## Úvod Neurónový strojový preklad (NMT) je prístup k strojovému prekladu, ktorý využíva umelú neurónovú sieť na predpovedanie pravdepodobnosti postupnosti slov, typicky modelovaním celých viet v jednom integrovanom modeli. NMT nie je drastickým krokom nad rámec toho, čo sa tradične robí v štatistickom strojovom preklade (SMT). Štruktúra modelov je jednoduchšia ako frázové modely. Neexistuje žiadny samostatný jazykový model, prekladový model a model zmeny poradia, ale iba jeden sekvenčný model, ktorý predpovedá jedno slovo po druhom. Táto predikcia postupnosti je však podmienená celou zdrojovou vetou a celou už vyprodukovanou cieľovou sekvenciou. ## Neurónová sieť Neurónovú sieť tvoria neuróny, ktoré sú medzi sebou poprepájané. Všeobecne môžeme poprepájať ľubovoľný počet neurónov, pričom okrem pôvodných vstupov môžu byť za vstupy brané aj výstupy iných neurónov. Počet neurónov a ich vzájomné poprepájanie v sieti určuje tzv. architektúru (topológiu) neurónovej siete. Neurónová sieť sa v čase vyvíja, preto je potrebné celkovú dynamiku neurónovej siete rozdeliť do troch dynamík a potom uvažovať tri režimy práce siete: organizačná (zmena topológie), aktívna (zmena stavu) a adaptívna (zmena konfigurácie). Jednotlivé dynamiky neurónovej siete sú obvykle zadané počiatočným stavom a matematickou rovnicou, resp. pravidlom, ktoré určuje vývoj príslušnej charakteristiky sieti v čase. Synaptické váhy patria medzi dôležité časti Neurónovej siete. Tieto váhy ovplyvňujú celú sieť tým, že ovplyvňujú vstupy do neurónov a tým aj ich stavy. Synaptické váhy medzi neurónmi i, j označujeme wi,j. Najdôležitejším momentom pri činnosti Neurónovej siete je práve zmena váh delta wi,j. Vo všeobecnosti ich rozdeľujeme na kladné (excitačné) a záporné (inhibičné). Neurón je základným prvkom Neurónovej siete. Rozdiel medzi umelým a ľudským je v tom, že v súčasnosti je možné vytvoriť oveľa rýchlejší neurón, ako ľudský. Avšak čo sa týka počtu neurónov, ľudský mozog sa skladá z 10 na 11 až 10 na 14 neurónov a každý neurón má 10 na 3 až 10 na 4 neurónových spojení. V súčasnej dobe nie je možné nasimulovať v rámci jednej Neurónovej siete také množstvo neurónov. V tomto ohľade je ľudský mozog podstatne silnejší oproti nasimulovanej Neurónovej siete. [3] |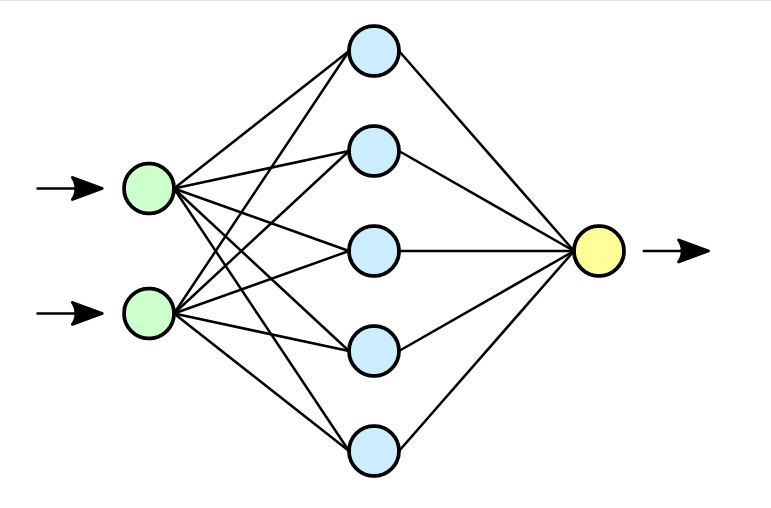| |:--:| |Obr 1. základné zobrazenie Neurónovej siete| Činnosť Neurónových sieti rozdeľujeme na : - Fáza učenia – v tejto fáze sa znalosti ukladajú do synaptických váh neurónovej siete, ktoré sa menia podľa stanovených pravidiel počas procesu učenia. V prípade neurónových sieti môžeme pojem učenie chápať ako adaptáciu neurónových sieti, teda zbieranie a uchovávanie poznatkov. - Fáza života – dochádza ku kontrole a využitiu nadobudnutých poznatkov na riešenie určitého problému (napr. transformáciu signálov, problémy riadenia procesov, aproximáciu funkcií, klasifikácia do tried a podobne). V tejto fáze sa už nemenia synaptické váhy. Neurónová sieť by vo všeobecnosti mala mať pravidelnú štruktúru pre ľahší popis a analýzu. Viacvrstvová štruktúra patrí k pomerne dobre preskúmaným štruktúram Neurónovej siete a skladá sa z : - Vstupná vrstva (angl. Input layer) – na vstup prichádzajú len vzorky z vonkajšieho sveta a výstupy posiela k ďalším neurónom - Skrytá vrstva (angl. Hidden layer) – vstupom sú neuróny z ostatných neurónov z vonkajšieho sveta (pomocou prahového prepojenia) a výstupy posiela opäť ďalším neurónom - Výstupná vrstva (angl. Output layer) – prijíma vstupy z iných neurónov a výstupy posiela do vonkajšieho prostredia Reprezentatívna vzorka je jedným zo základných pojmov Neurónových sieti. Jedná sa o usporiadanú množinu usporiadaných dvojíc, pričom ku každému vstupu je priradený vyhovujúci výstup. Poznáme dva typy reprezentatívnych vzoriek : - Trénovaciu vzorku – využíva sa pri fáze učenia (pri tejto vzorke je dôležité vybrať tú najvhodnejšiu a najkvalitnejšiu, pretože získané poznatky sa ukladajú učením do synaptických váh neurónovej siete) - Testovacia vzorka – používa sa vo fáze života Topológiu Neurónových sieti rozdeľujeme na : - Dopredné Neurónové siete (angl. feed-forward neural network), ktoré sa ďalej delia na kontrolované a nekontrolované učenie, v tejto topológií je signál šírený iba jedným smerom. U dopredných sietí neexistujú spojenia medzi neurónmi tej istej vrstvy, ani medzi neurónmi vzdialených vrstiev. |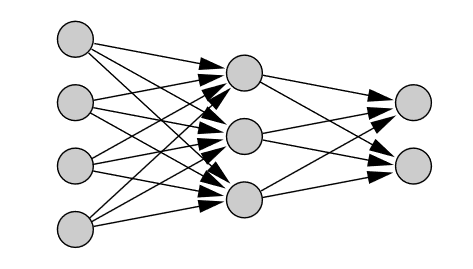| |:--:| |Obr 2. Dopredná Neurónová sieť| - Rekurentné Neurónové siete (angl. recurrent neural network), ktoré sa ďalej delia na kontrolované a nekontrolované učenie, signál sa šíry obojsmerne (neuróny sa môžu správať ako vstupné aj výstupné). [3] |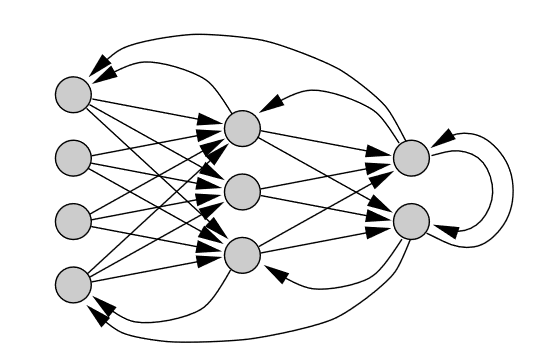| |:--:| |Obr 3. Rekurentná Neurónová sieť| **Exploding and vanishing gradient problems** V strojovom učení sa s problémom miznúceho gradientu stretávame pri trénovaní umelých neurónových sietí metódami učenia založenými na gradiente a spätnou propagáciou. V takýchto metódach dostáva každá z váh neurónovej siete aktualizáciu úmernú čiastočnej derivácii chybovej funkcie vzhľadom na aktuálnu váhu v každej iterácii trénovania. Problém je v tom, že v niektorých prípadoch bude gradient zbytočne malý, čo účinne zabráni tomu, aby váha zmenila svoju hodnotu. V najhoršom prípade to môže úplne zabrániť neurónovej sieti v ďalšom trénovaní. Ako jeden príklad príčiny problému majú tradičné aktivačné funkcie, ako je hyperbolická tangenciálna funkcia, gradienty v rozsahu (0, 1) a spätné šírenie počíta gradienty podľa pravidla reťazca. To má za následok znásobenie n týchto malých čísel na výpočet gradientov prvých vrstiev v sieti n-vrstiev, čo znamená, že gradient (chybový signál) exponenciálne klesá s n, zatiaľ čo prvé vrstvy trénujú veľmi pomaly. Ak sa použijú aktivačné funkcie, ktorých deriváty môžu nadobúdať väčšie hodnoty, riskujeme, že narazíme na súvisiaci problém s explodujúcim gradientom. Problém s explodujúcim gradientom je problém, ktorý sa môže vyskytnúť pri trénovaní umelých neurónových sietí pomocou gradientného klesania spätným šírením. Problém s explodujúcim gradientom je možné vyriešiť prepracovaním sieťového modelu, použitím usmernenej lineárnej aktivácie, využitím sietí s LSTM, orezaním gradientu a regularizáciou váh. Ďalším riešením problému s explodujúcim gradientom je zabrániť tomu, aby sa gradienty zmenili na 0, a to pomocou procesu známeho ako orezávanie gradientov, ktorý kladie na každý gradient vopred definovanú hranicu. Orezávanie prechodov zaisťuje, že prechody budú smerovať rovnakým smerom, ale s kratšími dĺžkami. [2] **Neurónový preklad** Neurónový strojový preklad vo všeobecnosti zahŕňa všetky typy strojového prekladu, kde sa na predpovedanie postupnosti čísel používa umelá neurónová sieť. V prípade prekladu je každé slovo vo vstupnej vete zakódované na číslo, ktoré neurónová sieť prepošle do výslednej postupnosti čísel predstavujúcich preloženú cieľovú vetu. Prekladový model následne funguje prostredníctvom zložitého matematického vzorca (reprezentovaného ako neurónová sieť). Tento vzorec prijíma reťazec čísel ako vstupy a výstupy výsledného reťazca čísel. Parametre tejto neurónovej siete sú vytvárané a vylepšované trénovaním siete s miliónmi vetných párov. Každý takýto pár viet tak mierne upravuje a vylepšuje neurónovú sieť, keď prechádza každým vetným párom pomocou algoritmu nazývaným spätné šírenie. [3] **Systém neurónového strojového prekladu spoločnosti Google** Neurónový strojový preklad (angl. NMT - neural machine translation) používa end-to-end učenie pre strojový preklad, ktorého cieľom je prekonať slabé stránky konvenčných frázových systémov. End-to-end učenie je typ Deep Learningu, v ktorom sú všetky parametre trénované spoločne, a nie krok za krokom. Bohužiaľ systémy NMT výpočtovo náročné počas trénovania ako aj pri samotnom preklade (je to kvôli ochrane napr. pri vysokom množstve veľkých súborov a veľkých modelov). Niekoľko autorov tiež uviedlo (odkaz na [1]), že systémom NMT chýba robustnosť, najmä keď vstupné vety obsahujú zriedkavé, alebo zastaralé slová. Tieto problémy bránili používaniu NMT v praktických nasadeniach a službách, kde je nevyhnutná presnosť aj rýchlosť. Spoločnosť Google preto predstavila GNMT (google´s neural machine translation) systém , ktorý sa pokúša vyriešiť mnohé z týchto problémov. Tento model sa skladá z hlbokej siete Long Short-Term Memory (LSTM) s 8 kódovacími a 8 dekódovacími vrstvami, ktoré využívajú zvyškové spojenia, ako aj pozorovacie spojenia zo siete dekodéra ku kódovaciemu zariadeniu. Aby sa zlepšila paralelnosť a tým pádom skrátil čas potrebný na trénovanie, tento mechanizmus pozornosti spája spodnú vrstvu dekodéra s hornou vrstvou kódovacieho zariadenia. Na urýchlenie konečnej rýchlosti prekladu používame pri odvodzovacích výpočtoch aritmetiku s nízkou presnosťou. Aby sa vylepšila práca so zriedkavými slovami, slová sa delia na vstup aj výstup na obmedzenú množinu bežných podslovných jednotiek („wordpieces“). Táto metóda poskytuje dobrú rovnováhu medzi flexibilitou modelov oddelených znakom a účinnosťou modelov oddelených slovom, prirodzene zvláda preklady zriedkavých slov a v konečnom dôsledku zvyšuje celkovú presnosť systému. Štatistický strojový preklad (SMT - statistical machine translation) je po celé desaťročia dominantnou paradigmou strojového prekladu. Implementáciami SMT sú vo všeobecnosti systémy založené na frázach (PBMT - phrase-based machine translation), ktoré prekladajú postupnosti slov alebo frázy, kde sa môžu dĺžky líšiť. Ešte pred príchodom priameho neurónového strojového prekladu sa neurónové siete s určitým úspechom používali ako súčasť systémov SMT. Možno jeden z najpozoruhodnejších pokusov spočíval v použití spoločného jazykového modelu na osvojenie frázových reprezentácií, čo prinieslo pozoruhodné zlepšenie v kombinácii s prekladom založeným na frázach. Tento prístup však vo svojej podstate stále využíva frázové prekladové systémy, a preto dedí ich nedostatky. O koncepciu end-to-end učenia pre strojový preklad sa v minulosti pokúšali s obmedzeným úspechom. Po mnohých seminárnych prácach v tejto oblasti sa kvalita prekladu NMT priblížila k úrovni frázových prekladových systémov pre bežné výskumné kritériá. V anglickom a francúzskom jazyku WMT’14 dosiahol tento systém zlepšenie o 0,5 BLEU (je algoritmus na hodnotenie kvality textu) v porovnaní s najmodernejším frázovým systémom. Odvtedy bolo navrhnutých veľa nových techník na ďalšie vylepšenie NMT ako napríklad použitie mechanizmu pozornosti na riešenie zriedkavých slov, mechanizmu na modelovanie pokrytia prekladu, rôznymi druhmi mechanizmov pozornosti, minimalizáciou strát na úrovni vety. LSTM sú špeciálny typ Rekurentných neurónových sietí (RNN), ktorý slúži na dosiahnutie dlhodobého kontextu (napr. Pri doplnení chýbajúcej interpunkcie alebo veľkých písmen). Najväčšie využitie LSTM je v oblasti strojového učenia a hlbokého učenia. Vlastnosti LSTM: - pripravený spracovať nielen jednoduché dáta, ale aj celé sekvenčné dáta (napr. reč alebo video), - sú vhodné na klasifikáciu, spracovanie a vytváranie predikcií na základe časových údajov - LSTM boli definované tak, aby si na rozdiel od RNN vedeli pomôcť s problémom, ktorý sa nazýva „Exploding and vanishing gradient problems“. [1] **Wordpiece Model** Tento prístup je založený výlučne na dátach a je zaručené, že pre každú možnú postupnosť znakov vygeneruje deterministickú segmentáciu (segmenty používateľov založené na nejakej hypotéze následne sa dáta analyzujú, aby sa zistilo, či sú segmenty zaujímavé a užitočné). Je to podobné ako metóda použitá pri riešení zriedkavých slov v strojovom preklade neurónov. Na spracovanie ľubovoľných slov najskôr rozdelíme slová na slovné druhy, ktoré sú dané trénovaným modelom slovných spojení. Pred cvičením modelu sú pridané špeciálne symboly hraníc slov, aby bolo možné pôvodnú sekvenciu slov získať z postupnosti slovných spojení bez nejasností. V čase dekódovania model najskôr vytvorí sekvenciu slovných spojení, ktorá sa potom prevedie na zodpovedajúcu sekvenciu slov. |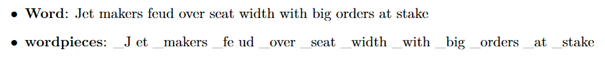| |:--:| |Obr 4. Príklad postupnosti slov a príslušná postupnosť slovných spojení| Vo vyššie uvedenom príklade je slovo „Jet“ rozdelené na dve slovné spojenia „_J“ a „et“ a slovo „feud“ je rozdelené na dve slovné spojenia „_fe“ a „ud“. Ostatné slová zostávajú ako jednotlivé slová. „_“ Je špeciálny znak pridaný na označenie začiatku slova. Wordpiece model sa generuje pomocou prístupu založeného na údajoch, aby sa maximalizovala pravdepodobnosť jazykových modelov cvičných údajov, vzhľadom na vyvíjajúcu sa definíciu slova. Vzhľadom na cvičný korpus a množstvo požadovaných tokenov D je problémom optimalizácie výber wordpieces D tak, aby výsledný korpus bol minimálny v počte wordpieces, ak sú segmentované podľa zvoleného wordpiece modelu. V tejto implementácii používame špeciálny symbol iba na začiatku slov, a nie na oboch koncoch. Počet základných znakov tiež znížime na zvládnuteľný počet v závislosti na údajoch (zhruba 500 pre západné jazyky, viac pre ázijské jazyky). Zistili sme, že použitím celkovej slovnej zásoby medzi 8 000 a 32 000 slovnými jednotkami sa dosahuje dobrá presnosť (BLEU skóre) aj rýchlosť dekódovania pre dané jazykové páry. V preklade má často zmysel kopírovať zriedkavé názvy entít alebo čísla priamo zo zdroja do cieľa. Na uľahčenie tohto typu priameho kopírovania vždy používame wordpiece model pre zdrojový aj cieľový jazyk. Použitím tohto prístupu je zaručené, že rovnaký reťazec vo zdrojovej a cieľovej vete bude segmentovaný presne rovnakým spôsobom, čo uľahčí systému naučiť sa kopírovať tieto tokeny. Wordpieces dosahujú rovnováhu medzi flexibilitou znakov a efektívnosťou slov. Zistili sme tiež, že naše modely dosahujú lepšie celkové skóre BLEU pri používaní wordpieces - pravdepodobne kvôli tomu, že naše modely teraz efektívne pracujú v podstate s nekonečnou slovnou zásobou bez toho, aby sa uchýlili iba k znakom. [1] ## OpenNMT-py tutoriál Pri práci na tomto tutoriáli som použil školský server idoc, rovnako ako aj voľne dostupné linuxové prostredie Ubuntu. Predtým než začneme so samotným tutoriálom je nutné si nainštalovať PyTorch (rámec pre preklad neurónových strojov s otvoreným zdrojom) verziu projektu OpenNMT rovnako ako inštaláciu najnovšej dostupnej verzie knižnice pip. To vykonáme zadaním nasledujúcich príkazov: - pip install --upgrade pip - pip install OpenNMT-py Prvým krokom v tutoriáli je príprava dát, na to nám poslúži predpripravená vzorka dát v anglicko-nemeckom jazyku voľne dostupná na internete obsahujúca 10 000 tokenizovaných viet (tokenizovanie je rozdelenie frázy, vety, odseku alebo celého textu na menšie jednotky teda tokeny,). Údaje pozostávajú z paralelných zdrojových (src) a cieľových (tgt) údajov obsahujúcich jednu vetu na riadok s tokenmi oddelenými medzerou. - wget https://s3.amazonaws.com/opennmt-trainingdata/toy-ende.tar.gz - tar xf toy-ende.tar.gz - cd toy-ende Pre pokračovanie si musíme pripraviť konfiguračný súbor YAML, aby sme určili údaje, ktoré sa použijú: - -# toy_en_de.yaml - -## Where the samples will be written - save_data: toy-ende/run/example - -## Where the vocab(s) will be written - src_vocab: toy-ende/run/example.vocab.src - tgt_vocab: toy-ende/run/example.vocab.tgt - -# Prevent overwriting existing files in the folder - overwrite: False - -# Corpus opts: - data: - corpus_1: - path_src: toy-ende/src-train.txt - path_tgt: toy-ende/tgt-train.txt - valid: - path_src: toy-ende/src-val.txt - path_tgt: toy-ende/tgt-val.txt ... Z tejto konfigurácie môžeme zostaviť slovnú zásobu, ktorá bude potrebná na trénovanie modelu: - onmt_build_vocab -config toy-ende/toy_en_de.yaml -n_sample 10000 Aby sme mohli model trénovať, musíme do konfiguračného súboru YAML pridať: -- cesty slovnej zásoby, ktoré sa budú používať (v tomto prípade cesty vygenerované programom onmt_build_vocab) -- tréning špecifických parametrov. Pridáme do YAML konfiguračného súboru nasledujúce riadky: - -# Vocabulary files that were just created - src_vocab: toy-ende/run/example.vocab.src - tgt_vocab: toy-ende/run/example.vocab.tgt - -# Where to save the checkpoints - save_model: toy-ende/run/model - save_checkpoint_steps: 500 - train_steps: 1000 - valid_steps: 500 Potom už len stačí spustiť proces trénovania: - onmt_train -config toy-ende/toy_en_de.yaml V tejto konfigurácii bude bežať predvolený model, ktorý sa skladá z dvojvrstvového modulu LSTM s 500 skrytými jednotkami v kodéri aj v dekodéri. Posledným krokom je samotný preklad, ktorý vykonáme zadaním nasledujúceho príkazu: - onmt_translate -model toy-ende/run/model_step_1000.pt -src toy-ende/src-test.txt -output toy-ende/pred_1000.txt -verbose Výsledkom je model, ktorý môžeme použiť na predpovedanie nových údajov. To prebieha spustením tzv. Beam search. Beam search sa využíva za účelom udržania ľahšieho ovládania vo veľkých systémoch s nedostatkom pamäte na uloženie celého vyhľadávacieho stromu. To vygeneruje predpovede do výstupného súboru toy-ende/pred_1000.txt . V mojom prípade proces prekladu trval na školskom serveri idoc približne 5 hodín zatiaľ čo v Linuxovom prostredí Ubuntu 1 hodinu. V obidvoch prípadoch boli výsledky podpriemerné, pretože demo súbor údajov bol dosť malý. ## Zoznam použitej literatúry [1]. WU Y., SCHUSTER M., CHEN Z., LE V. Q., NOROUZI M.: _Google’s Neural Machine Translation System: Bridging the Gapbetween Human and Machine Translation._ [online]. [citované 08-09-2016]. [2]. PYKES K.: _The Vanishing/Exploding Gradient Problem in Deep Neural Networks._ [online]. [citované 17-05-2020]. [3]. ŠÍMA J., NERUDA R.: Teoretické otázky neurónových sítí [online]. [1996].