| .. | ||
| timovy_projekt | ||
| README.md | ||
| uss.PNG | ||
{kind=link}
| title | published | taxonomy | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Maroš Harahus | true |
|
Maroš Harahus
- Git repozitár ai4steel (pre členov skupiny)
- GIT repozitár s poznámkami (súkromný)
Dizertačná práca
v roku 2023/24
Automatické opravy textu a spracovanie prirodzeného jazyka
Ciele:
- Zverejniť a obhájiť minimovku
- Napísať dizertačnú prácu
- Publikovať 2 články triedy Q2-Q3
Druhý rok doktorandského štúdia
Ciele:
- Publikovanie článku Q2/Q3 - podmienka pre pokračovanie v štúdiu.
- Obhájiť minimovku. Minimovka by mala obsahovať definíciu riešenej úlohy, prehľad problematiky, tézy dizertačnej práce - vedecké prínosy.
- Poskytnite najnovší prehľad.
- Popísať vedecký prínos dizertačnej práce
- Zverejniť min. 1 príspevok na školskej konferencii.
- Publikovať min. 1 riadny konferenčný príspevok.
- Pripraviť demo.
- Pomáhať s výukou, projektami a výskumom.
Prvý ročník PhD štúdia
29.6.
- Vyskúšané https://github.com/NicGian/text_VAE, podľa článku https://arxiv.org/pdf/1511.06349.pdf Tento prístup je pôvodne na Question Generation. Využíva GLOVE embeding a VAE. Možno by sa to dalo využiť ako chybový model.
- So skriptami fairseq sú zatiaľ problémy.
Úlohy:
- Pokračovať v otvorených úlohách.
- Vyskúšať tutoriál https://fairseq.readthedocs.io/en/latest/getting_started.html#training-a-new-model.
- Prečítať knihu "Bishop: Pattern Recognition".
17.6.
- Končí financovanie USsteel , je potrebné zmeniť tému.
Úlohy:
- Do konca ďalšieho školského roka submitovať karent článok. To je podmienka pre ďalšie pokračovanie. Článok by mal nadviazať na predošlý výskum v oblasti "spelling correction".
- Preštudovať články:
- Survey of automatic spelling correction
- Learning string distance with smoothing for OCR spelling correction
- Sequence to Sequence Convolutional Neural Network for Automatic Spelling Correction
- Iné súvisiace články. Kľúčové slová: "automatic spelling correction."
- Naučiť sa pracovať s fairseq. Naučiť sa ako funguje strojový preklad.
- Zopakovať experiment OCR Trec-5 Confusion Track. Pridaný prístup do repozitára https://git.kemt.fei.tuke.sk/dano/correct
Zásobník úloh:
- Vymyslieť systém pre opravu gramatických chýb. Aka Grammarly.
- Využiť GAN-VAE sieť na generovanie chybového textu. To by mohlo pomôcť pri učení NS.
3.6.
Úlohy:
- Pripraviť experiment pri ktorom sa vyhodnotia rôzne spôsoby zhlukovania pre rôzne veľkosti priestoru (PCA, k-means, DBSCAN, KernelPCA - to mi padalo). Základ je v súbore embed.py
- Do tabuľky spísať najdôležitejšie a najmenej dôležité parametre pre rôzne konvertory a pre všetky konvertory naraz (furnace-linear.py).
- Vypočítanie presnosti pre každý konvertor zo spojeného modelu, pokračovať.
27.5.
- Našli sme medzné hodnoty pre dáta zo skriptov USS.
- Urobený skript, polynómová transformácia príznakov nepomáha.
- rozrobený skript na generovanie dát GAN.
Otvorené úlohy:
- Pokračovať v otvorených úlohách.
- (3) Urobiť zhlukovanie a pridať informáciu do dátovej množiny. Zistiť, či informácia o zhlukoch zlepšuje presnosť. Informácia o grade umožňuje predikciu.
Stretnutie 20.5.
Otvorené úlohy:
- (1) Vypočítanie presnosti pre každý konvertor zo spojeného modelu a porovnanie s osobitnými modelmi. Chceme potvrdiť či je spojený model lepší vo všetkých prípadoch.
- (2) Doplniť fyzické limity pre jednotlivé kolónky do anotácie. Ktoré kolónky nemôžu byť negatívne? Tieto fyzické limity by mali byť zapracované do testu robustnosti.
- (4) Overenie robustnosti modelu. Vymyslieť testy invariantnosti, ktoré overia ako sa model správa v extrémnej situácii. Urobiť funkciu, kotrá otestuje parametre lineárnej regresie a povie či je model validný. Urobiť funkciu, ktorá navrhne nejaké vstupy a otestuje, či je výstup validný.
Neprioritné úlohy:
- [o] Preskúmať možnosti zníženia rozmeru vstupného priestoru. PCA? alebo zhlukovanie? Zistiť, či vôbec má zmysel používať autoenóder (aj VAE). (Asi to nemá zmysel)
- Vyradenie niektorých kolóniek, podľa koeficientu lineárnej regresie (daniel, funguje ale nezlepšuje presnosť).
- Generovať umelé "extrémne" dáta. Sledovať, ako sa model správa. Extrémne dáta by mali byť fyzicky možné.
Urobené úlohy:
- Hľadanie hyperparametrov pre neurónku a náhodný les.
Report 29.4.2022
- Práca na VE.
- Čítanie článkov.
Report 8.4.2022
- Študovanie teórie
- Práca na VAE kóde rozpracovaný
Report 1.4.2022
- práca na DH neurónovej sieťi
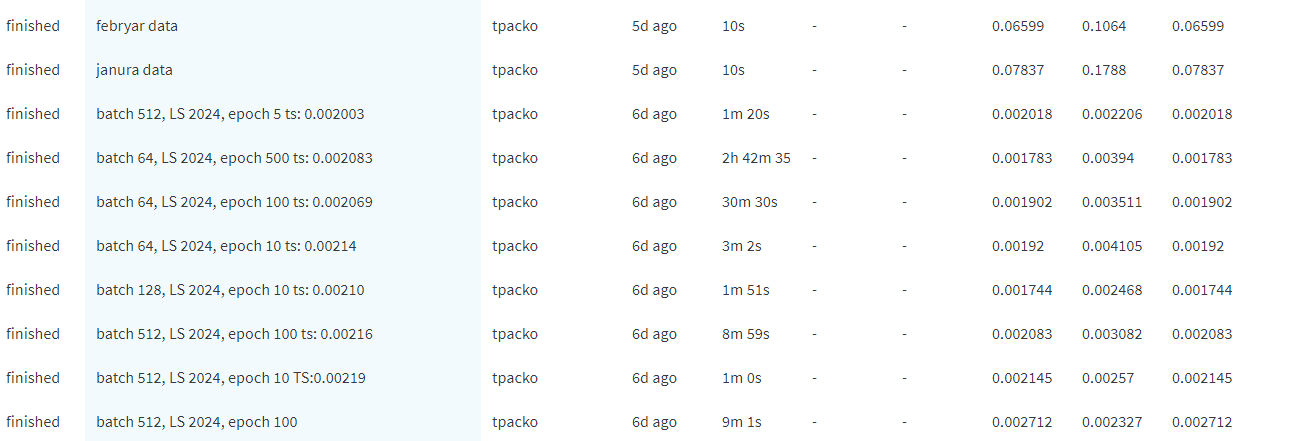
- študovanie o Deep Belief Network
Stretnutie 28.3.
Úlohy:
- Dokončiť podrobnú anotáciu dát. Aké sú kazuálne súvisosti medzi atribútmi?
- Zopakovať a vylepšiť DH neurónovú sieť na predikciu síry
Zásobník úloh:
- Zvážiť použitie Deep Belief Network.
Report 25.3.2022
- Porovnávanie dát január, február (subor je na gite)
- Hodnotenie ešte nemám spisujem čo tým chcem dosiahnuť ci to ma vôbec zmysel na tom pracovať
Report 18.3.2022
- práca na dátach (príprava na TS, zisťovanie súvislosti, hľadanie hraničných hodnôt)
- študovanie timesesries (https://heartbeat.comet.ml/building-deep-learning-model-to-predict-stock-prices-part-1-2-58e62ad754dd,)
- študovanie o reinforcement learning (https://github.com/dennybritz/reinforcement-learning https://github.com/ShangtongZhang/reinforcement-learning-an-introduction)
- študovanie o transfer learning
- študovanie feature selection (https://machinelearningmastery.com/feature-selection-machine-learning-python/ https://www.kdnuggets.com/2021/12/alternative-feature-selection-methods-machine-learning.html)
Report 11.3.2022
-
Data Preprocessing (inspirácia- https://www.kaggle.com/tajuddinkh/drugs-prediction-data-preprocessing-json-to-csv)
-
Analyzovanie dát (inspirácia- https://www.kaggle.com/rounakbanik/ted-data-analysis, https://www.kaggle.com/lostinworlds/analysing-pokemon-dataset https://www.kaggle.com/kanncaa1/data-sciencetutorial-for-beginners)
-
Pracovanie na scripte jsnol --> csv
-
Študovanie time series (https://www.machinelearningplus.com/time-series/time-series-analysis-python/ Python Live - 1| Time Series Analysis in Python | Data Science with Python Training | Edureka Complete Python Pandas Data Science Tutorial! (Reading CSV/Excel files, Sorting, Filtering, Groupby) https://www.kaggle.com/kashnitsky/topic-9-part-1-time-series-analysis-in-python)
-
Time series články (https://ieeexplore.ieee.org/abstract/document/8853246 https://ieeexplore.ieee.org/abstract/document/8931714 https://ieeexplore.ieee.org/abstract/document/8942842 https://arxiv.org/abs/2103.01904)
Working on:
- Neurónovej siete pre GAN time series (stále mam nejaké errory)
- klasickej neuronke
Stretnutie 1.3.2022
Úlohy:
- Zapracovať wandB pre reporting experimentov
- Textovo opísať dáta
Zásobník úloh:
- Vyskúšať predtrénovanie pomocou "historických dát".
Report 25.02.2022
- Prehlaď o jazykových modeloch (BERT, RoBERTa, BART, XLNet, GPT-3) (spracovane poznámky na gite)
- Prehlaď o time-series GAN
- Úprava skriptu z peci jsnol -- > csv
- Skúšanie programu GAN na generovanie obrázkov (na pochopenie ako to funguje)
- Hľadanie vhodnej implementácie na generovanie dát
- Rozpracovaná (veľmi malo) analýza datasetu peci
Stretnutie 2.2.2022
In progress:
- Práca na prehľade článkov VAE-GAN
- na (súkromný) git pridaný náhľad dát a tavný list
- práca na Pandas skripte
Úlohy:
- Dokončiť spacy článok
- Dokončiť prehľad článkov
- Pripraviť prezentáciu na spoločné stretnutie. Do prezentácie uveď čo si sa dozvedel o metódach VAE a GAN. Vysvetli, ako funguje "autoenkóder".
- Napísať krátky blog vrátane odkazov nal literatúru o tom ako funguje neurónový jazykový model (BERT, Roberta, BART, GPT-3, XLNet). Ako funguje? Na čo všetko sa používa?
Stretnutie 18.1.2022
Úlohy:
- Do git repozitára pridať súbor s podrobným popisom jednotlivých kolóniek v dátovej množine.
- [-] Do git repozitára pridať skript na načítanie dát do Pandas formátu.
- Vypracovať písomný prehľad metód modelovania procesov v oceliarni (kyslíkového konvertora BOS-basic oxygen steelmaking).
- Nájsť oznam najnovších článkov k vyhľadávaciuemu heslu "gan time series", "vae time series", "sequence modeling,prediction" napísať ku nim komentár (abstrakt z abstraktu) a dať na git.
- Preformulovať zadanie BP Stromp.
- [-] Dokončiť draft článok spacy.
Zásobník úloh:
- [-] Získať prehľad o najnovších metódach NLP - transformers,GAN, VAE a nájsť súvis s modelovaním BOS.
- nájsť vhodnú implementáciu gan-vae v pythone pre analýzu časových radov alebo postupnosti.
Stretnutie 17.1.2022
- Mame dáta z vysokej pece (500GB)
- Zlepšený konvolučný autoenkóder - dosahuje state-of-the-art.
- Prečítané niečo o transformers a word2vec.
Stretnutie 9.12.2021
- Natrénovaný autoenkóder (feed-forward) pre predikciu celkovej váhy Fe a obsahu S.
- dát je celkom dosť.
Úlohy:
- Vyskúšať iné neurónové siete (keras?).
- Pohľadať dátové množiny, ktoré sú podobné riešenej úlohe. Napr. Open Data.
Stretnutie 26.11.2021
Dáta z US Steel:
- Najprv sa do vysokej pece nasypú suroviny.
- Z tavby sa postupne odoberajú vzorky a meria sa množstvo jednotlivých vzoriek.
- Na konci tavby sa robí finálna analýza taveniny.
- Priebeh procesu závisí od vlastností konkrétnej pece. Sú vlastnosti pece stacionárne? Je možné , že vlastnosti pece sa v čase menia.
- Cieľom je predpovedať výsledky anaýzy finálnej tavby na základe predošlých vzoriek?
- Cieľom je predpovedať výsledky nasledujúceho odberu na základe predchádzajúcich?
- Čo znamená "dobrá tavba"?
- Čo znamená "dobrá predpoveď výsledkov"?
- Je dôležitý čas odbery vzorky?
Zásobník úloh:
- Formulovať problém ako "predikcia časových radov" - sequence prediction.
- Nápad: The analysis of time series : an introduction / Chris Chatfield. 5th ed. Boca Raton : Chapman and Hall, 1996. xii, 283 s. (Chapman & Hall texts in statistical science series). - ISBN 0-412-71640-2 (brož.).
- Prezrieť literatúru a zistiť najnovšie metódy na predikciu.
- Navrhnúť metódu konverzie dát na vektor príznakov. Sú potrebné binárne vektory?
- Navrhnúť metódu výpočtu chybovej funkcie - asi euklidovská vzdialenosť medzi výsledkov a očakávaním.
- Vyskúšať navrhnúť rekurentnú neurónovú sieť - RNN, GRU, LSTM.
- Nápad: Transformer network, Generative Adversarial Network.
- Nápad: Vyskúšať klasické štatistické modely (scikit-learn) - napr. aproximácia polynómom, alebo SVM.
Stretnutie 1.10.
Stav:
- Štúdium základov neurónových sietí
- Úvodné stretnutie s US Steel
Úlohy:
- Vypracovať prehľad aktuálnych metód grafových neurónových sietí
- Nájsť a vyskúšať toolkit na GNN.
- Vytvoriť pracovný repozitár na GITe.
- Naštudovať dáta z US Steel.
- Publikovať diplomovú prácu.
Diplomová práca 2021
Názov diplomovej práce: Neurónová morfologická anotácia slovenského jazyka
- Vysvetlite, ako funguje neurónová morfologická anotácia v knižnici Spacy. Vysvetlite, ako funguje predtrénovanie v knižnici Spacy.
- Pripravte slovenské trénovacie dáta vo vhodnom formáte a natrénujte základný model morfologickej anotácie pomocou knižnice Spacy.
- Pripravte model pre morfologickú anotáciu s pomocou predtrénovania.
- Vyhodnoťte presnosť značkovania modelov vo viacerých experimentoch a navrhnite možné zlepšenia.
Diplomový projekt 2 2020
Zásobník úloh:
- skúsiť prezentovať na lokálnej konferencii, (Data, Znalosti and WIKT) alebo fakultný zborník (krátka verzia diplomovky).
- Využiť korpus Multext East pri trénovaní. Vytvoriť mapovanie Multext Tagov na SNK Tagy.
- vykonať a opísať viac experinentov s rôznymi nastaveniami.
Stretnutie 12.2.
Stav:
- Práca na texte
Do ďalšieho stretnutia:
- Opraviť text podľa ústnej spätnej väzby
- Vysvetlite čo je to morfologická anotácia.
- Vystvetlite ako sa robí? Ako funguje spacy neurónová sieť?
- atď. predošlé textové úlohy z 30.10. 2020
Stretnutie 25.1.2021
Stav:
- Urobená prezentácia, spracované experimenty do tabuľky.
Do ďalšieho stretnutia:
- Pracovať na súvislom texte.
Virtuálne stretnutie 6.11.2020
Stav:
- Prečítané (podrobne) 2 články a urobené poznámky. Poznánky sú na GITe.
- Dorobené ďalšie experimenty.
Úlohy do ďalšieho stretnutia:
- Pokračovať v otvorených úlohách.
Virtuálne stretnutie 30.10.2020
Stav:
- Súbory sú na GIte
- Vykonané experimenty, Výsledky experimentov sú v tabuľke
- Návod na spustenie
- Vyriešenie technických problémov. Je k dispozicíí Conda prostredie.
Úlohy na ďalšie stretnutie:
- Preštudovať literatúru na tému "pretrain" a "word embedding"
- Healthcare NER Models Using Language Model Pretraining
- Design and implementation of an open source Greek POS Tagger and Entity Recognizer using spaCy
- https://arxiv.org/abs/1909.00505
- https://arxiv.org/abs/1607.04606
- LSTM, recurrent neural network,
- Urobte si poznámky z viacerých čnánkov, poznačte si zdroj a čo ste sa dozvedeli.
- Vykonať viacero experimentov s pretrénovaním - rôzne modely, rôzne veľkosti adaptačných dát a zostaviť tabuľku
- Opísať pretrénovanie, zhrnúť vplyv pretrénovania na trénovanie v krátkom článku cca 10 strán.
Virtuálne stretnutie 8.10.2020
Stav:
- Podarilo sa vykonať pretrénovanie aj trénovanie, prvé výsledky experimentov.
- pretrénovanie funguje na GPU, použila sa verzia spacy 2.2, trénovanie na IDOC
- trénovanie ide lepšie na CPU
- vyskytol sa problém že nevie alokovať viac ako 2GB RAM
- 200 iterácií pretrénovania, 4000 riadkov viet
Úlohy do ďalšieho stretnutia:
- Dať zdrojáky na GIT
- Urobiť porovnanie voči presnosti bez pretrain
- Výsledky dajte do tabuľky - aké parametre ste použili pri trénovaní a pretrénovaí?
- experimenty si poznačte do skriptu aby sa dali zopakovať
- Do článku (do súboru README na GIte) presne opíšte nastavenie experimentu - parametre, dáta a spôsob overenia, aspoň rozpracovať.
- Začnite spisovať teoretickú časť článku, aspoň rozpracovať.
Stretnutie 25.9.2020
Stav:
- chyba pri použití príkazu pretrain, ktorá sa objavila s novou verziou Spacy
Úlohy do ďalšieho stretnutia:
- pokračovať so starou verziou Spacy (2.2)
Návrhy na zlepšenie:
- Použiť viac textových dát.
Zvážiť publikovanie na: http://conf.uni-obuda.hu/sami2021/index.html
- najprv napísať po slovensky, potom sa to preloží
- opísať experimenty
Diplomový projekt 2020
Zdroje:
Doplnenie podpory morfologického značkovania slovenského jazyka do nlp frameworku (spacy alebo flair)
- Úlohy na tento semester:
- Pozrieť jazykové zdroje z https://www.clarin.eu/resource-families/manually-annotated-corpora (MultextEast)
- Oboznámte sa so sadou morfologických značiek Universal Dependencies https://universaldependencies.org/sk/index.html
- Oboznámte sa so sadou SNK https://korpus.sk/morpho.html
- Natrénovať Spacy Model s POS a s pretrénovaním
Stretnutie 23.6.2020:
- Výsledok: Skript na trénovanie Spacy POS
Stretnutie 12.6.2020:
- Pretrénovanie Fasttext a trénovanie POS Spacy modelu - ešte treba vylepšiť presnosť
K zápočtu:
- Finálny okomentovaný skript pre trénovanie POS modelu podľa Slovak Treebank s pretrénovaním Fasttext.
- Ak sa dá tak pri trénovaní využite GPU
- Zistite výslednú presnosť, mala by byť nad 80 percent.
- Porovnajte s presnosťou bez pretrénovania.
Virtuálne stretnutie 15.5.2020:
- Spustenie exitujúceho skriptu pre trénovanie POS modelu z repozitára spacy-skmodel, problém nastal pri NER dátach.
- Vytvorený repozitár
Nové úlohy:
- Podrobne preštudovať a realizovať spacy pretrain
- Blog o Spacy pretrain
Revízia 9.4.2020:
Report o doterajšej práci:
- naštudovanie Fasttext
- implementácia do Spacy
- úprava modelu v spacy na rozpoznanie jazyka
- snaha o spacy-udpipe pre non-English text
Nové úlohy:
- pridajte zdrojový text a odkaz na "implementáciu".
- natrénujte model podľa https://git.kemt.fei.tuke.sk/dano/spacy-skmodel
- skúste pridať "word-embeddingy" z fasttext do trénovania.
- vyhodnoťte natrénovaný model - zistite presnosť značkovania. Aký vplyv majú embeddingy na presnosť?
- porozmýšľajte ako sa dá presnosť zlepšiť.
Stretnutie 5.3.2020:
Úlohy na ďalšie stretnutie:
- zobrať alebo vytvoriť fasttext model
- pozrieť sa na spacy pretrain - tam sa bude dať využiť fasttext model
- vložiť ho do spacy modelu pomocou
spacy pretrain - pozrieť si http://nl.ijs.si/ME/V4/ morfosyntaktická anotácia MULTEXT
- porozmýšľať ako využiť korpus "MultextEast" - potrebné vytvoriť mapovanie značiek na SNK Tagset
Poznámka:
- Aktivovaná Omega
- Pozrieť sa na https://git.kemt.fei.tuke.sk/dano/spacy-skmodel/src/branch/master/sources/slovak-treebank , aktivovaný prístup
- už existuje mapovanie Universal Dependencie na SNK tagset
Stretnutie: 20.2.2020:
Úlohy na ďalšie stretnutie:
- Pozrieť https://spacy.io/usage/training#tagger-parser
- Pozrieť si čo je word embedding - word2vec, fasttext, glove
- Nájsť spôsob ako využiť existujúci model word embedding pri trénovaní https://fasttext.cc/docs/en/pretrained-vectors.html
- Ako natrénovať Spacy POS model?
Tímový projekt 2019
Projektové stránky:
- Vypracovať tutoriál pre prácu s nástrojom Spacy pre úlohu zisťovania gramatických značiek (part-of-speech). Súčasťou tutoriálu by mali byť aj odkazy na relevantné zdroje (odborné članky, min. 4).