forked from KEMT/zpwiki
one
This commit is contained in:
commit
6b358c865a
@ -11,6 +11,14 @@ Rok začiatku štúdia: 2016
|
|||||||
|
|
||||||
Repozitár so [zdrojovými kódmi](https://git.kemt.fei.tuke.sk/dl874wn/dp2021)
|
Repozitár so [zdrojovými kódmi](https://git.kemt.fei.tuke.sk/dl874wn/dp2021)
|
||||||
|
|
||||||
|
Názov: Obnovenie interpunkcie pomocou hlbokých neurónových sietí
|
||||||
|
|
||||||
|
1. Vypracujte prehľad metód na obnovenie interpunkcie pomocou neurónových sietí.
|
||||||
|
2. Vyberte vhodnú metódu obnovenia interpunkcie pomocou neurónových sietí.
|
||||||
|
3. Pripravte množinu dát na trénovanie neurónovej siete, navrhnite a vykonajte sadu experimentov s rôznymi parametrami.
|
||||||
|
4. Vyhodnoťte experimenty a navrhnite možné zlepšenia.
|
||||||
|
|
||||||
|
|
||||||
## Diplomový projekt 2 2020
|
## Diplomový projekt 2 2020
|
||||||
|
|
||||||
Stretnutie 25.1.2021
|
Stretnutie 25.1.2021
|
||||||
@ -79,12 +87,6 @@ Urobené:
|
|||||||
- 3. Vykonať sadu experimentov na overenie presnosti klasifikácie zvolenej neurónovej siete
|
- 3. Vykonať sadu experimentov na overenie presnosti klasifikácie zvolenej neurónovej siete
|
||||||
|
|
||||||
|
|
||||||
Názov: Obnovenie interpunkcie pomocou neurónových sietí
|
|
||||||
|
|
||||||
1. Vypracujte prehľad metód na obnovenie interpunkcie pomocou neurónových sietí.
|
|
||||||
2. Vyberte vhodnú metódu obnovenia interpunkcie pomocou neurónových sietí.
|
|
||||||
3. Pripravte množinu dát na trénovanie neurónovej siete, navrhnite a vykonajte sadu experimentov s rôznymi parametrami.
|
|
||||||
4. Vyhodnoťte experimenty a navrhnite možné zlepšenia.
|
|
||||||
|
|
||||||
## Zápis o činnosti
|
## Zápis o činnosti
|
||||||
|
|
||||||
|
|||||||
@ -2,7 +2,7 @@
|
|||||||
title: Dominik Nagy
|
title: Dominik Nagy
|
||||||
published: true
|
published: true
|
||||||
taxonomy:
|
taxonomy:
|
||||||
category: [dp2021,bp2019]
|
category: [dp2022,bp2019]
|
||||||
tag: [translation,nlp]
|
tag: [translation,nlp]
|
||||||
author: Daniel Hladek
|
author: Daniel Hladek
|
||||||
---
|
---
|
||||||
@ -10,8 +10,43 @@ taxonomy:
|
|||||||
|
|
||||||
*Rok začiatku štúdia*: 2016
|
*Rok začiatku štúdia*: 2016
|
||||||
|
|
||||||
|
## Diplomová práca 2022
|
||||||
|
|
||||||
|
*Názov diplomovej práce*: Prepis postupností pomocou neurónových sietí pre strojový preklad
|
||||||
|
|
||||||
|
*Meno vedúceho*: Ing. Daniel Hládek, PhD.
|
||||||
|
|
||||||
|
*Zadanie diplomovej práce*:
|
||||||
|
|
||||||
|
1. Vypracujte teoretický prehľad metód "sequence to sequence".
|
||||||
|
2. Pripravte si dátovú množinu na trénovanie modelu sequence to sequence pre úlohu strojového prekladu.
|
||||||
|
3. Vyberte minimálne dva rôzne modely a porovnajte ich presnosť na vhodnej dátovej množine.
|
||||||
|
4. Na základe výsledkov experimentov navrhnite zlepšenia.
|
||||||
|
|
||||||
|
|
||||||
|
## Príprava na Diplomový projekt 2 2021
|
||||||
|
|
||||||
|
Zásobník úloh:
|
||||||
|
|
||||||
|
- Využiť BERT model pri strojovom preklade zo slovenčiny
|
||||||
|
|
||||||
|
Stretnutie 17.2.2021
|
||||||
|
|
||||||
|
Stav:
|
||||||
|
|
||||||
|
- Plán ukončiť v roku 2022
|
||||||
|
- Vypracovaný tutoriál https://fairseq.readthedocs.io/en/latest/getting_started.html#training-a-new-model a https://fairseq.readthedocs.io/en/latest/tutorial_simple_lstm.html
|
||||||
|
|
||||||
|
Do ďalšieho stretnutia:
|
||||||
|
|
||||||
|
- Pripraviť slovensko-anglický korpus do podoby vhodnej na trénovanie. Zistite v akej podobe je potrebné dáta mať.
|
||||||
|
- Natrénovať model fairseq pre strojový preklad zo slovenčiny.
|
||||||
|
- Zistite ako prebieha neurónový strojový preklad, čo je to neurónová sieť, čo je to enkóder, dekóder model a napíšte to vlastnými slovami. Napíšte aj odkiaľ ste to zistili.
|
||||||
|
- Prečítajte si https://arxiv.org/abs/1705.03122 a https://arxiv.org/abs/1611.02344 a napíšte čo ste sa dozvedeli.
|
||||||
|
|
||||||
## Diplomový projekt 2
|
## Diplomový projekt 2
|
||||||
|
|
||||||
|
|
||||||
Virtuálne stretnutie 25.9.
|
Virtuálne stretnutie 25.9.
|
||||||
|
|
||||||
- Možnosť predĺženia štúdia
|
- Možnosť predĺženia štúdia
|
||||||
@ -59,18 +94,6 @@ Stretnutie 6.3.2020.
|
|||||||
- Pozrieť článok [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://www.aclweb.org/anthology/N19-4009/)
|
- Pozrieť článok [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://www.aclweb.org/anthology/N19-4009/)
|
||||||
- Pozrieť prístup a článok https://github.com/pytorch/fairseq/blob/master/examples/joint_alignment_translation/README.md
|
- Pozrieť prístup a článok https://github.com/pytorch/fairseq/blob/master/examples/joint_alignment_translation/README.md
|
||||||
|
|
||||||
## Diplomová práca 2021
|
|
||||||
|
|
||||||
*Názov diplomovej práce*: Prepis postupností pomocou neurónových sietí pre strojový preklad
|
|
||||||
|
|
||||||
*Meno vedúceho*: Ing. Daniel Hládek, PhD.
|
|
||||||
|
|
||||||
*Zadanie diplomovej práce*:
|
|
||||||
|
|
||||||
1. Vypracujte teoretický prehľad metód "sequence to sequence".
|
|
||||||
2. Pripravte si dátovú množinu na trénovanie modelu sequence to sequence pre úlohu strojového prekladu.
|
|
||||||
3. Vyberte minimálne dva rôzne modely a porovnajte ich presnosť na vhodnej dátovej množine.
|
|
||||||
4. Na základe výsledkov experimentov navrhnite zlepšenia.
|
|
||||||
|
|
||||||
## Tímový projekt 2019
|
## Tímový projekt 2019
|
||||||
|
|
||||||
|
|||||||
@ -8,9 +8,46 @@ taxonomy:
|
|||||||
---
|
---
|
||||||
# Jakub Maruniak
|
# Jakub Maruniak
|
||||||
|
|
||||||
|
|
||||||
*Rok začiatku štúdia*: 2016
|
*Rok začiatku štúdia*: 2016
|
||||||
|
|
||||||
|
*Návrh na názov DP*:
|
||||||
|
|
||||||
|
Anotácia a rozpoznávanie pomenovaných entít v slovenskom jazyku.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
1. Vypracujte teoretický úvod, kde vysvetlíte čo je to rozpoznávanie pomenovaných entít a akými najnovšími metódami sa robí. Vysvetlite, ako pracuje klasifikátor pre rozpoznávanie pomenovaných entít v knižnici Spacy.
|
||||||
|
2. Pripravte postup na anotáciu textového korpusu pre systém Prodigy pre trénovanie modelu vo vybranej úlohe spracovania prirodzeného jazyka.
|
||||||
|
3. Vytvorte množinu textových dát v slovenskom jazyku vhodných na trénovanie štatistického modelu spracovania prirodzeného jazyka pomocou knižnice Spacy.
|
||||||
|
4. Natrénujte štatistický model pomocou knižnice Spacy a zistite, aký vplyv má veľkosť trénovacej množiny na presnosť klasifikátora.
|
||||||
|
|
||||||
|
*Spolupráca s projektom*:
|
||||||
|
|
||||||
|
- [Podpora slovenčiny v Spacy](/topics/spacy)
|
||||||
|
- [Anotácia textových dát](/topics/prodigy)
|
||||||
|
- [Rozpoznávanie pomenovaných entít](/topics/named-entity)
|
||||||
|
- [Spracovanie prir. jazyka](/topics/nlp)
|
||||||
|
- [Programovanie v jazyku Python](/topics/python)
|
||||||
|
|
||||||
|
|
||||||
|
## Diplomová práca 2021
|
||||||
|
|
||||||
|
|
||||||
|
Stretnutie 12.3.
|
||||||
|
|
||||||
|
Stav:
|
||||||
|
|
||||||
|
- Anotovanie dát, vykonané experimenty s trénovaním.
|
||||||
|
- Dosiahli sme presnosť cca 72 percent.
|
||||||
|
- Výsledky sú zhrnuté v tabuľke.
|
||||||
|
|
||||||
|
Úlohy:
|
||||||
|
|
||||||
|
- Píšte prácu.
|
||||||
|
- Uložte trénovacie skripty na GIT.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## Diplomový projekt 2
|
## Diplomový projekt 2
|
||||||
|
|
||||||
Ciele:
|
Ciele:
|
||||||
@ -19,10 +56,18 @@ Ciele:
|
|||||||
|
|
||||||
Zásobník úloh:
|
Zásobník úloh:
|
||||||
|
|
||||||
- Zvážiť zmenu názvu práce. Je "Crowdsourcing" relevantný pojen?
|
|
||||||
- Použiť model na podporu anotácie
|
- Použiť model na podporu anotácie
|
||||||
- Do konca ZS vytvoriť report vo forme článku.
|
- Do konca ZS vytvoriť report vo forme článku.
|
||||||
|
|
||||||
|
Stretnutie 12.2.:
|
||||||
|
|
||||||
|
- Prebrali sme článok. Treba vyhodiť a popresúvať niektoré časti, inak v poriadku.
|
||||||
|
|
||||||
|
Do budúceho stretnutia:
|
||||||
|
|
||||||
|
- Vybrať vhodný časopis na publikovanie
|
||||||
|
- Využiť pri trénovaní ďalšie anotované dáta.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
@ -206,21 +251,3 @@ Návrh možných entít na anotáciu:
|
|||||||
|
|
||||||
*Písomná práca*: [Rešerš](./timovy_projekt)
|
*Písomná práca*: [Rešerš](./timovy_projekt)
|
||||||
|
|
||||||
*Návrh na zadanie DP*:
|
|
||||||
|
|
||||||
1. Vypracujte prehľad metód prípravy textových korpusov pomocou crowdsourcingu.
|
|
||||||
2. Pripravte postup na anotáciu textového korpusu pre systém Prodigy pre trénovanie modelu vo vybranej úlohe spracovania prirodzeného jazyka.
|
|
||||||
3. Vytvorte množinu textových dát v slovenskom jazyku vhodných na trénovanie štatistického modelu spracovania prirodzeného jazyka pomocou knižnice Spacy.
|
|
||||||
4. Natrénujte štatistický model pomocou knižnice Spacy a zistite, aký vplyv má veľkosť trénovacej množiny na presnosť klasifikátora.
|
|
||||||
|
|
||||||
*Návrh na názov DP*:
|
|
||||||
|
|
||||||
Anotácia textových dát v slovenskom jazyku pomocou metódy crowdsourcingu
|
|
||||||
|
|
||||||
*Spolupráca s projektom*:
|
|
||||||
|
|
||||||
- [Podpora slovenčiny v Spacy](/topics/spacy)
|
|
||||||
- [Anotácia textových dát](/topics/prodigy)
|
|
||||||
- [Rozpoznávanie pomenovaných entít](/topics/named-entity)
|
|
||||||
- [Spracovanie prir. jazyka](/topics/nlp)
|
|
||||||
- [Programovanie v jazyku Python](/topics/python)
|
|
||||||
|
|||||||
@ -23,6 +23,18 @@ taxonomy:
|
|||||||
3. Navrhnite a vypracujte experimenty, v ktorých vyhodnotíte vybrané metódy odhodnotenia dokumentov.
|
3. Navrhnite a vypracujte experimenty, v ktorých vyhodnotíte vybrané metódy odhodnotenia dokumentov.
|
||||||
4. Navrhnite možné zlepšenia presnosti vyhľadávania.
|
4. Navrhnite možné zlepšenia presnosti vyhľadávania.
|
||||||
|
|
||||||
|
Stretnutie 12.3.
|
||||||
|
|
||||||
|
Stav:
|
||||||
|
|
||||||
|
- Implementovaný PageRank, indexovanie webových stránok
|
||||||
|
|
||||||
|
Úlohy:
|
||||||
|
|
||||||
|
- Pripravte experiment s PageRank, databáza SCNC2, vyhodnotenie pomocou P-R-F1
|
||||||
|
- Pozrite do knihy na metódy vyhodnotenta s PageRank
|
||||||
|
- Pozrite do knihy a skúste pripraviť inú metriku.
|
||||||
|
- Popri tom priprave demonštráciu s webovým rozhraním.
|
||||||
|
|
||||||
## Diplomový projekt 2 2020
|
## Diplomový projekt 2 2020
|
||||||
|
|
||||||
|
|||||||
@ -10,6 +10,29 @@ taxonomy:
|
|||||||
|
|
||||||
*Rok začiatku štúdia:* 2016
|
*Rok začiatku štúdia:* 2016
|
||||||
|
|
||||||
|
|
||||||
|
Názov: Paralelné trénovanie neurónových sietí
|
||||||
|
|
||||||
|
*Meno vedúceho:* Ing. Daniel Hládek, PhD.
|
||||||
|
|
||||||
|
## Diplomová práca 2021
|
||||||
|
|
||||||
|
1. Vypracujte prehľad literatúry na tému "Paralelné trénovanie neurónových sietí".
|
||||||
|
2. Vyberte vhodnú metódu paralelného trénovania.
|
||||||
|
3. Pripravte dáta a vykonajte sadu experimentov pre overenie funkčnosti a výkonu paralelného trénovania.
|
||||||
|
4. Navrhnite možné zlepšenia paralelného trénovania neurónových sietí.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Stretnutie: 5.3.2021
|
||||||
|
|
||||||
|
Stav:
|
||||||
|
|
||||||
|
- Urobené trénovanie na dvoch servroch pomocou distributed_data_parallel MNIST.
|
||||||
|
- Funguje LUNA dataset (na 1 stroji a na viacerých kartách).
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## Diplomový projekt 2 2020
|
## Diplomový projekt 2 2020
|
||||||
|
|
||||||
Ciele na semester:
|
Ciele na semester:
|
||||||
@ -175,18 +198,6 @@ Stretnutie 9.3.2020
|
|||||||
|
|
||||||
*Písomná práca:* [Paralelné spracovanie prirodzeného jazyka](./timovy_projekt)
|
*Písomná práca:* [Paralelné spracovanie prirodzeného jazyka](./timovy_projekt)
|
||||||
|
|
||||||
## Diplomová práca 2021
|
|
||||||
|
|
||||||
### Paralelné trénovanie neurónových sietí
|
|
||||||
|
|
||||||
*Meno vedúceho:* Ing. Daniel Hládek, PhD.
|
|
||||||
|
|
||||||
*Návrh na zadanie DP:*
|
|
||||||
|
|
||||||
1. Vypracujte prehľad literatúry na tému "Paralelné trénovanie neurónových sietí".
|
|
||||||
2. Vyberte vhodnú metódu paralelného trénovania.
|
|
||||||
3. Pripravte dáta a vykonajte sadu experimentov pre overenie funkčnosti a výkonu paralelného trénovania.
|
|
||||||
4. Navrhnite možné zlepšenia paralelného trénovania neurónových sietí.
|
|
||||||
|
|
||||||
|
|
||||||
- Zaujímavá príručka [Word2vec na Spark](http://spark.apache.org/docs/latest/ml-features.html#word2vec)
|
- Zaujímavá príručka [Word2vec na Spark](http://spark.apache.org/docs/latest/ml-features.html#word2vec)
|
||||||
|
|||||||
@ -8,16 +8,15 @@ taxonomy:
|
|||||||
---
|
---
|
||||||
# Maroš Harahus
|
# Maroš Harahus
|
||||||
|
|
||||||
Názov diplomovej práce: Štatistická morfologická anotácia slovenského jazyka
|
Názov diplomovej práce: Neurónová morfologická anotácia slovenského jazyka
|
||||||
|
|
||||||
|
|
||||||
## Návrh na zadanie DP
|
## Návrh na zadanie DP
|
||||||
|
|
||||||
1. Vypracujte prehľad spôsobov morfologickej anotácie slovenského jazyka.
|
1. Vysvetlite, ako funguje neurónová morfologická anotácia v knižnici Spacy. Vysvetlite, ako funguje predtrénovanie v knižnici Spacy.
|
||||||
2. Vysvetlite, ako funguje morfologická anotácia v knižnici Spacy. Vysvetlite, ako funguje predtrénovanie v knižnici Spacy.
|
2. Pripravte slovenské trénovacie dáta vo vhodnom formáte a natrénujte základný model morfologickej anotácie pomocou knižnice Spacy.
|
||||||
3. Pripravte slovenské trénovacie dáta vo vhodnom formáte a natrénujte základný model morfologickej anotácie pomocou knižnice Spacy.
|
3. Pripravte model pre morfologickú anotáciu s pomocou predtrénovania.
|
||||||
4. Pripravte model pre morfologickú anotáciu s pomocou predtrénovania.
|
4. Vyhodnoťte presnosť značkovania modelov vo viacerých experimentoch a navrhnite možné zlepšenia.
|
||||||
5. Vyhodnoťte presnosť značkovania modelov vo viacerých experimentoch a navrhnite možné zlepšenia.
|
|
||||||
|
|
||||||
## Diplomový projekt 2 2020
|
## Diplomový projekt 2 2020
|
||||||
|
|
||||||
@ -25,6 +24,21 @@ Zásobník úloh:
|
|||||||
|
|
||||||
- skúsiť prezentovať na lokálnej konferencii, (Data, Znalosti and WIKT) alebo fakultný zborník (krátka verzia diplomovky).
|
- skúsiť prezentovať na lokálnej konferencii, (Data, Znalosti and WIKT) alebo fakultný zborník (krátka verzia diplomovky).
|
||||||
- Využiť korpus Multext East pri trénovaní. Vytvoriť mapovanie Multext Tagov na SNK Tagy.
|
- Využiť korpus Multext East pri trénovaní. Vytvoriť mapovanie Multext Tagov na SNK Tagy.
|
||||||
|
- vykonať a opísať viac experinentov s rôznymi nastaveniami.
|
||||||
|
|
||||||
|
Stretnutie 12.2.
|
||||||
|
|
||||||
|
Stav:
|
||||||
|
|
||||||
|
- Práca na texte
|
||||||
|
|
||||||
|
Do ďalšieho stretnutia:
|
||||||
|
|
||||||
|
- Opraviť text podľa ústnej spätnej väzby
|
||||||
|
- Vysvetlite čo je to morfologická anotácia.
|
||||||
|
- Vystvetlite ako sa robí? Ako funguje spacy neurónová sieť?
|
||||||
|
- atď. predošlé textové úlohy z 30.10. 2020
|
||||||
|
|
||||||
|
|
||||||
Stretnutie 25.1.2021
|
Stretnutie 25.1.2021
|
||||||
|
|
||||||
|
|||||||
@ -25,6 +25,42 @@ Návrh na nástroje pre strojový preklad:
|
|||||||
3. Pripraviť vybraný paralelný korpus do vhodnej podoby a pomocou vybranej metódy natrénovať model pre strojový preklad.
|
3. Pripraviť vybraný paralelný korpus do vhodnej podoby a pomocou vybranej metódy natrénovať model pre strojový preklad.
|
||||||
4. Vyhodnotiť experimenty a navrhnúť možnosti na zlepšenie.
|
4. Vyhodnotiť experimenty a navrhnúť možnosti na zlepšenie.
|
||||||
|
|
||||||
|
## Diplomový projekt 1
|
||||||
|
|
||||||
|
Stretnutie 12.3.
|
||||||
|
|
||||||
|
Stav:
|
||||||
|
|
||||||
|
- poznámky k článku "Google’s neural machine translation system .
|
||||||
|
- Śtúdium ostatných článkov pokračuje.
|
||||||
|
- Problém - aktuálna verzia OpenNMT-py nefunguje s pythonom 3.5. Je potrebné využit Anacondu.
|
||||||
|
|
||||||
|
Úlohy:
|
||||||
|
|
||||||
|
- Vypracujte poznámky k článkom
|
||||||
|
- Pokračujte v tutoriáli OpenNMT-py cez prostredie Anaconda.
|
||||||
|
- Poznámky pridajte na zpWiki vo formáte Markdown
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Stretnutie 18.2.
|
||||||
|
|
||||||
|
Stav:
|
||||||
|
- Vypracovaný článok z minulého semestra
|
||||||
|
|
||||||
|
Úlohy:
|
||||||
|
|
||||||
|
- V linuxovom prostredí (napr. idoc) si vytvorte python virtuálne prostredie:
|
||||||
|
- vytvorte si adresár s projektom
|
||||||
|
- mkdir ./venv
|
||||||
|
- python3 -m virtualenv ./venv
|
||||||
|
- source ./venv/bin/activate
|
||||||
|
- Keď skončíte: deactivate
|
||||||
|
- Prejdite si tutoriál https://github.com/OpenNMT/OpenNMT-py
|
||||||
|
- Prečítjte si články z https://opennmt.net/OpenNMT-py/ref.html
|
||||||
|
- Vypracujte poznámky k článku "Google’s neural machine translation system: bridging the gap between human and machine translation. arXiv preprint arXiv:1609.08144, 2016". Čo ste sa z čánku dozvedeli?
|
||||||
|
|
||||||
|
|
||||||
## Tímový projekt 2021
|
## Tímový projekt 2021
|
||||||
|
|
||||||
Ciel:
|
Ciel:
|
||||||
|
|||||||
45
pages/students/2016/patrik_pavlisin/dp21/README.md
Normal file
45
pages/students/2016/patrik_pavlisin/dp21/README.md
Normal file
@ -0,0 +1,45 @@
|
|||||||
|
|
||||||
|
## Google's neural machine translation system
|
||||||
|
|
||||||
|
NMT používa end-to-end vzdelávací prístup pre automatický preklad, ktorého cieľom je prekonať slabé stránky konvenčných frázových systémov. Bohužiaľ systémy NMT sú výpočtovo nákladné počas trénovania ako aj pri samotnom preklade (niekedy kvôli ochrane napr. pri vysokom množstve veľkých súborov a veľkých modelov). Niekoľko autorov tiež uviedlo, že systémom NMT chýba robustnosť, najmä keď vstupné vety obsahujú zriedkavé, alebo zastaralé slová. Tieto problémy bránili používaniu NMT v praktických nasadeniach a službách, kde je nevyhnutná presnosť aj rýchlosť. Spoločnosť Google preto predstavila GNMT (Google´s Neural Machine Translation) systém , ktorý sa pokúša vyriešiť mnohé z týchto problémov. Tento model sa skladá z hlbokej siete Long Short-Term Memory (LSTM) s 8 kódovacími a 8 dekódovacími vrstvami, ktoré využívajú zvyškové spojenia, ako aj pozorovacie spojenia zo siete dekodéra ku kódovaciemu zariadeniu. Aby sa zlepšila paralelnosť a tým pádom skrátil čas potrebný na tréning, tento mechanizmus pozornosti spája spodnú vrstvu dekodéra s hornou vrstvou kódovacieho zariadenia. Na urýchlenie konečnej rýchlosti prekladu používame pri odvodzovacích výpočtoch aritmetiku s nízkou presnosťou. Aby sa vylepšila práca so zriedkavými slovami, slová sa delia na vstup aj výstup na obmedzenú množinu bežných podslovných jednotiek („wordpieces“). Táto metóda poskytuje dobrú rovnováhu medzi flexibilitou modelov oddelených znakom a účinnosťou modelov oddelených slovom, prirodzene zvláda preklady vzácnych slov a v konečnom dôsledku zvyšuje celkovú presnosť systému.
|
||||||
|
|
||||||
|
Štatistický strojový preklad (SMT) je po celé desaťročia dominantnou paradigmou strojového prekladu. Implementáciami SMT sú vo všeobecnosti systémy založené na frázach (PBMT), ktoré prekladajú sekvencie slov alebo frázy, kde sa môžu dĺžky líšiť. Ešte pred príchodom priameho neurónového strojového prekladu sa neurónové siete s určitým úspechom používali ako súčasť systémov SMT. Možno jeden z najpozoruhodnejších pokusov spočíval v použití spoločného jazykového modelu na osvojenie frázových reprezentácií, čo prinieslo pozoruhodné zlepšenie v kombinácii s prekladom založeným na frázach. Tento prístup však vo svojej podstate stále využíva frázové prekladové systémy, a preto dedí ich nedostatky.
|
||||||
|
|
||||||
|
O koncepciu end-to-end učenia pre strojový preklad sa v minulosti pokúšali s obmedzeným úspechom. Po seminárnych prácach v tejto oblasti sa kvalita prekladu NMT priblížila k úrovni frázových prekladových systémov pre bežné výskumné kritériá. V anglickom až francúzskom jazyku WMT’14 dosiahol tento systém zlepšenie o 0,5 BLEU v porovnaní s najmodernejším frázovým systémom. Odvtedy bolo navrhnutých veľa nových techník na ďalšie vylepšenie NMT ako napríklad použitie mechanizmu pozornosti na riešenie zriedkavých slov, mechanizmu na modelovanie pokrytia prekladu, rôznymi druhmi mechanizmov pozornosti, minimalizáciou strát na úrovni vety. Aj keď presnosť prekladu týchto systémov bola povzbudivá, systematické porovnanie s veľkým rozsahom chýba, frázové prekladové systémy založené na kvalite výroby chýbajú.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
LSTM sú špeciálny typ Rekurentných neurónových sietí (RNN), ktorý slúži na dosiahnutie dlhodobého kontextu (napr. Pri doplnení chýbajúcej interpunkcie alebo veľkých písmen). Najväčšie využitie LSTM je v oblasti strojového učenia a hĺbkového učenia.
|
||||||
|
|
||||||
|
Vlastnosti LSTM:
|
||||||
|
|
||||||
|
- pripravený spracovať nielen jednoduché dáta, ale aj celé sekvenčné dáta (napr. reč alebo video),
|
||||||
|
|
||||||
|
- sú vhodné na klasifikáciu, spracovanie a vytváranie predikcií na základe časových údajov
|
||||||
|
|
||||||
|
- LSTM boli definované tak, aby si na rozdiel od RNN vedeli pomôcť s problémom, ktorý sa nazýva „Exploding and vanishing gradient problems“.
|
||||||
|
|
||||||
|
## Exploding and vanishing gradient problems
|
||||||
|
|
||||||
|
V strojovom učení sa s problémom miznúceho gradientu stretávame pri trénovaní umelých neurónových sietí metódami učenia založenými na gradiente a spätnou propagáciou. V takýchto metódach dostáva každá z váh neurónovej siete aktualizáciu úmernú čiastočnej derivácii chybovej funkcie vzhľadom na aktuálnu váhu v každej iterácii tréningu. Problém je v tom, že v niektorých prípadoch bude gradient zbytočne malý, čo účinne zabráni tomu, aby váha zmenila svoju hodnotu. V najhoršom prípade to môže úplne zabrániť neurónovej sieti v ďalšom tréningu. Ako jeden príklad príčiny problému majú tradičné aktivačné funkcie, ako je hyperbolická tangenciálna funkcia, gradienty v rozsahu (0, 1) a spätné šírenie počíta gradienty podľa pravidla reťazca. To má za následok znásobenie n týchto malých čísel na výpočet gradientov prvých vrstiev v sieti n-vrstiev, čo znamená, že gradient (chybový signál) exponenciálne klesá s n, zatiaľ čo prvé vrstvy trénujú veľmi pomaly.
|
||||||
|
|
||||||
|
Ak sa použijú aktivačné funkcie, ktorých deriváty môžu nadobúdať väčšie hodnoty, riskujeme, že narazíme na súvisiaci problém s explodujúcim gradientom. Problém s explodujúcim gradientom je problém, ktorý sa môže vyskytnúť pri trénovaní umelých neurónových sietí pomocou gradientného klesania spätným šírením. Problém s explodujúcim gradientom je možné vyriešiť prepracovaním sieťového modelu, použitím usmernenej lineárnej aktivácie, využitím sietí s dlhodobou krátkodobou pamäťou (LSTM), orezaním gradientu a regularizáciou hmotnosti. Ďalším riešením problému s explodujúcim gradientom je zabrániť tomu, aby sa gradienty zmenili na 0, a to pomocou procesu známeho ako orezávanie gradientov, ktorý kladie na každý gradient vopred definovanú hranicu. Orezávanie prechodov zaisťuje, že prechody budú smerovať rovnakým smerom, ale s kratšími dĺžkami.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## Wordpiece Model
|
||||||
|
|
||||||
|
Tento prístup je založený výlučne na dátach a je zaručené, že pre každú možnú postupnosť znakov vygeneruje deterministickú segmentáciu. Je to podobné ako metóda použitá pri riešení zriedkavých slov v strojovom preklade neurónov. Na spracovanie ľubovoľných slov najskôr rozdelíme slová na slovné druhy, ktoré sú dané trénovaným modelom slovných spojení. Pred cvičením modelu sú pridané špeciálne symboly hraníc slov, aby bolo možné pôvodnú sekvenciu slov získať zo sekvencie slovného slova bez nejasností. V čase dekódovania model najskôr vytvorí sekvenciu slovných spojení, ktorá sa potom prevedie na zodpovedajúcu sekvenciu slov.
|
||||||
|
|
||||||
|
|
|
||||||
|
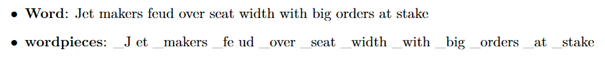
|
||||||
|
|
|
||||||
|
|:--:|
|
||||||
|
|Obr 1. príklad postupnosti slov a príslušná postupnosť slovných spojení|
|
||||||
|
|
||||||
|
|
||||||
|
Vo vyššie uvedenom príklade je slovo „Jet“ rozdelené na dve slovné spojenia „_J“ a „et“ a slovo „feud“ je rozdelené na dve slovné spojenia „_fe“ a „ud“. Ostatné slová zostávajú ako jednotlivé slová. „_“ Je špeciálny znak pridaný na označenie začiatku slova.
|
||||||
|
|
||||||
|
Wordpiece model sa generuje pomocou prístupu založeného na údajoch, aby sa maximalizovala pravdepodobnosť jazykových modelov cvičných údajov, vzhľadom na vyvíjajúcu sa definíciu slova. Vzhľadom na cvičný korpus a množstvo požadovaných tokenov D je problémom optimalizácie výber wordpieces D tak, aby výsledný korpus bol minimálny v počte wordpieces, ak sú segmentované podľa zvoleného wordpiece modelu. V tejto implementácii používame špeciálny symbol iba na začiatku slov, a nie na oboch koncoch. Počet základných znakov tiež znížime na zvládnuteľný počet v závislosti na údajoch (zhruba 500 pre západné jazyky, viac pre ázijské jazyky). Zistili sme, že použitím celkovej slovnej zásoby medzi 8 000 a 32 000 slovnými jednotkami sa dosahuje dobrá presnosť (skóre BLEU) aj rýchla rýchlosť dekódovania pre dané jazykové páry.
|
||||||
|
|
||||||
|
V preklade má často zmysel kopírovať zriedkavé názvy entít alebo čísla priamo zo zdroja do cieľa. Na uľahčenie tohto typu priameho kopírovania vždy používame wordpiece model pre zdrojový aj cieľový jazyk. Použitím tohto prístupu je zaručené, že rovnaký reťazec vo zdrojovej a cieľovej vete bude segmentovaný presne rovnakým spôsobom, čo uľahčí systému naučiť sa kopírovať tieto tokeny. Wordpieces dosahujú rovnováhu medzi flexibilitou znakov a efektívnosťou slov. Zistili sme tiež, že naše modely dosahujú lepšie celkové skóre BLEU pri používaní wordpieces - pravdepodobne kvôli tomu, že naše modely teraz efektívne pracujú v podstate s nekonečnou slovnou zásobou bez toho, aby sa uchýlili iba k znakom.
|
||||||
BIN
pages/students/2016/patrik_pavlisin/tp20/Bez názvu.png
Normal file
BIN
pages/students/2016/patrik_pavlisin/tp20/Bez názvu.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 18 KiB |
@ -1,82 +1,97 @@
|
|||||||
# Strojový preklad
|
# Strojový preklad
|
||||||
|
|
||||||
## Štatistický strojový preklad
|
## Štatistický strojový preklad
|
||||||
|
|
||||||
Strojový preklad je automatický preklad jednej, alebo skupiny viacerých viet jedného jazyka do druhého pomocou počítačov. Jedná sa o dôležitú aplikáciu v oblasti spracovania prirodzeného jazyka a záujem o toto odvetvie je takmer taký starý ako elektronický počítač. Štatistický strojový preklad zaznamenal za necelé dve desaťročia obrovský pokrok a v súčasnosti práve on dominuje v tejto oblasti výskumu. SMT využíva veľké množstvo paralelných korpusov a textov, ktoré už boli predtým preložené, vďaka čomu je stroj preložiť dovtedy nevidené vety. Príkladom pre SMT sú modely IBM, slovné modely, ktoré predstavujú prvú generáciu štatistického strojového prekladu. S použitím rôznych nástrojov a dostatku paralelného textu tak môžeme vytvoriť strojový preklad pre nový jazykový pár vo veľmi krátkom čase, podľa niektorých štúdii dokonca za menej ako deň.
|
Strojový preklad je automatický preklad jednej, alebo skupiny viacerých viet jedného jazyka do druhého pomocou počítačov. Jedná sa o dôležitú aplikáciu v oblasti spracovania prirodzeného jazyka a záujem o toto odvetvie je takmer taký starý ako elektronický počítač. Štatistický strojový preklad zaznamenal za necelé dve desaťročia obrovský pokrok a v súčasnosti práve on dominuje v tejto oblasti výskumu. SMT využíva veľké množstvo paralelných korpusov a textov, ktoré už boli predtým preložené, vďaka čomu je stroj preložiť dovtedy nevidené vety. Príkladom pre SMT sú modely IBM, slovné modely, ktoré predstavujú prvú generáciu štatistického strojového prekladu. S použitím rôznych nástrojov a dostatku paralelného textu tak môžeme vytvoriť strojový preklad pre nový jazykový pár vo veľmi krátkom čase, podľa niektorých štúdii dokonca za menej ako deň.
|
||||||
|
|
||||||
Popularita internetu výrazne ovplyvnila záujem o strojový preklad a šírenie informácii vo viacerých jazykoch. Príkladom sú viacjazyčné vlády, spravodajské agentúry a spoločnosti pôsobiace na globálnom trhu. Vďaka tomuto rozšíreniu sú základným zdrojom vo výskume SMT, pretože sú každodenným produktom bežných ľudských činností. A je to taktiež jeden z dôvodov, prečo Európska únia, či Vláda Spojených štátov zvýšila financovanie výskumu strojového prekladu na podporu svojich záujmov v oblasti politiky. Rýchli a lacný výpočtový hardvér umožnil aplikácie, ktoré závisia od veľkého počtu súborov údajov a miliárd štatistík. Výrazne k tomu prispeli pokroky v rýchlosti procesora, veľkosti a rýchlosti pamäte novších počítačov. Vývoj metrík automatického prekladu taktiež umožnil zrýchliť vývoj systémov strojového prekladu a podporil konkurenciu medzi výskumnými skupinami. [10]
|
Popularita internetu výrazne ovplyvnila záujem o strojový preklad a šírenie informácii vo viacerých jazykoch. Príkladom sú viacjazyčné vlády, spravodajské agentúry a spoločnosti pôsobiace na globálnom trhu. Vďaka tomuto rozšíreniu sú základným zdrojom vo výskume SMT, pretože sú každodenným produktom bežných ľudských činností. A je to taktiež jeden z dôvodov, prečo Európska únia, či Vláda Spojených štátov zvýšila financovanie výskumu strojového prekladu na podporu svojich záujmov v oblasti politiky. Rýchli a lacný výpočtový hardvér umožnil aplikácie, ktoré závisia od veľkého počtu súborov údajov a miliárd štatistík. Výrazne k tomu prispeli pokroky v rýchlosti procesora, veľkosti a rýchlosti pamäte novších počítačov. Vývoj metrík automatického prekladu taktiež umožnil zrýchliť vývoj systémov strojového prekladu a podporil konkurenciu medzi výskumnými skupinami. [10]
|
||||||
|
|
||||||
## Neurónový strojový preklad
|
## Neurónový strojový preklad
|
||||||
Sila NMT spočíva v jeho schopnosti učiť sa priamo, end-to-end spôsobom, mapovanie zo vstupného textu na asociovaný výstupný text. Neurónový strojový preklad je jedným z novších prístupov k štatistickej strojovej translácii založenej čisto na neurónových sieťach, pozostávajú z kódovacieho zariadenia a dekódera. Tento typ strojového prekladu viedol k zlepšeniu najmä v oblasti hodnotenia ľudí, v porovnaní so systémami založenými na štatistických pravidlách a štatistickým strojovým prekladom. Posledné štúdie však ukazujú, že NMT všeobecne produkuje plynulé, ale nedostatočné preklady, čo je v kontraste s konvenčným štatistickým strojovým prekladom, ktorý produkuje adekvátne, ale nie plynulé preklady. Kóder extrahuje reprezentáciu pevnej dĺžky zo vstupnej vety s premennou dĺžkou a dekóder následne vygeneruje finálny preklad z danej reprezentácie. Neurálny strojový preklad funguje dobre predovšetkým na krátke vety bez neznámych slov, preklad sa však zhoršuje s pribúdajúcou dĺžkou textu a neznámych slov, taktiež slovná zásoba ma veľký vplyv na výkon prekladu. Výhodou neurálneho strojového prekladu je, že oproti SMT vyžaduje iba zlomok pamäte pre trénovanie (napr. ak neurónový strojový preklad použije 500 MB pamäte, SMT by na rovnaké trénovanie využil desiatky gigabajtov). Na rozdiel od iných konvenčných prekladových systémov, sa každý komponent modelu neurálneho prekladu trénuje spoločne, aby sa maximalizoval výkon prekladu. [4] [5] [6] [7]
|
|
||||||
|
Sila NMT spočíva v jeho schopnosti učiť sa priamo, end-to-end spôsobom, mapovanie zo vstupného textu na asociovaný výstupný text. End-to-end učenie je typ procesu Deep Learning, v ktorom sú všetky parametre trénované spoločne, a nie krok za krokom. Neurónový strojový preklad je jedným z novších prístupov v štatistickom strojovom preklade založený čisto na neurónových sieťach, pozostávajú z kódovacieho zariadenia a dekódera. Tento typ strojového prekladu viedol k zlepšeniu najmä v oblasti hodnotenia ľudí, v porovnaní so systémami založenými na štatistickom strojovom preklade. Podľa najnovších štúdií NMT všeobecne produkuje plynulé, ale nedostatočné preklady, čo je v kontraste s konvenčným štatistickým strojovým prekladom, ktorý produkuje adekvátne, ale nie plynulé preklady. Kódovacie zariadenie extrahuje reprezentáciu pevnej dĺžky zo vstupnej vety s premennou dĺžkou a dekóder následne vygeneruje finálny preklad z danej reprezentácie. Neurálny strojový preklad funguje dobre predovšetkým na krátke vety bez neznámych slov, preklad sa však zhoršuje s pribúdajúcou dĺžkou textu a neznámych slov, taktiež slovná zásoba ma veľký vplyv na výkon prekladu. Výhodou neurónového strojového prekladu je, že oproti SMT vyžaduje iba zlomok pamäte pre trénovanie (napr. ak neurónový strojový preklad použije 500 MB pamäte, SMT by na rovnaké trénovanie využil desiatky gigabajtov). Na rozdiel od iných konvenčných prekladových systémov, sa každý komponent modelu neurálneho prekladu trénuje spoločne, aby sa maximalizoval výkon prekladu. [4] [5] [6] [7]
|
||||||
## NMT s SMT výhodami
|
|
||||||
|
## NMT s SMT výhodami
|
||||||
Vzhľadom na vedomosti, ktoré máme o NMT a SMT je preto prirodzené pokúsiť sa využívať výhody oboch modelov na lepšie preklady. Konkrétne začleniť model SMT do rámca NMT, čo znamená, že v každom kroku SMT odošle ďalšie odporúčania generovaných slov na základe dekódovacích informácii z NMT. Experimentálne výsledky čínsko-anglického prekladu (NMT advised by SMT, 2016) ukazujú, že navrhovaný prístup dosahuje mimoriadne konzistentné vylepšenia oproti najnovším NMT a SMT modelom. Jedným z rozdielov v tomto prístupe je, že tento model nevyberá ďalšie slovo len na základe vektorových reprezentácií, ale umožňuje tiež predikciu na základe odporúčaní z modelu SMT. (Viac informácii na [3] ).
|
|
||||||
|
Vzhľadom na vedomosti, ktoré máme o NMT a SMT je preto prirodzené pokúsiť sa využívať výhody oboch modelov na lepšie preklady. Konkrétne začleniť model SMT do rámca NMT, čo znamená, že v každom kroku SMT odošle ďalšie odporúčania generovaných slov na základe dekódovacích informácii z NMT. Experimentálne výsledky čínsko-anglického prekladu (NMT advised by SMT, 2016) ukazujú, že navrhovaný prístup dosahuje mimoriadne konzistentné vylepšenia oproti najnovším NMT a SMT modelom. Jedným z rozdielov v tomto prístupe je, že tento model nevyberá ďalšie slovo len na základe vektorových reprezentácií (vektory čísel, ktoré predstavujú význam slova), ale umožňuje tiež predikciu na základe odporúčaní z modelu SMT. (Viac informácii na [3] ).
|
||||||
## Recurrent neural network
|
|
||||||
|
## Recurrent neural network
|
||||||
Rekurentná neurónová sieť (RNN) je trieda umelých neurónových sietí, kde spojenia medzi uzlami vytvárajú usmernený graf pozdĺž časovej postupnosti. To mu umožňuje vykazovať časové dynamické správanie. RNN môžu používať svoj vnútorný stav (pamäť) na spracovanie sekvencií vstupov s premennou dĺžkou. Obojsmerná rekurentná neurónová sieť, známa ako kódovač, používa neurónová sieť na kódovanie zdrojovej vety pre druhý RNN, známy ako dekodér, ktorý sa používa na predikciu slov v cieľovom jazyku. Rekurentné neurónové siete čelia problémom pri kódovaní dlhých vstupov do jedného vektora. To je možné kompenzovať pomocou tzv. attention mechanisms, ktorý umožňuje dekodéru sústrediť sa na rôzne časti vstupu pri generovaní každého slova výstupu. Existujú ďalšie modely pokrytia, ktoré sa zaoberajú problémami v takýchto mechanizmoch pozornosti, napríklad ignorovanie informácií o minulom zosúladení vedúcich k nadmernému prekladu a nedostatočnému prekladu.
|
|
||||||
|
Rekurentné neurónové siete (RNN) sú najmodernejším algoritmom pre sekvenčné dáta a používajú ich napr. Apple´s Siri alebo Google. Je to prvý algoritmus, ktorý si pamätá svoj vstup a to vďaka vnútornej pamäti, čo ho robí perfektným pre problémy strojového učenia, ktoré zahŕňajú sekvenčné dáta. RNN môžu používať svoj vnútorný stav (pamäť) na spracovanie sekvencií vstupov s premennou dĺžkou. Obojsmerná rekurentná neurónová sieť, známa ako kóder, používa neurónová sieť na kódovanie zdrojovej vety pre druhý RNN, známy ako dekodér, ktorý sa používa na predikciu slov v cieľovom jazyku. Neurónová sieť sa považuje za snahu napodobniť akcie ľudského mozgu zjednodušeným spôsobom. Mechanizmus pozornosti je tiež pokusom o implementáciu rovnakej akcie selektívneho sústredenia sa na niekoľko dôležitých vecí, zatiaľ čo ostatné sú ignorované v hlbokých neurónových sieťach. Rekurentné neurónové siete čelia problémom pri kódovaní dlhých vstupov do jedného vektora. To je možné kompenzovať pomocou tzv. attention mechanisms (mechanizmus pozornosti), ktorý umožňuje dekodéru sústrediť sa na rôzne časti vstupu pri generovaní každého slova výstupu.
|
||||||
Termín „rekurentná neurónová sieť“ sa používa bez rozdielu na označenie dvoch širokých tried sietí s podobnou všeobecnou štruktúrou, kde jedna je konečný impulz a druhá nekonečný impulz. Obe triedy sietí vykazujú časové dynamické správanie. Konečná impulzná opakujúca sa sieť je usmernený acyklický graf, ktorý je možné rozvinúť a nahradiť ho striktne doprednou neurálnou sieťou, zatiaľ čo nekonečná impulzná opakujúca sa sieť je usmernený cyklický graf, ktorý sa nedá rozvinúť. Konečné impulzné aj nekonečné impulzné opakujúce sa siete môžu mať ďalšie uložené stavy a úložisko môže byť pod priamou kontrolou neurónovej siete. Úložisko je tiež možné nahradiť inou sieťou alebo grafom, ak obsahuje časové oneskorenia alebo má spätnoväzbové slučky. (Viac informácii na ( [7],[8] ).
|
|
||||||
|
Termín „rekurentná neurónová sieť“ sa používa bez rozdielu na označenie dvoch širokých tried sietí s podobnou všeobecnou štruktúrou, kde jedna je konečný impulz a druhá nekonečný impulz. Obe triedy sietí vykazujú časové dynamické správanie. Konečná impulzná opakujúca sa sieť je filter, ktorého impulzná odozva (alebo odozva na akýkoľvek vstup konečnej dĺžky) má konečnú dobu trvania, pretože sa v konečnom čase usadí na nule, zatiaľ čo nekonečná impulzná odozva (IIR) je vlastnosť vzťahujúca sa na mnoho lineárnych časovo invariantných systémov, ktoré sa vyznačujú tým, že majú impulznú odozvu h (t), ktorá sa nestane presne nulou za určitým bodom, ale pokračuje donekonečna. (Viac informácii na ( [7],[8] ).
|
||||||
## Convolutional Neural Networks
|
|
||||||
|
|
||||||
Okrem RNN je ďalším prirodzeným prístupom k riešeniu sekvencií s premennou dĺžkou použitie rekurzívnej konvolučnej neurónovej siete, kde sú parametre na každej úrovni zdieľané cez celú sieť. Konvolučné neurónové siete sú v zásade o niečo lepšie pre dlhé nepretržité sekvencie, ale pôvodne sa nepoužívali kvôli niekoľkým slabinám. Tie boli v roku 2017 úspešne kompenzované pomocou „attention mechanisms“.
|
## Convolutional Neural Networks
|
||||||
|
|
||||||
Konvolučná neurónová sieť (CNN) je trieda hlbokých neurónových sietí, ktorá sa najčastejšie používa na analýzu vizuálnych snímok. Sú tiež známe ako umelé neurónové siete s posunom invariantu alebo s priestorovým invariantom (SIANN) na základe ich architektúry zdieľaných váh a charakteristík invariantnosti translácie. CNN používajú v porovnaní s inými algoritmami klasifikácie obrázkov relatívne malé predbežné spracovanie. To znamená, že sa sieť učí filtre, ktoré boli v tradičných algoritmoch vyrobené ručne. Táto nezávislosť od predchádzajúcich znalostí a ľudského úsilia pri navrhovaní funkcií je hlavnou výhodou.
|
Okrem RNN je ďalším prirodzeným prístupom k riešeniu sekvencií s premennou dĺžkou použitie rekurzívnej konvolučnej neurónovej siete, kde sú parametre na každej úrovni zdieľané cez celú sieť. Konvolučné neurónové siete sú v zásade o niečo lepšie pre dlhé nepretržité sekvencie, ale pôvodne sa nepoužívali kvôli niekoľkým slabinám. Tie boli v roku 2017 úspešne kompenzované pomocou „attention mechanisms“.
|
||||||
|
|
||||||
CNN sú legalizované verzie viacvrstvových perceptrónov. Viacvrstvové perceptróny zvyčajne znamenajú plne spojené siete, to znamená, že každý neurón v jednej vrstve je spojený so všetkými neurónmi v nasledujúcej vrstve. Vďaka „úplnému prepojeniu“ týchto sietí sú náchylné na preplnenie údajov. Typické spôsoby regularizácie zahŕňajú pridanie určitej formy merania hmotnosti k stratovej funkcii. CNN používajú odlišný prístup k regularizácii: využívajú hierarchický vzorec v dátach a zhromažďujú zložitejšie vzory pomocou menších a jednoduchších vzorov. Z hľadiska rozsahu prepojenosti a zložitosti sú teda CNN na dolnej extrému. (Viac informácii na [5],[6] ).
|
Konvolučná neurónová sieť (CNN) je trieda hlbokých neurónových sietí, ktorá sa najčastejšie používa na analýzu vizuálnych snímok. Sú tiež známe ako umelé neurónové siete s invariantným posunom alebo s priestorovým invariantom (SIANN) na základe ich architektúry zdieľaných váh a charakteristík invariantnosti prekladu. CNN používajú v porovnaní s inými algoritmami klasifikácie obrázkov relatívne malé predbežné spracovanie. To znamená, že sa sieť učí filtre, ktoré boli v tradičných algoritmoch vyrobené ručne. Táto nezávislosť od predchádzajúcich znalostí a ľudského úsilia pri navrhovaní funkcií je hlavnou výhodou.
|
||||||
|
|
||||||
## Encoder–Decoder Approach
|
Konvolučné siete sa inšpirovali biologickými procesmi v tom, že vzorec spojenia medzi neurónmi pripomína organizáciu vizuálnej mozgovej kôry zvieraťa. Jednotlivé kortikálne neuróny (vonkajšia vrstva nervového tkaniva mozgu) reagujú na podnety iba v obmedzenej oblasti zorného poľa známej ako receptívne pole. Vnímavé polia rôznych neurónov sa čiastočne prekrývajú tak, že pokrývajú celé zorné pole.
|
||||||
|
|
||||||
Architektúra Encoder-Decoder s rekurentnými neurónovými sieťami sa stala efektívnym a štandardným prístupom pre neurálnu strojovú transláciu (NMT) a predikciu sekvencie za sekvenciou (seq2seq) všeobecne.
|
CNN používajú v porovnaní s inými algoritmami klasifikácie obrázkov relatívne málo predbežného spracovania. To znamená, že sa sieť učí filtre, ktoré boli v tradičných algoritmoch vyrobené ručne. Pri spracovaní signálu je filtrom zariadenie alebo proces, ktorý odstraňuje zo signálu niektoré nežiaduce komponenty alebo vlastnosti. Táto nezávislosť od predchádzajúcich znalostí a ľudského úsilia pri navrhovaní funkcií je hlavnou výhodou. (Viac informácii na [5],[6] ).
|
||||||
|
|
||||||
Strojový preklad je hlavnou problémovou doménou pre modely sekvenčnej transdukcie, ktorých vstup aj výstup sú sekvencie s premennou dĺžkou. Na zvládnutie tohto typu vstupov a výstupov môžeme navrhnúť architektúru s dvoma hlavnými komponentmi. Prvým komponentom je kódovač, ktorý berie ako vstup sekvenciu s premennou dĺžkou a transformuje ju do stavu s pevným tvarom. Druhým komponentom je dekodér, ktorý mapuje kódovaný stav pevného tvaru na sekvenciu s premennou dĺžkou. Toto sa nazýva architektúra dekodér-dekodér.
|
|
||||||
|
## Encoder–Decoder Approach
|
||||||
Aj keď je architektúra Encoder-Decoder efektívna, má problémy s dlhými sekvenciami textu, ktoré sa majú preložiť. Problém pramení z internej reprezentácie pevnej dĺžky, ktorá sa musí použiť na dekódovanie každého slova vo výstupnej sekvencii. Riešením je použitie attention mechanism (mechanizmu pozornosti), ktorý umožňuje modelu naučiť sa, kam má venovať pozornosť vstupnej sekvencii, pretože každé slovo výstupnej sekvencie je dekódované.
|
|
||||||
|
Architektúra Encoder-Decoder s rekurentnými neurónovými sieťami sa stala efektívnym a štandardným prístupom pre neurónový strojový preklad (NMT) a predikciu Sequence-to-sequence (seq2seq) všeobecne. Seq2seq je trénovanie modelov na prevod sekvencií z jednej domény (napr. vety v angličtine) na sekvencie v inej doméne (napr. rovnaké vety preložené do slovenčiny)
|
||||||
Kľúčovými výhodami tohto prístupu sú schopnosť trénovať jeden end-to-end model priamo na zdrojových a cieľových vetách a schopnosť zvládnuť vstupné a výstupné sekvencie textu s rôznou dĺžkou. Ako dôkaz úspechu metódy je architektúra jadrom prekladateľskej služby Google. Architektúra rekurentnej neurónovej siete Encoder-Decoder s pozornosťou je v súčasnosti najmodernejším riešením niektorých benchmarkových problémov pre strojový preklad. Táto architektúra je použitá v jadre systému Google Neural Machine Translation alebo GNMT, ktorý sa používa v ich službe Google Translate. [8]
|
|
||||||
|
Mnoho úloh strojového učenia sa dá vyjadriť ako transformácia - alebo transdukcia - vstupných sekvencií do výstupných sekvencií (napr. rozpoznávanie reči, strojový preklad, alebo prevod textu na reč. (Alex Graves, 2012)
|
||||||
**Obr 1. encoder-decoder architektúra**
|
|
||||||
|
Strojový preklad je hlavnou problémovou doménou pre modely sekvenčnej transdukcie, ktorých vstup aj výstup sú sekvencie s premennou dĺžkou. Na zvládnutie tohto typu vstupov a výstupov môžeme navrhnúť architektúru s dvoma hlavnými komponentmi. Prvým komponentom je kódovacie zariadenie, ktoré berie ako vstup sekvenciu s premennou dĺžkou a transformuje ju do stavu s pevným tvarom. Druhým komponentom je dekodér, ktorý mapuje kódovaný stav pevného tvaru na sekvenciu s premennou dĺžkou. Toto sa nazýva Encoder-Decoder architektúra.
|
||||||
|
|
||||||
## BERT
|
Aj keď je architektúra Encoder-Decoder efektívna, má problémy s dlhými sekvenciami textu, ktoré sa majú preložiť. Problém pramení z internej reprezentácie pevnej dĺžky, ktorá sa musí použiť na dekódovanie každého slova vo výstupnej sekvencii. Riešením je použitie attention mechanism (mechanizmu pozornosti), ktorý umožňuje modelu naučiť sa, kam má venovať pozornosť vstupnej sekvencii, pretože každé slovo výstupnej sekvencie je dekódované.
|
||||||
|
|
||||||
Bidirectional Encoder Representations from Transformers (BERT) je strojové školenie zamerané na techniku strojového učenia na spracovanie prirodzeného jazyka (NLP) vyvinuté spoločnosťou Google. Keď bol BERT publikovaný, dosiahol vynikajúcu výkonnosť v mnohých úlohách porozumenia prirodzenému jazyku ako napr. SQuAD (Stanford Question Answering Dataset) a SWAG (Situations With Adversarial Generations). Dôvody spoľahlivého výkonu BERT v týchto úlohách porozumenia prirodzenému jazyku ešte nie sú dobre pochopené.
|
Kľúčovými výhodami tohto prístupu sú schopnosť trénovať jeden end-to-end model priamo na zdrojových a cieľových vetách a schopnosť zvládnuť vstupné a výstupné sekvencie textu s rôznou dĺžkou. Ako dôkaz úspechu metódy je architektúra jadrom prekladateľskej služby Google. Architektúra rekurentnej neurónovej siete Encoder-Decoder s pozornosťou je v súčasnosti najmodernejším riešením niektorých benchmarkových problémov pre strojový preklad. Táto architektúra je použitá v jadre systému Google Neural Machine Translation alebo GNMT, ktorý sa používa v ich službe Google Translate. [8]
|
||||||
|
|
||||||
V súčasnosti sú vopred vytrénované jazykové modely BERT považované za dôležité pre širokú škálu úloh NLP, ako sú napríklad Natural Language Inference (NLI) a Question Answer (QA). Napriek svojmu obrovskému úspechu stále majú limity na reprezentáciu kontextových informácií v korpuse špecifickom pre danú oblasť, pretože sú trénované na všeobecnom korpuse (napr. Anglická Wikipedia). Napríklad Ubuntu Corpus, ktorý je najpoužívanejším korpusom pri výbere odpovedí, obsahuje množstvo terminológií a príručiek, ktoré sa vo všeobecnom korpuse zvyčajne nevyskytujú (napr. Apt-get, mkdir a grep). Pretože sa korpus zameriava predovšetkým na určitú doménu, existujúce diela majú obmedzenia pri porovnávaní kontextu dialógu a odozvy. Korpus konverzácií, ako napríklad Twitter a Reddits, sa navyše skladá hlavne z hovorových výrazov, ktoré sú zvyčajne gramaticky nesprávne. [1] [2]
|
|
||||||
|
||
|
||||||
## Metódy vyhodnotenia
|
|:--:|
|
||||||
|
|Obr 1. encoder-decoder architektúra|
|
||||||
Ako zistíme či je náš výstup zo systému SMT dobrý ? Na vyhodnotenie strojového prekladu bolo navrhnutých veľa rôznych metód. Zaujímavosťou je že o metódach pre hodnotenie strojového prekladu sa za v posledných rokoch píše viac ako o samotnom strojovom preklade. Vyhodnotenie človekom je vo všeobecnosti veľmi časovo a finančne náročné, pretože vyžaduje zaplatenie odborníka v daných dvoch jazykoch. Z toho dôvodu sa začali vyvíjať automatické metriky, ktoré úzko korelujú s ľudských úsudkom. Čím presnejšie tieto metriky budú tým lepšia bude naša výkonnosť v hodnotením strojového prekladu. Pri vývoji týchto metrík bolo dôležité použiť sady testovacích viet, pre ktoré už existovali ľudské preklady, napríklad z paralelného korpusu. Metódy automatického prekladu sú založené na čiastočnom zosúladení reťazcov medzi výstupným a referenčným prekladom (viz. Obrázok 1).
|
|
||||||
|
|
||||||
**Obr 2. Príklad čiastočnej zhody reťazcov používaný vo väčšine metód hodnotenia.**
|
## BERT
|
||||||
|
|
||||||
|
Bidirectional Encoder Representations from Transformers (BERT) je Transformer-based technika strojového učenia pre spracovanie prirodzeného jazyka vyvinutý spoločnosťou Google. Transformátor je model Deep Learning predstavený v roku 2017, ktorý sa používa predovšetkým v oblasti spracovania prirodzeného jazyka (NLP). Deep Learning je funkcia umelej inteligencie (AI), ktorá napodobňuje činnosť ľudského mozgu pri spracovaní údajov a vytváraní vzorcov pre použitie pri rozhodovaní. Keď bol BERT publikovaný, dosiahol vynikajúcu výkonnosť v mnohých úlohách porozumenia prirodzenému jazyku ako napr. SQuAD (Stanford Question Answering Dataset) a SWAG (Situations With Adversarial Generations). Dôvody spoľahlivého výkonu BERT v týchto úlohách porozumenia prirodzenému jazyku ešte nie sú dobre pochopené.
|
||||||
Jednou z metrík na hodnotenie je napríklad známy Levenshtein, známy tiež ako word error rate (WER), ten predstavuje počet vložení, odstránení a substitúcii potrebných na prevedenie výstupnej vety na vetu vstupnú. Táto metrika je však najmenej vhodná, pretože nerozpoznáva nové usporiadanie slov. Slovo, ktoré je správne preložené, ale na zlom mieste bude penalizované ako vymazanie (na výstupe) a vloženie (na správnom mieste). Preto je výhodnejšie použiť position-independent word error rate (PER), ktorá nepenalizuje poradie, pretože výstupné a referenčné vety považuje za neusporiadané. Za posledné roky je však najbežnejšou používanou metrikou BLEU, ktorá berie do úvahy jednoslovné zhody medzi výstupnou a referenčnou vetou ako aj zhody n-gramov. BLEU je zameraná na presnosť, čo znamená, že počet n-gramových zhôd považuje za zlomok počtu celkových n-gramov vo výstupe. Zlomok sa počíta osobitne pre každé n a berie sa geometrický priemer. Presnosť metriky BLEU je upravená tak, aby eliminovala opakovania, ktoré sa vyskytujú vo vetách.
|
|
||||||
|
BERT využíva Transformátor, attention mechanism (mechanizmus pozornosti), ktorý sa učí kontextové vzťahy medzi slovami v texte. Vo svojej základnej podobe obsahuje Transformer dva samostatné mechanizmy – encoder, ktorý číta text zo vstupu, a dekodér, ktorý vytvára predpoveď pre danú úlohu. Pretože cieľom BERT je vygenerovať jazykový model, je potrebný iba encoder mechanizmus. Na rozdiel od smerových modelov, ktoré čítajú textový vstup postupne (zľava doprava alebo sprava doľava), Transformer encoder číta celú postupnosť slov naraz. Preto sa považuje za obojsmerný, aj keď by bolo presnejšie povedať, že je nesmerový. Táto vlastnosť umožňuje modelu naučiť sa kontext slova na základe celého jeho okolia (vľavo a vpravo od slova). Vstupom je postupnosť tokenov, ktoré sa najskôr vložia do vektorov a potom sa spracujú v neurónovej sieti. Výstupom je postupnosť vektorov veľkosti H, v ktorých každý vektor zodpovedá vstupnému tokenu s rovnakým indexom.
|
||||||
Aj keď sa BLEU pokúša zachytiť povolené rozdiely v preklade, tak tento systém zachádza oveľa ďalej ako by mal. BLEU nekladie žiadne výslovné obmedzenia na hranicu, v ktorej sa vyskytujú zodpovedajúce n-gramy. Pre umožnenie variácie pri výbere slova sa preto v preklade metriky BLEU používajú viacnásobné preklady odkazov, ale taktiež kladie len veľmi málo obmedzení na to ako je možné čerpať gramové zhody z viacerých referenčných prekladov. BLEU je týmito spôsobmi obmedzené, umožňuje obrovské množstvo variácií, ďaleko nad rámec toho, čo by sa dalo považovať za prijateľnú variáciu v strojovom preklade. Ukázalo sa, že pre priemerný preklad hypotéz existuje viac ako milión možných variantov, z ktorých každý získal podobné skóre BLEU. Tvrdíme preto, že počet prekladov, ktoré majú rovnaké skóre, je taký veľký, že je nepravdepodobné, aby všetci z nich boli hodnotené ľudskými prekladateľmi rovnako kvalitne. Z toho vyplýva, že je možné dostať identické skóre po hodnotení metrikou BLEU, ktoré by ale ľudia hodnotili horšie. Je preto tiež možné dosiahnuť vyššie skóre BLEU, bez toho, aby sa v skutočnosti zlepšila samotná kvalita strojového prekladu.
|
|
||||||
|
V súčasnosti sú vopred vytrénované jazykové modely BERT považované za dôležité pre širokú škálu úloh NLP, ako sú napríklad Natural Language Inference (NLI je podtémou spracovania prirodzeného jazyka v umelej inteligencii, ktorá sa zaoberá strojovým čítaním s porozumením) a Question Answer (QA je disciplína informatiky v oblasti získavania informácií). Napriek svojmu obrovskému úspechu stále majú limity na reprezentáciu kontextových informácií v korpuse špecifickom pre danú oblasť, pretože sú trénované na všeobecnom korpuse (napr. Anglická Wikipedia). Napríklad Ubuntu Corpus, ktorý je jedným z najpoužívanejších korpusov pri výbere odpovedí, obsahuje množstvo terminológií a príručiek, ktoré sa vo všeobecnom korpuse zvyčajne nevyskytujú (napr. Apt-get, mkdir a grep). Pretože sa korpus zameriava predovšetkým na určitú doménu, existujúce diela majú obmedzenia pri porovnávaní kontextu dialógu a odozvy. Korpus konverzácií, ako napríklad Twitter a Reddits, sa navyše skladá hlavne z hovorových výrazov, ktoré sú zvyčajne gramaticky nesprávne. [1] [2]
|
||||||
Neschopnosť BLEU rozlišovať medzi náhodne generovanými variáciami prekladu naznačuje, že to v niektorých prípadoch nemusí korelovať s ľudskými úsudkami o kvalite prekladu. S pribúdajúcim počtom identického skóre klesá pravdepodobnosť, že by sa všetky z nich dali považovať za rovnako pravdepodobné. To zdôrazňuje skutočnosť, že BLEU je metrika na meranie hrubej kvality prekladu. K tomuto tvrdeniu prispieva aj niekoľko ďalších faktorov ako napríklad, že so synonymami a parafrázami sa zaobchádza iba vtedy ak sú v skupine viacerých referenčných odkazov. Dalej skóre slov sa počíta rovnako, takže v prípade chýbajúceho obsahového materiálu to neprináša žiadnu penalizáciu. Každá z týchto chýb prispieva k zvýšeniu zle preložených a nezrozumiteľných prekladov. Vzhľadom na to, že BLEU môže teoreticky priradiť rovnaké skóre prekladu dvom textom odlišnej kvality, je logické, že vyššie skóre BLEU nemusí nevyhnutne znamenať skutočne zlepšenie kvality prekladu. [9]
|
|
||||||
|
|
||||||
## Zoznam použitej literatúri
|
## Metódy vyhodnotenia
|
||||||
|
|
||||||
[1]. WANG T., LEE D., LEE CH. YANG K., OH D., LIM H.: _Domain Adaptive Training BERT for Response Selection._ [online]. [citované 01-08-2019].
|
Ako zistíme či je náš výstup zo systému SMT dobrý ? Na vyhodnotenie strojového prekladu bolo navrhnutých veľa rôznych metód. Zaujímavosťou je že o metódach pre hodnotenie strojového prekladu sa za v posledných rokoch píše viac ako o samotnom strojovom preklade. Vyhodnotenie človekom je vo všeobecnosti veľmi časovo a finančne náročné, pretože vyžaduje zaplatenie odborníka v daných dvoch jazykoch. Z toho dôvodu sa začali vyvíjať automatické metriky, ktoré úzko korelujú s ľudských úsudkom. Čím presnejšie tieto metriky budú tým lepšia bude naša výkonnosť v hodnotením strojového prekladu. Pri vývoji týchto metrík bolo dôležité použiť sady testovacích viet, pre ktoré už existovali ľudské preklady, napríklad z paralelného korpusu. Metódy automatického prekladu sú založené na čiastočnom zosúladení reťazcov medzi výstupným a referenčným prekladom (viz. Obrázok 2).
|
||||||
|
|
||||||
[2]. DEVLIN J., CHANG M., LEE K., TOUTANOVA K.: BERT: _Pre-training of Deep Bi-directional Transformers for Language Understanding._ [online]. [citované 24-05-2019].
|
||
|
||||||
|
|:--:|
|
||||||
[3]. WANG X., LU Z., TU Z., LI H., XIONG D., ZHANG M.: _Neural Machine Translation Advised by Statistical Machine Translation._ [online]. [citované 30-12-2016].
|
|Obr 2. Príklad čiastočnej zhody reťazcov používaný vo väčšine metód hodnotenia.|
|
||||||
|
|
||||||
[4]. ZHANG A., LIPTON C. Z., LI M., SMOLA J. A.: _Dive into Deep Learning._ [online]. [citované 06-11-2020].
|
|
||||||
|
Jednou z metrík na hodnotenie je napríklad známy Levenshtein, známy tiež ako word error rate (WER), ten predstavuje počet vložení, odstránení a substitúcii potrebných na prevedenie výstupnej vety na vetu vstupnú. Táto metrika je však najmenej vhodná, pretože nerozpoznáva nové usporiadanie slov. Slovo, ktoré je správne preložené, ale na zlom mieste bude penalizované ako vymazanie (na výstupe) a vloženie (na správnom mieste). Preto je výhodnejšie použiť position-independent word error rate (PER), ktorá nepenalizuje poradie, pretože výstupné a referenčné vety považuje za neusporiadané. Za posledné roky je však najbežnejšou používanou metrikou BLEU, ktorá berie do úvahy jednoslovné zhody medzi výstupnou a referenčnou vetou ako aj zhody n-gramov. BLEU je zameraná na presnosť, čo znamená, že počet n-gramových zhôd považuje za zlomok počtu celkových n-gramov vo výstupe. Zlomok sa počíta osobitne pre každé n a berie sa geometrický priemer. Presnosť metriky BLEU je upravená tak, aby eliminovala opakovania, ktoré sa vyskytujú vo vetách.
|
||||||
[5]. O´SHEA K., NASH R.: _An Introduction to Convolutional Neural Networks._ [online]. [citované 02-12-2015].
|
|
||||||
|
Aj keď sa BLEU pokúša zachytiť povolené rozdiely v preklade, tak tento systém zachádza oveľa ďalej ako by mal. BLEU nekladie žiadne výslovné obmedzenia na hranicu, v ktorej sa vyskytujú zodpovedajúce n-gramy. Pre umožnenie variácie pri výbere slova sa preto v preklade metriky BLEU používajú viacnásobné preklady odkazov, ale taktiež kladie len veľmi málo obmedzení na to ako je možné čerpať gramové zhody z viacerých referenčných prekladov. BLEU je týmito spôsobmi obmedzené, umožňuje obrovské množstvo variácií, ďaleko nad rámec toho, čo by sa dalo považovať za prijateľnú variáciu v strojovom preklade. Ukázalo sa, že pre priemerný preklad hypotéz existuje viac ako milión možných variantov, z ktorých každý získal podobné skóre BLEU. Tvrdíme preto, že počet prekladov, ktoré majú rovnaké skóre, je taký veľký, že je nepravdepodobné, aby všetci z nich boli hodnotené ľudskými prekladateľmi rovnako kvalitne. Z toho vyplýva, že je možné dostať identické skóre po hodnotení metrikou BLEU, ktoré by ale ľudia hodnotili horšie. Je preto tiež možné dosiahnuť vyššie skóre BLEU, bez toho, aby sa v skutočnosti zlepšila samotná kvalita strojového prekladu.
|
||||||
[6]. KALCHBERNNER N., GREFENSTETTE E., BLUNSOM P.: _A Convolutional Neural Network for Modelling Sentences__._ [online]. [citované 08-08-2014].
|
|
||||||
|
Neschopnosť BLEU rozlišovať medzi náhodne generovanými variáciami prekladu naznačuje, že to v niektorých prípadoch nemusí korelovať s ľudskými úsudkami o kvalite prekladu. S pribúdajúcim počtom identického skóre klesá pravdepodobnosť, že by sa všetky z nich dali považovať za rovnako pravdepodobné. To zdôrazňuje skutočnosť, že BLEU je metrika na meranie hrubej kvality prekladu. K tomuto tvrdeniu prispieva aj niekoľko ďalších faktorov ako napríklad, že so synonymami a parafrázami sa zaobchádza iba vtedy ak sú v skupine viacerých referenčných odkazov. Dalej skóre slov sa počíta rovnako, takže v prípade chýbajúceho obsahového materiálu to neprináša žiadnu penalizáciu. Každá z týchto chýb prispieva k zvýšeniu zle preložených a nezrozumiteľných prekladov. Vzhľadom na to, že BLEU môže teoreticky priradiť rovnaké skóre prekladu dvom textom odlišnej kvality, je logické, že vyššie skóre BLEU nemusí nevyhnutne znamenať skutočne zlepšenie kvality prekladu. [9]
|
||||||
[7]. ZAREMBA W., SUTSKEVER I., VINYALS O.: _Recurrent Neural Network Regularization_. [online]. [citované 19-02-2015].
|
|
||||||
|
## Zoznam použitej literatúri
|
||||||
[8]. CHO K., MERRIENBOER vB., BAHDANAU D.: _On the Properties of Neural Machine Translation: Encoder–Decoder Approaches._ [online]. [citované 07-10-2014].
|
|
||||||
|
[1]. WANG T., LEE D., LEE CH. YANG K., OH D., LIM H.: _Domain Adaptive Training BERT for Response Selection._ [online]. [citované 01-08-2019].
|
||||||
[9]. CALLISON-BURCH C., OSBORNE M., KOEHN P.: _Re-evaluating the Role of BLEU in Machine Translation Research__._ [online]. [citované 2006].
|
|
||||||
|
[2]. DEVLIN J., CHANG M., LEE K., TOUTANOVA K.: BERT: _Pre-training of Deep Bi-directional Transformers for Language Understanding._ [online]. [citované 24-05-2019].
|
||||||
|
|
||||||
|
[3]. WANG X., LU Z., TU Z., LI H., XIONG D., ZHANG M.: _Neural Machine Translation Advised by Statistical Machine Translation._ [online]. [citované 30-12-2016].
|
||||||
|
|
||||||
|
[4]. ZHANG A., LIPTON C. Z., LI M., SMOLA J. A.: _Dive into Deep Learning._ [online]. [citované 06-11-2020].
|
||||||
|
|
||||||
|
[5]. O´SHEA K., NASH R.: _An Introduction to Convolutional Neural Networks._ [online]. [citované 02-12-2015].
|
||||||
|
|
||||||
|
[6]. KALCHBERNNER N., GREFENSTETTE E., BLUNSOM P.: _A Convolutional Neural Network for Modelling Sentences__._ [online]. [citované 08-08-2014].
|
||||||
|
|
||||||
|
[7]. ZAREMBA W., SUTSKEVER I., VINYALS O.: _Recurrent Neural Network Regularization_. [online]. [citované 19-02-2015].
|
||||||
|
|
||||||
|
[8]. CHO K., MERRIENBOER vB., BAHDANAU D.: _On the Properties of Neural Machine Translation: Encoder–Decoder Approaches._ [online]. [citované 07-10-2014].
|
||||||
|
|
||||||
|
[9]. CALLISON-BURCH C., OSBORNE M., KOEHN P.: _Re-evaluating the Role of BLEU in Machine Translation Research__._ [online]. [citované 2006].
|
||||||
|
|
||||||
[10]. LOPEZ A.: _A Survey of Statistical Machine Translation._ [online]. [citované 01-04-2007].
|
[10]. LOPEZ A.: _A Survey of Statistical Machine Translation._ [online]. [citované 01-04-2007].
|
||||||
@ -11,7 +11,15 @@ taxonomy:
|
|||||||
|
|
||||||
## Diplomová práca 2021
|
## Diplomová práca 2021
|
||||||
|
|
||||||
Vytváranie komplexných korpusov pre aplikácie porozumenia prirodzeného jazyka
|
Názov: Tvorba korpusu otázok a odpovedí v slovenskom jazyku pomocou crowdsourcingu
|
||||||
|
|
||||||
|
Zadanie:
|
||||||
|
|
||||||
|
1. Vypracujte prehľad metód vytvárania jazykových zdrojov pomocou crowsdourcingu.
|
||||||
|
2. Vypracujte prehľad aktuálnych systémov pre generovanie odpovede na otázku v prirodzenom jazyku.
|
||||||
|
3. Navrhnite postup pre vytvorenie korpusu otázok a odpovedí v slovenskom jazyku.
|
||||||
|
4. Vytvorte webovú aplikáciu a pomocou nej anotujte dostatočné množstvo otázok a odpovedí.
|
||||||
|
5. Navrhnite zlepšenia procesu anotácie otázok a odpovedí.
|
||||||
|
|
||||||
Cieľom práce je príprava nástrojov a budovanie tzv. "Question Answering datasetov"
|
Cieľom práce je príprava nástrojov a budovanie tzv. "Question Answering datasetov"
|
||||||
|
|
||||||
|
|||||||
@ -10,7 +10,7 @@ taxonomy:
|
|||||||
|
|
||||||
*Rok začiatku štúdia*: 2017
|
*Rok začiatku štúdia*: 2017
|
||||||
|
|
||||||
## Bakalársky projekt 2020
|
## Bakalárska práca 2020
|
||||||
|
|
||||||
Názov: Webová aplikácia pre demonštráciu strojového prekladu
|
Názov: Webová aplikácia pre demonštráciu strojového prekladu
|
||||||
|
|
||||||
@ -19,6 +19,48 @@ Názov: Webová aplikácia pre demonštráciu strojového prekladu
|
|||||||
3. Vytvorte demonštračnú webovú aplikáciu v Javascripte pomocou ktorej je možné vyskúšať viaceré služby pre strojový preklad.
|
3. Vytvorte demonštračnú webovú aplikáciu v Javascripte pomocou ktorej je možné vyskúšať viaceré služby pre strojový preklad.
|
||||||
4. Navrhnite možné zlepšenia Vami vytvorenej aplikácie.
|
4. Navrhnite možné zlepšenia Vami vytvorenej aplikácie.
|
||||||
|
|
||||||
|
Zásobník úloh:
|
||||||
|
|
||||||
|
- Zapisať človekom urobený preklad do databázy.
|
||||||
|
- Vyrobiť deployment a zverejniť stránku s demom.
|
||||||
|
- pripraviť modul s vlastným prekladom.
|
||||||
|
- Vyhodnotiť preklad metódou BLEU
|
||||||
|
|
||||||
|
Stretnutie 13.3.
|
||||||
|
|
||||||
|
Stav:
|
||||||
|
- práca na písomnej časti (neurónový strojový preklad).
|
||||||
|
- odladená chyba axios cors na translation.tukekemt.xyz.
|
||||||
|
|
||||||
|
|
||||||
|
Úlohy:
|
||||||
|
- Písať.
|
||||||
|
|
||||||
|
|
||||||
|
Stretnutie 5.3.
|
||||||
|
|
||||||
|
Stav:
|
||||||
|
|
||||||
|
- Nastal progres v písomnej časti, pokračujte ďalej
|
||||||
|
|
||||||
|
Stretnutie 26.2.
|
||||||
|
|
||||||
|
Stav:
|
||||||
|
|
||||||
|
- Prerobený úvod práce podľa nového zadania.
|
||||||
|
- Práca na vlastnom backende (vedúci). Backend je prístupný na https://translation.tukekemt.xyz/ende/.
|
||||||
|
|
||||||
|
Úlohy:
|
||||||
|
|
||||||
|
- Pokračujte v písomnej práci.
|
||||||
|
- Backend momentálne nefunguje. Keď bude fungovať, pracujte na napojení na frontend.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## Bakalársky projekt 2020
|
||||||
|
|
||||||
|
|
||||||
Konzultácie sa budú konať osobne alebo cez [Teams](https://teams.microsoft.com/l/team/19%3aa8596a401a3842e5b91ac918a2a0afb1%40thread.tacv2/conversations?groupId=4fc0c627-d424-4587-b73a-2e47509862e9&tenantId=1c9f27ef-fee6-45f4-9a64-255a8c8e25a5) minimálne raz za dva týždne, menej ako 6 konzultácií za semester je dôvodom pre zníženie hodnotenia semester je dôvodom pre zníženie hodnotenia alebo neudelenie zápočtu. Odporúčaný čas konzultácie je piatok.
|
Konzultácie sa budú konať osobne alebo cez [Teams](https://teams.microsoft.com/l/team/19%3aa8596a401a3842e5b91ac918a2a0afb1%40thread.tacv2/conversations?groupId=4fc0c627-d424-4587-b73a-2e47509862e9&tenantId=1c9f27ef-fee6-45f4-9a64-255a8c8e25a5) minimálne raz za dva týždne, menej ako 6 konzultácií za semester je dôvodom pre zníženie hodnotenia semester je dôvodom pre zníženie hodnotenia alebo neudelenie zápočtu. Odporúčaný čas konzultácie je piatok.
|
||||||
|
|
||||||
Možné backendy:
|
Možné backendy:
|
||||||
@ -29,13 +71,6 @@ Možné backendy:
|
|||||||
- [Zdrojové kódy k REST Servru](https://github.com/OpenNMT/OpenNMT-py/blob/master/onmt/bin/server.py|
|
- [Zdrojové kódy k REST Servru](https://github.com/OpenNMT/OpenNMT-py/blob/master/onmt/bin/server.py|
|
||||||
|
|
||||||
|
|
||||||
Zásobník úloh:
|
|
||||||
|
|
||||||
- Zapisať človekom urobený preklad do databázy.
|
|
||||||
- Vyrobiť deployment a zverejniť stránku s demom.
|
|
||||||
- pripraviť modul s vlastným prekladom.
|
|
||||||
- Vyhodnotiť preklad metódou BLEU
|
|
||||||
|
|
||||||
### Poznámka vedúceho 2.2
|
### Poznámka vedúceho 2.2
|
||||||
|
|
||||||
Inštalácia OpenNMT-py na servri idoc:
|
Inštalácia OpenNMT-py na servri idoc:
|
||||||
|
|||||||
@ -3,14 +3,14 @@ title: Than Trung Thanh
|
|||||||
published: true
|
published: true
|
||||||
taxonomy:
|
taxonomy:
|
||||||
category: [bp2021]
|
category: [bp2021]
|
||||||
tag: [demo,nlp]
|
tag: [demo,nlp, named entity, ne, spacy, prodigy, anotation]
|
||||||
author: Daniel Hladek
|
author: Daniel Hladek
|
||||||
---
|
---
|
||||||
# Than Trung Thanh
|
# Than Trung Thanh
|
||||||
|
|
||||||
## Bakalársky projekt 2020
|
## Bakalársky projekt 2020
|
||||||
|
|
||||||
Rozpoznávanie pomenovaných entít v slovenskom jazyku
|
Rozpoznávanie pomenovaných entít v slovenskom jazyku pomocou nástrojov Spacy a Prodigy
|
||||||
|
|
||||||
- Tvorba korpusu a modelu pomocou nástrojov Spacy a Prodigy
|
- Tvorba korpusu a modelu pomocou nástrojov Spacy a Prodigy
|
||||||
- Práca na internom projekte [rozpoznávanie pomenovaných entít](https://git.kemt.fei.tuke.sk/KEMT/zpwiki/src/branch/master/pages/topics/named-entity).
|
- Práca na internom projekte [rozpoznávanie pomenovaných entít](https://git.kemt.fei.tuke.sk/KEMT/zpwiki/src/branch/master/pages/topics/named-entity).
|
||||||
@ -28,10 +28,23 @@ Predbežné zadanie:
|
|||||||
- Vypracujte teoretický úvod, kde vysvetlíte čo je to rozpoznávanie pomenovaných entít a akými najnovšími metódami sa robí.
|
- Vypracujte teoretický úvod, kde vysvetlíte čo je to rozpoznávanie pomenovaných entít a akými najnovšími metódami sa robí.
|
||||||
- Vysvetlite, ako pracuje klasifikátor pre rozpoznávanie pomenovaných entít v knižnici Spacy .
|
- Vysvetlite, ako pracuje klasifikátor pre rozpoznávanie pomenovaných entít v knižnici Spacy .
|
||||||
- Pomocou nástroja Prodigy anotujte dostatočné množstvo textu pre výskyt pomenovaných entít.
|
- Pomocou nástroja Prodigy anotujte dostatočné množstvo textu pre výskyt pomenovaných entít.
|
||||||
- Pomocou nástroja Spacy vytvorte a vyhodnoťte model pre rozpoznávanie pomenovaných entít v slovenčine.
|
- Pomocou nástroja Spacy vytvorte a vyhodnoťte model pre rozpoznávanie pomenovaných entít v slovenčine. Zistite, ako Vami anotované dáta zlepšili presnosť vytvoreného modelu.
|
||||||
- Zistite, ako Vami anotované dáta zlepšili presnosť vytvoreného modelu.
|
- Navrhnite spôsoby pre ďalšie zlepšenie presnosti modelu pre rozpoznávanie pomenovaných entít.
|
||||||
|
|
||||||
|
|
||||||
|
Stretnutie 8.2.2020:
|
||||||
|
|
||||||
|
Stav:
|
||||||
|
- Anotovaných 1000 anotácií (3 dni).
|
||||||
|
- Prečítané články a spracovaný rešerš na 3,5 strany.
|
||||||
|
|
||||||
|
Do ďalšieho stretnutia:
|
||||||
|
|
||||||
|
- Pracovať na zlepšení písomného prejavu.
|
||||||
|
- Nájsť odborné články z dokumentácie Spacy, ku každému napísať bibliografický odkaz a čo ste sa dozvedeli do prehľadu.
|
||||||
|
- Prepracovať rešerš kompletne - odstrániť sémantické aj gramatické chyby.
|
||||||
|
- Prečítajte si a napíšte poznámky z: Li, Jing, et al. "A survey on deep learning for named entity recognition." IEEE Transactions on Knowledge and Data Engineering (2020).
|
||||||
|
|
||||||
Stretnutie 28.1.2020:
|
Stretnutie 28.1.2020:
|
||||||
|
|
||||||
Stav:
|
Stav:
|
||||||
|
|||||||
@ -14,11 +14,52 @@ Podmienkou pre získanie zápočtu je účasť na konzultácii min. raz za 2 tý
|
|||||||
Komunikácia je možná aj cez [MS Teams](https://teams.microsoft.com/l/team/19%3aa8596a401a3842e5b91ac918a2a0afb1%40thread.tacv2/conversations?groupId=4fc0c627-d424-4587-b73a-2e47509862e9&tenantId=1c9f27ef-fee6-45f4-9a64-255a8c8e25a5).
|
Komunikácia je možná aj cez [MS Teams](https://teams.microsoft.com/l/team/19%3aa8596a401a3842e5b91ac918a2a0afb1%40thread.tacv2/conversations?groupId=4fc0c627-d424-4587-b73a-2e47509862e9&tenantId=1c9f27ef-fee6-45f4-9a64-255a8c8e25a5).
|
||||||
Konzultačné hodiny sú v piatok 9:20-14:00.
|
Konzultačné hodiny sú v piatok 9:20-14:00.
|
||||||
|
|
||||||
|
## Bakalárska práca 2020
|
||||||
|
|
||||||
|
Názov: Demonštrácia spracovania slovenského prirodzeného jazyka pomocou knižnice Spacy
|
||||||
|
|
||||||
|
Návrh na zadanie:
|
||||||
|
|
||||||
|
1. Vypracujte teoretický úvod do spracovania prirodzeného slovenského jazyka. Vysvetlite, čo to je parsing, morfologická analýza a rozpoznávanie pomenovaných entít a akými metódami sa vykonávajú.
|
||||||
|
1. Podrobne vysvetlite, ako pracuje parsing, morfologická analýza a rozpoznávanie pomenovaných entít v knižnici Spacy.
|
||||||
|
1. Vytvorte demonštračnú webovú aplikáciu pomocou ktorej je možné vyskúšať spracovanie slovenského aj anglického jazyka.
|
||||||
|
1. Navrhnite možné zlepšenia Vami vytvorenej aplikácie.
|
||||||
|
|
||||||
|
|
||||||
|
Zásobník úloh:
|
||||||
|
- Vymyslite a doplňte REST API pre služby knižnice Spacy. Cieľ je vedieť využiť Spacy pomocou curl, alebo pythonu cez HTTP na spracovane textových súborov.
|
||||||
|
- Vymyslieť ako spracovať väčšie textové súbory pomocou REST API alebo podobného?
|
||||||
|
- Urobiť deployment s demom
|
||||||
|
|
||||||
|
Stretnutie 12.3.
|
||||||
|
|
||||||
|
Stav:
|
||||||
|
|
||||||
|
- Riešenie deploymentu. V základdnom modeli chýbajú priečinky tagger a parser, je potrebné modifikovať skript pre zostavenie slovenského modelu v repozitári spacy-skmodel.
|
||||||
|
- Práca na písomnej časti
|
||||||
|
|
||||||
|
Úlohy:
|
||||||
|
|
||||||
|
- Písať.
|
||||||
|
|
||||||
|
|
||||||
|
Stretnutie 26.2.
|
||||||
|
|
||||||
|
Stav:
|
||||||
|
|
||||||
|
- Dokončená a fungujúca aplikácia
|
||||||
|
- Písomná časť je rozpracovaná vo forme útržkovitých poznámok a nadpisov sekcií.
|
||||||
|
|
||||||
|
Úlohy:
|
||||||
|
|
||||||
|
- vytvoriť súvislý text.
|
||||||
|
- V texte uviesť odkazy na odbornú literatúru.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## Bakalársky projekt 2020
|
## Bakalársky projekt 2020
|
||||||
|
|
||||||
Názov: Online demonštrácia spracovania slovenského prirodzeného jazyka
|
|
||||||
|
|
||||||
Cieľ:
|
Cieľ:
|
||||||
- Vytvoriť demonštráciu spracovania slovenského jazyka pomocou knižnice spacy
|
- Vytvoriť demonštráciu spracovania slovenského jazyka pomocou knižnice spacy
|
||||||
|
|
||||||
@ -32,16 +73,7 @@ Zásobník úloh:
|
|||||||
- Vymyslieť ako spracovať väčšie textové súbory pomocou REST API alebo podobného?
|
- Vymyslieť ako spracovať väčšie textové súbory pomocou REST API alebo podobného?
|
||||||
|
|
||||||
|
|
||||||
Návrh na zadanie:
|
Stretnutie 2.2.:
|
||||||
|
|
||||||
1. Vypracujte teoretický úvod do spracovania prirodzeného slovenského jazyka. Vysvetlite čo to je parsing, morfologická analýza a rozpoznávanie pomenovaných entít a akými metódami sa vykonávajú.
|
|
||||||
1. Podrobne vysvetlite, ako pracuje parsing, morfologická analýza a rozpoznávanie pomenovaných entít v knižnici Spacy.
|
|
||||||
1. Natrénujte a vyhodnoťte model pre spracovanie slovenského a anglického jazyka v knižnici Spacy.
|
|
||||||
1. Vytvorte demonštračnú webovú aplikáciu pomocou ktorej je možné vyskúšať natrénované modely.
|
|
||||||
1. Navrhnite možné zlepšenia Vami vytvorenej aplikácie.
|
|
||||||
|
|
||||||
|
|
||||||
Stretnutie:
|
|
||||||
|
|
||||||
- Práca na frontende
|
- Práca na frontende
|
||||||
- Dorobená slovenčina - prerobené spacy explain. Vysvetľuje tagy.
|
- Dorobená slovenčina - prerobené spacy explain. Vysvetľuje tagy.
|
||||||
|
|||||||
@ -17,9 +17,7 @@ Súvisiace stránky:
|
|||||||
- [Question Answering](/topics/question) - interný projekt
|
- [Question Answering](/topics/question) - interný projekt
|
||||||
- Matej Čarňanský (BERT)
|
- Matej Čarňanský (BERT)
|
||||||
|
|
||||||
## Bakalársky projekt 2020
|
## Bakalárska práca 2021
|
||||||
|
|
||||||
Konzultácie sa budú konakť minimálne raz za dva týždne, menej ako 6 konzultácií za semester je dôvodom pre zníženie hodnotenia alebo neudelenie zápočtu.
|
|
||||||
|
|
||||||
Téma:
|
Téma:
|
||||||
|
|
||||||
@ -32,6 +30,20 @@ Návrh na zadanie BP:
|
|||||||
- Navrhnite, vykonajte a vyhodnoťte experimenty s generovaním odpovede na otázky v prirodzenom jazyku.
|
- Navrhnite, vykonajte a vyhodnoťte experimenty s generovaním odpovede na otázky v prirodzenom jazyku.
|
||||||
- Navrhnite možné zlepšenia systému pre generovanie odpovede.
|
- Navrhnite možné zlepšenia systému pre generovanie odpovede.
|
||||||
|
|
||||||
|
|
||||||
|
Stretnutie 19.3.
|
||||||
|
|
||||||
|
Stav:
|
||||||
|
|
||||||
|
- Podarilo sa natrénovať SQUAD model pre DrQA.
|
||||||
|
- Podarilo sa spustiť skript pre vyhodnotenie.
|
||||||
|
- Webová aplikácia je funkčná.
|
||||||
|
- Písomná časť je rozporacovaná.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## Bakalársky projekt 2020
|
||||||
|
|
||||||
Zásobník úloh:
|
Zásobník úloh:
|
||||||
|
|
||||||
- Nainštalovať a natrénovať systém DrQA s databázou SquAD.
|
- Nainštalovať a natrénovať systém DrQA s databázou SquAD.
|
||||||
@ -39,6 +51,11 @@ Zásobník úloh:
|
|||||||
- Vyhodnnotte natrénovaný model.
|
- Vyhodnnotte natrénovaný model.
|
||||||
- Pripravte jednoduché demo ako webovú aplikáciu (doplňujúca úloha).
|
- Pripravte jednoduché demo ako webovú aplikáciu (doplňujúca úloha).
|
||||||
|
|
||||||
|
|
||||||
|
Konzultácie sa budú konakť minimálne raz za dva týždne, menej ako 6 konzultácií za semester je dôvodom pre zníženie hodnotenia alebo neudelenie zápočtu.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Stretnutie 2.2.2021
|
Stretnutie 2.2.2021
|
||||||
|
|
||||||
Stav:
|
Stav:
|
||||||
|
|||||||
@ -17,20 +17,79 @@ Súvisiace stránky:
|
|||||||
- [Question Answering](/topics/question) - interný projekt
|
- [Question Answering](/topics/question) - interný projekt
|
||||||
- Matej Čarňanský (BERT)
|
- Matej Čarňanský (BERT)
|
||||||
|
|
||||||
|
## Bakalárska práca 2020
|
||||||
|
|
||||||
## Bakalársky projekt 2020
|
|
||||||
|
|
||||||
Názov: Neurónové jazykové modelovanie s pomocou nástroja Fairseq
|
Názov: Neurónové jazykové modelovanie typu BERT.
|
||||||
|
|
||||||
Návrh na zadanie:
|
Návrh na zadanie:
|
||||||
|
|
||||||
1. Vypracujte prehľad metód jazykového modelovania pomoocu neurónových sietí
|
1. Vypracujte prehľad metód jazykového modelovania pomocou neurónových sietí.
|
||||||
2. Vytvorte jazykový model metódou BERT alebo podobnou metódou.
|
2. Vypracujte prehľad aplikácií modelu typu BERT a spôsoby ich vyhodnotenia.
|
||||||
3. Vyhodnotte vytvorený jazykový model a navrhnite zlepšenia.
|
3. Natrénujte jazykový model metódou BERT alebo podobnou.
|
||||||
|
4. Vyhodnoťte jazykový model a navrhnite zlepšenia presnosti.
|
||||||
|
|
||||||
Zásobník úloh:
|
Zásobník úloh:
|
||||||
|
|
||||||
- Cieľom je vedieť natrénovať BERT model a vyhodnotiť ho na zvolenej testovacej množine.
|
- Cieľom je vedieť natrénovať BERT model a vyhodnotiť ho na zvolenej testovacej množine.
|
||||||
|
- vyhodnotiť slovenský Roberta Model na pokusnej množine SK-quad.
|
||||||
|
|
||||||
|
Stretnutie 12.3.
|
||||||
|
|
||||||
|
Stav:
|
||||||
|
|
||||||
|
- Konzultácia štruktúry práce
|
||||||
|
|
||||||
|
Úlohy:
|
||||||
|
|
||||||
|
- Písať.
|
||||||
|
|
||||||
|
Stretnutie 26.2.
|
||||||
|
|
||||||
|
Stav:
|
||||||
|
|
||||||
|
- Vyriešený technický problém s architektúrou modelu podľa predpokladu.
|
||||||
|
- Urobené vyhodnotenie modelu wiki103 na CommonsenseQA.
|
||||||
|
|
||||||
|
Úlohy:
|
||||||
|
|
||||||
|
- Pokračujte v práci na textovej časti.
|
||||||
|
- Odovzdané pracovné dáta pre slovenský Roberta Model aj SK-Quad. Pokúste sa to vyhodnotiť ako neprioritnú ulohu.
|
||||||
|
|
||||||
|
|
||||||
|
Stretnutie 22.2.
|
||||||
|
|
||||||
|
Stav:
|
||||||
|
|
||||||
|
- Natrénovaný model wiki103 na stroji Quadro. Problém sa vyriešil vypnutím GPU pri trénovaní,
|
||||||
|
- Vznikol problém pri vypracovaní https://github.com/pytorch/fairseq/blob/master/examples/roberta/commonsense_qa/README.md - Architecture mismatch. Možné riešenie - iný prepínač `-arch` pri dotrénovaní. tak aby sedel s predtrénovaním.
|
||||||
|
|
||||||
|
Úlohy:
|
||||||
|
|
||||||
|
- skúsiť vyhodnotenie Wiki 103 na Commonsense
|
||||||
|
- Pokračujte v práci na textovej časti - vytvorte plynulý text.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## Bakalársky projekt 2020
|
||||||
|
|
||||||
|
Stretnutie 12.2.
|
||||||
|
|
||||||
|
Stav:
|
||||||
|
|
||||||
|
- Pokúšame sa vytvoriť hodnotenie pomcou množiny CommonSenseQA
|
||||||
|
- Problém pri trénovaní na Wiki103 na stroji Quadra, (vyzerá to ako deadlock)
|
||||||
|
- Máme k dispozícii ROBERTA model natrénovaný na veľkej množine slovenských dát.
|
||||||
|
|
||||||
|
Do budúceho stretnutia:
|
||||||
|
|
||||||
|
- Problém sa možno dá obísť skopírovaním modelu zo stroja Tesla.
|
||||||
|
- na kopírovanie použite príkaz `scp -r user@server:zdrojovyadresar cielovyadresar`.
|
||||||
|
- pokračovať vo vyhodnotení pomocou CommonSenseQA.
|
||||||
|
- skúste vyhodnotiť aj slovenský model. Ako?
|
||||||
|
- pracujte na súvislom texte bakalárskej práce.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Virtuálne stretnutie 18.12.2020
|
Virtuálne stretnutie 18.12.2020
|
||||||
|
|
||||||
|
|||||||
@ -11,21 +11,70 @@ taxonomy:
|
|||||||
|
|
||||||
Rok začiatku štúdia: 2018
|
Rok začiatku štúdia: 2018
|
||||||
|
|
||||||
## Bakalársky projekt 2020
|
|
||||||
|
|
||||||
Pokusný klaster Raspberry Pi pre výuku klaudových technológií
|
## Bakalárska práca 2020
|
||||||
|
|
||||||
1. Vypracujte teoretický úvod do technológie Kubernetes
|
|
||||||
2. Vytvorte pokusný klaster pomocou viacerých modulov Raspberry Pi a nainštalujte na neho Kubernmetes
|
Pokusný Kubernetes klaster použitím Raspberry Pi pre výuku klaudových technológií
|
||||||
3. Vypracujte podrobný návod na zostavenie hardvérovej časti
|
|
||||||
|
1. Vypracujte teoretický úvod do technológie Kubernetes.
|
||||||
|
2. Vytvorte pokusný klaster pomocou viacerých modulov Raspberry Pi a nainštalujte na neho Kubernetes.
|
||||||
|
3. Vypracujte podrobný návod na zostavenie hardvérovej časti klastra.
|
||||||
4. Vypracujte podrobný návod na inštaláciu softvéru - operačného systému a súčastí Kubernetes.
|
4. Vypracujte podrobný návod na inštaláciu softvéru - operačného systému a súčastí Kubernetes.
|
||||||
|
|
||||||
Cieľ projektu je vytvoriť domáci lacný klaster pre výuku cloudových technológií.
|
Cieľ projektu je vytvoriť domáci lacný klaster pre výuku cloudových technológií.
|
||||||
|
|
||||||
|
|
||||||
Zásobník úloh:
|
Zásobník úloh:
|
||||||
|
|
||||||
- Aktivujte si technológiu WSL2 a Docker Desktop ak používate Windows.
|
- Aktivujte si technológiu WSL2 a Docker Desktop ak používate Windows.
|
||||||
|
- Cieľ je vedieť dať klaster rýchlo do východiskového stavu - klvalitný návod a skritpty ktoré sa dajú opakovať.
|
||||||
|
|
||||||
|
Stretnutie 19.3.:
|
||||||
|
|
||||||
|
Stav:
|
||||||
|
|
||||||
|
- doplnený a primontovaný switch, skrátené káble.
|
||||||
|
- ručne priradené IP adresy (do súboru /etc/network-interfaces).
|
||||||
|
- práca na písomnej časti.
|
||||||
|
|
||||||
|
Úlohy:
|
||||||
|
|
||||||
|
- vyskúšajte prácu s K8s podľa návodov z cvičení Základov klaudových technológií.
|
||||||
|
- Doplniť register obrazov kontajnera - pripraviť deployment.
|
||||||
|
- Pripraviť deployment pre ingress. (nginx ingress controller).
|
||||||
|
- píšte prácu.
|
||||||
|
|
||||||
|
Stretnutie 5.3.2021:
|
||||||
|
|
||||||
|
Stav:
|
||||||
|
|
||||||
|
- Hardware je zmontovaný - ide chladenie, switch, napájanie, kabeláž aj uzly.
|
||||||
|
- Zo software: podarilo sa nabootovať a nainštalovať K8s. - MicroK8s a Ubuntu 20.04 ARM 64
|
||||||
|
|
||||||
|
Úlohy:
|
||||||
|
|
||||||
|
- Zabezpečiť aby klaster mal stabilné IP adresy. Statické IP adresy (zakódovať do obrazu?) Alebo použiť dynamické IP adresy - dhcp? bootovanie zo siete?
|
||||||
|
- Doplniť register obrazov kontajnera.
|
||||||
|
- Možno primontovať switch na klaster?
|
||||||
|
- Začať pracovať na písomnej časti.
|
||||||
|
|
||||||
|
|
||||||
|
Stretnutie 19.2.
|
||||||
|
|
||||||
|
Stav:
|
||||||
|
|
||||||
|
- Zmontovaný klaster, ale nie je kompletný. Zostavený cluster case, karty a dosky.
|
||||||
|
- Vyskytla sa chyba po zapojení micro HDMI kábla (čierna obrazovka), bliká červená LED na doske.
|
||||||
|
|
||||||
|
Do ďalšieho stretnutia:
|
||||||
|
|
||||||
|
- Pokročiť so zostavením HW. Vymyslieť sieťovú kabeláž, primontovanie zdroja, primontovanie switcha.
|
||||||
|
- Pokračujte v práci na písomnej časti.
|
||||||
|
- Skúste na zostavenom klastri rozbehať Kubernetes.
|
||||||
|
- Pripraviť postup na vytvorenie obrazu operačného systému. Napísať skript pre inštaláciu baličkov a programov na čístý Raspbery PI OS. Vymyslieť skript na zostavenie nového obrazu flash karty.
|
||||||
|
|
||||||
|
|
||||||
|
## Bakalársky projekt 2020
|
||||||
|
|
||||||
Stretnutie 27.11.
|
Stretnutie 27.11.
|
||||||
|
|
||||||
|
|||||||
37
pages/students/2019/michal_stromko/README.md
Normal file
37
pages/students/2019/michal_stromko/README.md
Normal file
@ -0,0 +1,37 @@
|
|||||||
|
---
|
||||||
|
title: Michal Stromko
|
||||||
|
---
|
||||||
|
|
||||||
|
rok začiatku štúdia: 2019
|
||||||
|
|
||||||
|
## Vedecký projekt 2021
|
||||||
|
|
||||||
|
Klaudové služby pre získavanie informácií
|
||||||
|
|
||||||
|
Cieľom projektu je zistiť ako fungujú klaudové služby pre umelú inteligenciu a ako fungujú webové vyhľadávače.
|
||||||
|
|
||||||
|
Úlohy:
|
||||||
|
|
||||||
|
- Zistite čo je to získavanie informácií.
|
||||||
|
- Oboznámte sa s Azure Cognitive Search a získajte prístup k službe. Pre prihlásenie môžete použiť Váše študentské prihlasovacie údaje.
|
||||||
|
- Vypracujte minimálne jeden tutoriál pre prácu s Azure Cognitive Search.
|
||||||
|
- Vypracujte krátky report na 2 strany kde napíšete čo ste robili a čo ste sa dozvedeli.
|
||||||
|
|
||||||
|
Zásobník úloh:
|
||||||
|
|
||||||
|
- Vytvorte index a vyhľadávanie na ZP Wiki.
|
||||||
|
- Napíšte tutoriál o tom ako ste to dokázali.
|
||||||
|
|
||||||
|
Stretnutie 19.3
|
||||||
|
|
||||||
|
Stav:
|
||||||
|
|
||||||
|
- Vytvorený prístup na Azure Portal
|
||||||
|
|
||||||
|
Úlohy:
|
||||||
|
|
||||||
|
- Vypracujte minimálne jeden tutoriál pre prácu s Azure Cognitive Search.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
33
pages/students/2019/samuel_horani/README.md
Normal file
33
pages/students/2019/samuel_horani/README.md
Normal file
@ -0,0 +1,33 @@
|
|||||||
|
---
|
||||||
|
title: Samuel Horáni
|
||||||
|
---
|
||||||
|
|
||||||
|
rok začiatku štúdia: 2019
|
||||||
|
|
||||||
|
## Vedecký projekt 2021
|
||||||
|
|
||||||
|
Dialógový systém pomocou RASA framework
|
||||||
|
|
||||||
|
Cieľom projektu je naučiť sa niečo o dialógových systémoch a oboznámiť sa so základnými nástrojmi.
|
||||||
|
|
||||||
|
- Nainštalujte a oboznámte sa s RASA frameworkom. Pri inštalácii využite systém Anaconda.
|
||||||
|
- Vyberte a prejdite najmenej jeden tutoriál pre prácu s RASA frameworkom.
|
||||||
|
- Napíšte krátky report na 2 strany kde napíšete čo ste urobili a čo ste sa dozvedeli.
|
||||||
|
|
||||||
|
Stretnutie 19.3.2020
|
||||||
|
|
||||||
|
Zásobník úloh:
|
||||||
|
|
||||||
|
- Doplniť podporu slovenčiny do fr. RASA
|
||||||
|
|
||||||
|
|
||||||
|
Stav:
|
||||||
|
|
||||||
|
- Je nainštalovaný fr. RASA pomcou Anaconda
|
||||||
|
- Je vytvorený základný jazykový model - v anglickom jazyku.
|
||||||
|
- Prezretý video kanál s [RASA tutoriálom](https://www.youtube.com/watch?v=rlAQWbhwqLA&list=PL75e0qA87dlHQny7z43NduZHPo6qd-cRc)
|
||||||
|
|
||||||
|
Úlohy:
|
||||||
|
|
||||||
|
- Skúsiť vytvoriť agenta ktorý komunikuje po slovensky. Najprv by sa preložili trénovacie príklady.
|
||||||
|
- Zistiť ako doplniť podporu slovenčiny do RASA. Komponenty ktoré máme k dispozícii sú: spacy model, fastext a glove word embedding model, BERT model (fresh and secret).
|
||||||
@ -1,23 +1,69 @@
|
|||||||
---
|
---
|
||||||
title: Otvorené projekty
|
title: Otvorené projekty
|
||||||
|
published: true
|
||||||
|
taxonomy:
|
||||||
|
category: [info]
|
||||||
|
tag: [nn,nlp]
|
||||||
|
author: Daniel Hladek
|
||||||
---
|
---
|
||||||
|
# Otvorené témy záverečných prác
|
||||||
|
|
||||||
Strojový preklad slovenského jazyka
|
Daniel Hládek
|
||||||
- Zoberte existjúci systém pre strojový preklad
|
|
||||||
- Pripravte existujúci paralelný korpus pre trénovanie
|
|
||||||
|
## Bakalárske práce
|
||||||
|
|
||||||
|
Naučíte sa:
|
||||||
|
|
||||||
|
- niečo o spracovaní prirodzeného jazyka
|
||||||
|
- vytvárať webové aplikácie
|
||||||
|
- pracovať s nástrojmi v jazyku Python
|
||||||
|
- prekonávať technické problémy
|
||||||
|
|
||||||
|
Požiadavky:
|
||||||
|
|
||||||
|
- chcieť sa naučiť niečo nové
|
||||||
|
|
||||||
|
### Demonštračný systém pre generovanie odpovede na otázku v prirodzenom jazyku
|
||||||
|
|
||||||
|
- Natrénujte existujúci systém pre generovanie odpovede na otázku v prorodzdenom jazyku.
|
||||||
|
- Vytvorte demonštračnú webovú aplikáciu.
|
||||||
|
|
||||||
|
### Strojový preklad slovenského jazyka
|
||||||
|
|
||||||
|
- Zoberte existjúci systém pre strojový preklad.
|
||||||
|
- Pripravte existujúci paralelný korpus pre trénovanie.
|
||||||
- Vytvorte model pre strojový preklad slovenského jazyka.
|
- Vytvorte model pre strojový preklad slovenského jazyka.
|
||||||
|
|
||||||
Rozpoznávanie pomenovaných entít:
|
### Rozpoznávanie pomenovaných entít v slovenskom jazyku
|
||||||
- Zlepšite model pre rozpoznávanie pomenovaných entít
|
|
||||||
|
|
||||||
Morfologická analýza s podporou predtrénovania
|
- Zlepšite model pre rozpoznávanie pomenovaných entít
|
||||||
- Zoberte existujúci model pre morfologickú anlaýzu slovenského jazyka vyhodnotte ho
|
- Anotujte korpus, navrhnite lepší klasifikátor.
|
||||||
- Použite BERT model na natrénovanie morfologickej anotácie a pporovnajte presnosť so základným modelom.
|
|
||||||
|
### Vyhľadávač na slovenskom internete
|
||||||
|
|
||||||
Vyhľadávač na slovenskom internete
|
|
||||||
- Vytvorte index pre vyhľadávanie v databáze slovenských stránok (Cassandra, Elasticseaech).
|
- Vytvorte index pre vyhľadávanie v databáze slovenských stránok (Cassandra, Elasticseaech).
|
||||||
- Vytvorte webové rozhranie k vyhľadávaču
|
- Vytvorte webové rozhranie k vyhľadávaču
|
||||||
|
|
||||||
|
## Diplomové práce
|
||||||
|
|
||||||
|
Naučíte sa:
|
||||||
|
|
||||||
|
- Niečo viac o neurónových sieťach.
|
||||||
|
- Vytvárať jednoduché programy na úpravu dát.
|
||||||
|
- Zapojiť sa do reálneho výskumu.
|
||||||
|
|
||||||
|
### Morfologická analýza s podporou predtrénovania
|
||||||
|
|
||||||
|
- Zoberte existujúci model pre morfologickú analýzu slovenského jazyka vyhodnotte ho
|
||||||
|
- Použite BERT model na natrénovanie morfologickej anotácie a porovnajte presnosť so základným modelom.
|
||||||
|
|
||||||
|
### Slovné jednotky v predspracovaní pre strojový preklad
|
||||||
|
|
||||||
|
- Natrénujte systém pre strojový preklad
|
||||||
|
- Vytvorte niekoľko modelov pre rozdelenie slov na menšie jednotky v slovenskom jazyku. Pre každý model rozdelenia slov natrénujte systém pre strojový preklad.
|
||||||
|
- Porovnajte výsledky strojového prekladu s rôznymi rozdeleniami slov.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@ -2,7 +2,7 @@
|
|||||||
title: Anotácia textových dát
|
title: Anotácia textových dát
|
||||||
published: true
|
published: true
|
||||||
taxonomy:
|
taxonomy:
|
||||||
category: [project]
|
category: [info]
|
||||||
tag: [annotation,ner,question-answer,nlp]
|
tag: [annotation,ner,question-answer,nlp]
|
||||||
author: Daniel Hladek
|
author: Daniel Hladek
|
||||||
---
|
---
|
||||||
|
|||||||
@ -64,31 +64,52 @@ Najprv sa Vám zobrazí krátky článok. Vašou úlohou bude prečítať si č
|
|||||||
4. Ten istý článok sa Vám zobrazí 5 krát, vymyslite k nemu 5 rôznych otázok.
|
4. Ten istý článok sa Vám zobrazí 5 krát, vymyslite k nemu 5 rôznych otázok.
|
||||||
5. Ak sa Vám zobrazí hlasenie "No tasks available", skúste obnoviť stránku.
|
5. Ak sa Vám zobrazí hlasenie "No tasks available", skúste obnoviť stránku.
|
||||||
|
|
||||||
Aby bola anotácia platná:
|
|
||||||
|
|
||||||
- Otázka musí byť jednoznačná.
|
|
||||||
- Odpoveď sa musí nachádzať v článku.
|
|
||||||
|
|
||||||
Ak je zobrazený text nevhodný, tak ho zamietnite. Nevhodný text:
|
|
||||||
|
|
||||||
- Príliš krátky na 5 otázok.
|
|
||||||
- Obsahuje chyby formátovania.
|
|
||||||
- Obsahuje príliš veľa zoznamov.
|
|
||||||
- Obsahuje málo súvislého textu
|
|
||||||
- Obsahuje veľa skratkovitých informácií.
|
|
||||||
- Obsahuje príliš málo faktov.
|
|
||||||
|
|
||||||
## Začnite anotovať
|
## Začnite anotovať
|
||||||
|
|
||||||
Do formulára napíšte Váš e-mail aby bolo možné rozpoznať, kto vykonal anotáciu.
|
Do formulára napíšte Váš e-mail aby bolo možné rozpoznať, kto vykonal anotáciu.
|
||||||
|
|
||||||
|
|
||||||
{% include "forms/form.html.twig" with { form: forms('question1') } %}
|
{% include "forms/form.html.twig" with { form: forms('question1') } %}
|
||||||
|
|
||||||
Pozrite sa koľko ste anotovali. Súčet sa synchronizuje raz za hodinu:
|
Pozrite sa koľko ste anotovali. Súčet sa synchronizuje raz za hodinu:
|
||||||
|
|
||||||
{% include "forms/form.html.twig" with { form: forms('questionapp') } %}
|
{% include "forms/form.html.twig" with { form: forms('questionapp') } %}
|
||||||
|
|
||||||
|
## Vyradenie nevhodných textov
|
||||||
|
|
||||||
|
Ak je zobrazený text nevhodný, tak ho zamietnite. Nevhodný text:
|
||||||
|
|
||||||
|
- Obsahuje príliš málo faktov na to aby ste napísali 5 otázok.
|
||||||
|
- Obsahuje chyby formátovania.
|
||||||
|
- Obsahuje príliš veľa zoznamov.
|
||||||
|
- Obsahuje málo súvislého textu.
|
||||||
|
- Text je príliš dlhý.
|
||||||
|
- Ak sa neviete rozhodnúť, radšej text zamietnite aby ste nestrácali čas.
|
||||||
|
- Text zamietnite aj v prípade, že sa vám k nemu nezobrazí 1. otázka.
|
||||||
|
|
||||||
|
## Vyznačovanie odpovede
|
||||||
|
|
||||||
|
Odpoveď na otázku musí byť jednoliata časť paragrafu. Odpoveď nemôže byť viacero rôznych častí toho istého odseku.
|
||||||
|
V prípade, že vyznačíte viac častí jednej odpovede tak sa výsledná odpoveď počíta od začiatku prvej časti po koniec poslednej časti.
|
||||||
|
Ak Vám používateľské rozhranie nedovoľuje vyznačiť celú odpoveď, tak stačí vyznačiť začiatočné a konečné slovo odpovede.
|
||||||
|
|
||||||
|
## Platné a neplatné anotácie
|
||||||
|
|
||||||
|
Do celkového počtu Vami vykonaných anotácií sa nebudú počítať anotácie:
|
||||||
|
|
||||||
|
- ktoré ste vyradili z dôvodu nevhodného textu,
|
||||||
|
- kde ste zabudli napísať otázku,
|
||||||
|
- kde je otázka príliš krátka (menej ako 3 slová),
|
||||||
|
- kde nie je vyznačená žiadna odpoveď.
|
||||||
|
|
||||||
|
Snažte sa, aby bola anotácia platná aj z významového hľadiska:
|
||||||
|
|
||||||
|
- Odpoveď sa musí nachádzať v článku.
|
||||||
|
- Otázka musí byť jednoznačná. Jednoznačná otázka je otázka ktorú musíte položiť, aby ste dostali vyznačenú odpoveď.
|
||||||
|
|
||||||
|
Príklad na nejednoznačnú otázku:
|
||||||
|
|
||||||
|
- Kto sa narodil v roku 1982? (veľa rôznych ľudí).
|
||||||
|
- Kto sa umiestnil na druhom mieste na olympiáde? (nie je jasné na ktorej olymiáde a v ktorej disciplíne).
|
||||||
|
|
||||||
## Príklad na anotáciu otázok
|
## Príklad na anotáciu otázok
|
||||||
|
|
||||||
@ -105,4 +126,3 @@ Príklad na nesprávu otázku:
|
|||||||
2. Čo sa deje v mŕtvych bunkách? - otázka nie je jednoznačná, presná odpoveď sa v článku nenachádza.
|
2. Čo sa deje v mŕtvych bunkách? - otázka nie je jednoznačná, presná odpoveď sa v článku nenachádza.
|
||||||
3. Čo je normálny fyziologický proces? - odpoveď sa v článku nenachádza.
|
3. Čo je normálny fyziologický proces? - odpoveď sa v článku nenachádza.
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@ -2,7 +2,7 @@
|
|||||||
title: Prepis postupností
|
title: Prepis postupností
|
||||||
published: true
|
published: true
|
||||||
taxonomy:
|
taxonomy:
|
||||||
category: [project]
|
category: [info]
|
||||||
tag: [nn,nlp]
|
tag: [nn,nlp]
|
||||||
author: Daniel Hladek
|
author: Daniel Hladek
|
||||||
---
|
---
|
||||||
|
|||||||
Loading…
Reference in New Issue
Block a user