Merge branch 'master' of git.kemt.fei.tuke.sk:KEMT/zpwiki
@ -17,6 +17,32 @@ Generovanie vektorových reprezentácií štruktúrovaných dát.
|
|||||||
|
|
||||||
- Grafové neurónové siete
|
- Grafové neurónové siete
|
||||||
|
|
||||||
|
Stretnutie 26.11.2021
|
||||||
|
|
||||||
|
Dáta z US Steel:
|
||||||
|
|
||||||
|
- Najprv sa do vysokej pece nasypú suroviny.
|
||||||
|
- Z tavby sa postupne odoberajú vzorky a meria sa množstvo jednotlivých vzoriek.
|
||||||
|
- Na konci tavby sa robí finálna analýza taveniny.
|
||||||
|
- Priebeh procesu závisí od vlastností konkrétnej pece. Sú vlastnosti pece stacionárne? Je možné , že vlastnosti pece sa v čase menia.
|
||||||
|
- Cieľom je predpovedať výsledky anaýzy finálnej tavby na základe predošlých vzoriek.
|
||||||
|
- Cieľom je predpovedať výsledky nasledujúceho odberu na základe predchádzajúcich?
|
||||||
|
- Čo znamená "dobrá tavba"?
|
||||||
|
- Čo znamená "dobrá predpoveď výsledkov"?
|
||||||
|
- Je dôležitý čas odbery vzorky?
|
||||||
|
|
||||||
|
Zásobník úloh:
|
||||||
|
|
||||||
|
- Formulovať problém ako "predikcia časových radov" - sequence prediction.
|
||||||
|
- Nápad: The analysis of time series : an introduction / Chris Chatfield. 5th ed. Boca Raton : Chapman and Hall, 1996. xii, 283 s. (Chapman & Hall texts in statistical science series). - ISBN 0-412-71640-2 (brož.).
|
||||||
|
- Prezrieť literatúru a zistiť najnovšie metódy na predikciu.
|
||||||
|
- Navrhnúť metódu konverzie dát na vektor príznakov. Sú potrebné binárne vektory?
|
||||||
|
- Navrhnúť metódu výpočtu chybovej funkcie - asi euklidovská vzdialenosť medzi výsledkov a očakávaním.
|
||||||
|
- Vyskúšať navrhnúť rekurentnú neurónovú sieť - RNN, GRU, LSTM.
|
||||||
|
- Nápad: Transformer network, Generative Adversarial Network.
|
||||||
|
- Nápad: Vyskúšať klasické štatistické modely (scikit-learn) - napr. aproximácia polynómom, alebo SVM.
|
||||||
|
|
||||||
|
|
||||||
Stretnutie 1.10.
|
Stretnutie 1.10.
|
||||||
|
|
||||||
Stav:
|
Stav:
|
||||||
|
|||||||
@ -38,6 +38,21 @@ Zásobník úloh:
|
|||||||
|
|
||||||
- natrénovať aj iné preklady (z a do češtiny).
|
- natrénovať aj iné preklady (z a do češtiny).
|
||||||
|
|
||||||
|
28.10.
|
||||||
|
|
||||||
|
Stav:
|
||||||
|
|
||||||
|
- Vypracovaný draft článoku o transformeroch, treba vylepšiť. Článok je na ZP Wiki
|
||||||
|
- Problém pri príprave trénovacích dát.
|
||||||
|
|
||||||
|
Úlohy:
|
||||||
|
|
||||||
|
- Naučte sa pripravovať textové dáta. Prejdite si knihu https://diveintopython3.net aspoň do 4 kapitoly. Vypracujte všetky príklady z nej.
|
||||||
|
- Pokračujte v práci na článku. Treba doplniť odkazy do textu. Treba zlepšiť štruktúru a logickú náväznosť viet. Vyslvetlite neznáme pojmy.
|
||||||
|
- Zmente článok na draft diplomovej práce. Vypracujte osnovu diplomovej práce - napíšte názvy kapitol a ich obsah. Zaraďte tam text o transformeroch ktorý ste vypracovali.
|
||||||
|
- Pripravte textové dáta do vhodnej podoby a spustite trénovanie.
|
||||||
|
|
||||||
|
|
||||||
Stretnutie 30.9.
|
Stretnutie 30.9.
|
||||||
|
|
||||||
Stav:
|
Stav:
|
||||||
|
|||||||
@ -66,7 +66,6 @@ Neurónový strojový preklad (angl. NMT - neural machine translation) používa
|
|||||||
|
|
||||||
Spoločnosť Google preto predstavila GNMT (google´s neural machine translation) systém , ktorý sa pokúša vyriešiť mnohé z týchto problémov. Tento model sa skladá z hlbokej siete Long Short-Term Memory (LSTM) s 8 kódovacími a 8 dekódovacími vrstvami, ktoré využívajú zvyškové spojenia, ako aj pozorovacie spojenia zo siete dekodéra ku kódovaciemu zariadeniu. Aby sa zlepšila paralelnosť a tým pádom skrátil čas potrebný na trénovanie, tento mechanizmus pozornosti spája spodnú vrstvu dekodéra s hornou vrstvou kódovacieho zariadenia. Na urýchlenie konečnej rýchlosti prekladu používame pri odvodzovacích výpočtoch aritmetiku s nízkou presnosťou. Aby sa vylepšila práca so zriedkavými slovami, slová sa delia na vstup aj výstup na obmedzenú množinu bežných podslovných jednotiek („wordpieces“). Táto metóda poskytuje dobrú rovnováhu medzi flexibilitou modelov oddelených znakom a účinnosťou modelov oddelených slovom, prirodzene zvláda preklady zriedkavých slov a v konečnom dôsledku zvyšuje celkovú presnosť systému.
|
Spoločnosť Google preto predstavila GNMT (google´s neural machine translation) systém , ktorý sa pokúša vyriešiť mnohé z týchto problémov. Tento model sa skladá z hlbokej siete Long Short-Term Memory (LSTM) s 8 kódovacími a 8 dekódovacími vrstvami, ktoré využívajú zvyškové spojenia, ako aj pozorovacie spojenia zo siete dekodéra ku kódovaciemu zariadeniu. Aby sa zlepšila paralelnosť a tým pádom skrátil čas potrebný na trénovanie, tento mechanizmus pozornosti spája spodnú vrstvu dekodéra s hornou vrstvou kódovacieho zariadenia. Na urýchlenie konečnej rýchlosti prekladu používame pri odvodzovacích výpočtoch aritmetiku s nízkou presnosťou. Aby sa vylepšila práca so zriedkavými slovami, slová sa delia na vstup aj výstup na obmedzenú množinu bežných podslovných jednotiek („wordpieces“). Táto metóda poskytuje dobrú rovnováhu medzi flexibilitou modelov oddelených znakom a účinnosťou modelov oddelených slovom, prirodzene zvláda preklady zriedkavých slov a v konečnom dôsledku zvyšuje celkovú presnosť systému.
|
||||||
|
|
||||||
<<<<<<< HEAD
|
|
||||||
Tento prístup je založený výlučne na dátach a je zaručené, že pre každú možnú postupnosť znakov vygeneruje deterministickú segmentáciu. Je to podobné ako metóda použitá pri riešení zriedkavých slov v strojovom preklade neurónov. Na spracovanie ľubovoľných slov najskôr rozdelíme slová na slovné druhy, ktoré sú dané trénovaným modelom slovných spojení. Pred cvičením modelu sú pridané špeciálne symboly hraníc slov, aby bolo možné pôvodnú sekvenciu slov získať zo sekvencie slovného slova bez nejasností. V čase dekódovania model najskôr vytvorí sekvenciu slovných spojení, ktorá sa potom prevedie na zodpovedajúcu sekvenc
|
Tento prístup je založený výlučne na dátach a je zaručené, že pre každú možnú postupnosť znakov vygeneruje deterministickú segmentáciu. Je to podobné ako metóda použitá pri riešení zriedkavých slov v strojovom preklade neurónov. Na spracovanie ľubovoľných slov najskôr rozdelíme slová na slovné druhy, ktoré sú dané trénovaným modelom slovných spojení. Pred cvičením modelu sú pridané špeciálne symboly hraníc slov, aby bolo možné pôvodnú sekvenciu slov získať zo sekvencie slovného slova bez nejasností. V čase dekódovania model najskôr vytvorí sekvenciu slovných spojení, ktorá sa potom prevedie na zodpovedajúcu sekvenc
|
||||||
|
|
||||||
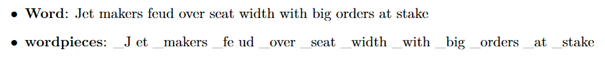|
|
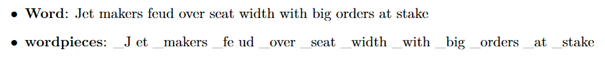|
|
||||||
@ -88,7 +87,6 @@ Tento prístup je založený výlučne na dátach a je zaručené, že pre každ
|
|||||||
|
|
||||||
|
|
||||||
|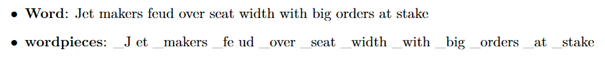|
|
|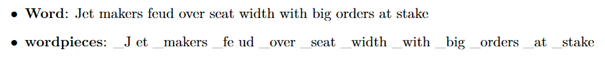|
|
||||||
>>>>>>> origin
|
|
||||||
|:--:|
|
|:--:|
|
||||||
|Obr 4. Príklad postupnosti slov a príslušná postupnosť slovných spojení|
|
|Obr 4. Príklad postupnosti slov a príslušná postupnosť slovných spojení|
|
||||||
|
|
||||||
@ -177,70 +175,3 @@ Výsledkom je model, ktorý môžeme použiť na predpovedanie nových údajov.
|
|||||||
|
|
||||||
[3]. ŠÍMA J., NERUDA R.: Teoretické otázky neurónových sítí [online]. [1996].
|
[3]. ŠÍMA J., NERUDA R.: Teoretické otázky neurónových sítí [online]. [1996].
|
||||||
|
|
||||||
<<<<<<< HEAD
|
|
||||||
V preklade má často zmysel kopírovať zriedkavé názvy entít alebo čísla priamo zo zdroja do cieľa. Na uľahčenie tohto typu priameho kopírovania vždy používame wordpiece model pre zdrojový aj cieľový jazyk. Použitím tohto prístupu je zaručené, že rovnaký reťazec vo zdrojovej a cieľovej vete bude segmentovaný presne rovnakým spôsobom, čo uľahčí systému naučiť sa kopírovať tieto tokeny. Wordpieces dosahujú rovnováhu medzi flexibilitou znakov a efektívnosťou slov. Zistili sme tiež, že naše modely dosahujú lepšie celkové skóre BLEU pri používaní wordpieces - pravdepodobne kvôli tomu, že naše modely teraz efektívne pracujú v podstate s nekonečnou slovnou zásobou bez toho, aby sa uchýlili iba k znakom.
|
|
||||||
**Neurónová sieť**
|
|
||||||
|
|
||||||
Neurónovú sieť tvoria neuróny, ktoré sú medzi sebou poprepájané. Obecne môžeme neuróny poprepájať medzi ľubovoľným počtom neurónov, pričom okrem pôvodných vstupov môžu byť za vstupy brané aj výstupy iných neurónov. Počet neurónov a ich vzájomné poprepájanie v sieti určuje tzv. architektúru (topológiu) neurónovej siete. Neurónová sieť sa v čase vyvíja, preto je potrebné celkovú dynamiku neurónovej siete rozdeliť do troch dynamík a potom uvažovať tri režimy práce siete: organizačná (zmena topológie), aktívna (zmena stavu) a adaptívna (zmena konfigurácie). Jednotlivé dynamiky neurónovej siete sú obvykle zadané počiatočným stavom a matematickou rovnicou, resp. pravidlom, ktoré určuje vývoj príslušnej charakteristiky sieti v čase.
|
|
||||||
|
|
||||||
Synaptické váhy patria medzi dôležité časti Neurónovej siete. Tieto váhy ovplyvňujú celú sieť tým, že ovplyvňujú vstupy do neurónov a tým aj ich stavy. Synaptické váhy medzi neurónmi _i, j_ označujeme _w__i,j_. Najdôležitejším momentom pri činnosti Neurónovej siete je práve zmena váh delta _w__i,j_. Vo všeobecnosti ich rozdeľujeme na kladné (excitačné) a záporné (inhibičné).
|
|
||||||
|
|
||||||
Neurón je základným prvkom Neurónovej siete. Rozdiel medzi umelým a ľudským je v tom, že v súčasnosti je možné vytvoriť oveľa rýchlejší neurón, ako ľudský. Avšak čo sa týka počtu neurónov, ľudský mozog sa skladá z 10 na 11 až 10 na 14 neurónov a každý neurón má 10 na 3 až 10 na 4 neurónových spojení. V súčasnej dobe nie je možné nasimulovať v rámci jednej Neurónovej siete také množstvo neurónov. V tomto ohľade je ľudský mozog podstatne silnejší oproti nasimulovanej Neurónovej siete. [3]
|
|
||||||
|
|
||||||
|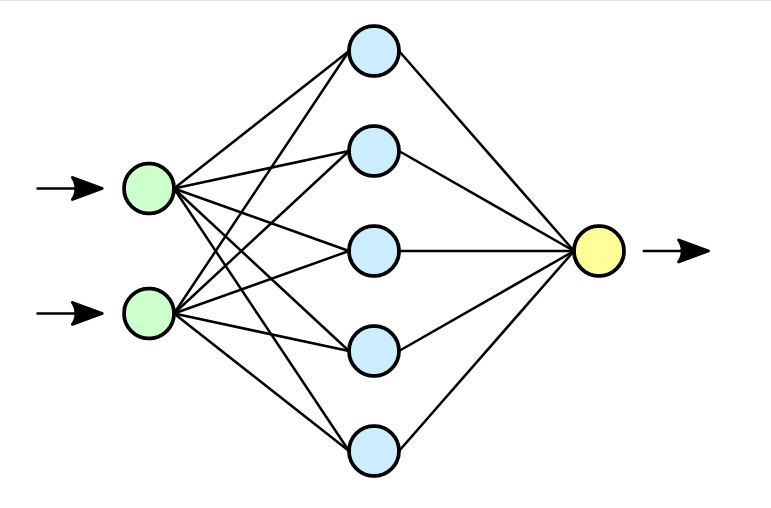|
|
|
||||||
|:--:|
|
|
||||||
|Obr 2. základné zobrazenie Neurónovej siete|
|
|
||||||
|
|
||||||
|
|
||||||
Činnosť Neurónových sieti rozdeľujeme na :
|
|
||||||
|
|
||||||
- Fáza učenia – v tejto fáze sa znalosti ukladajú do synaptických váh neurónovej siete, ktoré sa menia podľa stanovených pravidiel počas procesu učenia. V prípade neurónových sieti môžeme pojem učenie chápať ako adaptáciu neurónových sieti, teda zbieranie a uchovávanie poznatkov.
|
|
||||||
|
|
||||||
- Fáza života – dochádza ku kontrole a využitiu nadobudnutých poznatkov na riešenie určitého problému (napr. transformáciu signálov, problémy riadenia procesov, aproximáciu funkcií, klasifikácia do tried a podobne). V tejto fáze sa už nemenia synaptické váhy.
|
|
||||||
|
|
||||||
Neurónová sieť by vo všeobecnosti mala mať pravidelnú štruktúru pre ľahší popis a analýzu. Viacvrstvová štruktúra patrí k pomerne dobre preskúmaným štruktúram Neurónovej siete a skladá sa z :
|
|
||||||
|
|
||||||
- Vstupná vrstva (Input layer) – na vstup prichádzajú len vzorky z vonkajšieho sveta a výstupy posiela k ďalším neurónom
|
|
||||||
|
|
||||||
- Skrytá vrstva (Hidden layer) – vstupom sú neuróny z ostatných neurónov z vonkajšieho sveta (pomocou prahového prepojenia) a výstupy posiela opäť ďalším neurónom
|
|
||||||
|
|
||||||
- Výstupná vrstva (Output layer) – prijíma vstupy z iných neurónov a výstupy posiela do vonkajšieho prostredia
|
|
||||||
|
|
||||||
Reprezentatívna vzorka je jedným zo základných pojmov Neurónových sieti. Jedná sa o usporiadanú množinu usporiadaných dvojíc, pričom ku každému vstupu je priradený vyhovujúci výstup. Poznáme dva typy reprezentatívnych vzoriek :
|
|
||||||
|
|
||||||
- Trénovaciu vzorku – využíva sa pri fáze učenia (pri tejto vzorke je dôležité vybrať tú najvhodnejšiu a najkvalitnejšiu, pretože získané poznatky sa ukladajú učením do synaptických váh neurónovej siete)
|
|
||||||
|
|
||||||
- Testovacia vzorka – používa sa vo fáze života
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Topológiu Neurónových sieti rozdeľujeme na :
|
|
||||||
|
|
||||||
- Dopredné Neurónové siete (feed-forward neural network), ktoré sa ďalej delia na kontrolované a nekontrolované učenie, v tejto topológií je signál šírený iba jedným smerom.
|
|
||||||
|
|
||||||
|
|
||||||
|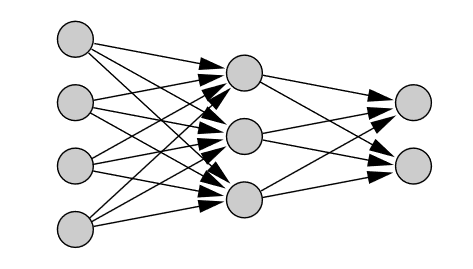|
|
|
||||||
|:--:|
|
|
||||||
|Obr 3. Dopredná Neurónová sieť|
|
|
||||||
|
|
||||||
|
|
||||||
- Rekurentné Neurónové siete (recurrent neural network), ktoré sa ďalej delia na kontrolované a nekontrolované učenie, signál sa šíry obojsmerne (neuróny sa môžu správať ako vstupné aj výstupné). [3]
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|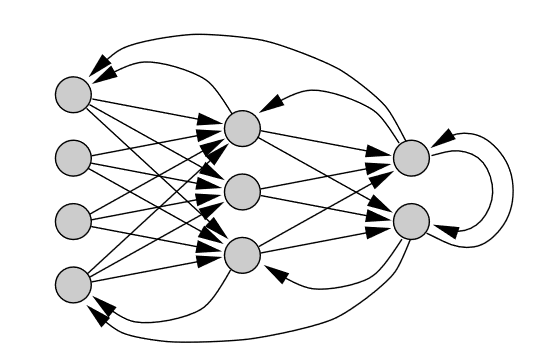|
|
|
||||||
|:--:|
|
|
||||||
|Obr 3. Rekurentná Neurónová sieť|
|
|
||||||
|
|
||||||
**Neurónový preklad**
|
|
||||||
|
|
||||||
Neurónový strojový preklad vo všeobecnosti zahŕňa všetky typy strojového prekladu, kde sa na predpovedanie sekvencie čísel používa umelá neurónová sieť. V prípade prekladu je každé slovo vo vstupnej vete zakódované na číslo, ktoré neurónová sieť prepošle do výslednej postupnosti čísel predstavujúcich preloženú cieľovú vetu. Prekladový model následne funguje prostredníctvom zložitého matematického vzorca(reprezentovaného ako neurónová sieť). Tento vzorec prijíma reťazec čísel ako vstupy a výstupy výsledného reťazca čísel. Parametre tejto neurónovej siete sú vytvárané a vylepšované trénovaním siete s miliónmi vetných párov. Každý takýto pár viet tak mierne upravuje a vylepšuje neurónovú sieť, keď prechádza každým vetným párom pomocou algoritmu nazývaným spätné šírenie. [3]
|
|
||||||
|
|
||||||
[1]. WU Y., SCHUSTER M., CHEN Z., LE V. Q., NOROUZI M.: _Google’s Neural Machine Translation System: Bridging the Gapbetween Human and Machine Translation._ [online]. [citované 08-09-2016].
|
|
||||||
|
|
||||||
[2]. PYKES K.: _The Vanishing/Exploding Gradient Problem in Deep Neural Networks._ [online]. [citované 17-05-2020].
|
|
||||||
|
|
||||||
[3]. ŠÍMA J., NERUDA R.: Teoretické otázky neurónových sítí [online]. [1996].
|
|
||||||
=======
|
|
||||||
[4]. ZHANG A., LIPTON C. Z., LI M., SMOLA J. A.: Dive into Deep Learning. [online]. [citované 06-11-2020].
|
|
||||||
>>>>>>> origin
|
|
||||||
|
|||||||
{kind=link}
|
After Width: | Height: | Size: 98 KiB |
{kind=link}
|
After Width: | Height: | Size: 32 KiB |
BIN
pages/students/2016/patrik_pavlisin/dp22/R-Transformer.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 42 KiB |
@ -1 +1,127 @@
|
|||||||
THE TRANSFORMER
|
## Attention, The Transformer
|
||||||
|
|
||||||
|
**Úvod**
|
||||||
|
|
||||||
|
Transformer je modelová architektúra, ktorá sa vyhýba opakovaniu a namiesto toho sa úplne spolieha na mechanizmus pozornosti na kreslenie globálnych závislostí medzi vstupom a výstupom. Je to prvý transdukčný model, ktorý sa spolieha úplne na vlastnú pozornosť pri výpočte reprezentácii vstupu a výstupu bez použitia RNN (Recurrent Neural Network) alebo CNN (Convolution Neural Network). Používa sa predovšetkým v oblasti NLP (Natural Language Processing) a CV (Computer Vision). Mechanizmy pozornosti sa stali súčasťou presvedčivého modelovania sekvencií a prenosových modelov v rôznych úlohách, ktoré umožňujú modelovanie závislostí bez ohľadu na ich vzdialenosť vo vstupných alebo výstupných sekvenciách. Takmer vo všetkých prípadoch sa však takéto mechanizmy pozornosti používajú v spojení s rekurentnou sieťou. Systémy počítačového videnia (CV) založené na CNN môžu tiež ťažiť z mechanizmov pozornosti. Hlavnou vlastnosťou tzv. “mechanizmus pozornosti” je že vie na základe vstupnej postupnosti v každom kroku rozhodnúť, ktoré časti postupnosti sú dôležité. Je to technika, ktorá napodobňuje kognitívnu pozornosť.
|
||||||
|
|
||||||
|
Najmä Multi-head attention mechanizmus v Transformeri umožňuje, aby bola každá pozícia priamo spojená s akýmikoľvek inými pozíciami v sekvencii. Informácie tak môžu prúdiť cez pozície bez akejkoľvek medzistraty. Napriek tomu existujú dva problémy, ktoré môžu poškodiť účinnosť Multi-head attention pri sekvenčnom učení. Prvý pochádza zo straty sekvenčných informácií o pozíciách, pretože s každou pozíciou zaobchádza rovnako. Na zmiernenie tohto problému Transformer zavádza vkladanie pozícií, ktorých účinky sa však ukázali ako obmedzené. [4]
|
||||||
|
|
||||||
|
Na vyriešenie vyššie uvedených obmedzení štandardného Transformera bol navrhnutý nový model sekvenčného učenia R-Transformer. Ide o viacvrstvovú architektúru postavenú na RNN a štandardnom Transformeri, pričom využíva výhody oboch svetov, ale zároveň sa vyhýba ich príslušným nevýhodám. Konkrétnejšie, pred výpočtom globálnych závislostí pozícii pomocou Multi-head attention najskôr spresníme znázornenie každej polohy tak, aby sa sekvenčné a lokálne informácie v jej susedstve mohli v reprezentácii skomprimovať. Aby sa to dosiahlo bola zavedená lokálna rekurentná neurónová sieť, označená ako LocalRNN, na spracovanie signálov v rámci lokálneho okna končiaceho na danej pozícii. LocalRNN navyše pracuje na miestnych oknách všetkých pozícií identicky a nezávisle a pre každú z nich vytvára skrytú reprezentáciu. Okrem toho, keďže sa lokálne okno posúva pozdĺž sekvencie jednu pozíciu za druhou, sú zahrnuté aj globálne sekvenčné informácie. Dôležité najme je, že nakoľko LocalRNN sa používa iba na lokálne okná, vyššie uvedené nevýhody RNN je možné zmierniť. [1][6]
|
||||||
|
|
||||||
|
Rekurentné neurónové siete, najmä long short-term pamäť (LSMT, špeciálny druh RNN, vytvorený na riešenie problémov s miznúcim gradientom) a uzavreté rekurentné neurónové siete, boli pevne zavedené ako najmodernejšie prístupy k problémom sekvenčného modelovania a prenosov, ako je jazykové modelovanie a strojový preklad. LSTM je architektúra umelej rekurentnej neurónovej siete (RNN), ktorá sa používa v oblasti deep-learning učenia. Na rozdiel od štandardných dopredných neurónových sietí (ang. Feedforward neural network) má LSTM spätnú väzbu. Dokáže spracovať nielen jednotlivé dátové body (napríklad obrázky), ale aj celé sekvencie dát (napríklad reč alebo video). Početné snahy odvtedy pokračujú v posúvaní hraníc rekurentných jazykových modelov a architektúr encoder-decoder. Sieťové pamäte typu end-to-end sú založené na RNN (Recurrent Neural Network) mechanizme namiesto opakovania zarovnaného podľa sekvencie a ukázalo sa, že fungujú dobre pri úlohách zodpovedajúcich otázky v jednoduchom jazyku a pri modelovaní jazykov. End-to-end učenie je typ Deep Learningu, v ktorom sú všetky parametre trénované spoločne, a nie krok za krokom. [7] [8]
|
||||||
|
|
||||||
|
RNN boli dlhodobo dominantnou voľbou pre sekvenčné modelovanie, závažne však trpia najme dvoma problémami. Po prvé, ľahko trpí problémami s miznutím a explodovaním gradientu, čo do značnej miery obmedzuje schopnosť naučiť sa veľmi dlhodobé závislosti. Po druhé, sekvenčná povaha prechodov dopredu aj dozadu veľmi sťažuje, ak nie priam znemožňuje, paralelizáciu výpočtu, čo dramaticky zvyšuje časovú zložitosť v tréningovom aj testovacom postupe. Preto mnohé nedávno vyvinuté modely sekvenčného učenia úplne vypustili rekurentnú štruktúru a spoliehajú sa iba na konvolučnú (Convolution Neural Network) alebo mechanizmus pozornosti, ktoré sa dajú ľahko paralelizovať a umožňujú tok informácií v ľubovoľnej dĺžke. Dva reprezentatívne modely, ktoré pritiahli veľkú pozornosť, sú Temporal Convolution Networks (TCN) a Transformer. V rôznych úlohách sekvenčného učenia preukázali porovnateľný alebo dokonca lepší výkon ako výkonnosť RNN. [8]
|
||||||
|
|
||||||
|
**Modelová architektúra**
|
||||||
|
|
||||||
|
Väčšina konkurenčných prenosových modelov neurónovej sekvencie má štruktúru encoder-decoder. V tomto prípade encoder mapuje vstupnú sekvenciu symbolových reprezentácií (x1, ..., xn) na sekvenciu spojitých reprezentácií z = (z1, ..., zn). Vzhľadom na z, decoder potom generuje výstupnú sekvenciu (y1, ..., ym) symbolov jeden po druhom. V každom kroku je model automaticky regresívny a pri generovaní ďalšieho spotrebuje predtým vygenerované symboly ako ďalší vstup. [1]
|
||||||
|
|
||||||
|
|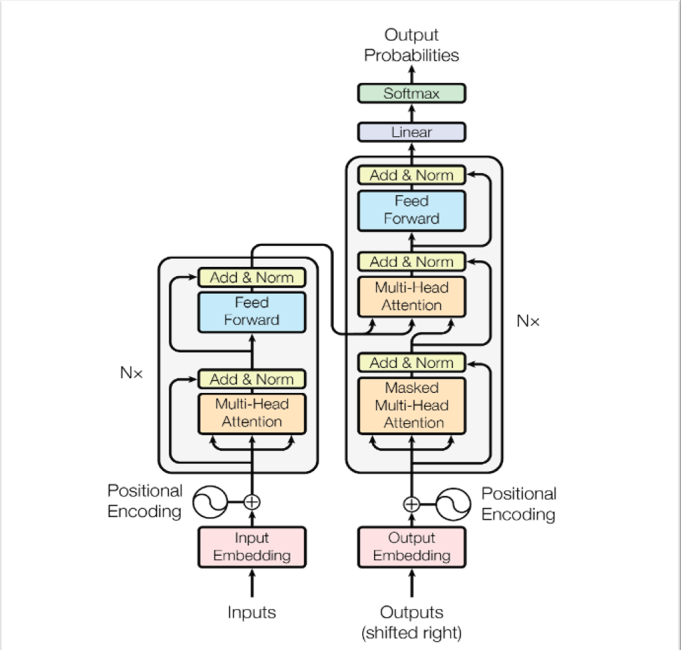|
|
||||||
|
|:--:|
|
||||||
|
|Obr 1. Modelová architektúra Transformer|
|
||||||
|
|
||||||
|
## Encoder-Decoder architektúra
|
||||||
|
|
||||||
|
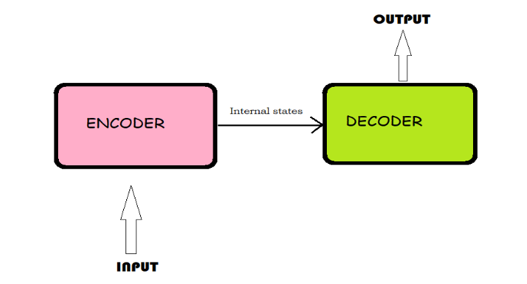
Rovnako ako predchádzajúce modely, Transformer používa architektúru encoder-decoder. Encoder-Decoder architektúra je spôsob použitia rekurentných neurónových sietí na problémy s predikciou sekvencie k sekvencii. Pôvodne bol vyvinutý pre problémy so strojovým prekladom, aj keď sa osvedčil pri súvisiacich problémoch s predikciou sekvencie k sekvencii, ako je zhrnutie textu a zodpovedanie otázok. Skladá sa z 3 častí (encoder, intermediate vector a decoder).
|
||||||
|
|
||||||
|
Encoder – prijme jeden prvok vstupnej sekvencie v každom časovom kroku, spracuje ho, zhromaždí informácie o danom prvku a šíri ho ďalej.
|
||||||
|
|
||||||
|
Intermediate vector – konečný vnútorný stav vytvorený z časti encoder modelu. Obsahuje informácie o celej vstupnej sekvencii, ktoré pomôžu decoderu robiť presné predpovede.
|
||||||
|
|
||||||
|
Decoder – predpovedá výstup v každom časovom kroku.
|
||||||
|
|
||||||
|
Encoder pozostáva z kódovacích vrstiev, ktoré spracovávajú vstup iteračne jednu vrstvu za druhou, zatiaľ čo decoder pozostáva z dekódovacích vrstiev, ktoré robia to isté s výstupom encodera. Funkciou každej vrstvy encodera je generovať kódovanie, ktoré obsahuje informácie o tom, ktoré časti vstupov sú navzájom relevantné. Odošle svoje kódovanie do ďalšej vrstvy encodera ako vstupy. Každá decoderová vrstva robí opak, pričom použije všetky kódovania a na začlenenie výstupnej sekvencie použije svoje začlenené kontextové informácie. Aby sa to dosiahlo, každá vrstva encodera a decodera využíva mechanizmus pozornosti.
|
||||||
|
|
||||||
|
Pri každom vstupe pozornosť zvažuje relevanciu každého ďalšieho vstupu a čerpá z neho pri vytváraní výstupu. Každá decoderová vrstva má mechanizmus dodatočnej pozornosti, ktorý čerpá informácie z výstupov predchádzajúcich decoderov, než vrstva decodera čerpá informácie z kódovaní.
|
||||||
|
|
||||||
|
Obe vrstvy encodera a decodera majú feed-forward neurónovú sieť (umelá neurónová sieť, v ktorej spojenia medzi uzlami netvoria cyklus) na dodatočné spracovanie výstupov a obsahujú zvyškové spojenia a kroky na normalizácie vrstiev. [3]
|
||||||
|
|
||||||
|
||
|
||||||
|
|:--:|
|
||||||
|
|Obr 2. Štruktúra modelu sequence to sequence (encoder-decoder)|
|
||||||
|
|
||||||
|
**Transformer Encoder**
|
||||||
|
|
||||||
|
Encoder sa skladá zo zásobníka _N = 6_ rovnakých vrstiev. Každá vrstva má dve podvrstvy. Prvým je multi-head self-attention mechanizmus a druhým je jednoduchá polohovo plne prepojená sieť spätnej väzby. Multi-head Attention je modul pre mechanizmy pozornosti, ktorý prechádza mechanizmom pozornosti niekoľkokrát paralelne. Self-attention, tiež známy ako Intra-attention, je mechanizmus pozornosti, ktorý spája rôzne polohy jednej sekvencie s cieľom vypočítať reprezentáciu tej istej sekvencie. Okolo každej z dvoch čiastkových vrstiev sa používa zvyškové spojenie, po ktorom nasleduje normalizácia vrstvy. To znamená, že výstupom každej podvrstvy je _LayerNorm (x + Sublayer (x))_, kde _Sublayer (x)_ je funkcia implementovaná samotnou podvrstvou. Aby sa uľahčili tieto zvyškové spojenia, všetky podvrstvy v modeli, ako aj vkladacie vrstvy, produkujú výstupy dimenzie _dmodel_ = 512. [1]
|
||||||
|
|
||||||
|
**Transformer Decoder**
|
||||||
|
|
||||||
|
Decoder je tiež zložený zo zásobníka _N = 6_ rovnakých vrstiev. Okrem dvoch podvrstiev v každej vrstve encodera, decoder vkladá tretiu podvrstvu, ktorá vykonáva multi-head attention nad výstupom encoder zásobníka. Podobne ako encoder, používa zvyškové spojenia okolo každej z podvrstiev, po ktorých nasleduje normalizácia vrstvy. Toto maskovanie v kombinácii so skutočnosťou, že vloženia výstupov sú posunuté o jednu pozíciu, zaisťuje, že predpovede pre polohu _i_ môžu závisieť iba od známych výstupov v polohách menších ako _i_. [1]
|
||||||
|
|
||||||
|
**Scaled Dot-Product Attention**
|
||||||
|
|
||||||
|
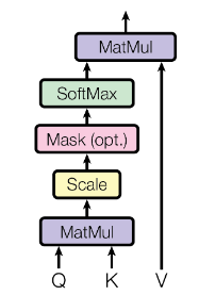
Našu osobitnú pozornosť nazývame „Pozornosť zameraná na produkt“ (obrázok 2). Vstup pozostáva z dotazov a kľúčov dimenzie _dk_ a hodnôt dimenzie _dv_. Bodové produkty dotazu vypočítame všetkými klávesmi, každý vydelíme √_dk_ a použijeme funkciu _softmax_, aby sme získali váhy hodnôt.
|
||||||
|
|
||||||
|
||
|
||||||
|
|:--:|
|
||||||
|
|Obr 3. Scaled Dot-Production Attention|
|
||||||
|
|
||||||
|
V praxi počítame funkciu pozornosti pre množinu dotazov súčasne zabalených do matice _Q_. Kľúče a hodnoty sú tiež zabalené spolu do matíc _K_ a _V_. Maticu výstupov vypočítame ako:
|
||||||
|
|
||||||
|
||
|
||||||
|
|:--:|
|
||||||
|
|
||||||
|
Dve najčastejšie používané funkcie pozornosti sú additive attention a dot-product attention. Dot-product attention je identická s naším algoritmom, s výnimkou faktora mierky 1/$\sqrt{dk}$. Additive attention počíta funkciu kompatibility pomocou siete spätnej väzby s jednou skrytou vrstvou. Aj keď sú tieto dva teoreticky náročné, dot-product attention je v praxi oveľa rýchlejšia a priestorovo efektívnejšia, pretože je možné ich implementovať pomocou vysoko optimalizovaného maticového multiplikačného kódu.
|
||||||
|
|
||||||
|
Zatiaľ čo pri malých hodnotách dk tieto dva mechanizmy fungujú podobne, additive attention prevyšuje pozornosť produktu bez toho, aby sa škálovala pri väčších hodnotách _dk_. Je pravdepodobné, že pri veľkých hodnotách _dk_ sa bodové produkty zväčšujú a tlačia funkciu _softmax_ do oblastí, kde má extrémne malé gradienty (v strojovom učení je gradient derivátom funkcie, ktorá má viac ako jednu vstupnú premennú). Aby sa tomuto efektu zabránilo, škálujeme bodové produkty o 1/$\sqrt{dk}$ [1] [4]
|
||||||
|
|
||||||
|
**Multi-Head Attention**
|
||||||
|
|
||||||
|
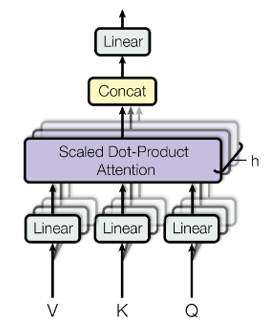
Namiesto toho, aby sme vykonávali funkciu jedinej pozornosti s _dmodel_-dimenzionálnymi kľúčmi, hodnotami a dotazmi, považuje sa za výhodné lineárne premietať dotazy, kľúče a hodnoty _h_-krát s rôznymi, naučenými lineárnymi projekciami do dimenzií _dk_, _dk_ a _dv_. Na každej z týchto predpokladaných verzií dotazov, kľúčov a hodnôt potom paralelne vykonávame funkciu pozornosti, čím sme získali _dv_-dimenzionálne výstupné hodnoty. Tieto sú zreťazené a znova premietnuté, výsledkom sú konečné hodnoty (obrázok 4).
|
||||||
|
|
||||||
|
||
|
||||||
|
|:--:|
|
||||||
|
|Obr 4. Multi-Head Attention|
|
||||||
|
|
||||||
|
Multi-head attention umožňuje modelu spoločne sa zaoberať informáciami z rôznych reprezentačných podpriestorov na rôznych pozíciách. Pri použití single-head attention to priemerovanie bráni.
|
||||||
|
|
||||||
|
|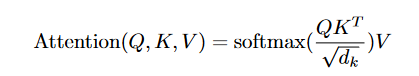|
|
||||||
|
|:--:|
|
||||||
|
|
||||||
|
|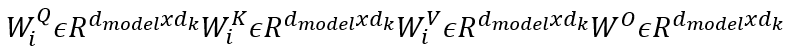|
|
||||||
|
|:--:|
|
||||||
|
|Obr 5. matice parametrov|
|
||||||
|
|
||||||
|
V tomto prípade si za _h_ dosadíme 8 paralelných vrstiev pozornosti, alebo „heads“. Pre každý z nich používame _dk_ = _dv_ = _dmodel/h_ = _64_. Vzhľadom na zmenšený rozmer každej hlavy sú celkové výpočtové náklady podobné nákladom na pozornosť single-head s plnou dimenzionalitou (koľko atribútov má množina údajov).
|
||||||
|
|
||||||
|
The Transformer využíva Multi-head attention tromi rôznymi spôsobmi:
|
||||||
|
|
||||||
|
Vo vrstvách „encoder-decoder attention“ pochádzajú dotazy z predchádzajúcej vrstvy decodera a pamäťové kľúče a hodnoty sú z výstupu encodera. To umožňuje každej pozícii v decoderi zúčastniť sa na všetkých pozíciách vo vstupnej sekvencii.
|
||||||
|
|
||||||
|
Encoder obsahuje vrstvy self-attention. Vo vrstve self-attention pochádzajú všetky kľúče, hodnoty a dotazy z rovnakého miesta, teda predchádzajúcej vrstvy v encoderu. Každá pozícia v encoderi sa môže venovať všetkým polohám v predchádzajúcej vrstve encodera.
|
||||||
|
|
||||||
|
Vrstvy self-attention v decoderi umožňujú každej pozícii v decoderi zúčastniť sa na všetkých polohách v decoderi až do danej polohy. Musí sa zabrániť toku informácii v decoderi, aby sa zachovala autoregresívna vlastnosť (model časových radov, ktorý používa pozorovania z predchádzajúcich časových krokov ako vstup do regresnej rovnice na predpovedanie hodnoty v nasledujúcom časovom kroku). To implementujeme do scaled dot-product attention pomocou maskovania (nastavením na -∞) všetkých hodnôt na vstupe softmax, ktoré zodpovedajú nezákonným spojeniam. [1] [4]
|
||||||
|
|
||||||
|
## R-Transformer
|
||||||
|
|
||||||
|
|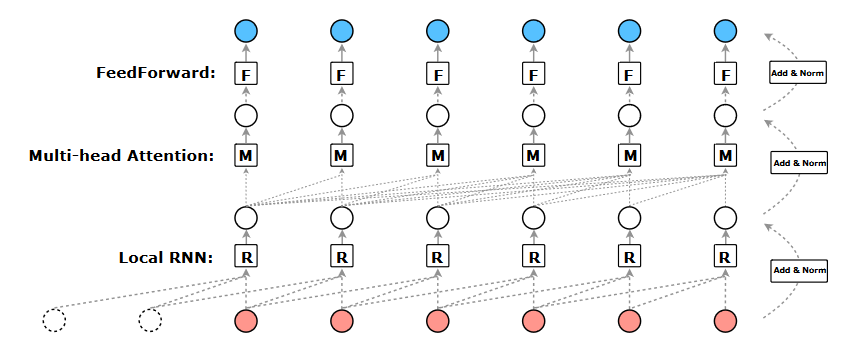|
|
||||||
|
|:--:|
|
||||||
|
|Obr 5. R-Transformer|
|
||||||
|
|
||||||
|
Navrhovaný transformátor R sa skladá zo stohu rovnakých vrstiev. Každá vrstva má 3 komponenty, ktoré sú usporiadané hierarchicky. Ako je znázornené na obrázku, nižšou úrovňou sú lokálne rekurentné neurónové siete, ktoré sú určené na modelovanie lokálnych štruktúr v sekvencii, stredná úroveň je Multi-head attention, ktorá je schopná zachytiť globálne dlhodobé závislosti a horná úroveň je position-wise feedforward sieť, ktorá vykonáva nelineárnu transformáciu prvkov. [2]
|
||||||
|
|
||||||
|
**Porovnanie s TCN**
|
||||||
|
|
||||||
|
R-Transformer je čiastočne motivovaný hierarchickou štruktúrou v TCN, v TCN je lokalita v sekvenciách zachytená konvolučnými filtrami. Sekvenčné informácie v rámci každého receptívneho poľa sú však pri konvolučných operáciách ignorované. Na rozdiel od toho, štruktúra LocalRNN v R-Transformer ju môže plne začleniť vďaka sekvenčnej povahe RNN. Pre modelovanie globálnych dlhodobých závislostí to TCN dosahuje pomocou rozšírených konvolúcií, ktoré fungujú na nenásledných pozíciách. Aj keď táto operácia vedie k väčším receptívnym poliam v nižších vrstvách, chýba značné množstvo informácií z veľkej časti pozícií v každej vrstve. [2]
|
||||||
|
|
||||||
|
**Porovnanie s Transformerom**
|
||||||
|
|
||||||
|
R-Transformer a štandardný Transformer majú podobnú kapacitu dlhodobého zapamätania vďaka Multi-head attention mechanizmu. Dve dôležité vlastnosti však odlišujú R-Transformer od štandardného Transformera. Po prvé, R-Transformer explicitne a efektívne zachytáva lokalitu v sekvenciách s novou štruktúrou LocalRNN, zatiaľ čo štandardný Transformer ju modeluje veľmi nepresne pomocou Multi-head attention, ktorá pôsobí na všetkých pozíciách. Po druhé, R-Transformer sa nespolieha na žiadne vloženie polohy ako Transformer. V skutočnosti sú výhody jednoduchého polohového zabudovania veľmi obmedzené a vyžaduje značné úsilie na navrhnutie efektívnych polohových zabudovaní, ako aj správnych spôsobov ich začlenenia. [2] [4]
|
||||||
|
|
||||||
|
## Zoznam použitej literatúry
|
||||||
|
|
||||||
|
[1]. VASWANI A., SHAZEER N., PARMAR N., USZKOREIT J., JONES L., GOMEZ N.A., KASIER L., POLUSUKHIN.I.: _Attention Is All You Need._ [online]. [citované 2017].
|
||||||
|
|
||||||
|
[2]. WANG Z., MA Y., LIU Z., TANG J.: _R-Transformer: Recurrent Neural Network Enhanced Transformer._ [online]. [citované 12-07-2019].
|
||||||
|
|
||||||
|
[3]. SRIVASTAVA S.: _Machine Translation (Encoder-Decoder Model)!._ [online]. [citované 31-10-2019].
|
||||||
|
|
||||||
|
[4]. ALAMMAR J.: _The Illustrated Transformer._ [online]. [citované 27-06-2018].
|
||||||
|
|
||||||
|
[5]. _Sequence Modeling with Neural Networks (Part 2): Attention Models_ [online]. [citované 18-04-2016].
|
||||||
|
|
||||||
|
[6]. GIACAGLIA G.: _How Transformers Work._ [online]. [citované 11-03-2019].
|
||||||
|
|
||||||
|
[7]. _Understanding LSMT Networks_ [online]. [citované 27-08-2015].
|
||||||
|
|
||||||
|
[8]. _6 Types of Artifical Neural Networks Currently Being Used in Machine Translation_ [online]. [citované 15-01-201].
|
||||||
|
|||||||
{kind=link}
|
After Width: | Height: | Size: 18 KiB |
BIN
pages/students/2016/patrik_pavlisin/dp22/Screenshot_1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 5.6 KiB |
BIN
pages/students/2016/patrik_pavlisin/dp22/rovnica 1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 12 KiB |
BIN
pages/students/2016/patrik_pavlisin/dp22/rovnica 2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 5.9 KiB |
{kind=link}
|
After Width: | Height: | Size: 16 KiB |
@ -18,11 +18,13 @@ Súvisiace práce:
|
|||||||
|
|
||||||
## Diplomová práca 2022
|
## Diplomová práca 2022
|
||||||
|
|
||||||
|
[Repozitár s výsledkami](https://git.kemt.fei.tuke.sk/tk634rv/dp2022)
|
||||||
|
|
||||||
Názov: Tvorba korpusu otázok a odpovedí v slovenskom jazyku pomocou strojového prekladu
|
Názov: Tvorba korpusu otázok a odpovedí v slovenskom jazyku pomocou strojového prekladu
|
||||||
|
|
||||||
Zadanie:
|
Zadanie:
|
||||||
|
|
||||||
1. Vypracujte prehľad jazykových mutácii overovacej množiny SQUAD a opíšte spôsob ich tvorby.
|
1. Vypracujte prehľad jazykových mutácii overovacej množiny SQUAD a opíšte spôsob ich tvorby.
|
||||||
2. Vypracujte prehľad aktuálnych systémov pre generovanie odpovede na otázku v prirodzenom jazyku.
|
2. Vypracujte prehľad aktuálnych systémov pre generovanie odpovede na otázku v prirodzenom jazyku.
|
||||||
3. Navrhnite postup pre vytvorenie korpusu otázok a odpovedí v slovenskom jazyku pomocou strojového prekladu z anglického jazyka,
|
3. Navrhnite postup pre vytvorenie korpusu otázok a odpovedí v slovenskom jazyku pomocou strojového prekladu z anglického jazyka,
|
||||||
4. Porovnajte strojovo preloženú verziu SQUAD s manuálne vytvorenou verziou.
|
4. Porovnajte strojovo preloženú verziu SQUAD s manuálne vytvorenou verziou.
|
||||||
@ -32,6 +34,30 @@ Zadanie:
|
|||||||
|
|
||||||
Cieľom je vytvoriť strojovo preloženú verziu SQUAD a overiť ju na QA systém.
|
Cieľom je vytvoriť strojovo preloženú verziu SQUAD a overiť ju na QA systém.
|
||||||
|
|
||||||
|
Sttetnutie 22.10.2021
|
||||||
|
|
||||||
|
Stav:
|
||||||
|
|
||||||
|
- Začatý prieskum jazykových mutácií strojovo preloženého SQUAD - španielsky, taliansky, francúzsky a švédsky.
|
||||||
|
- Začatý priestup prekladových API - napr. na google sa platí 20 $ za milion znakov.
|
||||||
|
- Zaujala ma metód prekladu pomocou špeciálnych znakov.
|
||||||
|
- Španielsky SQUAD má svoju štatistickú metódu zarovnania.
|
||||||
|
- Možnosti pre preklad:
|
||||||
|
- Google, Microsoft v rámci Free kreditu (asi ho je málo).
|
||||||
|
- Zakúpiť kredit cez projekt.
|
||||||
|
- Využiť "nekomerčný" projekt pre preklad, napr. [etranslation](https://ec.europa.eu/cefdigital/wiki/display/CEFDIGITAL/eTranslation).
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Úlohy:
|
||||||
|
|
||||||
|
- Pokračujte v písomnom prieskume jazykových mutácií SQUAD.
|
||||||
|
- Začnite pracovať na skripte na strojový preklad SQUAD. Jedna z možností je prepísať SQUAD do čisto textového formátu obohateného o špeciálne značky. Pripravte skript, ktorý prevedie SQUAD do čisto textového formátu obohateného o špeciálne značky. Vyskúšajte formát v dostupných prekladačoch. V prípade, že značky sú zachované, pripravte aj skript na spätnú konverziu preloženého výsledku do formátu SQUAD.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Stretnutie 15.10.
|
Stretnutie 15.10.
|
||||||
|
|
||||||
Stav:
|
Stav:
|
||||||
@ -46,7 +72,7 @@ Stav:
|
|||||||
|
|
||||||
Zásobník úloh:
|
Zásobník úloh:
|
||||||
|
|
||||||
- Urobiť vyhodnotenie SQUAD na knižnici Hugging Face Transformers.
|
- [ ] Urobiť vyhodnotenie SQUAD na knižnici Hugging Face Transformers.
|
||||||
|
|
||||||
## Diplomová práca 2021
|
## Diplomová práca 2021
|
||||||
|
|
||||||
|
|||||||
@ -18,10 +18,30 @@ Automatické odpovede z Wikipédie
|
|||||||
3. Nainštalujte a vyskúšajte jeden alebo viac existujúcich systémom pre generovanie odpovede na otázku v prirodzenom jazyku.
|
3. Nainštalujte a vyskúšajte jeden alebo viac existujúcich systémom pre generovanie odpovede na otázku v prirodzenom jazyku.
|
||||||
4. Na základe vykonaného prieskumu navrhnite systém pre generovanie odpovede na otázku v slovenskom jazyku.
|
4. Na základe vykonaného prieskumu navrhnite systém pre generovanie odpovede na otázku v slovenskom jazyku.
|
||||||
|
|
||||||
|
|
||||||
## Bakalársky projekt 2021
|
## Bakalársky projekt 2021
|
||||||
|
|
||||||
Vytovrenie prehľadu existujúcich systémov QA.
|
Vytovrenie prehľadu existujúcich systémov QA.
|
||||||
|
|
||||||
|
Stretnutie 28.10.2021
|
||||||
|
|
||||||
|
Stav:
|
||||||
|
|
||||||
|
Vypracovaný prehľad viacerých systémov QA a viacerých datasetov na QA.
|
||||||
|
|
||||||
|
Úlohy:
|
||||||
|
|
||||||
|
- Doplňte odkazy na zdroje, aj do textu.
|
||||||
|
- Doplňte teoretický úvod do QA.
|
||||||
|
- Dopíšte informácie o datasetoch SQUAD -1.0 a 2.0. a [MRQA](https://mrqa.github.io/2019/shared).
|
||||||
|
- Doplnte metodiku vyhodnotenia QA, napr. F1-precision-recall.
|
||||||
|
- Vyberte jeden systém QA, skúste ho nainštalovať a vyskúšať tak ako je.
|
||||||
|
|
||||||
|
Zásobník úloh:
|
||||||
|
|
||||||
|
- Nainštalujte si najprv balíček Anaconda.
|
||||||
|
- Prejdite si knihu https://diveintopython3.net/
|
||||||
|
|
||||||
Stretnutie 15.10.2021
|
Stretnutie 15.10.2021
|
||||||
|
|
||||||
Stav:
|
Stav:
|
||||||
|
|||||||
@ -10,11 +10,25 @@ Rok začiatku štúdia: 2019
|
|||||||
|
|
||||||
# Bakalárska práca 2022
|
# Bakalárska práca 2022
|
||||||
|
|
||||||
|
Grafové neurónové siete pre vyhľadávanie na internete.
|
||||||
|
|
||||||
|
https://arxiv.org/abs/1810.05997
|
||||||
|
|
||||||
|
|
||||||
Návrh na zadanie:
|
Návrh na zadanie:
|
||||||
|
|
||||||
|
1. Vysvetlite čo je to grafová neurónová sieť
|
||||||
|
2. Vypracujte prehľad najnovších druhov grafových neurónovýsh sietí.
|
||||||
|
3. Vyberte jednu metódu grafových neurónových sietí a navrhnite spôsob experimentálneho ohodnotenia sady prepojených článkov pomocou grafovej neurónovej siete.
|
||||||
|
4. Vyhodnnoťte experimenty a navrhnite zlepšenia Vášho prístupu.
|
||||||
|
|
||||||
|
|
||||||
Cieľ práce:
|
Cieľ práce:
|
||||||
|
|
||||||
|
Zlpešite metódy ohodnotenia prepojených ddkumentov na internete .
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## Bakalársky projekt 2021
|
## Bakalársky projekt 2021
|
||||||
|
|
||||||
|
|||||||
@ -34,17 +34,31 @@ Ciele:
|
|||||||
3. Vytvoriť kompletný reťazec CI-CD ku aplikácii Traktor. Automatický build a test, zobrazenie reportu.
|
3. Vytvoriť kompletný reťazec CI-CD ku aplikácii Traktor. Automatický build a test, zobrazenie reportu.
|
||||||
4. Vypracovanie písomného prehľadu.
|
4. Vypracovanie písomného prehľadu.
|
||||||
|
|
||||||
|
Stretnutie 22.10.
|
||||||
|
|
||||||
|
- Napísaný prvý draf s poznámkami o CI CD
|
||||||
|
- pripravené prvé test-case
|
||||||
|
|
||||||
|
Úlohy:
|
||||||
|
|
||||||
|
- Pokračujte v otvorených úlohách
|
||||||
|
- Vytvorte GIT repozitár s názvom bp2022 a nahrajte do neho testovacie scenáre.
|
||||||
|
|
||||||
|
|
||||||
|
Zásobník úloh:
|
||||||
|
|
||||||
|
- [ ] Skúste vytvoriť nasadenie vhodného CI CD na tuke cloude.
|
||||||
|
- [ ] Upravte scenáre tak, aby boli ľahko automaticky spustiteľné. vytvorte skript pre inštaláciu potrebných komponentov a pre spustenie testov.
|
||||||
|
|
||||||
|
|
||||||
Stretnutie 23.9.
|
Stretnutie 23.9.
|
||||||
|
|
||||||
- Dohodli sme sa na zadaní, cieľoch a názve.
|
- Dohodli sme sa na zadaní, cieľoch a názve.
|
||||||
|
|
||||||
Úlohy:
|
Úlohy:
|
||||||
|
|
||||||
- Urobte písomný prehľad systémov CI-CD. Uveďte zdroje z ktorých ste čerpali.
|
- [ ] Urobte písomný prehľad systémov CI-CD. Uveďte zdroje z ktorých ste čerpali.
|
||||||
- Nájdite vhodnú odbornú literatúru, uveďte ju do prehľadu. V školskej knižnici môže byť dobrá kniha.
|
- [ ] Nájdite vhodnú odbornú literatúru, uveďte ju do prehľadu. V školskej knižnici môže byť dobrá kniha.
|
||||||
- Navrhnite základné testovacie scenáre pre aplikáciu https://traktor.kemt.fei.tuke.sk.
|
- [x] Navrhnite základné testovacie scenáre pre aplikáciu https://traktor.kemt.fei.tuke.sk.
|
||||||
|
|
||||||
Zásobník úloh:
|
|
||||||
|
|
||||||
- Skúste vytvoriť nasadenie vhodného CI CD na tuke cloude.
|
|
||||||
|
|
||||||
|
|||||||
@ -12,9 +12,9 @@ rok začiatku štúdia: 2019
|
|||||||
# Bakalárska práca 2022
|
# Bakalárska práca 2022
|
||||||
|
|
||||||
|
|
||||||
- [Repozitár](https://git.kemt.fei.tuke.sk/ms111of/bp2022) ja
|
- [Repozitár](https://git.kemt.fei.tuke.sk/ms111of/bp2022)
|
||||||
|
|
||||||
Názov: Indexovanie slovenského textu
|
Názov: Indexovanie slovenského textu pomocou Elasticsearch
|
||||||
|
|
||||||
1. Vypracujte prehľad metód pre získavanie informácií.
|
1. Vypracujte prehľad metód pre získavanie informácií.
|
||||||
2. Vytvorte vyhľadávací index dokumentov zo slovenského internetu.
|
2. Vytvorte vyhľadávací index dokumentov zo slovenského internetu.
|
||||||
@ -29,6 +29,20 @@ Ciele na semester:
|
|||||||
- vedieť zaindexovať väčšie množstvo slovenských textov.
|
- vedieť zaindexovať väčšie množstvo slovenských textov.
|
||||||
- vytvoriť funkčné webové demo na vyhľadávanie v týchto textoch.
|
- vytvoriť funkčné webové demo na vyhľadávanie v týchto textoch.
|
||||||
|
|
||||||
|
|
||||||
|
Stretnutie 22.10.2021:
|
||||||
|
|
||||||
|
- Pokračovanie na otvrených úlohách - problémy s Essential Data Docker setup
|
||||||
|
|
||||||
|
Úlohy:
|
||||||
|
|
||||||
|
- Nainštalovať ES a Kibana, upravte compose na https://alysivji.github.io/elasticsearch-kibana-with-docker-compose.html
|
||||||
|
- Pozrieť si knihu https://nlp.stanford.edu/IR-book/ a urobiť z nej poznámky do teoretickej časti BP. Odvolávajte sa na túto knihu v texte.
|
||||||
|
- Skúste cez Kibanu zaindexovať jeden text a vyhľadať niečo.
|
||||||
|
- Preštudujte si ES Analyzer.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Stretnutie 15.10.2021
|
Stretnutie 15.10.2021
|
||||||
|
|
||||||
Stav:
|
Stav:
|
||||||
|
|||||||
@ -26,8 +26,8 @@ Nápady na balakársku prácu:
|
|||||||
|
|
||||||
Výsledky:
|
Výsledky:
|
||||||
|
|
||||||
- https://git.kemt.fei.tuke.sk/sh662er/rasa-flask-website
|
- [Repozitár s webovou aplikáciou](https://git.kemt.fei.tuke.sk/sh662er/rasa-flask-website)
|
||||||
- https://git.kemt.fei.tuke.sk/sh662er/Rasa
|
- [Repozitár s chatbotom](https://git.kemt.fei.tuke.sk/sh662er/Rasa)
|
||||||
|
|
||||||
## Bakalársky projekt 2021
|
## Bakalársky projekt 2021
|
||||||
|
|
||||||
@ -38,6 +38,12 @@ Ciele:
|
|||||||
|
|
||||||
- - -
|
- - -
|
||||||
|
|
||||||
|
Stretnutie 22.10.2021
|
||||||
|
|
||||||
|
- Urobené webové rozhranie pre analýzu konverzácií.
|
||||||
|
|
||||||
|
Pokračovať v otvorených úlohách.
|
||||||
|
|
||||||
Stretnutie 12.10.
|
Stretnutie 12.10.
|
||||||
|
|
||||||
Stav:
|
Stav:
|
||||||
@ -57,7 +63,7 @@ Stav:
|
|||||||
Zásobník úloh:
|
Zásobník úloh:
|
||||||
|
|
||||||
- [ ] Vytvorte dockerfile.
|
- [ ] Vytvorte dockerfile.
|
||||||
- [ ] Analyzovať logy z konverzácií. Pripraviť export konverzácií v JSON pre spracovanie a HTML formáte pre zobrazenie.
|
- [x] Analyzovať logy z konverzácií. Pripraviť export konverzácií v JSON pre spracovanie a HTML formáte pre zobrazenie.
|
||||||
|
|
||||||
- - -
|
- - -
|
||||||
|
|
||||||
|
|||||||
@ -6,45 +6,32 @@ author: Daniel Hládek
|
|||||||
|
|
||||||
! Cieľ:
|
! Cieľ:
|
||||||
!
|
!
|
||||||
! - Natrénovať a slovenský jazykový model typu BERT z korpusu webových textov
|
! - Natrénovať a vyhodnotiť slovenský jazykový model typu BERT z korpusu webových textov
|
||||||
! - Vyhodnotiť jazykový model dotrénovaním na úlohách:
|
|
||||||
! - SK-QUAD 2.0
|
|
||||||
! - POS z Slovak Treebank
|
|
||||||
! - kategórie zo Slovak Categorized news Corpus
|
|
||||||
|
|
||||||
## Súvisiace projekty
|
## Súvisiace projekty
|
||||||
|
|
||||||
- [SlovakBERT](https://github.com/gerulata/slovakbert) od Kinit, a [článok](https://arxiv.org/abs/2109.15254)
|
- [SlovakBERT](https://github.com/gerulata/slovakbert) od Kinit, a [článok](https://arxiv.org/abs/2109.15254)
|
||||||
- [SK Quad](/topics/question) - Slovak Question Answering Dataset
|
- [SK Quad](/topics/question) - Slovak Question Answering Dataset
|
||||||
- bakalárska práca [Ondrej Megela](/students/2018/ondrej_megela)
|
- bakalárska práca [Ondrej Megela](/students/2018/ondrej_megela)
|
||||||
|
- https://git.kemt.fei.tuke.sk/dano/bert-train
|
||||||
## Hardvérové požiadavky
|
|
||||||
|
|
||||||
[https://medium.com/nvidia-ai/how-to-scale-the-bert-training-with-nvidia-gpus-c1575e8eaf71](zz):
|
|
||||||
|
|
||||||
When the mini-batch size n is multiplied by k, we should multiply the starting learning rate η by the square root of k as some theories may suggest. However, with experiments from multiple researchers, linear scaling shows better results, i.e. multiply the starting learning rate by k instead.
|
|
||||||
|
|
||||||
| BERT Large | 330M |
|
|
||||||
| BERT Base | 110M |
|
|
||||||
|
|
||||||
Väčšia veľkosť vstupného vektora => menšia veľkosť dávky => menší parameter učenia => pomalšie učenie
|
|
||||||
|
|
||||||
|
|
||||||
## Hotové úlohy
|
## Hotové úlohy
|
||||||
|
|
||||||
|
- Vyhodnotenie na SK SQUAD, UDP POS tagging
|
||||||
|
- Trénovacie skripty
|
||||||
- Dotrénovaný model multilingual BERT base na SK QUAD, funguje demo skript. Nefunguje exaktné vyhodnotenie.
|
- Dotrénovaný model multilingual BERT base na SK QUAD, funguje demo skript. Nefunguje exaktné vyhodnotenie.
|
||||||
- Natrénovaný model Electra-small 128, slovník SNK Morpho 1M slov., 30 tisíc BPE tokenov. Squad Vyhodnotenie 0.17
|
- Natrénovaný model Electra-small 128, 256 batch size, learning 2e-4, skweb2017dedup, Slovník 32K wordpiece, 0.83 POS, 0.51 Squad
|
||||||
|
|
||||||
## Rozpracované úlohy
|
## Budúce úlohy
|
||||||
|
|
||||||
|
- Konvertovať do Transformers pomocou ransformers/src/transformers/models/electra/convert_electra_original_tf_checkpoint_to_pytorch.py
|
||||||
|
- Pridať OSCAR a Wikipedia do trénovania.
|
||||||
|
- Trénovanie na TPU Google Colab
|
||||||
- Natrénovať Electra Base.
|
- Natrénovať Electra Base.
|
||||||
- Vylepšiť parametre trénovania.
|
|
||||||
- Dokončiť SK SQUAD databázu pre exaktné vyhodnotenie.
|
- Dokončiť SK SQUAD databázu pre exaktné vyhodnotenie.
|
||||||
- Dotrénovať model na SK QUAD a exaktne vyhodnotiť pomocou oficiálneho squad skriptu.
|
- Pripraviť aj iné množiny na vyhodnotnie: kategorizácia textu na SCNC1.
|
||||||
- Pripraviť aj iné množiny na vyhodnotnie:
|
|
||||||
- kategorizácia textu na SCNC1.
|
|
||||||
- POS na Slovak Treebank.
|
|
||||||
- pripraviť iné množiny.
|
|
||||||
|
|
||||||
## Poznámky
|
## Poznámky
|
||||||
|
|
||||||
@ -68,7 +55,6 @@ Väčšia veľkosť vstupného vektora => menšia veľkosť dávky => menší pa
|
|||||||
## Budúci výskum
|
## Budúci výskum
|
||||||
|
|
||||||
- Zistiť aký je optimálny počet tokenov? V Slovak BERT použili 50k.
|
- Zistiť aký je optimálny počet tokenov? V Slovak BERT použili 50k.
|
||||||
- Zistiť aký je optimálný slovník?
|
|
||||||
- Pripraviť webové demo na slovenské QA.
|
- Pripraviť webové demo na slovenské QA.
|
||||||
- Integrovať QA s dialógovým systémom.
|
- Integrovať QA s dialógovým systémom.
|
||||||
- Integrovať QA s vyhľadávačom.
|
- Integrovať QA s vyhľadávačom.
|
||||||
@ -76,3 +62,14 @@ Väčšia veľkosť vstupného vektora => menšia veľkosť dávky => menší pa
|
|||||||
- Natrénovať BART model.
|
- Natrénovať BART model.
|
||||||
- Natrénovať model založený na znakoch.
|
- Natrénovať model založený na znakoch.
|
||||||
- Adaptovať SlovakBERT na SQUAD. To znamená dorobiť úlohu SQUAD do fairseq.
|
- Adaptovať SlovakBERT na SQUAD. To znamená dorobiť úlohu SQUAD do fairseq.
|
||||||
|
|
||||||
|
## Hardvérové požiadavky
|
||||||
|
|
||||||
|
[https://medium.com/nvidia-ai/how-to-scale-the-bert-training-with-nvidia-gpus-c1575e8eaf71](zz):
|
||||||
|
|
||||||
|
When the mini-batch size n is multiplied by k, we should multiply the starting learning rate η by the square root of k as some theories may suggest. However, with experiments from multiple researchers, linear scaling shows better results, i.e. multiply the starting learning rate by k instead.
|
||||||
|
|
||||||
|
| BERT Large | 330M |
|
||||||
|
| BERT Base | 110M |
|
||||||
|
|
||||||
|
Väčšia veľkosť vstupného vektora => menšia veľkosť dávky => menší parameter učenia => pomalšie učenie
|
||||||
|
|||||||