merge
This commit is contained in:
commit
3f75d311e8
@ -38,6 +38,15 @@ Zásobník úloh:
|
||||
|
||||
- natrénovať aj iné preklady (z a do češtiny).
|
||||
|
||||
12.11.2021
|
||||
|
||||
Práca na texte
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zlepšiť štruktúru práce
|
||||
- Dotrénovať a vyhodnotiť model slovenčina-angličtina.
|
||||
|
||||
28.10.
|
||||
|
||||
Stav:
|
||||
@ -48,7 +57,7 @@ Stav:
|
||||
Úlohy:
|
||||
|
||||
- Naučte sa pripravovať textové dáta. Prejdite si knihu https://diveintopython3.net aspoň do 4 kapitoly. Vypracujte všetky príklady z nej.
|
||||
- Pokračujte v práci na článku. Treba doplniť odkazy do textu. Treba zlepšiť štruktúru a logickú náväznosť viet. Vyslvetlite neznáme pojmy.
|
||||
- Pokračujte v práci na článku. Treba doplniť odkazy do textu. Treba zlepšiť štruktúru a logickú náväznosť viet. Vysvetlite neznáme pojmy.
|
||||
- Zmente článok na draft diplomovej práce. Vypracujte osnovu diplomovej práce - napíšte názvy kapitol a ich obsah. Zaraďte tam text o transformeroch ktorý ste vypracovali.
|
||||
- Pripravte textové dáta do vhodnej podoby a spustite trénovanie.
|
||||
|
||||
|
||||
@ -66,10 +66,6 @@ Neurónový strojový preklad (angl. NMT - neural machine translation) používa
|
||||
|
||||
Spoločnosť Google preto predstavila GNMT (google´s neural machine translation) systém , ktorý sa pokúša vyriešiť mnohé z týchto problémov. Tento model sa skladá z hlbokej siete Long Short-Term Memory (LSTM) s 8 kódovacími a 8 dekódovacími vrstvami, ktoré využívajú zvyškové spojenia, ako aj pozorovacie spojenia zo siete dekodéra ku kódovaciemu zariadeniu. Aby sa zlepšila paralelnosť a tým pádom skrátil čas potrebný na trénovanie, tento mechanizmus pozornosti spája spodnú vrstvu dekodéra s hornou vrstvou kódovacieho zariadenia. Na urýchlenie konečnej rýchlosti prekladu používame pri odvodzovacích výpočtoch aritmetiku s nízkou presnosťou. Aby sa vylepšila práca so zriedkavými slovami, slová sa delia na vstup aj výstup na obmedzenú množinu bežných podslovných jednotiek („wordpieces“). Táto metóda poskytuje dobrú rovnováhu medzi flexibilitou modelov oddelených znakom a účinnosťou modelov oddelených slovom, prirodzene zvláda preklady zriedkavých slov a v konečnom dôsledku zvyšuje celkovú presnosť systému.
|
||||
|
||||
Tento prístup je založený výlučne na dátach a je zaručené, že pre každú možnú postupnosť znakov vygeneruje deterministickú segmentáciu. Je to podobné ako metóda použitá pri riešení zriedkavých slov v strojovom preklade neurónov. Na spracovanie ľubovoľných slov najskôr rozdelíme slová na slovné druhy, ktoré sú dané trénovaným modelom slovných spojení. Pred cvičením modelu sú pridané špeciálne symboly hraníc slov, aby bolo možné pôvodnú sekvenciu slov získať zo sekvencie slovného slova bez nejasností. V čase dekódovania model najskôr vytvorí sekvenciu slovných spojení, ktorá sa potom prevedie na zodpovedajúcu sekvenc
|
||||
|
||||
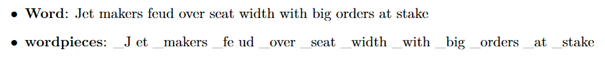|
|
||||
=======
|
||||
Štatistický strojový preklad (SMT - statistical machine translation) je po celé desaťročia dominantnou paradigmou strojového prekladu. Implementáciami SMT sú vo všeobecnosti systémy založené na frázach (PBMT - phrase-based machine translation), ktoré prekladajú postupnosti slov alebo frázy, kde sa môžu dĺžky líšiť. Ešte pred príchodom priameho neurónového strojového prekladu sa neurónové siete s určitým úspechom používali ako súčasť systémov SMT. Možno jeden z najpozoruhodnejších pokusov spočíval v použití spoločného jazykového modelu na osvojenie frázových reprezentácií, čo prinieslo pozoruhodné zlepšenie v kombinácii s prekladom založeným na frázach. Tento prístup však vo svojej podstate stále využíva frázové prekladové systémy, a preto dedí ich nedostatky.
|
||||
|
||||
O koncepciu end-to-end učenia pre strojový preklad sa v minulosti pokúšali s obmedzeným úspechom. Po mnohých seminárnych prácach v tejto oblasti sa kvalita prekladu NMT priblížila k úrovni frázových prekladových systémov pre bežné výskumné kritériá. V anglickom a francúzskom jazyku WMT’14 dosiahol tento systém zlepšenie o 0,5 BLEU (je algoritmus na hodnotenie kvality textu) v porovnaní s najmodernejším frázovým systémom. Odvtedy bolo navrhnutých veľa nových techník na ďalšie vylepšenie NMT ako napríklad použitie mechanizmu pozornosti na riešenie zriedkavých slov, mechanizmu na modelovanie pokrytia prekladu, rôznymi druhmi mechanizmov pozornosti, minimalizáciou strát na úrovni vety.
|
||||
|
||||
@ -23,6 +23,28 @@ Automatické odpovede z Wikipédie
|
||||
|
||||
Vytovrenie prehľadu existujúcich systémov QA.
|
||||
|
||||
Stretnutie 12.11.2021
|
||||
|
||||
- Pokračuje práca na texte
|
||||
- Nainštalovaná Anaconda
|
||||
- Začiatok Python Tutoriálu
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračujte v práci na texte.
|
||||
- Pokračujte v Python Tutoriáli.
|
||||
- Prečítajte si blogy na https://qa.fastforwardlabs.com/ Vyskúšajte si, či Vám to pôjde v Anaconde.
|
||||
- Nainštalujte si HuggingFace transformers: https://huggingface.co/transformers/installation.html do Anacondy
|
||||
- Prejdite si tutoriál https://huggingface.co/transformers/training.html
|
||||
- Ak Vám to pôjde, prejdite si tutoriál https://github.com/huggingface/notebooks/blob/master/examples/question_answering.ipynb
|
||||
- Ak sa zaseknete, skúsime to vyriešiť na konzultácii.
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Nainštalujte a vyskúšajte toto: https://github.com/facebookresearch/DrQA
|
||||
|
||||
|
||||
Stretnutie 5.11.2021
|
||||
|
||||
- Splnené zadané úlohy z minulého týždňa, okrem nainštalovania
|
||||
|
||||
@ -34,6 +34,13 @@ Ciele:
|
||||
3. Vytvoriť kompletný reťazec CI-CD ku aplikácii Traktor. Automatický build a test, zobrazenie reportu.
|
||||
4. Vypracovanie písomného prehľadu.
|
||||
|
||||
Stretnutie 12.11.2012
|
||||
|
||||
Práca na texte.
|
||||
|
||||
Úlohy: Pokračujte v otvorených úlohách
|
||||
- Napíšte čo je to testovanie a aké spôsoby testovania poznáme (aplikačné, použiteľnosti, jednotkové... ).
|
||||
|
||||
Stretnutie 22.10.
|
||||
|
||||
- Napísaný prvý draf s poznámkami o CI CD
|
||||
@ -44,7 +51,6 @@ Stretnutie 22.10.
|
||||
- Pokračujte v otvorených úlohách
|
||||
- Vytvorte GIT repozitár s názvom bp2022 a nahrajte do neho testovacie scenáre.
|
||||
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- [ ] Skúste vytvoriť nasadenie vhodného CI CD na tuke cloude.
|
||||
|
||||
@ -23,6 +23,14 @@ Názov: Indexovanie slovenského textu pomocou Elasticsearch
|
||||
|
||||
## Bakalársky projekt 2021
|
||||
|
||||
Stretnutie 12.11.2021
|
||||
|
||||
Pokračujú práce na písomnej časti, na praktickej zatiaľ nie.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Zlepšiť štruktúru práce.
|
||||
- Doplniť do textu odkazy na literatúru.
|
||||
|
||||
Ciele na semester:
|
||||
|
||||
|
||||
@ -36,8 +36,23 @@ Ciele:
|
||||
- Vypracovať draft B. práce.
|
||||
- Mať funkčné demo vo forme nasadenej webovej aplikácie.
|
||||
|
||||
|
||||
- - -
|
||||
|
||||
Stretnutie 12.1.2021
|
||||
|
||||
Vyhodnotenie zatiaľ nefunguje.
|
||||
|
||||
Úlohy:
|
||||
|
||||
- Pokračovať v písaní práce.
|
||||
- Dokončiť web demo.
|
||||
- [ ] Vytvorte dockerfile.
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- Vyhdonotiť NLU (úlohy z 12.10.)
|
||||
|
||||
Stretnutie 22.10.2021
|
||||
|
||||
- Urobené webové rozhranie pre analýzu konverzácií.
|
||||
@ -62,7 +77,6 @@ Stav:
|
||||
|
||||
Zásobník úloh:
|
||||
|
||||
- [ ] Vytvorte dockerfile.
|
||||
- [x] Analyzovať logy z konverzácií. Pripraviť export konverzácií v JSON pre spracovanie a HTML formáte pre zobrazenie.
|
||||
|
||||
- - -
|
||||
|
||||
Loading…
Reference in New Issue
Block a user