Update 'pages/students/2016/patrik_pavlisin/dp22/README.md'
This commit is contained in:
parent
562bca06cb
commit
81d53ed746
@ -96,3 +96,22 @@ Vo vrstvách „encoder-decoder attention“ pochádzajú dotazy z predchádzaj
|
|||||||
Encoder obsahuje vrstvy Self-attention. Vo vrstve self-attention pochádzajú všetky kľúče, hodnoty a dotazy z rovnakého miesta, teda predchádzajúcej vrstvy v encoderu. Každá pozícia v encoderi sa môže venovať všetkým polohám v predchádzajúcej vrstve encodera.
|
Encoder obsahuje vrstvy Self-attention. Vo vrstve self-attention pochádzajú všetky kľúče, hodnoty a dotazy z rovnakého miesta, teda predchádzajúcej vrstvy v encoderu. Každá pozícia v encoderi sa môže venovať všetkým polohám v predchádzajúcej vrstve encodera.
|
||||||
|
|
||||||
Vrstvy self-attention v decoderi umožňujú každej pozícii v decoderi zúčastniť sa na všetkých polohách v decoderi až do danej polohy. Musí sa zabrániť toku informácii v decoderi, aby sa zachovala autoregresívna vlastnosť (model časových radov, ktorý používa pozorovania z predchádzajúcich časových krokov ako vstup do regresnej rovnice na predpovedanie hodnoty v nasledujúcom časovom kroku). To implementujeme do scaled dot-product attention pomocou maskovania (nastavením na -∞) všetkých hodnôt na vstupe softmax, ktoré zodpovedajú nezákonným spojeniam.
|
Vrstvy self-attention v decoderi umožňujú každej pozícii v decoderi zúčastniť sa na všetkých polohách v decoderi až do danej polohy. Musí sa zabrániť toku informácii v decoderi, aby sa zachovala autoregresívna vlastnosť (model časových radov, ktorý používa pozorovania z predchádzajúcich časových krokov ako vstup do regresnej rovnice na predpovedanie hodnoty v nasledujúcom časovom kroku). To implementujeme do scaled dot-product attention pomocou maskovania (nastavením na -∞) všetkých hodnôt na vstupe softmax, ktoré zodpovedajú nezákonným spojeniam.
|
||||||
|
|
||||||
|
**R-Transformer**
|
||||||
|
|
||||||
|
||
|
||||||
|
|:--:|
|
||||||
|
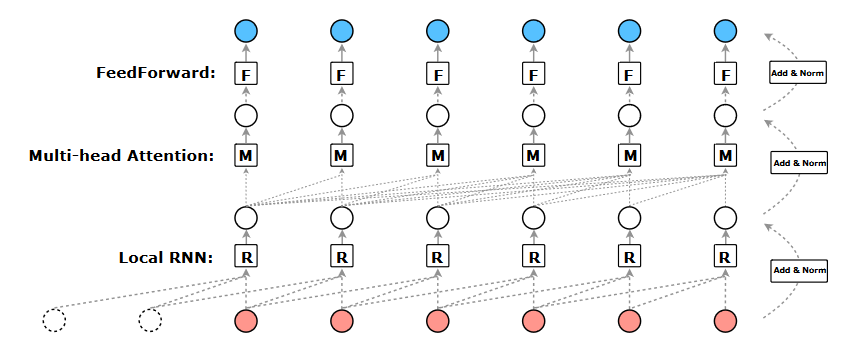
|Obr 5. R-Transformer|
|
||||||
|
|
||||||
|
Navrhovaný transformátor R sa skladá zo stohu rovnakých vrstiev. Každá vrstva má 3 komponenty, ktoré sú usporiadané hierarchicky. Ako je znázornené na obrázku, nižšou úrovňou sú lokálne rekurentné neurónové siete, ktoré sú určené na modelovanie lokálnych štruktúr v sekvencii, stredná úroveň je Multi-head attention, ktorá je schopná zachytiť globálne dlhodobé závislosti a horná úroveň je position-wise feedforward sieť, ktorá vykonáva nelineárnu transformáciu prvkov.
|
||||||
|
|
||||||
|
## Zoznam použitej literatúry
|
||||||
|
|
||||||
|
[1]. VASWANI A., SHAZEER N., PARMAR N., USZKOREIT J., JONES L., GOMEZ N.A., KASIER L., POLUSUKHIN.I.: _Attention Is All You Need._ [online]. [citované 2017].
|
||||||
|
[2]. WANG Z., MA Y., LIU Z., TANG J.: _R-Transformer: Recurrent Neural Network Enhanced Transformer._ [online]. [citované 12-07-2019].
|
||||||
|
[3]. SRIVASTAVA S.: _Machine Translation (Encoder-Decoder Model)!._ [online]. [citované 31-10-2019].
|
||||||
|
[4]. ALAMMAR J.: _The Illustrated Transformer._ [online]. [citované 27-06-2018].
|
||||||
|
[5]. _Sequence Modeling with Neural Networks (Part 2): Attention Models_ [online]. [citované 18-04-2016].
|
||||||
|
[6]. GIACAGLIA G.: _How Transformers Work._ [online]. [citované 11-03-2019].
|
||||||
|
[7]. _Understanding LSMT Networks_ [online]. [citované 27-08-2015].
|
||||||
|
[8]. _6 Types of Artifical Neural Networks Currently Being Used in Machine Translation_ [online]. [citované 15-01-201].
|
||||||
Loading…
Reference in New Issue
Block a user