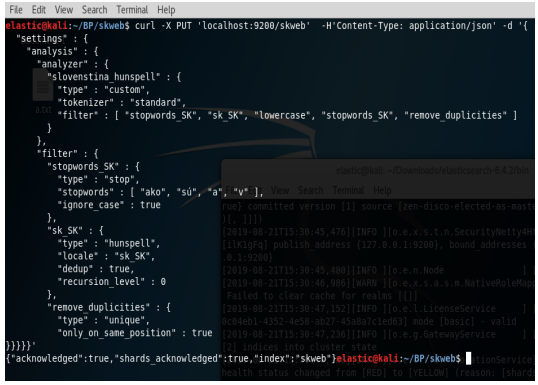
Mapping
Po nastavení analyzéra potrebujeme ešte pred samotným indexovaním dát nastaviť mapping. Je dôležité nastaviť to na začiatku, kedže mapping už potom nie je možné upraviť. Bolo by potrebné zmazať celý index a nastaviť mapping znova. Pri mappingu potrebujeme vedieť, že každý článok bude obsahovať svoje jedinečné ID, názov(title) a telo(body) článku. Týmto poliam musíme definovať štruktúru, čiže ID bude typu integer, polia title a body budú typu text.
Indexovanie dát
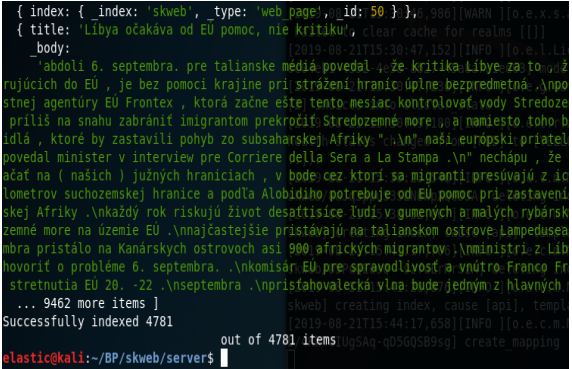
Na indexovanie použijeme pripravený zdrojový kód s názvom elasticsearch.js. Na spustenie javascript kód potrebujeme mať nainštalovaný program Nodejs, najlepšie v čo najnovšej verzii. Kód spustíme pomocou príkazového riadka zadaním príkazu: nodejs elasticsearch.js. Zdrojový kód načítava súbor, v ktorom sú všetky novinové články vo formáte JSON, kde jeden riadok je jeden JSON, čiže jeden novinový článok. Načítavanie prebieha po riadkoch, kde každému riadku je priradený index postupne v rozsahu 1 až 4781. každý článok obsahuje jedinečné ID, názov a telo. Po spustení kódu sa nám zobrazí hláška, ktorá nás informuje o počte indexovaných článkov a vytvorí index s názvom "skweb", kde sa indexuje 4781 novinových článkov, ktorým budú priradené ID. Po úspešnom indexovaní môžeme začať dáta vyhľadávať. Ukážka správneho indexovania je na obrázku :
Vyhľadávanie
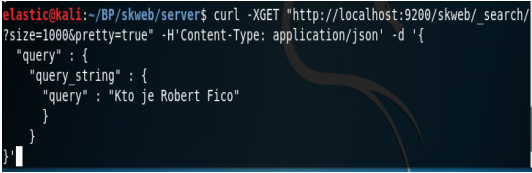
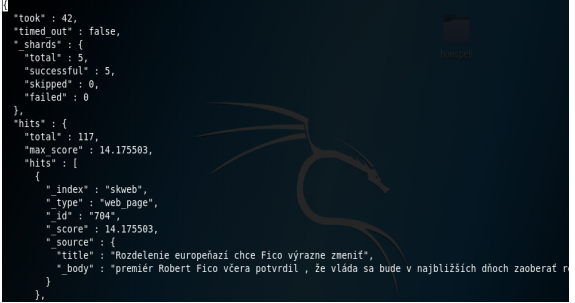
Po úspešnom indexovaní môžeme začať s vyhľadávaním. Musíme si pripraviť dotaz pre ES. Obrázok 5-4 znázorňuje komunikáciu s ES a vyhľadávanie pomocou neho. Odpoveď ES si môžeme pozrieť na obrázku. Sú tam zobrazené informácie o trvaní vyhľadávania v ms, počte nájdených dokumentov, indexe, v ktorom sa nachádza nájdený dokument, type, v ktorom je uložený dokument a ID dokumentu.
Výpočet presnosti
Použijeme metódu precision-recall. V priečinku ../scnc21 sa nachádza súbor answers, ktorý obsahuje ID všetkých relevantných článkov pre každú otázku. Pri vyhľadávaní majú články ID v rozsahu 1-4871. V súbore answers majú články ID dokumentov označené inými číslami. Preto je potrebné každému ID z nášho vyhľadávača priradiť ID zo súboru answers aby sme správne vedeli vypočítať presnosť. Keďže naše indexovanie článkov prebiehalo načítavaním po riadkoch tak ID dokumentu, ktorý nám našiel vyhľadávač je vlastne číslo riadku, pomocou ktorého sme indexovali dáta. Stačí si pozrieť súbor info.txt , pomocou ktorého vieme prideliť správne ID. Potom nám stačí použiť nástroj na výpočet precision-recall, môžeme to byť npm balíček precision-recall alebo online kalkulátor. Ak vypočítame presnosť pre každú otázku na záver stačí vypočítať aritmetický priemer všetkých otázok.
Všetky potrebné zdrojové súbory su priložené v tomto repozitári